Материалы по тегу: c
|
27.11.2023 [17:10], Сергей Карасёв
FriendlyElec выпустила комплект CM3588 NAS Kit для создания хранилищ на базе M.2 SSDКоманда FriendlyElec, как сообщает ресурс CNX-Software, анонсировала комплект CM3588 NAS Kit, предназначенный для построения компактных сетевых хранилищ на основе M.2 2280 NVMe SSD. В основу решения положена аппаратная платформа Rockchip. В состав комплекта входят вычислительный модуль CM3588 и интерфейсная плата. Модуль несёт на борту чип RK3588 (4 × Cortex-A76 @ 2,4 ГГц, 4 × Cortex-A55 @ 1,8 ГГц, Arm Mali-G610 MP4). Имеется нейропроцессорный блок (NPU) с производительностью до 6 TOPS. Объём оперативной памяти LPDDR4x-2133 может составлять 4, 8 и 16 Гбайт. Есть возможность установки флеш-накопителя eMMC вместимостью 64 Гбайт. Присутствуют сетевой контроллер Realtek RTL8125BG 2.5GbE и аудиокодек Realtek ALC5616. Размеры вычислительного модуля — 65 × 55 мм. 
Источник изображения: FriendlyElec Интерфейсная плата располагает четырьмя коннекторами для SSD формата M.2 2280 (PCIe 3.0) и слотом для карты microSD. Доступны два выхода HDMI 2.1 (один с поддержкой 8Kp60, второй — 4Kp60), порт USB Type-C / DisplayPort (до 4Kp60), вход HDMI 2.0 (4Kp60), коннекторы MIPI DSI и MIPI CSI, аудиогнездо на 3,5 мм, разъём RJ-45, два порта USB 3.0 Type-A и порт USB 2.0. Предусмотрены 40-контактная колодка GPIO (2 × SPI, 6 × UART, 1 × I2C, 8 × PWM, 2 × I2S, 28 × GPIO), инфракрасный приёмник и разъём для вентилятора охлаждения. Габариты — 160 × 116 мм. Диапазон рабочих температур простирается от 0 до +70 °C. Питание подаётся через разъём DC (12 В). Цена комплекта FriendlyElec CM3588 NAS Kit составляет $155 с вычислительным модулем 8 + 64 Гбайт, интерфейсной платой, радиатором охлаждения и блоком питания.
27.11.2023 [10:42], Сергей Карасёв
Объём мирового НРС-рынка превысит $100 млрд к 2028 годуАналитики ResearchAndMarkets обнародовали прогноз по глобальному НРС-рынку до 2028 года. Эксперты полагают, что отрасль продолжит демонстрировать устойчивый рост на фоне стремительного развития приложений ИИ и увеличивающейся потребности в обработке больших данных. По оценкам, в 2022-м мировые затраты в сфере НРС достигли $46,2 млрд. В перспективе ожидается показатель CAGR (среднегодовой темп роста в сложных процентах) на уровне 15,5 %. Если этот прогноз оправдается, к 2028-му объём рынка составит около $107,8 млрд. 
Источник изображения: Microsoft В 2022 году на НРС-рынке доминировал сегмент аппаратного обеспечения с затратами примерно $23,8 млрд. В данной области также прогнозируется величина CAGR на отметке 15,5 %. Таким образом, к 2028-му расходы на аппаратные решения поднимутся до $55,1 млрд. Вклад в расширение закупок «железа» для НРС-платформ вносят такие отрасли, как производство, оборона, финансовый сектор, здравоохранение, научно-исследовательский сегмент и пр. Ключевыми драйверами рынка ResearchAndMarkets называет приложения с интенсивным использованием данных (ИИ, машинное обучение, аналитика), цифровую трансформацию предприятий, расширение облачного сегмента, правительственные инициативы по развитию высокопроизводительных вычислений и конвергенцию технологий (HPC, ИИ, квантовые и периферийные вычисления). Вместе с тем аналитики указывают и на ряд сложностей, препятствующих росту НРС-рынка. Среди них — высокие затраты на создание инфраструктуры, увеличение энергопотребления, нехватка квалифицированных специалистов и нормативно-правовые вопросы.
