Материалы по тегу: s
|
24.03.2026 [15:25], Руслан Авдеев
Работа облака AWS в Бахрейне снова нарушена в результате активности беспилотниковКомпания Amazon объявила, что региональное подразделение Amazon Web Services (AWS), расположенное в Бахрейне, пострадало от «нарушения работы», связанного с текущим конфликтом на Ближнем Востоке. Это уже второй случай за месяц, когда в регионе страдает инфраструктура ЦОД компании, напоминает Reuters. Сбой в работе AWS вызван активностью в районе ЦОД беспилотников. Впрочем, пока подробностей нет, а Amazon пока не ответила на запрос о том, был ли объект в Бахрейне непосредственно атакован беспилотниками или сбой вызван ударами дронов по объектам в близлежащей округе. Компания помогает клиентам перевести свои данные в другие регионы AWS, пока работа не будет восстановлена, но масштаб ущерба и вероятная продолжительность отсутствия обслуживания не разглашаются. Регион AWS в Бахрейне пострадал после начала активной фазы конфликта на Ближнем Востоке уже второй раз. Ранее в марте AWS объявила, что зоны доступности в Бахрейне и ОАЭ пострадали в результате удара БПЛА, оставшись без электроснабжения. Сообщалось, что компания работает над восстановлением работоспособности инфраструктуры, включая перенос вычислительных нагрузок в другие облачные регионы. 
Источник изображения: Afsal Shaji/unsplash.com По данным Reuters, удар по объекту в ОАЭ носит знаковый характер — это первый случай, когда военные действия нарушили работу объекта одной из крупнейших американских технологических компаний. Из-за структурных повреждений Amazon ориентировалась на «длительный» период восстановления работоспособности. Сообщается, что удары «причинили структурный ущерб, нарушили подачу электричества, а в некоторых случаях потребовалось тушение пожаров, что вызвало дополнительный ущерб от воды». На момент первых атак Amazon заявила, что расположенный в Бахрейне регион пострадал от удара беспилотника «в непосредственной близости» от одного из объектов компании.
23.03.2026 [14:20], Сергей Карасёв
DDoS нового уровня: Curator нейтрализовала длительную атаку в 2 Тбит/с на платформу онлайн-ставокКомпания Curator, специализирующаяся на обеспечении доступности интернет-ресурсов и нейтрализации DDoS-атак, нейтрализовала масштабную DDoS-атаку типа UDP flood, направленную на организацию из сегмента «Онлайн-ставки». Пиковые значения объёма вредоносного трафика достигали 2 Тбит/с и около 1 млрд пакетов в секунду. При этом атака сохраняла высокую интенсивность более 40 минут. В ходе инцидента, произошедшего в середине марта, было зафиксировано 11 всплесков трафика, четыре из которых превышали 1 Тбит/с. Такая структура указывает на многоэтапный характер атаки и попытки поддерживать длительное интенсивное давление на инфраструктуру жертвы. 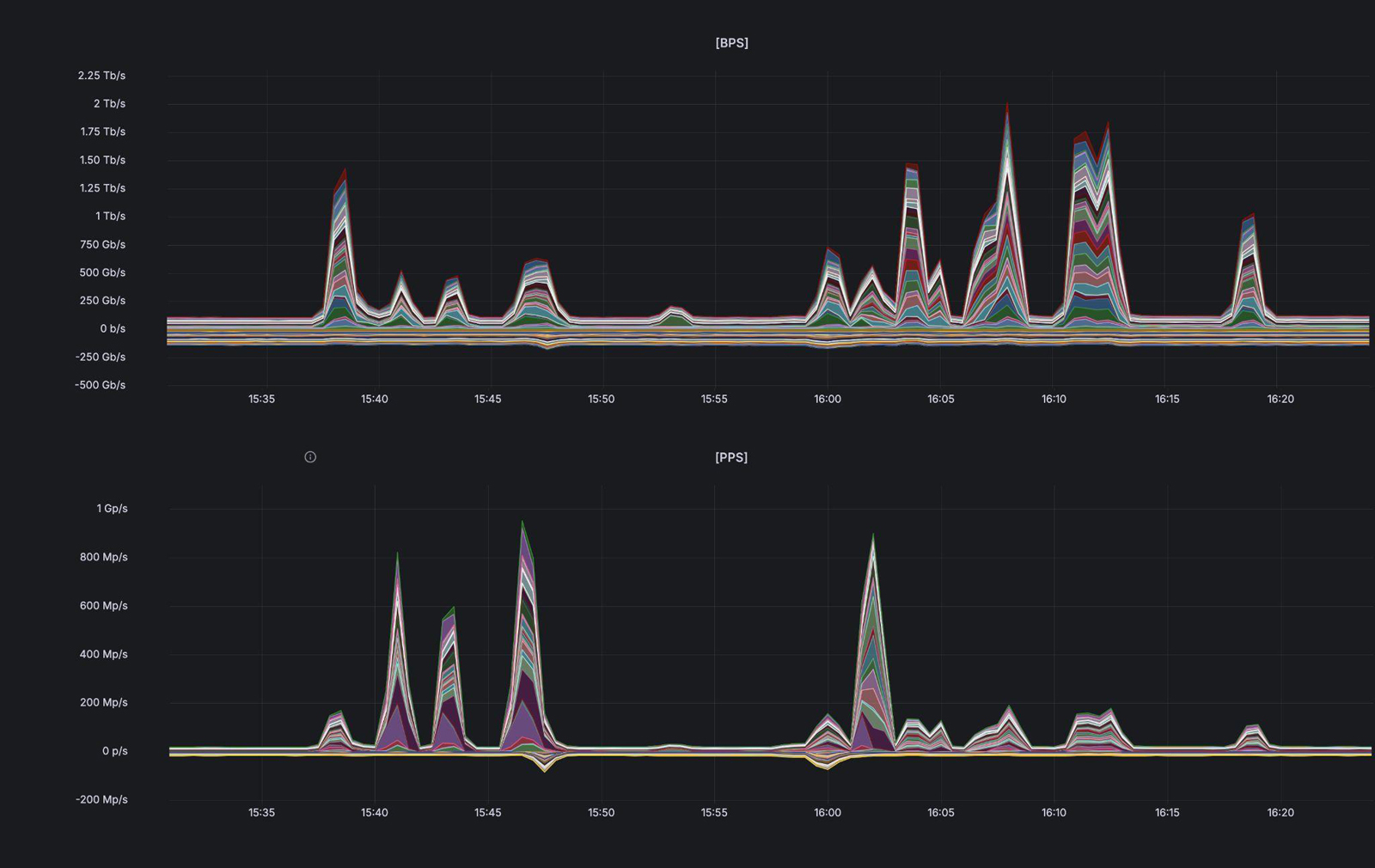
