Материалы по тегу: c
|
20.12.2023 [16:22], Сергей Карасёв
ASRock Industrial выпустила индустриальные NUC на базе Intel Core Ultra Meteor LakeASRock Industrial представила компьютеры небольшого форм-фактора NUC Ultra 100 Box и NUCS Ultra 100 Box, предназначенные для edge-приложений, индустриальных задач и пр. В основу устройств легла аппаратная платформа Intel Core Ultra Meteor Lake, дебютировавшая в декабре 2023 года. Представлены четыре мини-ПК: NUCS Box-155H, NUCS Box-125H, NUC Box-155H и NUC Box-125H. Версии с индексом 155H несут на борту процессор Core Ultra 7 155H с 16 ядрами (6P+8E+2LPE; 22 потока; до 4,8 ГГц), а модели с обозначением 125H получили чип Core Ultra 5 125H с 14 ядрами (4P+8E+2LPE; 18 потоков; до 4,5 ГГц). Все новинки поддерживают до 96 Гбайт оперативной памяти DDR5-5600 в виде двух модулей SO-DIMM. Есть адаптеры Wi-Fi 6E и Bluetooth 5.3, а также по одному слоту M.2 2280 PCIe 4.0 x4 и M.2 2242 PCIe 4.0 x1. 
Источник изображений: ASRock Размеры компьютеров NUC Ultra 100 Box составляют 117,5 × 110 × 49 мм. Внутри предусмотрено место для SFF-накопителя с интерфейсом SATA-3. В оснащение входят сетевые контроллеры Intel I226LM и Intel I226V стандарта 2.5GbE, по одному порту Thunderbolt 4 и USB 3.2 Gen2 Type-C (DisplayPort Alt Mode), три порта USB 3.2 Gen2 Type-A, два разъёма HDMI 2.1 и аудиогнездо на 3,5 мм.  Версии NUCS Ultra 100 Box имеют габариты 117,5 × 110 × 38 мм и при этом не располагают отсеком для SFF-накопителя. Оснащение включает контроллер Intel I226LM стандарта 2.5GbE, по одному порту Thunderbolt 4 и USB 3.2 Gen2 Type-C (DisplayPort Alt Mode), четыре порта USB 3.2 Gen2 Type-A, два интерфейса HDMI 2.1 и 3,5-мм аудиогнездо. Все устройства весят около 1 кг.
19.12.2023 [14:40], Руслан Авдеев
Пентагон получил 9-Пфлопс суперкомпьютер Carpenter: 280 тыс. ядер AMD и 563 Тбайт RAMАмериканское военное ведомство ввело в эксплуатацию новый суперкомпьютер. По данным Datacenter Dynamics, Центр исследований и разработок армии США (ERDC) представил систему Carpenter производительностью 9 Пфлопс, названную в честь капрала Уильяма Кайла Карпентера (William Cyle Carpenter). Впервые ERDC поделился планами строительства нового суперкомпьютера в августе прошлого года, изначально ожидалось, что машина получит по два чипа на узел, каждый со 192 ядрами и 384 Гбайт памяти, и 200G-интерконнект. Суперкомпьютер построен в лаборатории Army Computing Lab в Виксбурге (Миссисипи). Система, базирующаяся на платформе HPE Cray EX4000, оснащена 277 248 вычислительными ядрами AMD EPYC и 563 Тбайт памяти. О наличии каких-либо ускорителей не сообщается. 
Источник изображения: ERDC Первый суперкомпьютер ERDC получил в 1990 году, а в 1992 году центр начал реализацию проекта High Performance Computing Modernization Program (HPCMP). В частности, она позволяет учёным Пентагона получать доступ к мощностям для разработки, тестирования и оценки оборонных систем. В ведении ERDC также находятся суперкомпьютеры Freeman и Onyx. Последний должны были «отправить на покой» ещё в августе этого года, но он всё ещё числится в ноябрьском списке TOP500, равно как и система Topaz 2015 года.
