Материалы по тегу: ускоритель
|
28.10.2024 [15:19], Владимир Мироненко
Мало берёте: Дженсен Хуанг пожурил Европу за слабое развитие ИИ и похвалил Индию за закупки десятков тысяч ускорителейКак пишет Data Center Dynamics, генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) сообщил на саммите AI Summit в Мумбаи, что американская компания заключила серию партнёрских соглашений с индийскими фирмами для развёртывания своих чипов и технологий ИИ, расширяя присутсвие на ключевом для себя рынке. С некоторыми из фирм были заключены контракты на поставку десятков тысяч ускорителей H100, в частности, с Tata Communications и Yotta Data Services. Tata Communications модернизирует свою облачную ИИ-инфраструктуру в Индии. Компания начнёт первую фазу крупномасштабного развёртывания NVIDIA Hopper в конце этого года, а на фазе в 2025 году добавит к ним ускорители NVIDIA Blackwell. Как утверждает Tata Communications, её платформа будет одним из крупнейших ИИ-суперкомпьютеров в Индии. Yotta Data Services уже представила шесть новых ИИ-сервисов для своей платформы Shakti Cloud, в том числе на базе NVIDIA NIM. К ним относятся AI Lab, AI Workspace, Serverless AI Inferencing, GPUaaS и др. 
Источник изображения: NVIDIA NVIDIA также сотрудничает с крупнейшим в стране конгломератом Reliance Industries над созданием облачной ИИ-инфраструктуры для обработки данных, обучения сотрудников и создания собственных больших языковых моделей с поддержкой распространённых в стране языков. В рамках партнёрства Reliance развернёт суперускорители GB200. Tech Mahindra намерена использовать чипы и ПО NVIDIA для разработки ИИ-модели на хинди под названием Indus 2.0. Работа над этим проектом будет вестись в Центре передового опыта (Center of Excellence), базирующемся в лабораториях Tech Mahindra в Пуне и Хайдарабаде. На прошлой неделе Дженсен Хуанг также принял участие в церемонии запуска суверенного ИИ-суперкомпьютера Gefion. По данным ресурса The Register, в своём выступлении Хуанг отметил, что ЕС должен ускорить прогресс в области ИИ. «В каждой стране пробуждается понимание того, что данные — это национальный ресурс», — заявил гендиректор NVIDIA. Европейским странам необходимо больше инвестировать в ИИ, если они хотят сократить разрыв с США и Китаем, подчеркнул глава NVIDIA, подразумевая, что лучшим средством для этого будут ускорители его компании.
24.10.2024 [12:36], Сергей Карасёв
Raspberry Pi выпустила фирменные M.2 SSD и ИИ-модуль AI HAT+Компания Raspberry Pi представила под собственным брендом первые SSD и наборы SSD Kit для одноплатного компьютера Raspberry Pi 5. Дебютировали накопители в форм-факторе M.2 2230 вместимостью 256 и 512 Гбайт. На сайте Raspberry Pi говорится, что SSD используют интерфейс PCIe 3.0 (NVMe 1.4). Однако в описании самого мини-компьютера Raspberry Pi 5 упомянута только поддержка PCIe 2.0 x1 (для подключения периферии). Ресурс Tom's Hardware отмечает, что совместимость с PCIe 3.0 можно задать в настройках raspi-config, что позволит повысить скорость передачи данных. Для установки накопителей на Raspberry Pi 5 требуется модуль Raspberry Pi M.2 HAT+ (Hardware Attached on Top) с коннектором M.2: эта вспомогательная плата изначально включена в комплекты SSD Kit. В набор также входят соединительный шлейф и необходимый крепёж. В характеристиках SSD указан показатель IOPS (операций ввода-вывода в секунду) при работе с блоками данных по 4 Кбайт. У младшей версии он достигает 40 тыс. при произвольном чтении и 70 тыс. при произвольной записи, у старшей — 50 тыс. и 90 тыс. соответственно. Диапазон рабочих температур — от 0 до +70 °C. 