Источник изображения: Curator Это важное изменение: ранее в случае атак подобного масштаба пиковая интенсивность, как правило, сохранялась лишь считанные секунды. Злоумышленники экономили ресурсы и быстро прекращали высокоинтенсивное воздействие как в случае успеха атаки — уже деградировавший сервис можно поддерживать в таком состоянии меньшими объемами вредоносного трафика, — так и в случае, когда они не могли добиться своей цели, чтобы не расходовать ресурсы впустую. В данном случае повторяющиеся пики свидетельствуют о попытках атакующих адаптировать стратегию и добиться эффекта за счёт продолжительного воздействия. Несмотря на их усилия, Curator удалось эффективно нейтрализовать атаку и обеспечить непрерывную доступность защищаемого сервиса. Как показывает статистика, масштаб DDoS-атак продолжает расти. Этот тренд во многом обусловлен снижением стоимости проведения атак: использование ИИ-инструментов и IoT-ботнетов позволило значительно удешевить генерацию вредоносного трафика — по некоторым оценкам, до 95 % за последний год. В результате злоумышленники могут не только запускать атаки высокой интенсивности чаще, но и поддерживать их дольше. «Терабитные DDoS-атаки больше не являются редкостью: применение атакующими ИИ и дешёвых IoT-ботнетов значительно снизило стоимость их проведения. Как показывает данный инцидент, это меняет характер атак: злоумышленники теперь способны не только создавать пики трафика в несколько Тбит/с, но и поддерживать высокую интенсивность в течение длительного времени. Это подчёркивает необходимость использования масштабируемой и эффективной DDoS-защиты», — отмечает Дмитрий Ткачев, генеральный директор Curator.
23.03.2026 [12:04], Сергей Карасёв
Мини-ПК ASUS ExpertCenter PN55 получил чип AMD Ryzen AI 400 с ИИ-производительностью до 91 TOPSКомпания ASUS анонсировала компьютер небольшого форм-фактора ExpertCenter PN55, предназначенный для использования в бизнес-сфере. Устройство, выполненное на аппаратной платформе AMD, подходит для работы с ИИ-приложениями. Новинка будет предлагаться в виде barebone-систем и в полностью укомплектованных конфигурациях. Применён процессор Ryzen AI 400 поколения Gorgon Point. В частности, максимальная конфигурация включает чип Ryzen AI 9 HX 470, который объединяет 12 ядер (24 потока инструкций) с базовой частотой 2 ГГц и максимальной частотой 5,2 ГГц. В состав изделия входят графический блок Radeon 890M с частотой 3,1 ГГц и нейропроцессорный узел (NPU) с производительностью 60 TOPS. Общее ИИ-быстродействие (с учётом ядер CPU и GPU) достигает 91 TOPS. 
