Материалы по тегу: c
|
23.06.2025 [11:58], Сергей Карасёв
Подземный суперкомпьютер Olivia стал самым мощным в НорвегииВ Норвегии введён в эксплуатацию самый мощный в стране суперкомпьютер — система Olivia, созданная корпорацией HPE. Комплекс расположен в дата-центре Лефдаль (Lefdal Mine Datacenter, LMD) на базе бывшего рудника, а для его охлаждения используется холодная вода из близлежащего фьорда. Машина построена на платформе HPE Cray Supercomputing EX (EX254n). В её состав входят 252 узла, каждый из которых содержит два 128-ядерных процессора AMD EPYC 9745 (Turin). В сумме это даёт 64 512 CPU-ядер. Кроме того, задействован GPU-кластер с 76 узлами, оснащёнными четырьмя гибридными суперчипами NVIDIA GH200: таким образом, в общей сложности применены 304 ускорителя. Используется интерконнект HPE Slingshot 11. За хранение данных отвечает система HPE Cray ClusterStor E1000 вместимостью 5,3 Пбайт. В текущей конфигурации GPU-кластер Olivia обладает производительностью 13,2 Пфлопс (FP64) и пиковым быстродействием 16,8 Пфлопс. При этом энергопотребление составляет 219 кВт. Таким образом, машина демонстрирует производительность в 60,274 Гфлопс/Вт. В июньском рейтинге мощнейших суперкомпьютеров мира TOP500 GPU-комплекс Olivia располагается на 117-й позиции, тогда как в списке самых энергоэффективных суперкомпьютеров GREEN500 он занимает 22-ю строку. CPU-блок Olivia занимает 271-е место в рейтинге с фактической и пиковой FP64-производительностью 4,25 и 4,95 Пфлопс соответственно. 
Источник изображения: Sigma2 Olivia эксплуатируется государственной компанией Sigma2. Применять суперкомпьютер планируется для проведения исследований в различных областях, включая изменения климата, здравоохранение, ИИ и пр. Суперкомпьютер обладает возможностями для дальнейшего расширения. В частности, количество ядер CPU может быть увеличено до 119 808. Кроме того, могут быть добавлены ещё 224 ускорителя.
21.06.2025 [01:43], Анжелла Марина
Основатель SoftBank предложил создать в США хаб Crystal Land стоимостью $1 трлн для развития ИИ и роботовОснователь SoftBank, японский миллиардер Масаёси Сон (Masayoshi Son), предложил создать в штате Аризона масштабный индустриальный комплекс стоимостью до $1 трлн для развития ИИ и робототехники. Проект получил внутреннее название Crystal Lan. Он может стать одним из самых амбициозных проектов бизнесмена за всю его карьеру. Как пишет Bloomberg, Сон мечтает создать в США аналог крупного китайского технопарка в Шэньчжэне, где сосредоточены мощности по выпуску электроники. В состав комплекса могут войти линии по производству промышленных роботов на основе ИИ. При этом детали участия ключевых игроков, таких как тайваньского производителя чипов TSMC, остаются неясными. Хотя SoftBank стремится вовлечь эту компанию в проект, её представитель подчеркнул, что планы TSMC в Аризоне никак не связаны с Crystal Land. Тем не менее, суммарные инвестиции TSMC в США уже оцениваются в $165 млрд. Сейчас SoftBank ведёт переговоры с американскими властями, включая министра торговли США Говарда Лютника (Howard Lutnick), чтобы получить налоговые льготы и другие преференции для компаний, которые решат строить свои заводы в новом парке. Помимо этого, Сон лично обсуждает возможность участия Samsung Electronics. Примечательно, что на фоне этих новостей акции SoftBank выросли на 2,7 %, бумаги TSMC прибавили 1,9 %, а Samsung на 0,5 %. Официальных комментариев от компаний пока не последовало. 
Источник изображения: SoftBank Как отмечает Bloomberg, реализация Crystal Land зависит от множества факторов. Например, от интереса крупных технологических корпораций к этому проекту, наличия спроса и долгосрочного финансирования. При этом, по замыслу Сона, в будущем такие центры могут появиться не только в Аризоне, но и в других регионах США. В числе потенциальных участников также рассматриваются портфельные компании SoftBank Vision Fund, включая стартап Agile Robots SE, занимающийся автоматизацией. При этом у SoftBank есть и другие масштабные планы. В частности, компания намерена вложить до $40 млрд в OpenAI, купить за $6,5 млрд Ampere Computing и участвовать в проекте Stargate вместе с Oracle и MGX из ОАЭ. Для реализации всех инициатив SoftBank рассчитывает на внешние инвестиции, используя модель проектного финансирования, как это делают, например, при строительстве трубопроводов или других масштабных объектов.
19.06.2025 [17:13], Руслан Авдеев
Экзафлопсный суперкомпьютер Fugaku Next получит Arm-процессоры Fujitsu MONAKA-XЯпонская Fujitsu получила контракт на разработку преемника суперкомпьютера Fugaku, получившего условное название FugakuNEXT (Fugaku Next), сообщает Datacenter Dynamics. Информация об этом появилась ещё в прошлом году, но теперь заключено официальное соглашение. Новую машину разместят рядом с уже действующей в институте Riken (Япония) системой. Контракт включает и поставку вычислительного оборудования, а первая фаза проектирования продлится до конца февраля 2026 года. Fujitsu разрабатывает энергоэффективные 2-нм 144-ядерные Arm-процессоры MONAKA с 3.5D-упаковкой, начало выпуска которых запланировано на 2027 год. Для FugakuNEXT компания создаст процессоры MONAKA-X, которые позволят не только ускорить работу уже существующих приложений для Fugaku, но и добавят современные возможности ускорения ИИ-вычислений. В компании уверены, что новые процессоры пригодятся не только в очередном суперкомпьютере, но и в самых разных сферах экономики, общественной жизни и промышленности. Кроме того, компания направит усилия на создание NPU следующего поколения. 
