Материалы по тегу: hardware
|
30.06.2026 [14:06], Руслан Авдеев
Crusoe инвестирует в израильские ЦОД $10 млрдCrusoe рассчитывает инвестировать в ЦОД на территории Израиля $10 млрд в течение 10–15 лет, сообщает Datacenter Dynamics. В частности, неооблачный провайдер заключил соглашения об аренде мощностей ЦОД ещё на 100 МВт, в дополнение к уже действующим там контрактам. Так, новые договоры предполагают расширение уже имеющегося соглашения с Anan Group с 40 до 80 МВт. Учитывается и недавно заключенный контракт с MegaDC на 67,6 МВт. Из них порядка 58 МВт придётся на технопарк Idan HaNegev Industrial Park, а оставшиеся 10 МВт — на площадку в Хайфе. В целом арендованные Crusoe мощности в Израиле достигнут 150 МВт. 
Источник изображения: Rade Šaptović/unsplash.com На днях компания Mega Or, владеющая MegaDC, раскрыла данные о контракте на 67,6 МВт. В документе, предназначенном для Тель-Авивской фондовой биржи имя заказчика не указано, но подчёркивается, что мощности в Idan HaNegev запустят в два этапа. Первая очередь заработает в IV квартале 2027 года, вторая — в I квартале 2028-го. Mega Or сообщает, что строительство обойдётся в $12 млн/МВт IT-мощностей. Соглашение на 10 МВт, касающееся проекта в Хайфе, должно быть реализовано во II квартале 2027 года, стоимость строительства оценивается примерно в $9 млн/МВт. В MegaDC рассчитывают, что только два этих объекта будут приносить около $85 млн выручки ежегодно. Неооблачный провайдер Nebius также активно наращивает присутствие в Израиле. Общий объём арендованных мощностей оценивается в 120 МВт. Также в январе компания подписала в этом году соглашение с Mega Or, обязавшись арендовать 80 МВт мощностей. У Crusoe большие планы. В первой половине июня сообщалось, что компания набрала контрактов почти на 5 ГВт ИИ ЦОД, хотя один из крупных проектов поставлен на паузу. В конце месяца появились данные, что Crusoe обеспечит Meta✴ 1,6 ГВт новых мощностей ЦОД.
30.06.2026 [13:34], Руслан Авдеев
Первый ЦОД, построенный в действующей шахте, открылся в Доломитовых АльпахСостоялся официальный ввод в эксплуатацию дата-центра, построенного в Доломитовых Альпах на северо-востоке Италии. ЦОД Intacture расположен на глубине 100 м в каменоломне Tuenetto di Predaia в итальянской долине Валь-ди-Нон. Рядом с помещениями ЦОД — хранилища яблок, игристого вина и сыра, сообщает Datacenter Dynamics. Проект стоимостью €50 млн ($58 млн) реализован в рамках государственно-частного партнёрства Trentino DataMine, организованного Университетом Тренто и местными бизнесами в сентябре 2025 года. О завершении строительства сообщалось ещё в апреле, но официальный ввод в эксплуатацию состоялся только теперь. На реализацию проекта ушло немногим более двух лет. Более €18 млн ($21 млн) из всех инвестиций поступило в рамках одной из программ Национального плана восстановления и устойчивости Италии (National Recovery and Resilience Plan, PNRR). В Trentino DataMine заявляют, что Intacture — первый ЦОД в Европе, построенный непосредственно в действующей шахте. Мощность составляет 6 МВт, объект не использует воды и на 100 % питается за счёт электричества из возобновляемых источников. Более 80 % площадей ЦОД приходится на подземные помещения, это позволило избежать строительства больших зданий на поверхности. В процессе строительства извлекли около 63 тыс. м3 горных пород, проложили 15 км тоннелей и построили вертикальную шахту. 
Источник изображения: Университет Тренто По словам представителя итальянского правительства, страна имеет всё необходимое, чтобы стать средиземноморским хабом в сфере обработки данных и вычислительных мощностей благодаря стратегически выгодному географическому положению, развитой цифровой инфраструктуре и динамичной, конкурентоспособной производственной экосистеме. Подземные ЦОД становятся всё популярнее в Европе из-за высокого уровня физической защиты и относительной безопасности для окружающей среду. Бельгийский провайдер IT-сервисов Cegeka в прошлом году анонсировал первоначальные инвестиции в объёме €40 млн ($46,9 млн) в строительство подземного дата-центра в бельгийской провинции Лимбург. В феврале 2025 года сообщалось, что Scandinavian Data Centers построит экологичный ЦОД с энергохранилищем на месте подземного военного завода в Швеции. А в Норвегии под землёй разместили суперкомпьютер Olivia.