26.11.2023 [23:28], Руслан Авдеев
Великобритания инвестирует ещё £500 млн в ИИ-вычисления и реализует пять новых квантовых проектов
hardware
hpc
великобритания
ии
инвестиции
квантовые вычисления
квантовый компьютер
суперкомпьютер
финансы
Британское правительство намерено потратить дополнительные £500 млн (около $626 млн), чтобы местные учёные и исследовательские организации получили возможность заниматься передовыми ИИ-разработками. Как уточняет Silicon Angle, дополнительно будет реализовано пять новых квантовых проектов в рамках Национальной квантовой стратегии с бюджетом £2.5 млрд (примерно $3,1 млрд). £500 млн потратят на ИИ-инфраструктуру в ближайшие два года, а общий объём планируемых инвестиций в эту сферу превысит £1,5 млрд. Закупленное оборудование будет доступно учёным и экспертам по машинному обучению, а также стартапам в области ИИ. В частности, именно в рамках этой инициативы для Бристольского университета создаётся ИИ-суперкомпьютер Isambard-AI. В рамках Национальной квантовой стратегии власти намерены запустить пять специализированных проектов. В частности, одна из инициатив направлена на внедрение квантовых компьютеров, «способных выполнять триллион операций» [подряд до первой ошибки]. Власти считают, что такие вычисления нецелесообразно проводить с помощью классических компьютеров и суперкомпьютеров. В перспективе они надеются с помощью квантовых технологий добиться прорывов в самых разных отраслях: здравоохранении, финансах, оборонном и энергетическом секторах, промышленности и др. 
Источник изображения: Karlis Reimanis/unsplash.com Параллельно будет реализовано создание сети, связывающей многочисленные удалённые квантовые процессоры, причём одной из задач станет коммерциализация квантовых сетевых технологий. Наконец, ещё три проекта связаны с разработкой квантовых сенсоров, в том числе мобильных, а также созданием нового поколения систем навигации на базе квантовых решений. Кроме того, Великобритания выделит средства на поддержку талантливых учёных и университетских стартапов, подготовку венчурных инвесторов и математиков, создание батарей и низкоорбитальных спутников и т.д.
25.11.2023 [19:56], Сергей Карасёв
Китайский процессор Sunway SW26010 Pro с 384 ядрами обеспечивает быстродействие 13,8 ТфлопсНа фоне американских санкций Китай ведёт активную разработку собственных процессоров. Одним из таких изделий является чип Sunway SW26010-Pro для суперкомпьютеров и НРС-систем. Недавно, как сообщает ресурс Tom's Hardware, были раскрыты характеристики этого изделия. Процессор SW26010-Pro, первая информация о котором появилась в 2021 году, является значительно улучшенной версией модели SW26010. От прародителя Pro-вариант унаследовал базовую архитектуру. 