Источник изображения: Van Tay Media/unspalsh.com Введённый в эксплуатацию весной 2020 года суперкомпьютер Fugaku несколько лет подряд занимал первые места в TOP500 и других рейтингах. В последнем списке TOP500 он занимает седьмую позицию. Министерством образования, культуры, спорта, науки и технологий Японии (MEXT) разработку FugakuNEXT анонсировало в августе 2024 года. Тогда утверждалось, что компьютер станет первой вычислительной машиной зеттафлопсного уровня. Впрочем, такая пиковая производительность относится только к ИИ-вычислениям. Так или иначе, ранее MEXT публиковало документ, согласно которому каждый узел Fugaku Next должен обеспечить пиковую производительность в сотни Тфлопс (FP64), что в совокупности может составить 1 Эфлопс.
16.06.2025 [14:45], Руслан Авдеев
Schneider Electric и NVIDIA предложат европейцам модульные ИИ ЦОД с мегаваттными стойкамиSchneider Electric и NVIDIA предложат инфраструктурные решения для предлагаемого Еврокомиссией проекта AI Continent Action Plan, в рамках которого Европу планируется превратить в ИИ-континент, сообщает Datacenter Dynamics. В рамках проекта предполагается потратить €20 млрд ($22 млрд) на ИИ-фабрики, в которых разместятся около 100 тыс. ускорителей нового поколения, в том числе при участии консорциума EuroHPC JU. NVIDIA же заявила, что Европа получит ускорители Blackwell суммарной производительностью более 3000 Эфлопс (точность не указана). «Континентальный» план предусматривает строительство пяти «ИИ-гигафабрик» в ЕС, а также 13 объектов поменьше в рамках частно-государственного финансирования. По словам главы NVIDIA Дженсена Хуанга (Jensen Huang), компания будет строить ИИ-фабрики вместе со Schneider Electric. Речь идёт о ключевой инфраструктуре, которая позволит обеспечить ИИ любую компанию, отрасль промышленности или сферу общественной жизни. Инициатива Schneider Electric и NVIDIA стала своеобразным ответом на план Еврокомиссии, основы взаимодействия были заложены на базе оговоренного ранее неэксклюзивного партнёрства. Schneider и NVIDIA совместно работали над эталонными серверными архитектурами и архитектурами ЦОД с прошлого года, а также над «цифровыми двойниками» в Omniverse. Schneider в рамках партнёрства будет работать над физической инфраструктурой, включающей системы питания и охлаждения, собственно стойки, ПО для индуcтриального оборудования и т.п. 
Источник изображения: Schneider Electric Как отмечает The Register, в свете новых договорённостей Schneider пополнила портфолио EcoStruxure, представив готовые модульные блоки (Prefabricated Modular EcoStruxure Pod Data Center), предназначенные для быстрого развёртывания энергоёмких ИИ-кластеров — 1 МВт на стойку и более. Компания предлагает усиленные стойки с увеличенными габаритами и грузоподъёмностью NetShelter SX Advanced Enclosures, а также обновлённые блоки распределения питания с поддержкой высоких мощностей NetShelter Rack PDU Advanced. Кроме того, анонсированы стойки с открытой архитектурой NetShelter Open Architecture, совместимые со стандартами OCP, в том числе с поддержкой кластеров на базе NVIDIA GB200 NVL72. Также предлагаются системы распределения электроэнергии и охлаждения, включая интегрированные в стойки технологии прямого жидкостного охлаждения чипов на базе СЖО Motivair (компания приобрела бизнес в прошлом году). По словам Schneider, рынок ЦОД всё более тяготеет к заранее собранным на заводе модульными решениям. При строительстве таких решений с нуля экономия может составить до 30 % в сравнении с классическими дата-центрами, а внедрение инфраструктуры может проходить намного быстрее.
13.06.2025 [02:20], Владимир Мироненко
AMD готовит ИИ-стойки Helios AI двойной ширины с Instinct MI400, AMD EPYC Venice и 800GbE DPU Pensando VulcanoВместе с анонсом ускорителей MI350X и MI355X также рассказала о планах на ближайшее будущее, включая выпуск ускорителей серий MI400 (Altair) в 2026 году и MI500 (Altair+) в 2027 году, а также решений UALink, Ultra Ethernet, DPU Pensando и стоечных архитектур, которые послужат основой ИИ-кластеров. Так, AMD анонсировала новую архитектуру Helios AI с стойками двойной ширины, которая объединит процессоры AMD EPYC Venice с ядрами Zen 6, ускорители Instinct MI400 и DPU Vulcano. Благодаря приобретению ZT Systems компания смогла существенно ускорить разработку и интеграцию решений уровня стойки — Helios AI появятся уже в 2026 году. Как сообщает DataCenter Dynamics, Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер AMD по ЦОД рассказал перед мероприятием, что решение об увеличении ширины стойки было принято в сотрудничестве с «ключевыми партнёрами» AMD, поскольку предложение должно соответствовать «правильной точке проектирования между сложностью, надёжностью и предоставлением преимуществ производительности». По словам AMD, это позволит объединить тысячи чипов таким образом, чтобы их можно было использовать как единую систему «стоечного масштаба». «Впервые мы спроектировали каждую часть стойки как единую систему», — заявила генеральный директор AMD Лиза Су (Lisa Su) на мероприятии, пишет CNBC. 