Источник изображений: Raspberry Pi Стоимость накопителя на 256 Гбайт составляет $30, на 512 Гбайт — $45. Комплекты с модулем Raspberry Pi M.2 HAT+ обойдутся в $40 и $55. Приём заказов уже начался. Производиться новинки будут минимум до января 2032 года.  Также компания представила обновлённый вариант ИИ-модуля для инференса — Raspberry Pi AI HAT+. От представленного ранее AI Kit новинка отличается тем, что теперь чип ускорителя интегрирован непосредственно на плату, а не подключается через M.2-коннектор. На выбор по-прежнему доступны чипы Hailo-8 (26 TOPS) и Hailo-8L (13 TOPS). Стоят модули с ними $110 и $70 соответственно. Диапазон рабочих температур — от 0 до +50 °C. Выпускаться модули будут минимум до января 2030 года.
23.10.2024 [16:57], Владимир Мироненко
NVIDIA переименовала будущие ИИ-ускорители Blackwell Ultra в B300Согласно данным аналитической компании TrendForce, NVIDIA решила переименовать продукты семейства Blackwell Ultra в серию B300. В связи с этим ускоритель B200 Ultra стал B300, а GB200 Ultra теперь называется GB300. Кроме того, B200A Ultra и GB200A Ultra получили имена B300A и GB300A соответственно. Серия ускорителей B300, как ожидается, выйдет в I–II квартале 2025 года, а поставки (G)B200 начнутся не позднее I квартал 2025 года. TrendForce отметила, что NVIDIA совершенствует сегментацию чипов Blackwell, чтобы лучше соответствовать требованиям по стоимости и производительности со стороны облачных провайдеров (CSP) и OEM-производителей серверов и смягчить требования к цепочкам поставок. Так, модель B300A нацелена на OEM-клиентов, её массовое производство планируется начать во II квартале 2025 года после пика поставок H200. Изначально NVIDIA хотела предложить данному сегменту упрощённый вариант B200A, но, судя по всему, спрос на него оказался более слабом, чем ожидалось. Вместе с тем переход с GB200A на GB300A для стоечных решений может привести к увеличению первоначальных затрат для корпоративных клиентов, что также может отразиться на спросе. 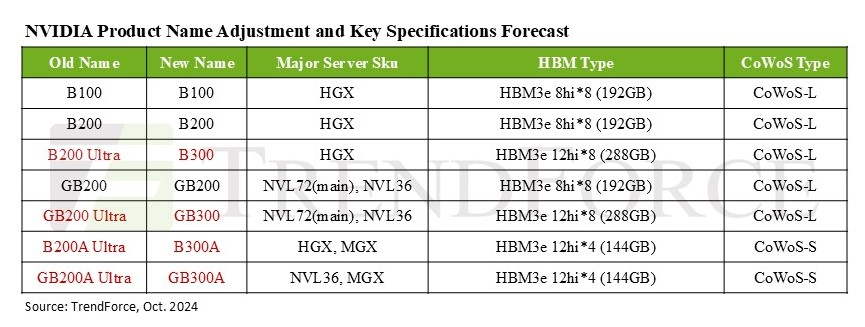
Источник изображения: TrendForce Сейчас компания вкладывает значительные средства в улучшение стоечных решений NVL, помогая поставщикам серверных систем с оптимизацией производительности и жидкостным охлаждением для систем NVL72, а AWS и Meta✴ настоятельно призывают перейти с NVL36 на NVL72. TrendForce также ожидает, что предложение топовых ускорителей NVIDIA будет расширяться, а их общая доля в поставках, как ожидается, достигнет около 50 % в 2024 году, то есть вырастет на 20 п.п. год к году. Ожидается, что выпуск ускорителей Blackwell увеличит этот показатель до 65 % в 2025 году. Аналитики также отметили роль NVIDIA в стимулировании спроса на технологию упаковки CoWoS. Благодаря Blackwell спрос на данный тип упаковки вырастет более чем на 10 п.п. в годовом исчислении. NVIDIA, скорее всего, сосредоточится на поставках чипов B300 и GB300 крупным североамериканским гиперскейлерам — оба варианта используют технологию CoWoS-L. Компания активно наращивает закупки HBM — согласно прогнозам, в 2025 году на NVIDIA придётся более 70 % мирового рынка HBM (рост на 10 п.п. год к году). TrendForce также отмечает, что все чипы серии B300 будут оснащены памятью HBM3e 12Hi, производство которой начнётся не позднее I квартал 2025 года. Но поскольку это будут первые массовые продукты с таким типом памяти, поставщикам, как ожидается, потребуется не менее двух кварталов для отработки процессов и стабилизации объёмов производства.