Источник изображений: Chips and Cheese Решение SW26010-Pro использует 64-битную платформу RISC. В состав чипа входят шесть групп ядер (Core Group, CG) и блок обработки протоколов (Protocol Processing Unit, PPU). Каждый узел CG содержит 64 вычислительных элемента (Compute Processing Element, CPE) с 512-бит векторным механизмом, а также 256 Кбайт быстрого кеша данных и 16 Кбайт кеша для инструкций. Таким образом, общее количество ядер достигает 384 против 256 у обычной версии SW26010. Кроме того, в конструкцию SW26010-Pro входит один элемент обработки управления (Management Processing Element, MPE) в расчёте на узел CG: это суперскалярное ядро с внеочередным исполнением и векторным движком, 32 Кбайт кеша инструкций и 32 Кбайт кеша данных L1, 256 Кбайт кеша L2 и 128-бит интерфейсом памяти DDR4-3200. MPE и CPE используют протокол на основе директорий, который обеспечивает согласованный обмен данными. Это сокращает объём информации, которой обмениваются ядра, и гарантирует точное взаимодействие, что важно для приложений с нерегулярным доступом к совместно используемым данным. 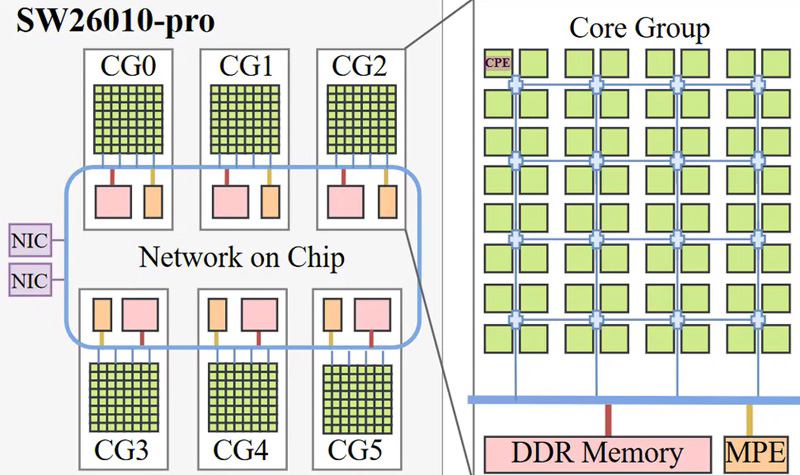 Процессор SW26010-Pro функционирует на частотах 2,25 ГГц для CPE и 2,10 ГГц для MPE против 1,45 ГГц (в обоих случаях) у предшественника. Заявленная производительность достигает 13,8 Тфлопс FP64 и 27,6 Тфлопс FP32. Для сравнения: у обычной модели SW26010 быстродействие FP64 равно 2,9 Тфлопс, а у процессора AMD EPYC 9654 Genoa — 5,4 Тфлопс. Каждый узел CG теперь поддерживает 16 Гбайт памяти DDR4 (против 8 Гбайт DDR3 у SW26010), а максимально допустимый объём ОЗУ достигает 96 Гбайт. При этом, как отмечается, у SW26010 Pro сохраняются ограничения в плане производительности кеша и подсистемы ОЗУ. Так, 256 Кбайт кеша в расчёте на CPE при отсутствии надлежащего кеша L2 недостаточно, а двухканальной подсистемы памяти DDR4-3200 (51,2 Гбайт/с) едва хватает на 64 ядра, каждое из которых имеет 512-бит векторный FPU и обеспечивает производительность до 16 Флопс/цикл (FP64).
25.11.2023 [19:51], Сергей Карасёв
Сандийские национальные лаборатории возьмут на вооружение НРС-платформу NextSiliconСандийские национальные лаборатории (SNL) Министерства энергетики США объявили о заключении партнёрского соглашения с компаниями NextSilicon и Penguin Solutions с целью создания системы прототипов на основе передовой архитектуры (Advanced Architecture Prototype System AAPS, AAPS). Речь идёт об определении и оценке новых технологий, которые ещё не были протестированы или внедрены, чтобы установить возможность их использования в рамках программы Advanced Simulation and Computing (ASC). Данная инициатива реализуется Национальным управлением по ядерной безопасности США (NNSA). 
Источник изображения: NextSilicon NextSilicon разрабатывает новую вычислительную платформу, ориентированную на сегмент НРС. Компания использует интеллектуальные программные алгоритмы для динамической реконфигурации оборудования на основе данных, получаемых непосредственно во время выполнения задачи. Это даёт возможность оптимизировать производительность и энергопотребление, обеспечив преимущества по сравнению с традиционными аппаратными решениями. Лаборатории SNL сотрудничают с NextSilicon более трёх лет. Решения NextSilicon будут интегрированы и поставлены специалистами компании Penguin Solutions, с которой SNL работают с 2010 года. Новый НРС-комплекс стандарта OCP получит СЖО Chilldyne, что поможет поднять энергоэффективность. Системы закупаются по проекту Sandia Vanguard: отгрузка первых образцов запланирована на 2024 год, после чего последует поставка Spectra — решения второго поколения. Между тем компании DataDirect Networks (DDN) и NextSilicon представили комплексное решение, которое оптимизирует производительность ввода-вывода ЦОД при выполнении ресурсоёмких задач. Платформа, как утверждается, обеспечивает значительное повышение быстродействия благодаря одновременному подключению устройства хранения данных AI400NVX2 DDN к высокоскоростным сетям InifiniBand и Ethernet.
