Материалы по тегу: c
|
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 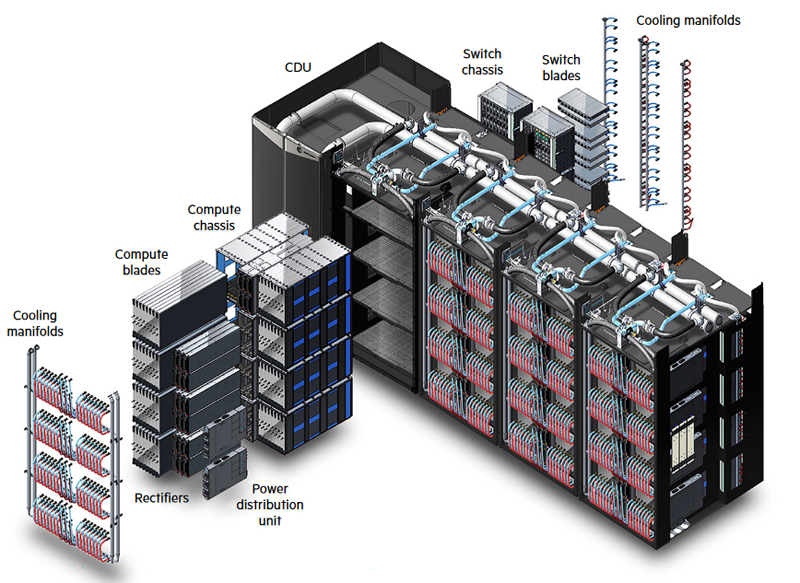 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
19.11.2024 [17:30], Сергей Карасёв
1,742 Эфлопс: El Capitan стал самым мощным в мире суперкомпьютером рейтинга TOP500Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США (DOE), Администрация по национальной ядерной безопасности США (NNSA), компании AMD и HPE официально представили El Capitan — самый производительный в мире суперкомпьютер. Эта машина возглавила ноябрьский рейтинг мощнейших вычислительных систем TOP500. Комплекс El Capitan создан специалистами HPE Cray. Суперкомпьютер обладает FP64-быстродействием 1,742 Эфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 2,746 Эфлопс. Прежний лидер TOP500 — система Frontier — с производительностью 1,353 Эфлопс теперь находится на втором месте рейтинга. Машина Aurora, так и не прибавившая в производительности, хотя и заявленная когда-то как 2-Эфлопс система, занимает теперь третье место. В основу El Capitan легла платформа HPE Cray Shasta. Используется гибридная архитектура AMD с APU Instinct MI300A: изделие содержит 24 ядра Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. В общей сложности в составе суперкомпьютера объединены 11 136 узлов, каждый из которых несёт на борту четыре экземпляра Instinct MI300A. Применён интерконнект HPE Slingshot-11 с пропускной способностью 200 Гбит/с. Система включает узлы Rabbit, которые формируют дезагрегированное NVMe-хранилище с прямым PCIe-подключением к вычислительным узлам. 
