Материалы по тегу: llm
|
20.02.2026 [23:37], Руслан Авдеев
«Гонка вооружений» в сфере ИИ бессмысленна — США и Китай преследуют совершенно разные целиВ ИИ уже вложено больше денег, чем потребовалось для высадки людей на Луну, а в 2026 году расходы на технологию могут достигнуть $700 млрд, почти удвоившись год к году. В США политики и бизнес часто стремятся в этой сфере «победить Китай», однако такой подход предполагает общую цель двух стран и относительную «симметрию» при её достижении. На деле цели у стран на рынке ИИ весьма разные, сообщает IEEE Spectrum. По словам Селины Сюй (Selina Xu), руководящей исследованиями и стратегическими инициативами, касающимися Китая и ИИ в офисе Эрика Шмидта (Eric Schmidt), бывшего главы Google, внимательное изучение развития ИИ в двух странах показывает, что они не стремятся в этой сфере к одним и тем же целям. Более того, они движутся совсем в разных направлениях. По мнению Сюй, США делают акцент на масштабирование, стремясь создать «общий искусственный интеллект» (AGI), тогда как для Китая важнее повышение экономических показателей и использование в реальном мире. По словам Сюй, менталитет «гонки на выживание» способен только навредить — правительства и компании будут пренебрегать необходимыми мерами безопасности для достижения мнимого «первенства». Отчасти это уже наблюдается, например, в сфере энергетики, где администрация президента США продвигает «атомные кампусы» с ослабленными требованиями к безопасности АЭС. Сам Шмидт уже предупреждал об опасности стремления США к доминированию в области ИИ. 
Источник изображения: Joss Broward / Unsplash По мере развития систем машинного обучения в 2010-х гг., видные общественные деятели вроде Стивена Хокинга и Илона Маска уже предупреждали, что универсальный потенциал ИИ невозможно будет отделить от военного и экономического — повторяется модель конкуренции времён Холодной войны. По мнению некоторых экспертов, концепция такого «состязания» выгодна передовым лабораториям, инвесторам и СМИ, которым просто удобнее оперировать простыми метриками успеха вроде размера моделей, контрольных показателей и большей вычислительной мощности. В парадигме «гонки вооружений» «общий искусственный интеллект» — и есть «финишная линия», победителем станет тот, кто первый её достигнет. Тем временем, как считают эксперты, нет никакой гарантии, что страна, создавшая AGI, станет именно победителем и её интересы восторжествуют, поскольку такой искусственный интеллект будет умнее людей и, следовательно, неуправляемым и непредсказуемым. Кроме того, Китай и США совсем-по разному подходят к реализации ИИ-проектов и экономические условия этих стран кардинально отличаются. 
Источник изображения: Nicolas Hoizey / Unsplash После десятилетий быстрого роста КНР столкнулась с экономическим спадом, поэтому страна стремится найти новый «двигатель экономики». Вместо того, чтобы вкладывать ресурсы в «спекулятивные» модели развития искусственного интеллекта, Поднебесная рассматривает ИИ как инструмент, позволяющий совершенствовать действующие отрасли, от здравоохранения до энергетики и сельского хозяйства, как инструмент, улучшающий жизнь обычных людей. Для этого ИИ внедряется в производство, логистику, энергетику, финансы и госуслуги. Автопроизводители активно внедряют роботов на заводах с минимальным участием людей, по имеющейся статистике на 2024 год в КНР использовалось впятеро больше промышленных роботов, чем в США. Сельскохозяйственные модели помогают фермерам, в здравоохранении ИИ-инструменты помогают врачам ставить диагнозы и лечить пациентов и др. Даже очень маленькие предприятия изучают возможность использовать ИИ для повышения производительности. 
Источник изображения: JESHOOTS.COM / Unsplash В США ИИ-модели тоже внедряются в разные отрасли всё чаще, но основной акцент делается на сервис и обработку информации с применением больших языковых моделей (LLM). Они применяются для обработки неструктурированных данных и автоматизации коммуникаций. Например, банками используются помощники на основе LLM для помощи в управлении счетами пользователей и обработки их рутинных запросов, LLM помогают врачам извлекать ключевые данные из медицинских записей и клинической документации. По словам отраслевых экспертов, LLM больше подходят для экономики США, ориентированной на сферу услуг, чем для китайской индустриальной экономики. Конечно, Китай и США конкурируют в некоторых областях, связанных с ИИ, в частности, касающихся разработки и производства полупроводников для обеспечения работы искусственного интеллекта. Также обе страны стремятся обрести контроль над цепочками поставок для обеспечения национальной безопасности. Китай, безусловно, стремится избавиться от зависимости от американских чипов. 