Источник изображений: ASUS Компьютер оснащён двумя слотами SO-DIMM для модулей оперативной памяти DDR5-5600 суммарным объёмом до 96 Гбайт. Могут быть установлены два SSD типоразмера M.2 2280 с интерфейсом PCIe 4.0 x4 (NVMe) вместимостью до 2 Тбайт каждый. В оснащение входят двухпортовый сетевой адаптер 2.5GbE (RTL8125BG), звуковой кодек Realtek ALC8233, контроллер беспроводной связи MediaTek MT7922 (Wi-Fi 6E и Bluetooth 5.4) или MediaTek MT7925 (Wi-Fi 7 и Bluetooth 5.4).  На фронтальную панель выведены порт USB 3.1 Type-C (10 Гбит/с) и два порта USB 3.1 Type-A (10 Гбит/с), а также комбинированное аудиогнездо на 3,5 мм. В тыльной части сосредоточены порты USB4 (40 Гбит/с; поддержка DisplayPort 2.1 и PD с мощностью 100 Вт), USB 3.1 Type-A, USB 2.0, HDMI 2.1, два интерфейса DisplayPort 1.4, два гнезда RJ45 для сетевых кабелей. Питание подаётся через DC-коннектор от внешнего блока мощностью 120 Вт. Компьютер имеет размеры 130 × 130 × 34 мм и весит 530 г. Говорится о совместимости с Windows 11 и Windows 11 IoT Enterprise. Допускается монтаж посредством крепления VESA — например, на заднюю стенку монитора.
22.03.2026 [13:10], Сергей Карасёв
Почти втрое быстрее NVIDIA H20: Huawei представила ИИ-ускоритель Atlas 350 для инференсаКомпания Huawei Technologies, по сообщению газеты South China Morning Post (SCMP), представила ускоритель Atlas 350, предназначенный для ИИ-инференса. Утверждается, что в таких задачах новинка обеспечивает прирост производительности до 2,8 раза по сравнению с NVIDIA H20. Известно, что решение Atlas 350 выполнено на чипе Ascend 950PR. Заявленная ИИ-производительность в формате FP4 достигает 1,56 Пфлопс. Показатели быстродействия в других режимах пока не раскрываются, но ранее говорилось об 1 Пфлопс в FP8. Как отмечается, Huawei использует собственную память HBM. Её объём в зависимости от конфигурации ускорителя составляет до 128 Гбайт, пропускная способность — 1,6 Тбайт/с. Прочие технические характеристики не приводятся. Ускоритель Atlas 350 оптимизирован для предварительного заполнения (Prefill) в ходе инференса — это наиболее ресурсоёмкая фаза работы больших языковых моделей (LLM) в рамках процесса генерации контента: на данном этапе производится обработка входного запроса пользователя. Скорость выполнения предварительного заполнения напрямую влияет на показатель TTFT (Time To First Token), то есть, на время, прошедшее с момента ввода запроса до начала ответа. Таким образом, решение Atlas 350 подходит для ИИ-приложений реального времени и агентных систем. 
Источник изображения: Huawei Huawei также заявила о планах масштабного обновления своих СХД, включая решения OceanStor Dorado и Pacific 9926 класса All-Flash. Кроме того, компания готовит платформу FusionCube A1000, которая поможет малым и средним предприятиям быстро разворачивать ИИ-системы. «Если первая половина эпохи ИИ была сосредоточена на вычислительной мощности, то вторая половина будет определяться данными. В 2026 году Huawei продолжит модернизацию своих СХД и будет активно участвовать в крупных национальных проектах по формированию соответствующей инфраструктуры», — говорит Юань Юань (Yuan Yuan), президент подразделения по хранению данных Huawei.