22.10.2024 [18:10], Руслан Авдеев
Индия и NVIDIA обсуждают совместную работу над ИИ-ускорителямиИндийское правительство ведёт переговоры с NVIDIA о возможности совместной разработки ИИ-чипов. Министр Ашвини Ваишнав (Ashwini Vaishnaw), отвечающий за электронику и IT в целом, заявил, что обсуждение находится на начальной стадии, не сообщив никаких деталей, передаёт The Register. В рамках новой стратегии страны приоритетным стало развитие ИИ-инфраструктуры, причём с опорой на собственные решения там, где это возможно. В частности, планируется построить суперкомпьютер с 10 тыс. ускорителей. Также выделены средства на аренду ускорителей для тех, кто не может их купить, а условия поддержки смягчили, дав возможность развиваться небольшим IT-провайдерам. При это страна готова закупать даже урезанные варианты ускорителей NVIDIA, которые из-за санкций не достались Китаю. С соседом у Индии отношения всё ухудшаются и ухудшаются, а некоторые крупные китайские игроки сами уходят из страны, а их место занимают западные и локальные компании. 
Источник изображения: Laurentiu Morariu/unsplash.com Индия давно стремится к развитию полупроводникового производства и намерена расширить своё влияние в этой сфере. Местные СМИ сообщают, что переговоры властей и NVIDIA якобы касаются разработки чипов, оптимизированных для некоторых сфер. Например, для обеспечения работы систем безопасности разветвлённой сети индийских железных дорог. У NVIDIA уже есть подобные решения на платформе Orin. Но выпуск даже такой платформы на территории Индии пока не представляется возможным, так что речь, вероятнее всего, идёт именно о сотрудничестве в сфере разработки.
20.10.2024 [11:09], Сергей Карасёв
AMD выпустила ускоритель для трейдеров Alveo UL3422 на базе FPGA Virtex UltraScale+ VU2PКомпания AMD анонсировала изделие Alveo UL3422: это, как утверждается, самый быстрый в мире однослотовый ускоритель половинной длины (FHHL) для брокерских и биржевых приложений. Новинка уже поставляется заказчикам из финансового сектора по всему миру. В устройстве применена FPGA Virtex UltraScale+ VU2P. Конфигурация включает 32 трансивера с ультранизкой задержкой, 787 тыс. LUT и 1680 DSP. В состав FPGA входят 256 Мбайт встроенной памяти — 76 Мбайт блочной RAM и 180 Мбайт UltraRAM. Заявленная задержка на уровне трансиверов составляет менее 3 нс. Карта использует интерфейс PCIe 4.0 x8 (коннектор x16). Заявленный показатель TDP равен 120 Вт; используется пассивное охлаждение. В оснащение входят 16 Гбайт памяти DDR4-2400. Предусмотрены два разъёма QSFP-DD (16×10/25G) и два коннектора ARF6. 
Источник изображения: AMD Ускоритель Alveo UL3422 может использоваться в комплексе с платформой разработки Vivado Design Suite. AMD также предоставляет клиентам среду разработки FINN с открытым исходным кодом и поддержкой сообщества, что позволяет интегрировать модели ИИ с низкими задержками в высокопроизводительные торговые системы. FINN использует PyTorch и методы квантования нейронных сетей. Ускоритель поставляется с набором референсных проектов и тестов производительности. Среди ключевых сфер применения новинки названы торговые операции со сверхнизкими задержками и анализ рисков.
20.10.2024 [11:01], Сергей Карасёв
NVIDIA передаст OCP спецификации компонентов суперускорителя GB200 NVL72Некоммерческая организация Open Compute Project Foundation (OCP), специализирующаяся на создании открытых спецификаций оборудования для ЦОД, сообщила о том, что для её инициативы Open Systems for AI собственные разработки предоставят NVIDIA и Meta✴. Проект Open Systems for AI был анонсирован в январе 2024 года при участии Intel, Microsoft, Google, Meta✴, NVIDIA, AMD, Arm, Ampere, Samsung, Seagate, SuperMicro, Dell и Broadcom. Цель инициативы заключается в разработке открытых стандартов для кластеров ИИ и дата-центров, в которых размещаются такие системы. Предполагается, что Open Systems for AI поможет повысить эффективность и устойчивость ИИ-платформ, а также обеспечит возможность формирования цепочек поставок оборудования от нескольких производителей. В рамках инициативы NVIDIA предоставит OCP спецификации элементы электромеханической конструкции суперускорителей GB200 NVL72, включая архитектуры стойки и жидкостного охлаждения, механические части вычислительного и коммутационного лотков. 
