Материалы по тегу: обучение
|
16.06.2026 [12:28], Руслан Авдеев
Турция вложится в ИИ, ЦОД, облака и обучение в рамках программы AI Action PlanПрезидент Турции Реджеп Тайип Эрдоган (Recep Tayyip Erdoğan) анонсировал новую национальную программу развития ИИ в стране — AI Action Plan, сообщает Anadolu Agency (AA). В рамках нового плана Турция намерена привлечь не менее $10 млрд инвестиций, преимущественно частных, для развития индустрии ЦОД, облачных вычислений и ИИ-инфраструктуры. AI Action Plan держится на четырёх столпах: «изучать», «использовать», «создавать» и «управлять» ИИ. Каждое направление будет включать по четыре дополнительных комплекса мер. Выступая на мероприятии Türkiye Artificial Intelligence Summit в Стамбуле, Эрдоган заявил, что Турция намерена увеличить установленные мощности национальных ЦОД не менее чем до 1 ГВт уже к 2030 году. По словам президента страны, на проекты, связанные с ИИ-индустрией, будет направлено не менее 2 % средств, выделяемых в Турции в рамках государственных инвестиционных программ. 
Источник изображения: Enes Aktas/unsplash.com Также президент анонсировал планы обеспечить гражданам доступ минимум к 2 тыс. датасетов при посредничестве Национальной библиотеки данных (National Data Library). В том числе речь идёт о наборах данных о здравоохранении, сельском хозяйстве, обороне и электронной коммерции. В рамках нового плана Турция обучит 10 тыс. высококвалифицированных ИИ-специалистов и 100 тыс. профессионалов по внедрению и использованию ИИ-решений. Во всей 81 провинции страны стартуют программы обучения ИИ-навыкам, в течении двух лет они помогут обучить 5 млн граждан. Новая программа рассчитана на то, чтобы правильное понимание ИИ получили люди всех возрастов и смогли безопасно использовать его. Программы обучения ИИ весьма распространены в современном мире, правительства и отдельные корпорации активно вкладывают ресурсы в подготовку готовых к работе с искусственным интеллектом специалистов. Так, в апреле сообщалось, что японская NEC совместно при поддержке Anthropic займётся подготовкой ИИ-экспертов, в том же месяце появилась информация, что Meta✴ бесплатно обучит американцев работе с ВОЛС для ускоренного развёртывания своих ЦОД. В ноябре 2025 года сообщалось, что Google и Turkcell объединились для создания в Турции облачного региона и постройки первого ЦОД гиперскейл-класса.
28.04.2026 [15:15], Владимир Мироненко
NEC с помощью Anthropic создаст крупнейшую в Японии команду специалистов в области ИИ, хотя сами японцы скептически относятся к ИИЯпонская корпорация NEC объявила о стратегическом сотрудничестве с ИИ-стартапом Anthropic PBC с целью ускорения внедрения ИИ в корпоративном секторе страны. Как отмечено в пресс-релизе, NEC станет первым глобальным партнёром Anthropic, базирующимся в Японии. NEC и Anthropic будут совместно разрабатывать в рамках сотрудничества безопасные, специализированные продукты на основе ИИ для японских клиентов. Около 30 тыс. сотрудников NEC по всему миру будут использовать ИИ-модели Claude для разработки ПО с ИИ. На первом этапе совместная разработка будет сосредоточена на ИИ-решениях для таких секторов, как финансы, производство и местное самоуправление. NEC отметила, что уже использует передовые ИИ-технологии Anthropic в работе сервисов Центра оперативного управления безопасностью (SOC) для защиты цифровой инфраструктуры компаний, работающих как в Японии, так и по всему миру, от всё более сложных киберугроз. В дальнейшем корпорации планирует использовать новые разработки и опыт, накопленный в рамках сотрудничества, для создания новых предложений в сфере кибербезопасности нового поколения с использованием Claude. 
Источник изображения: Willian Justen de Vasconcellos / Unsplash Компании также интегрируют Claude, включая Claude Opus 4.7 и Claude Code, в платформу NEC BluStellar Scenario, которая объединяет консалтинг, ИИ-инструменты, безопасность и услуги цифровой инфраструктуры для бизнеса, начиная с предложений по управлению на основе данных и улучшению клиентского опыта, и постепенно расширяясь на другие области. Процесс интеграции NEC начнёт с использования Claude в двух сценариях из пакета BluStellar Scenario — «Сценарии для управления на основе данных» и «Сценарии для трансформации клиентского опыта» — и постепенно распространит её применение на другие сценарии. Совместные планы включают создание NEC Центра передового опыта (CoE) с целью подготовки высококвалифицированных специалистов по разработке с применением ИИ, используя техническую поддержку и обучение, предоставляемые Anthropic, с интеграцией Claude Code и других инструментов в повседневные рабочие процессы. Благодаря запуску центра NEC намерена создать одну из крупнейших в Японии команд инженеров, специализирующихся на ИИ. NEC применяет подход Client Zero (клиент-ноль) к выпуску продуктов, то есть её сотрудники сначала используют продукты во внутренних бизнес-операциях, прежде чем продавать их потенциальным клиентам. В рамках партнёрства NEC расширит использование Claude Cowork в своих внутренних бизнес-операциях для Client Zero. Использование ИИ-помощника, который частично автоматизирует задачи во многих областях, позволит повысить эффективность и сэкономить время. 