24.11.2023 [17:14], Сергей Карасёв
Лос-Аламосская национальная лаборатория внедрит обновлённые ИИ-системы SambaNovaЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США (DOE) заключила соглашение о сотрудничестве со стартапом SambaNova Systems, который специализируется на разработке ИИ-решений. Финансовые условия договора не раскрываются, но ранее стартап уже поставлял LANL свои решения. В рамках партнёрства LANL расширит применение программно-аппаратных комплексов SambaNova DataScale. Речь идёт о системе DataScale SN30, содержащей восемь ускорителей собственной разработки Cardinal SN30, суммарно имеющих 5 Гбайт SRAM и 8 Тбайт DRAM. Конфигурация комплекса может включать от одного до трёх узлов SN30. Кроме того, LANL внедрит решение SambaNova Suite для генеративного ИИ. Эта платформа предоставляет различные ИИ-модели, оптимизированные для корпоративных и государственных организаций. Они могут быть развёрнуты локально или в облаке с возможностью адаптации к собственному набору данных заказчика. 
Источник изображения: SambaNova Новое многолетнее соглашение между LANL и SambaNova является расширением действующего партнёрства между сторонами. Лаборатория будет использовать технологии SambaNova для решения широкого спектра задач, связанных с ИИ и большими языковыми моделями (LLM), в том числе в интересах национальной безопасности. Отмечается, что платформа SambaNova Suite предлагает быстрый и эффективный способ развёртывания генеративного ИИ для реализации самых сложных проектов.
23.11.2023 [01:01], Владимир Мироненко
Nokia поможет консорциуму Ultra Ethernet в разработке новых спецификаций Ethernet для систем ИИNokia объявила о поддержке консорциума Ultra Ethernet Consortium (UEC), созданного с целью объединения усилий компаний для обновления спецификаций Ethernet и разработки API, позволяющих удовлетворить растущие сетевые требований систем ИИ и HPC. Компания отметила, что почти универсальный протокол для сетей передачи данных Ethernet способен удовлетворить широкие потребности систем ИИ в производительности, а благодаря поддержке Nokia консорциум сможет разрабатывать новые стандарты, лучшие практики и архитектуры для специализированных сетей ЦОД с ИИ. Nokia добилась больших успехов в разработке сверхмасштабируемых сетевых решений с низкой задержкой для ЦОД и интерконнекта. Компания планирует использовать накопленный опыт при участии в нескольких рабочих группах UEC, помогая обеспечить соответствие продуктов консорциума критическим потребностям всех своих клиентов. 
Источник изображения: Nokia «Используя наше широкое присутствие в сфере коммуникаций, корпоративных и веб-сетей, мы стремимся сделать Ultra Ethernet высоко совместимой, недорогой и функционально интероперабельной частью будущих стеков приложений искусственного интеллекта и высокопроизводительных вычислений», — заявил глава IP-подразделения Nokia.
22.11.2023 [01:23], Владимир Мироненко
NVIDIA в рекордные сроки завершила строительство первой фазы израильского ИИ-суперкомпьютера Israel-1Компания NVIDIA объявила во вторник о досрочном завершении сборки первой фазы ИИ-суперкомпьютера Israel-1, анонсированного летом этого года. Сообщается, что суперкомпьютер уже доступен для использования исследовательскими и опытно-конструкторскими группами компании, а также её отдельными партнёрами. После завершения строительства Israel-1 станет самым мощным ИИ-суперкомпьютером в Израиле. По данным NVIDIA, первая фаза компьютерной системы была построена менее чем за 20 недель или почти на два месяца раньше намеченных сроков — это намного быстрее, чем требуется для создания традиционных суперкомпьютеров, которые могут создаваться и несколько лет. Первая фаза Israel-1, обеспечивающая производительность при обработке ИИ-нагрузок в 4 Эфлопс (FP8) и при научных вычислениях в 65 Пфлопс (FP64), послужит испытательным стендом для разработанной в Израиле сетевой Ethernet-платформы NVIDIA/Mellanox Spectrum-X, предназначенной для повышения производительности и эффективности облачных ИИ-сервисов. 
