Материалы по тегу: инференс
|
02.06.2026 [01:04], Владимир Мироненко
ИИ-ускоритель Intel Crescent Island получит до 480 Гбайт LPDDR5XIntel сообщила новые подробности о своём будущем ИИ-ускорителе для ЦОД с кодовым именем Crescent Island, который был анонсирован в прошлом году. Новый GPU основан на архитектуре Xe3P, представляющей усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake. Ожидается, что Xe3P также будет использоваться в GPU Intel серии Arc-C для клиентских устройств. Компания отметила, что чип разработан специально для рабочих нагрузок агентного ИИ. В то время как традиционные ИИ-ускорители от NVIDIA и AMD полагаются на дорогую память HBM, в новом чипе Intel используется LPDDR5X, и он предназначен для работы в серверах с воздушным охлаждением, а не с жидкостным. Crescent Island будет поддерживать до 480 Гбайт памяти LPDDR5X, хотя базовая эталонная конфигурация рассчитана на 160 Гбайт. Intel заявила, что Crescent Island оптимизирован по производительности на Вт — до TDP 350 Вт в версии с воздушным охлаждением и интерфейсом PCIe. 
Источник изображений: Intel Сообщается, что GPU будет поддерживать широкий спектр форматов данных от FP4 до FP64, а также полностью открытый программный стек oneAPI, что идеально подходит для поставщиков услуг «токены как услуга» и сценариев использования для инференса. Концептуально новинка напоминает Rubin CPX, от которого NVIDIA отказалась.  Intel уже оценивает свой открытый унифицированный программный стек для гетерогенных систем ИИ с помощью существующей линейки Arc Pro B-серии, поэтому будущие версии чипов получат доступ к этим оптимизациям на ранних этапах. Intel планирует начать тестирование GPU Crescent Island для клиентов во II половине 2026 года с общей доступностью в 2027 году.
01.06.2026 [12:15], Сергей Карасёв
ADATA представила решение TRUSTA AI Scaler Extended Memory Solution для расширения памяти в ИИ-системахБренд TRUSTA, принадлежащий компании ADATA Technology, анонсировал программно-аппаратную платформу AI Scaler Extended Memory Solution. Она нацелена на решение проблемы нехватки памяти в ускорителях на базе GPU в таких сценариях, как ИИ-инференс и точная настройка больших языковых моделей (LLM). По оценкам аналитиков, мировой рынок ИИ-инфраструктур будет расти в среднем на 26 % в год до 2034-го. Причём ИИ-нагрузки всё чаще переносятся из традиционных облаков в локальный контур и на периферию. При таких подходах компаниям приходится решать вопросы, связанные с конфиденциальностью данных, соответствием нормативным требованиям и оптимизацией затрат. Новая архитектура TRUSTA призвана помочь организациям уменьшить расходы при внедрении ИИ в собственной среде. В отличие от традиционных ИИ-систем, которые полностью полагаются на память GPU-ускорителей, платформа TRUSTA AI Scaler Extended Memory Solution, как и Phison aiDAPTIV+, предполагает распределение нагрузки между памятью GPU, DRAM и SSD-накопителями, что позволяет более эффективно использовать доступные ресурсы. Утверждается, что задачи инференса, которые обычно требуют наличия нескольких GPU-карт, могут быть оптимизированы для работы на одном ускорителе в сочетании с использованием других типов памяти. При этом нагрузки динамически перераспределяются между высокоскоростной памятью GPU, оперативной памятью и твердотельными накопителями. В результате, как отмечается, затраты на развёртывание ИИ могут быть снижены более чем на 50 % по сравнению с обычными инфраструктурами. 
Источник изображения: ADATA Для новой программно-аппаратной платформы создан набор инструментов TRUSTA AI Scaler Toolkit. Это бесплатный продукт с открытым исходным кодом, не привязанный к конкретным аппаратным конфигурациям. С его помощью компании, исследовательские организации и независимые разработчики смогут настраивать ресурсы в соответствии со своими потребностями и выполняемыми задачами. Заявлена совместимость с такими LLM, как Llama, Qwen, Mistral, Mixtral, GPT-OSS, DeepSeek, Phi и Gemma, а дальнейшем список будет расширяться. Кроме того, поддерживаются различные приложения для ИИ-агентов, включая OpenClaw, NemoClaw и Hermes Agentic. Набор инструментов TRUSTA AI Scaler Toolkit уже доступен для загрузки. Кроме того, TRUSTA представила SSD корпоративного класса TD7P51 ECO с интерфейсом PCIe 5.0. Он имеет вместимость до 15,36 Тбайт. Заказчикам будут предлагаться варианты в трёх форм-факторах — U.2, E1.S и E3.S.
