Материалы по тегу: llm
|
06.07.2026 [18:07], Владимир Мироненко
Selectel и ИТМО создали СП для разработки платформы по созданию ИИ-агентов для бизнесаSelectel и Национальный исследовательский университет ИТМО объявили о запуске совместного предприятия с целью разработки решений в сфере ИИ, в частности — платформы для создания, внедрения и промышленной эксплуатации мультиагентных систем на базе больших языковых моделей (LLM). Новая платформа позволит быстро создавать ИИ-решения под конкретные бизнес-процессы заказчиков, подключать их к корпоративным данным и системам, измерять качество работы и безопасно их развивать по мере изменения задач бизнеса. Коммерческая модель будет учитывать фактическое потребление вычислительных ресурсов и токенов. Оплата заказчиком использования ИИ-агентов будет производиться в зависимости от объёма, сложности и места выполнения работы: на инфраструктуре Selectel, в выделенном контуре или непосредственно у заказчика. Сообщается, что в штат СП войдёт проектная группа ИТМО и опытные эксперты индустрии. ИТМО выступит ключевым центром компетенций с готовыми наработками, а Selectel обеспечит финансирование проекта на сумму более 1 млрд руб., а также предоставит необходимую IT-инфраструктуру. Ранее сообщалось, что Selectel создал новую компанию для реализации ИИ-проектов — «Эмерджентные мультиагентные системы» (ООО «ЭМС»). По словам Олега Любимова, гендиректора Selectel, объединив экспертизу Selectel в построении специализированной инфраструктуры для ИИ с профильными компетенциями команды ИТМО, и действуя при этом как самостоятельный игрок, новое предприятие будет способствовать ускорению развития прикладных решений, необходимых крупному бизнесу на фоне перехода к агентной экономике ИИ-систем. 
Источник изображения: ИТМО Любимов уточнил в интервью ресурсу Forbes, что у Selectel доля в уставном капитале СП составляет ⅔, у ИТМО — ⅓. Руководитель ИТМО Александр Бухановский рассказал Forbes, что специалисты ИТМО разработали технологию, которая автоматизирует конструирование прикладных агентов ИИ и мультиагентных систем на их основе под комплексные бизнес-задачи. «Мы реализовали ИИ, который умеет делать ИИ», — отметил он. С 2020 года Selectel инвестировал в развитие ИИ-решений более 3,5 млрд руб. В ближайшие пять лет провайдер планирует увеличить финансирование проектов в сфере ИИ, выделив на эти цели 10 млрд руб. С конца прошлого года 25 % АО «Селектел» принадлежит компании «Каталитик Пипл», созданной МКПАО «Т-Технологии» и ХК «Интеррос».
01.07.2026 [18:17], Руслан Авдеев
Австрия призвала Евросоюз привлечь Anthropic на свою территорию после введённых США ограничений на передовые ИИ-моделиАвстрия предлагает властям Евросоюза расширить присутствие Anthropic на территории блока. Предложение было сделано после того, как США ввели ограничения на доступ некоторых иностранных пользователей к передовым ИИ-моделям компании. Это вновь ставит вопрос зависимости Европы от американских ИИ-технологий, сообщает eWeek. США ограничили доступ иностранным пользователям к новейшим ИИ-моделям Anthropic в июне. Фактически возможности Европы по получению доступа к критически важным зарубежным технологиям оказались под вопросом. Австрийские власти призвали государства — члены ЕС рассмотреть вариант «стратегического размещения Anthropic на территории Евросоюза». Утверждается, что ЕС может предложить компании правовую определённость, доступ к рынку, капитал и ценности, соответствующие философии самой компании. Признаётся, что инициативу неизбежно встретят скептически, тем более что механизмов конкретной реализации плана не предоставлено. Тем не менее подчёркивается, что речь идёт о стратегическом технологическом будущем Европы, вопрос не в том, легко ли это осуществить, а в том, готовы ли европейцы сами стать «архитекторами своего технологического будущего» или так и будут полагаться на решения, принятые в других странах. Предложение стало отражением обеспокоенности европейских элит зависимостью от зарубежных ИИ-продуктов, доступность которых может измениться из-за принятых вне блока решений. Ограничения могут повлиять не только коммерческие аспекты, но и на вопросы национальной безопасности и экспортной политики. Европейские власти уже обсуждают возникшую проблему с представителями США, в то же время продвигая развитие собственных облачных технологий, ИИ и полупроводниковой индустрии. 
Источник изображения: Jacek Dylag/unsplash.com По некоторым данным, размещение Anthropic в ЕС рассматривается Австрией как возможность привлечь в Европу высококвалифицированных специалистов, сохранить инвестиции и помочь формированию стандартов в сфере ИИ, не вытесняя собственно европейские ИИ-бизнесы. Неопределённость может подтолкнуть бизнес к диверсифицировать поставщиков ИИ-решений, будет способствовать росту инвестиций в местную ИИ-инфраструктуру и усилит внимание к европейским проектам, связанным с искусственным интеллектом. Предложение расширяет концепцию европейского цифрового суверенитета. Вместо того, чтобы полагаться только на «выращивание» собственных лидеров ИИ-индустрии, Австрия призывает привлекать извне к работе в Европе уже состоявшиеся бизнесы. Впрочем, даже если Anthropic расширит своё присутствие в Европе, остаётся ряд нерешённых вопросов в юридической и регуляторной плоскостях. В том числе непонятно, будут ли в этом случае по-прежнему действовать нормы экспортного контроля США. В любом случае сам факт дискуссии на государственном уровне показывает, что доступность ИИ становится вопросом не только и не столько технологическим, сколько геополитическим. В своё время агентство Gartner сообщало, что суверенное облако могут позволить себе только США и Китай, но не Европа. Ещё в апреле, до введения США ограничений, британское правительство пригласит Anthropic расширить присутствие в Соединённом Королевстве, желая извлечь выгоду из имевшего места конфликта многомиллиардного стартапа с американским военным ведомством.
