Материалы по тегу: c
|
07.12.2023 [17:18], Сергей Карасёв
Scale Computing представила компактный компьютер HE153 на базе Intel Raptor Lake для периферийных вычисленийКомпания Scale Computing анонсировала первые устройства серии HE100, в основу которых положены компьютеры небольшого форм-фактора ASUS Next Unit of Computing (NUC). Решения, выполненные на платформе Intel Raptor Lake, предназначены для организации периферийных вычислений. Максимальная конфигурация включает процессор Core i7-1370P (6Р+8Е; 20 потоков; 1,4–5,2 ГГц; 20–28 Вт; Intel Iris Xe Graphics). Объём оперативной памяти может составлять 16, 32 или 64 Гбайт. Допускается установка одного SSD формата M.2 (NVMe) вместимостью 1, 2, 4 или 8 Тбайт. Дебютировали модели HE153 и HE153s: первая оснащена двумя сетевыми портами 2.5GbE, вторая — одним. На устройствах применена фирменная «самовосстанавливающаяся» программная платформа, позволяющая приложениям автономно функционировать на периферии. Прочие характеристики новинок пока не раскрываются. 
Источник изображения: Scale Computing Благодаря небольшим размерам три компьютера серии HE100 могут бок о бок монтироваться в серверное шасси типоразмера 1U. В качестве альтернативного варианта допускается установка нескольких устройств стопкой друг на друга. На фронтальную панель изделий выведены два порта USB 3.х Type-A. Сзади находится интерфейс HDMI. В продажу новинки поступят в I половине 2024 года по цене от $5400 за кластер из трёх узлов.
07.12.2023 [16:54], Сергей Карасёв
GigaIO создаст уникальное ИИ-облако с тысячами ускорителей AMD Instinct MI300XКомпания GigaIO объявила о заключении соглашения по созданию инфраструктуры для специализированного ИИ-облака TensorNODE, которое создаётся провайдером TensorWave. В составе платформы будут применяться ускорители AMD Instinct MI300X, оснащённые 192 Гбайт памяти HBM3. Основой TensorNODE послужат мини-кластеры SuperNODE, дебютировавшие летом уходящего года. Особенность этого решения заключается в том, что оно позволяет связать воедино 32 и даже 64 ускорителя посредством распределённого интерконнекта на базе PCI Express. TensorWave будет использовать FabreX для формирования пулов памяти петабайтного масштаба. На первом этапе в начале 2024 года платформа TensorNODE объединит до 5760 ускорителей Instinct MI300X в одном домене. Таким образом, при решении сложных задач можно будет получить доступ более чем к 1 Пбайт памяти с любого узла. Это, как отмечается, позволит обрабатывать даже самые ресурсоёмкие нагрузки в рекордно короткие сроки. 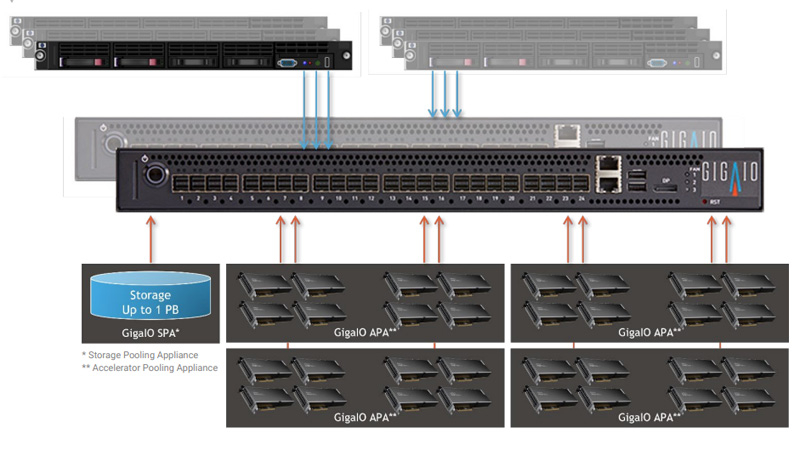
Источник изображения: GigaIO В течение следующего года планируется развернуть несколько систем TensorNODE. Архитектура GigaIO обеспечит улучшенную гибкость по сравнению с традиционными решениями: инфраструктуру можно будет оптимизировать «на лету» для удовлетворения как текущих, так и будущих потребностей в области ИИ и больших языковых моделей (LLM). Отмечается, что TensorNODE полностью базируется на ключевых компонентах AMD. Помимо ускорителей Instinct MI300X, это процессоры EPYC Genoa. Облако TensorWave обеспечит снижение энергозатрат и общей стоимости владения благодаря исключению из конфигурации избыточных серверов и связанного с ними сетевого оборудования.
