Материалы по тегу: ии
|
29.06.2025 [13:30], Владимир Мироненко
Meta✴ хочет привлечь $29 млрд на строительство ИИ ЦОД в СШАMeta✴ планирует привлечь $29 млрд для финансирования строительства ЦОД в США. Переговоры с частными инвесторами, в числе которых несколько крупных игроков, включая Apollo Global Management, KKR, Brookfield, Carlyle и Pimco, находятся на продвинутой стадии, пишет газет Financial Times. Meta✴ хочет привлечь $3 млрд в виде акционерного капитала и $26 млрд в виде займа. На переговорах компания обсуждает, как структурировать масштабное привлечение средств. Сообщается, что Meta✴ привлекла консультантов из Morgan Stanley, чтобы организовать финансирование и обсудить варианты, которые позволили бы сделать долговые обязательства более ликвидными после привлечения заёмных средств. Это один из вопросов, который подняли потенциальные инвесторы, учитывая сумму сделки, сообщила Financial Times. 
Источник изображения: Lightsaber Collection/unsplash.com Последнее время гендиректор Meta✴ Марк Цукерберг (Mark Zuckerberg) резко активизировал усилия по выводу компании в «лидеры ИИ», которая серьёзная отстала от конкурентов в разработке ИИ-технологии. Её большая языковая модель Llama 4 не показала ожидаемых результатов, а выпуск флагманской LLM Behemoth пришлось отложить. Чтобы привлечь талантливого менеджера, основателя Scale AI Александра Вана (Alexandr Wang) в новую команду «суперинтеллекта», которая займётся разработкой сильного ИИ (AGI), Meta✴ инвестировала в стартап громадную сумму в $14,3 млрд, также получив в нём 49-% долю. Сообщается, что Цукерберг лично пытался переманить других талантливых специалистов в области ИИ, предлагая бонусы за переход в компанию в размере $100 млн. В настоящее время Meta✴ строит крупный кампус ЦОД в Луизиане. Возможно, часть нового финансирования будет направлена на реализацию этого проекта. В январе Meta✴ объявила о планах потратить до $60–$65 млрд на ИИ-инфраструктуру в этом году, а в мае повысила прогноз капитальных затрат на 2025 год на 10 % до $64–$72 млрд, сославшись на «дополнительные инвестиции в ЦОД» для поддержки продвижения разработок в сфере ИИ, а также в связи с «увеличением ожидаемой стоимости инфраструктурного оборудования». В этом месяце Meta✴ объявила, что выкупила всю электроэнергию, вырабатываемую атомной электростанции в Иллинойсе, на два десятилетия вперёд для поддержки своих проектов в области ИИ. Другие крупные игроки ИИ-рынка тоже используют заёмный капитал и привлекают инвесторов к участию в своих проектах. CoreWeave, которая управляет ИИ-облаком, имела около $8 млрд долга в декабре 2024 года. Crusoe Energy Systems и инвестиционная фирма Blue Owl Capital получили кредиты на сумму $7 млрд на строительство комплекса ЦОД в Техасе. Сообщается, что Oracle будет использовать площадку для размещения чипов NVIDIA на сумму $40 млрд для предоставления в аренду OpenAI в рамках проекта Stargate.
27.06.2025 [17:45], Андрей Крупин
VK Tech представил линейку новых сервисов информационной безопасностиРазработчик корпоративного программного обеспечения VK Tech (входит в экосистему VK) сообщил о доступности заказчикам новых решений для обеспечения информационной безопасности бизнеса. Всего компанией представлено четыре решения — все они являются собственными разработками VK, выполнены в формате сервисов и включены в состав облачной платформы VK Cloud во всех вариантах поставки. В числе продуктов: платформа для автоматизации проверки безопасности кода Security Gate, система централизованного сбора и анализа событий безопасности Security Information and Event Management (SIEM), сервис контроля доступа к ресурсам Zero Trust Architecture (ZTA) и система защиты данных Data Security Posture Management (DSPM), которая показывает, где в организации находятся конфиденциальные данные, как они используются, и кто имеет к ним доступ. 