Источник изображения: Rock Staar / Unsplash Важной сферой для конкуренции является ИИ для военного применения, поскольку та или иная сторона может получить преимущества в плоскости отдельных военных технологий. При этом Китай всё ещё не подобрал «фаворита» для военного и промышленного сектора. После триумфального дебюта DeepSeek в 2025 году, главный получатель средств для разработки «общего искусственного интеллекта» так и не выбран, а вкладывать все средства в AGI страна, похоже, не планирует, поскольку это слишком рискованно. На деле американские и китайские компании до сих пор сотрудничают, несмотря на постепенное «разделение» экономик двух стран. Фактически, по мнению Сюй, для создания безопасного и заслуживающего доверия ИИ было бы лучше, чтобы исследователи и политики США и КНР наладили диалог и достигли консенсуса относительно того, что запрещено, а потом конкурировали бы в этих рамках. В концепции «гонки вооружений» упускается из виду реальная ситуация на местах, обмен опытом между компаниями, обмен научными данными, переток талантов с одного рынка на другой и то, насколько тесно переплетены экосистемы двух стран в целом.
19.02.2026 [15:57], Руслан Авдеев
Microsoft бросилась исправлять ИИ-неравенство в мире и выделила на это $50 млрдНа недавнем мероприятии India AI Impact Summit представители Microsoft объявили, что компания готовится инвестировать к концу десятилетия $50 млрд для того, чтобы обеспечить доступ к ИИ странам Глобального Юга. Технологии искусственного интеллекта стремительно распространяются, но чрезвычайно неравномерно в мировом масштабе. В докладе Microsoft AI Diffusion Report утверждается, что в странах Глобального Севера ИИ используется вдвое активнее, чем на юге, и неравенство продолжает увеличиваться. Это сказывается не только на национальном и региональном экономическом росте, но и перспективах развития. Более века неравный доступ к электроэнергии увеличивал экономический разрыв между Глобальным Севером и Югом. С ИИ может произойти аналогичная история. Потребности в новых технологиях требуют существенных инвестиций и больших усилий правительств, частного сектора и НКО. Выделенные Microsoft $50 млрд призваны поддержать новые возможности в странах Глобального Юга. Программа развития ИИ состоит из пяти элементов:

Источник изображения: Chastagner Thierry/unsplash.com Инфраструктура жизненно необходима для распространения ИИ, говорит компания. ИИ требует энергии, каналов связи, вычислительных мощностей. Только в последнем финансовом году Microsoft инвестировала более $8 млрд в инфраструктуру ЦОД, обслуживающую Глобальный Юг, включая Индию, Мексику, страны Африки, Южной Америки, Юго-Восточной Азии и Ближнего Востока. В первую очередь компания стремится расширить доступ в интернет 250 млн человек в макрорегионе. Microsoft заявила, что уже помогла получить доступ в интернет 117 млн человек в Африке. Инвестиции в ИИ-инфраструктуру осуществляются с учётом необходимости обеспечения местного суверенитета, хотя не так давно компания объявила, что не может обеспечить суверенитет данных в Европе из-за особенностей американского законодательства. Microsoft