Источник изображения: NVIDIA Кроме того, NVIDIA расширит поддержку стандартов OCP в своей сетевой инфраструктуре Spectrum-X. Речь идёт об обеспечении совместимости со стандартами OCP Switch Abstraction Interface (SAI) и Software for Open Networking in the Cloud (SONiC). Это позволит клиентам использовать адаптивную маршрутизацию Spectrum-X и управление перегрузками на основе телеметрии для повышения производительности Ethernet-соединений в составе масштабируемой инфраструктуры ИИ. Адаптеры ConnectX-8 SuperNIC с поддержкой OCP 3.0 появятся в 2025 году. В свою очередь, Meta✴ передаст проекту Open Systems for AI свою архитектуру Catalina AI Rack, которая специально предназначена для создания ИИ-систем высокой плотности с поддержкой GB200. Это, как ожидается, позволит организации OCP «внедрять инновации, необходимые для создания более устойчивой экосистемы ИИ».
18.10.2024 [20:45], Игорь Осколков
Microsoft стремительно увеличила закупки суперускорителей NVIDIA GB200 NVLПо словам аналитика Минг-Чи Куо (Ming-Chi Kuo), Microsoft резко нарастила закупки суперускорителей NVIDIA GB200 NVL. Заказы на IV квартал текущего года выросли в три-четыре раза, а общий объём заказов Microsoft выше, чем у других облачных провайдеров. Поставщики ключевых компонентов для новых ИИ-платформ Microsoft начнут их массовое производство и отгрузку в IV квартале, что укрепит цепочку поставок компании. При этом компоненты будут отгружаться в независимости от того, смогут ли сборщики готовых платформ вовремя удовлетворить запросы Microsoft. Предполагается, что до конца года будет поставлено 150–200 тыс. чипов Blackwell, а в I квартале 2025 года поставки вырастут до 500–550 тыс. ед. И Microsoft готова закупать их. В дополнение к первоначальным заказам GB200 NVL36 (в основном для тестирования) Microsoft намерена получить кастомизированные суперускорители GB200 NVL72 до начала массового производства референсного варианта DGX GB200 NVL72 от самой NVIDIA (середина II квартала 2025 года). Заказы Microsoft на IV квартал выросли с изначальных 300–500 стоек (в основном NVL36) до примерно 1400–1500 стоек (около 70 % NVL72). Последующие заказы Microsoft будут сосредоточены преимущественно на NVL72. 
Источник изображения: X/@satyanadella Согласно опросам двух крупнейших сборщиков GB200 NVL, Foxconn и Quanta, заказы Microsoft в настоящее время, по-видимому, превышают общий объём заказов от других облачных провайдеров. Так, Amazon рассчитывает до конца года получить всего 300–400 стоек GB200 NVL36, а Meta✴ и вовсе ориентируется на платы Ariel, имеющие по одному чипу B200 и Grace, а не пару B200, как у «классических» плат Bianca. NVIDIA, по словам Минг-Чи Куо, решила отказаться от выпуска двухстоечной конфигурации GB200 NVL36×2. При этом NVIDIA, судя по всему, не удалось убедить Microsoft закупать полностью готовые NVL-стойки. На днях редмондский гигант показал свою реализацию суперускорителя GB200 NVL с огромным теплообменником. Первыми эти системы получат дата-центры Microsoft, расположенные в более холодном климате, например, на севере США, в Канаде, в Финляндии и т. д. Это позволит избежать проблем из-за недостатка времени на оптимизацию систем охлаждения ЦОД.
18.10.2024 [18:58], Руслан Авдеев
Google тоже показала собственный вариант суперускорителя NVIDIA GB200 NVLGoogle показала собственный вариант суперускорителя NVIDIA Blackwell GB200 NVL для своей облачной ИИ-платформы, передаёт Datacenter Dynamics. Решение Google отличается от вариантов Meta✴ и Microsoft, представленных ранее. Тем не менее, это показывает высокий интерес к новой ИИ-платформе NVIDIA со стороны гиперскейлеров. Google заявила о тесном сотрудничестве с NVIDIA для формирования «устойчивой вычислительной инфраструктуры будущего». 
