Материалы по тегу: hardware
|
03.05.2025 [21:12], Руслан Авдеев
ABI Research: из-за пошлин Трампа США рискуют проиграть Китаю в ИИ-гонкеНовые американские пошлины, если их действительно введут в полной мере, вероятно, приведут к росту цен на компоненты и материалы для дата-центров. В худшем случае они будут стоить США лидерства в гонке ИИ. Новые тарифы могут привести к приостановке или отмене инвестиций, сообщает The Register со ссылкой на исследование ABI Research. В документе «Как преодолеть тарифную турбулентность в технологическом секторе» (Navigating Tariff Turbulence In The Technology Sector) агентство указывает, что последствия пошлин, введённых президентом США Дональдом Трампом (Donald Trump), непредсказуемо меняют рынок ИИ, поскольку бизнес пересматривает цепочки поставок и инвестиционную политику. Например, компании, импортирующие готовые изделия, столкнулись с базовой пошлиной в объёме 10 %, а товары из Китая облагаются пошлиной 145 %, хотя многие высокотехнологичные продукты и/или их компоненты закупаются именно в Китае. Хотя такая стратегия призвана укрепить внутреннее производство США, на деле она создаёт сложности для многих отраслей, включая сектор IT, которые в значительной степени зависят от внешних поставок. 
Источник изображения: Hannah Xu/unsplash.com Так, даже строительство ЦОД в Соединённых Штатах станет более затратным из-за роста цен на сталь, алюминий и медь, а также электрическое оборудование, поставляемые из-за границы. Сильнее всего это ударит по мелким игрокам с ограниченными ресурсами. Но и крупным бизнесам придётся значительно увеличить капитальные затраты, что скажется на конкурентоспособности. Более высокие расходы на серверы, сетевое оборудование и системы хранения данных негативно скажутся на стоимости оборудования для операторов ЦОД. В результате компаниям придётся снизить рентабельность или терять клиентскую базу. В более широком контексте тарифы способны изменить динамику цепочек поставок, побуждая американских операторов диверсифицировать поставки компонентов и, возможно, вкладываться в местное производство для снижения затрат в будущем. Хотя США, с одной стороны, станут более самодостаточными, глобальные цепочки поставок в результате пострадают. Впрочем, некоторые компании уже пытаются включиться в новую американскую схему. Так, тайваньские производители серверов инвестируют в производство в США. 
Источник изображения: Dmitry Ant/unsplash.com Как сообщают в ABI, хотя полупроводники исключены из последнего пакета пошлин, в более широком контексте IT-отрасль всё равно пострадает, поскольку на инфраструктуру оказывается давление со всех сторон. Ранее эксперты уже сообщали, что нестабильная тарифная политика США вряд ли поможет рынку ЦОД, а в отрасли готовятся к резкому росту цен на серверы. Ситуация, возможно, усугубится из-за покупателей, уже запасшихся ключевыми компонентами до вступления пошлин в силу, об этом свидетельствуют данные поставщиков вроде Samsung и SK Hynix. HPE закупает для ИИ-серверов компоненты и материалы в Мексике, Китае, на Тайване, в Индии, Сингапуре, Малайзии и других странах, а также ведёт дела в Чехии. Введение пошлин существенно увеличит стоимость серверов компании. Сама HPE уже прогнозирует снижение выручки во II квартале из-за новых тарифов. Не застрахованы от потрясений и компании вроде Supermicro, подчёркивающие свою политику «Сделано в США». Они всё ещё сильно зависят от зарубежных компонентов. Компания уже сообщила, что её будущие квартальные результаты, вероятно, значительно отстанут от прогнозируемых ранее. 
Источник изображения: Bermix Studio/unsplash.com Другими словами, у американских компаний или увеличатся издержки и сократится прибыль, или придётся повысить цены для клиентов. В то же время на международном рынке покупатели смогут приобретать более конкурентоспособные продукты от Lenovo или Huawei. Предполагается, что это может привести к замедлению темпов расширения ЦОД и снижению спроса на ключевые компоненты, особенно на чипы высокой производительности. Компании вроде TSMC и Intel взяли на себя обязательство инвестировать немалые средства в производство полупроводников в США, но новые пошлины ставят их начинания под угрозу, поскольку создавать производственные мощности, включая заводы на основе машин ASML, тоже будет невыгодно. ABI предполагает, что в таких условиях многие проекты могут заморозить или отменить в надежде дождаться времён, когда инвестиции вновь начнут окупаться. Теоретически одним из решений могла бы стать реинвестиция пошлин во внутреннее производство, но, такой сценарий эксперты считают «маловероятным». Вероятнее всего долгосрочный отток инвестиций в инфраструктуру ИИ и замедление роста выпуска серверов, сокращение строительства ЦОД и, возможно, даже потеря лидирующих позиций США на мировом рынке ИИ. Рост затрат на производство окажет влияние на IT-бюджеты, и компаниям придётся пересмотреть планы развития ИИ в своих компаниях. Дорогие и «необязательные» ИИ-проекты, возможно, будут приостановлены или отменены, что замедлит внедрение ИИ в краткосрочной перспективе из-за финансовых ограничений. Проще говоря, политика Трампа, мечтающего восстановить американскую промышленность, может привести к тому, что США уступят первенство в сфере ИИ Китаю.
03.05.2025 [16:30], Владимир Мироненко
Новые пошлины США обойдутся Meta✴ в несколько миллиардов долларов — снижать темпы развития ИИ ЦОД компания не намеренаMeta✴ Platforms сообщила финансовые результаты I квартала 2025 года, завершившегося 31 марта. Основные показатели компании превысили прогнозы аналитиков, а прогноз на II квартал оказался в пределах ожиданий Уолл-стрит, благодаря чему акции компании выросли в цене на расширенных торгах на 5 %, пишет CNBC. Выручка Meta✴ увеличилась год к году на 16 % до $42,31 млрд, что также выше консенсус-прогноза аналитиков, опрошенных LSEG, в размере $41,40 млрд. Чистая прибыль подскочила на 35 % до $16,64 млрд по сравнению с $12,37 млрд годом ранее. Прибыль на разводнённую акцию увеличилась на 37 % до $6,43 с $4,37 в прошлом году, также превысив консенсус-прогноз аналитиков LSEG, равный $5,28 на разводнённую акцию. Капитальные затраты составили $13,69 млрд. Meta✴ ожидает, что выручка во II квартале составит от $42,5 до $45,5 млрд. Это соответствует среднему прогнозу аналитиков в $44,03 млрд. Также компания сообщила о планируемом сокращении общих расходов в 2025 году с прежних целевых показателей $114 – $119 млрд до $113 – $118 млрд. 