Источник изображения: Flipsnack / unsplash.com По заверениям разработчика, все четыре продукта отличаются высокой производительностью при обработке больших массивов информации. Так, Security Gate способен в течение суток сканировать более 40 тысяч репозиториев и 1 млрд строк кода. SIEM-система позволяет обрабатывать до 10 млн событий в секунду (EPS) и хранить до 15 Пбайт телеметрии в сжатом виде для быстрого поиска и расследования инцидентов. Система DSPM способна анализировать более 1 петабайта данных ежедневно. «Утечка данных способна нанести бизнесу многомиллионные убытки и подорвать доверие пользователей. Мы превратили наработанную внутри VK экспертизу в готовые сервисы — от DevSecOps до Zero Trust — чтобы наши клиенты могли выдерживать и нейтрализовывать современные кибератаки без роста операционных затрат», — отмечает VK.
27.06.2025 [17:17], Руслан Авдеев
Deloitte: прожорливость ИИ ЦОД может привести к перегрузке энергетической инфраструктуры СШАПотребность ИИ ЦОД в США в энергии к 2035 году может вырасти в 30 раз — до 123 ГВт с 4 ГВт в 2024 году. При этом работающие с ИИ-оборудованием дата-центры требуют гораздо больше энергии на единицу площади, чем классические, что может вызвать серьёзные проблемы в энергосетях уже в обозримом будущем, сообщает The Register со ссылкой на отчёт Deloitte Insights «Сможет ли инфраструктура США успеть за экономикой ИИ?» (Can US infrastructure keep up with the AI economy?) В исследование подчёркивается, что крупные ЦОД потребляют всё больше энергии, в то время модернизация энергосетевой инфраструктуры и ввод новых источников энергии сталкиваются с рядом препятствий из-за бюрократии и сбоев в цепочках поставок. Потенциальным решением могут стать технологические инновации, которые сделают инфраструктуру ЦОД более энергоэффективной. Кроме того, успех зависит от упрощения регулирования и масштабов финансовых вливаний в отрасль. Оценки Deloitte свидетельствуют, что в прошлом году американские дата-центры потребовали около 33 ГВт, но из них лишь 4 ГВт ушло на ИИ-проекты. Компания прогнозирует, что к 2035 году мощность ЦОД в целом вырастет впятеро, а вот ИИ ЦОД — более чем в 30 раз. На них придётся до 70 % от общего объёма в 176 ГВт. 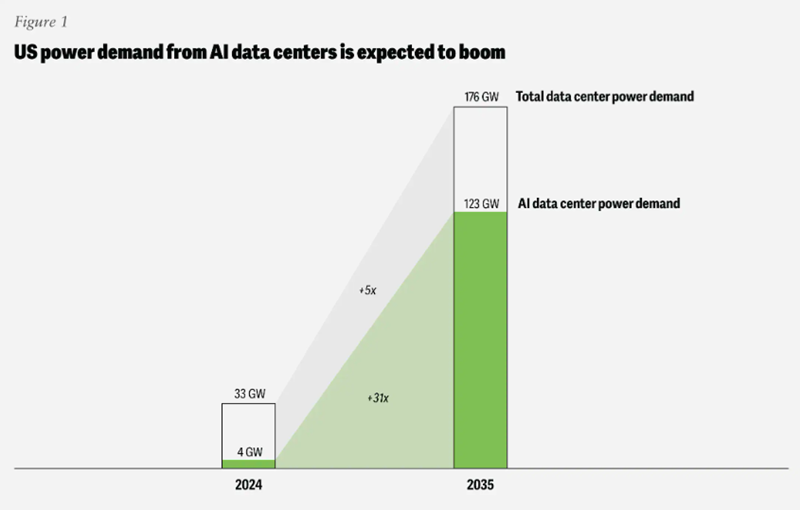
Источник изображения: Deloitte Дата-центров станет больше, и они будут крупнее. В Deloitte подчёркивают, что сейчас крупнейшие американские ЦОД «большой тройки» гиперскейлеров потребляют менее 500 МВт каждый, но сейчас строятся объекты с мощностью более 2 ГВт. На ранних стадиях планирования находятся дата-центры, потребляющие уже до 5 ГВт. Другими словами, спрос на электричество продолжит расти. За последний год рост спроса в основном компенсировался увеличением генерации энергии газовыми электростанциями, несмотря на то что гиперскейлеры неоднократно декларировали приверженность «зелёной» повестке и обещали добиться нулевых выбросов. Компания предупреждает, что некоторые запросы на присоединение смогут быть удовлетворены лишь через семь лет, причём на строительство ЦОД обычно уходит меньше времени, чем на создание генерирующих мощностей. Если дата-центр можно построить за несколько лет, то новые газовые электростанции, свободные от контрактов на поставку энергии, вероятно, появятся не раньше следующего десятилетия. 