Источник изображения: Google Подробнее о новой платформе будут рассказано на одной из будущих конференций Google. Пока что, увы, даже не до конца ясна конфигурация суперускорителя в исполнении Google. На фото видно сразу две стойки. Одна содержит неназванное количество ускорителей GB200, а вторая комплектуется оборудованием Google, в том числе блоками питания, коммутаторами и модулями охлаждения. Хотя NVIDIA рекомендует использовать в качестве интерконнекта InfiniBand в своих ИИ-платформах, некоторые эксперты считают, что Google пользуется собственными инфраструктурными наработками на базе Ethernet. Так, компания уже применяет оптические коммутаторы (OCS) собственной разработки в ИИ-кластерах с фирменными ускорителями TPU. Вариант Microsoft также состоит из двух стоек. Во второй смонтирован огромный теплообменник, который, вероятно, обслуживает не одну стойку с ускорителями, а сразу несколько. Известно, что ранее между Microsoft и NVIDIA были разногласия по поводу компоновки платформ для GB200. Наконец, вариант Meta✴ наиболее близок к оригинальной версии NVIDIA GB200 NVL72. При этом NVIDIA открыла её спецификации в рамках OCP. Ранее компания отказалась от выпуска «компромиссных» суперускорителей GB200 NVL36×2, которые сами по себе занимают две стойки.
11.10.2024 [19:55], Алексей Степин
256 Гбайт HBM3e — это хорошо, а 288 Гбайт — ещё лучше: AMD анонсировала ускорители Instinct MI325X и MI355XВчера компания AMD анонсировала серверные процессоры EPYC 9005 (Turin) и ускорители Instinct MI325X. Если верить AMD, новинки устанавливают новые эталоны производительности в своих сферах применения. О процессорах речь пойдёт в отдельном материале, а сейчас попробуем разобраться с Instinct MI325X — чем же именно он отличается от представленного ранее MI300X, архитектура которого в своё время была разобрана достаточно подробно. Сама AMD позиционирует MI325X в качестве наследника MI300X, способного конкурировать с NVIDIA H200 и, возможно, даже с B200. В сравнении с тем, что было опубликовано ранее, характеристики новинки несколько изменились. В частности, новый ускоритель получил 256 Гбайт памяти HBM3e, а не 288 Гбайт, как было обещано ранее. 
Источник здесь и далее: AMD via WCCFTech На приведённых слайдах с изображением кристалла MI325X отчетливо видно, что количество сборок HBM по-прежнему равно восьми, однако вместо ожидаемых сборок ёмкостью 36 Гбайт использованы менее ёмкие «стопки» на 32 Гбайт. Это не позволяет говорить о 50 % приросте по объёму, только о 33 %. Но и это немало! Пропускная способность подросла с 5,3 до 6 Тбайт/с.  Последнее может быть объяснено повышением тактовой частоты, но из-за тесной интеграции HBM3e с остальными частями ускорителя должна была вырасти и производительность. Тем не менее, AMD приводит же цифры, что и для MI300X —1,3 Пфлопс в режиме FP16 и 2,6 Пфлопс в режиме FP8. По сути, улучшены только характеристики подсистемы памяти.  