Источник изображений: Meta✴ Вместе с тем Meta✴ объявила о решении увеличить свои капитальные расходы на 2025 год до $64–$72 млрд, что выше предыдущего прогноза в $60–$65 млрд. «Этот обновленный прогноз отражает дополнительные инвестиции в ЦОД для поддержки наших усилий в области ИИ, а также увеличение ожидаемой стоимости инфраструктурного оборудования», — заявила финансовый директор Сьюзан Ли (Susan Li). «Большая часть наших капитальных затрат в 2025 году по-прежнему будет направлена на наш основной бизнес», — добавила она. Отвечая на вопрос о том, являются ли более высокие капитальные затраты Meta✴ на инфраструктуру ЦОД результатом введения новых торговых пошлин администрацией США, Сьюзан Ли сообщила: «Более высокие расходы, которые мы ожидаем понести на инфраструктурное оборудование в этом году, на самом деле исходят от поставщиков, которые закупают продукцию из стран по всему миру. И вокруг этого просто много неопределенности, учитывая продолжающиеся торговые дискуссии».  Как отметил The Register, дело не только в пошлинах. Заявление Ли также свидетельствует о том, что компания не просто платит больше за компоненты для ИИ ЦОД, но и развёртывает больше таких объектов. Ли сообщила, что пересмотренный прогноз капитальных вложений также отражает стремление компании увеличить мощности своих ИИ ЦОД. Ожидается, что дата-центры следующего поколения будут поддерживать как внутреннее обучение базовых моделей, так и инференс в экосистеме Meta✴, включая умные очки, помощников на базе LLM и функции «Семейного доступа». Она добавила, что Meta✴ работает над повышением эффективности рабочих нагрузок своих ЦОД. «Многие инновации, полученные в результате нашей работы по ранжированию, направлены на повышение эффективности наших систем, — сказала Ли. — Этот акцент на эффективность помогает нам стабильно получать высокую отдачу от наших основных инициатив в области ИИ». Ранее Meta✴ объявила о намерении ввести в эксплуатацию около 1 ГВт вычислительных мощностей в 2025 году и иметь к концу года более 1,3 млн ускорителей для обучения и обслуживания ИИ-моделей.
03.05.2025 [16:00], Руслан Авдеев
В Рио-де-Жанейро построят крупнейший в Латинской Америке кампус ЦОД Rio AI CityВ Рио-де-Жанейро объявлено о строительстве нового ИИ ЦОД. После завершения проекта кампус дата-центров станет крупнейшим в Латинской Америке и одним из крупнейших в мире, сообщает Datacenter Dynamics. Кампус Rio AI City расположится на территории Olympic Park. Первые 1,8 ГВт намерены ввести в строй к 2027 году, а к 2032 году возможно расширение до 3 ГВт. Ожидается, что в кампусе будут обеспечены условия для развёртывания новейших суперкомпьютеров. По словам мэра города, анонсировавшего проект, главная цель строительства нового кампуса — повысить роль Рио в развитии ИИ и закрепить за городом статус «столицы инноваций Латинской Америки». Город намерен стать движущей силой «ИИ-революции» и обеспечить гарантии того, что развитие искусственного интеллекта пойдёт обществу на благо. Мэр пообещал, что кампус будет целиком обеспечиваться «чистой» энергией и получит «неограниченный» запас воды для охлаждения оборудования. 
Источник изображения: Davi Costa/unsplash.com Кампус напрямую связан с проектом Porto Maravilha, предполагающим восстановление в городе старого портового района. По словам муниципальных властей, район станет центром экоустойчивых инноваций, а вычислительные мощности Rio AI City станут использовать для поддержки роста локальных стартапов. По данным Data Center Map, в Рио-де-Жанейро в настоящее время действует 21 дата-центр. В городе работают операторы Ascenty, Elea и Equinix. В прошлом месяце Equinix запустила в городе свой третий ЦОД — RJ3. Буквально на днях появилась информация, что ByteDance рассматривает строительство в Бразилии дата-центра TikTok, но он будет находиться в отдалении от Рио, в штате Сеара.
03.05.2025 [15:45], Владимир Мироненко
AWS показала самые слабые темпы роста за пять месяцев, но Amazon по-прежнему намерена вкладываться в развитие ЦОДФинансовые результаты Amazon в I квартале 2025 года, завершившемся 31 марта, в целом превзошли прогнозы аналитиков, но снижение темпов роста облачного подразделения Amazon Web Services (AWS), выручка которого оказалась ниже ожиданий Уолл-стрит, привело к падению акций компании на 3 % на внебиржевых торгах, пишет SiliconANGLE. Как сообщила Amazon, выручка AWS в I квартале 2025 года увеличилась год к году на 17 % до $29,27 млрд, в то время как консенсус-прогноз аналитиков, опрошенных StreetAccount, составил $29,42 млрд. Рост выручки подразделения также был ниже, чем в IV квартале 2024 года, составившем 18,9 %, и оказался самым слабым за последние пять кварталов. На AWS приходится около 19 % общего дохода Amazon. Это крупнейший в мире поставщик облачной инфраструктуры, но по темпам роста выручки подразделение уступает облачному бизнесу конкурентов — Microsoft Azure и Google Cloud Platform. 