01.06.2026 [10:00], Руслан Авдеев
Ampere Computing: экстремальная жара в мире потребует больше энергии, повышения эффективности вычислений и сокращения количества ЦОД
ampere
arm
hardware
дефицит
ии
инференс
метео
охлаждение
прогноз
цод
экология
энергетика
энергоэффективность
Наступившее лето обещает быть чрезвычайно жарким, похожим на прошлогоднее, когда среднемировая температура достигла исторического максимума. Жара и засухи вынуждают индустрию и власти принимать трудные решения на фоне растущего расширения ЦОД, сообщил директор по продуктам Ampere Computing Джефф Виттич (Jeff Wittich). Согласно прогнозу AccuWeather на 2026 год, счета за электричество могут взлететь текущим летом из-за вероятной повсеместной жары по всей территории США. По оценкам отвечающей за надёжность электроснабжения в стране North American Electric Reliability Corporation, летний пиковый спрос на энергию вырастет на 224 ГВт за следующие 10 лет. Это более чем на 69 % выше прогноза 2024 года и на 24 % — пикового спроса 2025-го. В первую очередь ожидаемый рост спроса обусловлен потреблением электричества новыми ЦОД. В 2023 году в США дата-центры потребляли 4,4 % всей электроэнергии, а к 2028 году будут потреблять 12 %. Из-за роста спроса на электричество многим странам пришлось ужесточить правила для снижения нагрузки на энергосистемы и население. Во многом проблема в том, что энергосистемы не справляются с колебаниями энергопотребления в связи с экстремальной погодой. В июле прошлого года сообщалось, что аномальная жара привела к сбоям в лондонских дата-центрах Google и Oracle. Более того, согласно исследованию Rest of World, около 80 % всех дата-центров в мире построены в не особенно подходящих для них климатических условиях. Так, в 2025 году в США было внесено более 200 законопроектов, направленных на регулирование работы ЦОД, и по меньшей мере в 18 штатах предложены специальные тарифы для крупных потребителей электричества, а в Мэне предпринята пока не увенчавшаяся успехом попытка вовсе запретить строительство новых ЦОД. В некоторых законопроектах от желающих строить ЦОД требуют инвестиций в модернизацию инфраструктуры и обеспечение преимуществ для рядовых потребителей энергии. 
Источник изображения: Ant Rozetsky/unsplash.com В 2025 году в Амстердаме продлили мораторий на строительство новых ЦОД и расширение в столичном муниципалитете уже действующих. Приоритет отдан жилью, а новые дата-центры появятся не раньше 2030 года. Во Франкфурте на ЦОД приходится до 40 % от всего потребления городской агломерации, что создаёт непосильную нагрузку местной энергосистеме. В некоторых районах введены временные моратории на подключение новых «индустриальных» объектов, строительство новых не ожидают до II квартала 2027 года. В условиях развития ИИ-проектов дефицит ресурсов будет всё ощутимее. Поддержать этот рост без ущерба окружающей среде можно, повысив эффективность вычислений каждого отдельного ЦОД. Это позволит строить меньше дата-центров для удовлетворения спроса на вычисления или уменьшать их сами по себе, чтобы снизить энергопотребление. Кроме того, потребуется модернизация систем охлаждения. Пока же бум ИИ подталкивает отрасль к экстенсивному развитию, тогда как необходимо максимизировать реальную производительность не только на уровне чипов, но и на остальных уровнях тоже. Для этого необходимы более энергоэффективные чипы, чем сейчас. Виттич подчёркивает, что мощные ИИ-ускорители на основе GPU стоит использовать только там, где это действительно необходимо. Если для обучения и масштабного инференса без них не обойтись, то для многих других задач они избыточны. Оптимизируя вычисления для каждой задачи, следует использовать энергоёмкую инфраструктуру только там, где это действительно необходимо. 
Источник изображения: Peter Herrmann/unsplash.com Более эффективные системы охлаждения необходимо использовать независимо от снижения энергопотребления. При этом рекомендуется сочетать разные варианты охлаждения. Например, жидкостное всё чаще используется с энергоёмким ИИ-оборудованием. К сожалению для операторов ЦОД, модернизация систем охлаждения требует серьёзного изменения инфраструктуры, а на старых объектах модернизация сложна и дорога или вовсе невозможна. В существующих ЦОД нередко выгоднее использовать маломощные чипы с воздушным охлаждениями, размещая новые компоненты только там, где они действительно нужны. Фактически это означает переосмысление вычислительных архитектур для получения максимальной производительности на ватт за счёт использования современных чипов. Кроме того, придётся перераспределить рабочие нагрузки и проектировать системы, в которых производительность соответствует требованиям к допустимому тепловыделению и энергосбережению. В конечном итоге, чем больше вычислительных возможностей можно «извлечь» из каждого Вт и м2, тем меньше ЦОД нужно будет строить в будущем. Чем меньше ЦОД придётся строить, тем ниже нагрузка на водные и энергетические ресурсы в конкретных локациях. По словам представителя Ampere, для удовлетворения растущих энергетических потребностей потребуется не просто расширять инфраструктуру, но и оптимизировать её, начиная с вычислительных мощностей. И хотя Виттич прямо об этом не говорит, Ampere видит себя как раз-таки поставщиком энергоэффективных чипов, в том числе CPU для инференса. Однако на практике компания задержала выпуск AmpereOne M, была продана SoftBank и рискует лишиться одного из крупнейших заказчиков в лице Oracle, которая весьма заинтересована в NVIDIA Vera. Ей же приходится конкурировать с собственными Arm-процессорами AWS, Google, Microsoft и Alibaba, а также теперь уже и с самой Arm, Fujitsu и Qualcomm.
31.05.2026 [00:34], Владимир Мироненко
Snowflake потратит $6 млрд на чипы AWS, в том числе на Arm-процессоры GravitonКомпания Snowflake, специализирующаяся на облачных решениях для обработки данных с использованием ИИ, объявила о заключении пятилетнего соглашения о стратегическом сотрудничестве (SCA) с AWS, в рамках которого обязалась потратить $6 млрд на многолетние инфраструктурные проекты, включая использование серверных Arm-процессоров Amazon Graviton, а также ИИ-ускорителей. Компании не раскрывают, о каком поколении Graviton идёт речь, сообщает The Next Web. Для оценки, насколько крупной является сделка для компаний, ненамного больше — около $7 млрд — Snowflake получила выручки от своих сервисов через AWS Marketplace с момента основания компании в 2012 году. В 2020 году Snowflake объявила о пятилетнем облачном контракте с AWS на сумму $1,2 млрд, который впоследствии был увеличен до $2,5 млрд в 2023 году. Эта эволюция иллюстрирует растущую важность облачной инфраструктуры в развитии ИИ. Только в 2025 году расходы Snowflake на услуги AWS составили $2 млрд. За последние несколько лет Snowflake перевела большую часть вычислительных ресурсов с процессоров Intel и AMD на инстансы на базе Graviton, отметил The Register. Согласно соглашению, Snowflake будет запускать и обучать свои модели и сервисы генеративного ИИ, используя комбинацию ускорителей, работающих в AWS, и Graviton. 