Источник изображений: LLNL Суммарное количество ядер CPU и GPU в составе El Capitan достигает 11 039 616, объём памяти — 5,4375 Пбайт. За отвод тепла отвечает система прямого жидкостного охлаждения HPE. Заявленная энергетическая эффективность составляет 58,89 Гфлопс/Вт: с таким показателем машина оказалась на 18-м месте в списке «зелёных» суперкомпьютеров GREEN500, но с учётом масштаба и общего энергопотребления 29,58 МВт — это хороший показатель. Система охлаждения HPC-объекта использует 28 тыс. т воды. Отмечается, что El Capitan станет главным вычислительным ресурсом для Tri-lab — группы, в которую вместе с LLNL входят Сандийские национальные лаборатории (SNL) и Лос-Аламосская национальная лаборатория (LANL). Использовать мощности нового суперкомпьютера планируется для обеспечения национальной безопасности и решения сложных задач, связанных с ядерным оружием. В частности, El Capitan обеспечит беспрецедентные возможности моделирования и имитации, необходимые для Программы управления ядерными запасами NNSA. Кроме того, НРС-комплекс поможет в модернизации и создании нового оружия, такого как боеголовки W87-1 и W93, которые в настоящее время находятся на стадии разработки.  Отмечается также, что на 10-й позиции в рейтинге TOP500 оказался суперкомпьютер Tuolumne, также построенный в рамках проекта LLNL и NNSA. Фактически Tuolumne — это младший брат El Capitan: машина использует ту же архитектуру на базе Instinct MI300A, но обладает примерно на порядок меньшей FP64-производительностью 208,10 Пфлопс с пиковым значением 288,88 Пфлопс. Применять мощности Tuolumne планируется для «несекретных» задач, таких как исследования в области энергетической безопасности, изменений климата, вычислительной биологии, разработки лекарственных препаратов следующего поколения и пр. Стоит отметить, что Frontier — не единственная система, которая уступила пальму первенства более новым НРС-комплексам в ноябрьском рейтинге TOP500. Та же участь постигла самый мощный суперкомпьютер Европы LUMI, который опустился с пятого на восьмое место. На пятой позиции оказалась совершенно новая система HPC6, расположенная в центре нефтегазовой компании Eni в Феррера-Эрбоньоне (Италия). Её производительность достигает 477,9 Пфлопс при пиковом показателе 606,97 Пфлопс.
19.11.2024 [12:57], Руслан Авдеев
Dell отобрала у Supermicro крупный заказ на ИИ-серверы для xAI Илона МаскаОснованный Илоном Маском (Elon Musk) стартап xAI, похоже, отнял все прежние заказы на ИИ-серверы у испытывающей не лучшие времена Supermicro, чтобы передать их её конкурентам. Как сообщает UDN, выгодоприобретателями станет Dell, а также её партнёры Inventec и Wistron. Для Supermicro, которой и без того грозит делистинг с Nasdaq, это станет очередным ударом. Ранее Dell и Supermicro поставляли оборудования компаниям Илона Маска, в т.ч. xAI и Tesla. Официально сообщалось, что xAI закупила ИИ-серверы с жидкостным охлаждением у Supermicro. Но после того, как Министерство юстиции США начало расследование деятельности поставщика в связи с вероятными махинациями с бухгалтерской отчётностью и нарушением санкционного режима, акции компании обрушились. После этого, по данным UDN, компании Маска и приняли решения передать заказы другим исполнителям. Среди поставщиков ИИ-серверов у Dell хорошие возможности получения заказов. Например, Wistron выпускает материнские платы для ИИ-серверов компании и выполняет некоторые задачи по сборке — партнёры станут одними из основных бенефициаров краха Supermicro. Фактически Wistron уже расширяет производственные мощности для удовлетворения спроса, в частности на трёх заводах на Тайване, а также в Мексике. В Wistron смотрят в будущее с большим оптимизмом и ожидают, что спрос на ИИ-серверы будет расти «трёхзначными» значениями в процентном отношении. 
Источник изображения: Bermix Studio/unsplash.com Inventec также является крупным поставщиком Dell и тоже получит свою долю «пирога» от заказа Supermicro. Компания давно участвует в производстве ИИ-систем и входит в тройку ведущих партнёров Dell, участвующих в сборке серверов. В 2024 году компания поставляла машины на чипах семейства NVIDIA Hopper, но в I квартале 2025 года она сможет поставлять уже варианты на платформе NVIDIA Blackwell — с ускорителями B200 и B200A. Считается, что у компании есть свободные производственные мощности в Мексике, поэтому она сможет нарастить выпуск ИИ-серверов для компаний, ранее работавших с Supermicro. 