Источник изображения: Deloitte Проблемы с цепочками поставок мешают как энергокомпаниям, так и гиперскейлерам, поскольку импорт в США многих критически важных компонентов с недавних пор подпадает под действие заградительных тарифов. Кроме того, потенциально будут расти цены на сталь, алюминий, медь и цемент, что только усугубит ситуацию в энергетике. Исследователи Deloitte опросили операторов ЦОД и энергетические компании, чтобы выяснить, какие стратегии помогут справиться с потенциальной нехваткой энергии, вызванной бумом строительства ЦОД. Ключевыми инструментами названы технологические инновации, изменения в регулировании и рост финансирования. Инновации, как ожидается, позволят создать более энергоэффективную инфраструктуру — например, можно будет перейти на оптическую передачу данных и современные твердотельные трансформаторы. Реформа нормативно-правовой базы регуляторами может включать переход от поддержки «спекулятивных» проектов на более реалистичные, с переходом на принцип «первым готов — первым обслужен». С похожими проблемами уже столкнулась Великобритания, в связи с чем регулятор Ofgem пересмотрел систему очередями на подключение, призванную исключить т. н. «зомби-проекты», и ускорить процесс введения в эксплуатацию более жизнеспособных. 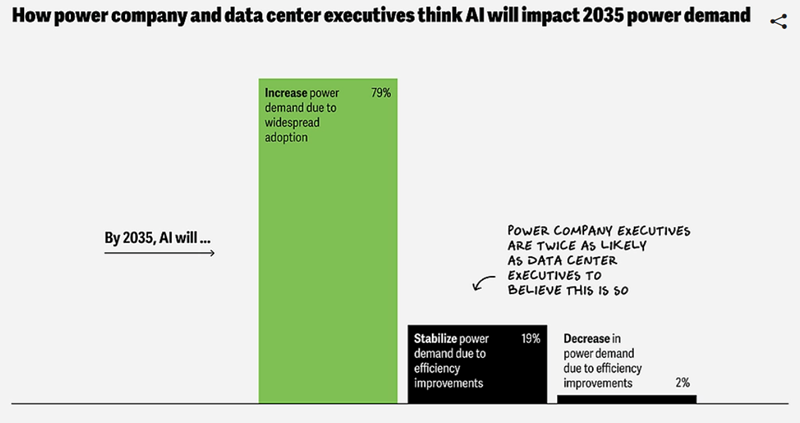
Источник изображения: Deloitte В итоге всё сводится к наличию больших денег, поскольку развитие инфраструктуры потребует масштабного финансирования, а влияние ИИ ЦОД на стратегию развития становится всё более очевидным в дискуссиях об инвестициях. Потенциальные риски связаны с тем, что ограничения мощности и пропускной способности современных энергосетей США могут затормозить развитие ИИ — энергокомпании могут упустить шанс расширить и модернизировать сети, что может привести к катастрофическим последствиям для отрасли. В результате под вопросом может оказаться экономическое и геополитическое лидерство США — для страны это вопрос конкурентоспособности или даже национальной безопасности. Американский регулятор North American Electric Reliability Corp. (NERC), отвечающий за надзор за электросетями и сопутствующей инфраструктурой, сообщил, что подключение ЦОД к электричеству сегодня весьма рискованно из-за их нестабильного энергопотребления. Ситуация может усугубиться с появлением ускорителей с энергопотреблением 15 кВт. В апреле Deloitte сообщала, что АЭС смогут обеспечить 10 % будущего спроса ЦОД США на электроэнергию, но строить их придётся быстрее.
