Материалы по тегу: ускоритель
|
20.11.2024 [01:40], Владимир Мироненко
Microsoft представила кастомные чипы Azure Boost DPU и Integrated HSM, уникальный AMD EPYC 9V64H с HBM и собственный вариант NVIDIA GB200 NVL72
amd
azure arc
azure stack
dpu
epyc
gb200
hardware
hbm
hpc
microsoft
microsoft azure
nvidia
гибридное облако
ии
информационная безопасность
облако
стойка
ускоритель
Microsoft представила на конференции Microsoft Ignite новые специализированные чипы Azure Boost DPU и Azure integrated Hardware Security Module (HSM), предназначенные для использования в ЦОД с целью поддержки рабочих нагрузок в облаке Azure и повышения безопасности. 
Источник изображений: Microsoft Чтобы снизить зависимость от поставок чипов сторонних компаний, Microsoft занимается разработкой собственных решений для ЦОД. Например, на прошлогодней конференции Microsoft Ignite компания представила Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100 собственной разработки. Azure Boost DPU включает специализированные ускорители для работы с сетью и хранилищем, а также предлагает функции безопасности. Так, скорость работы с хранилищем у будущих инстансов Azure будет вчетверо выше, чем у нынешних, а энергоэффективность при этом вырастет втрое.  Не вызывает сомнений, что в разработке Azure Boost DPU участвовали инженеры Fungible, производителя DPU, который Microsoft приобрела в декабре прошлого года. Как отмечает TechCrunch, в последние годы популярность DPU резко увеличилась. AWS разработала уже несколько поколений Nitro, Google совместно с Intel создала IPU, AMD предлагает DPU Pensando, а NVIDIA — BlueField. Есть и другие нишевые игроки. Согласно оценкам Allied Analytics, рынок чипов DPU может составить к 2031 году $5,5 млрд.  Ещё один кастомный чип — Azure integrated Hardware Security Module (HSM) — отвечает за хранение цифровых криптографических подписей и ключей шифрования в защищённом модуле «без ущерба для производительности или увеличения задержки». «Azure Integrated HSM будет устанавливаться на каждом новом сервере в ЦОД Microsoft, начиная со следующего года, чтобы повысить защиту всего парка оборудования Azure как для конфиденциальных, так и для общих рабочих нагрузок», — заявила Microsoft. Azure Integrated HSM работает со всем стеком Azure, обеспечивая сквозную безопасность и защиту.  Microsoft также объявила, что задействует ускорители NVIDIA Blackwell и кастомные серверные процессоры AMD EPYC. Так, инстансы Azure ND GB200 v6 будут использовать суперускорители NVIDIA GB200 NVL 72 в собственном исполнении Microsoft, а интерконнект Quantum InfiniBand позволит объединить десятки тысяч ускорителей Blackwell. Компания стремительно наращивает закупки этих систем. А инстансы Azure HBv5 получат уникальные 88-ядерные AMD EPYC 9V64H с памятью HBM, которые будут доступны только в облаке Azure. Каждый инстанс включает четыре таких CPU и до 450 Гбайт памяти с агрегированной пропускной способностью 6,9 Тбайт/с.  Кроме того, Microsoft анонсировала новое решение Azure Local, которое заменит семейство Azure Stack. Azure Local — это облачная гибридная инфраструктурная платформа, поддерживаемая Azure Arc, которая объединяет локальные среды с «большим» облаком Azure. По словам компании, клиенты получат обновление до Azure Local в автоматическом режиме. Наконец, Microsoft анонсировала новые возможности в Azure AI Foundry, новой «унифицированной» платформе приложений ИИ, где организации смогут проектировать, настраивать и управлять своими приложениями и агентами ИИ. В числе новых опций — Azure AI Foundry SDK (пока в виде превью).