21.03.2026 [13:08], Сергей Карасёв
От чистки ковров к СЖО: Ecolab планирует купить CoolIT почти за $5 млрдАмериканская компания Ecolab, по сообщению Datacenter Dynamics, рассматривает возможность приобретения поставщика систем жидкостного охлаждения CoolIT Systems. Стоимость сделки может составить $4,75 млрд, а завершить транзакцию планируется позднее в текущем году. В настоящее время CoolIT принадлежит фондам, управляемым инвестиционной компанией KKR. Последняя приобрела разработчика СЖО в 2023 году: тогда актив оценивался в $270 млн. В начале марта 2026-го стало известно о том, KKR намерена продать CoolIT, получив при этом около $3 млрд. Теперь же говорится, что стоимость сделки может и вовсе составить почти $5 млрд. Ecolab (ранее известная как Economics Laboratory), базирующаяся в Миннесоте, была основана более века назад — в 1923 году. Изначально фирма специализировалась на поставках средств для быстрой очистки ковровых покрытий в различных помещениях, таких как гостиничные номера. Сейчас Ecolab предлагает продукцию и услуги по очистке и мониторингу воды для ряда отраслей, включая пищевую промышленность, здравоохранение, гостиничный бизнес и производство. В ноябре 2025-го компания представила собственные решения в области СЖО. 
Источник изображения: CoolIT Предполагается, что, объединив технологии CoolIT с опытом Ecolab в области водоснабжения, химии и цифрового обслуживания, стороны смогут предложить клиентам комплексные системы охлаждения, повышающие эффективность и надёжность при одновременном сокращении потребления воды и энергии. По оценкам Ecolab, на фоне быстрого внедрения СЖО в дата-центрах для ИИ-задач выручка CoolIT в течение ближайшего года достигнет $550 млн. Сделка потенциально позволит Ecolab существенно увеличить продажи в соответствующей области.
20.03.2026 [11:44], Сергей Карасёв
Платформа NVIDIA DGX Rubin NVL8 использует процессоры Intel Xeon 6Корпорация Intel сообщила о том, что в составе платформы NVIDIA DGX Rubin NVL8 для агентного ИИ применяются CPU поколения Xeon 6. Эти чипы отвечают за критически важные функции, такие как управление памятью, оркестрация задач и распределение рабочей нагрузки. Система DGX Rubin NVL8 несёт на борту два процессора Xeon 6776P семейства Granite Rapids. Изделия содержат 64 вычислительных ядра с возможностью одновременной обработки до 128 потоков инструкций. Базовая тактовая частота составляет 2,3 ГГц, максимальная — 3,9 ГГц. В режиме Priority Core Turbo (PCT) с восемью ядрами частота достигает 4,6 ГГц. Показатель TDP равен 350 Вт. CPU специально оптимизированы Intel для ИИ-узлов. «Intel Xeon 6 обеспечивает превосходную производительность, эффективность и совместимость с обширной экосистемой программного обеспечения x86, на которую полагаются клиенты при выполнении инференса в масштабе», — говорит Джефф Маквей (Jeff McVeigh), корпоративный вице-президент и генеральный директор стратегических ЦОД-программ Intel. 
Источник изображения: NVIDIA В состав DGX Rubin NVL8 входят восемь ускорителей Rubin с суммарным объёмом памяти 2,3 Тбайт (пропускная способность — 160 Тбайт/с). Задействованы восемь однопортовых адаптеров NVIDIA ConnectX-9 VPI (до 800 Гбит/с NVIDIA Infiniband и Ethernet), а также два DPU NVIDIA BlueField-4. Общая пропускная способность шины NVIDIA NVLink достигает 28,8 Тбайт/с. Энергопотребление — приблизительно 24 кВт. Заявленное ИИ-быстродействие на задачах инференса NVFP4 составляет до 400 Пфлопс, при обучении моделей NVFP4 — 280 Пфлопс, при обучении FP8/FP6 — 140 Пфлопс. Среди поддерживаемого софта упомянуты NVIDIA DGX OS, Ubuntu, Red Hat Enterprise Linux, Rocky Linux.
17.03.2026 [19:23], Руслан Авдеев
Amazon и NVIDIA расширят сотрудничество: в течение года AWS развернёт более 1 млн ИИ-ускорителей NVIDIAAWS и NVIDIA анонсировали расширение технологического сотрудничества. Речь идёт о взаимодействии в сфере ускоренных вычислений, технологий интерконнекта, настройки ИИ-моделей и инференса. План включают развёртывание AWS в облачных регионах по всему миру более 1 млн новых ИИ-ускорителей NVIDIA, в т.ч. семейств Blackwell и Rubin, и сетевых технологий NVIDIA Spectrum. Ведётся подготовка к запуску новых инстансов EC2 на основе ускорителей NVIDIA RTX Pro 4500 Blackwell Server Edition. AWS стала первым крупным облачным провайдером, анонсировавшим поддержку этих ускорителей. Эти инстансы предназначены для аналитики, «говорящих» ИИ-систем, генерации контента, рекомендательных систем, видеостриминга, видеорендеринга и др. Они будут построены на архитектуре AWS Nitro С ростом инфраструктуры ключевой проблемой становится взаимодействие между ускорителями NVIDIA и AWS Trainium. Компании объявили о поддержке NVIDIA Inference Xfer Library (NIXL) и AWS Elastic Fabric Adapter (EFA), что позволяет ускорить распределённый инференс ИИ-моделей на EC2. Подобная архитектура распределённого инференса позволяет эффективно совмещать вычисления и передачу данных, снижать задержки и максимизировать использование ИИ-ускорителей. NIXL с EFA интегрируются с популярными открытыми фреймворками, включая NVIDIA Dynamo, vLLM и SGLang. 