30.06.2026 [13:27], Сергей Карасёв
NVIDIA Jetson поможет в ИИ-обработке данных на орбите ЛуныВ конце 2026 года американская частная аэрокосмическая компания Firefly Aerospace намерена осуществить запуск лунных аппаратов в рамках проекта Blue Ghost Mission 2. Орбитальный модуль, проектируемый по этой программе, будет использовать вычислительную платформу NVIDIA Jetson для обработки изображений Луны с использованием ИИ-алгоритмов. В марте 2025-го космический аппарат Blue Ghost Mission 1 компании Firefly Aerospace совершил посадку на Луну: он передал на Землю почти 120 Гбайт необработанных данных, включая изображения и видео, полученные бортовыми камерами. Эта информация до сих пор обрабатывается и изучается в лабораториях. В случае Blue Ghost Mission 2 данные будут обрабатываться непосредственно на лунной орбите, что избавит от необходимости их длительной трансляции на Землю. ИИ-алгоритмы, запущенные на базе Jetson, позволят извлекать только необходимые сведения: это значительно сократит задержку. Таким образом, повысится эффективность работы системы Firefly Ocula — первого коммерческого сервиса для получения высокодетализированных изображений и карт лунной поверхности. 
Источник изображений: Firefly Aerospace Проект Blue Ghost Mission 2 предполагает запуск посадочного модуля с набором научных приборов, который должен опуститься на обратную сторону Луны. Ещё одним элементом программы станет орбитальный блок Elytra, оснащённый вычислительным узлом NVIDIA Jetson. Датчики системы Ocula будут получать изображения Луны в ультрафиолетовом и видимом диапазонах. Затем эти данные поступят на обработку в бортовой вычислительный узел на базе Jetson, использующий алгоритмы ИИ. После извлечения необходимые сведения будут передаваться на Землю.  Аппарат Elytra рассчитан на эксплуатацию в течение пяти лет. Установленная на нём электроника будет получать питание от солнечных панелей. Отмечается, что сервис Ocula, реализованный на основе Elytra, поможет в решении ряда важных задач, среди которых — выбор оптимальных зон посадки для будущих пилотируемых и роботизированных лунных миссий, определение минерального состава пород и пр.
30.06.2026 [09:14], Руслан Авдеев
Microsoft объявила о достижении положительного водного баланса, но не раскрыла объёмы потребления водыMicrosoft заявила, что достигла положительного водного баланса на пять лет раньше назначенного ранее срока. Компания утверждает, что «восполнила» больше воды, чем потратила в ходе работы по всему миру в 2025 финансовом году (закончился в июне прошлого года). По словам компании, она добилась повышения эффективности использования воды (WUE) в своих дата-центрах почти на 90 % с начала 2000-х гг. Использование снизилось с 2,3 л/кВт∙ч до 0,27 л/кВт∙ч в 2025 году, если речь идёт о парке ЦОД, принадлежащих самой компании, но следуеь учесть, что она арендует довольно много мощностей. Дополнительно Microsoft заявила, что сократила и интенсивность использования воды на 25 % в сравнении с «базовым» уровнем 2022 года — тем самым она прошла уже более половины пути к цели по снижению этого показателя на 40 % к концу десятилетия. Данные о потреблении воды в последний раз полностью раскрывались Microsoft в 2022 году. Тогда компания «выпила» более 6,39 млн м3, на 34 % больше в сравнении с предыдущим годом. Достигнутые за прошедшие годы улучшения связывают с постепенным переходом от испарительного охлаждения к прямому воздушному и жидкостному, в том числе к DLC СЖО с замкнутым контуром. На новых стройках все ЦОД, как ожидается, будут использовать именно такие системы. 