заявила о создании суверенного управления в публичных облаках, частных суверенных предложениях и тесном сотрудничестве с национальными партнёрами на местах. Утверждается, что в эру ИИ вся информация остаётся в руках клиентов под их полным контролем, без передачи сторонним провайдерам. При этом Глобальный Юг требует огромных инвестиций в инфраструктуру ЦОД, энергетику и связь, что крайне затруднительно без зарубежных инвестиций, в том числе со стороны техногигантов. В числе прочего для удовлетворения этих потребностей было сформировано партнёрство Trusted Tech Alliance, объединяющее 16 ведущих технологических компаний из 11 стран с четырёх континентов. 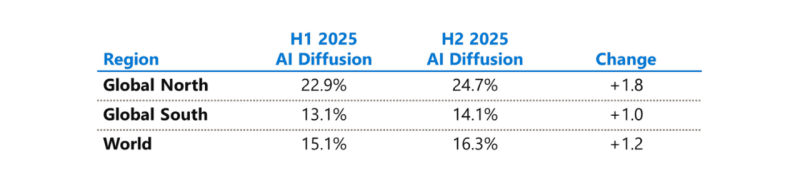
Источник изображения: Microsoft Однако ЦОД и интернет-каналы — лишь часть необходимой инфраструктуры. Не меньшее значение имеет доступ к технологиям для школ, университетов и НКО и цифровым компетенциям. В предыдущем финансовом году Microsoft инвестировала в программы для государств Глобального Юга $2 млрд, включая гранты, пожертвования, льготы и обучающие программы. В 2025 году компания запустила инициативу Microsoft Elevate, призванную к 2028 году подготовить 20 млн дипломированных специалистов с востребованными ИИ-компетенциями. В Индии компания обучила уже 5,6 млн человек, а к 2030 году намерена довести это число до 20 млн. Компания подготовит 2 млн учителей из более 200 тыс. школ и вузов, а также оснастит 25 тыс. учебных учреждений ИИ-инфраструктурой. Ещё одно направление — создание и доработка ИИ-моделей на местных языках, поскольку локальные решения пока что хуже, чем решения на английском языке. Microsoft поддержала инвестиции в инициативу LINGUA Africa (выделено $5,5 млн) по сбору языковых данных и развитие моделей для африканских языков. Дополнительно совершенствуется бенчмарк MLCommons AILuminate для индийских и азиатских языков для оценки безопасности ИИ вне англоязычной среды. 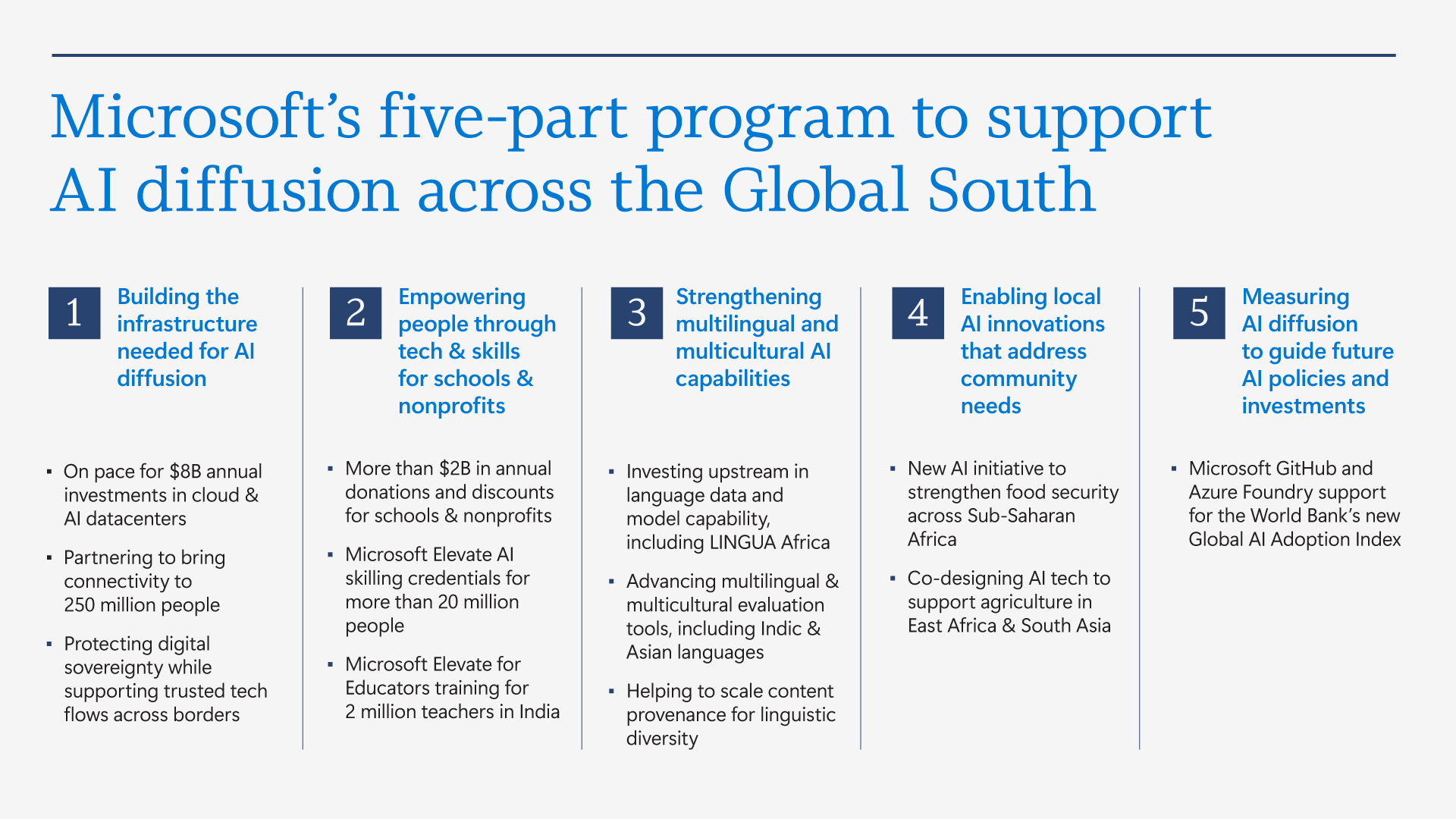
Источник изображения: Microsoft Совместно с образовательными и коммерческими структурами из Индии, Японии, Кореи и Сингапура при участии Microsoft создаётся мультиязычная и мультимодальная подборка из 7 тыс. высококачественных промптов для хинди, тамильского, малайского, японского и корейского языков. Также Microsoft развивает метод Samiksha для учёта локальных языковых и культурных контекстов. Samiksha позволяет выявлять сбои, которые часто упускаются «англоцентричными» методами оценки. В Африке компания совместно с NASA, властями и др. организациями будет применять ИИ к спутниковым данным для анализа продовольственной ситуации. Технология уже отработана в Индии. В рамках Project Gecko компания развивает ИИ-технологии совместно с сообществами в Восточной Африке и Южной Азии для поддержки с/х. В том числе речь идёт о семействе моделей для распознавания речи Paza, способных работать на мобильных устройствах с шестью кенийскими языками. Ведутся работы над многоязыковыми инструментами Copilot, Multimodal Critical Thinking (MMCT) Agent для анализа видео с учётом голоса и текста, адаптацией LLM к низкоресурсным языкам (в т.ч. чичева, инуктитут, маори) и т.д. 