Источник изображения: AWS Сделка также отражает собственный рост Snowflake: в среду компания опубликовала финансовые результаты за I квартал 2027 финансового года, закончившийся 30 апреля, которые значительно превзошли прогнозы Уолл-стрит. Компания сообщила о скорректированной прибыли в 39 центов на акцию при выручке в $1,39 млрд (+33 % г/г). Аналитики, опрошенные LSEG, прогнозировали 32 цента на акцию прибыли и выручку в $1,32 млрд (по данным CNBC). Прогноз компании на текущий квартал также был оптимистичным. Snowflake прогнозирует во II финансовом квартале скорректированную операционную маржу на уровне 12,5 % при выручке в размере от $1,415 до $1,420 млрд. Прогноз аналитиков, опрошенных StreetAccount, по операционной марже составляет 11,9 %, по выручке от продажи продуктов — $1,37 млрд. После объявления о финансовых результатах и сделке с AWS акции Snowflake подскочили примерно на 38 %. Обязательство Snowflake запускать свои облачные рабочие нагрузки на Graviton в масштабе является важным подтверждением жизнеспособности концепции Arm-серверов, которая незаметно меняет экономику облачной инфраструктуры уже пять лет, отметил The Next Web. Сделка подчёркивает растущую роль Arm-процессоров в ЦОД. IDC считает, что инвестиции Snowflake в AWS отражают то, как быстро корпоративные рабочие нагрузки ИИ адаптируются к потребностям долгосрочной инфраструктуры, пишет Data Center Knowledge. В ISG отмечают, что соглашение указывает на более широкий переход от экспериментальных развертываний ИИ к более долгосрочному спросу на инфраструктуру. 
Источник изображения: AWS Соглашение предоставляет Snowflake доступ к чипам AWS Graviton в то время, когда вычислительные мощности для ИИ ограничены, отметил ресурс GuruFocus. Оно также приближает инструменты Snowflake для хранения данных, аналитики и ИИ к AWS, где многие из её клиентов уже запускают свои рабочие нагрузки. Это важно для Snowflake, поскольку инвесторы опасались, что ИИ может навредить бизнесу традиционных компаний-разработчикой ПО, а не помочь им. Это обновление изменило ситуацию на Уолл-стрит. Snowflake заявила, что растёт спрос на такие инструменты, как Cortex Code и Snowpark, которые помогают компаниям создавать приложения ИИ и модели машинного обучения, используя собственные данные. Например, предлагаемая уже несколько лет Snowflake платформа Cortex AI может преобразовывать естественный язык в SQL-запросы, обобщать данные и проводить анализ настроений. Что касается AWS, то сделка с Snowflake продолжила серию крупных инвестиций в ИИ-инфраструктуру. Anthropic взяла на себя крупные многолетние обязательства перед AWS; OpenAI в начале этого года подписала значимое соглашение с AWS, несмотря на продолжающееся сотрудничество с её конкурентом Microsoft Azure. В прошлом месяце AWS заключила соглашение с Meta✴ о поставке миллионов чипов Graviton для удовлетворения растущих потребностей компании в вычислительных мощностях для ИИ. Это стало большой победой для AWS, поскольку несколькими месяцами ранее Meta✴ заключила сделку с Google Cloud на $10 млрд.
29.05.2026 [21:36], Владимир Мироненко
FuriosaAI и Broadcom создадут ИИ-ускоритель для платформы инференса для агентной эрыЮжнокорейский стартап FuriosaAI объявил о заключении соглашения о стратегическом партнёрстве с Broadcom для разработки тензорного (TCP) ИИ-ускорителя третьего поколения в качестве основы масштабируемой платформы инференса, предназначенной для обслуживания передовых агентных систем гиперскейлеров. Стартап намерен объединить передовые возможности Broadcom по упаковке, позволяющие интегрировать несколько кремниевых кристаллов в ИИ-ускоритель, и её достижения в масштабируемых сетевых решениях для ИИ со своей ИИ-архитектурой и программным стеком для создания платформы инференса в масштабе стойки По словам FuriosaAI, в результате сотрудничества с Broadcom архитектура процессора Tensor Contraction Processor (TCP) «превратится в многокристальную систему», которая лучше подходит для «высокопроизводительных требований к токенам» рабочих нагрузок инференса и агентного ИИ, пишет DataCenter Dynamics. FuriosaAI отметила, что эта архитектура сделает чипы более подходящими для «реальных рабочих ИИ-нагрузок» и что, сосредоточившись на высокоскоростной передаче данных, а не на управлении потоками вычислений, ускорители обеспечат более высокую производительность на ватт и большую «плотность» токенов, чем «передовые GPU». 