Источник изображения: Kelly Sikkema/unsplash.com По данным компании, около 90 % из принадлежащего ей в 2025 году парка ЦОД работает с системами, потребляющими либо мало воды, либо практически не использующими её вовсе. В регионах с прохладным климатом вроде Дублина и Амстердама к использованию воды приходится прибегать менее 5 % от всего времени работы систем охлаждения, а в более жарких местах вроде американского Финикса — до 40 % времени. Кроме того, Microsoft использует всё больше очищенной и непитьевой воды. В Куинси (шт. Вашингтон), Сингапуре и Сан-Антонио (Техас) на очищенную или непитьевую воду приходится 74 %, 99 % и 79 % потребления соответственно. Кроме того, в Нидерландах, Швеции и Ирландии внедрили системы сбора дождевой воды. Аналогичные системы планируется развернуть в Канаде, Великобритании, Финляндии, Италии, Южной Африке и Австрии. 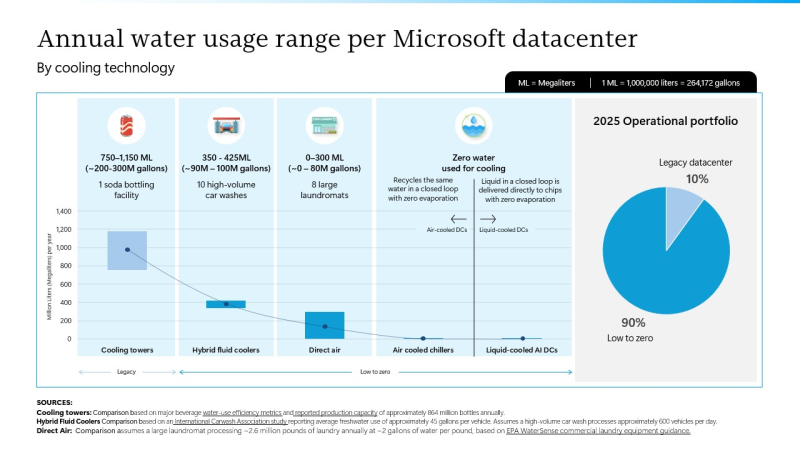
Источник изображения: Microsoft Хотя Microsoft докладывает о значительных достижениях в сфере организации водопользования, проблемы масштабного потребления воды дата-центрами по-прежнему актуальны. Компания признала, что оставаться водно-положительной по мере роста портфолио ЦОД будет проблематично. Кроме того, Microsoft изучает возможность точнее подбирать варианты систем охлаждения в зависимости от спецификаций используемого оборудования. Недавно статистику использования воды раскрыла Amazon, сообщив, что в прошлом году истратила более 9,46 млн м3. Компания по-прежнему намерена добиться водно-положительного баланса к 2030 году и, по её данным, уже на 75 % прошла путь к достижению этой цели. Водно-положительной к 2030 году намерена стать и Google.
29.06.2026 [12:57], Руслан Авдеев
На месте алюминиевого завода в Австралии построят ЦОД мощностью 540 МВтВ Новом Южном Уэльсе (Австралия), как ожидается, появится новый дата-центр. В заявке SEARS (запрос требований для подготовки экологической документации), поданной властям штата, представлены планы постройки ЦОД мощностью 540 МВт. Разместить объект намерены на территории бывшего алюминиевого завода Hydro Aluminium Kurri Kurri в долине Хантер, сообщает Datacenter Dynamics. Заявителем выступила компания ADW Johnson Pty Ltd., занимающаяся управлением проектами, но кто именно будет конечным пользователем, пока не разглашается. Общая площадь участка составляет 21 га. Документация свидетельствует, что ADW намерена построить крупное двухэтажное здание ЦОД и две электроподстанции с подключением к действующей 132-кВ ЛЭП AusGrid. Площадка примыкает непосредственно к территории 660-МВт газовой электростанции Kurri Kurri, которая заработала в прошлом году. 
Источник изображения: Tobias Keller/unspalsh.com Алюминиевый завод, запущенный Alcan Australia в 1969 году, прекратил выработку продукции в 2012 году и был окончательно закрыт через два года. Рекультивация территории в целом завершена, и теперь площадка практически не эксплуатируется. В 2020 году участок был продан Stevens Group и McCloy Group, которые планировали превратить его в район Loxford Waters площадью 2 тыс. га с 2 тыс. домов, промзонами и бизнес-парком. В заявке сообщается, что проект ЦОД напрямую способствует диверсификации экономики и восстановлению региона долины Хантер. Он обеспечит создание критически важной цифровой инфраструктуры. Это не единственный новый крупный проект в Австралии. Так, в начале июня сообщалось, что Iren намерена построить в Австралии кампус ЦОД мощностью 800 МВт, а ещё в конце апреля появились данные, что Microsoft вложит в местные ЦОД, ИИ и облака $18 млрд.