27.06.2025 [09:35], Руслан Авдеев
У гиперскейлеров есть уже 1,2 тыс. дата-центров, а через пять лет они будут доминировать на рынке ЦОДУже к 2030 году на гиперскейлеров будет приходиться 61 % всех мощностей ЦОД в мире, что обусловлено ростом облачных сервисов и увеличением спроса на ИИ-вычисления, Synergy Research Group. Доклад Synergy Research показал, что рост доли мощностей AWS, Microsoft и Google не связан со снижением доли корпоративных ЦОД. Напротив, on-premise и колокейшн-площадки тоже развиваются, но рост гиперскейлеров значительно опережает остальных игроков. В распоряжении гиперскейлеров на конец I квартала уже имелось 1189 ЦОД. Вместе на долю IT-гигантов приходится 44 % мировой мощности ЦОД. Из них более половины приходится на кампусы собственной постройки, остальное — на арендованные объекты. С учётом того, что на колокейшн-ЦОД, не связанных с гиперскейлерами, приходится ещё 22 % от общей мощности, на долю корпоративных ЦОД остаётся всего 34 %, хотя всего шесть лет назад на них приходилось 56 % ёмкости. В будущем же, вероятно, на объекты гиперскейлеров будет приходиться 61 %, а инфраструктуре on-premise останется всего 22 %. За указанный период будет расти мощность дата-центров всех типов, но основным драйвером станет трёхкратный рост мощности ЦОД гиперскейлеров в следующие шесть лет. 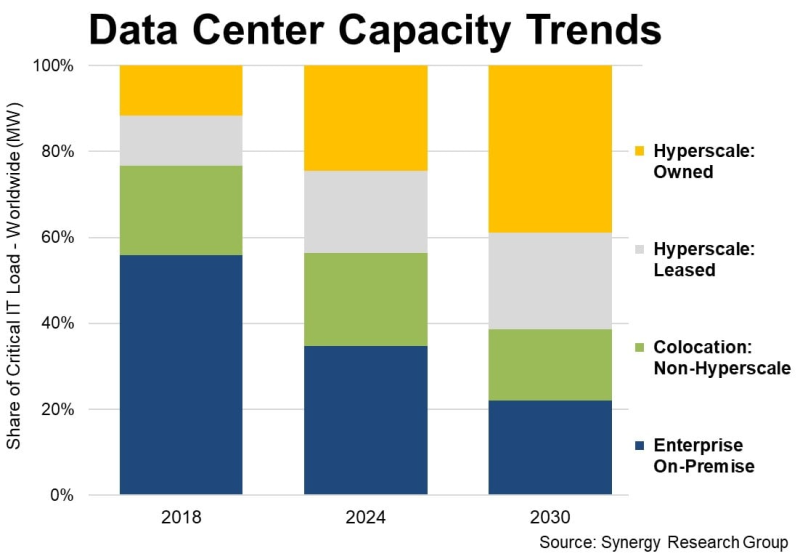
Источник изображения: Synergy Research Важно, что прирост ёмкости колокейшн-объектов тоже будет исчисляться двузначными значениям в процентах, но их доля всё равно будет сокращаться. Почти то же касается и корпоративных дата-центров. После долгой стагнации благодаря внедрению ИИ их масштаб вновь начнёт расти, но доля будет снижаться приблизительно на 2 п.п./год в течение всего прогнозируемого периода. По словам аналитиков, облачные и другие ключевые сервисы стали основными драйверами расширения мощностей дата-центров, а стремительное развитие технологий и ИИ-приложений даёт дополнительный импульс. Впрочем, в компании подчёркивают, что рыночные показатели мощностей значительно отличаются от региона к региону. Так, доля мощностей ЦОД в США значительно больше, чем в регионах EMEA (Европа, Ближний Восток и Африка) и странах Азиатско-Тихоокеанского региона, хотя в целом наблюдается общий вектор. Во всех регионах ожидаются двузначные годовые темпы роста общей мощности дата-центров в прогнозируемом периоде. Кроме того, во всех регионах доля мощностей ЦОД, принадлежащих гиперскейлерам, будет расти не менее чем на 20 % ежегодно. Немалую роль в прогнозах играет предположение о дальнейшем развитии ИИ-проектов. Впрочем, некоторые эксперты говорят, что существует риск перегрева рынка и появления «пузыря» подобного тому, что сопровождал бум и крах доткомов в конце 1990-х годах.