18.11.2024 [21:30], Сергей Карасёв
Счетверённые H200 NVL и 5,5-кВт GB200 NVL4: NVIDIA представила новые ИИ-ускорителиКомпания NVIDIA анонсировала ускоритель H200 NVL, выполненный в виде двухслотовой карты расширения PCIe. Изделие, как утверждается, ориентировано на гибко конфигурируемые корпоративные системы с воздушным охлаждением для задач ИИ и НРС. Как и SXM-вариант NVIDIA H200, представленный ускоритель получил 141 Гбайт памяти HBM3e с пропускной способностью 4,8 Тбайт/с. При этом максимальный показатель TDP снижен с 700 до 600 Вт. Четыре карты могут быть объединены интерконнкетом NVIDIA NVLink с пропускной способностью до 900 Гбайт/с в расчёте на GPU. При этом к хост-системе ускорители подключаются посредством PCIe 5.0 x16. В один сервер можно установить две такие связки, что в сумме даст восемь ускорителей H200 NVL и 1126 Гбайт памяти HBM3e, что весьма существенно для рабочих нагрузок инференса. Заявленная производительность FP8 у карты H200 NVL достигает 3,34 Пфлопс против примерно 4 Пфлопс у SXM-версии. Быстродействие FP32 и FP64 равно соответственно 60 и 30 Тфлопс. Производительность INT8 — до 3,34 Пфлопс. Вместе с картами в комплект входит лицензия на программную платформа NVIDIA AI Enterprise. 
Источник изображения: NVIDIA Кроме того, NVIDIA анонсировала ускорители GB200 NVL4 с жидкостным охлаждением. Они включает два суперчипа Grace-Backwell, что даёт два 72-ядерных процессора Grace и четыре ускорителя B100. Объём памяти LPDDR5X ECC составляет 960 Гбайт, памяти HBM3e — 768 Гбайт. Задействован интерконнект NVlink-C2C с пропускной способностью до 900 Гбайт/с, при этом всем шесть чипов CPU-GPU находятся в одном домене. 
Источник изображения: NVIDIA Система GB200 NVL4 наделена двумя коннекторами M.2 22110/2280 для SSD с интерфейсом PCIe 5.0, восемью слотами для NVMe-накопителей E1.S (PCIe 5.0), шестью интерфейсами для карт FHFL PCIe 5.0 x16, портом USB, сетевым разъёмом RJ45 (IPMI) и интерфейсом Mini-DisplayPort. Устройство выполнено в форм-факторе 2U с размерами 440 × 88 × 900 мм, а его масса составляет 45 кг. TDP настраиваемый — от 2,75 кВт до 5,5 кВт.
11.11.2024 [19:03], Руслан Авдеев
Softbank животворящий: Graphcore активно нанимает персонал для разработки новых ИИ-решенийЧерез четыре месяца после покупки японским конгломератом SoftBank британский стартап Graphcore, разрабатывающий ИИ-ускорители, занялся наймом новых сотрудников. По данным EE Times, сейчас у компании открыто 75 позиций в сферах разработки и тестирования полупроводников, управления инфраструктурой ЦОД и ИИ-исследований. Всего год назад компания спешно искала финансирование и сокращала персонал. Сейчас штат Graphcore насчитывает 375 человек, но компания намерена увеличить количество сотрудников на 20 % в Великобритании, Польше и на Тайване. Прочие офисы, включая подразделение в Китае, закрылись. По словам главы Graphcore Найджела Туна (Nigel Toon), компания представляет собой место, где эксперты по полупроводникам, ПО, ИИ и т.п. могут и полностью реализовать себя. Тем не менее, производственные планы бизнеса пока не раскрываются. 
