Материалы по тегу: c
|
25.11.2024 [13:10], Руслан Авдеев
Эффективность новинок NVIDIA в рейтинге суперкомпьютеров Green500 оказалась под вопросом из-за чипов AMD и… самой NVIDIAХотя ускорители NVIDIA считаются одними из самых энергоёмких в своём классе, суперкомпьютеры на основе чипов компании по-прежнему доминируют в мировом рейтинге энергоэффективности соответствующих машин — Green500. Тем не менее компания столкнулась с сильной конкуренцией со стороны AMD и не всегда готова состязаться даже с собственной продукцией, сообщает The Register. На первый взгляд, лидерство проектов на базе NVIDIA неоспоримо. Восемь из десяти суперкомпьютеров, входящих в «Топ-10» энергоэффективных машин, построены на чипах NVIDIA, из них пять — на 1000-ваттных гибридных ускорителях GH200. В новейшем рейтинге Green500 на их основе построены первая и вторая из наиболее энергоэффективных систем — JEDI (EuroHPC) и ROMEO-2025 (Romeo HPC Center). В бенчмарке High-Performance Linpack они продемонстрировали производительность 72,7 Гфлопс/Вт и 70,9 Гфлопс/Вт соответственно (FP64). Системы почти идентичны и построены на платформе BullSequana XH3000 компании Eviden (Atos). На решение GH200 также приходятся четвёртая, шестая и седьмая позиции рейтинга: Isambard-AI Phase 1 (68,8 Гфлопс/Вт), Jupiter Exascale Transition Instrument (67,9 Гфлопс/Вт) и Helios (66,9 Гфлопс/Вт). Системы с проверенными NVIDIA H100 занимают пятое, восьмое и девятое места — это Capella, Henri и HoreKa-Teal. 
Источник изображения: Jakub Żerdzicki/unsplash.com Тем не менее есть сомнения в том, что продукты NVIDIA и дальше будут безраздельно господствовать в рейтинге Green500. Уже на подходе решения Grace-Blackwell в виде GB200 (2,7 кВт) и GB200 NVL4 (5,4 кВт). Новые продукты далеко не всегда обеспечивают максимальную производительность на ватт энергии. При переходе от A100 (2020 год) к H100 (2022 год) FP64-производительность взлетела приблизительно в 3,5 раза, но в сравнении с 1,2-кВт платформой Blackwell даже 700-Вт H100 в режиме матричных FP64-вычислений фактически быстрее. Для FP64 улучшилась только работа с векторными операциями, где новинки оказались на 32 % производительнее. Другими словами, хотя сегодня NVIDIA может похвастаться высоким положением в рейтинге Green500, решение на ускорителях MI300A компании AMD уже заняло третье место (Adastra 2). MI300A анонсировали чуть менее года назад, решение получило 24-ядерный CPU и шесть чиплетов CDNA-3 в едином APU-модуле, оснащённым до 128 Гбайт памяти HBM3, а также настраиваемый уровень TDP 550–760 Вт. Более того, такая система в 1,8 раза производительнее NVIDIA H100 (по крайней мере, на бумаге). Суперкомпьютер Adastra 2 на базе HPE Cray EX255a обеспечивает производительность 69 Гфлопс/Вт. Десятое место также занимает машина на MI300A — RZAdams Ливерморской национальной лаборатории (62,8 Гфлопс/Вт). Таким образом, все системы, входящие в первую десятку рейтинга Green500, уже значительно превышают целевой показатель энергоэффективности в 50 Гфлопс/Вт, необходимый для достижений 1 Эфлопс (FP64) при энергопотреблении до 20 МВт. Проблема в том, что малые системы значительно эффективнее: JEDI потребляет всего 67 кВт, а самая производительная машина на базе GH200 в рейтинге TOP500 — швейцарская Alps — обеспечивает 434 Пфлопс (FP64), потребляя 7,1 МВт — это лишь 14-я из наиболее энергоэффективных машин (61 Гфлопс/Вт). Та же проблема и с Adastra 2: компьютер потребляет даже меньше JEDI — 37 кВт. Если бы удалось сохранять уровень 69 Гфлопс/Вт в больших масштабах, потребовалось бы всего 25,2 МВт для достижения 1,742 Эфлопс, как у El Capitan. Но последнему требуется около 29,6 МВт для достижения таких рекордных показателей.