Источник изображений: AMD Дикманн заявил, что Helios предложит на 50 % больше пропускной способности памяти и на 50 % больше горизонтальной пропускной способности (по сравнению с NVIDIA Vera Rubin), поэтому «компромисс [за счёт увеличения ширины стойки] был признан приемлемым, поскольку крупные ЦОД, как правило, ограничены не квадратными метрами, а мегаваттами». 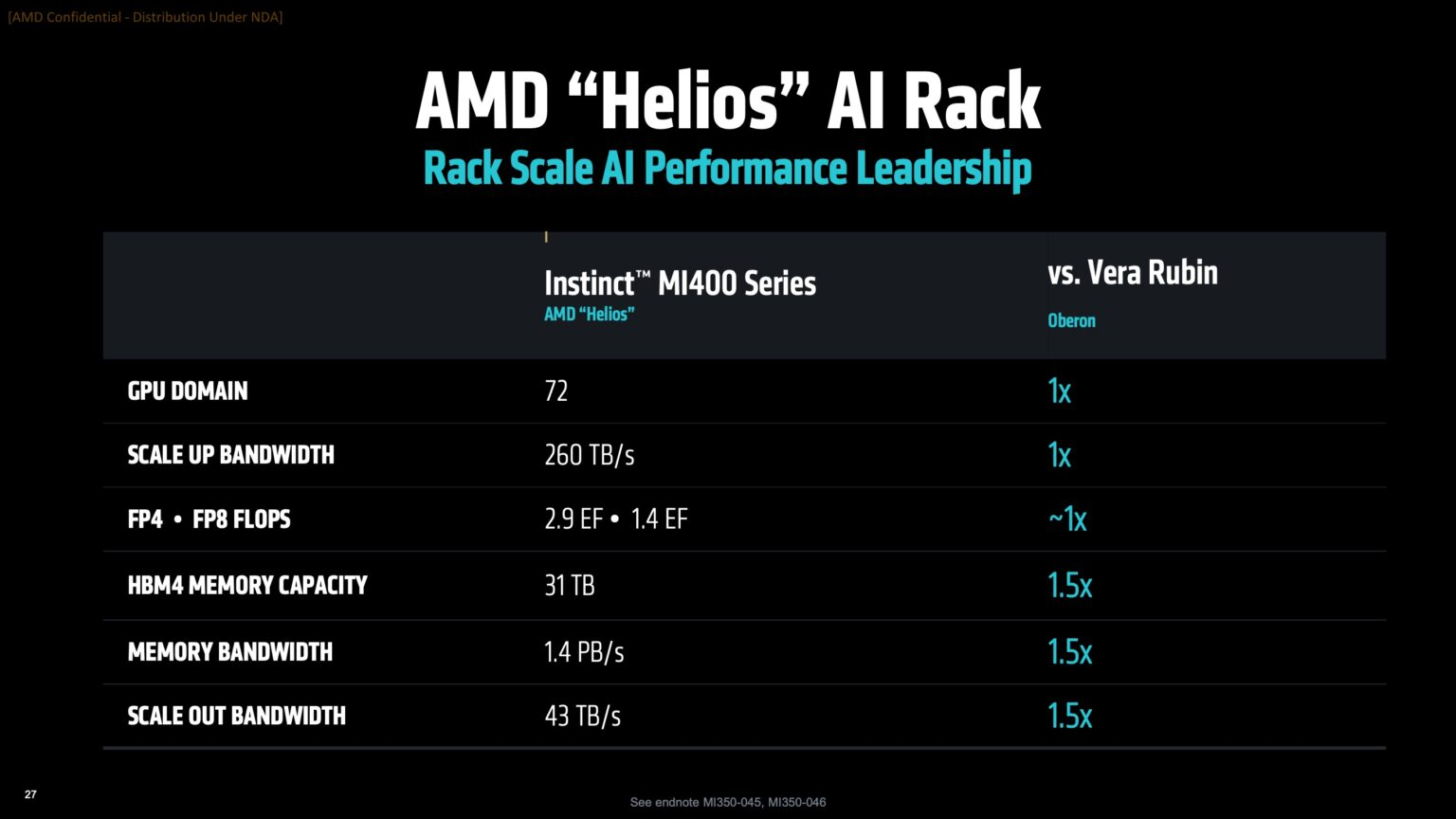 Как указано в блоге компании, «Helios создана для обеспечения вычислительной плотности, пропускной способности памяти, производительности и горизонтального масштабирования, необходимых для самых требовательных рабочих ИИ-нагрузок, в готовом к развёртыванию решении, которое ускоряет время выхода на рынок».  Helios представляет собой сочетание технологий AMD следующего поколения, включая:
 AMD отказалась сообщить стоимость анонсированных чипов, но, по словам Дикманна, ИИ-ускорители компании будут дешевле и в эксплуатации, и в приобретении в сравнении с чипами NVIDIA. «В целом, есть существенная разница в стоимости приобретения, которую мы затем накладываем на наше конкурентное преимущество в производительности, поэтому выходит значительная, исчисляемая двузначными процентами экономия», — сказал он.  AMD ожидает, что общий рынок ИИ-чипов превысит к 2028 году $500 млрд. Компания не указала, на какую долю общего пирога она будет претендовать — по оценкам аналитиков, в настоящее время у NVIDIA более 90 % рынка. Обе компании взяли на себя обязательство выпускать новые ИИ-чипы ежегодно, а не раз в два года, что говорит о том, насколько жёстче стала конкуренция и насколько важны передовые ИИ-технологии для гиперскейлеров. 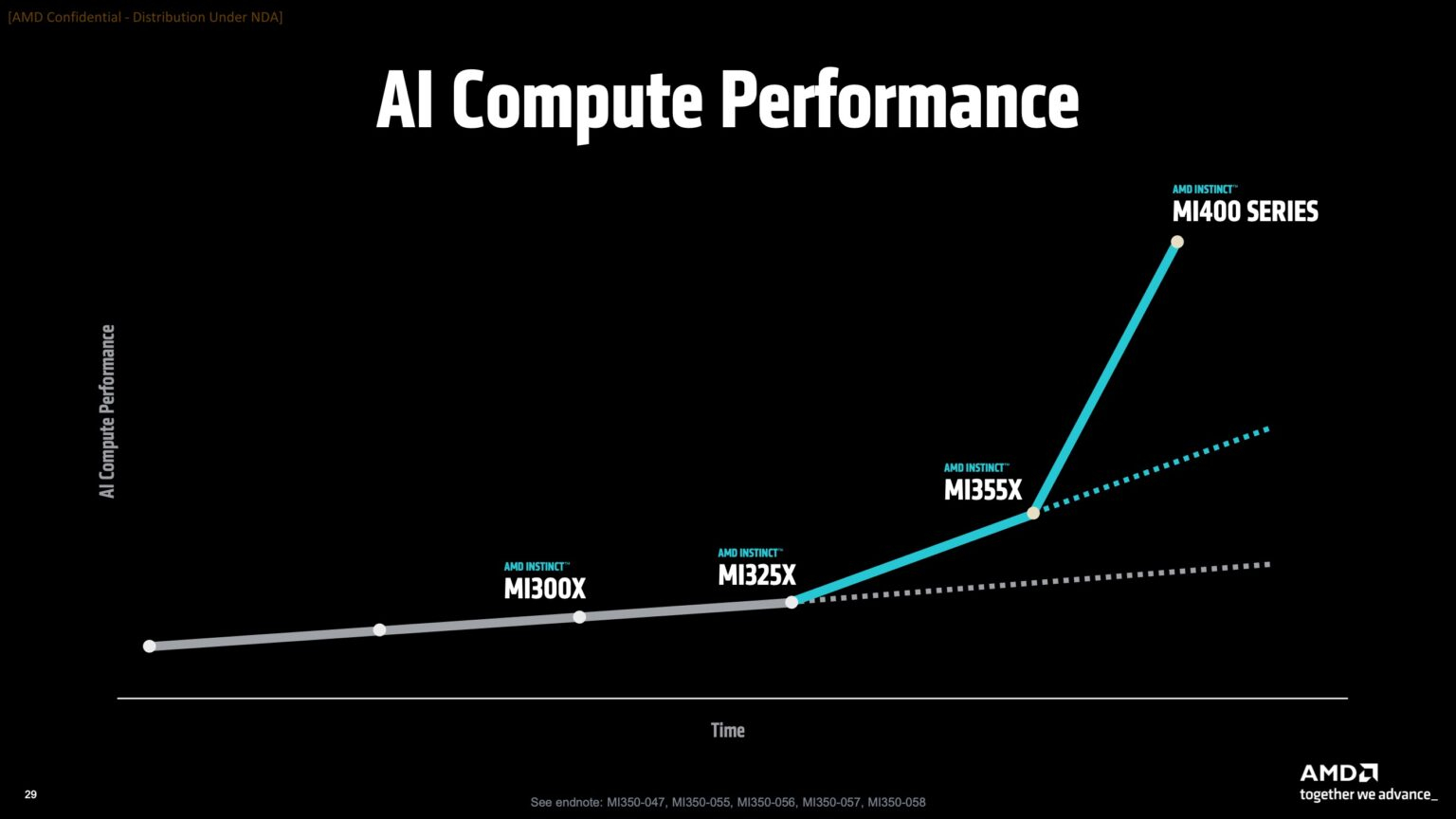 AMD сообщила, что её чипы Instinct используются семью из десяти крупнейших игроков ИИ-рынка, включая OpenAI, Tesla, xAI и Cohere. По словам AMD, Oracle планирует предложить своим клиентам кластеры с более чем 131 тыс. ускорителей MI355X. Meta✴ сообщила, что уже использует AMD-кластеры для инференса Llama и что она планирует купить серверы с чипами AMD следующего поколения. В свою очередь, представитель Microsoft сказал, что компания использует чипы AMD для обслуживания ИИ-функций чат-бота Copilot.
10.06.2025 [19:00], Игорь Осколков