Источник изображений: Amazon Операционная прибыль AWS составила $11,55 млрд, что больше прошлогоднего показателя в размере $9,42 млрд и консенсус-прогноза аналитиков от StreetAccount в $10,52 млрд. Операционная маржа равна 39, %, что является самым большим показателем, по крайней мере, с 2014 года. AWS заявила, что запускает в текущем квартале сервис потоковой передачи видеоигр и формирует группу агентского ИИ. Капитальные затраты подразделения составили $24,3 млрд, что на 74 % больше год к году. Значительный рост капзатрат объясняется стремлением расширить инфраструктуру ЦОД, необходимую для поддержки рабочих ИИ-нагрузок. В феврале Amazon сообщила о планах направить около $105 млрд на капитальные затраты в этом году, причем большая часть этих средств будет израсходована на расширение сети ЦОД. Что касается конкурентов, то Microsoft в этом году планирует потратить на инфраструктуру $80 млрд, Google — $75 млрд, а Meta✴ — до $65 млрд (и ещё +$8 млрд из-за новых пошлин). 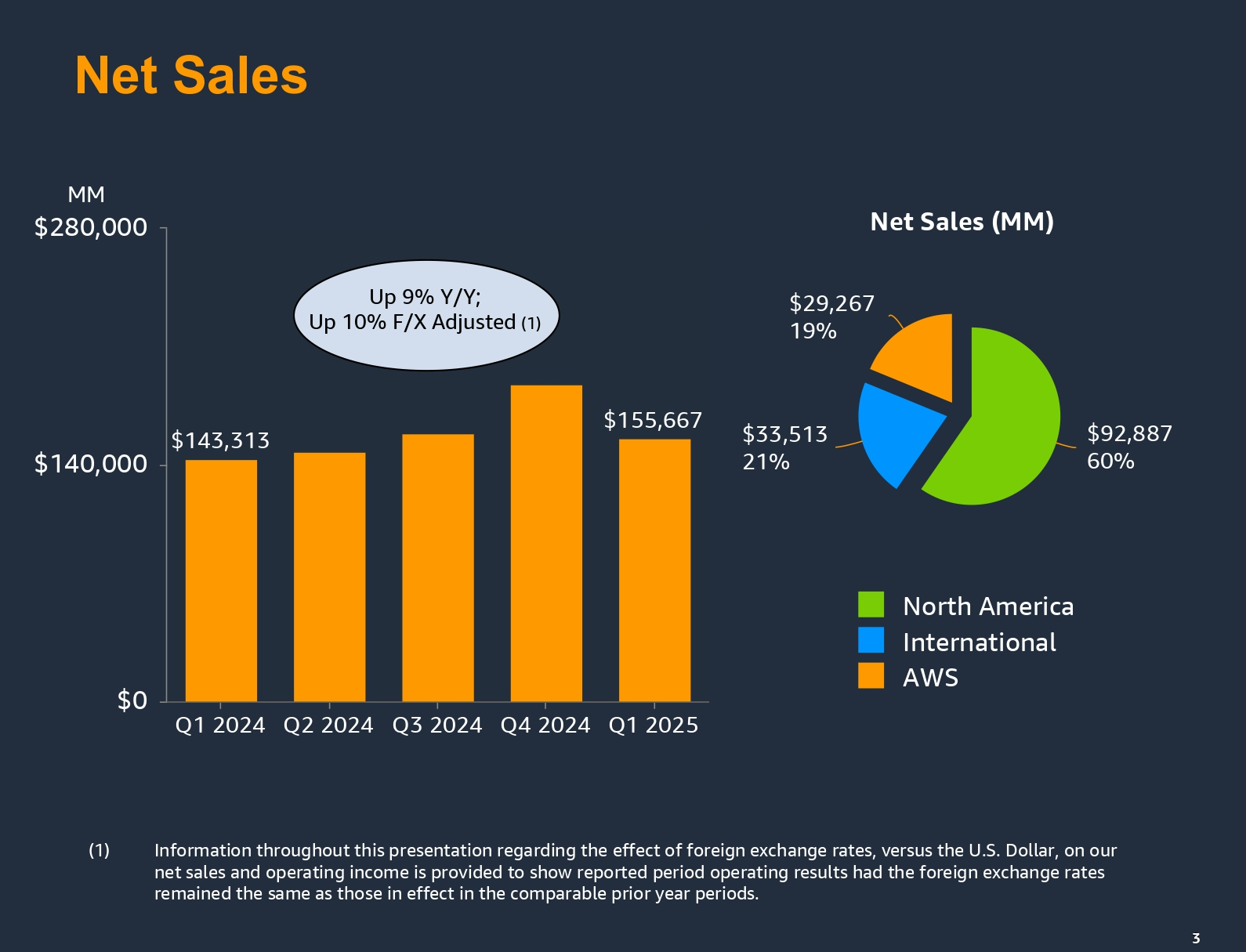 В своем ежегодном письме акционерам в прошлом месяце генеральный директор Amazon Энди Джасси (Andy Jassy) пообещал, что стоимость инфраструктуры ИИ-вычислений со временем снизится, отчасти благодаря специализированным процессорам Amazon, которые являются альтернативой ускорителям NVIDIA. В ходе телефонной конференции он сообщил аналитикам, что бизнес ИИ AWS теперь приносит «миллиарды» годового дохода. «Я думаю, что мы могли бы помогать большему количеству клиентов и приносить больше дохода для бизнеса, если бы у нас было больше мощностей, — сказал Джасси. — У нас гораздо больше инстансов Trainium2, а следующее поколение инстансов NVIDIA появится в ближайшие месяцы». Он отметил, что за последние шесть лет AWS диверсифицировала выпуск своих компонентов, отказавшись от китайских решений. 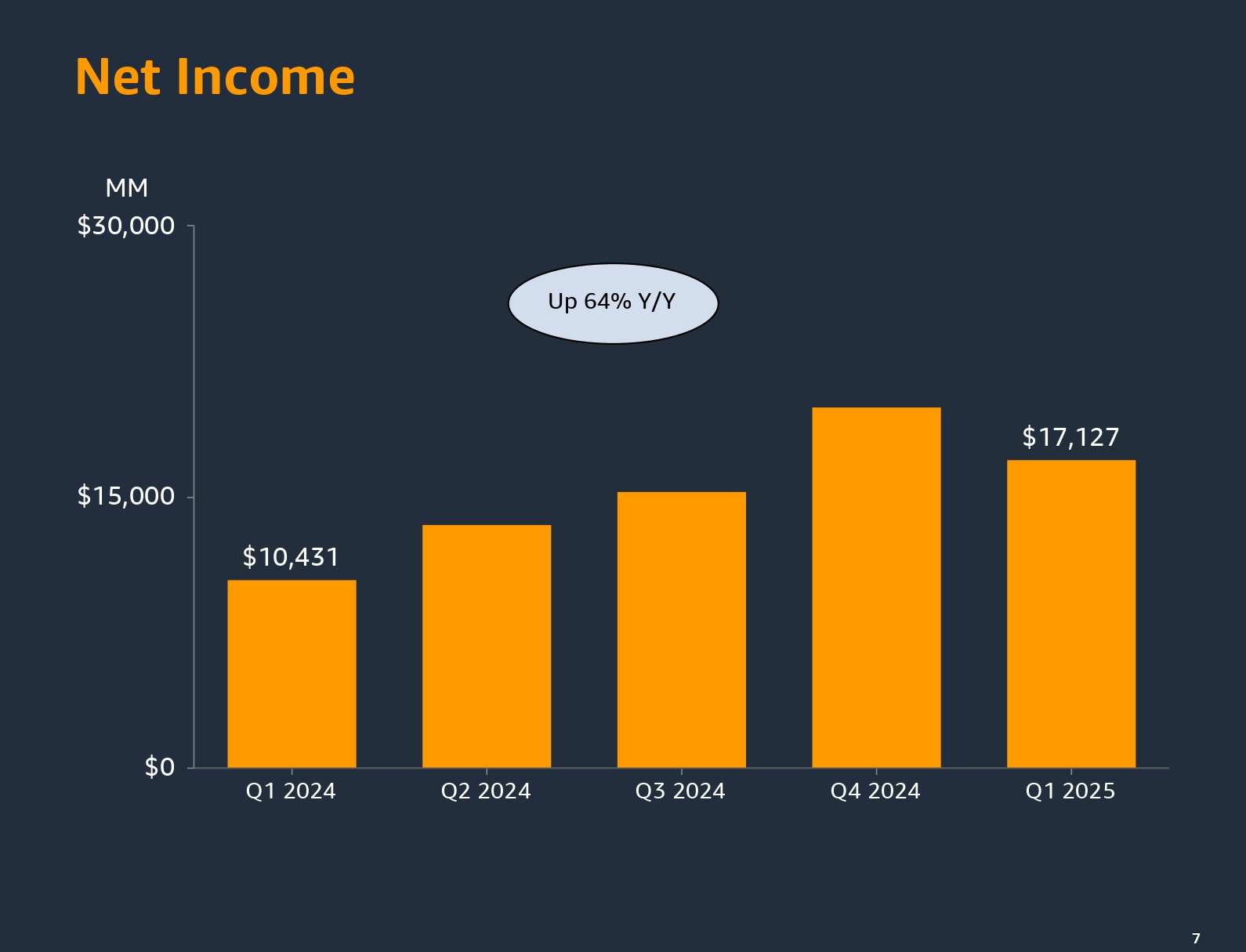 Что касается материнской компании Amazon, её выручка увеличилась на 9 % до $155,7 млрд со $143,3 млрд в аналогичном квартале 2024 года, превысив консенсус-прогноз аналитиков, опрошенных LSEG, в размере $155,04 млрд.