25.11.2024 [11:40], Владимир Мироненко
Hyperion Research: рынок HPC куда больше, чем считается, и растёт он куда быстрееАналитики The Next Platform считают, что обучение и инференс ИИ в ЦОД также относятся к высокопроизводительным вычислениям (HPC), хотя в некоторых случаях могут значительно отличаться от их традиционного определения. HPC используют небольшой набор данных, расширяя его до огромных симуляций, таких как прогнозы погоды или климата, в то время как ИИ анализирует массу данных о мире и преобразует их в модель, в которую можно добавлять новые данные для ответа на вопросы, сообщается на ресурсе The Next Platform. HPC и ИИ имеют разные потребности в вычислительных ресурсах, памяти и пропускной способности на разных этапах обработки приложений. Но в конечном итоге как при HPC, так и при обучении ИИ компании стремятся объединить множество узлов в единую систему для выполнения больших объёмов работы, которые невозможно выполнить иначе. 
Источник изображений: Hyperion Research Для получения «реальных» данных о рынке HPC необходимо добавить к расходам на традиционные платформы ModSim (моделирование и симуляция) средства, потраченные на применение технологий генеративного ИИ, традиционное обучение и инференс ИИ в ЦОД. Исходя из этого, Hyperion Research значительно пересмотрела оценку рынка, учтя продажи серверов ИИ, которые ранее не включались в расчёты, в том числе решения компаний NVIDIA, Supermicro и других.  В обновлённом прогнозе рынка HPC, представленном Hyperion Research в минувший вторник, расходы на серверы значительно выросли благодаря добавлению «нетрадиционных поставщиков». В 2021 году было продано серверов в объединённом секторе HPC/ИИ на $1,34 млрд, в 2022 году расходы на их покупку составили $3,44 млрд, а в 2023 году, благодаря буму на генеративный ИИ, они подскочили до $5,78 млрд. Hyperion Research ожидает, что эти производители заработают на серверах $7,46 млрд в 2024 году, и их доходы почти удвоятся к 2028 году, достигнув $14,97 млрд.  Историческая часть рынка серверов HPC/ИИ (согласно прежней методике), показанная синим цветом на диаграмме, как ожидается, составит $17,93 млрд в этом году и вырастет до $26,81 млрд к 2028 году. Объединённый рынок HPC/ИИ с учётом нового подхода составит в этом году $25,39 млрд и будет расти ежегодно на 15 %, достигнув $41,78 млрд к 2028 году.  Как отметили в Hyperion Research, теперь не все расходы на вычисления HPC и ИИ осуществляются локально (on-premise). Большая часть ИТ-бюджета на рабочие нагрузки HPC и ИИ переносится в облако.  Hyperion подсчитала, что приложения HPC и ИИ, работающие в облаке, в совокупности «потребили» $7,18 млрд виртуальных серверных мощностей в 2023 году и что эти цифры вырастут на 21,2 % до $8,71 млрд в 2024 году. К 2028 году расходы на вычислительные мощности HPC и ИИ в облаке составят $15,11 млрд, а совокупные годовые темпы роста с 2023 по 2028 год составят 16,1 %.  Помимо затрат на вычисления, бюджет HPC и ИИ включает расходы на хранение, ПО и сервисы. Hyperion ожидает, что в 2024 году общие расходы на HPC и ИИ вырастут на 22,4 %, с $42,4 млрд до $51,9 млрд. При совокупном годовом темпе роста в 15 % в период с 2023 по 2028 год все затраты на HPC и ИИ составят к 2028 году $85,5 млрд, что в два раза превышает показатель нынешнего года.  Согласно данным Hyperion, в 2021 году в Китае было установлено две экзафлопсные системы стоимостью $350 млн каждая. Также по одной системе с такой же стоимостью было установлено в 2023 году и нынешнем году. Hyperion ожидает, что в 2025 году Китай установит ещё одну или две экзафлопсные системы с оценочной стоимостью $300 млн за штуку и ещё две с такой же стоимостью в 2026 году. Общая стоимость девяти экзафлопсных систем составит около $2,95 млрд — примерно столько стартап xAI, курируемый Илоном Маском (Elon Musk), израсходовал на создание кластера Colossus из 100 000 ускорителей NVIDIA H100. В Японии до сих пор нет суперкомпьютера эксафлопсного класса (речь об FP64-производительности), и она получит свой первый такой суперкомпьютер стоимостью $200 млн в 2026 году. В 2027 и 2028 годах, как ожидает Hyperion, Япония построит две или три такие суперкомпьютерные системы стоимостью около $150 млн за единицу, потратив в общей сложности $300–450 млн. В Европе есть несколько преэкзафлопсных систем, и в 2025 году она получит две экзафлопсные системы по оценочной стоимости $350 млн каждая, а в 2026 году здесь появится ещё две или три системы стоимостью около $325 млн. Также следует ожидать строительство двух или трёх машин в 2027 году стоимостью $300 млн каждая и двух или трёх в 2028 году стоимостью $275 млн каждая. То есть в предстоящие несколько лет в Европе будет построено одиннадцать экзафлопсных суперкомпьютеров общей стоимостью $3,4 млрд. 