26.06.2025 [23:00], Владимир Мироненко
«Аквариус» передал в залог структуре «Сбера» доли в двух компаниях
hardware
аквариус
импортозамещение
инвестиции
реструктуризация
россия
сбер
сбербанк
сделано в россии
сделка
финансы
Один из крупнейших российских производителей компьютерной техники, ГК «Аквариус» передал 16 июня в залог структуре «Сбера» — ООО «Сбербанк Инвестиции» — 70-% долю в своём головном юрлице «Ай кью холдинг» (ранее «Смарт Холдинг») и 99,99-% долю в ООО «Аквариус технологии», сообщил «Коммерсантъ» со ссылкой на данные «Спарк-Интерфакса». Аналитики не исключают, что передача долей может быть частью более широкой сделки со «Сбером», связанной с реструктуризацией или возможным вхождением банка в капитал. В прошлом году «Сбербанк Инвестиции» уже получили 12-% долю в «Аквариусе». В «Аквариусе» пояснили «Коммерсанту», что частичный залог долей отдельных компаний группы является стандартной практикой при корпоративном кредитовании, и это не означает по умолчанию никакой продажи. Представитель ФГ «Финам» отметил, что в российской практике распространены сделки через посредничество банков, когда сначала банк выкупает актив и потом перепродаёт его. Впрочем, эксперты не исключают продажу компании и самому «Сбера», который является крупным потребителем IT-инфраструктуры. Как сообщает источник «Коммерсанта», знакомый с планами компании, у неё высокая долговая нагрузка и ей «не хватает средств на операционную деятельность». По его словам, в связи с этим в «Аквариусе» изначально рассматривали продажу компании новым инвесторам для расчётов с кредиторами либо её переход в управление «Сбера». Возможность проблем не исключил и другой собеседник издания, связавший их это с сокращением госзакупок и ростом ключевой ставки ЦБ. 
Источник изображения: «Аквариус» Как утверждает источник «Коммерсанта» на рынке разработчиков электроники, одной из проблем отрасли в целом остаётся «привязка к госзакупкам»: основные процедуры приходятся на начало года, средства поступают неравномерно, а поддерживать производство надо постоянно. По данным «Регблока», задолженность АО «А-холдинг» по кредитам и займам составляла 4,5 млрд руб., кредиторская задолженность ООО «Ай кью холдинг» — 1 млрд руб., что соответствует умеренному уровню. Вместе с тем эксперт ИК «Финам» отметил, что группа компаний может быть уязвима. В начале прошлого года сообщалось, что «Сбербанк» организовал производство собственных серверов. Весной этого года «Сбербанк» инициировал банкротство российского производителя OCP-серверов Gagar>n.
26.06.2025 [16:31], Андрей Крупин
VK Tech представил Private Cloud Light — альтернативу зарубежным платформам виртуализацииРоссийский разработчик корпоративного программного обеспечения VK Tech (входит в экосистему VK) представил Private Cloud Light — облегчённую версию платформы для построения инфраструктурных частных облаков во внутреннем контуре заказчика. Продукт сочетает виртуализацию и инфраструктуру как сервис (IaaS) в одном коробочном решении, способном заместить иностранное ПО данного класса. Private Cloud Light значительно снижает требования к оборудованию и позволяет оперативно развернуть инфраструктуру частного облака. Решение оптимально для организаций среднего масштаба и региональных филиалов крупных заказчиков. Минимальная конфигурация начинается от четырёх серверов и системы хранения данных, что позволяет сократить затраты на внедрение и эксплуатацию без потери отказоустойчивости и производительности. 
Источник изображения: Christina @ wocintechchat.com / unsplash.com Новая конфигурация даёт возможность создавать компактные и отказоустойчивые недораспределённые инсталляции, сохраняя при этом централизованное управление и контроль. Платформа включает в себя совмещённые управляющие и вычислительные узлы, API-доступ, аудит действий пользователей с возможностью выгрузки во внешние SIEM-системы и опциональный встроенный биллинг для управления расходами. Решение доступно в рамках закрытого тестирования и может поставляться как в виде программного обеспечения, так и в составе программно-аппаратного комплекса.
26.06.2025 [15:44], Руслан Авдеев
АЭС Three Mile Island начнёт поставлять энергию Microsoft на год раньше, чем планировалосьРаботы Constellation Energy по перезапуску АЭС Three Mile Island (Crane Clean Energy Center) продвигаются быстрее, чем ожидалось — станция заработает в 2027 году, а не 2028-м, сообщает Bloomberg. Отчасти изменение сроков связано с тем, что АЭС может подключиться к энергосети PJM Interconnection быстрее, чем планировалось. После ввода в эксплуатацию станция будет снабжать электричеством Microsoft, которой нужна безуглеродная энергия для ИИ ЦОД. В Constellation заявили, что закрытие станции было ошибкой — достаточно понаблюдать за параметрами энергосети несколько дней, чтобы понять, насколько необходимо возобновить проект. Three Mile Island является одной из двух атомных электростанций США, закрытых по экономическим причинам. Теперь их возвращают к жизни для удовлетворения спроса на электроэнергию. Так, Holtec International работает над перезапуском АЭС Palisades в Мичигане, закрытой в 2022 году. Сегодня интерес в США к ядерной энергетике получил «второе дыхание». Это обусловлено тем, что потребность ЦОД, заводов и домохозяйств в стране растёт. В мае президент США Дональд Трамп (Donald Trump) подписал указы, призванные ускорить строительство АЭС в стране. 