Источник изображения: Graphcore На момент покупки Graphcore имела в своём портфолио три поколения чипов. Однако последнее поколение Bow IPU, выпущенное в 2022 году, по большому счёту являлось апгрейдом продукта второго поколения от 2020 года. Модель имела 892 Мбайт набортной SRAM, дополненной внешней DDR-памятью, а не HBM. Другими словами, теоретически продукт не слишком подходит для обучения больших языковых моделей (LLM). Впрочем, Cerebras тоже использует SRAM в составе своих суперчипов, но последняя дополнена массивами гибридной памяти MemoryX. А SambaNova в SN40L в итоге пришла к сочетанию SRAM, HBM и DDR. Если Graphcore намерена создать новое поколение ИИ-ускорителей, то она, вероятно, пойдёт по пути SambaNova, считают в EE Times. На это косвенно указывает вакансия инженера ЦОД, для которой желателен опыт работы с жидкостным охлаждением. Также компании требуются специалисты для работы над облачными платформами и инфраструктурой ЦОД. Не исключено, что компания сменит бизнес-модель на манер Groq, продавая не ускорители, а доступ к ИИ-сервисам. Cerebras и SambaNova, например, уже успели по очереди похвастаться производительностью своих инференс-платформ. В случае Graphcore смещение фокуса на инференс открывает возможности для освоения корпоративных и суверенных ИИ-решений, которых ещё не было, когда последние чипы компании вышли на рынок. Тем не менее, пока нет данных, готов ли SoftBank обеспечить Graphcore достаточными средствами для развития больших ЦОД.
11.11.2024 [11:29], Сергей Карасёв
США запретили TSMC выпускать передовые чипы для китайских ИИ-компанийTSMC, по сообщению The Register, полностью прекратит выпуск передовых изделий для китайских заказчиков, которые занимаются разработкой аппаратных ИИ-решений, включая ускорители на базе GPU. Данная мера, как утверждается, продиктована необходимостью соблюдения экспортных требований США. Власти США последовательно вводят различные санкции, призванные ограничить возможности китайской полупроводниковой индустрии. Речь идёт о закупках чипов NVIDIA, памяти HBM и других компонентов. А нидерландской компании ASML запрещено поставлять в Китай оборудование для DUV-литографии, на котором можно изготавливать 5- и 7-нм продукцию. Теперь новые ограничительные меры в отношении клиентов из КНР вводит TSMC. Этот контрактный производитель объявил о том, что с 11 ноября 2024 года прекращает отгружать чипы, произведённые по 7-нм и более совершенным технологиям, китайским заказчикам, которые занимаются разработкой ИИ-устройств и GPU. Напомним, что в октябре TSMC уведомила американские власти о том, что некий китайский клиент, по всей видимости, пытается обойти экспортный контроль в отношении Huawei, размещая заказы на изделия, схожие с ИИ-ускорителем Ascend 910B. Это продукт был разработан Huawei в качестве альтернативы NVIDIA A100. Решение Ascend 910B представляет собой следующее поколение 7-нм чипа Ascend 910. По имеющейся информации, TSMC, следуя экспортным ограничения США, прекратила все поставки изделий этому неназванному клиенту. 
Источник изображения: TSMC Решение TSMC ограничит возможности китайских компаний по использованию технологий с нормами 7-нм и менее при создании ИИ-устройств. Вместе с тем, подчёркивается, что правила не распространяются на китайских клиентов, которые заказывают у TSMC 7-нм чипы для других приложений, таких как мобильные устройства и системы связи. Как отмечает TrendForce, решение TSMC «отражает осторожную позицию гиганта контрактного производства в глобальной цепочке поставок полупроводников на фоне разгорающейся войны в сфере микрочипов между двумя мировыми сверхдержавами».
04.11.2024 [17:05], Сергей Карасёв
NextSilicon представила самооптимизирующиеся ускорители вычислений Maverick-2Компания NextSilicon сообщила о разработке устройств Maverick-2 — так называемых интеллектуальных вычислительных ускорителей (Intelligent Compute Accelerator, ICA). Изделия, как утверждается, обеспечивают высокую производительность и эффективность при решении задач HPC и ИИ, а также при обслуживании векторных баз данных. NextSilicon разрабатывает новую вычислительную платформу для ресурсоёмких приложений. Применяются специальные программные алгоритмы для динамической реконфигурации оборудования на основе данных, получаемых непосредственно во время выполнения задачи. Это позволяет оптимизировать производительность и энергопотребление. 
