Материалы по тегу: nvidia
|
12.08.2024 [17:26], Руслан Авдеев
AMD сначала разрешила, а потом запретила доступ к коду проекта ZLUDA по запуску CUDA-приложений на своих ускорителяхПохоже, команда юристов AMD намерена получить полный контроль над значительной частью базы ПО, созданной в рамках открытого проекта ZLUDA. По данным The Register, ранее в этом году компания прекратила финансовую поддержку инициативы, позволяющей использовать CUDA-код на сторонних ускорителях. Теперь, похоже, AMD ужесточает политику. Изначально проект ZLUDA создавался для запуска CUDA-приложений без каких-либо модификаций на GPU Intel при поддержке со стороны самой Intel. Позже автор проекта Анджей Яник (Andrzej Janik) подписал с AMD контракт, в рамках которого предполагалось создание аналогичного инструмента для ускорителей AMD. В начале 2022 года проект стал закрытым, но уже в начале 2024 года Яник снова сделал проект открытым по соглашению сторон, поскольку AMD решила прекратить финансирование и дальнейшее развитие ZLUDA. 
Источник изображения: Mapbox/unsplash.com Однако позже AMD изменила своё решение. Именно по её запросу соответствующее ПО стало недоступным. По словам Яника, юристы AMD заявили, что предыдущее письмо с разрешением на публикацию кода не является юридически значимым документом. Яник после консультации с юристом пришёл к выводу, что законность писем не имеет значения, поскольку потенциальная судебная тяжба с AMD отняла бы у него слишком много ресурсов, а её результат трудно предсказать. Проще и быстрее переписать проект на базе старых наработок, хотя часть функций, вероятно, воссоздать не выйдет. Почему в AMD решили попытаться «похоронить» ZLUDA, достоверно неизвестно. Первой и самой очевидной причиной может быть желание AMD дистанцироваться от проекта, возможно, нарушающего права NVIDIA на интеллектуальную собственность. NVIDIA уже запретила использовать CUDA-код на других аппаратных платформах, создавая «слои трансляции CUDA», и прибегать к декомпиляции всего, что создано с помощью CUDA SDK, для адаптации ПО для запуска на других GPU. Кроме того, в AMD могли посчитать, что само существование ZLUDA могло бы помешать внедрению собственного ПО. Собственный инструментарий AMD предполагает именно портирование и рекомпиляцию исходного кода CUDA вместо запуска уже готовых программ. Кроме того, мог возникнуть конфликт относительного того, какой код, созданный в рамках ZLUDA, можно выпускать, а какой нет.
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры.
05.08.2024 [12:48], Руслан Авдеев
NVIDIA купила Run:ai, чтобы «похоронить» наработки стартапа, подозревает Минюст СШАПо данным Silicon Angle, американское Министерство юстиции взялось за сделку NVIDIA по покупке стартапа Run:ai, занимающегося разработкой софта для управления рабочими нагрузками ИИ. ПО позволяет более эффективно использовать вычислительные ресурсы при работе с ИИ-приложениями, что может оказаться помехой для бизнеса NVIDIA. Информация о расследовании появилась у СМИ на прошлой неделе. Пару месяцев назад источники уже сообщали, что министерство расследует доминирующее положение NVIDIA на рынке ИИ-чипов. По данным источников сделку будут рассматривать независимо от предыдущего расследования. 