Источник изображения: Buddy AN / Unsplash «Это долгосрочное партнёрство с Anthropic позволит NEC максимально использовать потенциал ИИ на японском рынке, — заявил исполнительный директор и главный операционный директор NEC Corporation. — Вместе мы стремимся создавать решения, отвечающие высоким стандартам безопасности, надёжности и качества, которые требуются компаниям и государственным учреждениям в Японии». Хотя японские компании и государственный сектор стремятся продвигать ИИ-технологии, общественность относится к внедрению ИИ с осторожностью, сообщил ресурс Cybernews. По данным опросов SPF, отношение японской общественности к внедрению ИИ «поразительно пессимистично» по сравнению с другими странами — японцы не уверены в способности ИИ существенно улучшить их личную жизнь и японского общества в целом. Согласно отчёту Организации экономического сотрудничества и развития (OECD), скептицизм в отношении ИИ в Японии выше, чем в других странах Азии. Основные опасения жителей Японии включают массовую автоматизацию и потерю из-за этого рабочих мест, а также потерю доверия к властям, которые, по сути, предают свои принципы и сильно зависят от массового ИИ-производства, принадлежащего крупным транснациональным технологическим компаниям.
21.04.2026 [00:10], Владимир Мироненко
Meta✴ бесплатно обучит американцев работе с волоконно-оптическими сетями, чтобы побыстрее развернуть свои ИИ ЦОДMeta✴ объявила о запуске бесплатной четырёхнедельной программы LevelUp Fiber Technician Pathway по подготовке специалистов в сфере волоконно-оптических сетей, призванной восполнить критический дефицит квалифицированных кадров. Управлять реализацией многолетней инициативы будет CBRE, занимающаяся недвижимостью и услугами в сфере критической инфраструктуры. Ожидается, что первые специалисты начнут обучение этим летом. Кадры Meta✴ действительно нужны — на одни только оптоволоконные кабели Corning она потратит $6 млрд, и кто-то их должен проверить, проложить и подключить. Meta✴ отметила, что сфера специалистов по ВОЛС — и строительная отрасль в целом — сталкивается с общенациональным дефицитом в то время, когда спрос на ЦОД высок как никогда. Программа призвана помочь участникам получить необходимые технические навыки для успешной работы на востребованных должностях специалистов по ВОЛС как в строительной отрасли, так и в сфере ЦОД. После завершения обучения они получат возможность работать на строительных площадках компании в США через сеть её подрядчиков. Похожие программы есть у других гиперскейлеров. Например, Google в последнее время вкладывается в обучение электриков. 
Источник изображения: Meta✴ «Будущее революции в области ИИ зависит от высококвалифицированной рабочей силы в США — той, которая способна справиться с созданием и поддержанием сложных систем, обеспечивающих инновации. Meta✴ гордится тем, что инвестирует в обучение технических специалистов для поддержки наших амбициозных целей в области инфраструктуры», — заявила Meta✴. В настоящее время Meta✴ эксплуатирует или строит 27 ЦОД в США. С 2010 года эти проекты обеспечили более 30 тыс. рабочих мест для квалифицированных специалистов на время строительства и более 5 тыс. постоянных рабочих мест.
19.02.2026 [15:57], Руслан Авдеев