Источник изображения: Microsoft Для ускоренного внедрения ИИ нужно понимать, где и как применяется ИИ, с каким недостатками приходится сталкиваться разработчикам, говорит Microsoft. На основе статистики публичных репозиториев GitHub и метрик Azure Foundry компания участвует в создании «рейтинга» Global AI Adoption Index Всемирного Банка. Например, индийское сообщество из 24 млн разработчиков — второе по величине на GitHub и самое быстрорастущее среди 30 ведущих экономик. С 2020 года ежегодный прирост составляет более 26 %, в 2025 году он составил более 36 %. Индийские специалисты занимают второе место в мире по вкладу в open source, использованию GitHub Education, по вкладу в публичные ИИ-проекты и др. Такие данные помогают точнее направлять инвестиции в инфраструктурные проекты, языковые технологии и на обучение. Поддержка подобных метрик помогает измерять достигнутый прогресс. Microsoft подчёркивает, что компания акцентирует внимание в вопросах внедрения ИИ на необходимости создания доступной инфраструктуры, надёжно работающих в реальном мире системах, а также технологиях, которые могут применяться с учётом местных условий. Для этого компания намерена работать с партнёрами, включая обмен данными для оценки прогресса.
01.02.2026 [12:05], Владимир Мироненко
Gartner: к 2029 году обеспечение цифрового ИИ-суверенитета будет обходиться странам в 1 % ВВП
gartner
llm
software
государство
ии
инвестиции
информационная безопасность
исследование
конфиденциальность
прогноз
финансы
По оценкам аналитической фирмы Gartner, к 2029 году для обеспечения цифрового суверенитета странам потребуется инвестировать не менее 1 % всего своего валового внутреннего продукта (ВВП) в ИИ-инфраструктуру, пишет The Register. В результате реализации цифрового суверенитета страны окажутся привязанными к региональным ИИ-платформам, основанным на собственных контекстных данных, что приведёт к сокращению сотрудничества между странами, дублированию усилий и увеличению стоимости проектов, утверждает Gartner. «Страны, стремящиеся к цифровому суверенитету, увеличивают инвестиции во внутренние платформы ИИ, поскольку они ищут альтернативы закрытой модели США, включая вычислительные мощности, ЦОД, инфраструктуру и ИИ-модели, соответствующие местным законам, культуре и региону», — заявил вице-президент и аналитик Gartner Гаурав Гупта (Gaurav Gupta). По оценкам Gartner, к следующему году 35 % стран будут привязаны к региональным системам. Локализованные модели обеспечивают большую контекстную ценность, превосходя неадаптированные глобальные модели в таких областях применения, как образование, соблюдение законодательства и государственные услуги, особенно, в случае использования языков, отличных от английского. Для Европы и других регионов стремление к цифровому суверенитету наталкивается на зависимость от облачной инфраструктуры США, отсюда и необходимость для стран тратить больше средств на собственную ИИ-инфраструктуру, отметил The Register. 
Источник изображения: Clint Patterson / Unsplash «Инфраструктура ЦОД и ИИ-фабрик составляет важнейшую основу стека, обеспечивающего суверенитет ИИ», — заявил Гупта. Он добавил, что в результате ЦОД и инфраструктура ИИ-фабрик будут стремительно развиваться и привлекать инвестиции в будущем, что позволит нескольким компаниям, контролирующим ИИ-стек, достичь оценок в триллионах долларов. Хотя 1 % ВВП страны представляет собой громадную сумму, которая, например, у Великобритании составляет около £30 млрд ($39 млрд), это для американских технологических гигантов не является проблемой, поскольку они уже инвестируют в ИИ-инфраструктуру больше, чем весь ВВП некоторых стран.
21.01.2026 [17:07], Руслан Авдеев
Глава Anthropic: продажа H200 в Китай равнозначна поставкам ядерного оружия Северной КорееГенеральный директор Anthropic Дарио Амодеи (Dario Amodei) недоволен тем, что США разрешили NVIDIA продавать китайским компаниям передовые ИИ-ускорители. Он сравнил это решение с раздачей ядерного оружия противникам, сообщает The Register. По словам Амодея, выступившего на Международном экономическом форуме в Давосе, руководители китайских компаний заявляют, что эмбарго на поставку американских чипов сдерживает их развитие. Он заявил, что продавать эти чипы — большая ошибка. Ранее США разрешили поставки ускорителей NVIDIA H200 китайским покупателям с пошлиной 25 %. Теперь слово за китайскими властями, которым ещё предстоит разрешить такие сделки. Anthropic желает, чтобы экспорт ИИ-технологий, наоборот, ужесточился — это заметно контрастирует с позициями NVIDIA и AMD, которые предупреждают, что запреты на экспорт только способствуют развитию ИИ-технологий в КНР. При этом на Китай приходится около половины исследователей в области искусственного интеллекта. Ранее Anthropic утверждала, что США и так лидируют в сфере ИИ-полупроводников, а экспортный контроль, на фоне того, что вычислительные мощности чипов удваиваются каждые два года, замедляет развитие Китая и укрепляет лидерство США. Компания уверена, что США на годы опережают Китай в способности выпускать передовые чипы. Доступ к американским разработкам позволит китайским создателям ПО вроде DeepSeek оказаться в лучшей позиции для конкуренции с Западом. При этом, как сообщает The Register, многие из наиболее производительных китайских LLM относятся к open source, поэтому их может использовать любой желающий, не опасаясь того, что данные его компании попадут в обучающий датасет, тогда как LLM американских компаний в основном «скрыты» за API, а сами компании расплывчато обещают не использовать пользовательские данные для обучения своих ИИ. При этом суды полны исков пользователей, связанных с нарушением прав на интеллектуальную собственность. 