Источник изображения: Romain Dancre/unsplash.com NVIDIA купила стартап из Тель-Авива Run:ai (зарегистрированный как Runai Labs Ltd) в начале года за $700 млн. Ранее он уже привлёк от инвесторов порядка $118 млн. Предлагаемая им платформа позволяет расширить функциональность кластеров ускорителей и повысить их уровень утилизации. В Run:ai позволяет запускать на одном и том же ускорителе несколько задач. Также платформа позволит избегать конфликтов памяти, а также присущих ИИ-вычислениям ошибок. Выполнение рабочих нагрузок может быть ускорено другими методами. Например, для обучения языковой модели разработчики разбивают её на части, каждую из которых тренируют на отдельном ускорителе. Фрагменты регулярно обмениваются данными в ходе обучения, но работа настроена благодаря Run:ai таким образом, что обмен данными происходит быстрее, а сеансы обучения выходят короче. Другими словами, реализация ИИ-проектов может быть ускорена без добавления новых вычислительных ресурсов. Верно и обратное, задачи можно завершать с той же скоростью с использованием меньшего числа ускорителей. Как раз последний вариант привлёк внимание Министерства юстиции. Платформа, способная снизить количество необходимых ускорителей, может привести к тому, что некоторые клиенты станут покупать меньше продуктов NVIDIA. Чиновники подозревают IT-гиганта в том, что он намерен просто «похоронить» технологию, угрожающую её основному бизнесу. 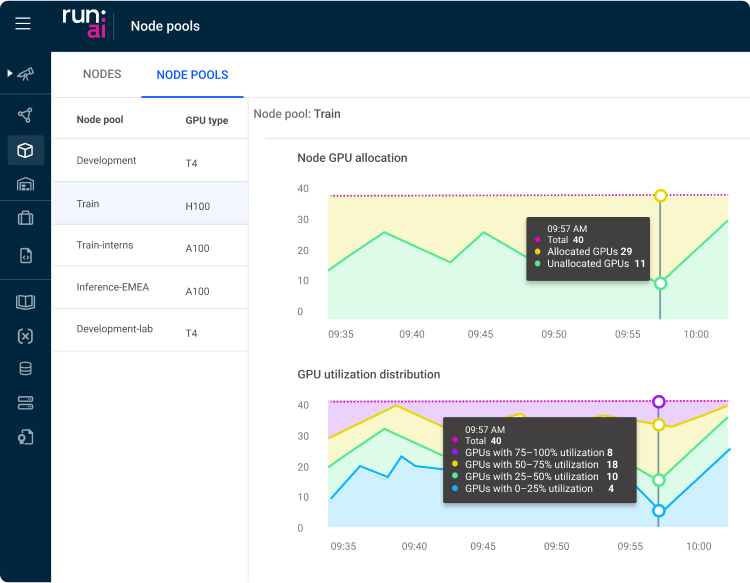
Источник изображения: Run:ai Изучаются и другие аспекты деятельности компании. Например, в министерстве желают знать, не ставит ли NVIDIA условием для доступа к своим ускорителям покупку клиентами других своих продуктов или не ставит ли она условием обязательство не покупать оборудование у конкурентов. В NVIDIA утверждают, что лидируют на рынке совершенно заслуженно, соблюдая все законы, а продукты компании открыты и доступны любым бизнесам — клиенты могут сами принять решение, которое подходит им лучше всего. В прошлом месяце появлялась информация о том, что выдвинуть обвинения против NVIDIA намерен антимонопольный регулятор Франции. Вероятно, в поле зрения попадает набор инструментов CUDA для разработки ПО, используемого с ускорителями и видеокартами компании. Чиновников беспокоит и вложения NVIDIA в облачные компании, ориентирующиеся на ИИ, вроде CoreWeave, массово внедряющие ускорители компании в своей инфраструктуре. Предполагается, что инвестор сможет повлиять на предпочтения партнёров при покупке ускорителей и ПО.