Источник изображения: Constellation В сентябре 2024 года Constellation Energy объявила о заключении 20-летнего контракта с Microsoft на поставку электроэнергии (PPA), которая будет производиться на АЭС Three Mile Island. Мощность АЭС составит 837 МВт. Этого хватит, чтобы обеспечить работу всех дата-центров компании в Пенсильвании, Чикаго, Вирджинии и Огайо. Сейчас ведётся перезапуск энергоблока Unit 1, остановленного в 2019 году. Ожидается, что перезапуск принесёт $3 млрд в виде государственных и федеральных налогов. Печально известный Unit 2, на котором в 1979 году произошла авария, выводится из эксплуатации. Ранее AWS приобрела за $650 млн кампус Talen Energy рядом с АЭС Susquehanna Steam Electric Station в Пенсильвании. Предполагалось, что станция обеспечит ЦОД до 960 МВт. Впрочем, из-за противодействия общественников и регуляторов, пришлось прибегнуть к покупке энергии обходными путями. На днях также сообщалось, что Нью-Йорк построит гигаваттную АЭС для ИИ ЦОД и других отраслей — это крупнейший в США проект новой АЭС за 15 лет.
26.06.2025 [12:05], Сергей Карасёв
HPE представила ИИ-систему Compute XD690 на базе NVIDIA HGX B300Компания HPE анонсировала высокопроизводительный сервер Compute XD690, предназначенный для решения таких ресурсоёмких задач, как обучение ИИ-моделей, инференс и пр. В основу новинки положены процессоры Intel и ускорители NVIDIA на архитектуре Blackwell. Поставки новинки компания планирует организовать в октябре нынешнего года. Система Compute XD690 выполнена в форм-факторе 10U с воздушным охлаждением. Полностью технические характеристики не раскрываются, но известно, что конфигурация включает два чипа Intel Xeon 6. Задействована платформа NVIDIA HGX B300 с восемью модулями Blackwell Ultra SXM. Заявленная производительность на операциях FP64 достигает 10 Тфлопс, на операциях FP4 — 144 Пфлопс. Суммарный объём памяти HBM3e составляет около 2,3 Тбайт. Применяется интерконнект NVLink пятого поколения с общей пропускной способностью 14,4 Тбайт/с. Говорится о поддержке XDR InfiniBand и Spectrum-X Ethernet. 
Источник изображения: HPE Как отмечает HPE, ускорители Blackwell Ultra обеспечивают на 50 % более высокую производительность FP4 и удвоенную пропускную способность GPU↔CPU по сравнению с решениями на архитектуре Blackwell предыдущего поколения. Благодаря этому возможна работа со сложными ИИ-моделями, агентами ИИ, рассуждающими системами и пр. Среди других вариантов использования названы генерация фотореалистичных видеоматериалов и симуляция детализированного 3D-окружения для робототехнических сред и самоуправляемых транспортных средств.
26.06.2025 [12:00], Сергей Карасёв
Вычислительный модуль iMX8M Mini DX-M1 оснащён ИИ-ускорителем Deepx DX-M1Компания Virtium Embedded Artists анонсировала вычислительный модуль iMX8M Mini DX-M1 SoM, предназначенный для использования в составе систем машинного зрения с поддержкой ИИ. Это могут быть дроны, платформы видеонаблюдения и обеспечения безопасности, средства автоматизированного контроля и мониторинга, транспортные комплексы и пр. В основу изделия положен чип NXP i.MX 8M Mini с четырьмя ядрами Arm Cortex-A53 с тактовой частотой 1,6 ГГц (индустриальная версия) или 1,8 ГГц (коммерческий вариант) и ядром реального времени Cortex-M4F с частотой 400 МГц. Предусмотрены графические блоки Vivante GC320 2D GPU и Vivante GCNanoUltra 2D/3D GPU с поддержкой OpenVG 1.1, OpenGL ES 2.0, а также VPU-модуль с возможностью декодирования видео 1080p60 H.265, H.264, VP8, VP9 и кодирования материалов 1080p60 H.264, VP8. Объём оперативной памяти LPDDR4-3000 составляет 2 Гбайт, вместимость встроенного флеш-накопителя eMMC — 16 Гбайт. 