Источник изображения: CDC/unspalsh.com Слова Амодеи о том, что китайские разработчики LLM угрожают американскому бизнесу, слегка сгущают краски, но всё может действительно измениться, если китайские компании смогут импортировать передовые ускорители из США. Пока же, по словам бизнесмена, ИИ из КНР производителен только «на бумаге», а системы якобы специально оптимизируют для бенчмарков. Так или иначе, корпоративные пользователи действительно имеют немного вариантов, если желают получить доступ к хорошим открытым моделям — они в основном из Китая. Сама Anthropic называет главными конкурентами не стартапы из КНР, а OpenAI, Google и, чуть реже, другие американские компании. Anthropic пока не выкладывала ни одну из своих флагманских моделей в открытый доступ, но участвовала в нескольких совместных проектах с избранными клиентами, самым значимым из которых является AWS. Амодеи подчеркнул, что его продукты почти ни разу не проиграли в борьбе за контракт ИИ-модели из Поднебесной. Ключевое слово — «почти». Это означает, что китайским разработчикам всё-таки удавалось одержать верх несмотря на сложную ситуацию, в которой они находятся из-за экспортных ограничений. Компания последовательно критикует инициативы, способные обеспечить сотрудничество Запада с Китаем и даже не приветствует взаимодействие с другими мировыми игроками. Так, летом 2025 года сообщалось, что она намерена привлечь инвестиции с Ближнего Востока, но только потому, что избежать работы с регионом не удастся. В 2024 году Anthropic даже отказалась от инвестиций из Саудовской Аравии по соображениям «национальной безопасности».
21.01.2026 [15:28], Руслан Авдеев
ByteDance стремительно завоёвывает рынок облачных ИИ-сервисов КитаяКомпания ByteDance агрессивно осваивает китайский облачный рынок. Владелец популярной социальной сети TikTok пытается использовать свои достижения в сфере ИИ для выхода за пределы рынка пользовательских приложений, обеспечивших в своё время успех компании, сообщает The Financial Times. Компания продвигает облачные решения Volcano Engine для корпоративных клиентов, увеличивая команду продаж и устраивая ценовые войны с конкурентами. Источники сообщают, что ByteDance предлагает корпоративным клиентам собственные обширные данные и вычислительные ресурсы, например, для создания ИИ-агентов с использованием собственных моделей ByteDance. Тем самым она теснит Alibaba, Tencent и Huawei, которые долго доминировали на этом рынке. По данным IDC, Volcano Engine является в Китае вторым по величине провайдером ИИ-инфраструктуры и ПО после Alibaba. На долю ByteDance в I половине 2025 года приходилось около 13 % выручки от китайских облачных ИИ-сервисов ($390 млн), на долю Alibaba — 23 %. При этом на китайском облачном рынке в целом ByteDance имеет долю лишь 3 %. Иными словами, ByteDance стала лидером в сфере ИИ-сервисов, самом быстрорастущем сегменте рынка. По мнению некоторых аналитиков, компания может стать одним из ключевых игроков в Китае в сегменте кастомных ИИ-инструментов благодаря крупным собранным датасетам и развитой аппаратной инфраструктуре, добавив для достижения успеха агрессивное ценообразование и глубокую интеграцию со своей экосистемой пользователей. 
Источник изображения: Liren/unsplash.com ByteDance хорошо разбирается в пользовательских технологиях, имея в портфолио социальную сеть TikTok и её китайский вариант Douyin, а также видеоредактор CapCut и новостной агрегатор Toutiao. Именно эти площадки обеспечивают большую часть выручки компании благодаря рекламе, продажам и подпискам. Согласно данным, предоставленным инвесторам, в III квартале выручка составила $50 млрд. Последние попытки выйти на рынок корпоративного ПО, включая премьеру похожего на Slack продукта Lark, не увенчались особенным успехом. Стратегия роста, ориентированная на ИИ, могла бы придать импульс для будущего выхода на IPO, которого инвесторы ожидают годами. ByteDance агрессивно выводит в коммерческую плоскость свои ИИ-возможности благодаря Volcano Engine. Компания акцентирует внимание на продажах флагманского сервиса HiAgent, посредством которого создаются кастомные ИИ-агенты для корпоративных клиентов. Стратегия опирается на массивные инвестиции в вычислительные мощности. ByteDance сегодня — в числе крупнейших покупателей ИИ-оборудования, она же была крупнейшим клиентом NVIDIA в 2024 году. По данным The Financial Times, в этом году значительная часть из ¥85 млрд, выделенных на ИИ-ускорители, будет потрачена на покупку NVIDIA H200, с некоторых пор разрешённых для поставок в КНР — если это одобрят китайские власти. При этом некоторые эксперты отмечают, что ByteDance имеет сильные позиции в разработке ПО и достаточные аппаратные ресурсы для получения значимой доли облачного рынка, но ей не хватает опыта в обслуживании корпоративных клиентов в сравнении с Tencent и Huawei, поэтому приходится навёрстывать упущенное. 