Фото: Michael Dell Одной из ключевых причин проблем Supermicro считается задержка с подачей финансовых документов, из-за чего компания рискует покинуть биржу Nasdaq. Чтобы избежать делистинга, Supermicro должна была объяснить задержки с подачей материалов и подать доклад по форме K-10 к 16 ноября, но сделать этого не успела. Впрочем, первые неприятности у Supermicro начались значительно раньше, когда Hindenburg Research опубликовала разгромный доклад о финансовой отчётности компании. Если Supermicro дождётся делистинга на бирже, это приведёт к серьёзными финансовыми последствиями, включая стремительное падение акций и необходимость немедленного погашения долга $1,725 млрд по конвертируемым облигациям — обычно такие «триггеры» учитываются в соглашениях и активируются при делистинге. Буквально на днях сообщалось, что Supermicro лишилась заказа от индонезийской YTL Group (YTLP) на поставку суперускорителей NVIDIA GB200 NVL72 для одного из крупнейших в Юго-Восточной Азии ИИ-суперкомпьютеров. Теперь поставками будет заниматься только Wiwynn, которая принадлежит всё той же Wistron. При этом сама Wiwynn сейчас судится с X (Twitter), которой владеет Илон Маск.
19.11.2024 [11:47], Сергей Карасёв
Esperanto и NEC займутся созданием HPC-решений на базе RISC-VСтартап Esperanto Technologies и корпорация NEC объявили о заключении соглашения о сотрудничестве в области НРС. Речь идёт о создании программных и аппаратных решений следующего поколения, использующих открытую архитектуру RISC-V. Напомним, Esperanto разрабатывает высокопроизводительные RISC-V-чипы для задач НРС и ИИ. Первым продуктом компании стало изделие ET-SoC-1, которое объединяет 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Решение предназначено для инференса рекомендательных систем, в том числе на периферии. В августе 2023 года стало известно о подготовке чипа ET-SoC-2 с высокопроизводительными ядрами RISC-V с векторными расширениями. В рамках соглашения о сотрудничестве, как отмечается, будут объединены опыт и экспертизы NEC в области проектирования суперкомпьютеров и создания специализированного софта для HPC-задач с технологиями Esperanto в сфере высокопроизводительных энергоэффективных чипов на основе набора инструкций RISC-V. При этом упоминаются достижения NEC по направлению векторных процессоров: японская компания проектировала уникальные изделия SX-Aurora, но их разработка была остановлена в 2023 году. 
Источник изображения: Esperanto «Используя глубокий опыт и экспертные знания NEC в области HPC, а также открытый набор инструкций RISC-V в сочетании с вычислительной технологией Esperanto, мы сможем разрабатывать масштабируемые и эффективные решения для ИИ и высокопроизводительных вычислений», — отметил Арт Свифт (Art Swift), президент и генеральный директор Esperanto.
18.11.2024 [13:38], Руслан Авдеев
Foxlink запустила мощнейший на Тайване суперкомпьютер для малого и среднего бизнесаFoxlink Group (Cheng Uei Precision Industry) открыла крупнейший на Тайване суперкомпьютерный центр Ubilink (Ubilink.AI). По данным DigiTimes, центр предназначен для обслуживания предприятий малого и среднего бизнеса (SME), которые не могут позволить себе собственных вычислительных мощностей. Хотя основной деятельностью Foxlink является производство разъёмов, компания расширяет бизнес, осваивая решения для управления электропитанием и коммуникаций, а также выпуск энергетических модулей. Центр Ubilink создан дочерней Shinfox Energy совместно с Asustek Computer и японской Ubitus, занимающейся предоставлением облачных услуг. В Ubitus сообщили, что инфраструктура Ubilink включает 128 серверов Asus, 1024 ускорителя NVIDIA H100 и интерконнект NVIDIA Quantum-2 InfiniBand. Конфигурация обеспечивает до 45,82 Пфлопс (FP64) — система занимает 31-е место в рейтинге TOP500. В будущем станут применять и более современные B100 и B200 — когда те будут доступны. Ожидается, что в 2025 году суммарно будет установлено 10 240 ускорителей H100, B100 и B200. Представители местных властей уже заявили, что Ubilink существенно улучшит позиции Тайваня на рынке ИИ-вычислений, на котором территория сегодня занимает 26-е место. В Asustek добавляют, что достигнутая производительность в 45,82 Пфлопс заметно превышает плановые 40 Пфлопс. Кроме того, центр имеет PUE на уровне 1,2 — ранее ожидалось, что удастся добиться энергоэффективности лишь на уровне 1,38. Благодаря использованию опыта Shinfox Energy в области возобновляемой энергетики, Ubilink стал первым в Азии суперкомпьютерным центром, использующим «зелёные» источники энергии — клиенты могут воспользоваться вычислениями без существенного ущерба окружающей среде. 