Источник изображений: NextSilicon Maverick-2 ICA, по словам компании, представляет собой программно-определяемый аппаратный ускоритель. По заявлениям NextSilicon, изделие в плане производительности на один ватт затрачиваемой энергии более чем в четыре раза превосходит традиционные GPU, а в сравнении с топовыми CPU и вовсе достигается 20-кратное превосходство. При этом говорится об уменьшении эксплуатационных расходов более чем в два раза.  «Телеметрические данные, собранные во время работы приложения, используются интеллектуальными алгоритмами NextSilicon для непрерывной самооптимизации в реальном времени. Результатом являются эффективность и производительность в задачах HPC при сокращении потребления энергии на 50–80 % по сравнению с традиционными GPU», — заявляет компания. Решения Maverick-2 доступны в виде однокристальной карты расширения PCIe 5.0 x16 и двухкристального OAM-модуля. В первом случае объём памяти HBM3e составляет 96 Гбайт, энергопотребление — 300 Вт. У второго изделия эти показатели равны 192 Гбайт и 600 Вт. Тактовая частота в обоих вариантах — 1,5 ГГц. При производстве применяется 5-нм технология TSMC. Говорится о совместимости с популярными языками программирования и фреймворками, такими как C/C++, Fortran, OpenMP и Kokkos. Это позволяет многим приложениям работать без изменений, упрощая портирование и устраняя необходимость в проприетарном программном стеке.
03.11.2024 [13:15], Сергей Карасёв
Google объявила о доступности ИИ-ускорителей TPU v6 TrilliumКомпания Google сообщила о том, что её новейшие ИИ-ускорители TPU v6 с кодовым именем Trillium доступны клиентам для ознакомления в составе облачной платформы GCP. Утверждается, что на сегодняшний день новинка является самым эффективным решением Google по соотношению цена/производительность. Официальная презентация Trillium состоялась в мае нынешнего года. Изделие оснащено 32 Гбайт памяти HBM с пропускной способностью 1,6 Тбайт/с, а межчиповый интерконнект ICI обеспечивает возможность передачи данных со скоростью до 3,58 Тбит/с (по четыре порта на чип). Задействованы блоки SparseCore третьего поколения, предназначенные для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. 