Источник изображения: Claudio Schwarz/unsplash.com Крупные китайские игроки сами дают ByteDance такую возможность. Например, Tencent заявляла, что будет тратить ресурсы ИИ-ускорителей для внутренних нужд, не планируя масштабного расширения облачных сервисов для клиентов. Huawei, тем временем, сократила свои облачные ИИ-амбиции за последний год, сфокусировавшись на продаже чипов Ascend напрямую клиентам. По данным IDC, доля обеих компаний на облачном ИИ-рынке КНР слегка уменьшилась в I половине 2025 года. Становление ByteDance в качестве одного из китайских ИИ-гигантов привлекло меньше внимания, чем успехи DeepSeek и Alibaba, которые развивают успешные открытые ИИ-модели и одновременно публикуют исследования о своих методиках обучения ИИ. Напротив, ByteDance сохранила полный контроль над своими самыми передовыми моделями и компании-клиенты имеют к ним доступ только по подписке. К слову, Alibaba, яро выступавшая за open source подход к распространению моделей, в последние месяцы оставила некоторые из передовых вариантов «закрытыми». Другими словами, успехи ByteDance в сфере ИИ-моделей не освещаются слишком широко, поскольку отдача open source продуктов вызывает некоторые сомнения у многих разработчиков. Один из представителей команды ByteDance подчеркнул, что компания концентрирует усилия на создании лучших ИИ-моделей для клиентов, а не на гонке в сегменте open source.
25.11.2025 [13:42], Андрей Крупин
Yandex B2B Tech открыла доступ к Alice AI LLM — самому мощному семейству нейросетей «Яндекса»Yandex B2B Tech (бизнес-группа «Яндекса», объединяющая технологии и инструменты компании для корпоративных пользователей, включая продукты Yandex Cloud и «Яндекс 360») сообщила о доступности пользователям облачной платформы Yandex Cloud нового семейства генеративных моделей — Alice AI LLM. Alice AI LLM является флагманской ИИ-разработкой компании «Яндекс». Модель построена на архитектуре MoE (Mixture of Experts) с технологией тренировки на основе обучения с подкреплением (Online RL). Нейросеть понимает около 20 языков (в том числе японский) и может быть использована для решения сложных задач: поиска по базам знаний и генерации результатов на основе найденной информации (RAG-сценарий), анализа документов, построения отчётов и аналитики, извлечения информации и автоматизации заполнения полей, форм и баз CRM, а также для создания «человеко-ориентированных» ИИ-ассистентов. 
Источник изображения: пресс-служба «Яндекса» / company.yandex.ru Alice AI LLM доступна через OpenAI-совместимые Completions API и Responses API, а также собственный API генерации текста в форматах REST и gRPC. Модель поддерживает интеграцию с популярными open source-библиотеками LangChain, AutoGPT и LlamaIndex. В Yandex B2B Tech подчёркивают, что стоимость использования Alice AI значительно ниже, чем у опенсорсных нейросетей, благодаря оптимизированному под русский язык разделению текста на токены. В один токен в Alice AI помещаются примерно 4–5 символов на кириллице, а в опенсорсных моделях — примерно 2–3 символа. Таким образом, конечная стоимость использования Alice AI в 1,5–2 раза ниже открытых моделей с той же тарификацией. Кроме того, запросы пользователя к нейросети и ответы модели тарифицируются по-разному: токены «на вход» нейросети стоят в четыре раза дешевле, чем «на выход», что позволяет использовать модель более экономно.
19.11.2025 [01:11], Владимир Мироненко
$30 млрд и 1 ГВт: Microsoft, NVIDIA и Anthropic договорились о сотрудничествеMicrosoft, NVIDIA и Anthropic объявили о стратегическом партнёрстве, которое включает ряд новых инициатив. Как сообщается, Anthropic взяла на себя обязательство приобрести вычислительные мощности Azure стоимостью $30 млрд и заключить контракт на поставку дополнительных вычислительных мощностей объёмом до 1 ГВт для обеспечения будущих потребностей в масштабировании. В рамках партнёрства NVIDIA и Microsoft также обязуются инвестировать в Anthropic до $10 и $5 млрд соответственно. Компании также расширят существующее партнёрство, чтобы обеспечить предприятиям более широкий доступ к ИИ-модели Claude. Клиенты Microsoft Azure AI Foundry смогут получить доступ к продвинутым (frontier) версиям модели Claude, включая Claude Sonnet 4.5, Claude Opus 4.1 и Claude Haiku 4.5. Это партнёрство делает Claude единственной frontier-моделью LLM, доступной во всех трёх самых известных облачных сервисах мира. Также Claude будет интегрирована в пакет Copilot, включающий GitHub Copilot, Microsoft 365 Copilot и Copilot Studio. Генеральный директор Anthropic Дарио Амодеи (Dario Amodei) отметил, что акцент Microsoft на корпоративные платформы естественным образом подходит Claude, которая часто используется в бизнес-приложениях, пишет The Wall Street Journal. 