29.06.2026 [12:15], Сергей Карасёв
Ugreen представила сетевые хранилища DXP6800 Ultra и DXP8800 Ultra на базе Intel Raptor Lake для малого бизнесаКомпания Ugreen, по сообщению ресурса NAS Compares, подготовила к выпуску сетевые хранилища DXP6800 Ultra и DXP8800 Ultra в «настольном» форм-факторе на аппаратной платформе Intel Raptor Lake. Устройства рассчитаны на профессиональных пользователей, создателей контента и предприятия малого бизнеса. Модель DXP6800 Ultra оснащена процессором Core 5 120U с десятью ядрами (2Р+8Е) с тактовой частотой до 5 ГГц. В состав изделия входят графический блок и нейронный ускоритель Intel GNA (Gaussian & Neural Accelerator). Допускается установка шести SATA-накопителей, а также двух SSD типоразмера М.2. Суммарная внутренняя вместимость может достигать 208 Тбайт. В системе охлаждения задействованы два вентилятора диаметром 90 мм. 
Источник изображений: Ugreen В свою очередь, модификация DXP8800 Ultra укомплектована чипом Core 7 150U с десятью ядрами (2Р+8Е), функционирующими на частоте до 5,4 ГГц. Предусмотрены восемь посадочных мест для SATA-накопителей и два слота М.2. Общая ёмкость составляет до 272 Тбайт. Применены два вентилятора на 120 мм.  Обе новинки в базовой конфигурации несут на борту 8 Гбайт DDR5 в виде модуля SO-DIMM (расширяется до 96 Гбайт) и системный SSD на 128 Гбайт. Реализованы по два порта 10GbE RJ45 и Thunderbolt 4 (40 Гбит/с). Имеется слот PCIe 4.0 x4 для карты расширения, например, дополнительного сетевого адаптера. Среди прочего упомянуты интерфейсы HDMI 2.1, USB 3.1 Type-A и USB 2.0 Type-A, слот для SD-карты (UHS-II). В продажу сетевые хранилища DXP6800 Ultra и DXP8800 Ultra поступят по ориентировочной цене $1120 и $1620 соответственно.
29.06.2026 [12:11], Сергей Карасёв
Компактные сетевые хранилища Minisforum S5 и S7 типа All-Flash оснащены чипом Intel Wildcat LakeКомпания Minisforum анонсировала сетевые хранилища (NAS) небольшого форм-фактора S5 и S7 типа All-Flash, разработанные в партнёрстве с Intel. Новинки могут использоваться в том числе в составе локальных систем, ориентированных на ИИ-нагрузки. Устройство Minisforum S5, по имеющейся информации, несёт на борту процессор Intel Core Series 3 поколения Wildcat Lake. Объём оперативной памяти LPDDR5X-7200 достигает 16 Гбайт. Реализованы пять слотов для SSD типоразмера M.2 2280 с интерфейсом PCIe 4.0 x1 (NVMe). В оснащение входят сетевые порты 10GbE и 2.5GbE с разъёмами RJ45, а также контроллер Wi-Fi 7. Есть по два порта USB 4 (40 Гбит/с) и USB 3.2 Type-A, а также интерфейс HDMI 2.1. Применено пассивное охлаждение; питание подаётся через AC-разъём. Вторая новинка, Minisforum S7, укомплектована чипом Intel Core Ultra Series 3. Максимально поддерживаемый объём ОЗУ не уточняется. Этот NAS рассчитан на семь твердотельных накопителей NVMe. В набор сетевых интерфейсов входят два порта 10G SFP+, по одному коннектору 10GbE RJ45 и 2.5GbE RJ45. Упомянуты два порта USB 4. Во фронтальной части корпуса расположены индикаторы, информирующие о текущем статусе. Прочие технические характеристики хранилищ пока не раскрываются. 