22.06.2026 [19:14], Владимир Мироненко
Законопроект о регулировании ИИ в России кардинально сократили и упростили22 июня в комиссии правительства по законопроектной деятельности пройдёт рассмотрение законопроект «О поддержке развития технологий ИИ в РФ», который, по словам источника «Коммерсанта», должны внести в Госдуму до конца недели. Сообщается, что документ претерпел значительные изменения по сравнению с первоначальным вариантом. Его сократили до 13 страниц и 13 статей, при этом действие законопроекта распространяется только на большие фундаментальные модели (LLM) с более 1 млрд параметров. Модели с меньшим количеством параметров, в том числе open source, были исключены из первоначального варианта законопроекта также, как и формулировка «доверенные» модели, после чего в нём теперь указаны только «суверенные» и «национальные». Отмечается, что от добавления в документ «доверенных» моделей для КИИ отказались, так как требования к софту, куда относится и ИИ, уже прописаны ФСТЭК и ФСБ. На объектах КИИ можно будет использовать только с «суверенные» и «национальные» модели, разработка которых может рассчитывать на господдержку. 
Источник изображения: Steve A Johnson/unsplash.com В документе указано, что «суверенная» модель ИИ может быть разработана на всех этапах только российским юрлицом и использоваться только на инфраструктуре в РФ. «Национальная» модель должна быть существенно разработана российским юрлицом, хотя её компоненты могут быть open source. Основные положения законопроекта вступают в силу с 1 сентября 2026 года, положения о полномочиях правительства (применение моделей, их определение, обязанности разработчиков и т. д.) — с 1 марта 2027 года. Если же до 1 марта 2027 года уже внедрены ИИ-модели, не подпадающие под критерии документа, переходный период для них продлён до 1 сентября 2032 года в случае, если данные обрабатываются в РФ. «Коммерсантъ» отметил, что в итоговой версии отказались от требования обеспечить маркировку синтезированного ИИ контента и усилить ответственность владельцев ИИ-сервисов за правонарушения при использовании технологии. Также из первоначальной версии были исключены вопросы, касающиеся регулирования ИИ ЦОД и практически полностью — вопросы, касающиеся авторского права.
18.06.2026 [01:45], Владимир Мироненко
NVIDIA стала лидером во всех тестах MLPerf Training 6.0Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 6.0. В нём появилось два новых теста — DeepSeek V3 и GPT-OSS 20B, что подчёркивает общеотраслевой переход к разреженным вычислениям, примером которого является архитектура MoE (Mixture-of-Experts). DeepSeek V3 — крупномасштабная MoE-модель c 671 млрд параметров, из которых 37 млрд активируются для генерации отдельного токена. Она предоставляет стандартизированную платформу для оценки эффективности обучения ведущей модели MoE с открытыми весами. GPT-OSS 20B — MoE-модель c 21 млрд параметров, из которых 3,6 млрд активируются для генерации одного токена. Она позволяет организациям оценивать сложную логику маршрутизации и шаблоны разреженных вычислений, характерные для архитектуры MoE, на аппаратных конфигурациях размером всего в один узел с восемью ускорителями. Версия MLPerf Training 6.0 установила новые рекорды по разнообразию представленных систем. Участники выложили результаты 95 уникальных систем, использующих тринадцать различных аппаратных ускорителей, 19 различных хост-процессоров и несколько различных программных фреймворков. 60 % систем были многоузловыми. При этом количество представленных облачных систем более чем вдвое больше, чем в раунде 5.1. 