Чистая прибыль Amazon за квартал составила $17,13 млрд или $1,59 на разводнённую акцию, что значительно выше показателей годом ранее в размере $10,43 млрд или $0,98 на разводнённую акцию, а также прогноза Уолл-стрит в $1,36 на разводнённую акцию. Amazon сообщила, что во II квартале ожидает получить выручку в диапазоне $159 – $164 млрд, что представляет собой рост год к году от 7 до 11 %. Средняя точка диапазона немного выше консенсус-прогноза аналитиков, опрошенных LSEG, в $160,91 млрд. Вместе с тем прогноз компании по операционной прибыли оказался ниже ожиданий аналитиков — $13–$17,5 млрд, что в средней точке значительно ниже целевого показателя Уолл-стрит в $17,64 млрд.  Финансовый директор Amazon Брайан Олсавски (Brian Olsavsky) сообщил в ходе телефонной конференции, что пошлины Трампа вызывают большую неопределенность, из-за чего сложно делать прогнозы. «Общая неопределённость, которую мы наблюдаем, и неопределенность потребительского спроса и всего остального заставляет нас немного расширить диапазон», — отметил он.
03.05.2025 [14:00], Владимир Мироненко
Samsung сообщила о рекордной выручке и предупредила о рыночной неопределённости из-за пошлин СШАSamsung Electronics сообщила финансовые результаты за I квартал 2025 года. Выручка компании достигла рекордного значения в ₩79,14 трлн (около $55,3 млрд), что больше показателя аналогичного квартала 2024 года на 10 % и выше её собственного прогноза в размере ₩79 трлн (около $55,2 млрд). Операционная прибыль составила ₩6,7 трлн ($4,68 млрд), превысив прошлогодний показатель на 1,2 %, а также собственный прогноз в размере ₩6,6 трлн ($4,61 млрд). Как сообщила Samsung, рост выручки и операционной прибыли был обеспечен за счёт успешных продаж флагманских смартфонов Galaxy S25 и продукции с высокой добавленной стоимостью — HBM и DRAM. Также на это повлиял рост закупок отдельных наименований продукции клиентами в связи с отсрочкой с введением пошлин США. 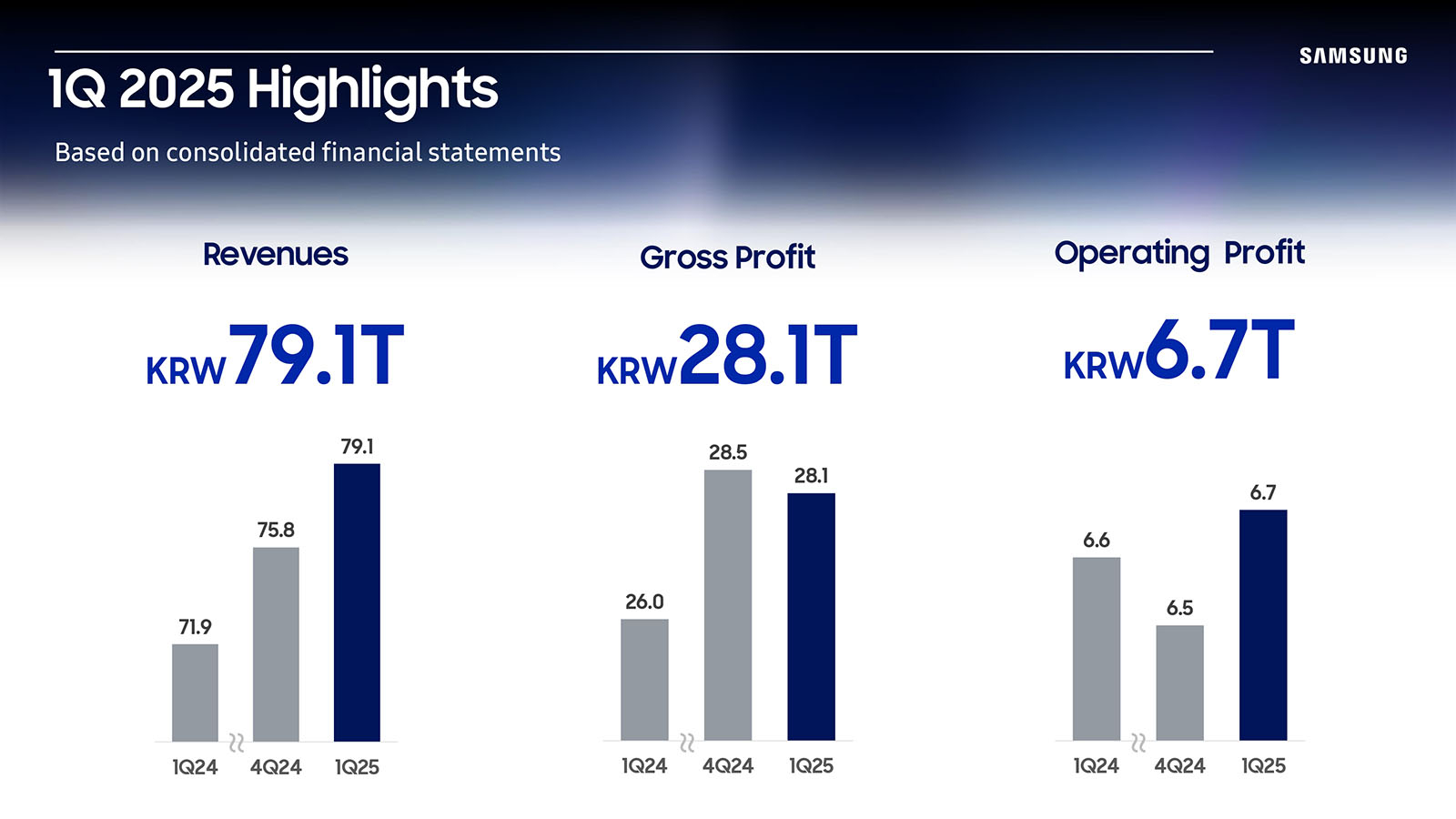
Источник изображений: Samsung Samsung заявила, что ожидает, что её полупроводниковый бизнес столкнётся с повышенной неопределённостью в течение года. Высокие пошлины США на китайские товары и ужесточение ограничений на продажу ИИ-чипов в Китае, главном рынке Samsung, грозят снизить спрос на некоторые электронные компоненты, которые производит компания, такие как чипы и дисплеи для смартфонов, сообщило агентство