Источник изображения: LLNL В США установили одну экзафлопсную систему в 2022 году (Frontier в Ок-Риджской национальной лаборатории, ORNL) и две — в 2024 году (Aurora в Аргоннской национальной лаборатории и El Capitan в Ливерморской национальной лаборатории им. Э. Лоуренса). По оценкам The Next Platform, за последние годы Соединённые Штаты потратили $1,4 млрд на установку трёх экзафлопсных машин. Согласно прогнозу Hyperion Research, в Соединённых Штатах в 2025 году установят две экзафлопсные системы стоимостью около $600 млн каждая, в 2026 году — одну или две стоимостью $325 млн каждая и одну или две стоимостью $275 млн каждая в 2027 и 2028 годах. В общей сложности будет потрачено $4,35 млрд на одиннадцать экзафлопсных систем.
24.11.2024 [09:54], Сергей Карасёв
AIC и ScaleFlux представили JBOF-массив на основе NVIDIA BlueField-3Компании AIC и ScaleFlux анонсировали систему F2026 Inference AI для ресурсоёмких приложений ИИ с интенсивным использованием данных. Решение выполнено в форм-факторе 2U. В оснащение входят два DPU NVIDIA BlueField-3, которые могут работать на скорости до 400 Гбит/с. Эти изделия способны ускорять различные сетевые функции, а также операции, связанные с передачей и обработкой больших массивов информации. Во фронтальной части F2026 Inference AI расположены 26 отсеков для высокопроизводительных вычислительных SSD семейства ScaleFlux CSD5000 (U.2). Накопители с интерфейсом PCIe 5.0 (NVMe 2.0b) имеют вместимость 3,84, 7,68, 15,36, 30,72, 61,44 и 122,88 Тбайт, а с учётом компрессии эффективная ёмкость может достигать приблизительно 256 Тбайт. Реализована поддержка TCG Opal 2.02 и шифрования AES-256, NVMe Thin Provisioned Namespaces Virtualization (48PF/32VF), ZNS, FDP. Платформа F2026 Inference AI представляет собой JBOF-массив, способный на сегодняшний день хранить 1,6 Пбайт информации (эффективный объём). В следующем году показатель будет доведён до 6,6 Пбайт. Утверждается, что сочетание BlueField-3 и энергоэффективной технологии хранения ScaleFlux помогает минимизировать энергопотребление, а также повысить долговечность и надёжность. Результаты проведённого тестирования F2026 Inference AI демонстрируют пропускную способность при чтении до 59,49 Гбайт/с, при записи — более 74,52 Гбайт/с. Благодаря объединению средств хранения, сетевых функций и инструментов безопасности в одну систему достигается снижение эксплуатационных расходов, что позволяет оптимизировать совокупную стоимость владения (TCO). 
Источник изображения: AIC Новинка является лишь одной из вариаций решений на базе F2026. Платформа, в частности, поддерживает работу других DPU, включая Kalray 200 и Chelsio T7. Также упоминается вариант шасси на 32 накопителя EDSFF E3.S/E3.L.