06.12.2023 [20:09], Руслан Авдеев
Министерство энергетики США выявило плохое обслуживание экзафлопсного суперкомпьютера FrontierУправление генерального инспектора (OIG) Министерства энергетики США провело проверку ЦОД Национальной лаборатории Ок-Ридж, на базе которой работают передовые суперкомпьютеры, в том числе — первая в мире экзафлопсная система Frontier. Как сообщает The Register, результаты оставляют желать лучшего. В сентябре прошлого года в OIG поступило заявление о необходимости проверки качества обслуживания и калибровки оборудования (в первую очередь речь температурных датчиках и автоматике систем охлаждения) на площадке лаборатории, расположенной в Теннеси. Лаборатория занимается проектами в области атомной энергетики и обеспечения национальной безопасности. Доклад по результатам проверки связан с ЦОД на площадке Ок-Ридж. В одном из кампусов находится центр Oak Ridge Leadership Computing Facility (OLCF), управляющий суперкомпьютером Frontier. 
Фото: ORNL Инспекция проводилась с января по сентябрь 2023 года и подтвердила данные поступившего регулятору заявления. Согласно докладу OIG, в заявлении сообщалось, что программа калибровки не соответствовала нормам, а предохранительные клапаны (PRV) в ЦОД или совсем не обслуживались, или обслуживались недобросовестно. Сбой работы клапанов мог привести к повышению давления выше допустимых пределов, что потенциально могло нанести вред как оборудованию, так и персоналу. Как сообщают в OIG, поскольку инфраструктура не обслуживалась должным образом, этом могло ограничить доступность вычислительных ресурсов и поставить под угрозу выполнение целей миссии лаборатории. Управление вычислительными мощностями лаборатории выполняет некоммерческая организация UT-Battelle, созданная в 2000 году исключительно для контроля над площадкой Ок-Ридж в интересах Министерства энергетики при сотрудничестве с Университетом Теннесси и некоммерческим Мемориальным институтом Баттеля. 
Фото: ORNL В OIG заявляют, что программа обслуживания UT-Battelle не соответствовала необходимым требованиям. В самой UT-Battelle сообщили регулятору, что регулярная калибровка не нужна, поскольку каждый элемент оборудования калибруется при установке, а позже системы ЦОД постоянно контролируются субподрядчиком с помощью ПО, уведомляющего об инцидентах. В OIG подчёркивают, что хотя такая практика разрешена, всё ПО должно контролироваться с помощью специальной программы обеспечения качества, описывающей, каким именно образом соблюдаются требования к безопасности. Однако лаборатория не смогла предоставить таких документов — в UT-Battelle фактически не знают, предоставляет ли ПО корректные данные. Кроме того, UT-Battelle не проверяла вовремя все воздушные клапаны, а почти половина клапанов для воды и теплоносителя не была протестирована и/или обследована в соответствиями с инструкциями. В некоторых случаях тесты проводили в соответствии с рекомендациями производителя, а не принятыми в лаборатории правилами. UT-Battelle заявляет, что процедура проверки сейчас пересматривается. 