Июньский TOP500 суперкомпьютеров: без сюрпризов, но не безынтересно65-я редакция TOP500 самых мощных суперкомпьютеров мира никаких особенных сюрпризов не преподнесла, но кое-какие новые и интересные машины в него попали. Лидерами списка среди стран всё ещё являются США (175 систем) и Китай (47 систем), вот только вклад их совершенно разный. Тройка лидеров по-прежнему представлена экзафлопсными суперкомпьютерами El Capitan, Frontier и Aurora Министерства энергетики США (DoE). Китайских же систем такого класса в списке нет, хотя никто не сомневается в их существовании. Хуже того, от КНР в этот раз снова не было подано ни одной заявки. Теперь к Китаю по количеству позиций в TOP500 приближается Германия — 41 машина, причём одна из них взобралась на четвёртое место июньской редакции списка. Она же является и единственным новичком в первой десятке. Это JUPITER Booster, совместный проект EuroHPC и Юлихского суперкомпьютерного центра (Jülich Supercomputing Centre). JUPITER (JU Pioneer for Innovative and Transformative Exascale Research) станет первым европейским экзафлопсным суперкомпьютером. Причём это изначально модульная система, «кусочек» которой под названием JETI (JUPITER Exascale Transition Instrument) уже попал в прошлогодний TOP500. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau JUPITER Booster по-прежнему использует платформу Atos/Eviden BullSequana XH3000 с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200. FP64-производительность представленного в TOP500 сегмента (это только часть всей машины) составила 793,4 Пфлопс при теоретическом пике в 930 Пфлопс. Энергопотребление составляет чуточку больше 13 МВт, но при этом в GREEN500 машина занимает только 21-е место. А на первом месте там… всё так же система JEDI на ровно той же аппаратной платформе, что неудивительно, ведь она тоже является «кусочком» JUPITER. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau На 11-ом месте оказался ещё один «сборный» суперкомпьютер — вторая фаза британского Isambard-AI на базе опять-таки NVIDIA GH200, которая добралась до отметки 216,5 Пфлопс (пик 278,6 Пфлопс). 13-е место досталось нидерландской системе ISEG2 от Nebius (когда-то Yandex) на базе Xeon Platinum 8468 (Sapphire Rapids), NVIDIA H200 (141 Гбайт) и InfiniBand NDR400. Неожиданностью можно назвать появление двух систем на базе векторных ускорителей SX-Aurora Type 10AE, разработку которых NEC уже забросила. Две безымянные машины на 113-м и 157-м местах принадлежат немецким метеорологам Deutscher Wetterdienst. Ближе к концу списка затесались ещё две любопытные системы из Норвегии, тоже безымянные. Интересны они тем, что сделаны xFusion (бывшее серверное подразделение Huawei, выделенное в проданную впоследствии независимую компанию), оснащены процессорами Intel Xeon 6900P (Granite Rapids-AP) и AMD EPYC 9005 (Turin), и… 100G-интерконнектом Intel Omni-Path. Буквально на днях Cornelis Networks догнала остальных разработчиков интерконнекта, представив, наконец, 400G-поколение CN5000. В целом же ситуация поменялась мало. На InfiniBand полагаются 54,2 % всех систем текущего списка, на Ethernet — суммарно по всем поколениям чуть больше трети. 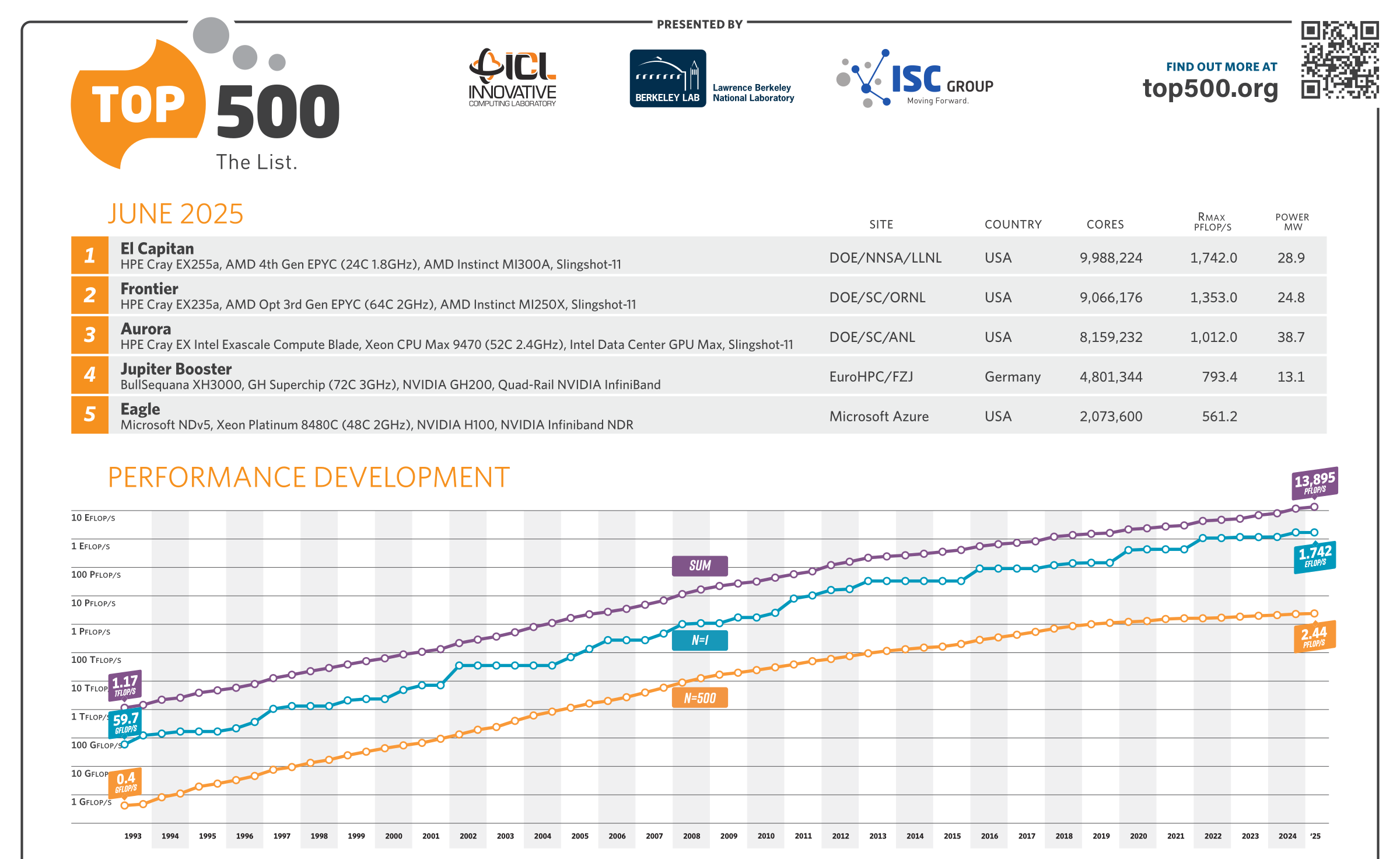