Источник изображения: NVIDIA В раунде MLPerf Training v6.0 представлены заявки от 24 организаций: AMD, ASUSTeK, Azure, Cisco, CoreWeave, Dell, Fujitsu, GigaComputing, Google, HPE, Inventec, Krai, Lambda, MITAC, Nebius, Netweb Technologies India, NVIDIA, Oracle, Quanta Cloud Technologies, SCITIX, Supermicro, tinycorp, TTA и Vultr. «Мы особенно рады приветствовать участников, впервые представляющих свои результаты в MLPerf Training: Inventec, Netweb Technologies India, TTA и Vultr», — сообщил Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. NVIDIA вновь стала лидером в новом раунде MLPerf Training, причём во всех тестах, в очередной раз став единственной платформой, которая предоставила результаты по всем тестам. Также NVIDIA была единственной платформой, представившей результаты по новым тестам, при этом система NVIDIA GB300 NVL72 «установила планку производительности благодаря оптимизированным программным стекам NVIDIA и конструкции, объединяющей 72 GPU Blackwell Ultra и 36 CPU Grace с использованием NVLink и NVLink Switch». В нескольких случаях партнёры NVIDIA масштабировали систему до 8192 ускорителей Blackwell, работающих согласованно в различных ЦОД. Эти результаты подтвердили реальную надёжность платформы Blackwell в масштабируемых кластерных средах, говорит NVIDIA. 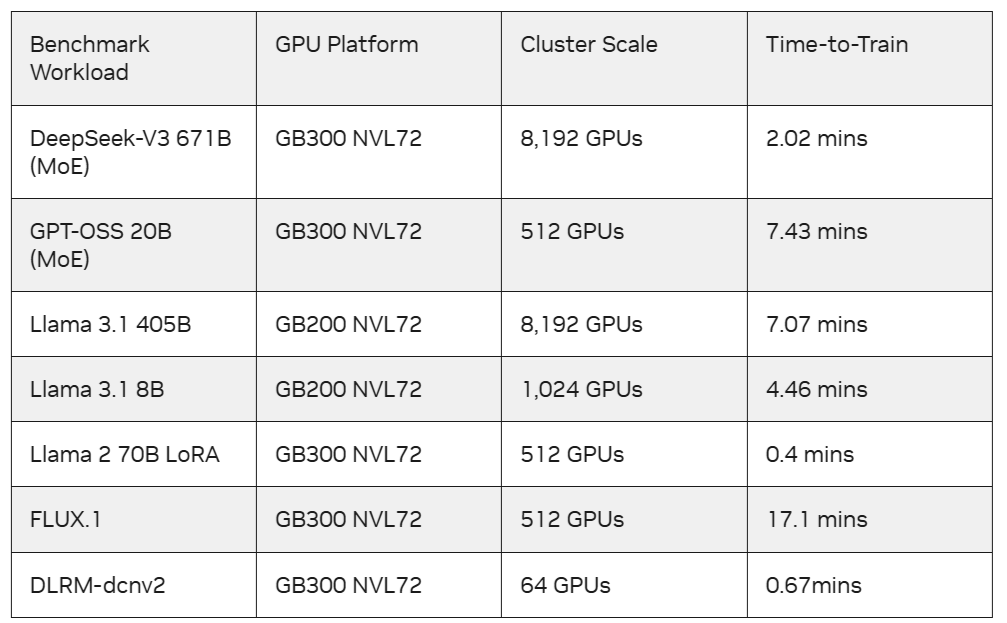
Источник изображения: NVIDIA Для достижения максимальной производительности таких моделей, как DeepSeek-V3, NVIDIA в этом раунде MLPerf Training применила несколько программных оптимизаций, включая использование итерационных графов CUDA для MoE без удаления токенов, применение CuTe DSL для продвинутых операций слияния ядер, алгоритм внимания MXFP8 для повышения производительности без ущерба для качества модели, оптимизацию маршрутизатора и оптимизацию схемы коммуникации 1F1B all-to-all overlap. Также NVIDIA оптимизировала компоновку и баланс параллельных этапов конвейера, минимизируя структурное простаивание. Для обработки DeepSeek-V3 671B компания NVIDIA использовала до 8192 GPU в системах GB200 NVL72, что стало самым масштабным результатом на основе Blackwell в MLPerf Training на сегодняшний день. NVIDIA также представила результаты на 5120 GPU с системами NVIDIA GB200 NVL72 в Llama 3.1 405B, одной из самых крупных LLM плотной архитектуры в этом бенчмарке. Результаты этого раунда также отражают тесное сотрудничество NVIDIA с компаниями-партнёрами в области системной архитектуры, сетей и ПО. Например, Microsoft Azure масштабировала обучение Llama 3.1 405B до 8192 GPU, используя системы GB200 NVL72, и достигла целевого эталонного значения за 7,07 мин., что является самым быстрым временем обучения для этого бенчмарка. А CoreWeave показала самое быстрое время обучения для DeepSeek-V3 671B, достигнув целевого качества за 2,02 мин. на 8192 GPU в составе GB300 NVL72, объединённых Spectrum-X Ethernet.
09.06.2026 [22:37], Андрей Крупин
Orion soft представил платформу StarGuard AI для безопасной работы с ИИРоссийский разработчик Orion soft выпустил шлюз безопасности StarGuard AI, предназначенный для централизованной и контролируемой работы с большими языковыми моделями (LLM) в корпоративной среде. Решение может быть актуально для крупного бизнеса, финансового сектора, промышленности, государственных организаций и компаний, внедряющих корпоративных ИИ-ассистентов, агентские системы и внутренние платформы на базе искусственного интеллекта. StarGuard AI функционирует как обратный прокси-сервер (Reverse Proxy) между пользователями и LLM-провайдерами. Каждый запрос и ответ проходят через набор детекторов до выхода за пределы защищённого контура. Шлюз помогает блокировать чувствительные данные, jailbreak- и prompt-инъекции, токсичный, запрещённый или нецелевой контент в ИИ-чатах, ассистентах, сервисах поддержки и корпоративных помощниках. Благодаря этому программный комплекс снижает репутационные риски во внутренних и клиентских ИИ-сервисах, закрывает риски утечки данных, контролирует разрешённые сценарии использования, централизует доступ к нескольким моделям и даёт прозрачный аудит всех событий. 
Источник изображения: Steve Johnson / unsplash.com Решение позволяет подключать облачные и локальные LLM, включая ChatGPT, Claude, DeepSeek, GigaChat, YandexGPT, а также любые локальные модели. Поддерживается интеграция с OpenWebUI, IDE, AI-агентами и корпоративными платформами. «Корпоративные ИИ-сервисы постепенно становятся частью критической IT-инфраструктуры, а значит требуют сопоставимого уровня контроля и защиты. StarGuard AI создаёт единый контур безопасной работы с LLM и позволяет организациям внедрять ИИ-инструменты без потери контроля над данными с политиками безопасности и нормативными требованиями», — поясняют разработчики продукта.