23.11.2024 [15:57], Сергей Карасёв
Microsoft и Meta✴ представили дизайн ИИ-стойки с раздельными шкафами для питания и IT-оборудованияКорпорация Microsoft в сотрудничестве с Meta✴ представила дизайн серверной стойки нового поколения для дата-центров, ориентированных на задачи ИИ. Спецификации системы, получившей название Mt. Diablo, предоставляются участникам проекта Open Compute Project (OCP). Отмечается, что инфраструктура ЦОД постоянно эволюционирует, а наиболее значительное влияние на неё оказывает стремительное внедрение ИИ. Тогда как традиционные стойки с вычислительным оборудованием и средствами хранения данных имеют мощность максимум до 20 кВт, при размещении современных ИИ-ускорителей этот показатель исчисляется сотнями киловатт. В результате при развёртывании дата-центров могут возникать различные сложности. Идея Mt. Diablo заключается в разделении стойки на независимые шкафы для компонентов подсистемы питания и вычислительного оборудования. То есть, речь идёт о дезагрегированной архитектуре, позволяющей гибко регулировать мощность в соответствии с меняющимися требованиями. 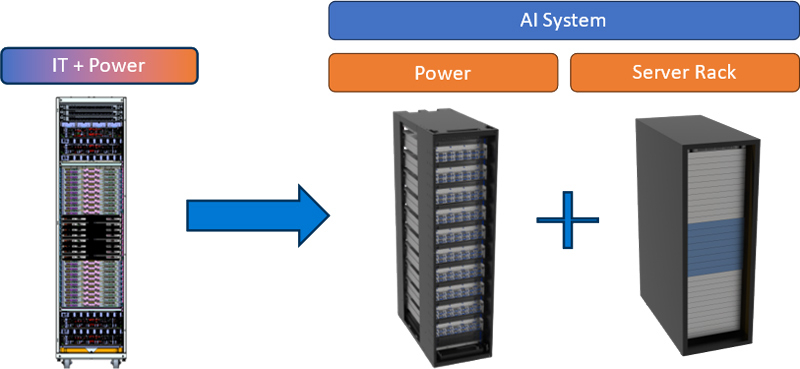
Источник изображения: Microsoft Одним из ключевых преимуществ нового подхода является оптимизация пространства. Утверждается, что в каждой серверной стойке можно размещать на 35 % больше ИИ-ускорителей по сравнению с традиционным дизайном. Ещё одним достоинством названа масштабируемость: конфигурацию стойки питания можно изменять в соответствии с растущими потребностями. Плюс к этому модульная конструкция позволяет реализовывать несколько проектов одновременно. Отмечается, что в современных OCP-системах уже используется единая шина питания постоянного тока с напряжением 48 В. В случае с новым дизайном возможен переход на архитектуру 400 В DC. Это открывает путь для создания более мощных и эффективных систем ИИ. Однако для внедрения стандарта 400 В потребуется общеотраслевая стандартизация. В индивидуальных проектах — например, суперкомпьютерах — для питания узлов уже используется шина HVDC.
23.11.2024 [15:35], Сергей Карасёв
Eviden создаст для Финляндии ИИ-суперкомпьютер Roihu производительностью 49 ПфлопсКомпания Eviden (дочерняя структура Atos) объявила о заключении соглашения с Финским научным IT-центром CSC о создании нового национального суперкомпьютера для задач ИИ. Система под названием Roihu, как ожидается, утроит вычислительную мощность существующих комплексов Puhti и Mahti. Суперкомпьютер Puhti общего назначения, запущенный в 2019 году, построен на платформе Atos BullSequana X400 (X1000). В общей сложности используются 682 узла CPU на процессорах Intel Xeon Cascade Lake-SP с пиковой FP64-производительностью 1,8 Пфлопс. Кроме того, применены 80 узлов GPU, каждый из которых несёт на борту четыре ускорителя NVIDIA V100: быстродействие этой секции — до 2,7 Пфлопс. Основной интерконнект — InfiniBand HDR100. В свою очередь, система Mahti (на изображении), введённая в эксплуатацию в 2020-м, основана на платформе Atos BullSequana XH2000. Суперкомпьютер насчитывает 1404 узла CPU и 24 узла GPU с теоретической пиковой FP64-производительностью 7,5 Пфлос и 2,0 Пфлопс соответственно. Все узлы содержат по два чипа AMD Rome 7H12, тогда как GPU-серверы комплектуются четырьмя ускорителями NVIDIA Ampere A100. 