Источник изображения: FuriosaAI Сообщается, что чип третьего поколения FuriosaAI будет включать вычислительный 2-нм кристалл, выделенный IO-кристалл SUE-интерконнекта и двуслойную память HBM4/4E. Благодаря интеграции Scale-Up Ethernet (SUE) и PCIe-решений Broadcom, система будет обеспечивать низкую задержку и высокую пропускную способность интерконнекта All-to-All между сотнями чипов в масштабе стойки. Существующие системы могут объединять не более восьми ИИ-ускорителей RNGD. Как отметил президент группы полупроводниковых решений Broadcom, производительность инференса больше не определяется исключительно вычислительными ресурсами. Она всё больше зависит от повторного использования данных и эффективности обмена данными между серверами и стойками: «Сочетая архитектуру TCP FuriosaAI с ведущей на рынке технологией XPU и IP-платформой Broadcom, масштабируемым Ethernet и коммутаторами сетевых фабрик, мы создаём платформу, которая решает ключевые проблемы крупномасштабного агентного ИИ», — заявил он. «Объединение инфраструктурных возможностей Broadcom и архитектуры Tensor Contraction Processor от FuriosaAI, а также её определяющего отрасль программного стека, позволяет нам выйти за рамки уровня чипа и предложить комплексное решение для эпохи фабрик токенов», — отметил соучредитель и генеральный директор FuriosaAI. 
Источник изображения: Broadcom Хотя вычислительная мощность по-прежнему важна для рабочих ИИ-нагрузок, особенно на этапе предварительного заполнения, FuriosaAI сосредоточилась на перемещении данных между HBM и DRAM. «TCP ориентирован на высокоскоростную передачу данных и масштабные тензорные операции, а не на управление тысячами крошечных потоков. Он рассматривает доступ к памяти как первостепенную задачу, устраняя “обрыв” эффективности, с которым сталкиваются GPU, когда модели выходят за рамки жёстких иерархий кеша», — сообщается в блоге компании. Аппаратное обеспечение FuriosaAI поддерживается программным стеком, который позволяет разработчикам быстро развёртывать приложения, а также легко переключаться на новые модели и новые методы оптимизации. В то время как устаревшие платформы требуют обширной ручной настройки ядер для каждой новой модели, SDK FuriosaAI использует универсальный компилятор, который автоматически сопоставляет высокоуровневый код PyTorch с полупроводниковой архитектурой. Для разработчиков, которым требуется более детальный контроль, виртуальная архитектура набора команд FuriosaAI предлагает декларативную модель программирования, которая обеспечивает управление оборудованием без недетерминированной сложности традиционного программирования для GPU, отметила компания. Ранее сообщалось, что Broadcom продлила сотрудничество с Meta✴ для разработки нескольких поколений кастомных ИИ-чипов. Также она расширила контракт с Google по снабжению её новыми поколениями ИИ-чипов. Создаёт Broadcom специализированные чипы и для OpenAI. Всего у компании в разработке порядка десяти кастомных ASIC.
29.05.2026 [09:30], Руслан Авдеев
Cisco: агентный ИИ трансформирует структуру интернет-коммуникаций, а через 10 лет на него придётся четверть трафикаХотя сегодня на пользовательский ИИ-трафик приходится лишь малая доля от общего объёма, распространение агентного ИИ существенно изменит его структуру. В отчёте AI Impact on Wide Area Networks (WAN) компания Cisco прогнозирует, что именно ИИ станет главным драйвером роста сетевого трафика, а потребительский трафик к середине 2030-х гг. вырастет приблизительно в 6,6 раза, сообщает блог IEEE ComSoc. По оценкам Cisco, ИИ обеспечит около 63 % дополнительного роста трафика, если сравнивать со сценарием без учёта ИИ. Исследование уделяет основное внимание именно WAN-сетям (без ЦОД и кластеров) и даёт рекомендации по проектированию сетей и планированию пропускной способности. Потребительский ИИ-трафик в основном по-прежнему состоит из коротких текстовых диалогов, но ситуация меняется с переходом к агентному ИИ и мультимодальным взаимодействиям. Пока же, по данным Comcast, 97,1 % ИИ-трафика приходилось на текст, 2,6 % на изображения и 0,3 % на видео. И хотя на инференс приходится лишь «незначительная» доля трафика, Cisco полагает, что к 2035 году на него будет приходиться приблизительно 25 % всего трафика Сети. 
Истчоник изображения: Robin Pierre/unsplash.com Важно, что инференс-трафик вдвое продолжительнее типичных веб-взаимодействий и к тому же интенсивнее, поскольку генерируется роботом. При выполнении некоторых задач агентами может использоваться до 450 % больше трафика на задачу, чем человеком, а около 9 % инференс-потоков обеспечивают больше исходящего трафика (upstream), чем входящего, тогда как у обычного веб-трафика на upstream приходится всего 0,5 %, и это уже серьёзный сдвиг в поведении Сети, который с ростом использования агентных ИИ будет только расти. Использование ИИ гораздо чувствительнее к задержкам, чем при большинстве обычных сетевых сценариев, поскольку коммуникация пользователя с ИИ часто идёт в виде разговора в интерактивном режиме, и ожидаются почти мгновенные ответы. По мнению Cisco, даже небольшие задержки становятся критичными для качества сервиса. В то же время растут и объёмы ИИ-трафика, поскольку увеличиваются мультимодальные промпты/загрузки и использование агентов. 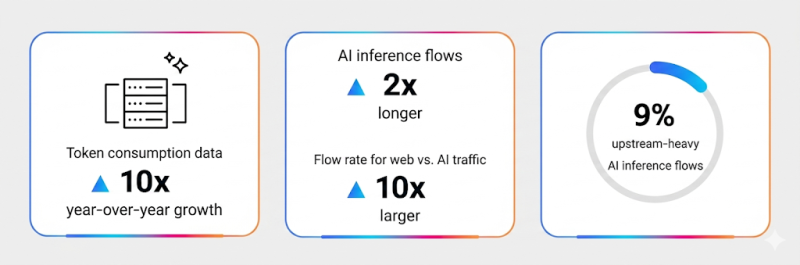
Источник изображения: Cisco Изменения структуры трафика потребуют и изменений физической инфраструктуры. Оптоволоконные сети уже обеспечивают относительно симметричные потоки данных и низкую задержку, но операторы DOCSIS вынуждены бороться за снижение задержки и выделять больше полос для исходящего трафика в ущерб входящему. Теперь для ШПД-сетей одной из ключевых задач становится пропускная способность upstream-каналов, задержки и т.п., а не просто общий объём пропускаемых данных. Повышение симметричности upstream- и downstream-каналов, а также возможность обеспечения низкой задержки становится чрезвычайно важным, особенно по мере роста мультимодального и агентного использования ИИ.