29.05.2026 [20:30], Руслан Авдеев
Gartner: большинство кастомных ИИ-моделей и проектов генеративного ИИ ожидает провалПо мнению Gartner, не менее половины всех проектов в сфере генеративного ИИ и создателей большинства ИИ-моделей ожидает неудача. Расходы на проекты будут выше планируемого из-за неудачных архитектурных решений и недостатка ноу-хау, а разработчики собственных моделей столкнутся с высокими затратами и другими сложностями, сообщает The Register. В докладе «Цикл хайпа вокруг генеративного ИИ» (Hype Cycle for Generative AI), в котором эксперты рассмотрели 30 ИИ-технологий, сообщается, что ни одна из них не достигла т.н. «плато производительности». На этом этапе продукты и технологии уже пережили два или три этапа эволюции, стабильны и приносят ощутимые выгоды. До достижения этого плато ИИ-технологии в своём развитии поднимаются до «Пика завышенных ожиданий» (Peak of Inflated Expectations), после чего следует спад в «Долину разочарований» (Trough of Disillusionment) и медленный подъём по «Склону просветления» (Slope of Enlightenment). По мнению Gartner, в областях вроде здравоохранения, финансов, юриспруденции и др. будут обеспечивать лучшие результаты модели, специально созданные «с нуля» под конкретную тематику, либо специально доработанные — в сравнении с универсальными моделями «общего назначения». Впрочем, подчёркивается, что создание специальных моделей требует значительных вычислительных ресурсов, специальных знаний и постоянного обслуживания. На достижение достаточной зрелости для массового применения таким моделям потребуется минимум 2–5 лет. 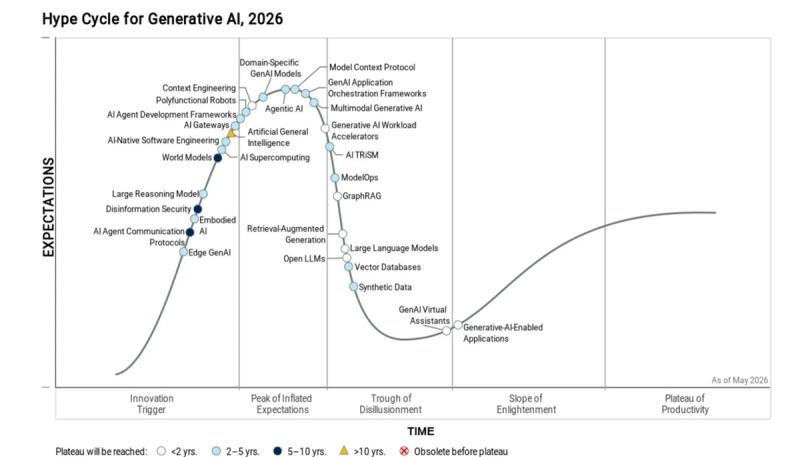
Источник изображения: Gartner Безусловный успех, по мнению Gartner, ожидает лишь ИИ-приложения вроде помощников в подготовке программного кода, создании графики и видео, а также обобщения контента. Впрочем, из-за проблем с интеллектуальной собственностью и склонностью ИИ к ошибкам, нишу ожидают некоторые проблемы. Тем не менее, Gartner уверена, что такие приложени довольно зрелые и они уже освоили более половины целевого рынка. Наименее зрелыми называются протоколы связи ИИ-агентов друг с другом и окружающей средой. Впрочем, этот сегмент довольно быстро развивается и даже уже имеется пара фаворитов. Наибольший потенциал по мнению экспертов имеют технологии защиты от дезинформации (Disinformation Security) и «Модели мира» (World Models). Технологии Disinformation Security помогают распознавать дипфейки, случаи кражи личности и создание другого фейкового контента, направленного на дискредитацию людей и организаций, а также на создание контента для кибератак и совершения других преступлений. По оценкам Gartner, до достижения зрелости этим технологиям ещё 5–10 лет. Модели мира позволяют ИИ выполнять сложные задачи прогнозирования и планирования, имитируя и понимая динамику окружающей среды. Это позволяет принимать обоснованные решения даже в условиях недостатка информации и непредвиденных обстоятельств. Такие инструменты также полезны для навигации робототехники в человеческом мире или создания видеоконтента с реалистичным отображением физики. Также Gartner считает, что организации, намеренные создавать ИИ-системы на основе открытых моделей, не получат доступ к самым передовым технологиям… если не готовы применять китайские разработки. Утверждается, что коммерциализация открытых LLM оказалась весьма сложной для их разработчиков. Многие западные технологические компании избирательно делают модели открытыми, благодаря чему все инновации в данной сфере пока сосредоточены в КНР, хотя развитие идёт и за пределами Китая.
12.05.2026 [13:24], Сергей Карасёв
Новое бизнес-подразделение OpenAI поможет клиентам во внедрении ИИГруппа OpenAI Group PBC сформировала бизнес-подразделение OpenAI Deployment Company, которое будет оказывать сторонним заказчикам услуги по внедрению ИИ-моделей и их оптимизации под конкретные задачи. Инвестиции в OpenAI Deployment Company на первом этапе составят $4 млрд при оценке этой структуры в $14 млрд. Средства поступят от самой OpenAI и более чем десяти других инвесторов, крупнейшим из которых является управляющая компания TPG. В раунде также приняли участие SoftBank Group, Bain Capital, Brookfield, Capgemini SE и McKinsey & Co. Контроль над формируемой организацией сохранит за собой OpenAI. Компания обязалась обеспечить минимальную доходность в размере 17,5% для внешних инвесторов OpenAI Deployment Company. Новая структура поможет крупным предприятиям во внедрении ИИ-моделей OpenAI. Для этого на объекты заказчиков будут направляться инженеры по развёртыванию (Forward Deployed Engineer, FDE) — специалисты, обладающие навыками разработки ПО и взаимодействия с клиентами. Такие инженеры выступают в качестве связующего звена между поставщиком продуктов и заказчиком. 
Источник изображения: unsplash.com / Growtika Внедрение ИИ-моделей на стороне клиента OpenAI намерена осуществлять в рамках многоэтапного процесса. Сначала специалисты оценят возможные варианты применения ИИ на площадке заказчика и разработают наиболее эффективные сценарии использования. Затем будет осуществлено пилотное развёртывание для «небольшого количества приоритетных рабочих процессов»: это поможет продемонстрировать отдачу от применения продуктов OpenAI. На финальном этапе произойдёт полноценное внедрение. Кроме того, по запросу клиента специалисты OpenAI Deployment Company могут осуществить сопутствующие работы, например, интегрировать ИИ-модель с существующими приложениями в IT-инфраструктуре заказчика. Для развития бизнеса OpenAI Deployment Company приобрела лондонскую фирму Tomoro AI Ltd., предоставляющую технологические услуги. В результате этой сделки, финансовые условия которой не раскрываются, OpenAI получила около 150 инженеров FDE и других технических специалистов.
21.04.2026 [20:48], Владимир Мироненко
В ВТБ призвали к партнёрству с Китаем для развития суверенного ИИРазвивать суверенные технологий ИИ в России, включая использование больших языковых моделей (LLM) и вычислительных мощностей, необходимо в партнёрстве с дружественными странами, прежде всего, с Китаем, заявил заместитель руководителя технологического блока ВТБ. Он подчеркнул, что при этом важно учитывать необходимость защиты данных россиян, которые используются при обучении ИИ. Топ-менеджер отметил, что открытые LLM, разработанные китайскими компаниями, работают «чуть лучше», чем российские модели, но их использование несёт определенные риски для технологического суверенитета, так как они созданы за пределами России. Использование российских моделей, в частности, от «Яндекса» и Сбера, снимает часть этих рисков. Вместе с тем топ-менеджер ВТБ считает, необходимо использовать лучшие технологии, чтобы не оказаться в числе отстающих: «Для того, чтобы наши модели были не хуже, мы стараемся обучать их на обезличенных данных. И считаем, что партнёрство с Китаем — это правильный возможный вариант, они действительно сейчас по многим направлениям лидируют». Это также относится к развитию суперкомпьютеров, необходимых для ИИ: «Если взять вычислительные мощности, которые есть за рубежом и которые есть у нас, понятно, что те суперкомпьютеры, которые сейчас работают, в первую очередь в США, многократно превышают те мощности, которые есть в России. И это тоже проблема». 