Источник изображения: UBITUS Предполагается, что Ubilink компенсирует отсутствие мощностей для местных малых и средних компаний, не имеющих доступа к значительным вычислительным ресурсам. Предлагая доступные вычислительные мощности, центр позволяет таким бизнесам расширить свои портфели предложений и конкурировать даже на мировом уровне. Суперкомпьютер уже востребован местными разработчиками чипов, компаний, занимающихся их упаковкой и тестированием, биотехнологическими бизнесами, а также исследовательскими институтами различной направленности. Из-за высокого спроса Foxlink уже рассматривает вторую и третью фазы расширения проекта.
17.11.2024 [11:37], Сергей Карасёв
«Систэм Электрик» представила модульные ИБП Excelente VS мощностью до 150 кВтРоссийская компания «Систэм Электрик» (Systême Electric, ранее Schneider Electric в России) объявила о начале продаж локализованных модульных источников бесперебойного питания (ИБП) серии Excelente VS. Устройства, по заявлениям разработчика, предназначены для защиты критически важных нагрузок. Напомним, ранее в семействе Excelente были доступны решения Excelente VM (50–300 кВА), Excelente VL (350–600 кВА) и Excelente VX (100–1200 кВА). Они обеспечивают до 96,6 % КПД в режиме двойного преобразования и до 99 % в режиме ECO. В случае новых ИБП серии Excelente VS мощность со встроенными модульными батареями может варьироваться от 30 до 60 кВА/кВт, с внешними батареями — от 30 до 150 кВА/кВт. В первом случае заказчик получает такие преимущества, как снижение занимаемой площади, удобное обслуживание без необходимости выключения ИБП и сокращение времени обслуживания всей системы питания, говорит компания. Версии с внешними литий-ионными аккумуляторами предлагают длительный срок службы батареи, повышенную ёмкость и более высокую температурную устойчивость. 
Источник изображения: «Систэм Электрик» Единичный коэффициент мощности по выходу (PF=1), как заявляет «Систэм Электрик», позволяет рассчитывать необходимый уровень защиты для текущей инфраструктуры без лишних затрат. Диапазон входных напряжений — от 135 до 485 В. Кроме того, говорится о высокой перегрузочной способности. Заявленный КПД достигает 96 % в режиме двойного преобразования (On-Line) и 99 % в режиме ECO. Устройства базируются на модульной архитектуре с возможностью горячей замены. Допускается параллельная работа до шести ИБП одновременно. В оснащение входят информационный дисплей, коммуникационные интерфейсы (SNMP, RS485 и USB), кнопка EPO для аварийного отключения, а также пылевой фильтр с быстрым доступом (находится за фронтальной панелью). Systeme Electric отмечает, что ИБП можно адаптировать для сложных проектов в средних и крупных дата-центрах, а также в сфере критически важной коммерческой и промышленной инфраструктуры. Устройства серии Excelente VS производится на площадке «Систэм Электрик» в особой экономической зоне «Технополис Москва».