Изображение: AMD В отчёте OIG подчёркивается, что в 2020 году уже проводилась аналогичная проверка, выявившая буквально те же проблемы. Хотя в некоторых аспектах положение улучшилось, требуются дальнейшие меры для приведения дел в порядок. При этом в UT-Battelle полностью признали правомерность рекомендаций и согласились разработать план обеспечения качества для мониторингового ПО и обеспечить работу и обслуживание PRV-клапанов в соответствии с актуальными процедурами и требованиями.
06.12.2023 [20:05], Сергей Карасёв
РСК создала для Института математики СО РАН суперкомпьютер с быстродействием 54,4 ТфлопсВ Институте математики имени С.Л. Соболева Сибирского отделения Российской академии наук (ИМ СО РАН) в Новосибирске появился новый суперкомпьютер, который планируется применять для разработки перспективных технологий, анализа данных, выполнения научных исследований и пр. Установку и тестирование системы выполнили специалисты группы компаний РСК. Отмечается, что монтажные и пуско-наладочные работы осуществлены в сжатые сроки — за 3,5 недели. На создание комплекса предоставлен грант в рамках федеральной инициативы «Развитие инфраструктуры для научных исследований и подготовки кадров» Национального проекта «Наука и университеты». В основу суперкомпьютера положена платформа «РСК Торнадо» с жидкостным охлаждением. Задействованы вычислительные узлы, оснащённые двумя процессорами Intel Xeon Ice Lake-SP (38 ядер; базовая частота 2,4 ГГц). Производительность кластера в текущей конфигурации составляет 54,4 Тфлопс. Система, как заявляет РСК, позволит сотрудникам института решать сложные исследовательские задачи в области математики, физики, биологии и пр. 
Источник изображения: РСК В дальнейшем запланированы несколько этапов модернизации комплекса. Так, в ближайшей перспективе будут установлены более 12 вычислительных узлов и узел с GPU-ускорителями. В результате, в 2024 году производительность поднимется на 89 Тфлопс, превысив 140 Тфлопс. Суммарная потребляемая мощность машины составит примерно 41 кВт. До 2025 года планируется повышение быстродействия суперкомпьютера до 234,4 Тфлопс. «У нас появилась возможность решать задачи невероятной сложности, моделировать объёмные процессы и предсказывать поведение сложных математических систем. Ресурсы этого вычислительного комплекса будут использоваться для разработки новых технологий, анализа данных и в образовательных целях, например, мы сможем обучать студентов и молодых учёных современным методам проведения исследований и работы с данными», — отметил и.о. директора ИМ СО РАН Андрей Миронов.
06.12.2023 [13:19], Сергей Карасёв
Yotta анонсировала Shakti Cloud — самую мощную в Индии ИИ-платформу на базе NVIDIA H100Компания Yotta Data Services объявила о заключении соглашения о сотрудничестве, в рамках которого планируется развёртывание облачной инфраструктуры Shakti Cloud — самой высокопроизводительной в Индии платформы для задач ИИ на основе GPU. По условиям договора, Yotta закупит крупную партию ускорителей NVIDIA H100. К январю 2024 года планируется ввести в эксплуатацию 4096 ускорителей. Ещё 16 384 ускорителя войдут в состав Shakti Cloud к июню наступающего года. А к концу 2025-го инфраструктура Yotta будет насчитывать 32 768 ускорителей. Yotta развернёт первый кластер из 16 384 ускорителей на площадке NM1 — это крупнейший в Азии дата-центр класса Tier IV, расположенный в Нави-Мумбаи на западном побережье индийского штата Махараштра. Затем Yotta создаст кластер аналогичного масштаба в D1 — своём новейшем ЦОД гиперскейл-уровня в Грейтер-Нойде недалеко от Дели. Проектная мощность Shakti Cloud составит 16 Эфлопс на операциях ИИ. 