05.08.2024 [08:16], Сергей Карасёв
Новые кластеры Supermicro SuperCluster с ускорителями NVIDIA L40S ориентированы на платформу Omniverse
emerald rapids
hardware
intel
l40
nvidia
omniverse
sapphire rapids
supermicro
xeon
ии
кластер
сервер
Компания Supermicro расширила семейство высокопроизводительных вычислительных систем SuperCluster, предназначенных для обработки ресурсоёмких приложений ИИ/HPC. Представленные решения оптимизированы для платформы NVIDIA Omniverse, которая позволяет моделировать крупномасштабные виртуальные миры в промышленности и создавать цифровых двойников. Системы SuperCluster for NVIDIA Omniverse могут строиться на базе серверов SYS-421GE-TNRT или SYS-421GE-TNRT3 с поддержкой соответственно восьми и четырёх ускорителей NVIDIA L40S. Обе модели соответствуют типоразмеру 4U и допускают установку двух процессоров Intel Xeon Emerald Rapids или Sapphire Rapids в исполнении Socket E (LGA-4677) с показателем TDP до 350 Вт (до 385 Вт при использовании СЖО). Каждый из узлов в составе новых систем SuperCluster несёт на борту 1 Тбайт оперативной памяти DDR5-4800, два NVMe SSD вместимостью 3,8 Тбайт каждый и загрузочный SSD NVMe M.2 на 1,9 Тбайт. В оснащение включены четыре карты NVIDIA BlueField-3 (B3140H SuperNIC) или NVIDIA ConnectX-7 (400G NIC), а также одна карта NVIDIA BlueField-3 DPU Dual-Port 200G. Установлены четыре блока питания с сертификатом Titanium мощностью 2700 Вт каждый. В максимальной конфигурации система SuperCluster for NVIDIA Omniverse объединяет пять стоек типоразмера 48U. В общей сложности задействованы 32 узла Supermicro SYS-421GE-TNRT или SYS-421GE-TNRT3, что в сумме даёт 256 или 128 ускорителей NVIDIA L40S. 
Источник изображения: Supermicro Кроме того, в состав такого комплекса входят три узла управления Supermicro SYS-121H-TNR Hyper System, три коммутатора NVIDIA Spectrum SN5600 Ethernet 400G с 64 портами, ещё два коммутатора NVIDIA Spectrum SN5600 Ethernet 400G с 64 портами для хранения/управления, два коммутатора управления NVIDIA Spectrum SN2201 Ethernet 1G с 48 портами. При необходимости конфигурацию SuperCluster for NVIDIA Omniverse можно оптимизировать под задачи заказчика, изменяя масштаб вплоть до одной стойки. В этом случае применяются четыре узла Supermicro SYS-421GE-TNRT или SYS-421GE-TNRT3.
04.08.2024 [15:25], Сергей Карасёв
В Google Cloud появился выделенный ИИ-кластер для стартапов Y CombinatorОблачная платформа Google Cloud, по сообщению TechCrunch, развернула выделенный субсидируемый кластер для ИИ-стартапов, которые поддерживаются венчурным фондом Y Combinator. Предполагается, что данная инициатива поможет Google привлечь в своё облако перспективные компании, которым в будущем могут понадобиться значительные вычислительные ресурсы. Отмечается, что для ИИ-стартапов на ранней стадии одной из самых распространённых проблем является ограниченная доступность вычислительных мощностей. Крупные предприятия обладают достаточными финансами для заключения многолетних соглашений с поставщиками облачных услуг на доступ к НРС/ИИ-сервисам. Однако у небольших фирм с этим возникают сложности. Ожидается, что Google Cloud поможет в решении данной проблемы. Google предоставит выделенный кластер с приоритетным доступом для стартапов Y Combinator. Платформа базируется на ускорителях NVIDIA и тензорных процессорах (TPU) самой Google. Каждый участник программы получит кредиты на сумму $350 тыс. для использования облачных сервисов Google в течение двух лет. Кроме того, Google предоставит стартапам кредиты в размере $12 тыс. на расширенную поддержку и бесплатную годовую подписку Google Workspace Business Plus. Молодые компании также смогут консультироваться с экспертами Google в области ИИ. 