Microsoft бросилась исправлять ИИ-неравенство в мире и выделила на это $50 млрдНа недавнем мероприятии India AI Impact Summit представители Microsoft объявили, что компания готовится инвестировать к концу десятилетия $50 млрд для того, чтобы обеспечить доступ к ИИ странам Глобального Юга. Технологии искусственного интеллекта стремительно распространяются, но чрезвычайно неравномерно в мировом масштабе. В докладе Microsoft AI Diffusion Report утверждается, что в странах Глобального Севера ИИ используется вдвое активнее, чем на юге, и неравенство продолжает увеличиваться. Это сказывается не только на национальном и региональном экономическом росте, но и перспективах развития. Более века неравный доступ к электроэнергии увеличивал экономический разрыв между Глобальным Севером и Югом. С ИИ может произойти аналогичная история. Потребности в новых технологиях требуют существенных инвестиций и больших усилий правительств, частного сектора и НКО. Выделенные Microsoft $50 млрд призваны поддержать новые возможности в странах Глобального Юга. Программа развития ИИ состоит из пяти элементов:

Источник изображения: Chastagner Thierry/unsplash.com Инфраструктура жизненно необходима для распространения ИИ, говорит компания. ИИ требует энергии, каналов связи, вычислительных мощностей. Только в последнем финансовом году Microsoft инвестировала более $8 млрд в инфраструктуру ЦОД, обслуживающую Глобальный Юг, включая Индию, Мексику, страны Африки, Южной Америки, Юго-Восточной Азии и Ближнего Востока. В первую очередь компания стремится расширить доступ в интернет 250 млн человек в макрорегионе. Microsoft заявила, что уже помогла получить доступ в интернет 117 млн человек в Африке. Инвестиции в ИИ-инфраструктуру осуществляются с учётом необходимости обеспечения местного суверенитета, хотя не так давно компания объявила, что не может обеспечить суверенитет данных в Европе из-за особенностей американского законодательства. Microsoft заявила о создании суверенного управления в публичных облаках, частных суверенных предложениях и тесном сотрудничестве с национальными партнёрами на местах. Утверждается, что в эру ИИ вся информация остаётся в руках клиентов под их полным контролем, без передачи сторонним провайдерам. При этом Глобальный Юг требует огромных инвестиций в инфраструктуру ЦОД, энергетику и связь, что крайне затруднительно без зарубежных инвестиций, в том числе со стороны техногигантов. В числе прочего для удовлетворения этих потребностей было сформировано партнёрство Trusted Tech Alliance, объединяющее 16 ведущих технологических компаний из 11 стран с четырёх континентов. 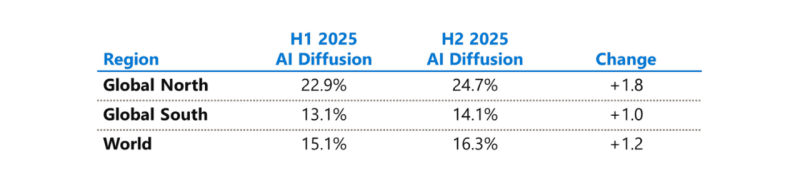
Источник изображения: Microsoft Однако ЦОД и интернет-каналы — лишь часть необходимой инфраструктуры. Не меньшее значение имеет доступ к технологиям для школ, университетов и НКО и цифровым компетенциям. В предыдущем финансовом году Microsoft инвестировала в программы для государств Глобального Юга $2 млрд, включая гранты, пожертвования, льготы и обучающие программы. В 2025 году компания запустила инициативу Microsoft Elevate, призванную к 2028 году подготовить 20 млн дипломированных специалистов с востребованными ИИ-компетенциями. В Индии компания обучила уже 5,6 млн человек, а к 2030 году намерена довести это число до 20 млн. Компания подготовит 2 млн учителей из более 200 тыс. школ и вузов, а также оснастит 25 тыс. учебных учреждений ИИ-инфраструктурой. Ещё одно направление — создание и доработка ИИ-моделей на местных языках, поскольку локальные решения пока что хуже, чем решения на английском языке. Microsoft поддержала инвестиции в инициативу LINGUA Africa (выделено $5,5 млн) по сбору языковых данных и развитие моделей для африканских языков. Дополнительно совершенствуется бенчмарк MLCommons AILuminate для индийских и азиатских языков для оценки безопасности ИИ вне англоязычной среды. 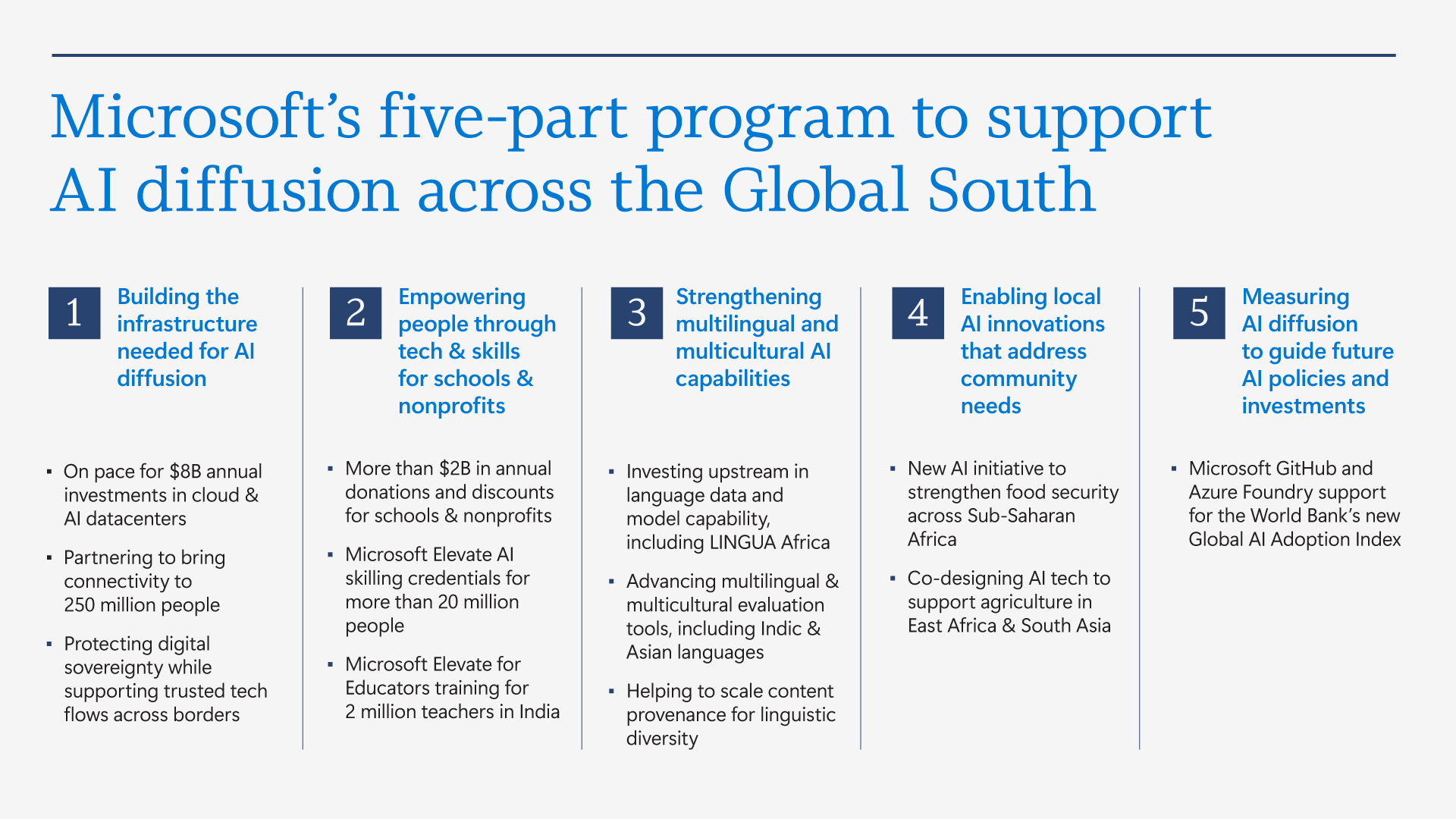