Архитектурно MI325X полностью подобен предшественнику, за исключением блока HBM. Он по-прежнему базируется на CDNA 3, имеет такое же количество транзисторов (153 млрд) и производится с использованием тех же техпроцессов, 5 нм для блоков XCD и 6 нм для IOD. Но теплопакет превышает 750 Вт, в то время как у MI300X данный параметр не достигал столь высокого значения. 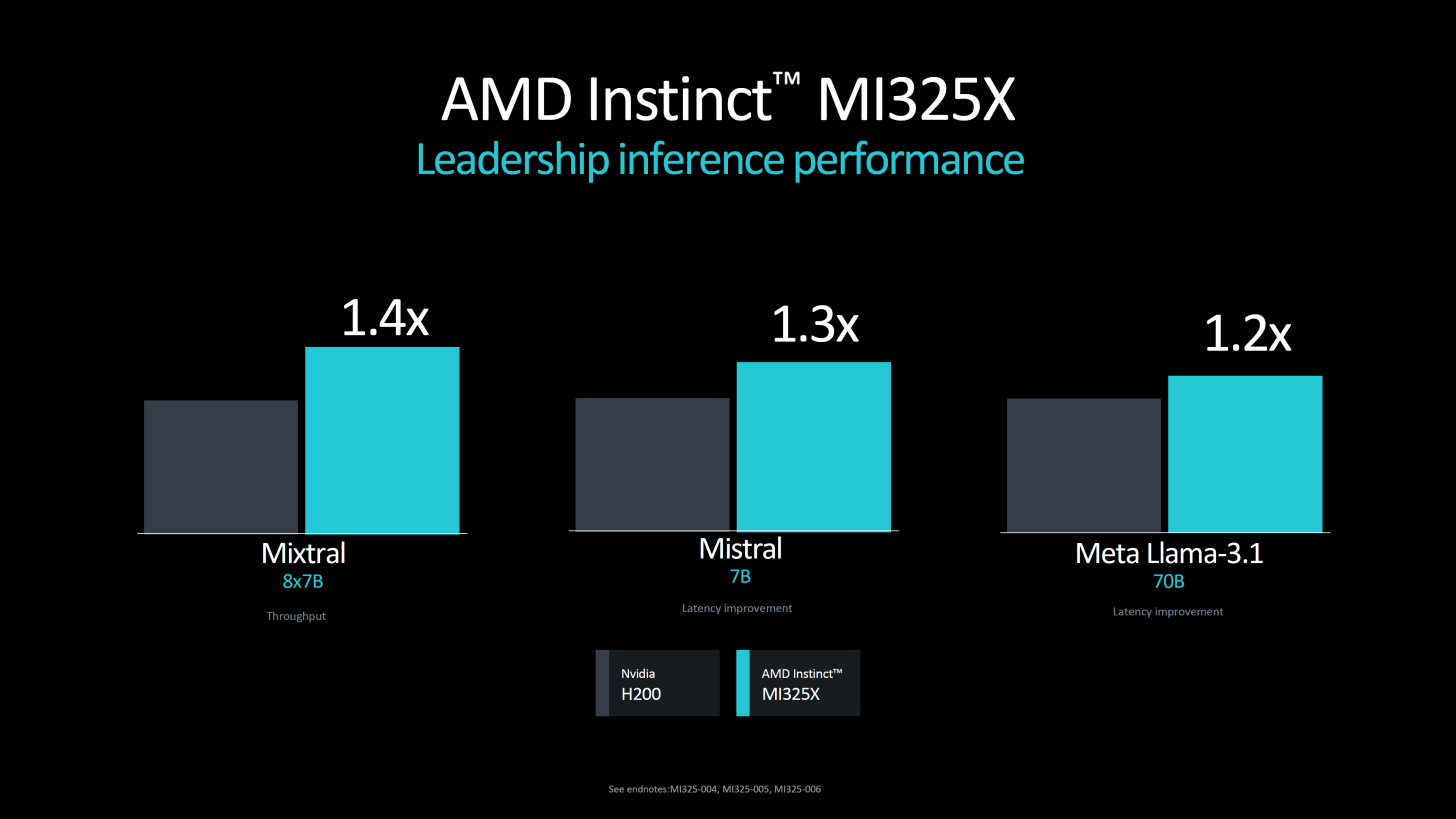 Ускорители подобного класса невозможно представить вне программной экосистемы. В настоящий момент AMD приводит данные о превосходстве MI325X над NVIDIA H200, варьирующемся в районе 20-40 % (в зависимости от нагрузки). Конечно, отчасти это заслуга памяти, но основной прирост заключается в оптимизации программной среды ROCm. По словам AMD, в задачах обучения и инференса производительность в версии 6.2 была увеличена более чем вдвое.  Для сравнения, в первых тестах MI300X в MLPerf Inference 4.1 отстал от NVIDIA H200 примерно на 50 %. Однако для полноты картины следует дождаться результатов тестов, проведённых сторонними источниками. Кроме того, H200 уже не самый совершенный ускоритель NVIDIA — в следующем году MI325X предстоит столкнуться с B200 на базе архитектуры Blackwell.  Ускорители Instinct MI325X будут доступны в I квартале 2025 года, но уже сейчас ясно, что усложнить жизнь своему главному конкуренту AMD в состоянии: так, вся обработка Llama 405B, используемой Meta✴, легла на плечи именно на MI300X. Активно используются решения AMD и в ЦОД Microsoft Azure.  Что касается следующего поколения ускорителей AMD Instinct MI355X, то оно намечено на II половину 2025 года. Оно получит обновлённую архитектуру CDNA 4, о которой пока нет никаких сведений, кроме упоминания о поддержке режимов FP6 и FP4. Вычислительные тайлы будут переведены на 3-нм техпроцесс, а их количество, как ожидается, возрастёт с 8 до 10. Тем не менее, роста тепловыделения избежать не удастся: заявлен теплопакет до 1000 Вт.  В Instinict MI355X получит дальнейшее развитие и подсистема памяти. Объём набортной HBM3e всё-таки достигнет 288 Гбайт, а пропускная способность вырастет с 6 до 8 Тбайт/с. Для связки из восьми MI355X AMD заявляет производительность в 18,5 Пфлопс в режиме FP16, что позволяет говорить о 2,31 Пфлопс для единственного ускорителя — то есть о примерно 80 % прироста в сравнении с MI325X.  Делать какие-либо далеко идущие выводы о решениях на базе CDNA 4 рано: вероятнее всего, даже лаборатории AMD ещё не располагают финальной версией MI355X, а кроме того, как уже понятно, огромную роль играет постоянно изменяющаяся и совершенствуемая программная среда, которая ко II половине 2025 года может претерпеть существенные изменения.  А вот гибридным решениям AMD планирует положить конец: преемника для Instinct MI300A, сочетающего в себе архитектуры CDNA 3 и Zen 4 не запланировано. Похоже, рынок для таких решений оказался слишком мал.