20.05.2026 [20:05], Владимир Мироненко
Alibaba представила ИИ-ускоритель Zhenwu M890, который втрое быстрее предшественникаAlibaba Group представила ИИ-ускоритель Zhenwu M890, разработанный её подразделением T-Head Semiconductor (Pingtouge Semiconductor), сообщило агентство Reuters. Согласно опубликованным сведениям о Zhenwu M890, это самый высокопроизводительный продукт, созданный T-Head на сегодняшний день. Он позиционируется как конкурент ускорителю NVIDIA H100, хотя и уступает ему по ряду показателей. Чип поддерживает форматы FP32/BF16/FP16 для обучения и FP8/FP4/INT8/INT4 — для инференса. Новый ускоритель был специально разработан для новой волны ИИ-агентов. Сообщается, что новинка примерно в три раза превосходит предшественника Zhenwu 810E по производительности, но точные характеристики не приводятся. Ускоритель имеет 144 Гбайт HBM и интерфейс PCI 5.0 x16. Каждый M890 имеет 8 портов интерконнекта ICN (800 Гбайт/с) и поддерживает бесшовное объединение до 64 карт. Также была представлена серверная система Panjiu AL128, которая объединяет 128 ускорителей Zhenwu M890 в одной стойке. Система вместе с фирменным стеком T-SAIL уже сейчас доступна китайским корпоративным клиентам через платформу Alibaba Cloud для внутреннего рынка, известную как Bailian. 
Источник изображений: T-Head По словам компании, новый чип хорошо подходит для обработки больших объёмов памяти и коммуникационных нагрузок агентских приложений, для которых модели должны сохранять длительные периоды контекста и координировать свои действия в реальном времени. T-Head сообщила, что на сегодняшний день отгрузила более 560 тыс. ускорителей семейства Zhenwu, и более 400 внешних клиентов из 20 отраслей, включая автопроизводителей и финансовые компании, уже их внедрили. В начале апреля Alibaba и оператор China Telecom заявили о запуске ЦОД на юге Китая, работающего на собственных чипах компании.  Alibaba также представила план разработки чипов на несколько лет вперёд, согласно которому в III квартале 2027 года выйдет преемник под названием V900, а в III квартале 2028 года — чип следующего поколения — J900. Согласно заявлению Alibaba, запланированный к выпуску в следующем году V900 обеспечит примерно трёхкратное увеличение производительности по сравнению с M890. По имеющейся информации, ускорители Alibaba Group производятся по техпроцессам, которые китайские заводы могут использовать без контролируемого США литографического оборудования, что является ограничивающим фактором, определяющим весь цикл производства микросхем в Китае. Поскольку ни один экземпляр H200 из одобренных США для поставки десяти китайским покупателям так и не был отгружен, китайские клиенты ускоряют переход к альтернативам местных компаний: Alibaba Zhenwu, Huawei Ascend, Cambricon Siyuan и др. По мнению Counterpoint Research, Zhenwu даст местным компаниям ещё один вариант для их ИИ-инфраструктуры, хотя остаются вопросы о том, сколько чипов Alibaba сможет выпустить на местных полупроводниковых заводах (SMIC): «M890 — это небольшой, но реальный вклад в самодостаточность Китая в области ИИ… С точки зрения чистой производительности кремния, M890 не является настоящим конкурентом H200. Но в этом и нет нужды. Для китайского рынка это достойная замена H200».
14.05.2026 [18:02], Владимир Мироненко
Благодаря спросу на ИИ AMD нарастила долю на рынке серверных CPU, а Intel потихоньку теснит ArmAMD добилась значительных успехов в сегменте серверных процессоров в I квартале 2026 года. По оценкам Mercury Research, на EPYC пришлось 46,2 % рынка серверных процессоров в денежном выражении, что стало новым историческим максимумом у компании в этой категории продукции. При этом в количественном выражении доля AMD EPYC в общем объёме продаж в сегменте гораздо меньше — 27,4 % (последовательный рост на 230 базисных пунктов), что указывает на их гораздо более высокую среднюю цену продажи (ASP) по сравнению с конкурентами. Общий объём поставок серверных процессоров увеличился примерно на 6 % последовательно и примерно на 19 % год к году. Больше половины рынка серверных чипов в количественном выражении (54,9 %, снижение на 370 базисных пунктов по сравнению с предыдущим кварталом) принадлежит Intel. И судя по её доле рынка в денежном выражении в размере 53,8 % и доле в количественном выражении, можно с уверенностью предположить, что средняя цена серверных процессоров Intel Xeon ниже, чем у AMD EPYC. По данным Mercury Research, на Arm-процессоры для ЦОД приходится около 17,7 % (последовательный рост на 140 базисных пунктов), что составляет почти пятую часть от общего объёма поставок в I квартале 2026 года. Вместе с тем, не уточняется, идёт ли речь о продукции Ampere и других производителей Arm-процессоров, или же о собственных разработках таких компаний, как Google, AWS или Microsoft. 