Источник изображения: AWS Дополнительно AWS и NVIDIA объявили об использовании Apache Spark в конфигурации Amazon EMR на Amazon EKS с инстансами G7e на основе ускорителей NVIDIA RTX Pro 6000 Blackwell, что втрое ускорит аналитику данных. При этом сохраняется совместимость с имеющимися приложениями Spark. Наконец, компании объявили о расширении поддержки ИИ-моделей NVIDIA Nemotron в Amazon Bedrock с адаптацией моделей для юриспруденции, здравоохранения, финансов и других специализированных областей. Вся инфраструктура управляется Bedrock, что значительно упрощает задачи разработчиков. Вскоре ожидается появление гибридной MoE-модели NVIDIA Nemotron 3 Super для финансовых сервисов, кибербезопасности, ретейла, разработки ПО и др. В целом компании создали полный стек ИИ-инфраструктуры — от ИИ-ускорителей и сетей до управляемых сервисов. Это позволит клиентам быстрее внедрять ИИ-решения, не конструируя инфраструктуру из разрозненных компонентов. Как сообщает Datacenter Dynamics, в феврале 2026 года глава AWS Мэтт Гарман (Matt Garman) заявил, что компания всё ещё использовала устаревшие ускорители NVIDIA A100 в некоторых серверах, поскольку спрос был высок даже на них. Широкий доступ к NVIDIA Blackwell Ultra появился в декабре 2025 года, в скором будущем планируется организовать доступ и к ускорителям Rubin. В то же время компания намерена инвестировать в собственные ускорители Trainium. В феврале OpenAI объявила, что будет использовать 2 ГВт мощностей на основе Trainium и других ускорителей в облаке AWS, во многом благодаря $50 млрд инвестиций со стороны Amazon.
17.03.2026 [11:02], Руслан Авдеев
Meta✴ потратит до $27 млрд на ИИ-инфраструктуру NebiusMeta✴ Platforms в течение пяти лет намерена заплатить $27 млрд за ИИ-инфраструктуру, доступ к которой предоставит облачный провайдер Nebius Group, базирующийся в Нидерландах, сообщает Bloomberg. В Meta✴ подтвердили сделку с Nebius. Nebius — стратегический партнёр NVIDIA, с 2027 года предоставит Meta✴ мощности ЦОД на $12 млрд, ещё до $15 млрд Meta✴ потратит на покупку мощностей, которые облачный провайдер строит для сторонних клиентов. Это один из крупнейших «разовых» контрактов, заключенных Meta✴, что подчёркивает стремление компании развиваться в сфере ИИ. Недавно появилась информация, что компания сократит более 20 % штата из-за высоких затрат на ИИ-проекты. В 2025 году она уже заключила сделку с Nebius на $3 млрд. За последние 12 месяцев акции Nebius выросли в цене в четыре раза, а на фоне новостей подорожали на 15 %, а Meta✴ — на 2,8 %. 