Источник: TOP500 Но если считать по Флопсам, то 48,2 % приходится на Slingshot, т.е. практически целиком на системы HPE, производительность которых суммарно составляет 47,9 % от производительности всего списка TOP500. Второе место по этому показателю у Atos/Eviden. По количеству суперкомпьютеров в списке HPE при этом занимает лишь второе место, уступая Lenovo и обгоняя Dell. Иными словам, HPE и Atos/Eviden преимущественно занимаются крупными машинами, а Lenovo, Dell и даже сама NVIDIA берут скорее числом. 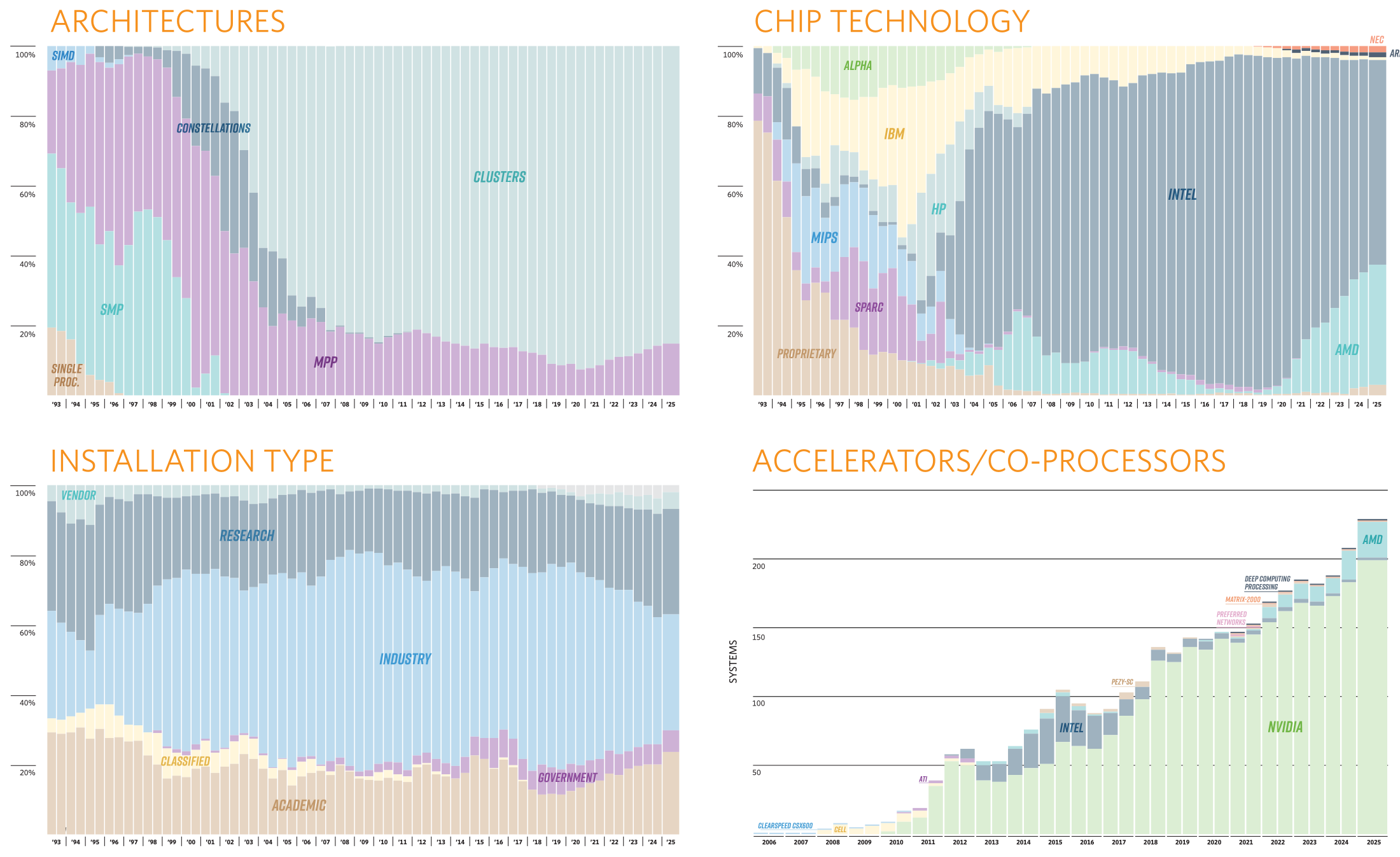
Источник: TOP500 В бенчмарке HPCG новым лидером стал El Capitan с показателем 17,407 Пфлопс, который сместил остальных участников на одну позицию вниз, отобрав первое место у Fugaku, которое она занимала несколько лет подряд. В бенчмарке HPL-MxP (HPL-AI) в расчётах смешанной точности первые места снова у El Capitan, Aurora и Frontier с показателями 16,7 Эфлопс, 11,6 Эфлопс и 11,4 Эфлопс соответственно. 
Источник изображения: NVIDIA Интересно, что в нынешнем TOP500 так и осталась только одна машина с AMD Instinct MI300X, а среди новинок всё больше MI300A да NVIDIA GH200 (а также более традиционных H100/H200). Очевидно, что новейшие NVIDIA B300 и Instinct MI325X в рейтинг могли и не попасть, но не исключено, что и в будущем вендоры будут по-прежнему ставить устаревающие ускорители как минимум NVIDIA. Всё дело в том, что в новых поколениях чипов NVIDIA сделала ставку на ИИ-нагрузки — разница между GB200 и GB300 в FP64-расчётах почти тридцатикратная. AMD якобы готовит Instinct MI430X с поддержкой FP64 и MI450X без таковой. Уже в анонсах суперкомпьютеров следующего поколения на базе Vera Rubin сама NVIDIA аккуратно обходит стороной вопрос «чистой» производительности, говоря лишь о «научных результатах» в случае системы Doudna. А в случае Blue Lion компания говорит о «слиянии симуляций, данных и ИИ». Возможно, это не совсем то, чего ждут учёные.
10.06.2025 [18:55], Руслан Авдеев