Источник изображения: AMD В 2026 году ключевым трендом на рынке ИИ стало активное внедрение ИИ-агентов и мультиагентных систем, что обусловило высокий спрос на процессоры и успех AMD. При развёртывании агентного ИИ растёт роль CPU, что привело к изменению конфигурации вычислительных систем от традиционного соотношения, когда один процессор работает в паре с четырьмя или даже восемью ускорителями, в сторону соотношения один к одному. Благодаря возросшему спросу AMD сейчас продаёт каждый произведённый процессор, а Intel реализует заинтересованным клиентам даже то, что ранее списывалось как брак. Вместе с тем в настоящее время AMD удаётся добиваться более высоких средних цен на свою продукцию.
13.05.2026 [00:40], Владимир Мироненко
Red Hat анонсировала интегрированную ИИ-платформу Red Hat AI 3.4Red Hat представила Red Hat AI 3.4, обновлённую версию корпоративной ИИ-платформы, разработанную для поддержки крупномасштабного инференса и развёртывания агентного ИИ в гибридных облачных средах. В качестве комплексной платформы Red Hat AI 3.4 предлагает архитектурную основу и операционные инструменты, необходимые для масштабирования моделей и рабочих процессов агентов в гибридном облаке. Стратегия Red Hat в области ИИ разделена на четыре ключевых направления, заявил Джо Фернандес (Joe Fernandes), вице-президент и генеральный директор Red Hat AI. «Во-первых, мы помогаем клиентам быстро, гибко и эффективно выполнять инференс, предоставляя модели в их среде, — передаёт SiliconANGLE. — Во-вторых, мы подключаем их корпоративные данные к этим моделям и агентам. В-третьих, мы помогаем им ускорить развёртывание и управление агентами в гибридной облачной среде. В-четвёртых, мы объединяем всё это на нашей интегрированной ИИ-платформе, позволяя им запускать любую модель в любом агенте на любом оборудовании и в любой облачной среде». Как отметила компания, ключевым элементом этого релиза является предоставление модели как услуги (MaaS), которое обеспечивает единый управляемый интерфейс для разработчиков, позволяющий получать доступ к тщательно отобранным моделям, а администраторам — отслеживать их использование и применять политики. Разработчики получают доступ к моделям через стандартные OpenAI-совместимые API. Таким образом, единое управление применяется как к внутренним, так и к внешним моделям. А инструменты AutoRAG и AutoML автоматизируют сложные задачи ИИ, начиная с выбора наиболее эффективных стратегий извлечения данных для конкретных наборов и заканчивая построением и оптимизацией моделей. 
Источник изображения: Red Hat В основе системы лежит открытая библиотека vLLM. Её дополняет Kubernetes-нативный стек для инференса llm-d. Поддержка спекулятивного декодирования, которая в этом релизе стала общедоступной, повышает скорость ответа в два-три раза с минимальным влиянием на его качество и снижает стоимость взаимодействия. Кроме того, vLLM теперь поддерживает работу на CPU, что актуально для небольших языковых моделей. Для управления инструментами для агентов Red Hat представляет каталог серверов MCP и связанный с ним шлюз MCP. Новый инструментарий AgentOps даёт возможность управления агентами в масштабе, независимо от используемой платформы, на протяжении всего их жизненного цикла. Это включает в себя интегрированную трассировку вызовов LLM, вызовов инструментов и этапов рассуждений, а также управление криптографической идентификацией через SPIFFE/SPIRE. Последний позволяет организациям заменять статические, жёстко закодированные ключи кратковременными токенами. Это поддерживает операции с минимальными привилегиями для автономных агентов на всех уровнях стека и помогает подтвердить, что действия агентов связаны с проверенной личностью. Для обеспечения интеграции корпоративных данных с моделями и агентами Red Hat AI 3.4 представляет управление с помощью промптов и центр оценки точности, качества и безопасности моделей и агентов. Последний не зависит от фреймворков и заменяет разрозненные методы тестирования единым интегрированным подходом. Prompt Lab and Registry, централизованное хранилище промптов в виде полноценных информационных ресурсов, предоставляет разработчикам и администраторам единый источник достоверной информации о входных данных, управляющих моделями и агентами. 
Источник изображения: Red Hat Новые возможности трассировки построены на основе MLflow. Интеграция MLflow обеспечивает прозрачность работы агента, позволяя осуществлять сквозную трассировку вызовов LLM, этапов рассуждений, запуска инструментов, ответов модели и использования токенов через OpenTelemetry. Это создаёт прозрачный журнал аудита для всего жизненного цикла подсказок, эмбеддингов и конфигураций RAG для поддержки отладки и аудита. MLflow также обеспечивает интегрированное отслеживание экспериментов и управление артефактами для сценариев использования генеративного ИИ и прогнозного ИИ. Платформа Red Hat AI позволяет пользователям проверять безопасность моделей и агентов с помощью автоматизированного сканирования на наличие угроз, которое теперь интегрировано непосредственно в цикл разработки. Используются инструменты Chatterbox Labs и Garak. Платформа проверяет модели и агентных систем на наличие таких рисков как взлом, промпт-инъекций и предвзятость, в сочетании с NVIDIA NeMo Guardrails для обеспечения безопасности во время выполнения. Сообщается, что Red Hat AI 3.4 изначально поддерживает ускорители NVIDIA Blackwell и AMD Instinct MI325X. Расширяя эту унифицированную архитектуру платформы для работы непосредственно в управляемых облаках сторонних разработчиков, в том числе посредством Red Hat AI Inference в IBM Cloud, Red Hat обеспечивает операционную согласованность на широком спектре оборудования и облачных провайдеров.