Источник изображения: Nebius Предполагается, что Meta✴ и её крупнейшие конкуренты потратят в 2026 году около $650 млрд на строительство ЦОД и покупку другой инфраструктуры на фоне взрывного роста спроса на ИИ-сервисы в ближайшие годы. Для Meta✴ ИИ в последнее время является ключевым приоритетом, и компания вкладывает значительные средства в конкуренцию с OpenAI, Google и др. С начала года заключены соглашения с NVIDIA и AMD о создании ИИ-инфраструктуры. Кроме того, Meta✴ разрабатывает и собственные ИИ-ускорители. В 2025 году заявлялось, что к 2028 году Meta✴ потратит на инфраструктурные инициативы в США $600 млрд. Для этого она будет использовать средства, вырученные от рекламного бизнеса и внешнее финансирование. Компания разрабатывает также и собственные ИИ-модели и др. 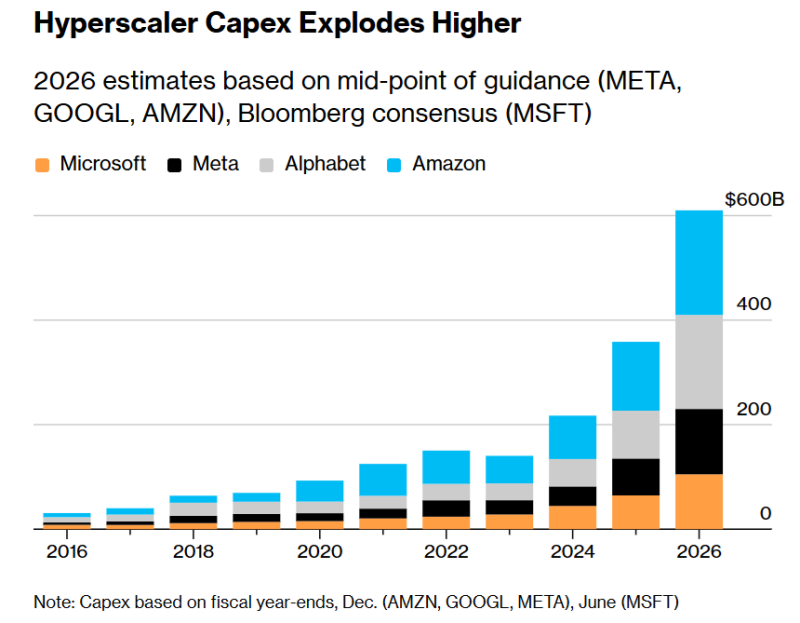
Источник изображения: Bloomberg Nebius, отделившаяся от «Яндекса» в 2024 году, — один из немногих новичков, очень успешно воспользовавшихся бумом ИИ-технологий. При этом немаловажную роль играет NVIDIA, активно инвестирующая в стартапы, конкурирующие с гиперскейлерами вроде Google и Amazon (AWS). На днях NVIDIA объявила о намерении инвестировать в Nebius $2 млрд, что привело к росту акций последней на 16 %. Значительная часть инвестиций NVIDIA была направлена компаниям, покупающим её собственные чипы. Это вызвало критику экспертов рынка, опасающихся, что такие инвестиции подпитывают создание ИИ-пузыря. Например, в январе NVIDIA сообщила об инвестициях $2 млрд в неооблачного провайдера CoreWeave, конкурирующего с Nebius, средства предназначались на внедрение ИИ-ускорителей самой NVIDIA. В 2026 году компания вложила $30 млрд в OpenAI, а также принимала участие в очередном раунде финансирования британской Nscale, желавшей привлечь $2 млрд. В январе сообщалось, что затраты Meta✴ на связанные с ИИ расходы в 2026 году составят от $115 до $135 млрд, это превышает прогнозы аналитиков в $110,7 млрд и почти вдвое больше, чем капитальные затраты компании в 2025 году, которые составили $72,2 млрд. Роста затрат направлен на поддержку подразделения Meta✴ Superintelligence Labs (MSL), а также основной повседневной деятельности компании.
17.03.2026 [00:52], Владимир Мироненко
TrueNAS Connect обеспечит пользователям Community Edition и сторонних СХД бесплатный доступ к продвинутым функциям TrueNAS EnterpriseКомпания TrueNAS (ранее — iXsystems) объявила о доступности сервиса TrueNAS Connect, который позиционируется как своего рода мост для доступа к корпоративным функциям хранения данных TrueNAS без необходимости приобретения её оборудования. TrueNAS Enterprise отличается от бесплатной TrueNAS Community Edition для NAS-устройств и других систем хранения данных, основанной на Linux, расширенными возможностями, включая проактивное оповещение, расширенное управление, безопасность уровня оборонных стандартов, повышение производительности, интеграцию со сторонним программным обеспечением и т. д. Доступ к этим функциям ранее можно было получить только через коммерческие партнёрские отношения с TrueNAS в рамках бизнес-модели Open-Core, например приобретая устройства TrueNAS Enterprise — различные серверы и решения для хранения данных с предустановленной TrueNAS Enterprise, предоставляющей самый продвинутый набор функций для этой открытой платформы. «TrueNAS Connect был представлен в начале 2026 года как решение для мониторинга и управления, расширяющее и улучшающее вашу установку TrueNAS за счёт дополнительных веб-функций, а также упрощающее процесс развёртывания для новых пользователей. В течение 2026 года TrueNAS Connect также станет мостом между нашей бесплатной версией Community Edition и нашими корпоративными устройствами Enterprise», — отметила компания. 