Германия получит суперкомпьютер Blue Lion на новейших ускорителях NVIDIA Vera RubinНемецкий Суперкомпьютерный центр Лейбница (Leibniz Supercomputing Centre, LRZ), входящий в HPC-группу Gauss Centre for Supercomputing, получит в своё распоряжение суперкомпьютер Blue Lion на базе ускорителей Vera Rubin. Ожидается, что он будет приблизительно в 30 раз производительнее своего предшественника — SuperMUC-NG. Ожидается, что платформа NVIDIA нового поколения кардинально изменит подход к научным исследованиям, сообщается в блоге компании. Это второй анонс машины на базе Vera Rubin после американского суперкомпьютера Doudna. По словам NVIDIA, новая аппаратная платформа — это «слиянии симуляций, данных и ИИ в единый движок для науки с высокой пропускной способностью, низкой задержкой, когерентными вычислениями и общей памятью». Непосредственно суперкомпьютер будет использовать платформу HPE Cray нового поколения с СЖО с тёплой водой (до +40 °C) на входе и 100-% безвентиляторным дизайном. Тепло системы будет использоваться для отопления близлежащих зданий. 
Источник изображения: NVIDIA Суперкомпьютер будет использоваться для исследований в областях климата, турбулентности, физики и машинного обучения — с комбинацией классических компьютерных симуляций и современного ИИ-моделирования. Также он станет помощником для реализации международных исследовательских проектов по всей Европе. Постройка новых компьютеров имеет важное значение, поскольку речь идёт о новой вехе в развитии суперкомпьютеров, которые теперь проектируются с прицелом на работу в реальном времени. ИИ более не является простым дополнением исследованиям, а данные постоянно находятся «в движении», поэтому стоящие за этим системы приходится постоянно поддерживать в актуальном состоянии, говорит NVIDIA.
06.06.2025 [11:08], Руслан Авдеев
Endeavour предложила ЦОД натриевые батареи TiamatВладеющая оператором дата-центров Edged компания Endeavour предложила дата-центрам натриевые аккумуляторы взамен литиевых. На этой неделе она объявила о стратегическом партнёрстве с производителем АКБ Tiamat для поставки батарей для ИИ ЦОД и систем стабилизации энергосетей, сообщает пресс-служба Endeavour. В Endeavour утверждают, что технология Tiamat даёт возможность полностью заряжать и разряжать аккумуляторы более 60 раз в час, тогда как Li-Ion варианты обеспечивают лишь 1–3 подобных цикла. Как заявляют в компании, такие показатели в сочетании с длительным сроком службы и высокой плотностью хранения энергии делают АКБ подходящими для работы с нестабильными ИИ-нагрузками без неконтролируемого перегрева аккумуляторов в процессе работы. В батареях Tiamat используются уникальные химические процессы в сравнении с сопоставимыми натриевыми решениями. В течение последнего года они тестируются с реальными рабочими ИИ-нагрузками с сотнями тысяч циклов заряда/разряда. Партнёры планируют глобальное внедрение этих решений. 