Источник изображения: Google Оказав поддержку ИИ-стартапам, Google в дальнейшем сможет рассчитывать на заключение с ними долгосрочных контрактов на обслуживание. Говорится, что за последние 18 лет примерно 5 % стартапов Y Combinator стали единорогами с оценкой $1 млрд и более. Такие компании могут принести облачной платформе Google значительную выручку в случае заключения соглашения о сотрудничестве. С другой стороны, фонд Y Combinator сможет привлечь больше перспективных ИИ-проектов, предлагая вычислительные ресурсы Google вместе со своей поддержкой. Аналогичные программы есть и у других игроков. Так, венчурный инвестор Andreessen Horowitz (a16z) тоже запасается ИИ-ускорителями, чтобы стать более привлекательным для ИИ-стартапов. AWS предлагает ИИ-стартапам доступ к облаку и сервисам, а Alibaba Cloud готова предоставить ресурсы в обмен на долю в стартапе. Сама Google на днях наняла основателей стартапа Character.AI и лицензировал его модели. Стартапу, по-видимому, не хватило средств на ИИ-ускорители для дальнейшего развития.
01.08.2024 [15:32], Руслан Авдеев
У Twitter нашёлся заброшенный кластер из когда-то дефицитных NVIDIA V100Работавший в Twitter во времена продажи социальной сети Илону Маску (Elon Musk) разработчик Тим Заман (Tim Zaman), ныне перешедший в Google DeepMind, рассказал о необычной находке, передаёт Tom’s Hardware. По его словам, через несколько недель после сделки специалисты обнаружили кластер из 700 простаивающих ускорителей NVIDIA V100. Сам Заман охарактеризовал находку как «честную попытку построить кластер в рамках Twitter 1.0». Об этом событии Заману напомнили новости про ИИ-суперкомпьютер xAI из 100 тыс. ускорителей NVIDIA H100. Находка наводит на печальные размышления о том, что Twitter годами имел в распоряжении 700 высокопроизводительных ускорителей на архитектуре NVIDIA Volta, которые были включены, но простаивали без дела. Они были в дефиците на момент выпуска в 2017 году, а Заман обнаружил бездействующий кластер только в 2022 году. Нет ничего удивительного, что приблизительно тогда же было решено закрыть часть дата-центров социальной сети. Примечательно, что в кластере использовались PCIe-карты, а не SXM2-версии V100 с NVLink, которые намного эффективнее в ИИ-задачах. 
Источник изображения: Alexander Shatov/unsplash.com Заман поделился и соображениями об «ИИ-гигафабрике». Он предположил, что использование 100 тыс. ускорителей в рамках одной сетевой фабрики должно стать эпическим вызовом, поскольку на таких масштабах неизбежны сбои, которыми необходимо грамотно управлять для сохранения работоспособности всей системы. По его мнению, следует разделить систему на независимые домены (крупные кластеры так и устроены). Заман также задался вопросом, какое максимальное количество ускорителей может существовать в рамках одного кластера. По мере того, как компании создают всё более масштабные системы обучения ИИ, будут выявляться как предсказуемые, так и неожиданные пределы того, сколько ускорителей можно объединить.
31.07.2024 [17:46], Руслан Авдеев
Появление NVIDIA Blackwell приведёт к увеличению доли СЖО в ЦОД до 10 % уже к концу годаРастущий спрос на высокопроизводительные вычисления ведёт к тому, что операторам ЦОД требуются всё более эффективные системы охлаждения для ИИ-серверов. По данным TrendForce, появление NVIDIA Blackwell к концу 2024 года приведёт к тому, что уровень проникновения СЖО в ЦОД может вырасти до 10 %. На решения Blackwell придётся около 83 % передовых продуктов компании. Отдельные ускорители (G)B200 будут потреблять около 1000 Вт. HGX-платформы по-прежнему будут объединять до восьми ускорителей, а NVL-стойки — сразу 36 или 72. Безусловно, всё это будет способствовать росту цепочки поставок СЖО для ИИ-серверов, поскольку традиционные системы воздушного охлаждения могут попросту не справиться. В частности, GB200 NVL36 и NVL72 могут потреблять до 70 кВт и 140 кВт соответственно. В TrendFirce уверены, что NVL36 будет использовать комбинацию жидкостного и воздушного охлаждения, а вот NVL72 без СЖО не обойтись. 