Источник изображения: Microsoft Совместно с образовательными и коммерческими структурами из Индии, Японии, Кореи и Сингапура при участии Microsoft создаётся мультиязычная и мультимодальная подборка из 7 тыс. высококачественных промптов для хинди, тамильского, малайского, японского и корейского языков. Также Microsoft развивает метод Samiksha для учёта локальных языковых и культурных контекстов. Samiksha позволяет выявлять сбои, которые часто упускаются «англоцентричными» методами оценки. В Африке компания совместно с NASA, властями и др. организациями будет применять ИИ к спутниковым данным для анализа продовольственной ситуации. Технология уже отработана в Индии. В рамках Project Gecko компания развивает ИИ-технологии совместно с сообществами в Восточной Африке и Южной Азии для поддержки с/х. В том числе речь идёт о семействе моделей для распознавания речи Paza, способных работать на мобильных устройствах с шестью кенийскими языками. Ведутся работы над многоязыковыми инструментами Copilot, Multimodal Critical Thinking (MMCT) Agent для анализа видео с учётом голоса и текста, адаптацией LLM к низкоресурсным языкам (в т.ч. чичева, инуктитут, маори) и т.д. 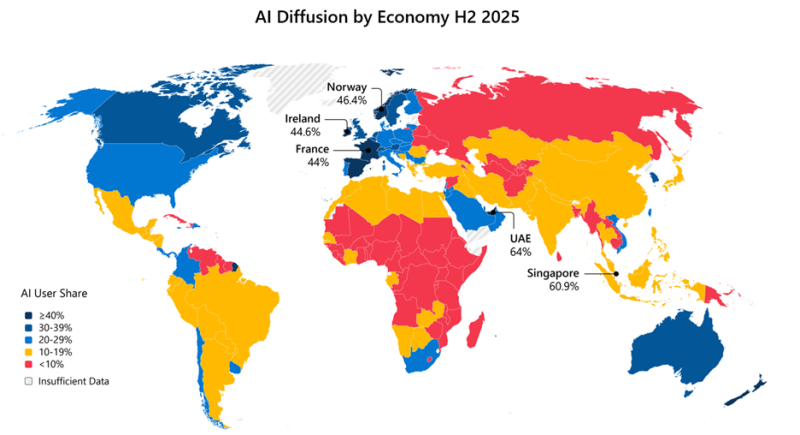
Источник изображения: Microsoft Для ускоренного внедрения ИИ нужно понимать, где и как применяется ИИ, с каким недостатками приходится сталкиваться разработчикам, говорит Microsoft. На основе статистики публичных репозиториев GitHub и метрик Azure Foundry компания участвует в создании «рейтинга» Global AI Adoption Index Всемирного Банка. Например, индийское сообщество из 24 млн разработчиков — второе по величине на GitHub и самое быстрорастущее среди 30 ведущих экономик. С 2020 года ежегодный прирост составляет более 26 %, в 2025 году он составил более 36 %. Индийские специалисты занимают второе место в мире по вкладу в open source, использованию GitHub Education, по вкладу в публичные ИИ-проекты и др. Такие данные помогают точнее направлять инвестиции в инфраструктурные проекты, языковые технологии и на обучение. Поддержка подобных метрик помогает измерять достигнутый прогресс. Microsoft подчёркивает, что компания акцентирует внимание в вопросах внедрения ИИ на необходимости создания доступной инфраструктуры, надёжно работающих в реальном мире системах, а также технологиях, которые могут применяться с учётом местных условий. Для этого компания намерена работать с партнёрами, включая обмен данными для оценки прогресса.
04.02.2026 [15:00], Руслан Авдеев
Барнсли станет первым ИИ-городом в ВеликобританииРасположенный в Южном Йоркшире (Великобритания) Барнсли, ранее известный добычей угля и стекольным производством, станет первым в стране «технологическим городом» (Tech Town). Он будет внедрять ИИ во все сферы жизнедеятельности — от местного бизнеса до государственных услуг, сообщает The Register. Как объявило Министерство науки, инноваций и технологий (DSIT), Барнсли станет примером для всей Великобритании в деле внедрения ИИ-технологий. В DSIT утверждают, что жители городка смогут увидеть повышение качества государственных услуг, более эффективную поддержку местных школ, более быстрый доступ к медицинской помощи, а также новые возможности для трудоустройства и повышения квалификации. В министерстве подчёркивают, что на примере Барнсли намерены показать, что ИИ помогает учиться, оказывает поддержку местному бизнесу и способствует повышению качества госуслуг. На этом примере можно будет продемонстрировать, сколь полезен искусственный интеллект для всей страны. В рамках новой программы жителям города будут предоставлять бесплатное обучение в сфере ИИ и цифровых технологий в местных учебных заведениях. Дополнительно запланировано тестирование в школах и городском колледже образовательных технологий для сбора данных об их влиянии на обучение и о том, смогут ли они снизить нагрузку на местный педагогический состав. 