Источник изображения: Tiamat Tiamat основана в 2017 году во Франции и её аккумуляторы, помимо прочего, будут использоваться в дата-центрах Edged, принадлежащей Endeavour. Поставки другим компаниям, в том числе гиперскейлерам, будут осуществляться при эксклюзивном посредничестве Endeavour. В Tiamat подчёркивают, что чрезвычайно довольны партнёрством. За последний год, как утверждают в компании, стало ясно, что такая технология АКБ — единственная, способная сегодня справиться со сложными требованиями, предъявленными инженерами Endeavour к уровню нагрузки и долговечности. 
Источник изображения: Tiamat Endeavour создана основателем Aligned Якобом Карнемарком (Jakob Carnemark). ЦОД-подразделение Edged имеет дата-центры, которые либо уже работают, либо находятся на стадии строительство в Бильбао, Мадриде и Барселоне (Испания), Лиссабоне (Португалия), а также в США (Миссури, Аризона, Техас, Джорджия, Огайо и Иллинойс). У Endeavour есть и другие перспективные разработки. Так, система безводного охлаждения ThermalWorks поддерживает до 70 кВт на стойку при воздушном охлаждении и до 200 кВт — при жидкостном. Партнёры не одиноки в своём стремлении использовать натриевые аккумуляторы. Около года назад появилась информация, что стартап Unigrid намерен наладить выпуск недорогих натрий-ионных аккумуляторов для ЦОД.
05.06.2025 [17:27], Руслан Авдеев
1 Тбит/с на 4,7 тыс. км: Nokia протестировала сверхбыструю квантово-защищённую сеть для ИИ-суперкомпьютеровNokia, финский центр CSC (Finnish IT Center for Science) и ассоциация образовательных и исследовательских учреждений Нидерландов SURF успешно испытали сверхбыструю (1,2 Тбит/с) квантово-безопасную магистраль передачи данных между Амстердамом и Каяани (Kajaani, Финляндия). Эксперимент направлен на подготовку инфраструктуры для HPC- и ИИ-систем, каналы связи которой защищены от взлома квантовыми компьютерами будущего, сообщает Converge. Испытание, проведённое в мае 2025 года, позволило установить связь по ВОЛС на расстоянии более 3,5 тыс. км, а длина одного из тестовых маршрутов через Норвегию составила 4,7 тыс. км (1 Тбит/с). Инициатива рассчитана на поддержку и развитие возможностей финского ИИ-суперкомпьютера LUMI-AI. Также речь идёт о поддержке будущих ИИ-фабрик (AI Factories), которым потребуются защищённые каналы со сверхвысокой пропускной способностью. Тестовый запуск включал передачу синтезированных и реальных исследовательских данных «с диска на диск» через пять исследовательских и образовательных сетей, включая SURF (Нидерланды), NORDUnet (преимущественно скандинавские страны), Sunet (Швеция), SIKT (Норвегия) и Funet (Финляндия). Эксперимент подтвердил возможность обработки огромных непрерывных потоков данных, необходимых для современных нагрузок, обучения и эксплуатации ИИ-моделей. 
Источник изображения: LUMI В сети использовали маршрутизаторы Nokia IP/MPLS с поддержкой FlexE (Flexible Ethernet) для гибкого разделения физических интерфейсов на логические каналы с гарантированной пропускной способностью и квантово-защищённой передачу данных. Новая веха свидетельствует о готовности европейской инфраструктуры к интенсивному использованию данных, в том числе пакетов климатической информации петабайтных объёмов, информации для обучения ИИ-моделей и т.д. Эксперимент также подтвердил возможность безопасных, дальних многодоменных передач между разными сетями или административными границами. Это насущная потребность для современных международных проектов, где данные нужно передавать через разные сети без ущерба производительности и безопасности. По словам финских исследователей, исследовательские сети проектируются с учётом потребностей будущего. В ЦОД CSC в Каяани уже размещен общеевропейский суперкомпьютер LUMI, а с реализацией подпроекта LUMI-AI и ввода других ИИ-фабрик EuroHPC наличие надёжной и масштабируемой системы связи Европе просто необходима.
04.06.2025 [01:00], Владимир Мироненко
Broadcom представила самые быстрые в мире Ethernet-коммутаторы Tomahawk 6: 102,4 Тбит/с на чип и 1,6 Тбит/с на портКомпания Broadcom объявила о старте поставок серии чипов-коммутаторов Tomahawk 6 (BCM78910), первых Ethernet-коммутаторов, обеспечивающий коммутационную способность 102,4 Тбит/с, что вдвое выше возможностей Ethernet-коммутаторов, доступных на рынке. Сообщается, что благодаря невероятной возможности масштабирования, энергоэффективности и оптимизированным для ИИ функциям Tomahawk 6 нацелен на использование в крупных ИИ-кластерах. В случае вертикального масштабирования (scale-up) новинка позволяет объединить до 512 XPU в один кластер. В двухуровневых горизонтально масштабируемых (scale-out) сетях Tomahawk 6 может объединить более 100 тыс. XPU со скоростью 200GbE на каждое подключение. В целом же решение позволяет объединить до 1 млн XPU. Tomahawk 6 предлагает SerDes-блоки 100G/200G PAM с поддержкой «дальнобойных» пассивных медных подключений. Есть и вариант с интегрированными оптическими интерфейсами (CPO), который обеспечивает более высокую энергоэффективность, более низкий уровень задержки, а также повышенную стабильность работы. 