19.12.2023 [14:19], Сергей Карасёв
Congatec представила модули COM Express Type 6 с чипами Intel Raptor Lake для экстремальных условийКомпания Congatec анонсировала модули семейства conga-TC675r в формате COM Express Type 6, рассчитанные на индустриальную сферу. Изделия могут эксплуатироваться в экстремальных условиях — например, на промышленных объектах, горнодобывающих площадках, предприятиях лесной промышленности и пр. В основу устройств положена платформа Intel Raptor Lake. Предусмотрены конфигурации с различными процессорами Core 13-го поколения, а максимальная комплектация включает чип Core i7-13800HRE (6P+8E; 20 потоков; 1,8–5,0 ГГц; 45 Вт). Объём набортной оперативной памяти LPDDR5x-6400 может достигать 64 Гбайт. 
Источник изображения: Congatec Предусмотрена возможность подключения SSD (NVMe; PCIe x4). Доступны до восьми линий PCIe 4.0 (PEG) и до восьми линий PCIe 3.0, два порта USB4, по четыре порта USB 3.2 Gen2 и USB 2.0, по два интерфейса SATA и UART, интерфейсы CAN, 8 × GPIO, SPI, I2C и пр. В оснащение входит сетевой контроллер 2.5GbE с поддержкой TSN (Intel i226). За безопасность отвечает чип TPM 2.0. Для вывода изображения могут быть задействованы интерфейсы DDI (×3; два на основе USB4), LVDS/eDP и D-Sub (опционально). Модуль имеет размеры 95 × 95 мм. Отмечается, что чипы ОЗУ впаяны на плату, что повышает надёжность. Диапазон рабочих температур простирается от -40 до +85 °C. Говорится о совместимости с ОС Windows 11 IoT Enterprise, Windows 10, Windows 10 IoT Enterprise, Linux, Yocto. Компания Congatec предлагает варианты conga-TC675r, кастомизированные в соответствии с требованиями OEM-заказчиков.
18.12.2023 [16:05], Сергей Карасёв
IDC: объём мирового рынка суверенных облаков превысит $250 млрд в 2027 годуКомпания International Data Corporation (IDC) опубликовала первый прогноз по глобальному рынку суверенных облаков. Аналитики полагают, что отрасль в ближайшие годы будет устойчиво расти, что объясняется необходимостью защиты данных, обеспечения национальной безопасности и пр. Концепция суверенного облака предполагает ряд дополнительных требований к размещению, хранению и обработке информации. В зависимости от вариантов развёртывания области аренды в суверенном облаке могут быть ограничены конкретной компанией, географическим регионом и пр. Заказчик может выбрать для хранения данных собственный ЦОД. Для суверенных облаков может потребоваться соблюдение устанавливаемых конкретным клиентом нормативных ограничений, а также дополнительных стандартов безопасности. 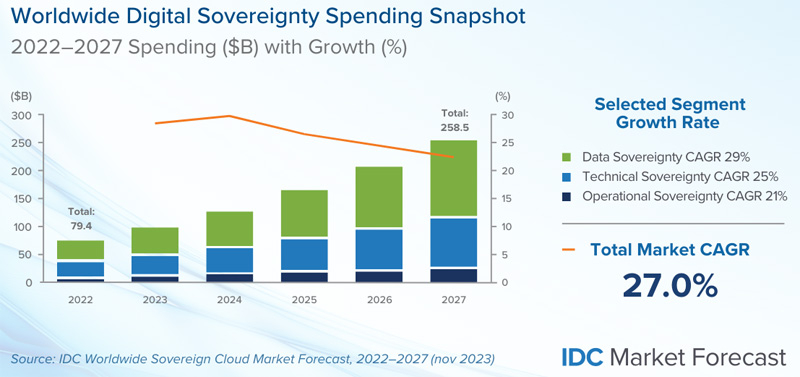
Источник изображения: IDC IDC в своём отчёте оценивает расходы по трём основным направлениям. Это суверенитет данных (учитывает, как информация собирается, классифицируется, обрабатывается, хранится и защищается), технический суверенитет (цифровая инфраструктура, расположенная в суверенной среде) и операционный суверенитет (решения, обеспечивающие прозрачность контроля над облачными операциями). По оценкам, в 2022 году объём глобального рынка суверенных облаков составил приблизительно $79,4 млрд. В 2023-м этот показатель превысит $103 млрд. В дальнейшем ожидается величина CAGR (среднегодовой темп роста в сложных процентах) на уровне 26,6 %. Если этот прогноз оправдается, в 2027 году затраты в рассматриваемом сегменте достигнут $258,5 млрд.