Источник изображения: Jamie Street/unsplash.com Действующая недалеко от центра города площадка Seam Digital Campus расширяется для оказания поддержки малому бизнесу при внедрении и масштабировании новых технологий. Городской совет в рамках программы получит стартовое финансирование £500 тыс. ($683 тыс.). В числе присоединившихся к программе компаний есть Microsoft и Cisco, уделяющие, с их слов, «особое внимание» обучению ИИ-навыкам взрослых и поддержке малых и средних предприятий. Впрочем, к середине прошлого года Microsoft, не в последнюю очередь благодаря внедрению ИИ, сократила 15 тыс. сотрудников, а эксперимент по использованию ИИ британскими госслужащими в Microsoft 365 и Office 365 в целом провалился, поскольку Copilot заметного роста производительности не дал. Cisco тоже сократила около 6 тыс. человек в рамках реструктуризации с переходом на ИИ-инструменты. В целом в компаниях, внедряющих ИИ, отмечается сокращение рабочих мест, поэтому польза для жителей Барнсли не вполне очевидна. DSIT отказалось дать СМИ прямые гарантии, что повсеместное внедрение искусственного интеллекта в городе не приведёт к потере рабочих мест. Остаются без ответа и другие вопросы, включая этические нормы применения ИИ в здравоохранении или образовании. А представители городского совета заявили, что одна из ключевых задач стратегии инклюзивного экономического роста — сделать Барнсли ведущим цифровым городом Великобритании. Сегодня речь идёт об «одной из важнейших инвестиций в город за всю его историю». 
Источник изображения: Maria Ilves/unsplash.com Уголь в городе больше не добывают, последние шахты там закрыли в начале 1990х гг., и масштабного появления вакансий не предвидится. По данным TechMarketView, отведённые для модернизации здравоохранения, образования и поддержки бизнеса 18 мес. могут означать, что ресурсы будут слишком сильно «распылены», что помешает добиться подлинных изменений в любой из областей. Кроме того, существует проблема доверия. Организации государственного сектора неоднократно вкладывали значительные ресурсы в технологические проекты, не получив взамен ожидаемой отдачи, поэтому на предложение о реализации очередного проекта они могут сослаться на отсутствие ресурсов, просто не желая тратить их без гарантий окупаемости. Если же медицинские учреждения, школы и др. не смогут выделить ресурсы, трансформация застопорится независимо от того, какие технологии предлагаются. TechMarketView подчёркивает, что если Барнсли не сможет добиться ощутимых успехов, это не просто помешает внедрению программы, но и вызовет скептическое отношение к инвестициям в ИИ у других регионов. Усугубляет риск отсутствие чётких показателей успеха — в условиях, когда население заинтересовано устранением выбоин на дорогах и своевременным вывозом мусора, объявление Барнсли «технологическим городом» может показаться жителям лишь отвлекающим манёвром. Внедрение новых цифровых технологий не всегда проходит успешно, в том числе в Великобритании. Так, рутинная на первый взгляд задача по смене ERP-системы в муниципалитете Бирмингема обернулась для местных властей настоящим кошмаром с катастрофическими затратами и задержками.
27.01.2026 [09:09], Руслан Авдеев
Сингапур потратит S$1 млрд на то, чтобы остаться в авангарде ИИ-прогрессаСингапур намерен потратить свыше S$1 млрд ($786 млн) на финансирование Национального плана исследований и разработок в области ИИ (NAIRD) для укрепления государственного потенциала в соответствующей сфере. По данным местного Министерства цифрового развития и информации (MDDI), финансирование будет осуществляться с 2025 по 2030 гг., сообщает Channel News Asia. Анонсированный главой MDDI Джозефин Тео (Josephine Teo) план призван поддержать укрепление амбиций страны в сфере ИИ в рамках обновлённой национальной стратегии National AI Strategy (NAIS) 2.0. В 2019 году появилась первая национальная стратегия Сингапура в сфере искусственного интеллекта, в рамках которой страна начала реализацию ИИ-проектов в области образования, здравоохранения, логистики, безопасности и др. NAIS 2.0 анонсировали в 2023 году, тогда ставилась цель более чем втрое нарастить количество специалистов в сфере ИИ (до 15 тыс. человек) и помочь Сингапуру стать лучшим регионом для ИИ-разработчиков. Нынешние инвестиции в объёме S$1 млрд — часть общих вложений Национального исследовательского фонда (NRF) Сингапура в объёме S$37 млрд в технологическое развитие страны, объявленных в декабре 2025 года. S$28 млрд на те же цели выделили годом ранее. План NAIRD предусматривает приоритетное развитие трёх направлений: фундаментальных исследований в сфере ИИ, прикладных исследований в той же области, а также поиск талантов для реализации национальной ИИ-стратегии. 
Источник изображения: Hu Chen/unsplash.com Для этого Сингапур построит центры исследований в сфере ИИ, в которых будут работать не только местные, но и зарубежные специалисты. По словам Тео, центры будут работать над решением долгосрочных, сложных задач. В частности, речь идёт об исследованиях и разработках в областях защиты от рисков, связанных с внедрением ИИ, и защитой от злоупотреблений такими системами. Центры будут работать и над широким кругом других смежных проблем, например, над разработкой многоцелевого искусственного интеллекта, способного решать задачи в разных сферах. В прикладной сфере новый план предусматривает укрепление потенциала для поддержки внедрения ИИ в промышленности, а также поддержку инициатив, выдвинутых исследовательскими, инновационными и корпоративными структурами. По словам властей, новый план также ориентирован на обучение «двуязычных» исследователей, владеющих и навыками в сфере ИИ, и одновременно являющихся экспертами в какой-либо области. Также Сингапур намерен создать условия для перехода от теории к практике, превращения исследования в прикладные продукты. 