Источник изображений: Broadcom Встроенная технология Cognitive Routing 2.0 автоматически выявляет перегрузки и перенаправляет потоки данных по альтернативным маршрутам, что помогает избежать узких мест в производительности. Cognitive Routing 2.0 в Tomahawk 6 включает расширенную телеметрию, динамический контроль перегрузки, быстрое обнаружение сбоев и обрезку пакетов, что обеспечивает глобальную балансировку нагрузки и адаптивное управление потоком. Эти возможности адаптированы для современных рабочих ИИ-нагрузок, включая MoE-модели, тонкую настройку, обучение с подкреплением и рассуждающие модели.  «Tomahawk 6 — это не просто обновление, это прорыв, — заявил Рам Велага (Ram Velaga), старший вице-президент и генеральный менеджер подразделения Core Switching Group компании Broadcom. — Он знаменует собой поворотный момент в проектировании ИИ-инфраструктуры, объединяя самую высокую пропускную способность, энергоэффективность и адаптивные функции маршрутизации для scale-up и scale-out сетей в одной платформе». Tomahawk 6 поддерживает как стандартные топологии, например, сеть Клоза или тор, так и сети на базе фреймворка Broadcom Scale-Up Ethernet (SUE). 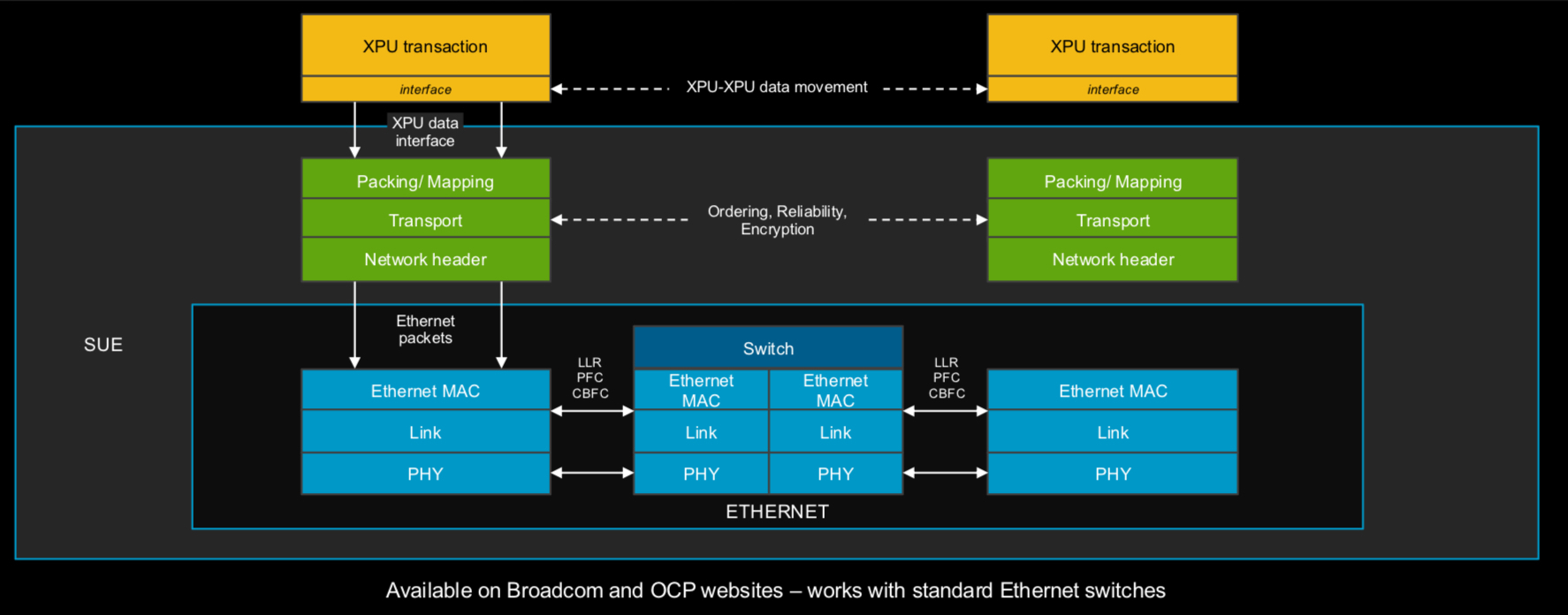 Компания отметила, что благодаря использованию 200G SerDes коммутатор обеспечивает самую большую дальность для пассивного медного соединения, что позволяет проектировать высокоэффективную систему с малой задержкой, высочайшей надежностью и самой низкой совокупной стоимостью владения (TCO). Возможные конфигурации портов: 64 × 1.6TbE, 128 × 800GbE, 256 × 400GbE, 512 × 200GbE. Но Tomahawk 6 предлагает и конфигурацию 1024 × 100GbE, т.е. высокоплотный и экономичный интерконнект на основе Ethernet. А поддержка CPO не просто избавляет от множества трансиверов, но и существенно сокращает связанные с ними перебои, что крайне важно для гиперскейлеров. 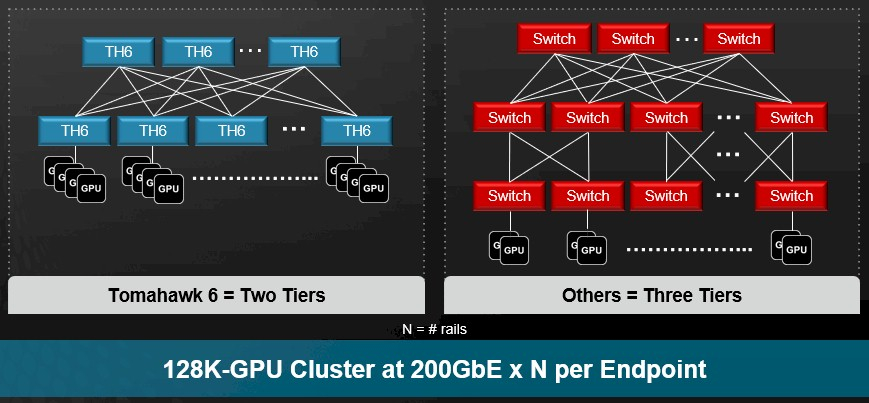 Использование Ethernet предоставляет операторам сетей значительные преимущества, позволяя им использовать единый технологический стек и согласованные инструменты во всей ИИ-инфраструктуре. Это также позволяет использовать взаимозаменяемые интерфейсы, с помощью которых облачные операторы могут динамически формировать кластеры XPU для различных рабочих нагрузок клиентов. Кроме того, Tomahawk 6 также соответствует требованиям Ultra Ethernet Consortium. |
|