Источник изображения: NVIDIA Агентство выделяет основные элементы, входящие в цепочку поставок СЖО для стоек с GB200: водоблоки, модули распределения (CDU), коллекторы, быстроразъёмные соединения (QD) и теплообменники задней двери (RDHx). Основным поставщиком CDU для ИИ-решений NVIDIA сегодня является компания Vertiv, а Chicony, Auras, Delta и CoolIT проходят тестирование. По слухам, NVIDIA уже столкнулась с протечками из-за некачественных компонентов. В 2025 году поставки GB200 NVL36 должны достигнуть 60 тыс. стоек (суммарно 2,1–2,2 млн ускорителей). Тогда же NVIDIA начнёт предлагать облачным провайдерам и корпоративным клиентам конфигурации HGX, GB200 Rack и MGX, соотношение поставок ожидается на уровне 5:4:1. Стоечные варианты GB200 Rack рассчитаны в первую очередь на гиперскейлеров. 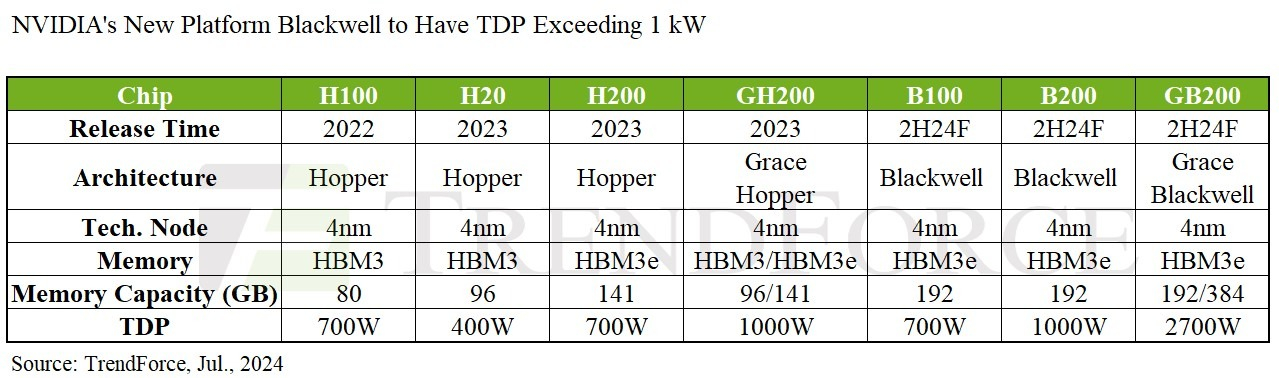
Источник изображения: TrendForce TrendForce прогнозирует, что NVIDIA может представить NVL36 уже в конце 2024 года и быстро выйти на рынок, а NVL72 появится только в 2025 году. Впрочем, облачные гиганты, вероятно, постараются избежать привязки к единственному поставщика и, возможно, захотят развернуть HGX/MGX-варианты на x86-чипах или вовсе задействуют ASIC собственной разработки. Кстати, компания NVIDIA ищет химика-материаловеда для разработки систем погружного жидкостного охлаждения для высокопроизводительных ускорителей. Специалист должен будет тестировать жидкости и материалы на совместимость, оценивать эффективность охлаждения, коррозионную стойкость и экологичность материалов, чтобы обеспечить оптимальную работу новых продуктов NVIDIA в ЦОД.