Источник изображения: NVIDIA На базе облака Yotta Shakti Cloud клиентам будут предоставляться различные услуги PaaS. Заказчики смогут обучать большие языковые модели (LLM), запускать ресурсоёмкие ИИ-задачи и другие рабочие нагрузки. Ожидается, что платформа поможет удовлетворить растущий спрос на услуги НРС со стороны исследовательских лабораторий, корпоративных пользователей и стартапов. Кроме того, Yotta намерена использовать решения NVIDIA InfiniBand для формирования GPU-кластеров, предназначенных для поддержания масштабных проектов, связанных с инференсом, обучением крупных ИИ-моделей и пр. В целом, партнёрство с NVIDIA поможет Индии укрепить позиции на стремительно растущем мировом рынке ИИ.
04.12.2023 [13:22], Сергей Карасёв
MediaTek представила чипы M60 и T300 для IoT-устройств 5G RedCapКомпания MediaTek анонсировала аппаратные решения с поддержкой 5G RedCap — модем M60 и чипсеты серии T300. Эти изделия предназначены для создания IoT-устройств коммерческого и промышленного классов с пониженным энергопотреблением и продолжительным сроком работы от батареи. 5G RedCap, или Reduced Capability, снижает требования к устройствам и в то же время предоставляет расширенные возможности по сравнению с 4G: это повышенная скорость передачи данных и уменьшенные задержки. При этом в отличие от обычных инфраструктур 5G, сети RedCap предоставляют базовые возможности подключения, адаптированные для менее мощного и требовательного IoT-оборудования. 
Источник изображения: MediaTek Модем M60 и чипсеты T300 соответствуют стандарту 3GPP R17. Благодаря фирменной технологии MediaTek UltraSave 4.0, по заявлениям MediaTek, изделие M60 обеспечивает снижение энергопотребления до 70 % по сравнению с аналогичными решениями 5G eMBB (enhanced Mobile BroadBand) и до 75 % по сравнению с решениями 4G. Как утверждается, T300 — это первая в мире 6-нм однокристальная радиочастотная система (RFSOC) для сетей RedCap. Она содержит одно ядро Arm Cortex-A35. Заявленная скорость загрузки данных через мобильную сеть достигает 227 Мбит/с, скорость передачи в сторону базовой станции — 122 Мбит/с. Изготавливаться изделие будет на предприятии TSMC. Появление изделий MediaTek 5G RedCap, как отмечается, поможет разработчикам в создании энергоэффективных, надёжных и экономичных IoT-продуктов нового поколения для потребительского, корпоративного и промышленного секторов. Устройства на базе MediaTek T300 будут представлены в I половине 2024-го, а коммерческие образцы выйдут во II полугодии.
03.12.2023 [00:13], Сергей Карасёв
SSSTC представила SSD серии PJ1 с технологией TruePLPКомпания Solid State Storage Technology Corporation (SSSTC), дочерняя структура Kioxia, анонсировала SSD семейства PJ1 для систем корпоративного уровня. Изделия выполнены в форм-факторе М.2 на основе микрочипов флеш-памяти eTLC NAND, а для обмена данными служит интерфейс PCIe 4.0 x4 (спецификация NVMe 1.4c). В устройствах реализована фирменная защита от потери питания TruePLP (Power Loss Protection). В оснащение входят высоконадежные конденсаторы для резервной подачи энергии. В случае сбоя TruePLP предоставляет SSD возможность записать любые данные из памяти DRAM во флеш-память NAND, предотвратив тем самым потерю информации. 
Источник изображения: SSSTC В серию PJ1 вошли модели типоразмера М.2 2280 и М.2 22110. В первом случае вместимость составляет 480 и 960 Гбайт, а также 1,92 Тбайт, во втором — ещё и 3,84 Тбайт. Скорость последовательного чтения информации у всех версий достигает 5000 Мбайт/с, скорость последовательной записи — соответственно 600, 1200, 2400 и 2400 Мбайт/с. Величина IOPS при произвольном чтении / записи данных блоками по 4 Кбайт составляет до 350 000 / 150 000, 650 000 / 300 000, 750 000 / 600 000 и 750 000 / 600 000. Гарантированный объём записанной информации (показатель TBW) — 1000, 2000, 4000 и 8000 Тбайт соответственно. Все накопители могут выдерживать 1,2 полных перезаписи в сутки (величина DWPD) на протяжении пяти лет. Говорится о поддержке TCG Opal 2.0. Показатель MTBF заявлен на уровне 3 млн часов. Диапазон рабочих температур простирается от 0 до +70 °C.