18.12.2023 [13:18], Сергей Карасёв
Процессор AMD EPYC Turin показался на «живых» фото: до 192 ядер Zen5cСетевые источники, по сообщению ресурса VideoCardz, обнародовали «живые» фотографии и новые данные о процессорах AMD EPYC пятого поколения с кодовым именем Turin (EPYC 7005). Эти чипы ориентированы на серверы для дата-центров и облачных платформ. О разработке процессоров EPYC Turin компания AMD говорила ещё в начале лета 2022 года. Тогда отмечалось, что будут доступны три разновидности кристаллов: обычные (Zen 5), с 3D V-Cache и «облачные» (Zen 5c) с высокой плотностью. Ожидается, что на коммерческом рынке изделия появятся до конца 2024 года. 
Источник изображений: YuuKi_AnS Теперь сообщается, что процессоры EPYC Turin будут использовать существующий сокет SP5 (LGA 6096). Они получат поддержку 12 каналов памяти DDR5-6000, а также стандартов CXL 2.0 и PCIe 5.0.  Конструкция стандартных изделий EPYC Turin предусматривает использование 16 вычислительных чиплетов CCD (до восьми ядер в каждом) и унифицированного чиплета IOD, выполняющего роль хаба ввода-вывода. Количество ядер Zen 5 может достигать 128 (256 потоков инструкций). В изделиях с высокой плотностью задействованы 12 чиплетов CCD (до 16 ядер в каждом), а суммарное число ядер Zen 5с составляет до 192 (384 потока). 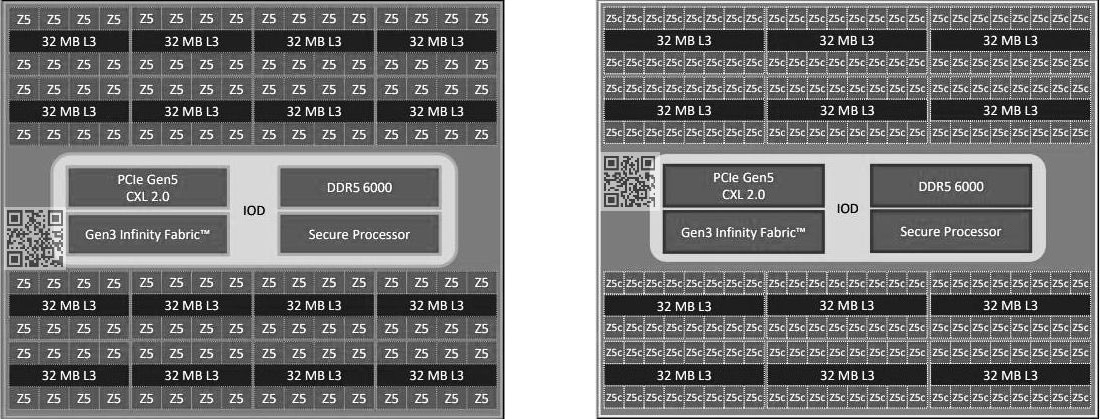 Для каждого из вычислительных чиплетов предусмотрено наличие 32 Мбайт кеша L3, что в сумме даёт до 512/384 Мбайт. Показатель TDP достигает 550 Вт. На фотографиях якобы запечатлён инженерный образец чипа EPYC Turin с шифром 100-00001245-07. Процессор произведён в Малайзии в 2023 году.
14.12.2023 [12:52], Сергей Карасёв
ASRock представила первый в мире мини-ПК на Ryzen 8040 с улучшенным ИИ-движкомКомпания ASRock Industrial анонсировала компьютеры небольшого форм-фактора 4X4 BOX 8040, ориентированные на корпоративный рынок. Устройства подходят для решения различных ИИ-задач в бизнес-сфере, построения интеллектуальных платформ Интернета вещей (AIoT) и пр. Новинки заключены в корпус с габаритами 117,5 × 110,0 × 49,0 мм. Применена аппаратная платформа AMD Ryzen 8040. Доступны модели 4X4 BOX-8640U и 4X4 BOX-8840U, оснащённые соответственно процессором Ryzen 5 8640U (6 ядер; 12 потоков; до 4,9 ГГц) и Ryzen 7 8840U (8 ядер; 16 потоков; до 5,1 ГГц). В обоих случаях имеется встроенный контроллер AMD Radeon Graphics. Используется активное охлаждение. 