Источник изображения: CSC В основу нового суперкомпьютера Roihu ляжет гибридная платформа BullSequana XH3000, которая позволяет объединять в рамках одного кластера чипы AMD, Intel и NVIDIA. Теоретическая пиковая производительность заявлена на уровне 49 Пфлопс (точность вычислений не уточняется). Прочие технические характеристики проектируемой машины пока не раскрываются. Стоимость контакта по созданию Roihu оценивается в €60 млн. Систему планируется использовать для широкого спектра задач, включая анализ аудио- и видеозаписей, ресурсоёмкие приложения ИИ в различных областях и традиционные нагрузки, такие как гидродинамика и моделирование климата. Кроме того, мощности суперкомпьютера будут применяться в образовательных целях.
22.11.2024 [11:55], Руслан Авдеев
Одна из структур Минпромторга закупит ИИ-серверы на 665 млн рублейПодведомственный Минпромторгу ФГАУ «Федеральный центр прикладного развития искусственного интеллекта» (ФЦПРИИ) объявил аукцион на закупку серверного и телеком-оборудования для обучения ИИ-моделей на сумму 665 млн руб., сообщают «Ведомости». Информация опубликована 11 ноября на портале госзакупок. Техзадание ФЦПРИИ предусматривает закупку восьми серверов на базе ИИ-ускорителей на 412,97 млн руб., двух вариантов систем хранения данных на 87,89 млн руб. и 89,06 млн руб. и классических серверов, но конкретные разработчики оборудования в документации к аукциону не указаны. В Минпромторге и ФЦПРИИ отказались от комментариев. По мнению экспертов, заказчик намерен сформировать высокопроизводительный вычислительный кластер как для обучения ИИ, так и для выполнения научно-технических вычислений большой сложности. 
Источник изображения: Astemir Almov/unsplash.com Отраслевые эксперты подчёркивают, что в России ускорителей для ИИ не производят, поэтому необходимо закупать соответствующие системы на стороне. По данным одного из источников «Ведомостей», на уровне предположений речь, вероятно, идёт о покупке серверов NVIDIA HGX H200 для обучения больших языковых моделей (LLM) — о закупках такого оборудования косвенно свидетельствует цена более 50 млн руб. за штуку. При этом производителями собственно серверов могут выступать как зарубежные, так и российские компании. Над серверами для ИИ работают многие российские компании. В апреле сообщалось, что в реестре радиоэлектронной продукции Минпромторга появился первый отечественный сервер для работы ИИ с поддержкой подключения нескольких ускорителей — Delta Sprut от ООО «Дельта компьютерс» (Delta Computers), позволяющий подключить до 16 ускорителей.
21.11.2024 [10:09], Сергей Карасёв
Lenovo представила сервер ThinkSystem SC750 V4 Neptune на базе Intel Xeon Granite Rapids с СЖОКомпания Lenovo анонсировала сервер ThinkSystem SC750 V4 Neptune, предназначенный для технических вычислений и обработки данных в различных областях, таких как аналитика, научные исследования, энергетика, проектирование и финансовое моделирование. Система ThinkSystem SC750 V4 Neptune объединяет два узла, которые заключены в 19″ корпус с возможностью вертикального монтажа. Каждый узел может нести на борту два процессора Intel Xeon 6900 поколения Granite Rapids (до 128 ядер) с показателем TDP до 500 Вт. В расчёте на узел доступны 24 слота для модулей оперативной памяти TruDDR5 RDIMM-6400 или MRDIMM-8800 (в сумме до 3 Тбайт). Каждый узел может комплектоваться шестью накопителями EDSFF E3.S NVMe SSD общей вместимостью до 92,16 Тбайт. Есть два сетевых порта 25GbE SFP28 на основе контроллера Broadcom 57414, один порт 1GbE RJ45 на базе Intel I210, два слота PCIe 5.0 x16. Габариты составляют 546 × 53 × 760 мм, масса — 37,2 кг. Говорится о совместимости с Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu и пр. 