Источник изображения: NVIDIA В рамках стратегического партнёрства Anthropic и NVIDIA будут сотрудничать в области проектирования и инжиниринга с целью обеспечения наилучшей производительности, экономичности и общей стоимости владения для моделей Anthropic, а также оптимизации будущих архитектур NVIDIA для рабочих нагрузок Anthropic. Первоначально Anthropic будет использовать вычислительные системы NVIDIA Grace Blackwell и Vera Rubin мощностью до 1 ГВт. Аналитики Bank of America утверждают, что эти, на первый взгляд, цикличные сделки являются для лидеров отрасли способом расширить свой потенциальный целевой рынок, что «может многократно увеличить будущие выгоды». Как отметил ресурс Converge! Network Digest, с учётом нынешнего объявления портфель обязательств Microsoft в области ИИ теперь превышает $100 млрд, включая контракты с OpenAI, Inflection и Anthropic. Эти долгосрочные соглашения помогают Microsoft обосновать ускоренное строительство ИИ ЦОД, закупки электроэнергии и развёртывание ИИ-систем. Сделка также укрепляет позиции Azure по сравнению с AWS, запустившей для Anthropic ИИ-кластер Project Rainier, и Google Cloud, TPU которой также пользуется Anthropic.
10.11.2025 [12:05], Сергей Карасёв
Фабрика токенов: Nebius, бывшая Yandex NV, запустила платформу Token Factory для инференса на базе открытых ИИ-моделейКомпания Nebius (бывшая материнская структура «Яндекса») представила платформу Nebius Token Factory для инференса: она позволяет разворачивать и оптимизировать открытые и кастомизированные ИИ-модели в больших масштабах с высоким уровнем надёжности и необходимым контролем. Nebius отмечает, что применение закрытых ИИ-моделей может создавать трудности при масштабировании. С другой стороны, открытые и кастомизированные модели позволяют устранить эти ограничения, но управление ими и обеспечение безопасности остаются технически сложными и ресурсоёмкими задачами для большинства команд. Платформа Nebius Token Factory призвана решить существующие проблемы: она сочетает гибкость открытых моделей с управляемостью, производительностью и экономичностью, которые необходимы организациям для реализации масштабных проектов в сфере ИИ. Nebius Token Factory базируется на комплексной ИИ-инфраструктуре Nebius. Новая платформа объединяет высокопроизводительный инференс, пост-обучение и управление доступом. Обеспечивается поддержка более 40 open source моделей, включая новейшие версии Deep Seek, Llama, OpenAI и Qwen. 
Источник изображения: Nebius Среди ключевых преимуществ Nebius Token Factory заявлены соответствие требованиям корпоративной безопасности (HIPAA, ISO 27001 и ISO 27799), предсказуемая задержка (менее 1 с), автоматическое масштабирование пропускной способности и доступность на уровне 99,9 %. Инференс выполняется в дата-центрах на территории Европы и США без сохранения данных на серверах Nebius. Задействована облачная экосистема Nebius AI Cloud 3.0 Aether, что, как утверждается, обеспечивает безопасность корпоративного уровня, проактивный мониторинг и стабильную производительность. Отмечается, что Nebius Token Factory может применяться для решения широкого спектра ИИ-задач: от интеллектуальных чат-ботов, помощников по написанию программного кода и генерации с дополненной выборкой (RAG) до высокопроизводительного поиска, анализа документов и автоматизированной поддержки клиентов. Интегрированные инструменты тонкой настройки и дистилляции позволяют компаниям адаптировать большие открытые модели к собственным данным. При этом достигается сокращение затрат на инференс до 70 %. Оптимизированные модели затем можно быстро разворачивать без ручной настройки инфраструктуры.