Источник изображения: ASRock Доступны два слота SO-DIMM для модулей DDR5-5600 суммарным объёмом до 96 Гбайт. Можно установить два SSD — в форматах M.2 2242/2280 и M.2 2242 с интерфейсом PCIe 4.0 x4. В оснащение входят сетевые адаптеры 2.5GbE (Realtek RTL8125BG) и 1GbE (Realtek RTL8111H), звуковой кодек Realtek ALC256, контроллеры Wi-Fi 6E 802.11ax и Bluetooth 5.2. На фронтальную панель выведены два пора USB 4 Type-C (DP 1.4a), разъём USB 3.2 Gen2 Type-A и аудиогнездо на 3,5 мм. Сзади находятся два интерфейса HDMI 1.4b, два гнезда RJ-45 для сетевых кабелей, два порта USB 2.0 и разъём DC для блока питания. Допускается вывод изображения одновременно на четыре дисплея. Возможен монтаж при помощи крепления VESA. Диапазон рабочих температур простирается от 0 до +40 °C. Вес составляет около 1 кг.
12.12.2023 [13:13], Сергей Карасёв
Мировой рынок публичных облаков в 2023 году вырастет примерно на 20 %Компания International Data Corporation (IDC) подсчитала, что в I половине 2023 года затраты на мировом рынке публичных облаков достигли приблизительно $315,5 млрд. Это на 19,1 % больше по сравнению с аналогичным периодом 2022-го, когда расходы оценивались в $264,8 млрд. Сегмент SaaS (приложения) остаётся самым крупным источником выручки на рынке публичных облаков: в январе–июне 2023-го на него пришлось 44,7 % от общего объёма отрасли — около $141,2 млрд. Рост в годовом исчислении зафиксирован на отметке 15,8 %. 
Источник изображения: IDC Сервисы IaaS обеспечили $64,4 млрд, что соответствует доли в 20,4 %. Ещё $56,8 млрд, или приблизительно 18,0 %, принесли решения PaaS. По направлению SaaS — SIS (ПО для системной инфраструктуры) выручка составила $53,2 млрд, или 16,9 % всех расходов. Рост в годовом исчислении в сегментах IaaS, PaaS и SaaS — SIS зарегистрирован на уровне 16,9 %, 27,7 % и 22,7 % соответственно. Ведущие поставщики публичных облачных услуг сохранили свои позиции в I полугодии 2023 года. Совокупная выручка пяти крупнейших игроков, в число которых входят Microsoft, Amazon Web Services (AWS), Salesforce, Google и Oracle, составила 41 % в общем объёме рынка и практически не изменилась в годовом исчислении. IDC прогнозирует, что в 2023 году в целом мировой рынок публичных облачных услуг достигнет $663 млрд, показав рост на 20,0 % по сравнению с предыдущим годом. В дальнейшем значение CAGR (среднегодовой темп роста в сложных процентах) составит 19,4 %, а затраты достигнут $1,34 трлн в 2027 году.
09.12.2023 [23:32], Сергей Карасёв