Источник изображения: Lenovo Применено прямое жидкостное охлаждение Lenovo Neptune. Утверждается, что по сравнению с аналогичной системой с воздушным охлаждением сервер ThinkSystem SC750 V4 Neptune обеспечивает увеличение общей производительности до 10 % благодаря постоянной работе процессоров в турбо-режиме. При этом энергопотребление ЦОД от серверов может быть уменьшено на 40 %, тогда как шум от вентиляторов устраняется полностью.  Восемь лотков ThinkSystem SC750 V4 Neptune могут быть установлены в шасси ThinkSystem N1380 формата 13U: в сумме это даёт 16 узлов. Шасси может быть оборудовано четырьмя узлами Power Conversion Stations (PCS) с сертификатом 80 PLUS Titanium.
20.11.2024 [12:11], Сергей Карасёв
Dell представила ИИ-серверы PowerEdge XE9685L и XE7740Компания Dell анонсировала серверы PowerEdge XE9685L и PowerEdge XE7740, предназначенные для НРС и ресурсоёмких рабочих нагрузок ИИ. Устройства могут монтироваться в 19″ стойку высокой плотности Dell Integrated Rack 5000 (IR5000), что позволяет экономить место в дата-центрах. 
Источник изображений: Dell Модель PowerEdge XE9685L в форм-факторе 4U рассчитана на установку двух процессоров AMD EPYC Turin. Применяется жидкостное охлаждение. Доступны 12 слотов для карт расширения PCIe 5.0. Говорится о возможности использования ускорителей NVIDIA HGX H200 или B200. По заявлениям Dell, система PowerEdge XE9685L предлагает самую высокую в отрасли плотность GPU с поддержкой до 96 ускорителей NVIDIA в расчёте на стойку. Новинка подходит для организаций, решающих масштабные вычислительные задачи, такие как создание крупных моделей ИИ, запуск сложных симуляций или выполнение геномного секвенирования. Конструкция сервера обеспечивает оптимальные тепловые характеристики при высоких рабочих нагрузках, а наличие СЖО повышает энергоэффективность.  Вторая модель, PowerEdge XE7740, также имеет типоразмер 4U, но использует воздушное охлаждение. Допускается установка двух процессоров Intel Xeon 6 на базе производительных ядер P-core (Granite Rapids). Заказчики смогут выбирать конфигурации с восемью ИИ-ускорителями двойной ширины, включая Intel Gaudi 3 и NVIDIA H200 NVL, а также с 16 ускорителями одинарной ширины, такими как NVIDIA L4.  Сервер подходит для различных вариантов использования, например, для тонкой настройки генеративных моделей ИИ, инференса, аналитики данных и пр. Конструкция машины позволяет эффективно сбалансировать стоимость, производительность и масштабируемость. Dell также готовит к выпуску новый сервер PowerEdge XE на базе NVIDIA GB200 NVL4. Говорится о поддержке до 144 GPU на стойку формата 50OU (Dell IR7000).
20.11.2024 [10:56], Сергей Карасёв
Microsoft представила инстансы Azure HBv5 на основе уникальных чипов AMD EPYC 9V64H с памятью HBM3Компания Microsoft на ежегодной конференции Ignite для разработчиков, IT-специалистов и партнёров анонсировала облачные инстансы Azure HBv5 для HPC-задач, которые предъявляют наиболее высокие требования к пропускной способности памяти. Новые виртуальные машины оптимизированы для таких приложений, как вычислительная гидродинамика, автомобильное и аэрокосмическое моделирование, прогнозирование погоды, исследования в области энергетики, автоматизированное проектирование и пр. Особенность Azure HBv5 заключается в использовании уникальных процессоров AMD EPYC 9V64H (поколения Genoa). Эти чипы насчитывают 88 вычислительных ядер Zen4, тактовая частота которых достигает 4 ГГц. Ближайшим родственником является изделие EPYC 9634, которое содержит 84 ядра (168 потоков) и функционирует на частоте до 3,7 ГГц. По данным ресурса ComputerBase.de, чип EPYC 9V64H также фигурирует под именем Instinct MI300C: по сути, это процессор EPYC, дополненный памятью HBM3. При этом клиентам предоставляется возможность кастомизации характеристик. Отметим, что ранее x86-процессоры с набортной памятью HBM2e были доступны в серии Intel Max (Xeon поколения Sapphire Rapids). Каждый инстанс Azure HBv5 объединяет четыре процессора EPYC 9V64H, что в сумме даёт 352 ядра. Система предоставляет доступ к 450 Гбайт памяти HBM3, пропускная способность которой достигает 6,9 Тбайт/с. Задействован интерконнект NVIDIA Quantum-2 InfiniBand со скоростью передачи данных до 200 Гбит/с в расчёте на CPU. 