Источник изображения: Hanson Lu/unsplash.com Он добавил, что в рамках кооперации уже запущены большие совместные лаборатории с китайскими коллегами. Также начинают осуществлять сборку серверов в России с китайскими GPU: «Это — будущее, так как без кооперации не обойтись. Мы большая и сильная страна, но есть другие большие и сильные страны, вместе с которыми мы достигнем больших результатов». Также было отмечено, что применение ИИ-технологий в финансовом секторе усложняется в связи с необходимостью выполнения требований по соблюдению банковской тайны и защите персональных данных. Поэтому, для того чтобы использовать самые эффективные и популярные большие языковые модели, но при этом не допустить утечку данных, в ВТБ используют их on-premise, ограничивая их применение защищённым банковским контуром. «На сегодняшний день к такому режиму работы готовы наши российские большие языковые модели, в том числе YandexGPT и GigaChat», — сообщил топ-менеджер.
27.03.2026 [10:03], Руслан Авдеев
ЦЕРН: для самых больших открытий на БАК нужны самые маленькие ИИ-модели, которые «зашиты» прямо в чипыИИ-инфраструктура Большого адронного коллайдера (БАК) имеет мало общего с классическим решениями на основе TPU или GPU. Вместо этого ЦЕРН (CERN) буквально «выжигает» кастомные ИИ-модели в «кремнии» для фильтрации огромных массивов данных практически в реальном времени, сообщает The Register. Ежегодно коллайдер «генерирует» 40 тыс. Эбайт «сырых» данных от сенсоров — приблизительно четверть объёма всего интернета. Такую информацию CERN хранить не может, поэтому приходится выбирать в режиме реального времени то, что представляет какую-либо ценность. Речь идёт о потоке данных до сотен терабайт в секунду. Алгоритмы для их обработки должны быть чрезвычайно быстрыми. Именно поэтому их приходится буквально «выжигать» непосредственно в чипах. В 27-км кольце БАК субатомные частицы сталкиваются на скоростях, близких к скорости света. По кольцу