Продажи Ethernet-коммутаторов корпоративного класса растут, а маршрутизаторов — падаютКомпания International Data Corporation (IDC) подвела квартальные итоги исследования мирового рынка сетевого оборудования корпоративного класса — коммутаторов Ethernet и маршрутизаторов. Отрасль показала смешанные результаты, несмотря на смягчение проблем с цепочками поставок, которые начались во время пандемии COVID-19. Продажи Ethernet-коммутаторов в III четверти 2023 года составили $11,7 млрд, что на 15,8 % больше год к году. В сегменте устройств для дата-центров выручка поднялась на 7,2 %, в сегменте решений для прочих корпоративных заказчиков — на 22,2 %. В рейтинг ведущих поставщиков коммутаторов Ethernet входят Cisco, Arista Networks, Huawei, HPE и H3C с долями соответственно 45,1 %, 10,6 %, 9,6 %, 7,7 % и 4,1 %. 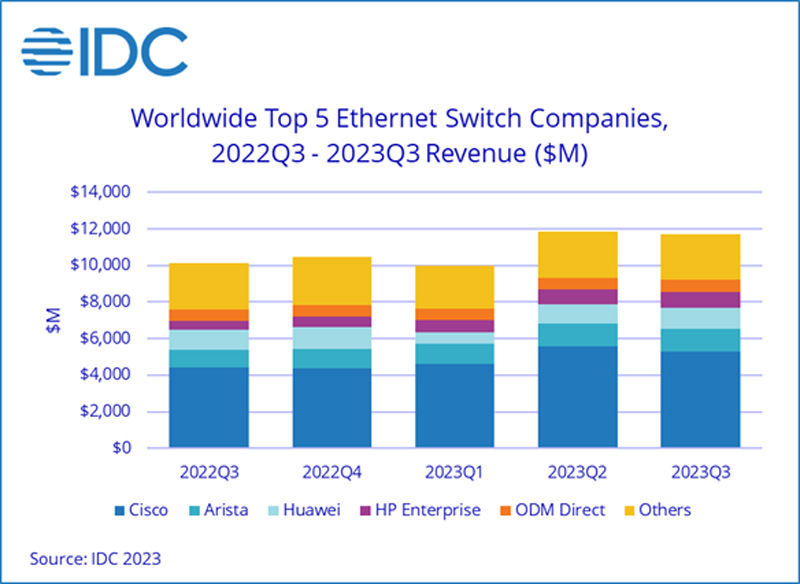
Источник изображения: IDC Поставки коммутаторов стандартов 200/400GbE для ЦОД выросли на 44,0 % по сравнению с прошлым годом, а количество реализованных портов поднялось на 63,9 %. Спрос на решения 100GbE увеличился на 6,0 % год к году, на модели 25/50GbE — на 26,3 %. По направлению коммутаторов для сегментов, не связанных с ЦОД, поставки устройств 1GbE прибавили 18,3 %, моделей 10GbE — 5,8 %. Выручка от оборудования 2,5/5GbE показала рост на 92,0 %. С географической точки зрения спрос на коммутаторы Ethernet увеличился в большинстве регионов мира. В США продажи в годовом исчислении поднялись на 26,7 %, в Канаде — на 28,6 %. В Латинской Америке зафиксирована прибавка на уровне 25,9 %, в Западной Европе — на 12,0 %, в Центральной и Восточной Европе — на 17,8%. В Азиатско-Тихоокеанском регионе (за исключением Японии и Китая) показан рост на 14,1 %. При этом в КНР продажи упали на 12,4 %, а в Японии — поднялись на 2,9 %. Что касается маршрутизаторов, то их отгрузки в III квартале 2023 года уменьшились на 9,4 %, составив $3,7 млрд. С региональной точки зрения продажи в Америке сократились на 7,3 %, в Азиатско-Тихоокеанском регионе — на 11,1 %, в Европе, на Ближнем Востоке и в Африке — на 10,4 %.
09.12.2023 [23:16], Сергей Карасёв
Supermicro представила ИИ-серверы с ускорителями AMD Instinct MI300 и СЖОКомпания Supermicro анонсировала серверы AS-8125GS-TNMR2, AS-4145GH-TNMR и AS-2145GH-TNMR, предназначенные для задач НРС и ИИ, в том числе для обучения больших языковых моделей (LLM). Новинки выполнены на аппаратной платформе AMD и оборудованы ускорителями серии Instinct MI300. Модель AS-8125GS-TNMR2 соответствует типоразмеру 8U. Она оснащена двумя процессорами AMD EPYC Genoa с показателем TDP до 400 Вт и восемью ускорителями Instinct MI300X со 192 Гбайт памяти HBM3. Объём оперативной памяти DDR5-4800 RDIMM/LRDIMM может достигать 6 Тбайт (24 слота). Доступны 18 отсеков для SFF-накопителей NVMe/SATA и коннектор M.2 NVMe. Предусмотрены восемь слотов для карт PCIe 5.0 x16 LP и два слота для карт PCIe 5.0 x16 FHFL. Задействована система воздушного охлаждения. Питание обеспечивают шесть или восемь блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. 