17.11.2024 [11:32], Сергей Карасёв
NEC создаст в Японии суперкомпьютер на базе Intel Xeon 6900P и AMD Instinct MI300A для исследований термоядерного синтезаКорпорация NEC займётся созданием нового НРС-комплекса, который планируется ввести в эксплуатацию в Японии в июле 2025 года. Система, базирующаяся на компонентах AMD и Intel, будет использоваться для различных исследований и разработок в области термоядерного синтеза. Заказ на создание суперкомпьютера поступил от Национальных институтов квантовой науки и технологий Японии (QST) при Национальном агентстве исследований и разработок (ANID), а также от Национального института термоядерных наук (NIFS) в составе Национальных институтов естественных наук (NINS). Система будет установлена в Институте термоядерной энергии Rokkasho (входит в QST) в Аомори (Япония). Основой проектируемого суперкомпьютера послужат 360 узлов NEC LX 204Bin-3, в состав каждого из которых войдут два процессора Intel Xeon 6900P поколения Granite Rapids (всего 720 чипов) и память DDR5 MRDIMM. Кроме того, будут задействованы 70 узлов NEC LX 401Bax-3GA, несущих на борту по четыре ускорителя AMD Instinct MI300A (в общей сложности 280 изделий). Говорится о применении интерконнекта InfiniBand с 400G-коммутаторами NVIDIA QM9700, а также хранилища DDN EXAScaler ES400NVX2 вместимостью 42,2 Пбайт с файловой системой Lustre. Для управления рабочими нагрузками будет использоваться софт Altair PBS Professional. 
Источник изображения: NEC Ожидается, что производительность суперкомпьютера достигнет 40,4 Пфлопс. Это в 2,7 раза больше суммарных показателей двух нынешних НРС-систем, установленных в рамках независимых проектов QST и NIFS. Учёные намерены применять новый НРС-комплекс для точного прогнозирования экспериментов и создания сценариев работы для Международного экспериментального термоядерного реактора (ITER). Кроме того, мощности суперкомпьютера будут востребованы исследовательскими группами токамака Satellite Tokamak JT-60SA и электростанции DEMO (DEMOnstration Power Plant), использующей термоядерный синтез.
16.11.2024 [20:59], Сергей Карасёв
Стартап xAI Илона Маска получит от арабов $5 млрд на покупку ещё 100 тыс. ускорителей NVIDIAКак сообщает CNBC, стартап xAI Илона Маска (Elon Musk) привлёк многомиллиардные инвестиции: деньги будут направлены на закупку ускорителей NVIDIA для расширения вычислительных мощностей ИИ-суперкомпьютера. Напомним, в начале сентября нынешнего года компания xAI запустила ИИ-кластер Colossus со 100 тыс. ускорителей NVIDIA H100. В составе платформы применяются серверы Supermicro, узлы хранения типа All-Flash, адаптеры SuperNIC, а также СЖО. Суперкомпьютер располагается в огромном дата-центре в окрестностях Мемфиса (штат Теннесси). Как теперь стало известно, в рамках нового раунда финансирования xAI привлечёт $6 млрд. Из них $5 млрд поступит от суверенных фондов Ближнего Востока, а ещё $1 млрд — от других инвесторов, имена которых не раскрываются. При этом рыночная стоимость стартапа достигнет $50 млрд. О том, что xAI получит дополнительные средства на развитие, также сообщает Financial Times. По данным этой газеты, речь идёт о $5 млрд при капитализации стартапа на уровне $45 млрд. 
Источник изображения: NVIDIA Ранее Маск говорил о намерении удвоить производительность Colossus: для этого, в частности, планируется приобрести примерно 100 тыс. ИИ-ускорителей, включая 50 тыс. изделий NVIDIA H200. Судя по всему, привлеченные средства стартап также направит на покупку других решений NVIDIA, в том числе коммутаторов Spectrum-X SN5600 и сетевых карт на базе BlueField-3. Между тем жители Мемфиса выражают недовольство в связи с развитием ИИ-комплекса xAI. Активисты, в частности, обвиняют стартап в том, что используемые на территории его дата-центра генераторы ухудшают качество воздуха в регионе.