постоянно перемещаются около 2,8 тыс. пучков протонов с 25-с интервалами. Хотя учёные «помогают» частицам, столкновения случаются сравнительно редко — из миллиардов протонов в каждой сессии сталкиваются лишь порядка 60 пар. При столкновении образуются новые частицы, улавливаемые детекторами CERN. 
Источник изображения: Brandon Style/unsplash.com Каждое столкновение пары частиц генерирует несколько мегабайт данных. В секунду происходит около миллиарда столкновений, что приблизительно даёт около 1 Пбайт информации. Естественно, собирать и хранить такие объёмы «сырой» информации технически невозможно, поэтому CERN создал гигантскую вычислительную систему для разделения данных на «интересные» и «неинтересные» ещё на уровне детекторов. 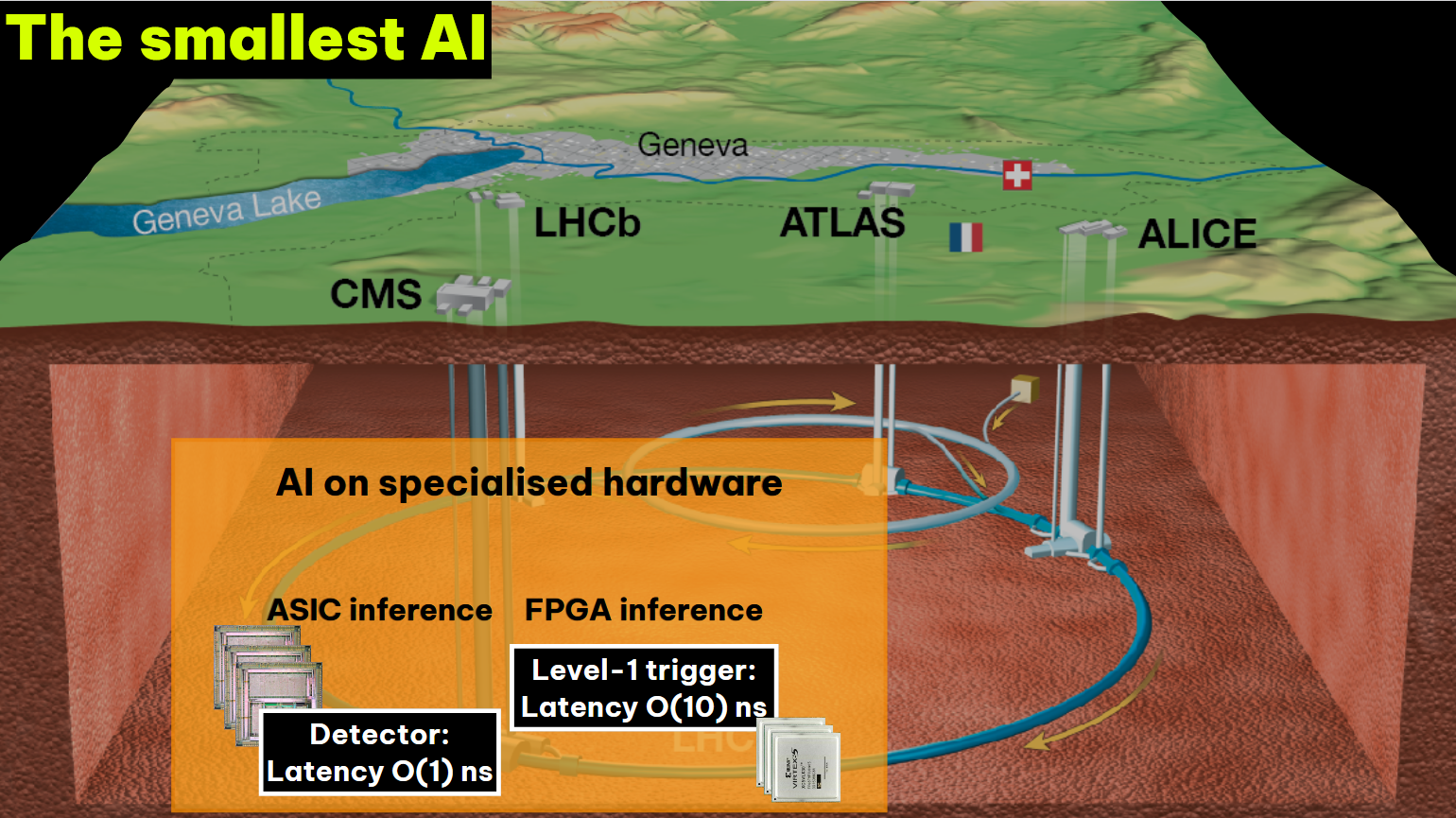
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Детекторы используют ASIC для буферизации данных за не более чем 4 мкс — они либо сохраняются, либо исчезают навсегда. Решение принимает фильтр Level One Trigger на базе порядка 1 тыс. FPGA, получающих данные по оптической линии на скорости около 10 Тбайт/с. Решения принимаются на лету силами самих чипов по мере поступления данных — даже самая быстрая внешняя память не справится с таким потоком информации. Специальный алгоритм AXOL1TL принимает решение не более чем за 50 нс. Фактически сохраняется лишь около 0,02 % информации о столкновениях, или приблизительно 110 тыс. событий в секунду. Отобранные сведения отправляются на поверхность, но даже после первичной фильтрации речь идёт о передаче терабайт данных ежесекундно. 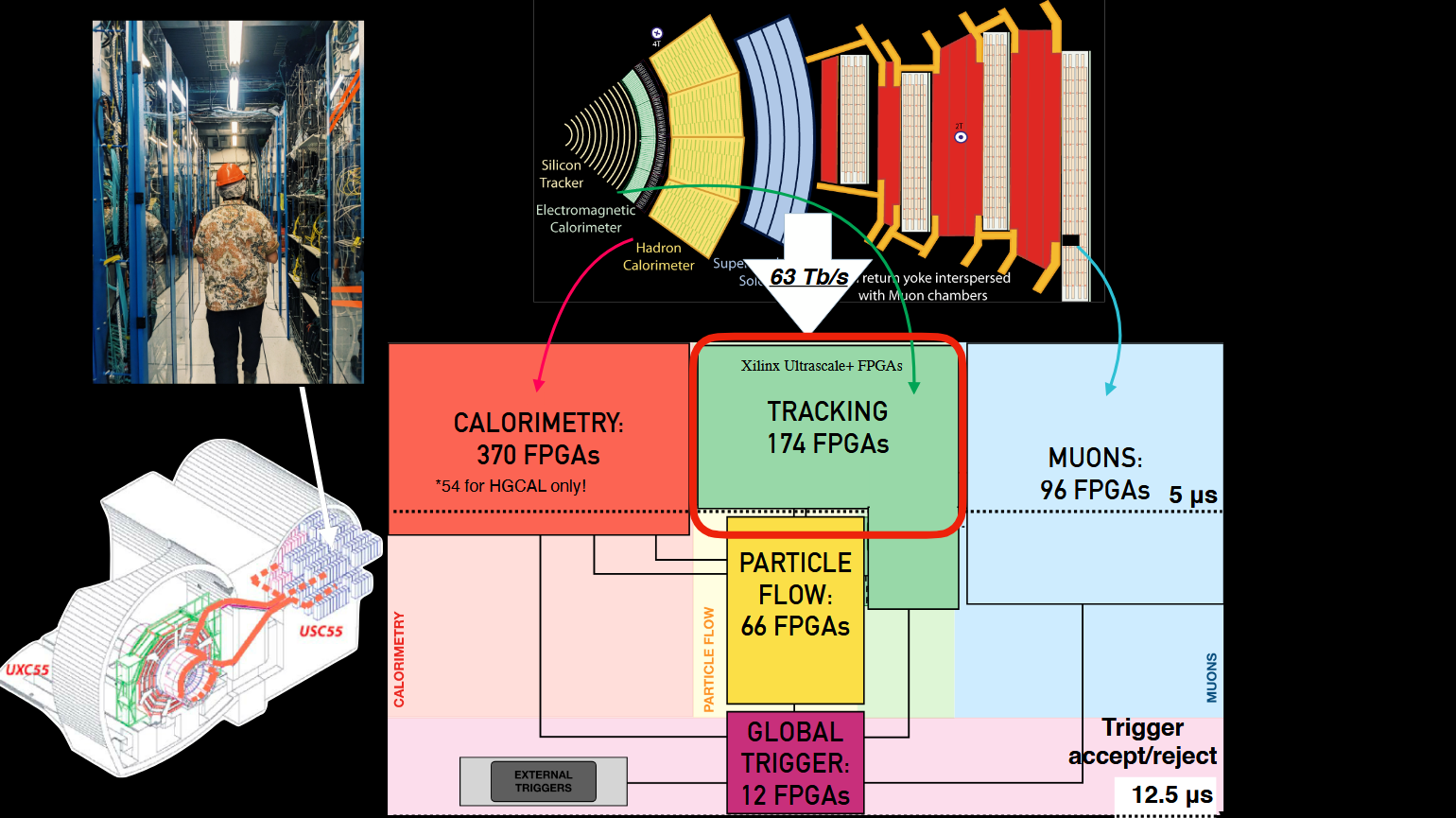
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) На поверхности второй фильтр — High Level Trigger — оставляет для изучения уже около 1 тыс. событий в секунду. Система оснащена 25,6 тыс. CPU и 400 GPU, которые реконструируют столкновения и отбирают наиболее интересные для анализа результатов. На выходе получается около 1 