Источник изображений: Supermicro Серверы AS-4145GH-TNMR и AS-2145GH-TNMR выполнены в форм-факторе 4U и 2U соответственно. Первый наделён системой воздушного охлаждения, второй — жидкостного. При этом оба получили четыре чипа Instinct MI300A (24 ядра EPYC Genoa, ускоритель CDNA 3 и 128 Гбайт памяти HBM3). Устройство AS-4145GH-TNMR располагает 24 отсеками для накопителей SFF NVMe/SAS/SATA с возможностью горячей замены и двумя разъёмами для модулей M.2 NVMe или SATA. Есть шесть слотов PCIe 5.0 x16 FHHL и два разъёма PCIe 5.0 x16 AIOM. Задействованы четыре блока питания на 1600 Вт с сертификатом 80 Plus Titanium.  Сервер AS-2145GH-TNMR получил восемь посадочных мест для накопителей SFF NVMe/SAS/SATA и два разъёма для SSD M.2 NVMe или SATA. Доступны четыре слота PCIe 5.0 x16 FHHL и два слота PCIe 5.0 x16 AIOM. За питание отвечают четыре блока на 1600 Вт с сертификатом 80 Plus Titanium.
09.12.2023 [23:09], Сергей Карасёв
На мировом рынке корпоративного WLAN-оборудования наблюдается спадКомпания International Data Corporation (IDC) представила свежие результаты исследования мирового рынка оборудования корпоративного класса для беспроводных локальных сетей (WLAN). В III квартале 2023 года продажи составили приблизительно $2,5 млрд, что на 5,2 % меньше по сравнению с результатом за тот же период предыдущего года. На точки доступа Dependent Access Point стандарта Wi-Fi 6E пришлось 20,4 % в общем объёме выручки и 9,6 % в штуках. Доля решений Wi-Fi 6 составила соответственно 74,8 % и 76,6 %. 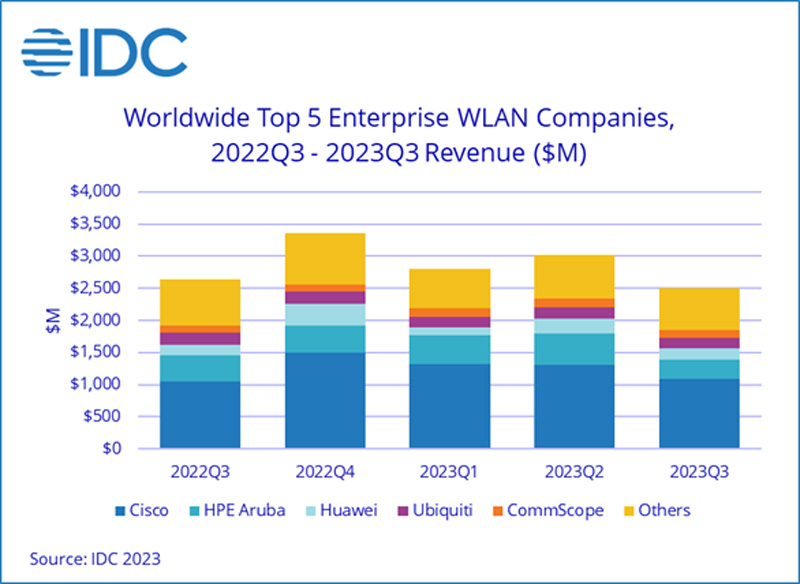
Источник изображения: IDC С географической точки зрения корпоративный сегмент WLAN показал неоднозначные результаты. Так, в США поставки в денежном выражении поднялись на 1,2 % в годовом исчислении, а в Канаде — напротив, сократились на 3,9 %. В Латинской Америке зафиксирована прибавка на 23,5 %, на Ближнем Востоке и в Африке — на 7,5 %. В Западной Европе расходы сократились на 11,2 %, в Центральной и Восточной Европе — на 6,7 %. В Азиатско-Тихоокеанском регионе, за исключением Японии и Китая, отмечено снижение на 0,6 %. В Китае продажи рухнули на 24,1 %, в Японии — на 12,8 %. Крупнейшими поставщиками WLAN-систем на корпоративном рынке по итогам III четверти 2023 года стали Cisco (43,4 % в денежном выражении), HPE Aruba Networking (12,0 %), Huawei (7,2 %), Ubiquiti (6,4 %), CommScope (5,1 %) и Juniper Networks (4,5 %). Потребительский сегмент рынка WLAN в III квартале 2023 года сократился на 13,7 % в годовом исчислении. На решения стандарта Wi-Fi 6 пришлось 57,9 % выручки, на продукты Wi-Fi 5 — 32,4 %. Внедрение Wi-Fi 6E находится на ранней стадии: такие устройства принесли только 6,2 % выручки. |
|