11.10.2024 [00:35], Владимир Мироненко
AMD представила серверные процессоры EPYC 9005 Turin и ускорители Instinct MI325XКомпания AMD представила ряд новых решений, включая серверные процессоры серии EPYC 9005 (Turin) и ускорители Instinct MI325X, которые, по словам компании, устанавливают новый стандарт производительности для ЦОД. Процессоры AMD EPYC 5-го поколения под кодовым названием Turin производятся с использованием техпроцесса 3 нм и 4 нм TSMC. Они предлагают тактовую частоту до 5,0 ГГц и от 8 до 192 ядер. AMD сообщила, что новая серия обеспечивает прирост показателя IPC на 17 % по сравнению с EPYC Genoa для корпоративных и облачных рабочих нагрузок и до 37 % в ИИ- и HPC-задачах по сравнению с Zen 4. Серия AMD EPYC 9005 включает 64-ядерный AMD EPYC 9575F, специально разработанный для ИИ-платформ на базе ускорителей, которым требуются максимальные возможности CPU. Турбочастота может достигать 5 ГГц, тогда как решение конкурента ограничено 3,8 ГГц — он до 28 % быстрее обрабатывает и передаёт данные ускорителям, что важно для требовательных рабочих нагрузок ИИ. 
Источник изображений: AMD В серии AMD EPYC 9005 доступны две версии чипов: 128-ядерная версия с классическими ядрами Zen5 и 192-ядерная версия с Zen5c. Оба варианта EPYC 9005 используют сокет SP5 и совместимы с некоторыми существующими платформами для Genoa (Zen4). Новинки поддерживают 12-канальную память DDR5-6400, а также предлагают полноценные обработку инструкций AVX-512 (целиком 512 бит за раз). 