Пбайт/день новых данных, которые распределяются между 170 научными центрами в 42 странах, где их могут анализировать учёные со всего света. Совокупная вычислительная мощность всех участников проекта составляет около 1,4 млн ядер. CERN стремится измерить параметры столкновений с точностью 99,999 % — это «золотой стандарт», необходимый для заявлений о научных открытиях. 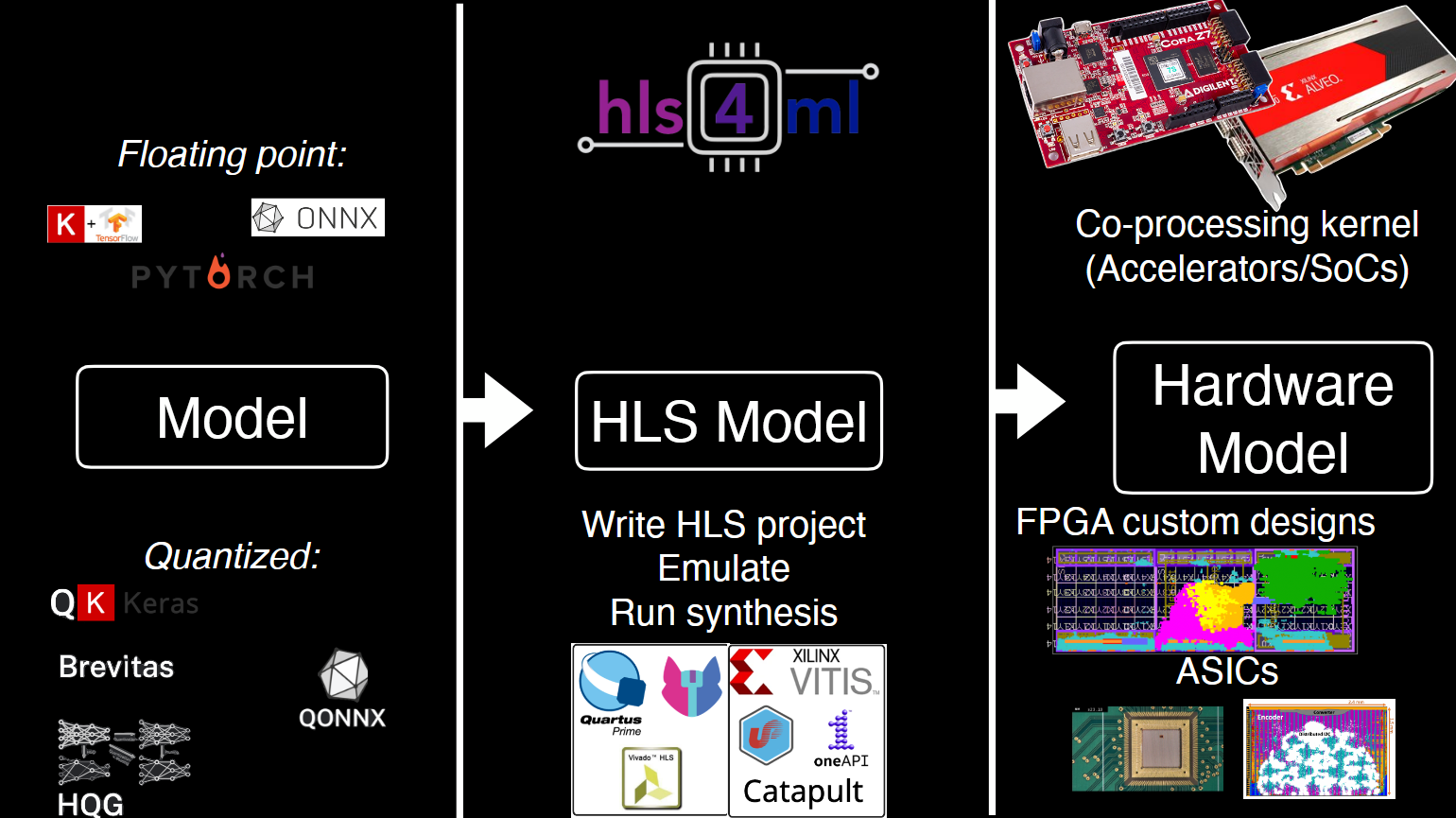
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Обычный ИИ-инструментарий плохо подходит для детекторов, поэтому инженерам CERN пришлось разработать собственный стек. ИИ-модели для БАК специально уменьшены, модернизированы, параллелизованы и «вымуштрованы» для выявления только действительно существенных данных. В случае с БАК они не менее производительны, но значительно «дешевле» традиционных ML-моделей. Для переноса моделей в аппаратную среду используется компилятор HLS4ML, конвертирующий модель в код C++, который можно запускать на ИИ-ускорителях, SoC, кастомных FPGA и даже «выжигать» в ASIC. При этом значительная часть ресурсов чипа отведена не под сам алгоритм, а под таблицы с предварительно рассчитанными результатами для типовых входящих значений, чтобы ещё быстрее фильтровать информацию. 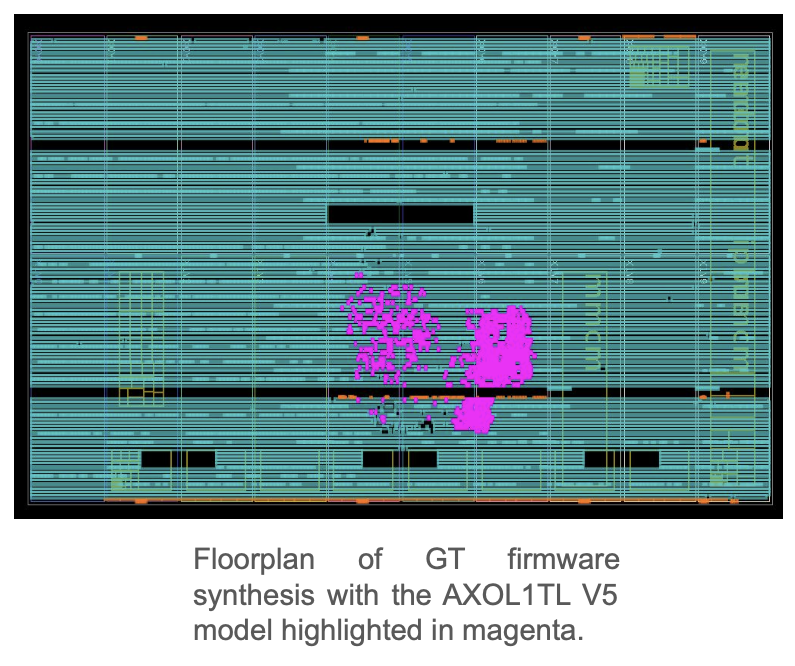
Источник изображения: CERN В конце года БАК закроют, а новый, более мощный коллайдер High Luminosity LHC должен заработать в 2031 году. Он получит более сильные магниты для фокусировки пучков частиц, сами пучки удвоятся в размерах, коллайдер будет генерировать в 10 раз больше данных, а объём информации от каждого события увеличится с 2 до 8 Мбайт. CERN уже накопил 1 Эбайт от БАК, но это лишь десятая часть от того, что предстоит хранить и обрабатывать в последующие 10 лет. И пока передовые ИИ-лаборатории создают LLM всё большего объёма, CERN движется в противоположном направлении, всеми силами упрощая и ускоряя выявление необычных событий с помощью искусственного интеллекта.