Изображение: NVIDIA В конечном итоге Israel-1 будет содержать 256 систем NVIDIA HGX H100, включающих в общей сложности 2048 ускорителей NVIDIA H100 с более чем 34 млн ядер CUDA и 1 млн тензорных ядер четвёртого поколения, 2560 единиц DPU BlueField-3 и 80 коммутаторов Spectrum-4. Первая фаза суперкомпьютера включает 128 серверов Dell PowerEdge XE9680 на базе платформы NVIDIA HGX H100, 1280 единиц DPU BlueField-3 и более 40 коммутаторов Spectrum-4.
21.11.2023 [09:51], Сергей Карасёв
Европейский экзафлопсный суперкомпьютер Jupiter получит универсальный блок cCuster на европейских Arm-процессорах SiPearl RheaВ 2024 году в Юлихском исследовательском центре (FZJ) в Германии заработает вычислительный комплекс Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Профессор Томас Липперт (Thomas Lippert; на фото ниже) из FZJ рассказал об особенностях конфигурации этой системы. Ранее сообщалось, что в состав Jupiter будет включён высокомасштабируемый блок ускорителей (Booster). Речь идёт об использовании платформы Eviden BullSequana XH3000 с прямым жидкостным охлаждением, а в состав каждого узла войдут модули NVIDIA Quad GH200. Общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Блок Booster предназначен для решения особо ресурсоёмких задач. Как сообщил господин Липперт, второй составляющей НРС-комплекса станет универсальный блок cCuster, который сможет поддерживать приложения всех типов: это, в частности, операции с высокой интенсивностью использования данных. Оба блока можно будет использовать по отдельности или вместе, что позволит добиться максимальной эффективности при реализации различных проектов. В основе cCuster — энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea. Эти изделия обеспечивают высокое соотношение производительности к пропускной способности — 0,5 байт/флоп. Поэтому процессоры хорошо подходят для сложных приложений с интенсивным использованием данных. 
Источник изображения: FZJ Все вычислительные узлы Jupiter подключены к высокопроизводительной сети NVIDIA Mellanox InfiniBand. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность «незначительно превысит 1 Эфлопс». Общая стоимость проекта составит €273 млн, включая доставку, установку и обслуживание Jupiter.
19.11.2023 [23:59], Владимир Мироненко