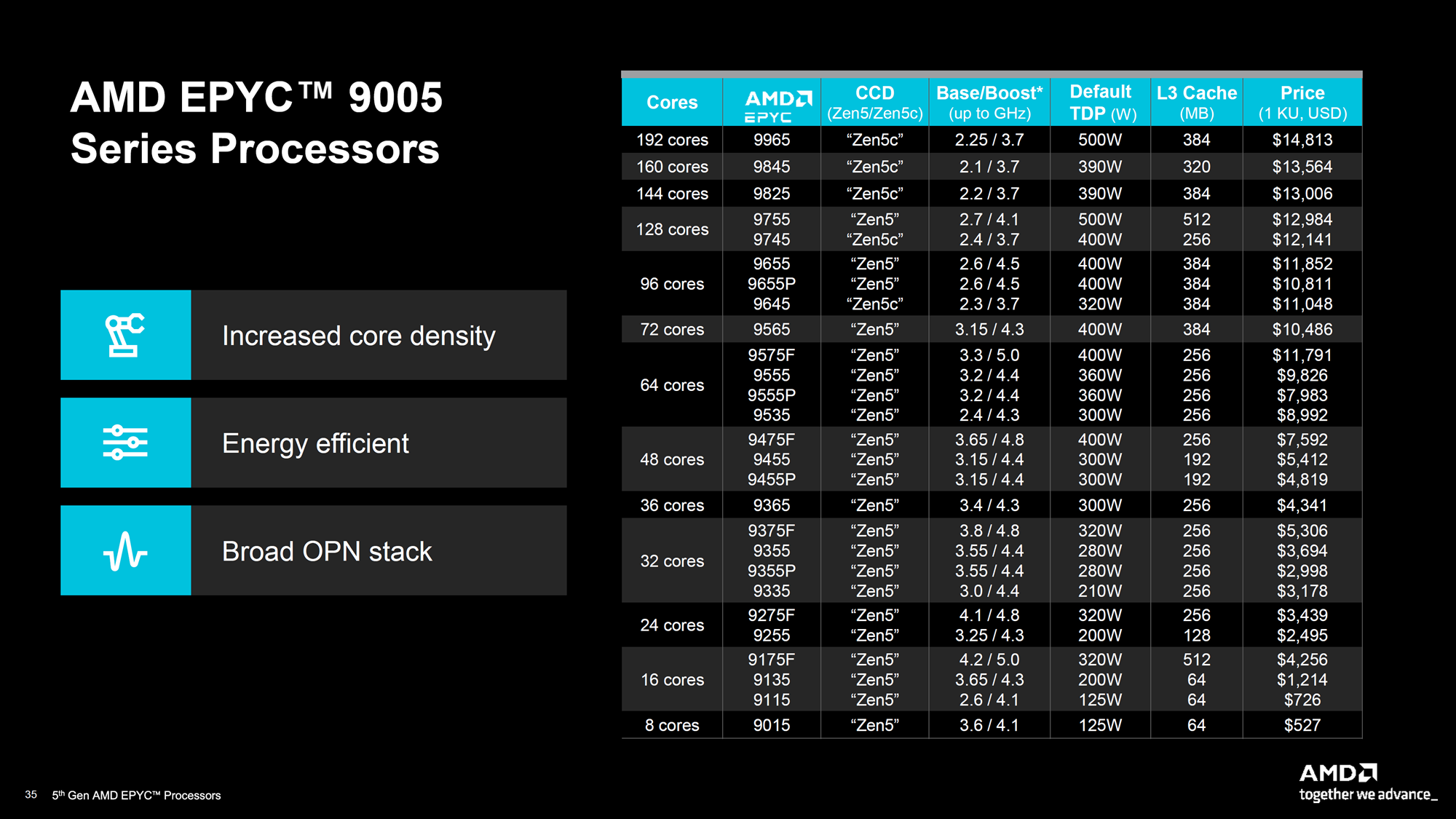 Как сообщает компания, флагманский процессор серии EPYC 9965 имеет 192 ядра Zen5c и тактовую частоту до 3,7 ГГц. Серверы на базе процессоров AMD EPYC 9965 обеспечивают по сравнению с серверами на базе процессоров Intel Xeon Platinum 8592+ (Emerald Rapids):
Также сообщается, что в сравнении с конкурентом 192-ядерный процессор EPYC 9965 обеспечивает до 3,7 раза большую производительность на end-to-end рабочих нагрузках ИИ, таких как TPCx-AI, которые имеют решающее значение для эффективного подхода к генеративному ИИ.  Что касается AMD Instinct MI325X, то новый ускоритель, построенный на архитектуре AMD CDNA 3, имеет 256 Гбайт памяти HBM3e с пропускной способностью 6,0 Тбайт/с, что соответственно в 1,8 и 1,3 раза больше, чем у NVIDIA H200. Ускоритель обеспечивает 2,6 Пфлопс производительности в режиме FP8, 1,3 Пфлопс производительности в режиме FP16.  Как утверждает AMD, по сравнению с H200 новый ускоритель в 1,3 раза быстрее в задачах инференса ИИ-модели Mistral 7B (FP16), в 1,2 раза — Llama 3.1 70B (FP8), в 1,4 раза — Mixtral 8x7B (FP16). Ускорители AMD Instinct MI325X будут доступны с I квартала 2025 года.  AMD также анонсировала следующее поколение ускорителей серии AMD Instinct MI350 на основе архитектуры AMD CDNA 4, разработанные для обеспечения 35-кратного улучшения производительности инференса по сравнению с ускорителями на базе AMD CDNA 3. Серия AMD Instinct MI350 получит до 288 Гбайт памяти HBM3e на ускоритель и поддержку форматов FP6/FP4. Новинка будет доступна во II половине 2025 года. |
|