Источник изображений: Google Google выделяет ряд существенных преимуществ Trillium (TPU v6e) перед ускорителями TPU v5e:
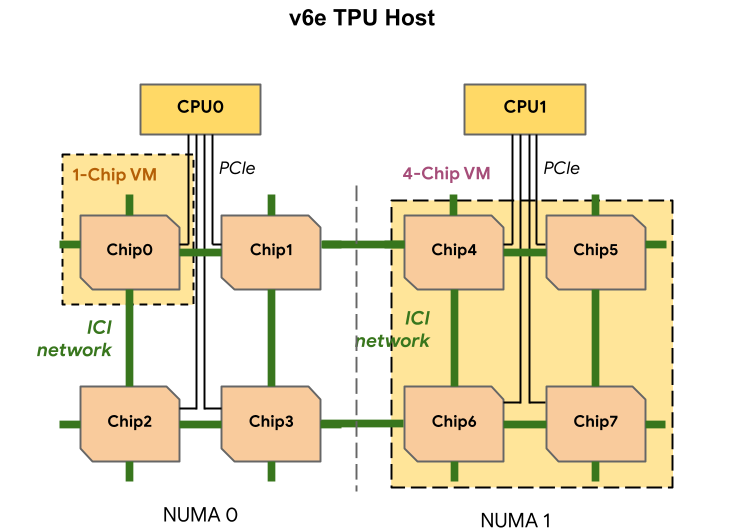 Один узел включает восемь ускорителей TPU v6e (в двух NUMA-доменах), два неназванных процессора (суммарно 180 vCPU), 1,44 Тбайт RAM и четыре 200G-адаптера (по два на CPU) для связи с внешним миром. Отмечается, что посредством ICI напрямую могут быть объединены до 256 изделий Trillium, а агрегированная скорость сетевого подключение такого кластера (Pod) составляет 25,6 Тбит/с. Десятки тысяч ускорителей могут быть связаны в масштабный ИИ-кластер благодаря платформе Google Jupiter с оптической коммутацией, совокупная пропускная способность которой достигает 13 Пбит/с. Trillium доступны в составе интегрированной ИИ-платформы AI Hypercomputer. 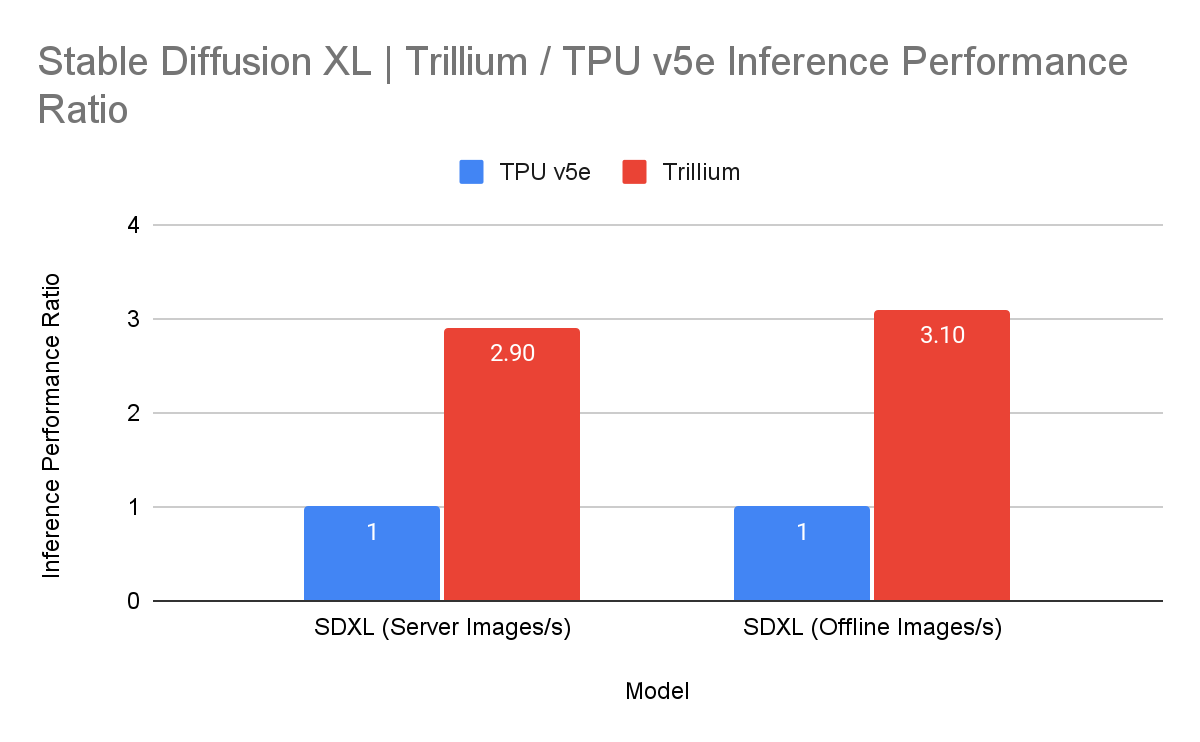 Заявляется, что благодаря ПО Multislice Trillium обеспечивается практически линейное масштабирование производительности для рабочих нагрузок, связанных с обучением ИИ. Производительность кластеров на базе Trillium может достигать 91 Эфлопс на ИИ-операциях: это в четыре раза больше по сравнению с самыми крупными развёртываниями систем на основе TPU v5p. BF16-производительность одного чипа TPU v6e составляет 918 Тфлопс, а INT8 — 1836 Топс. 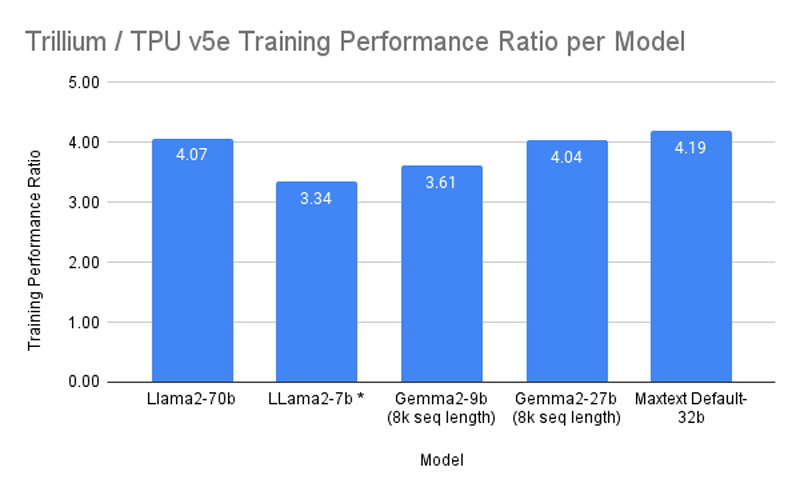 В бенчмарках Trillium по сравнению с TPU v5e показал более чем четырёхкратное увеличение производительности при обучении моделей Gemma 2-27b, MaxText Default-32b и Llama2-70B, а также более чем трёхкратный прирост для LLama2-7b и Gemma2-9b. Кроме того, Trillium обеспечивает трёхкратное увеличение производительности инференса для Stable Diffusion XL (по отношению к TPU v5e). По соотношению цена/производительность TPU v6e демонстрирует 1,8-кратный рост по сравнению с TPU v5e и примерно двукратный рост по сравнению с TPU v5p. Появится ли более производительная модификация TPU v6p, не уточняется.