01.12.2023 [23:19], Алексей Степин
Broadcom представила первый сетевой коммутатор со встроенным ИИ-движкомКомпания Broadcom представила Trident 5-X12 — первый сетевой коммутатор, снабжённый ИИ-движком, который поможет избавиться от сетевых заторов и ускорить обучение ИИ. Новый сетевой процессор относится к семейству StrataXGS и имеет маркировку BCM78800. Он предназначен в первую очередь для компактных ToR-коммутаторов нового поколения. Это первый сетевой ASIC, дополненный инференс-движком NetGNT (Networking General-purpose Neural-network Traffic-analyzer). NetGNT может быть «натаскан» на распознавание ситуации, потенциально ведущей к сетевому затору. К примеру, в сценариях, характерных для обучения нейросетей, часто встречается ситуация, когда множество потоков пакетов прибывает одновременно на один порт, что и вызывает затор. Но движок Broadcom способен предсказать и заранее предотвратить такое развитие событий. 
Источник изображений здесь и далее: Broadcom Trident 5-X12 также имеет расширенную систему телеметрии и располагает объёмными FIB с гибким распределением. Реализованы множественные механизмы распределения нагрузки и предотвращения заторов. Новинка относится к программируемым решениям (NPL), причём готовые сценарии предлагает и сама Broadcom. В рамках API сохранена совместимость с предыдущими решениями компании. Возможно использование SONiC. 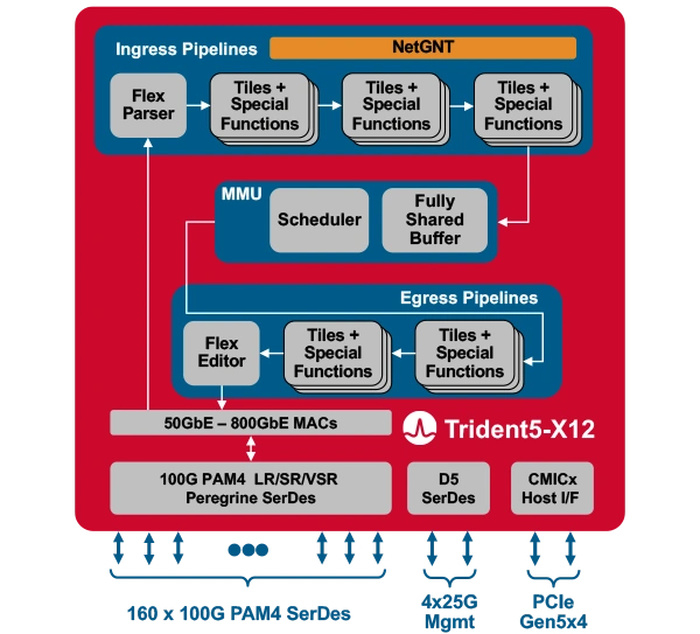 Чип оснащён 160 100G-блоками SerDes (PAM-4) и позволяет среди прочего реализовывать смешанные конфигурации — например, с 24 портами 400G и 8 портами 800G в 1U-шасси. При этом совокупная пропускная способность составляет 16 Тбит/с, однако благодаря 5-нм техпроцессу энергопотребление у новинки в пересчёте на порт на четверть ниже, нежели у Trident 4-X9.