08.05.2026 [01:10], Владимир Мироненко
AMD представила ускоритель Instinct MI350P — CDNA 4 в формате PCIeAMD представила Instinct MI350P с интерфейсом PCIe — двухслотовую FHFL-карту для стандартных серверов с воздушным охлаждением. MI350P предназначена для локального развёртывания инференса в рамках существующей инфраструктуры электропитания, охлаждения и серверных стоек ЦОД предприятий. AMD отметила, что новинки с возможностью установки до 8 ед. в одно шасси «идеально подходят для инференса малых, средних и крупных ИИ-моделей и конвейеров RAG». Это первая PCIe-карта Instinct, выпущенная AMD за последние четыре года после выхода модели Instinct MI210. 600-Вт чип MI350P, по сути, представляет собой половинку MI350X (четыре XCD). У MI350P PCIe вдвое меньше вычислительных блоков — 128, что соответствует 8192 потоковым процессорам и 512 матричным ядрам. Пиковая частота составляет 2200 МГц. Кроме того, вместо двух IOD-кристаллов тут только один, он изготовлен по 6-нм техпроцессу TSMC. Сам ускоритель сделан по 3-нм технологии TSMC как MI350X. Весь чип содержит 73 млрд транзисторов. 
Источник изображений: AMD Ускоритель оснащён 128 Мбайт кеш-памяти Infinity Cache и 144 Гбайт памяти HBM3E с 4096-бит шиной, обеспечивающей пропускную способность 4 Тбайт/с. Для сравнения, MI350X оснащён 288 Гбайт памяти HBM3E с 8192-бит шиной. Плата 16-контактный разъём для подачи дополнительного питания. TBP можно установить на уровне 450 Вт вместо стандартных 600 Вт, что снизит производительность и ещё больше — энергопотребление. Интерфейс — PCIe 5.0 x16. Чуть позже будет реализована поддержка SR-IOV и возможность поделить чип на два или четыре vGPU. 