02.11.2024 [14:06], Руслан Авдеев
Intel катастрофически отстала от NVIDIA и AMD по объёмам продаж ИИ-ускорителей, не продав Gaudi даже на $500 млнNVIDIA стала самым быстрорастущим производителем ИИ-ускорителей, своим успехом стимулируя работу AMD, тоже желающей воспользоваться высоким спросом на ИИ-решения. А вот у Intel, по данным The Verge, рассчитывавшей заработать $1–2 млрд в 2024 году на ИИ-ускорителях Gaudi, похоже, не выйдет получить и $500 млн. Об этом прямо заявил в ходе последнего отчёта года глава компании Пат Гэлсингер (Pat Galsinger). Хотя компания представила новейшие ускорители Gaudi3 в прошлом квартале, распространение Gaudi в целом было более медленным, чем ожидалось — на это повлиял переход с Gaudi2 на Gaudi 3 и специфика ПО. В 2025 году, как ожидается, поставки Gaudi3 тоже будут не столь велики, как планировалось ранее. Несмотря на то, что заявленных целей добиться не получится, компания «остаётся воодушевлена» рынком ИИ. Хотя Гелсингер не скрыл разочарования, по его словам, имеется очевидная необходимость в более выгодных с точки зрения TCO ИИ-решениях на основе открытых стандартов, так что Intel будет работать над дальнейшим улучшением Gaudi. 
Источник изображения: Intel Гелсингер также выразил недовольство огромными расходами индустрии на чипы, нацеленные на обучение моделей в облаках, сравнив такую «тренировку ИИ» с «созданием погодной модели без её использования». В его видении ИИ необходимо интегрировать вообще во все чипы, что может оказаться важным в долгосрочной перспективе. В прошлом квартале Intel анонсировала план снижения расходов на $10 млрд и увольнении более 15 тыс. человек. Также известно о структурных изменениях самого бизнеса, включая передачу подразделения, занятого edge-системами в Client Computing Group, которая вообще-то работает над решениями для настольных ПК и ноутбуков. Кроме того, предполагается интеграция команд разработчиков ПО в основные подразделения компании. По словам Гелсингера, Intel будет фокусировать внимание на меньшем числе проектов, главной задачей станет максимизация ценности x86-франшизы на рынках клиентских устройств, периферийных вычислений и центров обработки данных.