29.07.2024 [10:42], Сергей Карасёв
Провайдер облачной ИИ-платформы SMC намерен получить на развитие почти $1 млрдСингапурский стартап Sustainable Metal Cloud (SMC), по информации Bloomberg, рассчитывает привлечь почти $1 млрд для создания специализированной облачной платформы для задач ИИ. Речь идёт о системе на основе высокопроизводительных ускорителей NVIDIA. Фирма SMC основана в 2018 году. Она занимается созданием крупномасштабной инфраструктуры ЦОД: мощности площадки смогут использовать сторонние заказчики для разработки и запуска приложений ИИ. На сегодняшний день платформа SMC в Сингапуре объединяет приблизительно 1200 ускорителей NVIDIA H100. До конца текущего года их количество планируется довести до 5000. При этом реализована возможность масштабирования до 32 тыс. ускорителей. SMC использует технологию иммерсионного (погружного) охлаждения, которая, как утверждается, позволяет сократить выбросы углекислого газа в атмосферу на 48 % по сравнению с традиционными решениями (при работе с моделями ИИ). 
Источник изображения: SMC Как сообщает Bloomberg, SMC поддерживается сингапурской компанией ST Telemedia Global Data Centers (STT GDC). Говорится, что SMC находится на завершающей стадии осуществления инвестиционного раунда на сумму около $400 млн. Кроме того, компания намерена получить долговое финансирование в размере $550 млн. Таким образом, общая сумма средств, которые рассчитывает привлечь SMC, составляет $950 млн. Компания SMC создаёт новые облачные регионы в Сингапуре, Индии, Таиланде и Австралии. Оборудование размещается в независимо аккредитованных дата-центрах, что, как утверждается, позволяет формировать высокодоступную и безопасную инфраструктуру.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 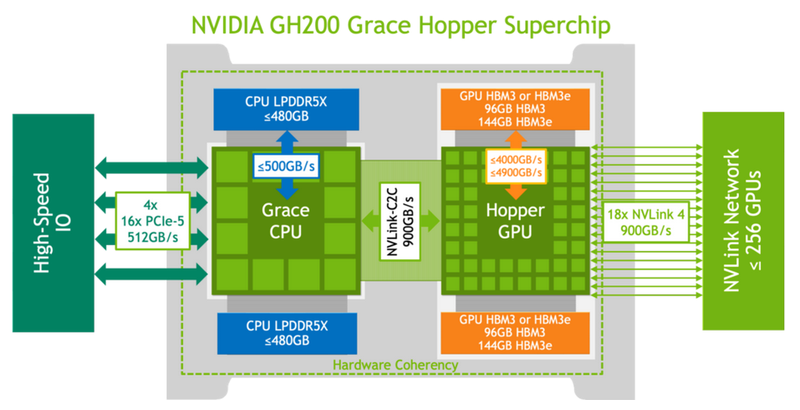
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 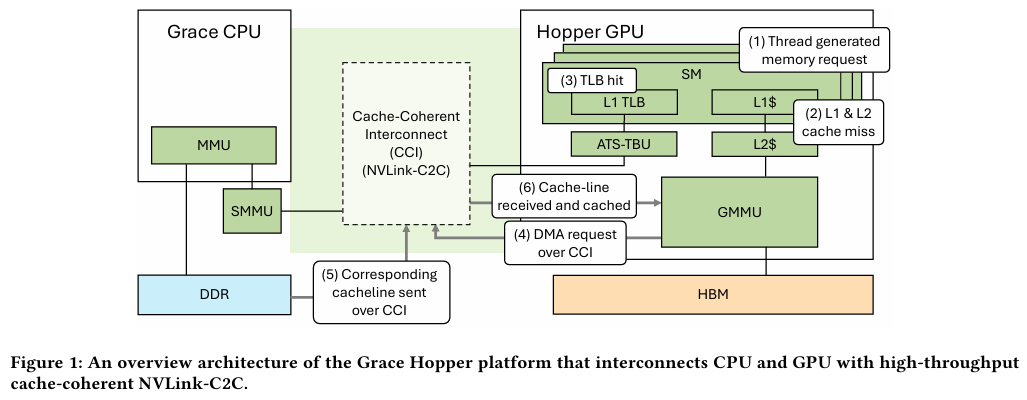
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 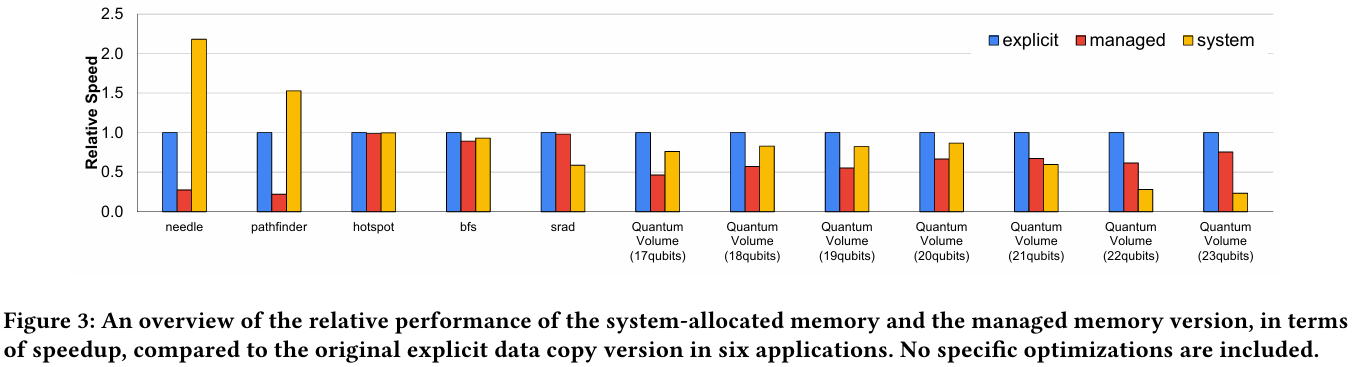
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
27.07.2024 [15:54], Сергей Карасёв