Источник изображения: TrueNAS Новое решение позволяет клиентам пользоваться расширенными функциями без необходимости приобретения устройств TrueNAS Enterprise. Это является подходящим вариантом для тех, кто уже инвестировал в другое оборудование или вынужден использовать его в соответствии с требованиями организации, но хочет максимально использовать возможности TrueNAS в корпоративной среде, отметил ресурс Phoronix. Компания пояснила, что Community Edition предназначена для энтузиастов, домашних лабораторий, студентов и самостоятельных технических команд, которым нужна мощная платформа хранения данных без лицензионных сборов. Она включает в себя полноценную OpenZFS с поддержкой файловых, блочных и объектных протоколов, виртуальных машин, Docker, приложений и многим другим. Версия будет оставаться бесплатной — ничего не удаляется, и постоянно добавляются новые open source функции. В свою очередь, TrueNAS Enterprise предназначена для ИТ-руководителей и профессиональных организаций, которым нужны готовые к использованию высокодоступные устройства, безопасность уровня оборонного предприятия, выделенная поддержка и глубокая интеграция с такими платформами, как VMware, Proxmox и Veeam. TrueNAS Connect предоставляет новые возможности для опытных пользователей: профессионалов, малых предприятий и т. д. «Это мост, обеспечивающий возможности корпоративного класса, такие как расширенный мониторинг, веб-доступ, проактивные оповещения, управление несколькими системами и защита от программ-вымогателей, для вашего собственного оборудования», — сообщила TrueNAS, добавив, что планирует в ближайшие годы предложить больше дополнительных функций для опытных пользователей. TrueNAS Connect включает бесплатный уровень Foundation, который охватывает базовую функциональность, а также платные уровни Plus и Business. Последний появится в будущем, он ориентирован на команды, которым требуется больше возможностей. Он также значительно упрощает установку Community Edition на оборудование bare metal. Компания отметила, что бизнес-модель Open-Core не меняется. ПО TrueNAS остаётся основой для всех трёх версий. Многие новые функции будут автоматически включены в бесплатную версию Community Edition. TrueNAS Connect управляет лицензированием и разрешениями, которые обеспечивают возможности Enterprise, выходящие за рамки бесплатного уровня.
14.03.2026 [18:42], Владимир Мироненко
Царь-ускорители Cerebras в облаке AWS пятикратно ускорят инференс ИИAmazon Web Services (AWS) и Cerebras Systems объявили о сотрудничестве, «которое позволит создать в ближайшие месяцы самые быстрые решения для инференса в системах генеративного ИИ и рабочих нагрузок машинного обучения». Решение, которое будет развёрнуто на платформе Amazon Bedrock в ЦОД AWS, объединяет серверы на базе ускорителей Trainium, системы Cerebras CS-3 на базе царь-чипов WSE-3 и DPU EFA. Ожидается, что эта технология увеличит скорость генерации результатов ИИ-моделями в пять раз. Позже в этом году AWS предложит ведущие open source решения машинного обучения и собственные ИИ-модели Amazon Nova, использующие оборудование Cerebras. Как отметил Дэвид Браун (David Brown), вице-президент по вычислительным и машинным сервисам AWS, при инференсе критическим узким местом для ресурсоёмких рабочих нагрузок, таких как помощь в кодировании в реальном времени и интерактивные приложения, остаётся скорость: «Решение, которое мы разрабатываем совместно с Cerebras, решает эту проблему: разделяя нагрузку по инференсу между Trainium и CS-3 и соединяя их с помощью EFA, каждая система делает то, что у неё лучше всего получается. В результате инференс будет на порядок быстрее и производительнее, чем сегодня». 
Источник изображения: Amazon Совместное решение использует «дезагрегацию вывода» — метод, который разделяет ИИ-инференс на два этапа: этап интенсивной обработки подсказок, или «предварительного заполнения» (процесс обработки запроса LLM), и этап генерации выходных данных, известный как «декодирование», на котором модель формирует ответ на вопрос пользователя. 