Источник изображения: Virtium Embedded Artists Особенностью новинки является наличие ИИ-ускорителя Deepx DX-M1 AI Booster, обеспечивающего производительность до 25 TOPS. Этот NPU функционирует на частоте 1 ГГц и использует 4 Гбайт памяти LPDDR5-5600. Модуль iMX8M Mini DX-M1 наделён сетевым 1GbE-контроллером Realtek RTL8211FDI, а опционально может быть добавлен адаптер Murata LBEE5HY2FY (2FY), отвечающий за поддержку Wi-Fi 6E (802.11a/b/g/n/ac/ax) и Bluetooth 5.4 (BR/EDR/BLE). Предусмотрены интерфейс SDIO на основе чипсета Infineon CYW55513, а также интерфейсы MIPI CSI (4 линии) и MIPI-DSI (4 линии; до 1080p60). Изделие имеет размеры 82 × 50 × 5 мм. Диапазон рабочих температур у индустриальной версии простирается от -40 до +85 °C, у коммерческой — от 0 до +70 °C. Для модуля iMX8M Mini DX-M1 будет доступна сопутствующая плата с набором разъёмов, включая порты USB.
26.06.2025 [08:46], Руслан Авдеев
Рынок ЦОД стал настолько привлекательным, что даже высокий порог входа не останавливает неквалифицированных инвесторовПривлекательность инвестиций в дата-центры во многом обусловлена почти гарантированной выручкой при их сдаче в аренду. По мнению инвесторов, когда контракты с арендаторами подходят к концу, клиенты обычно предпочитают оставаться в том же ЦОД, сообщает The Register. Ажиотаж вокруг ИИ привлекает на рынок ЦОД всё новые инвестиционные компании, увидевшие возможность заработать на растущем спросе. Управляющий директор Macquarie Asset Management Наталия Акст (Natalia Akst) высоко оценила финансовую привлекательность рынка дата-центров, при этом отметив, что порог входа на него довольно высок. Сама Macquarie действует на рынке уже несколько лет. Как заявила Акст, при оценке активов факторами их выбора для инвестиций является их критическая важность для общества, стабильное поступление выручки и, наконец, высокий порог входа с низким уровнем конкуренции. В случае с ЦОД порог как раз довольно высок — требуются большие капиталовложения, большие усилия, доступ к электроэнергии — не все компании «с улицы» способны войти в этот бизнес. 
Источник изображения: Glenov Brankovic/unsplash.com Вместе с тем в некоторых регионах строительство новых дата-центров становится всё сложнее из-за нехватки подходящих земель или электроэнергии. Впрочем, это не отпугивает инвесторов — если препятствия удаётся преодолеть, по окончании действия контрактов клиенты обычно предпочитают не менять локацию, поскольку перейти на другую площадку бывает довольно трудно и невыгодно по ряду причин. Ранее в текущем году Macquarie заявила об инвестициях более $17 млрд в два американских оператора ЦОД. Из них $5 млрд достанется Applied Digital, ещё $12 млрд пойдут на расширение Aligned Data Centers. В первую очередь речь идёт о средствах под управлением Macquarie. Ещё одним важным инвестором является Blackstone, вложившая в 2024 году £10 млрд ($13,4 млрд) в крупный ИИ ЦОД на северо-востоке Англии — потенциально «крупнейший дата-центр в Европе». Впрочем, некоторые полагают, что ажиотаж может привести к возникновению «пузыря» — на рынок «из ниоткуда» приходят инвесторы, не имеющие никакого опыта и представления об ИИ и ЦОД. Ранее председатель Alibaba Group Джо Цай (Joe Tsai) выразил обеспокоенность по поводу огромных вливаний в строительство ЦОД, предупредив, что его объёмы могут превысить реальный спрос. Бизнесмен подчеркнул, что многие привлекают средства для строительства, даже не имея покупателя или арендатора, определённых ещё до начала работ. Впрочем, сама Alibaba намерена потратить на облачную и ИИ-инфраструктуру $52 млрд в следующие три года. |
|