16.11.2024 [20:49], Сергей Карасёв
Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на огромных чипах Cerebras WSE-3Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) в рамках партнёрства с компанией Cerebras Systems объявили о запуске кластера Kingfisher, который будет использоваться в качестве испытательной платформы при разработке ИИ-технологий для обеспечения национальной безопасности. Основой Kingfisher служат узлы Cerebras CS-3, которые выполнены на фирменных ускорителях Wafer Scale Engine третьего поколения (WSE-3). Эти гигантские изделия содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт памяти SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, внутреннего интерконнекта — 214 Пбит/с. На сегодняшний день платформа Kingfisher объединяет четыре узла Cerebras CS-3, а конечная конфигурация предусматривает использование восьми таких блоков. Узлы Cerebras CS-3 мощностью 23 кВт каждый содержат СЖО, подсистемы питания, сетевой интерконнект Ethernet и другие компоненты. 
Источник изображения: SNL Развёртывание кластера Cerebras CS-3 является частью программы Advanced Simulation and Computing (ASC), которая реализуется Национальным управлением по ядерной безопасности США (NNSA). Речь идёт, в частности, об инициативе ASC Artificial Intelligence for Nuclear Deterrence (AI4ND) — искусственный интеллект для ядерного сдерживания. Предполагается, что Kingfisher позволит разрабатывать крупномасштабные и надёжные модели ИИ с использованием защищённых внутренних ресурсов Tri-lab — группы, в которую входят Сандийские национальные лаборатории, Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе (DOE).
15.11.2024 [17:47], Владимир Мироненко
FTC собралась расследовать жалобы на антиконкурентную практику в облачном бизнесе MicrosoftФедеральная торговая комиссия США (FTC) готовится начать расследование заявлений по поводу использования Microsoft антиконкурентных практик в своём облачном бизнесе, сообщила Financial Times со ссылкой на информированные источники. По их словам, FTC пока не запросила документы или другую информацию у Microsoft. Это говорит о том, что расследование находится на ранней стадии и нет никаких гарантий, что оно будет продолжено. Как утверждают источники, сейчас FTC изучает обвинения Microsoft в злоупотреблении своей рыночной властью — компания якобы навязывает карательные условия лицензирования, чтобы помешать клиентам переносить свои данные из Azure на другие платформы. В частности, чтобы усложнить переход на другую платформу, Microsoft существенно увеличивает абонентскую плату для тех, кто покидает Azure, вводит высокие сборы за выход и якобы делает продукты Office 365 несовместимыми с облаками конкурентов. На этот шаг регулятора подтолкнуло письмо Google с обвинением Microsoft в антиконкурентной практике, направленное в комиссию в июне 2023 года. В письме утверждается, что Microsoft использует ограничения по лицензированию ПО, чтобы заставить клиентов использовать облачные сервисы Azure для экономии денег.  Google также заявила, что Microsoft использует доминирующее положение Windows Server и Office, чтобы оказывать давление на клиентов, заставляя их пользоваться Azure, и использует «сложную сеть» лицензионных ограничений, которые призваны помешать компаниям диверсифицировать поставщиков корпоративного ПО. Также было отмечено, что Microsoft взимает плату со сторонних поставщиков облачной инфраструктуры, таких как Google Cloud и Amazon Web Services, за запуск её ПО, такого как Windows Server и Office, на их платформах. В конечном итоге расходы перекладываются на клиентов. При этом дополнительная плата за запуск ПО Microsoft в облаке Azure не взимается. Аналитик Хольгер Мюллер (Holger Mueller) из Constellation Research сообщил в прошлом году, что поставщики ПО ужесточают условия лицензирования, чтобы ограничить своих конкурентов. «Основная уловка заключается в том, что они либо ограничивают сервисы, не позволяя им работать в других облаках, либо взимают большую плату за такую возможность», — сказал Мюллер. Microsoft удалось избежать официального расследования деятельности своего облачного подразделения со стороны Еврокомиссии с помощью сделки с CISPE. При этом Google пыталась с помощью денежного вознаграждения убедить облачные компании не прекращать жаловаться на Microsoft в ЕС. В итоге Google подала в Еврокомиссию новую жалобу на Microsoft и сформировала новую коалицию Open Cloud Coalition. Аналогичные разбирательства ведутся и в Великобритании. |
|