Источник изображений: Minisforum Среди функций сопутствующего ПО выделяется фирменный ИИ-агент MinisOpenClaw: он предоставляет средства семантического поиска изображений по запросам на естественном языке вроде «найди фотографии со мной на пляже». 
29.06.2026 [09:49], Руслан Авдеев
ЦОД по всему миру всё чаще становятся мишенью для исков экоактивистовСогласно последним данным Лондонской школы экономики (LSE), стремительное развитие рынка ЦОД и ИИ всё чаще превращается в предмет судебных разбирательств. При этом тенденция отмечается по всему миру — от США и Великобритании до Чили и Ирландии, сообщает The Guardian. LSE проанализировала более 3,6 тыс. исков, поданных с 2015 года. Оказалось, что количество дел, связанных с энергетикой, водопотреблением и загрязнением воздуха ЦОД постоянно растёт, поскольку многие обеспокоены влиянием инфраструктуры. Одним из первых из подвергнутых анализу исков подан в 2020 году в Сантьяго (столице Чили), где планировалось строительство крупного ЦОД Google. Местные активисты и муниципалитет оспорили полученные компанией разрешения, посчитав, что проект негативно скажется на городской системе водоснабжения, и без того страдающей от климатических изменений, т.е. засухи. В результате реализация проекта была приостановлена — суд счёл, что климатические последствия строительства не учли должным образом. Тем не менее рост отрасли в Чили это не остановило, и нагрузка на водные ресурсы, уже пострадавшие от засух, растёт. Ирландия названа одной из ключевых локаций, где исков против ЦОД подано особенно много. Власти страны стремятся развивать отрасль, хотя та потребляет более 20 % всей вырабатываемой энергии страны. В декабре Комиссия по регулированию коммунальных услуг (CRU) Ирландии заявила, что крупные потребители энергии вроде операторов ЦОД получат возможность использовать ископаемое топливо ещё шесть лет, после чего на возобновляемую энергетику должно приходиться не менее 80 % их энергопотребления. НКО Friends of the Irish Environment (FIE), Friends of the Earth Ireland и ClientEarth стремятся добиться пересмотра этого решения в судебном порядке, поскольку опасаются того, что оно только укрепит зависимость Ирландии от природного газа на годы вперёд. FIE поданы и другие иски, связанные с заявками на строительство ЦОД в Ирландии, включая один против местного Агентства по охране окружающей среды в связи с тем, что оно одобрило один из проектов в Южном Дублине. 
Источник изображения: Barbara Burgess / Unsplash Противодействие в юридическом поле усиливается и в США. В Калифорнии город Питтсбург теперь обязан требовать от ЦОД использовать возобновляемую энергию и очищенные сточные воды для охлаждения. В Джорджии и Пенсильвании идут судебные процессы против регуляторов, одобривших строительство новых ЦОД, работающих за счёт ископаемого топлива. В Миссисипи активисты утверждают, что xAI нарушает Clean Air Act, используя газовые генераторы без разрешений, а Минюст США пытается заблокировать рассмотрение дела, утверждая, что компания играет ключевую роль для безопасности США. В Великобритании активисты оспорили решение властей о продвижении ЦОД гиперскейл-уровня в Бакингемшире. НКО Foxglove и Global Action Plan, интересы которых представляли юристы Leigh Day, заявили, что власти игнорировали требования проекта к электричеству и водным ресурсам, а также не дали должной оценки климатическим последствиям такой инициативы. Впоследствии британское правительство признало, что в ходе принятия решения были допущены процедурные ошибки, а иск отозвали. LSE отмечает, что процессы в США и Великобритании показывают, как такие разбирательства способствуют изменению подходов к принятию решений, касающихся климата, даже если истцы не добьются решений в свою пользу. Кроме того, разбирательства могут повысить прозрачность принятия решений. В LSE подчёркивают, что подобные иски далеко не всегда подаются для остановки строительства дата-центров. Зачастую главное в них — не допустить дальнейшего укрепления зависимости от ископаемого топлива.