Источник изображения: Swapnil Bapat/unspalsh.com Планируется и дальше поддерживать инициативы, направленные на поддержку интереса к ИИ-исследованиям среди молодёжи. На уровне высшего образования студентам предоставят возможность взаимодействия с ведущими научно-исследовательскими учреждениями локально и за рубежом, с расширением стипендиальных программ. Создаются и условия для поддержки преподавателей, в т.ч. речь идёт о программе приглашенных профессоров AI Visiting Professorship для обеспечения сотрудничества между местными и международными исследователями. Параллельно привлекаются и ведущие стартапы и ИИ-компании для размещения своих исследовательских команд в Сингапуре. В MDDI заявляют, что исследования в области ИИ позволят Сингапуру оставаться в авангарде в данной сфере. В 2025 году Сингапур занимал третье место в глобальном рейтинге ИИ-исследований издания The Observer, с ранжированием стран по уровню инвестиций, инноваций и внедрения ИИ. Страна уступает только США и Китаю. В последнее время в Сингапуре всё больше компаний, открывших собственные исследовательские лаборатории, включая Microsoft Research Asia и Google DeepMind. Одна из главных проблем Сингапура — острая нехватка свободной энергии и земли для ИИ ЦОД. Поэтому конкуренты не дремлют, и соседняя Малайзия уже недвусмысленно выражала желание стать главным IT-хабом региона. Собственные амбиции того же рода в регионе имеют Индонезия и Вьетнам. Попутно Сингапур всё чаще подозревают в помощи китайским компаниям в обходе санкций США.
22.01.2026 [17:40], Руслан Авдеев
OpenAI представила программу Stargate Community для налаживания добрососедских отношений с местными жителямиКомпания OpenAI, объявившая о намерении создать «общий искусственный интеллект» (AGI) на благо всего человечества, намерена организовать работу таким образом, чтобы в ходе достижения этой цели её кампусы приносили пользу местным жителям. С этой целью компания представила программу Stargate Community, способствующую развитию экономики и созданию рабочих мест в регионах присутствия. В рамках инициативы Stargate компания задалась целью нарастить инфраструктуру ИИ в США до 10 ГВт к 2029 году. Первый объект в Абилине (Abilene, Техас) уже работает, новые объекты строятся по всей стране. С момента запуска в январе 2025 года, партнёры по Stargate анонсировали несколько проектов большой мощности по всему миру. В сентябре были анонсированы планы построить пять кампусов ЦОД в Техасе, Нью-Мексико, Висконсине и Мичигане общей мощностью 5,5 ГВт. ИИ уже приносит ощутимую пользу, помогая сотням людей в вопросах здоровья и обеспечения общего благополучия, говорит OpenAI. В будущем каждая площадка Stargate будет иметь собственный план Stargate Community, подготовленный с учётом местных проблем. По словам компании, добиться результатов можно, только будучи «хорошими соседями». 
Источник изображения: Nathan Fertig / Unsplash Компания намерена компенсировать свои энергопотребности таким образом, что это не будет приводить к росту тарифов на электричество для местных жителей, строя энергохранилища, оплачивая создание генерирующих мощностей и модернизацию электросетей, разрабатывая режимы гибкого эгнергопотребления и др. Так, в Висконсине Oracle и Vantage совместно с WEC Energy Group развивают генерирующие мощности и полностью берут на себя расходы на энергетическую инфраструктуру нового объекта, чтобы все затраты на энергосети для ИИ ЦОД не перекладывались на обычных потребителей. В Мичигане Oracle и Related Digital взаимодействуют с DTE Energy в вопросе использования существующих энергоресурсов, дополненных новым аккумуляторным хранилищем, оплаченным проектом. Наконец, в Техасе принадлежащая SoftBank компания SB Energy рассчитывает построить новые генерирующие мощности и системы хранения энергии, чтобы обеспечить большую часть потребностей местного кампуса Stargate на 1,2 ГВт. OpenAI также приветствует инициативу Microsoft Community-First AI Infrastructure Plan, распространяющуюся на строящиеся для OpenAI кампусы, в рамках которой компания тоже пообещала сохранить стабильные тарифы на электроэнергию для обычных граждан, стать водноположительной, обучать и создавать рабочие места для местных жителей, а также направлять средства на социальные нужды и поддерживать местные НКО. 
Источник изображения: OpenAI В OpenAI тоже придерживаются подхода, при котором используются замкнутые или использующие мало питьевой воды системы охлаждения. Власти Абилина утверждают, что местный кампус будет потреблять в год вдвое меньше, чем город использует за день. Такие же решения внедряются в кампусах Stargate в других локациях, а в Висконсине не менее $175 млн направят на местную инфраструктуру и проекты восстановления водных ресурсов. В Абилине же откроется первая OpenAI Academу для подготовки специалистов в области ИИ ЦОД, от строителей до управляющих. Несмотря на все попытки OpenAI и партнёров, а также указы правительства, у экспертов и общественности сохраняются опасения, что крупные ИИ ЦОД приведут к росту цен на электричество. Вызывает обеспокоенность и вероятное использование природного газа для энергоснабжения объектов Stargate. В марте 2025 года сообщалось, что Crusoe, ответственная за строительство ЦОД в Абилине, заказала газовые турбины общей мощностью 4,5 ГВт для питания сети ЦОД.