Reuters. «Взаимные» тарифы Дональда Трампа (Donald Trump), введение большинства которых было приостановлено до июля, грозят затронуть десятки стран, включая Вьетнам и Южную Корею, где у Samsung размещено производство смартфонов и дисплеев. Samsung заявила, что ожидает сохранения стабильного спроса на чипы во II квартале благодаря устойчивому спросу на ИИ-серверы и упреждающим закупкам полупроводников после приостановки действия пошлин, пишет The Register. Вместе с тем, нынешние поставки чипов некоторым клиентам могут оказать негативное влияние на спрос в конце этого года, считает компания. 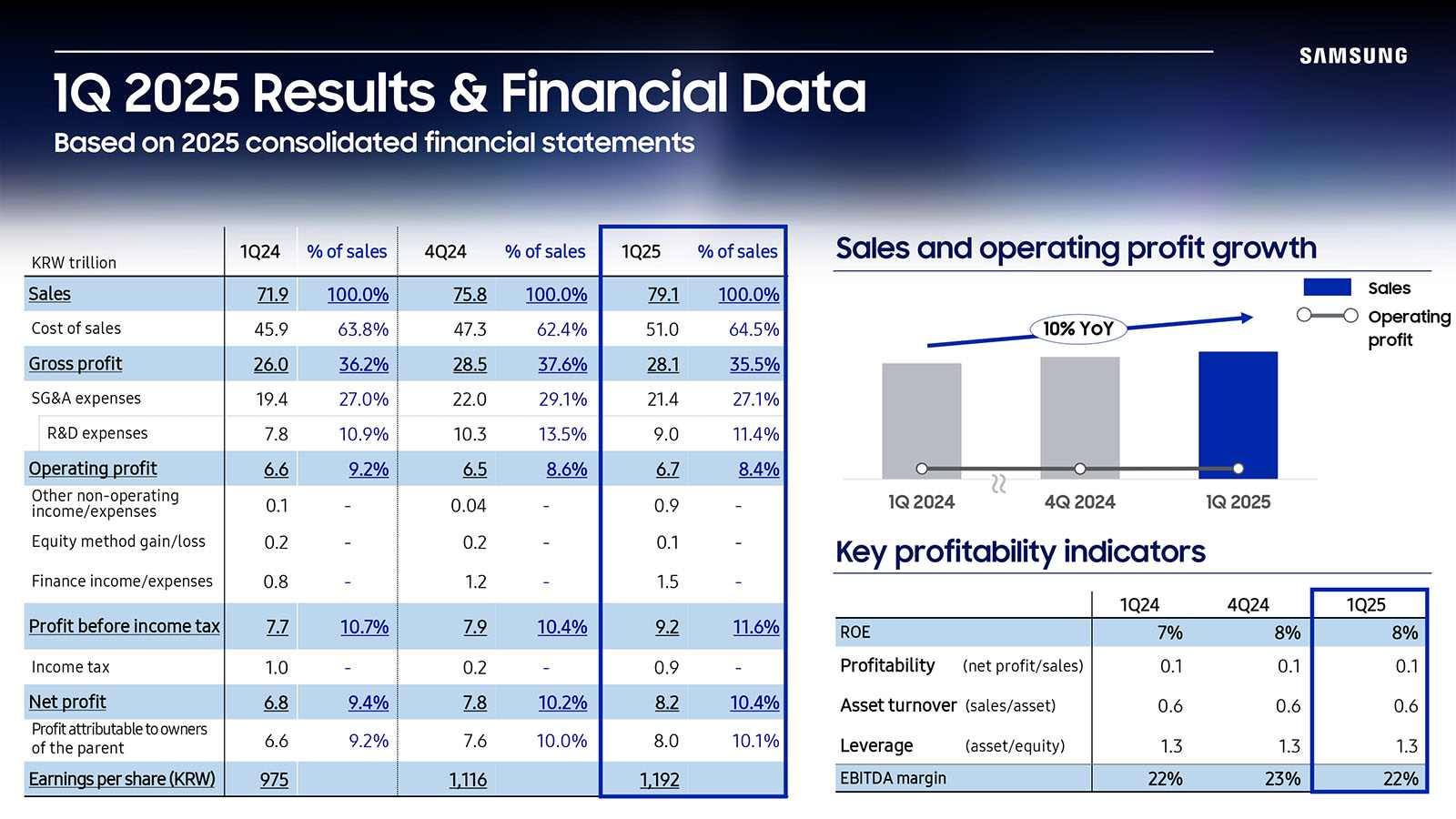 Выручка полупроводникового подразделения (Device Solutions, DS) составила ₩25,1 трлн ($17,53 млрд, рост 9 %), в то время как операционная прибыль упала на 42 % до ₩1,1 трлн ($0,77 млрд). Samsung сообщила о падении продаж памяти HBM, используемой в ИИ-чипах, отчасти из-за экспортного контроля США на ИИ-чипы и отложенного спроса в ожидании выхода следующего поколения памяти HBM3E. При этом общие поставки подразделения по производству памяти (Memory Business) выросли год к году на 9,1 % с ₩17,5 трлн до ₩19,1 трлн (с $12,22 до $13,42 млрд) благодаря росту продаж серверной DRAM и спросу на NAND-накопители.  Samsung планирует увеличить во II половине года продажи продуктов с высокой добавленной стоимостью, включая память HBM3E 12H и модули DDR5 высокой плотности ёмкостью 128 Гбайт и выше. По оценкам аналитиков, около трети выручки Samsung от HBM поступило от продаж в Китай, и она отстает от своего конкурента SK Hynix в поставках таких чипов для NVIDIA в Соединённые Штаты.  Исполнительный вице-президент Джэджун Ким (Jaejune Kim) сообщил, что спрос на твердотельные накопители, используемые в серверах, «остался относительно слабым после предыдущего квартала, поскольку некоторые проекты ЦОД были отложены». Ким заявил, что Samsung ожидает восстановления продаж SSD во II квартале и роста продаж памяти благодаря буму ИИ и дебюту новых ускорителей, которые стимулируют продажи серверов. Вместе с тем он предупредил, что «поскольку макроэкономическая неопределённость, связанная с изменением тарифной политики, продолжает расти, волатильность спроса, как ожидается, будет соответственно