29.06.2026 [08:42], Руслан Авдеев
CBRE: мировой спрос на ЦОД по-прежнему превышает предложение, влияя на стоимость аренды и строительстваПо оценкам экспертов в области коммерческой недвижимости из CBRE, в I квартале 2026 года предложение мощностей ЦОД год к году выросло по всему миру, но спрос всё ещё выше предложения, а стоимость аренды и строительства значительно выросли, сообщает Datacenter Dynamics. Очередной доклад Global Data Center Trends свидетельствует, что лидером по темпам роста установленной мощности ЦОД стала не Северная Америка или Азия, включая Ближний Восток, а Латинская Америка. Рост составил 41,3 % в годовом выражении, Северная Америка заняла только второе место с 33 %. Драйверами роста становятся некоторые развивающиеся рынки. Так, в Керетаро (Querétaro, Мексика) установленная мощность выросла на 450 %. В Северной Америке на четырёх крупнейших рынках ЦОД — в Северной Вирджинии, Атланте, Далласе/Форт-Уэрте и Чикаго — рост установленной мощности составил 33 % г/г. Впрочем, в сравнении с прошлым годом темпы роста были менее впечатляющими. В тот же период 2025 года рост составил 43 %. 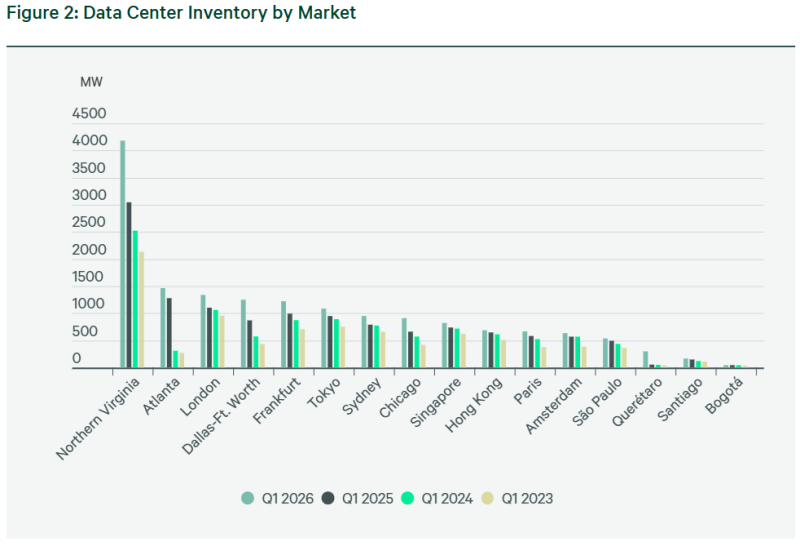
Источник изображения: CBRE Research Северная Вирджиния остаётся крупнейшим рынком ЦОД в мире, мощность г/г выросла на 1,13 ГВт. Даллас/Форт-Уэрт поднялся на две позиции и теперь является третьим по величине рынком Северной Америки, нарастив мощности на 43,7 % до 379,9 МВт. Рынок Чикаго обогнал по показателям Финикс и занял четвёртое место. Хотя общие установленные мощности растут, общих свободных из них всё меньше, вплоть до исторического минимума. Заметнее всего снижение в Атланте, с 3,6 до 1 % г/г. В Северной Вирджинии — до 0,3 % с 0,8 %. А в Далласе/Форт-Уэрте доступных для аренды мощностей стало больше всего на 1,4 МВт г/г. Впрочем, арендные ставки в США росли более умеренно, чем в предыдущем периоде. Максимальный рост отмечен в Чикаго, на уровне 14,7 %. Ставки увеличились с $200 до $230 за кВт/мес., второе место занимает Северная Вирджиния (рост с $190 до $235 кВт). Ставки в Атланте выросли на 2 %, а в Далласе/Форт-Уэрте не изменились. Как сообщает CBRE, в основном причина нынешней ситуации в проблемах с подключением новых источников электричества. В Европе в I квартале 2026 года предложение новых мощностей выросло на 18,9 % г/г. Рост во Франкфурте, Лондоне, Амстердаме и Париже это обусловлено спросом со стороны ИИ-проектов и гиперскейлеров. Больше всего предложение выросло в Франкфурте, на 23 % г/г, второе место занял Лондон с 21 %. У Амстердама самые низкие темпы роста — всего 11 %. По мнению экспертов, это