Fujitsu Adaptive GPU Allocator позволит эффективнее использовать дефицитные ИИ-ускорителиКомпания Fujitsu представила технологии Adaptive GPU Allocator и Interactive HPC, позволяющие оптимизировать использования ускорителей и HPC-кластеров. Эти технологии будут использоваться в некоторых из её собственных облачных HPC-продуктов. Компания утверждает, что новые решения призваны помочь решить проблему глобальной нехватки ускорителей в связи с большим спросом на генеративный ИИ, позволяя клиентам оптимизировать использование своих вычислительных ресурсов. По словам Fujitsu, Adaptive GPU Allocator способна динамически определять программы, для работы которых действительно требуется ускоритель, и программы, которым фактически достаточно CPU, и соответствующим образом распределять ресурсы. Технология основана на оценке уровня возможного ускорения при использовании GPU для каждой конкретной программы и выделении ресурсов ускорителей так, чтобы минимизировать общее время обработки всеми программами. 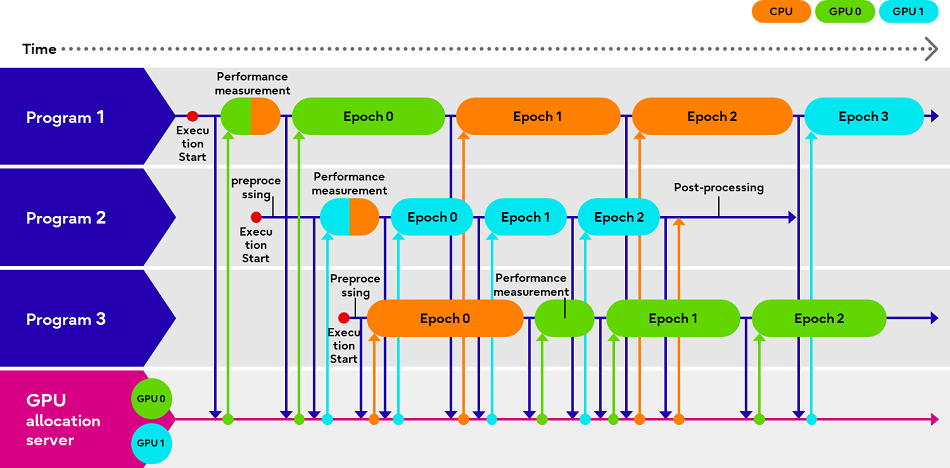
Изображения: Fujitsu Технических деталей о работе этой системы компания не предоставила. Сообщается лишь то, что при запросе программой доступа к ускорителю проводится замер скорости обработки одного и того же кусочка данных на CPU и GPU, на основании чего и принимается решение о дальнейшей обработке на CPU или GPU. Система может измерять производительность кода по мере его выполнения. Как уточняет The Register, что для работы Adaptive GPU Allocator программы должны задействовать фреймворк Fujitsu, который использует TensorFlow и PyTorch. 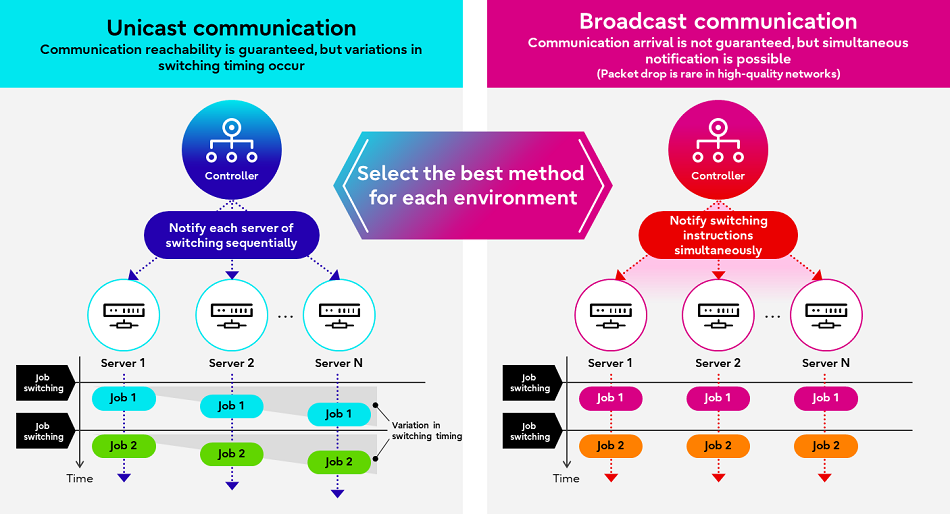 Adaptive GPU Allocator станет частью ИИ-платформы Fujitsu Kozuchi, выход которой ожидается после II половины 2024 финансового года, заканчивающегося 31 марта 2025 года. Чуть раньше появится технология Interactive HPC, которая позволит переключаться между несколькими задачами в HPC-кластерах в режиме реального времени, тогда как, по словам Fujitsu, традиционный подход предполагает отправку узлам команд на переключение по очереди. Деталей компания снова не сообщила, отметив лишь то, что в кластере из 256 узлов Interactive HPC позволила сократить время переключения с одной задачи на другую с нескольких секунд до 100 мс. |
|