Поставщик ИИ-услуг Gcore привлёк на развитие $60 млн от Wargaming и других инвесторовПровайдер облачных и периферийных сервисов Gcore, по сообщению Datacenter Dynamics, осуществил раунд финансирования Series A, в ходе которого на развитие получено $60 млн. Инвестиционную программу возглавил разработчик и издатель игр Wargaming при участии Constructor Capital и Han River Partners. Gcore была основана в Люксембурге в 2014 году. Компания управляет инфраструктурой, которая позволяет клиентам развёртывать свои рабочие нагрузки ИИ (обучение и инференс) на периферии. Штаб-квартира Gcore находится в Люксембурге, а представительства располагаются в Вильнюсе, Кракове, Белграде, Никосии, Тбилиси, Ташкенте, Маниле, Сеуле и Токио. На сегодняшний день инфраструктура Gcore объединяет примерно 180 edge-точек на шести континентах и более 25 облачных локаций, а общая пропускная способность сети достигает 200 Тбит/с. В качестве технологических партнёров выступают Intel, Dell, Lenovo, Wallarm, Equinix, Graphcore, Digital-Realty, Wasabi, HP, AMD, Arista и Kentik. 
Источник изображения: Gcore Gcore заявляет, что применяет в составе своей сети новейшее оборудование на процессорах AMD и Intel последнего поколения. Реализованы надёжные средства защиты от несанкционированного доступа и кражи данных. Упомянуты система обнаружения вторжений (IDS), инструменты резервного копирования и восстановления, двухфакторная аутентификация, шифрование AES-128/256, сертифицированные операционные системы. Полученные в рамках раунда Series A средства будут направлены на дальнейшее расширение платформы Gcore, включая приобретение новых ИИ-серверов на базе ускорителей NVIDIA. Это первое внешнее привлечение капитала с момента основания компании. «Растущий спрос на инфраструктуру ИИ со стороны предприятий малого и среднего бизнеса подчёркивает важность этого финансирования. Мы очень рады поддержке таких инвесторов, как Wargaming, Constructor Capital и Han River Partners», — говорит Андре Райтенбах (Andre Reitenbach), генеральный директор Gcore. |
|