довольно высокой». Samsung планирует направить усилия на стабилизацию производства чипов использованием 2-нм техпроцесса с технологией GAA с дальнейшим выходом на их массовый выпуск. Финансовый директор Samsung Пак Сун-чхоль (Park Soon-cheol) заявил, что компания «с осторожностью ожидает, что общие показатели постепенно улучшатся по мере перехода ко II половине года, предполагая ослабление текущей неопределённости». Он отметил, что повышению эффективности компании будут также способствовать её усилия по развитию направлений ИИ и робототехники.
03.05.2025 [13:50], Сергей Карасёв
Raspberry Pi снизила цены на CM4: модули подешевели на $5–$10Raspberry Pi объявила о снижении цен на вычислительные модули Compute Module 4 (CM4), которые широко применяются в самых разных устройствах — от медицинского оборудования и средств индустриального мониторинга до игровых ретро-консолей и компактных медиасерверов. В общей сложности подешевели 16 вариантов CM4. Это модели с 4 и 8 Гбайт оперативной памяти LPDDR4-3200 с поддержкой беспроводной связи Wi-Fi 802.11b/g/n/ac и Bluetooth 5.0 (BLE) или без таковой. Снижена стоимость CM4 со всеми вариантами вместимости встроенного накопителя eMMC — 8, 16 и 32 Гбайт, а также без интегрированного флеш-чипа (модификация Lite). 
Источник изображений: Raspberry Pi Версии с 4 Гбайт ОЗУ подешевели на $5: теперь их цена варьируется от $45 до $60 без Wi-Fi / Bluetooth и от $50 до $65 с поддержкой беспроводной связи. В случае модулей с 8 Гбайт ОЗУ падение стоимости достигает $10: новые цены составляют соответственно от $65 до $80 и от $70 до $85. Подчёркивается, что удешевление затронуло только модели CM4 со стандартным диапазоном рабочих температур — от -20 до +85 °C. Варианты Extended Temperature с расширенным температурным диапазоном — от -40 до +85 °C — предлагаются по прежним ценам. 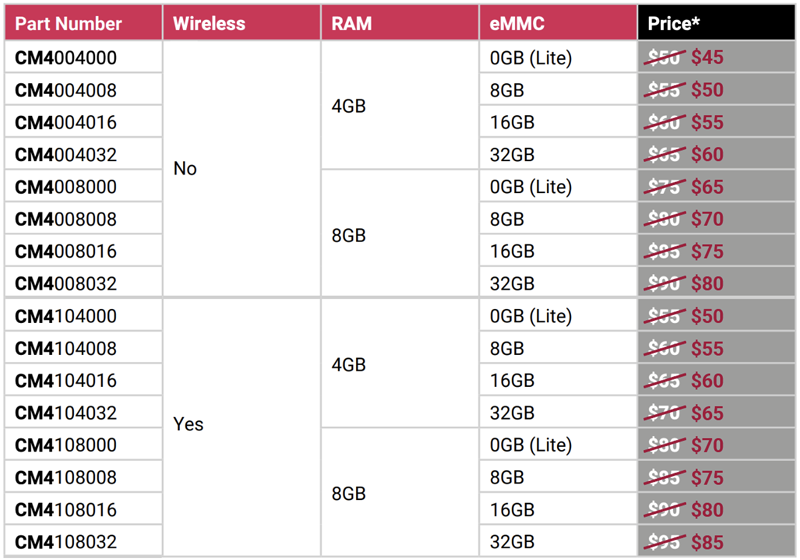 Вычислительные модули комплектуются 64-бит SoC Broadcom BCM2711 с четырьмя ядрами Cortex-A72 (ARM v8), работающими на частоте до 1,5 ГГц. Говорится о поддержке H.265 (декодирование материалов в формате до 4Kp60), H.264 (декодирование 1080p60 и кодирование 1080p30), OpenGL ES 3.1, Vulkan 1.0. Производить изделия планируется как минимум до января 2034 года.