Источник изображений: Microsoft Применены сетевые адаптеры Azure Boost NIC второго поколения, благодаря которым пропускная способность сети Azure Accelerated Networking находится на уровне 160 Гбит/с. Для локального хранилища на основе NVMe SSD заявлена скорость чтения информации до 50 Гбайт/с и скорость записи до 30 Гбайт/с. 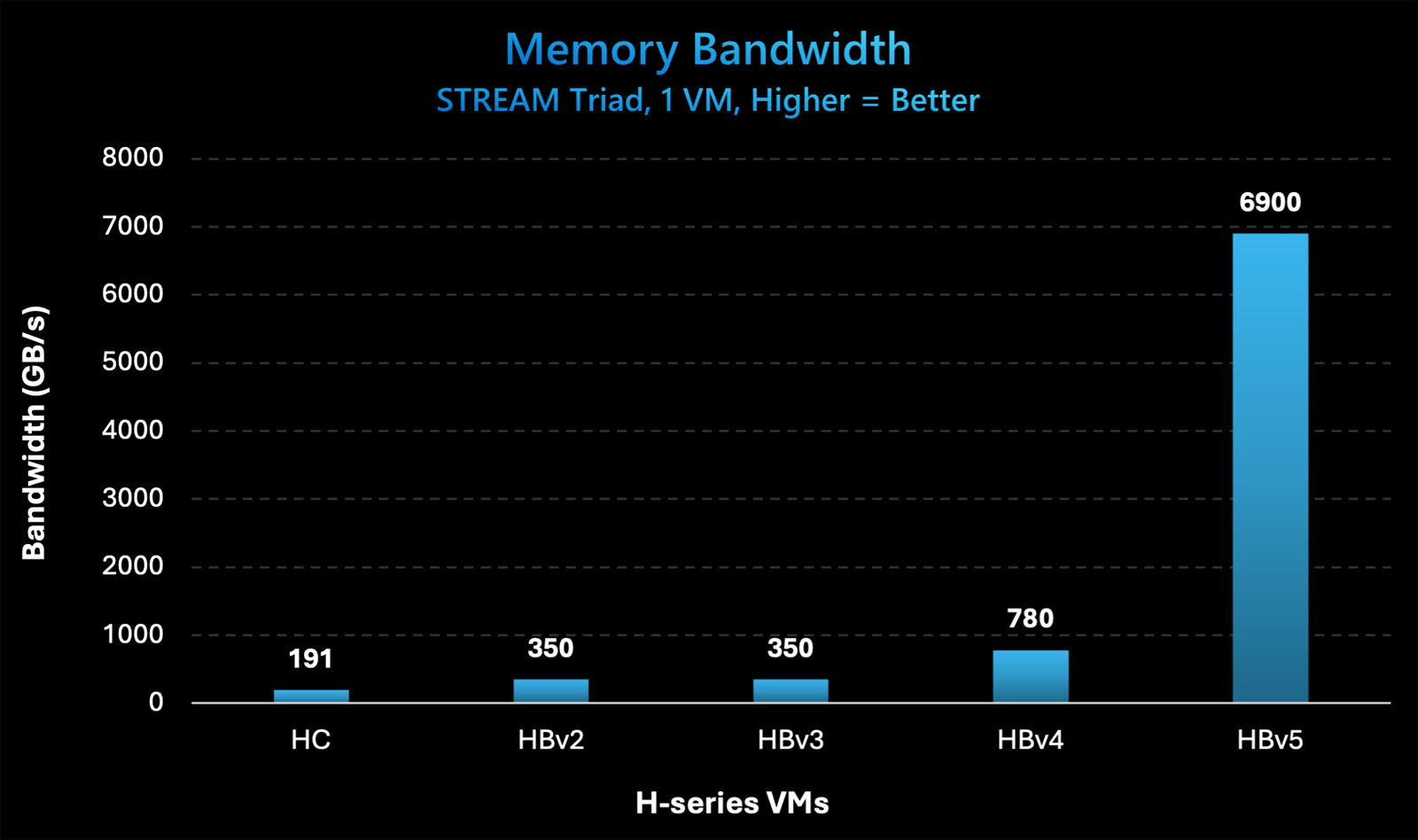 Отмечается, что по показателю пропускной способности памяти виртуальные машины Azure HBv5 примерно в 8 раз превосходят новейшие альтернативы bare-metal и cloud, в 20 раз опережают инстансы Azure HBv3 и Azure HBv2 (на базе EPYC Milan-X и EPYC Rome) и в 35 раз обходят HPC-серверы возрастом 4–5 лет, жизненный цикл которых приближается к завершению. Машины Azure HBv5 станут доступны в I половине 2025 года.