31.10.2024 [14:56], Владимир Мироненко
DIGITIMES Research: в 2024 году Google увеличит долю на рынке кастомных ИИ ASIC до 74 %Согласно отчету DIGITIMES Research, в 2024 году глобальные поставки ИИ ASIC собственной разработки для ЦОД, как ожидается, достигнут 3,45 млн единиц, а доля рынка Google вырастет до 74 %. Как сообщают аналитики Research, до конца года Google начнёт массовое производство нового поколения ИИ-ускорителей TPU v6 (Trillium), что ещё больше увеличит её присутствие на рынке. В 2023 году доля Google на рынке ИИ ASIC собственной разработки для ЦОД оценивалась в 71 %. В отчёте отмечено, что помимо самой высокой доли рынка, Google также является первым из трёх крупнейших сервис-провайдеров в мире, кто разработал собственные ИИ-ускорители. Первый TPU компания представила в 2016 году. Ожидается, что TPU v6 будет изготавливаться с применением 5-нм процесса TSMC, в основном с использованием 8-слойных чипов памяти HBM3 от Samsung. Также в отчёте сообщается, что Google интегрировала собственную архитектуру оптического интерконнекта в кластеры TPU v6, позиционируя себя в качестве лидера среди конкурирующих провайдеров облачных сервисов с точки зрения внедрения технологий и масштаба развёртывания. Google заменила традиционные spine-коммутаторы на полностью оптические коммутаторы Jupiter собственной разработки, которые позволяют значительно снизить энергопотребление и стоимость обслуживания ИИ-кластеров TPU POD по сравнению с решениями Broadcom или Mellanox. 
Источник изображения: cloud.google.com Кроме того, трансиверы Google получил ряд усовершенствований, значительно нарастив пропускную способность. Если в 2017 году речь шла о полнодуплексном 200G-решении, то в этом году речь идёт уже о 800G-решениях с возможностью модернизации до 1,6T. Скорость одного канала также существенно выросла — с 50G PAM4 в 2017 году до 200G PAM4 в 2024 году.
30.10.2024 [11:49], Сергей Карасёв
OpenAI разрабатывает собственные ИИ-чипы совместно с Broadcom и TSMC, а пока задействует AMD Instinct MI300XКомпания OpenAI, по информации Reuters, разрабатывает собственные чипы для обработки ИИ-задач. Партнёром в рамках данного проекта выступает Broadcom, а организовать производство изделий планируется на мощностях TSMC ориентировочно в 2026 году. Слухи о том, что OpenAI обсуждает с Broadcom возможность создания собственного ИИ-ускорителя, появились минувшим летом. Тогда говорилось, что эта инициатива является частью более масштабной программы OpenAI по увеличению вычислительных мощностей компании для разработки ИИ, преодолению дефицита ускорителей и снижению зависимости от NVIDIA. Как теперь стало известно, OpenAI уже несколько месяцев работает с Broadcom над своим первым чипом ИИ, ориентированным на задачи инференса. Соответствующая команда разработчиков насчитывает около 20 человек, включая специалистов, которые ранее принимали участие в проектировании ускорителей TPU в Google, в том числе Томаса Норри (Thomas Norrie) и Ричарда Хо (Richard Ho). Подробности о проекте не раскрываются. Reuters, ссылаясь на собственные источники, также сообщает, что OpenAI в дополнение к ИИ-ускорителям NVIDIA намерена взять на вооружение решения AMD, что позволит диверсифицировать поставки оборудования. Речь идёт о применении изделий Instinct MI300X, ресурсы которых будут использоваться через облачную платформу Microsoft Azure. 
Источник изображения: Unsplash Это позволит увеличить вычислительные мощности: компания OpenAI только в 2024 году намерена потратить на обучение ИИ-моделей и задачи инференса около $7 млрд. Вместе с тем, как отмечается, OpenAI пока отказалась от амбициозных планов по созданию собственного производства ИИ-чипов. Связано это с большими финансовыми и временными затратами, необходимыми для строительства предприятий.