связано с нехваткой электроэнергии и ограничениями на строительство объектов мощнее 70 МВт, из-за чего строительство смещается из известных городских хабов. Та же тенденция и во Франкфурте с Парижем, где строить начали на более доступной земле и избытком энергии. Так или иначе, доступных мощностей несмотря на все принимаемые меры немного, например — 5 % во Франкфурте и 8,6 % в Лондоне. 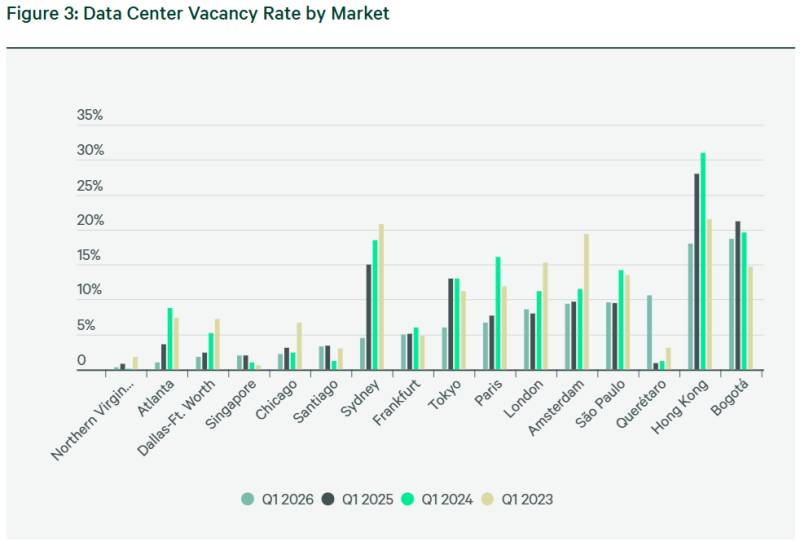
Источник изображения: CBRE Research За пределами ключевых Европейских рынков, развиваются регионы вроде Лиссабона и его округи. Хотя столица Португалии имеет всего чуть более 50 МВт мощностей, девелоперов привлекает конкурентоспособная стоимость возобновляемой энергии и относительная доступность электричества в целом. CBRE прогнозирует, что к 2030 году установленные мощности в Лиссабоне могут достигнуть 500 МВт. В АТР рост мощностей год к году составил 13,4 % на рынках Сингапура, Токио, Гонконга и Сиднея. Несмотря на дефицит электроэнергии, высокую стоимость строительства и регуляторные препятствия, гиперскейлеры и ИИ-компании поддержали рост, а неооблачные провайдеры стали одним из главных источников спроса. Свободные мощности остаются на уровне 7 %. Меньше всего (2 %) свободных мощностей в Сингапуре из-за нехватки свободных площадок, второе место занимает Сидней с 4,5 %, третье — Токио с 6 %. У Гонконга 18 %, но в предыдущий отчётный период было доступно аж 28 %. Арендные ставки в регионе в целом стабильны и в среднем составляли $403 за кВт/мес. в Сингапуре, $280 в Токио и $188 в Сиднее. В Гонконге они выросли с $270 до $295. Доступные мощности в целом сократились на 43 % г/г, но разрозненность предложения мешает реализации крупных проектов, хотя любые появляющиеся мощности «немедленно поглощаются рынком». 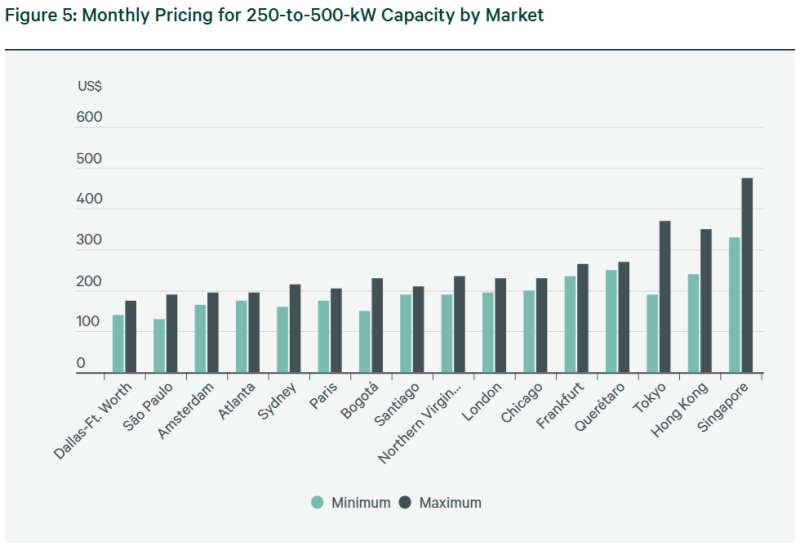
Источник изображения: CBRE Research В Латинской Америке установленная мощность на крупнейших рынках в Сан-Паулу, Керетаро, Сантьяго и Боготе выросла на 41,3 % г/г до 1,04 ГВт. В Керетаро рост составил 450,2 % до 298,2 МВт благодаря реализации проектов гиперскейлеров и ИИ-компаний. Тем не менее, Сан-Паулу остался крупнейшим рынком с 536,7 МВт. Рост в Сантьяго и Боготе составил 165,8 МВт и 44,3 МВт соответственно. Меньше всего свободных мощностей в Сантьяго (3,3 %), в Сан-Паулу речь идёт о 9,6 %, 10,6 % — в Керетаро и 18,7 % — в Боготе. Арендные ставки в Латинской Америке стабильны, ниже всего они в Сан-Паулу, от $130 до $190 кВт в месяц. Как и в остальном мире, доступность мощностей в Латинской Америке снизилась, но отличается от региона к региону. Доступность в Керетаро выросла до 31,5 МВт, в Сантьяго остаётся стабильной на уровне 5,4 МВт, в Сан-Паулу немного увеличилась до 51,5 МВт, а в Боготе снизилась до 8,3 МВт.