20.10.2025 [01:23], Владимир Мироненко
Ускорителей хватит на всех — Alibaba Aegaeon оптимизировал обработку ИИ-нагрузок, снизив использование дефицитных NVIDIA H20 на 82 %Alibaba Cloud представила Aegaeon, систему пулинга вычислений, позволяющую сократить количество ускорителей NVIDIA, необходимых для обслуживания ИИ-моделей, на 82 %, пишет ресурс SCMP. По словам разработчиков, благодаря Aegaeon количество ускорителей NVIDIA H20, необходимых для обслуживания десятков моделей с 72 млрд параметров, удалось сократить с 1192 до 213 единиц. «Aegaeon — это первое решение на рынке, которое выявило чрезмерные затраты, связанные с обслуживанием параллельных рабочих нагрузок LLM», — сообщили исследователи из Пекинского университета и Alibaba Cloud. Провайдеры облачных сервисов, такие как Alibaba Cloud и ByteDance Volcano Engine, предоставляют пользователям одновременно тысячи ИИ-моделей — множество вызовов API обрабатывается одновременно. Однако на практике для инференса чаще всего используются лишь несколько моделей, таких как Qwen и DeepSeek, а большинство других моделей применяются лишь эпизодически. Это приводит к неэффективному использованию вычислительных ресурсов: исследователи обнаружили, что 17,7 % ускорителей выделяется на обслуживание лишь 1,35 % запросов в Alibaba Cloud. Aegaeon выполняет «автоматическое масштабирование» на уровне токенов, обеспечивая переключение ускорителей между обслуживанием различных моделей в процессе генерации. В рамках системы один ускоритель поддерживает обработку до семи моделей по сравнению с двумя-тремя моделями в альтернативных системах. При этом задержка, связанная с переключением между моделями, снижена на 97 %, заявили исследователи. Alibaba Cloud сообщила, что решение уже используется на её торговой площадке моделей Bailian. 
Источник изображения: Alibaba Глава NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что из-за экспортных ограничений доля компании на рынке передовых чипов в Китае сократилась с 95 % до нуля. Этому также способствовала стратегия Пекина, направленная на самообеспечение местного рынка. В связи с этим планы NVIDIA возобновить отгрузки ИИ-ускорителей H20, на которые ранее были установлены ограничения правительством США, встретили в Китае довольно прохладно. Более того, в Китае вынесли запрет местным компаниям на покупку разработанного специально для местного рынка ускорителя NVIDIA RTX Pro 6000D, поскольку пришли к выводу, что китайские ИИ-чипы не уступают продукции NVIDIA, разрешённой к экспорту в Китай.
29.08.2025 [17:53], Руслан Авдеев
ИИ и IIoT помогли Aramco сократить время простоев на 40 % и снизить расходы на техобслуживание на 30 %Внедрение ИИ позволило нефтегазовой компании Aramco из Саудовской Аравии весьма эффективно оптимизировать бизнес, сообщает VAST Data. Благодаря комбинации алгоритмов машинного обучения с сетями IoT-датчиков в инфраструктуре компании — на буровых установках, трубопроводах предприятиях по нефтепереработке и т.д. — Aramco добилась сокращения времени незапланированных простоев на 40 % и снижении расходов на техническое обслуживание на 30 %. Системы компании позволяют выявлять признаки перегрузки оборудования задолго до того, как произойдёт серьёзный инцидент, своевременно предотвратив поломки и каскад аварий. Важен и экологический аспект. Сжигание попутного и «лишнего» газа всегда было неприятным пятном на репутации отрасли. Теперь ИИ Aramco использует более 18 тыс. датчиков для прогнозирования того, где и когда придётся сжигать газ и можно ли этого избежать. В результате с 2010 года сжигание сократилось более чем наполовину и уже более десяти лет сжигается менее 1 % от общего уровня добычи газа. На одном из крупнейших в мире месторождении Хурайс (Khurais) Aramco развёрнуто 40 тыс. датчиков на 500 нефтяных скважинах, потоки данных интегрируются в системы машинного обучения и роботизированные платформы. Фактически создан «живой» цифровой двойник месторождения с постоянным обновлением данных и возможностью моделирования процессов. 
Источник изображения: Zbynek Burival/unsplash.com Знаковой стала разработка первой в своём роде ИИ-модели Aramco METABRAIN c 7 млрд параметров, созданной из датасета на основе данных, накопленных компанией за 90 лет. В своём роде это всезнающий промышленный консультант. Модель обеспечивает предиктивную аналитику, оптимизирует рабочие процессы и поддерживает принятие тех или иных решений. Фактически речь идёт о банке памяти, объединённом с «рассуждающей» моделью, в том числе обрабатывается историческая информация для получения рекомендаций. Мегапроекты вроде реализуемого в Хурайсе, предусматривают использование не периодической отчётности, а данных от многочисленных сенсоров, поэтому стратегическое планирование поддерживается ИИ METABRAIN. С появлением ИИ роль руководителя проекта меняется от административного контроля к стратегической интерпретации. Контроль всё ещё важен, но теперь он тесно связан с непрерывным использованием ИИ-технологий, говорит компания. ИИ может порекомендовать перераспределить ресурсы или сообщить о вероятном сбое, но общение с другими людьми всё равно остаётся прерогативой человека. Aramco активно участвует в ИИ-проектах в Саудовской Аравии. Так, в сентябре 2024 года Aramco Digital объявила о партнёрстве с Cerebras, Groq и Qualcomm для развития ИИ и 5G IoT в стране. В феврале 2025 года Groq и Aramco Digital объявили об открытии крупнейшего в EMEA вычислительного ИИ-центра для инференса. |
|