01.12.2023 [11:50], Сергей Карасёв
В основу ИИ-суперкомпьютера NCSA DeltaAI лягут суперчипы NVIDIA GH200 Grace HopperНациональный центр суперкомпьютерных приложений (NCSA) при Университете Иллинойса в Урбане-Шампейне (США) сообщил о том, что в 2024 году в эксплуатацию будет введён вычислительный комплекс DeltaAI. Его основой послужат суперчипы NVIDIA GH200 Grace Hopper. Система DeltaAI создаётся с прицелом на ресурсоёмкие приложения ИИ. В рамках проекта NCSA в июле нынешнего года получил $10 млн от Национального научного фонда США (NSF). Инициатива DeltaAI направлена на расширение использования возможностей ИИ при реализации различных исследовательских задач. Комплекс DeltaAI станет дополнением к суперкомпьютеру Delta, который заработал в NCSA в 2022 году. Данная система занимает 199-е место в ноябрьском рейтинге TOP500 с быстродействием около 3,81 Пфлопс. Теоретическая пиковая производительность достигает 8,05 Пфлопс. В основу положены процессоры AMD EPYC 7763 Milan и интерконнект Slingshot-10. 
Источник изображения: NCSA Отмечается, что DeltaAI утроит вычислительные мощности NCSA, ориентированные на задачи ИИ, и значительно расширит ресурсы, доступные в НРС-экосистеме, финансируемой NSF. Благодаря использованию передовых интерфейсов система DeltaAI будет более доступна для различных исследовательских ИИ-проектов. Производительность DeltaAI пока не раскрывается. Нужно отметить, что суперчип GH200 Grace Hopper ляжет в основу более чем 40 ИИ-суперкомпьютеров по всему миру. Это, в частности, первый европейский суперкомпьютер экзафлопсного класса Jupiter, британский комплекс Isambard-AI в Бристольском университете и пр.
27.11.2023 [17:10], Сергей Карасёв
FriendlyElec выпустила комплект CM3588 NAS Kit для создания хранилищ на базе M.2 SSDКоманда FriendlyElec, как сообщает ресурс CNX-Software, анонсировала комплект CM3588 NAS Kit, предназначенный для построения компактных сетевых хранилищ на основе M.2 2280 NVMe SSD. В основу решения положена аппаратная платформа Rockchip. В состав комплекта входят вычислительный модуль CM3588 и интерфейсная плата. Модуль несёт на борту чип RK3588 (4 × Cortex-A76 @ 2,4 ГГц, 4 × Cortex-A55 @ 1,8 ГГц, Arm Mali-G610 MP4). Имеется нейропроцессорный блок (NPU) с производительностью до 6 TOPS. Объём оперативной памяти LPDDR4x-2133 может составлять 4, 8 и 16 Гбайт. Есть возможность установки флеш-накопителя eMMC вместимостью 64 Гбайт. Присутствуют сетевой контроллер Realtek RTL8125BG 2.5GbE и аудиокодек Realtek ALC5616. Размеры вычислительного модуля — 65 × 55 мм. 
Источник изображения: FriendlyElec Интерфейсная плата располагает четырьмя коннекторами для SSD формата M.2 2280 (PCIe 3.0) и слотом для карты microSD. Доступны два выхода HDMI 2.1 (один с поддержкой 8Kp60, второй — 4Kp60), порт USB Type-C / DisplayPort (до 4Kp60), вход HDMI 2.0 (4Kp60), коннекторы MIPI DSI и MIPI CSI, аудиогнездо на 3,5 мм, разъём RJ-45, два порта USB 3.0 Type-A и порт USB 2.0. Предусмотрены 40-контактная колодка GPIO (2 × SPI, 6 × UART, 1 × I2C, 8 × PWM, 2 × I2S, 28 × GPIO), инфракрасный приёмник и разъём для вентилятора охлаждения. Габариты — 160 × 116 мм. Диапазон рабочих температур простирается от 0 до +70 °C. Питание подаётся через разъём DC (12 В). Цена комплекта FriendlyElec CM3588 NAS Kit составляет $155 с вычислительным модулем 8 + 64 Гбайт, интерфейсной платой, радиатором охлаждения и блоком питания. |
|