20.11.2024 [01:40], Владимир Мироненко
Microsoft представила кастомные чипы Azure Boost DPU и Integrated HSM, уникальный AMD EPYC 9V64H с HBM и собственный вариант NVIDIA GB200 NVL72
amd
azure arc
azure stack
dpu
epyc
gb200
hardware
hbm
hpc
microsoft
microsoft azure
nvidia
гибридное облако
ии
информационная безопасность
облако
ускоритель
Microsoft представила на конференции Microsoft Ignite новые специализированные чипы Azure Boost DPU и Azure integrated Hardware Security Module (HSM), предназначенные для использования в ЦОД с целью поддержки рабочих нагрузок в облаке Azure и повышения безопасности. 
Источник изображений: Microsoft Чтобы снизить зависимость от поставок чипов сторонних компаний, Microsoft занимается разработкой собственных решений для ЦОД. Например, на прошлогодней конференции Microsoft Ignite компания представила Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100 собственной разработки. Azure Boost DPU включает специализированные ускорители для работы с сетью и хранилищем, а также предлагает функции безопасности. Так, скорость работы с хранилищем у будущих инстансов Azure будет вчетверо выше, чем у нынешних, а энергоэффективность при этом вырастет втрое.  Не вызывает сомнений, что в разработке Azure Boost DPU участвовали инженеры Fungible, производителя DPU, который Microsoft приобрела в декабре прошлого года. Как отмечает TechCrunch, в последние годы популярность DPU резко увеличилась. AWS разработала уже несколько поколений Nitro, Google совместно с Intel создала IPU, AMD предлагает DPU Pensando, а NVIDIA — BlueField. Есть и другие нишевые игроки. Согласно оценкам Allied Analytics, рынок чипов DPU может составить к 2031 году $5,5 млрд.  Ещё один кастомный чип — Azure integrated Hardware Security Module (HSM) — отвечает за хранение цифровых криптографических подписей и ключей шифрования в защищённом модуле «без ущерба для производительности или увеличения задержки». «Azure Integrated HSM будет устанавливаться на каждом новом сервере в ЦОД Microsoft, начиная со следующего года, чтобы повысить защиту всего парка оборудования Azure как для конфиденциальных, так и для общих рабочих нагрузок», — заявила Microsoft. Azure Integrated HSM работает со всем стеком Azure, обеспечивая сквозную безопасность и защиту.  Microsoft также объявила, что задействует ускорители NVIDIA Blackwell и кастомные серверные процессоры AMD EPYC. Так, инстансы Azure ND GB200 v6 будут использовать суперускорители NVIDIA GB200 NVL 72 в собственном исполнении Microsoft, а интерконнект Quantum InfiniBand позволит объединить десятки тысяч ускорителей Blackwell. Компания стремительно наращивает закупки этих систем. А инстансы Azure HBv5 получат уникальные 88-ядерные AMD EPYC 9V64H с памятью HBM, которые будут доступны только в облаке Azure. Каждый инстанс включает четыре таких CPU и до 450 Гбайт памяти с агрегированной пропускной способностью 6,9 Тбайт/с.  Кроме того, Microsoft анонсировала новое решение Azure Local, которое заменит семейство Azure Stack. Azure Local — это облачная гибридная инфраструктурная платформа, поддерживаемая Azure Arc, которая объединяет локальные среды с «большим» облаком Azure. По словам компании, клиенты получат обновление до Azure Local в автоматическом режиме. Наконец, Microsoft анонсировала новые возможности в Azure AI Foundry, новой «унифицированной» платформе приложений ИИ, где организации смогут проектировать, настраивать и управлять своими приложениями и агентами ИИ. В числе новых опций — Azure AI Foundry SDK (пока в виде превью). |
|