28.06.2026 [15:48], Сергей Карасёв
Китайские x86-процессоры Hygon C86-5G получили 128 ядер с поддержкой 512 потоковКитайская компания Hygon, по сообщениям сетевых источников, создала процессоры нового поколения с архитектурой x86. Речь идёт об изделиях C86-5G, которые, как ожидается, будут применяться в оборудовании для дата-центров. Кроме того, в разработке находятся другие продукты, включая ИИ-ускорители. Решения C86-5G придут на смену изделиям C86-4G, которые являются наследниками AMD Zen1. Чипы C86-4G насчитывают 16 вычислительных ядер с возможностью одновременной обработки до 32 потоков инструкций, а тактовая частота составляет 2,8 ГГц. Реализована поддержка оперативной памяти DDR5 и интерфейса PCIe 5.0. Известно, что процессоры C86-5G получат до 128 вычислительных ядер. Упомянута технология многопоточности SMT4, которая позволит каждому ядру обрабатывать четыре потока инструкций, что в сумме даст 512 потоков. Упомянута поддержка 104 линий PCIe 5.0, инструкций AVX512, а также режимов INT8 и BF16. Заявленная производительность — 10 Тфлопс на операциях FP64 (до 32 операций за такт). Ожидается, что в ЦОД-сегменте новые китайские процессоры станут альтернативой Intel Xeon 6. 
Источник изображений: Hygon Производство C86-5G уже началось. Чипы станут основой ряда серверов, включая двухсокетную модель H620G59 формата 2U с воздушным охлаждением. Эта система оборудована 32 слотами для модулей DDR5-6400, тремя разъёмами PCIe 5.0 х16, двумя слотами ОСР 3.0, восемью фронтальными отсеками для накопителей стандарта SFF, а также двумя внутренними коннекторами для SSD типоразмера М.2. Кроме того, готовятся серверные стойки высокой плотности TC800G6 (PUE — 1,08) и TC8600H G5 (PUE — 1,04) с жидкостным охлаждением.  Вместе с тем Hygon намерена выпустить GPU с памятью HBM и высокоскоростным интерконнектом. Известно, что это устройство допускает работу в режимах FP64/PF16/BF16. Новинка, предположительно, сможет составить конкуренцию NVIDIA A100. Наконец, в разработке находятся коммутационные решения класса 400/800 Гбит/с. Это чип с поддержкой 104 линий PCIe 5.0, высокоскоростной интерконнект для вертикального масштабирования (сопоставим с NVLink), решение ScaleFabric 400G (для NIC), а также ScaleFabric 400/800G. Последняя из перечисленных новинок обеспечивает поддержку 80 портов на 400 Гбит/с с RDMA, а коммутационная способность достигает 64 Тбит/с. Это устройство рассматривается в качестве альтернативы InfiniBand NDR. |
|