Источник изображений: Cerebras Предварительное заполнение является параллельным, вычислительно интенсивным процессом и не требует большой пропускной способности памяти. Декодирование, с другой стороны, является последовательным процессом с минимальными требованиями к вычислительным ресурсам, но интенсивно использует пропускную способность памяти. Декодирование обычно занимает большую часть времени при инференсе, поскольку каждый выходной токен должен генерироваться последовательно, отметила AWS. 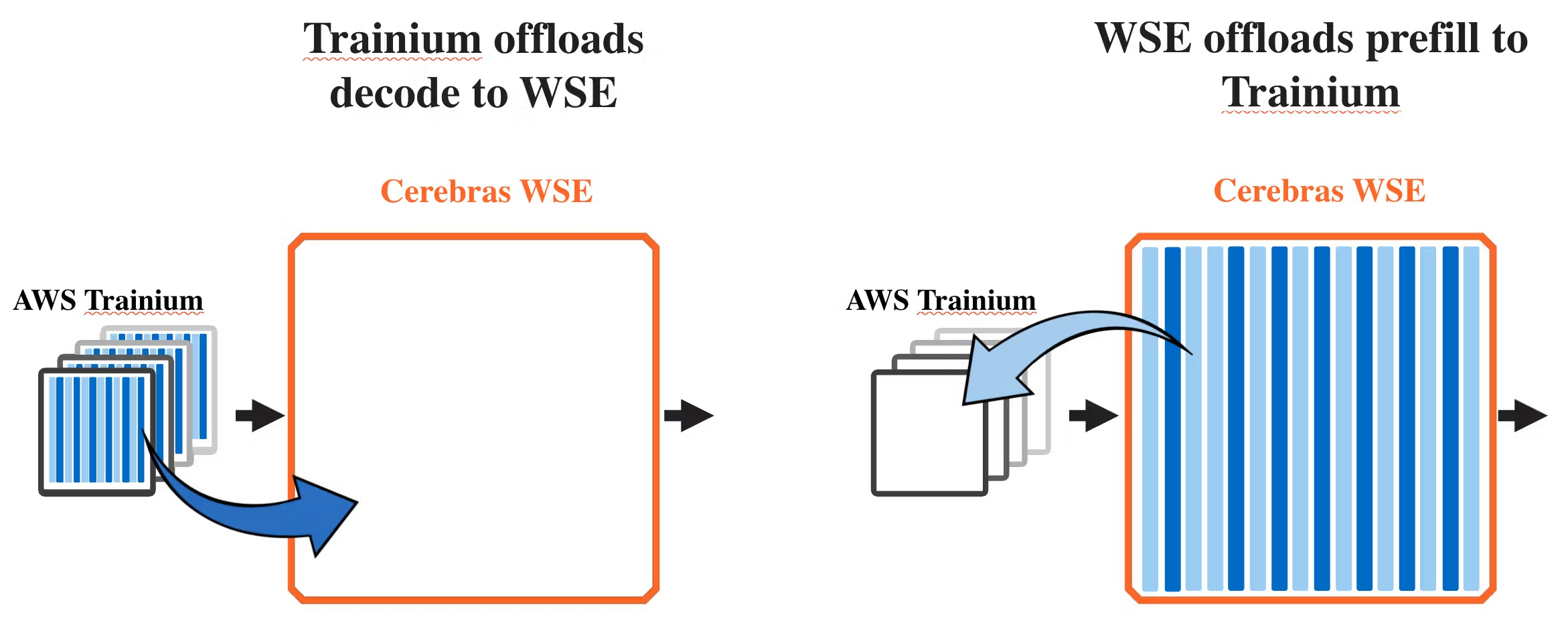 Задачи предварительного заполнения и декодирования обычно выполняются одним и тем же чипом. В дезагрегированной архитектуре AWS чипы Trainium обеспечивают этап предварительного заполнения, а чипы WSE-3 выполняют декодирование. «Дезагрегированный подход идеален, когда у вас большие, стабильные рабочие нагрузки, — сообщил в блоге директор по маркетингу продукции Cerebras Джеймс Ванг (James Wang). — Большинство клиентов используют смешанные рабочие нагрузки с различными коэффициентами предварительного заполнения/декодирования, где традиционный агрегированный подход по-прежнему идеален. Мы ожидаем, что большинство клиентов захотят иметь доступ к обоим вариантам».  Одним из главных преимуществ WSE-3 является то, что он может передавать данные между своими логическими схемами и цепями памяти быстрее, чем многие другие чипы. По данным Cerebras, WSE-3 обеспечивает внутреннюю пропускную способность памяти в 21 Пбайт/с, что значительно превышает пропускную способность NVLink для ускорителей от NVIDIA. Впрочем, у NVIDIA теперь есть ускорители Groq, которые тоже помогают ускорить инференс. Несколько недель назад Cerebras заключила с OpenAI сделку на $10 млрд по поставке чипов общей мощностью 750 МВт до 2028 года. Сделка была объявлена в период между двумя раундами финансирования, которые в совокупности принесли Cerebras более $2 млрд. Ожидается, что компания подаст заявку на IPO уже во II квартале 2026 года. Сделки с AWS и OpenAI могут способствовать повышению интереса инвесторов к листингу, отметил SiliconANGLE. |
|