11.12.2025 [14:05], Руслан Авдеев
Amazon инвестирует $35 млрд в Индию к 2030 году для инноваций в сфере ИИ и создания рабочих местAmazon объявила о намерении вложить более $35 млрд в индийские подразделения компании до 2030 года в дополнение к уже потраченным здесь $40 млрд. Новые инвестиции направят на масштабирование активности и три стратегически важных направления: цифровизацию на основе ИИ, рост экспорта и создание рабочих мест. В отчёте Keystone Strategy говорится, что инвестиции $40 млрд (в т.ч. выплаты сотрудникам и деньги на развитие инфраструктуры) сделали компанию крупнейшим зарубежным инвестором в стране, крупнейшим «катализатором» экспорта с помощью электронной торговли, и одним из ключевых создателей рабочих мест в Индии. Значительные средства затрачены на создание физической и цифровой инфраструктуры, в т.ч. пунктов обслуживания, логистических сетей, дата-центров и инфраструктуры цифровых платежей. По данным Keystone, Amazon оцифровала более 12 млн малых предприятий, помогла увеличению объёма экспорта с помощью электронной коммерции на сумму $20 млрд, а в 2024 году обеспечила порядка 2,8 млн прямых и косвенных рабочих мест в различных отраслях индийской экономики, включая технологическую сферу, логистику, службы поддержки и др. с медицинским страхованием и обучением. В Amazon утверждают, что влияние компании в стране выходит за рамки прямого трудоустройства сотрудников, она обеспечивает рабочие места в сфере упаковки, логистики и сопутствующих технологий, а также даёт возможность развития на своей торговой площадке тысячам малых предприятий. В 2030 году количество прямых и косвенных рабочих мест увеличится до 3,8 млн благодаря расширению бизнеса как самой Amazon, так и растущих сетей пунктов обслуживания и сервисов доставки — одновременно поддерживаются и смежные отрасли. Совокупный объём экспорта, связанный с электронной коммерцией, к 2030 году должен вырасти в четыре раза до $80 млрд. 
Источник изображения: pavan gupta/unsplash.com Благодаря дополнительным вложениям $35 млрд Amazon намерена ускорить цифровую трансформацию в стране, укрепить местную инфраструктуру и поддержать инновации. Инвестиции соответствуют приоритетам Индии и направлены на расширение возможностей ИИ, улучшение логистики, поддержку роста малого бизнеса и создание новых рабочих мест. Программа Amazon по внедрению ИИ во все сферы жизни должна помочь преобразовать цифровое пространство страны, поддерживая заявленную государством концепцию «ИИ для всех». К 2030 году Amazon намерена обеспечить преимущества ИИ 15 млн малых предприятий — продавцы на платформе Amazon.in уже используют ИИ-инструменты Seller Assistant, Next Gen Selling и др. Опыт покупок для сотен миллионов покупателей планируется улучшить с помощью инструментов Lens AI (визуальный поиск), интерактивных покупок с помощью Rufus и многоязычных интерфейсов. Также планируется предоставить 4 млн школьников возможности обучиться навыкам работы с ИИ и познакомить их с карьерными возможностями в технологической сфере. Программа включает разработку учебной программы, посвящённой ИИ, экскурсии в технологические компании, практические занятия в «ИИ-песочнице» и обучение самих преподавателей. Инициатива напрямую поддерживает цели Национальной образовательной политики Индии от 2020 года. 
Источник изображения: Varun Gaba/unspalsh.com О том, сколько именно средств выделят на ИИ-инфраструктуру, включая ЦОД AWS, не сообщается. В начале 2025 года AWS выделила $8,3 млрд только на строительство одного облачного региона — AWS Asia-Pacific в Мумбаи (Mumbai). Регион работает с 2016 года, к 2022 году компания инвестировала в него $3,7 млрд. В 2022 году она запустила облачный регион в Хайдарабаде (Hyderabad). Обязательство потратить $8,3 млрд на ЦОД в Мумбаи — часть более обширного инвестиционного плана, в рамках которого AWS намеревалась потратить в Индии $12,7 млрд. Также компания планирует инвестировать $7 млрд в течение 14 лет в облачный регион в Хайдарабаде. Последние новости об Amazon появились вскоре после того, как Microsoft объявила о планах потратить $17,5 млрд на ИИ-инфраструктуру в Индии к 2030 году. В октябре 2025 года Google подтвердила о реализации проекта по строительству кампуса ЦОД в штате Андхра-Прадеш (Andhra Pradesh), планируется потратить $15 млрд за пять лет.