02.05.2025 [14:05], Сергей Карасёв
Квартальная выручка Western Digital выросла почти на треть благодаря облачному сегментуКомпания Western Digital опубликовала показатели деятельности в III четверти 2025 финансового года, которая была завершена 28 марта. Выручка одного из крупнейших производителей HDD за год увеличилась на 31 % — с $1,75 млрд до $2,29 млрд. Положительная динамика обусловлена прежде всего хорошим спросом в облачном сегменте. Операционная прибыль Western Digital за год увеличилась в восемь раз, достигнув $760 млн против $94 млн в III квартале 2024 финансового года. Чистая прибыль, рассчитанная в соответствии с общепризнанными принципами бухгалтерского учёта (GAAP), составила $755 млн, или $2,11 в пересчёте на одну ценную бумагу. 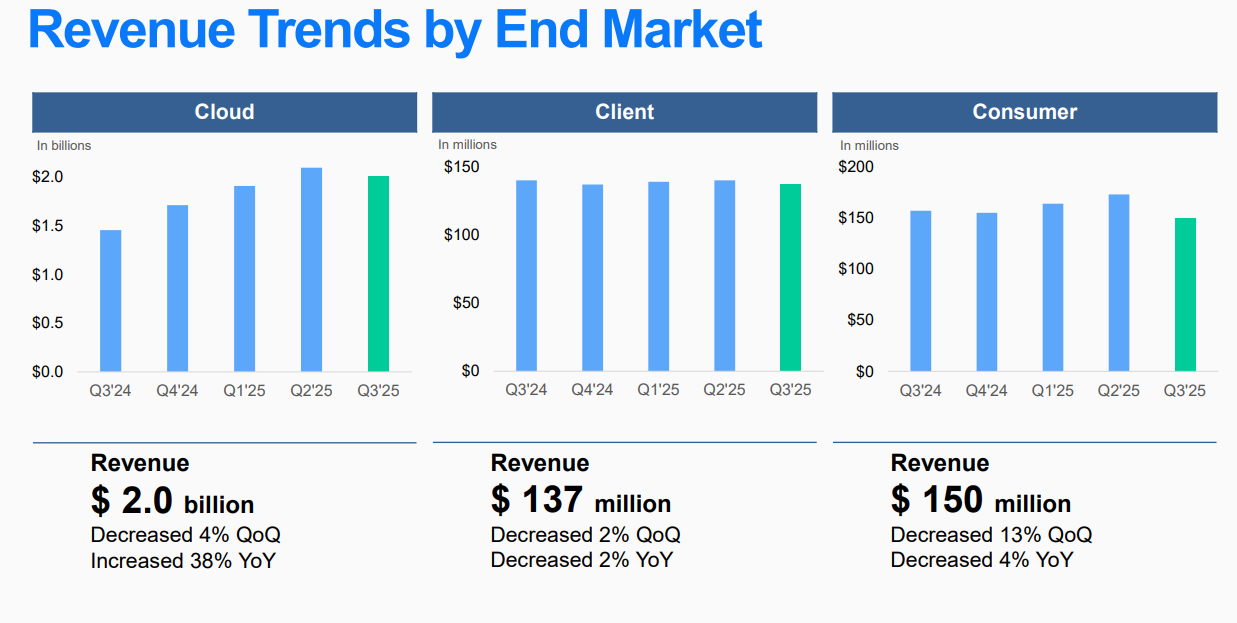
Источник изображения: Western Digital В облачном сегменте продажи достигли $2,01 млрд против $1,46 млрд годом ранее: это соответствует росту на 38 %. Вместе с тем в клиентском секторе выручка снизилась в годовом исчислении на 2 % — со $140 млн до $137 млн, а в потребительской сфере упала на 4 % — со $157 млн до $150 млн. Таким образом, на облачное направление пришлось 87 % от суммарных квартальных продаж Western Digital. В штучном выражении за отчётный период Western Digital реализовала 8,3 млн накопителей для облачного сектора, который включает гиперскейлеров и дата-центры. Это на 13,7 % больше по сравнению с результатом годичной давности, когда было реализовано 7,3 млн таких устройств. В ёмкостном плане отгрузки данных решений поднялись год к году на 32 %. В клиентском сегменте (ПК и OEM-производители) продажи в натуральном выражении за год снизились с 2,5 млн до 1,9 млн единиц. В потребительской области поставки за год практически не изменились, оставшись на уровне 1,9 млн штук. В целом, средняя стоимость реализованных HDD в годовом исчислении увеличилась со $145 до $179. В течение закрытого финансового квартала компания отгрузила более 800 тыс. HDD, конструкция которых включает 11 пластин: это CMR-устройства вместимостью до 26 Тбайт и модели UltraSMR ёмкостью 32 Тбайт. В IV финансовом квартале, который у Western Digital закончится 27 июня, компания рассчитывает получить около $2,45 млрд выручки (±$150 млн).