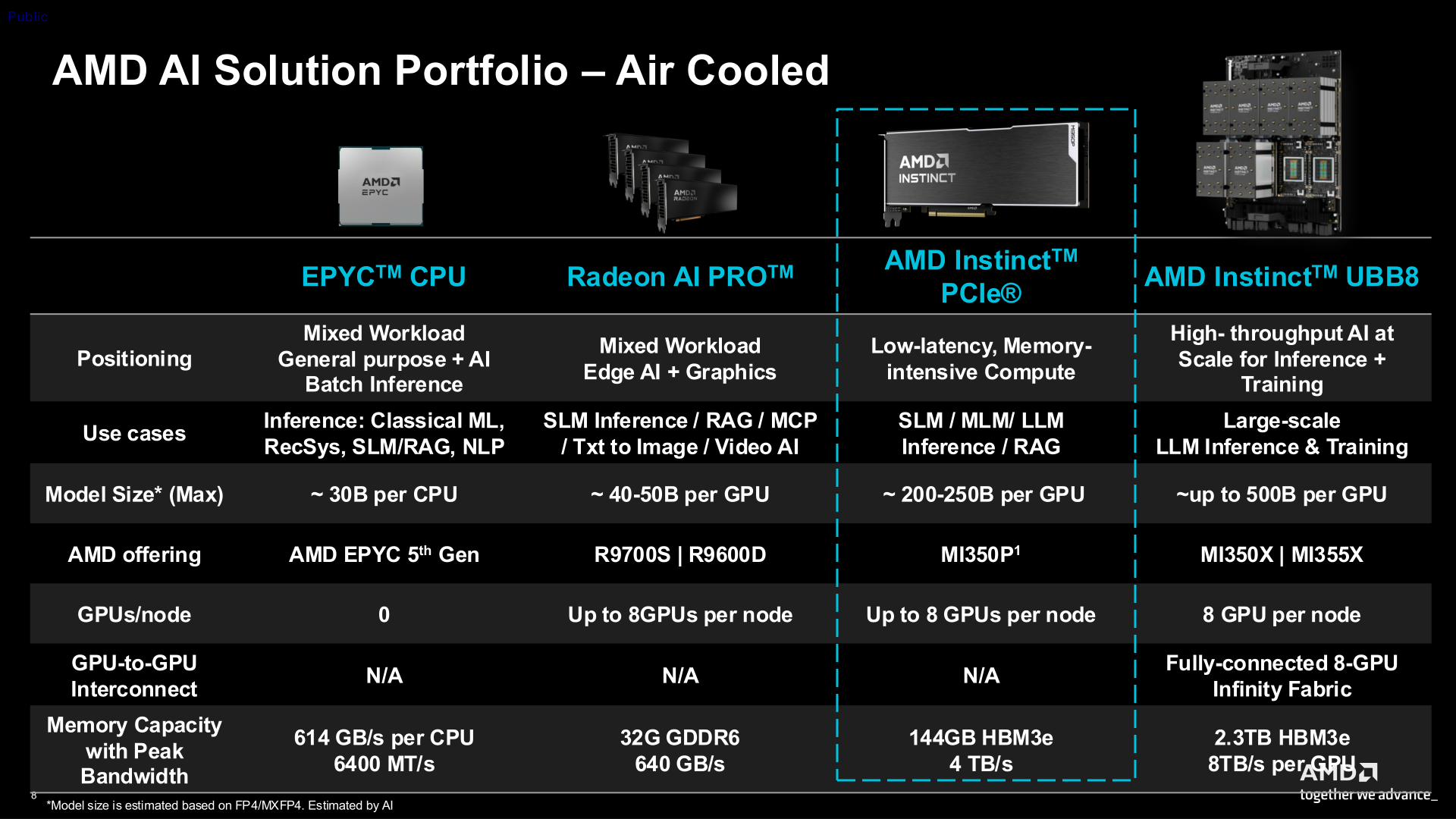 Расчётная производительность Instinct MI350P в MXFP4-расчётах составляет 2,3 Пфлопс, а пиковая — 4,6 Пфлопс. Это самая высокая производительность среди PCIe-ускорителей корпоративного класса, отметила компания. Предусмотрена поддержка разрежённости для форматов FP16, BF16, INT8 и OCP-FP8, что позволяет ускорить обработку данных. Векторная и матричная FP64-производительности составляет 36 Тфлопс. Кроме того, ускоритель снабжён декодерами HEVC/H.265, AVC/h.264, VP9 и AV1, а также кодеками (M)JPEG. 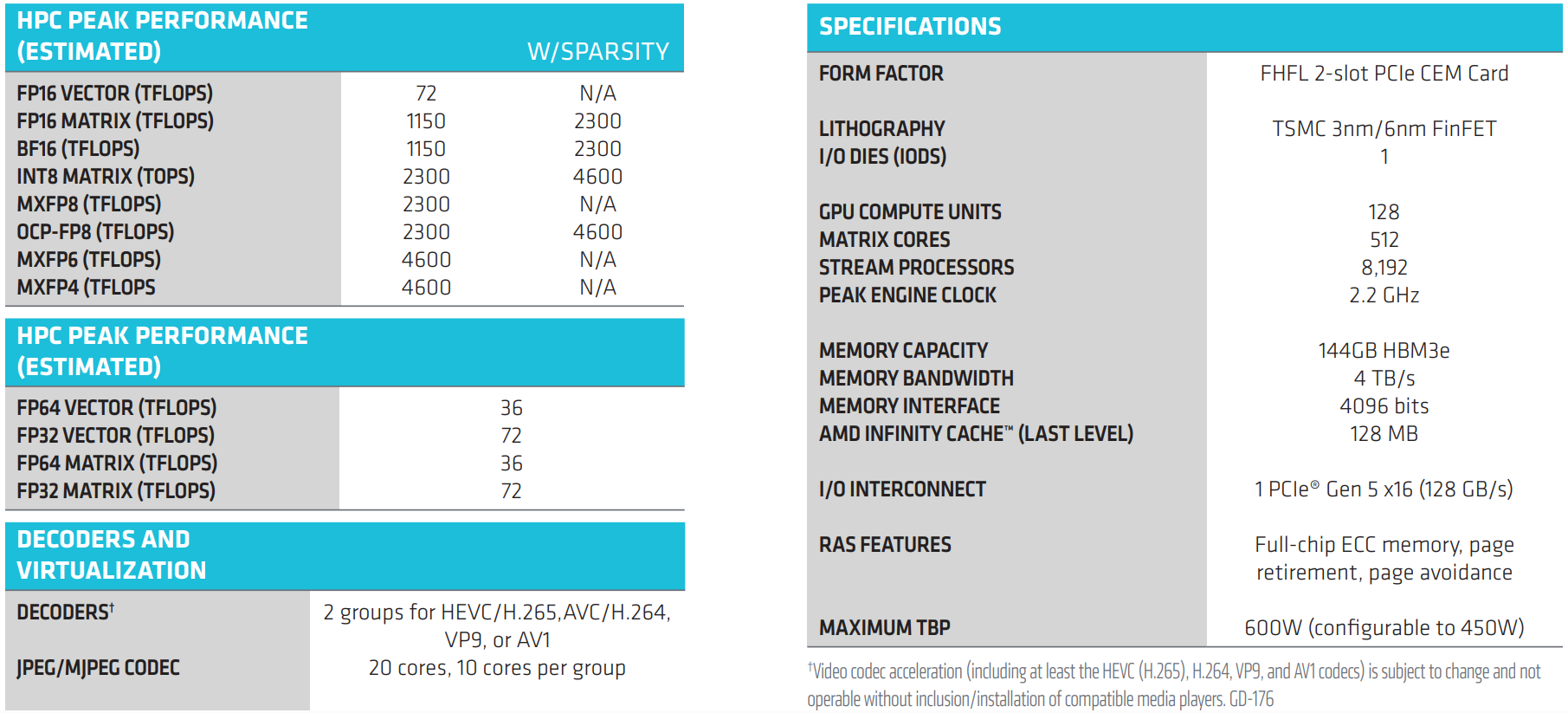 Самым существенным недостатком новинки — это отсутствие прямой связи между ускорителями посредством Infinity Fabric. Всё общение внутри одного узла происходит посредством PCIe-шины, так что наличие восьми MI350P в одном сервере позволит эффективно обслуживать восемь отдельных моделей (до 200–250 млрд параметров), а не одну большую, которая не помещается в памяти единичного ускорителя. NVIDIA попыталась чуть смягчить эту проблему, представив для своих PCIe-ускорителей плату с адаптерами ConnectX-8 SuperNIC со встроенными коммутаторами PCIe 6.0.  Сообщается, что Instinct MI350P доступны у различных партнёров компании. Они предлагают полностью открытую экосистему и программный стек Enterprise Ready AI с поддержкой ROCm. AMD заявила, что её эталонный open source пакет AMD Enterprise AI предоставляется партнёрам без каких-либо затрат на лицензирование. Это обеспечивает большую прозрачность кода и помогает снизить операционные расходы. В сочетании с картами Instinct MI350P и решениями от партнёров этот стек позволяет компаниям быстро развёртывать локальные системы без постоянных затрат на токены, говорит AMD. |
|