28.10.2024 [23:24], Владимир Мироненко
Ускоритель для ускорителя: Fujitsu представила ПО, способное вдвое повысить скорость обработки ИИ-задачFujitsu объявила о доступности ПО (middleware), предназначенного для оптимизации использования ускорителей ИИ. Как указано в пресс-релизе, это решение позволяет повысить эффективность работы ускорителей, что особенно актуально в условиях дефицита вычислительных ресурсов такого типа. ПО различает код, для запуска которого требуется GPU, и тот, что может работать и с использованием одного только CPU, оптимизируя распределение ресурсов и управление памятью на различных платформах и в приложениях ИИ. Кроме того, ПО управляет приоритетностью запуска вычислений, отдавая предпочтение более эффективным процессам. Интересно, что распределение не использует традиционный подход, когда выбор ресурсов основывается на задаче целиком. 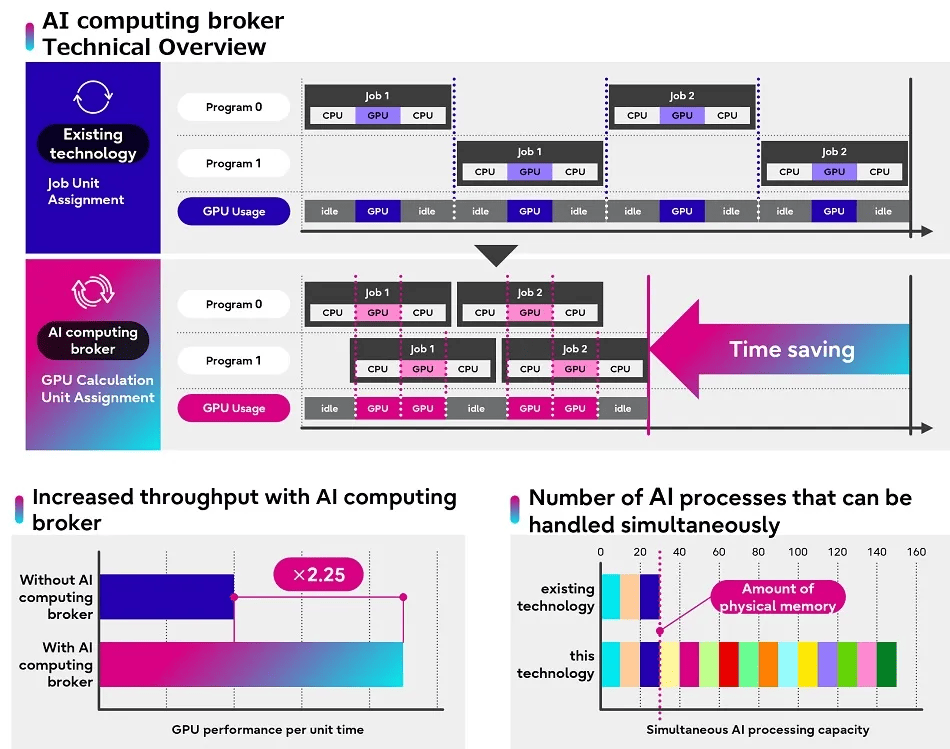
Источник изображения: Fujitsu Компания анонсировала решение (Adaptive GPU Allocator) в ноябре 2023 года. Тогда говорилось о необходимости использования фирменного фреймворка на базе TensorFlow и PyTorch. В нынешнем анонсе про это явно не говорится, но сообщается, что продукт объединяет технологию адаптивного распределения ресурсов каждого отдельного ускорителя с некой оптимизацией на базе ИИ. Более того, новинка позволяет эффективно обрабатывать даже те задачи, которые целиком в памяти ускорителя не помещаются. В ходе тестирования даже удалось наладить обработку 150 Гбайт ИИ-данных на GPU с приблизительно 30 Гбайт свободной RAM. Fujitsu заявила, что решение позволило увеличить в 2,25 раза эффективность ИИ-вычислений в ходе тестирования на реальных задачах компаний AWL, Xtreme-D и Morgenrot. А два крупных заказчика, Tradom и Sakura Internet, уже начали внедрять новый инструмент. «Решая проблемы нехватки ускорителей и энергии, вызванные растущим мировым спросом на ИИ, Fujitsu стремится внести свой вклад в повышение производительности бизнеса и креативности для своих клиентов», — заявила компания. Впрочем, пока решение способно ускорить только работу ускорителей в составе одного сервера, но компания работает над тем, чтобы она могла обслуживать множества GPU, установленных в нескольких серверах. Иными словам она не пока что позволит ускорить целый ИИ-кластер ускориться, но это всё равно удобный способ «выжать больше» из GPU-сервера, отметил ресурс The Register. |
|