02.05.2025 [14:00], Сергей Карасёв
Seagate в полтора раза увеличила суммарную ёмкость поставленных за квартал Nearline-накопителейКомпания Seagate Technology отчиталась о работе в III четверти 2025 финансового года, которая была закрыта 28 марта. Выручка составила около $2,16 млрд: это на 31 % больше по сравнению с результатом за III квартал предыдущего финансового года, когда продажи равнялись $1,66 млрд. Чистая прибыль, рассчитанная в соответствии с общепризнанными принципами бухгалтерского учёта (GAAP), достигла $340 млн. Для сравнения, годом ранее компания заработала $25 млн. Таким образом, прибыль подскочила почти в 14 раз. Прибыль в пересчёте на одну ценную бумагу увеличилась с $0,12 до $1,57. Суммарная вместимость отгруженных за квартал накопителей Seagate достигла 143,6 Эбайт. Это на 45 % больше по сравнению с предыдущим годом, когда показатель находился на уровне 99,1 Эбайт. В Nearline-сегменте поставке в плане ёмкости увеличились в годовом исчислении на 55 % — с 77,3 Эбайт до 119,7 Эбайт. Средняя вместимость реализованного устройства хранения данных составила 12,6 Тбайт, что на 44 % больше, чем годом ранее (8,7 Тбайт). 
Источник изображения: Seagate Technology В финансовом отчёте сказано, что общая выручка Seagate от продаж HDD в III квартале 2025 финансового года достигла $2,0 млрд. Для сравнения: годом ранее продажи этих изделий принесли $1,48 млрд. Рост оказался на отметке 36 %. Ещё около $157 млн обеспечили SSD и прочие продукты: по данному направлению зафиксировано снижение на 11 % — годом ранее показатель равнялся $178 млн. Seagate заявляет о наращивании поставок накопителей, использующих технологию магнитной записи с подогревом (HAMR). Речь идёт об HDD на фирменной платформе Mozaic 3+. Отмечается, что закупки таких устройств увеличивает неназванный облачный заказчик. Кроме того, ведутся переговоры с другими крупными клиентами: отгрузки для них будут организованы во II половине 2025 календарного года. В IV финансовом квартале компания Seagate рассчитывает продемонстрировать выручку в размере $2,4 млрд (±$150 млн).
02.05.2025 [13:55], Сергей Карасёв
MSI представила многоузловые OCP-серверы на базе AMD EPYC 9005 TurinКомпания MSI анонсировала многоузловые серверы высокой плотности, выполненные в соответствии со стандартом OCP ORv3 (Open Rack v3). Дебютировали модели Open Compute CD281-S4051-X2 и Core Compute CD270-S4051-X4 на аппаратной платформе AMD EPYC 9005 Turin. Решение Open Compute CD281-S4051-X2, выполненное в форм-факторе 2OU, представляет собой двухузловой сервер для инфраструктур гиперскейлеров. Каждый узел может оснащаться одним процессором EPYC 9005 с показателем TDP до 500 Вт и 12 модулями DDR5. Доступны до 12 посадочных мест для накопителей E3.S с интерфейсом PCIe 5.0 (NVMe). Говорится о поддержке CPU-радиаторов Extended Volume Air Cooling (EVAC) и 48-вольтной архитектуры питания ORv3 (48VDC). 
Источник изображений: MSI В свою очередь, Core Compute CD270-S4051-X4 (S4051D270RAU3-X4) — это четырёхузловой сервер стандарта Data Center Modular Hardware Systems (DC-MHS). Устройство имеет типоразмер 2U. Оно подходит для облачных вычислений, CDN-сетей, ИИ-инференса и машинного обучения, виртуализации сетевых функций, телеком-приложений и пр.  Каждый узел новинки рассчитан на один чип EPYC 9005 с TDP до 400 Вт. Есть 12 слотов для модулей DDR5-6000 RDIMM/RIMM-3DS суммарным объёмом до 3 Тбайт, три фронтальных отсека для накопителей U.2 с интерфейсом PCIe 5.0 x4 (NVMe), два внутренних коннектора M.2 2280/22110 для SSD с интерфейсом PCIe 3.0 x2 (NVMe), а также слот PCIe 5.0 x16 OCP 3.0. Кроме того, каждый узел располагает контроллером ASPEED AST2600, сетевым портом управления 1GbE, разъёмами USB 2.0 Type-A и Mini DisplayPort, последовательным портом (USB Type-A). Вся система Core Compute CD270-S4051-X4 оборудована двумя блоками питания мощностью 2700 Вт с сертификатом 80 PLUS Titanium. Установлены четыре вентилятора охлаждения с возможностью горячей замены. Диапазон рабочих температур — от 0 до +35 °C. Габариты составляют 448 × 87 × 747 мм.
02.05.2025 [13:50], Сергей Карасёв
MiTAC анонсировала OCP-серверы на основе AMD EPYC Turin с воздушным и жидкостным охлаждением, а также edge-сервер на базе Intel Xeon Sapphire RapidsКомпания MiTAC Computing Technology представила OCP-серверы нового поколения C2810Z5 и C2820Z5, предназначенные для приложений ИИ и НРС. Устройства выполнены на аппаратной платформе AMD EPYC 9005 Turin. Решение C2810Z5 типоразмера 2OU имеет двухузловую конструкцию. Каждый узел допускает установку одного процессора и 12 модулей оперативной памяти DDR5-6400. Доступны шесть отсеков для накопителей U.2 и два посадочных места для SSD стандарта E1.S. Предусмотрены слоты PCIe 5.0 x16 для карт FHHL, HHHL и OCP NIC 3.0. Устройство оснащено воздушным охлаждением. Данная модель подходит для развёртывания микросервисов в облачных средах. В свою очередь, вариант C2820Z5 — это четырёхузловая система 2OU с технологией прямого жидкостного охлаждения. Каждый узел поддерживает два процессора EPYC 9005 Turin и 24 модуля памяти DDR5. Сервер подходит для высокопроизводительных вычислений. Кроме того, MiTAC анонсировала семейство серверов Whitestone 2 (WS2): это, как утверждается, компактная, но мощная платформа, специально оптимизированная для сетей Open RAN и периферийных задач. Система выполнена в корпусе небольшой глубины формата 1U. Задействован процессор Intel Xeon поколения Sapphire Rapids. 
Источник изображения: MiTAC Предусмотрены восемь слотов для модулей DDR5. Во фронтальной части находятся четыре порта 25GbE SFP28 и восемь портов 10GbE SFP+. Говорится о поддержке IEEE 1588 v2, Sync-E и GPS для синхронизации. В тыльной части располагаются вентиляторы охлаждения в виде девяти сдвоенных блоков. |
|