26.03.2026 [14:25], Руслан Авдеев
Gartner: к 2030 году себестоимость инференса снизится на 90 %, но качественный ИИ дешевле не станетСогласно прогнозу Gartner, к 2030 году инференс LLM с триллионом параметров будет обходиться провайдерам ИИ-сервисов более чем на 90 % дешевле в сравнении с 2025 годом. При этом речь не идёт о получении всеобщего доступа к передовым вычислениям. В Gartner для исследования каждый токен «оценили» в 3,5 байта или приблизительно четыре символа английского текста. Эксперты предполагают, что снижение затрат будет обусловлено сочетанием повышенной эффективности ИИ-чипов и сопутствующей инфраструктуры, инновациями в разработке самих моделей, повышением эффективности использования чипов, расширением использования специализированных инференс-ускорителей, а также распространением периферийных вычислений для определённых сценариев. В результате, по прогнозам Gartner, к 2030 году LLM станут в 100 раз более экономически эффективными в сравнении с первыми моделями аналогичного масштаба, представленными в 2022 году. Согласно выкладкам Gartner, эксплуатировать модели с помощью передовых ИИ-чипов будет предсказуемо значительно дешевле, чем с использованием более старого или смешанного оборудования на основе более доступных полупроводников с учётом меньшей вычислительной мощности. Про это, в частности, регулярно говорит NVIDIA. 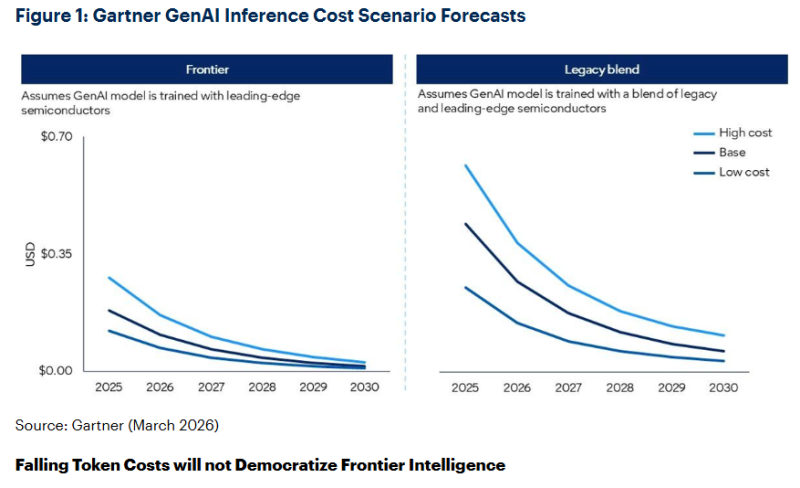
Источник изображения: Gartner Впрочем, снижение стоимости токенов вовсе не означает, что передовые технологии станут более доступными для всех. Во-первых, снижение себестоимости для ИИ-провайдеров не будет означать соизмеримого падения цен для корпоративных клиентов. Кроме того, передовым ИИ-технологиям нужно будет значительно больше токенов, чем сегодня. Так, ИИ-агенты требуют на задачу в 5–30 раз больше токенов, чем обычный чат-бот, и способны выполнять значительно больше задач, чем обычный человек, использующий ИИ. Хотя возможности ИИ расширятся, это будет сопровождаться «непропорционально большим» ростом спроса на токены. Их потребление растёт быстрее, чем снижается стоимость, поэтому ожидается увеличение затрат на инференс. Подчёркивается, что речь не идёт о демократизации передовых вычислений. Стоимость «стандартного» ИИ действительно продолжит падать, но ресурсы, необходимые для сложных ИИ-проектов, по-прежнему будут в дефиците. Руководителям ИИ-проектов, пока маскирующим недостатки их архитектур дешевеющими токенами, придётся столкнуться с трудностями при масштабировании вычислений, связанных с ИИ-агентами. По прогнозам Gartner, наиболее востребованными станут платформы, позволяющие координировать рабочие нагрузки, распределяемые в рамках целого портфеля моделей. Так, рутинные задачи необходимо поручать небольшим, специализированным ИИ-моделям, лучше подходящим при меньших затратах для специальных рабочих процессов в сравнении с универсальными решениями. А дорогостоящие ресурсы передовых моделей необходимо выделять со строгими ограничениями, резервируя их только для сложного, но высокомаржинального инференса. |
|