21.11.2025 [14:14], Руслан Авдеев
AWS и Humain построят в Эр-Рияде кампус AI Zone, где развернут до 150 тыс. ИИ-ускорителей NVIDIA GB300 и Amazon TrainiumAWS и инвестиционная компания Humain из Саудовской Аравии объявили о планах развёртывания в кампусе AI Zone в Эр-Рияде до 150 тыс. ИИ-ускорителей. В рамках расширенного партнёрства компании намерены предоставлять вычислительные мощности и ИИ-сервисы из Саудовской Аравии клиентам со всего мира. Первый в своём роде в Саудовской Аравии кампус AI Zone будет применяться для обучения ИИ и инференса, с доступом к новейшей ИИ-инфраструктуре на основе ускорителей NVIDIA GB300 и Amazon Trainium. Клиенты смогут быстро переходить от стадии концепции к непосредственно работам, а «железо» и ПО NVIDIA будут бесшовно интегрированы с инфраструктурой и сервисами AWS. Поддержка Amazon Bedrock, AgentCore и SageMaker обеспечит клиентам немедленный доступ к базовым моделям в рамках единой платформы без необходимости управления базовой инфраструктурой. Для расширения возможностей AI Zone компания Humain присоединится к программе AWS Solution Provider Program. Это поможет реализации совместного плана, анонсированного в мае 2025 года и предусматривающего инвестиции более $5 млрд в ИИ-инфраструктуру, сервисы AWS, обучение и развитие ИИ-специалистов в Саудовской Аравии. Представитель AWS в регионе EMEA заявил, что объединяя локальный опыт и инвестиции Humain с решениями AWS в сфере ИИ, а также аппаратные решения NVIDIA, инновационную платформу Amazon Bedrock и решения для бизнес-пользователей, включая Amazon Quick Suite, партнёры создают инновационный центр мирового уровня, способный обслуживать клиентов по всему миру. AWS и Humain также ускорят внедрение ИИ в государственном и частном секторах, в том числе развитие LLM с поддержкой арабского языка, включая ALLAM, и создание единого маркетплейса ИИ-агентов для правительственных сервисов. 
Истчоник изображения: backer Sha/unsplash.com Для подготовки квалифицированных кадров AWS обучит 100 тыс. граждан Саудовской Аравии работе с облачными технологиями и специфике генеративного ИИ в рамках программы Amazon Academy, отдельно планируется поддержать программу повышения квалификации для 10 тыс. женщин. Усилия направлены на подготовку кадров для «ИИ-центричной» экономики, которая, по прогнозам, к 2030 году внесёт в ВВП страны вклад в объёме $130 млрд. Подобные проекты стали возможны во многом благодаря визиту в США наследного принца Саудовской Аравии Мохаммеда бин Салмана (Mohammed bin Salman). Визит способствовал ряду соглашений американских компаний с саудовским бизнесом и Humain в частности — с участием AMD, xAI, NVIDIA и др., а также открыл дорогу для поставок в королевство передовых ИИ-чипов.
04.11.2025 [23:12], Владимир Мироненко
Microsoft инвестирует $15,2 млрд в ИИ-инфраструктуру и подготовку кадров в ОАЭВ то время как Объединённые Арабские Эмираты (ОАЭ) проводят свои ежегодные конференции по энергетике и технологиям компания Microsoft поделилась подробностями об инвестициях в эту страну, общая сумма которых за период с 2023 по 2029 год составит $15,2 млрд. «Это не деньги, собранные в ОАЭ. Это деньги, которые мы тратим в ОАЭ. И, как и везде в мире, мы сосредоточены не только на развитии нашего бизнеса, но и на содействии развитию местной экономики», — сообщил Брэд Смит (Brad Smith), заместитель председателя совета директоров и президент Microsoft. По словам Смита, в 2023–2025 гг. общий объём инвестиций Microsoft в ОАЭ составит чуть более $7,3 млрд. Эта сумма включает инвестиции в акционерный капитал G42 в размере $1,5 млрд, более $4,6 млрд капвложений в передовые ИИ-технологии и ЦОД, а также более $1,2 млрд в виде местных операционных расходов и стоимости проданных товаров. В 2026–2029 гг. компания планирует инвестировать ещё $7,9 млрд, из которых $5,5 млрд будут направлены на дальнейшее расширение инфраструктуры, а $2,4 млрд придётся на операционные расходы и продажи. Смит отметил, Microsoft была одной из немногих компаний при предыдущей администрации Белого дома США, получивших экспортные лицензии Министерства торговли на поставку ускорителей в ОАЭ, благодаря чему она накопила в стране эквивалент 21,5 тыс. NVIDIA A100. Фактически это комбинация чипов A100, H100 и H200. Он добавил, что Microsoft стала первой компанией, получившей экспортные лицензии уже при новой администрации, которые позволяют поставить в ОАЭ эквивалент 60,4 тыс. A100, хотя в данном случае это будут уже GB300. Поставки позволят начать в Абу-Даби строительство ИИ ЦОД в рамках майского соглашения между Дональдом Трампом и президентом ОАЭ шейхом Мухаммедом бен Заидом Аль Нахайяном (Mohamed bin Zayed Al Nahyan), которое было приостановлено из-за экспортных ограничений США, пишет TechCrunch . 
Источник изображения: Darcey Beau/unsplash.com Также Microsoft активно инвестирует в формирование кадров в ОАЭ и планирует к концу 2027 года обучить 1 млн человек. Программа включает в себя повышение квалификации 120 тыс. госслужащих федеральных и местных органов власти, а также обучение 175 тыс. студентов и 39 тыс. преподавателей. Ранее в этом году компания основала в Абу-Даби Глобальный центр развития инженерии (Global Engineering Development Center) для привлечения в ОАЭ технических специалистов мирового уровня. Здесь же был открыт новый центр Microsoft AI for Good Lab, где работают исследователи, специализирующиеся на ИИ-моделях и методах постобучения. А в феврале 2025 года Microsoft, G42 и Университет искусственного интеллекта имени Мохамеда бин Заида (MBZUAI) основали в Абу-Даби Фонд ответственного будущего ИИ (RAIFF), который продвигает этические стандарты ИИ на Ближнем Востоке и в странах глобального Юга. |
|

