Материалы по тегу: c
|
29.12.2023 [16:04], Сергей Карасёв
Из ядра Linux удалена поддержка так и не вышедших решений Intel Carillo Ranch, а заодно и устаревших SPARC-процессоровИз ядра Linux, по сообщению ресурса Phoronix, исключена поддержка продуктов Intel семейства Carillo Ranch, добавленная более 15 лет назад. Любопытно, что эти изделия никогда не были доступны на коммерческом рынке, а информацию о них практически невозможно найти в интернете. Судя по имеющимся данным, серия Carillo Ranch задумывалась как платформа для встраиваемых процессоров EP80579 на ядре Pentium M с кодовым именем Tolapai. Кроме того, упоминаются набор логики Vermillion Range и сопутствующий контроллер памяти. Внедрение поддержки Carillo Ranch в Linux уходит корнями в 2006 год. 
Источник изображения: Intel На сайте Intel присутствует информация об изделии EP80579 с частотой 1,2 ГГц. Однако в драйверах Linux платформа Carillo Ranch фигурирует как LE80578, а поиск по запросу «LE80578» в Google выдаёт информацию о принтерах HP Laserjet с процессором, работающим на частоте 800 МГц. Если же попытаться найти в Google собственно решения «Intel Carillo Ranch», то поисковик предложит исправить запрос на «Carrillo Ranch», добавив дополнительную букву «r». В этом случае выдаётся информация об одноимённом ранчо в Калифорнии. Так или иначе, для Linux выпущены два патча, которые очищают немногим более 2 тыс. строк кода, связанных с поддержкой Carillo Ranch. Удаление соответствующих драйверов, скорее всего, останется незамеченным для сообщества. Кроме того, как стало известно, из ядра Linux может быть убрана основная часть кода, связанного с поддержкой 32-битных процессоров SPARC для старых рабочих станций Sun. В процессорах Frontgrade Gaisler LEON3 по-прежнему используется 32-битная архитектура SPARC, поэтому основное ядро Linux не может полностью исключить соответствующую поддержку. Тем не менее, будут удалены примерно 10,5 тыс. строк старого кода SPARC32. В корпоративных же решениях данная архитектура фактическа мертва.
28.12.2023 [16:33], Сергей Карасёв
Стоимость активов российского производителя суперкомпьютеров «Т-платформы» рухнула в 16 разАрбитражный суд Москвы, как сообщает «Интерфакс», определил действительную стоимость активов российского разработчика суперкомпьютеров АО «Т-платформы». Она установлена в размере 343 млн руб., тогда как в конце 2016 года компания оценивалась в 5,6 млрд руб. Таким образом, показатель рухнул более чем в 16 раз. Проблемы у «Т-платформ» начались ориентировочно в 2019 году, когда по делу о поставке компьютеров в российское МВД на сумму 357,1 млн руб. был арестован основатель компании Всеволод Опанасенко. После этого «Т-платформы» фактически прекратили реальную деятельность, что, в конечном итоге, привело к банкротству предприятия. Согласно данным бухгалтерского баланса АО «Т-Платформы» за 2022 год, стоимость активов компании составляла 342,95 млн руб. Именно такую сумму конкурсный управляющий компании указал в заявлении, направленном в столичный арбитраж. Установление действительной стоимости активов предприятия необходимо для «целей дополнительного страхования ответственности арбитражного управляющего». 
Источник изображения: pixabay.com Господин Опанасенко, который по версии следствия хотел незаконным путём получить преимущественные условия при заключении госконтракта на поставку компьютерного оборудования МВД, в мае 2023 года был приговорён к двум годам и четырём месяцам колонии общего режима. При этом основатель «Т-платформ» был освобождён от отбытия наказания с учётом сроков его ареста и заочного ареста до суда. Для Опанасенко также назначен штраф в размере 300 тыс. руб. Отмечается, что в мошенническую схему был вовлечён бывший начальник управления связи департамента информационных технологий, связи и защиты информации МВД России Александр Александров. Согласно материалам дела, ему было известно, что поставляемое «Т-Платформами» оборудование с процессорами «Байкал-Т1» не соответствует техническим характеристикам, необходимым для нужд МВД. Ущерб, нанесённый государству, оценён более чем в 350 млн руб. Суд взыскал с Опанасенко и Александрова 357 тыс. руб. по иску МВД России и с Александрова — 122 тыс. руб. по гражданскому иску Воронежского института МВД.
27.12.2023 [16:40], Руслан Авдеев
Fujitsu и NEC занялись разработкой чипов для базовых станций 6GПока технология 5G активно масштабируется по всему миру, ведущие игроки на рынке телекоммуникационного оборудования уже полным ходом готовятся к созданию решений на базе 6G. Как сообщает CompsMag, поскольку стандарты для связи новейшего поколения смогут принять уже в 2024 году, японские гиганты Fujitsu и NEC готовят собственные 6G-чипы для базовых станций. Например, по данным DigiTimes, обе компании спешат разработать собственные микросхемы для такого оборудования — это важный шаг на пути обеспечения самодостаточности и инновационного развития в Восточной Азии. Япония намерена стать одним из ведущих игроков в развитии и распространении технологий 6G. Переход с 5G на 6G знаменует принципиально важный качественный скачок технологий беспроводных коммуникаций. Хотя технология 5G уже произвела революцию на этом рынке, 6G обещает новые преимущества, от использования частот терагерцового диапазона до чрезвычайно высокой скорости передачи данных, обещающих появление прорывных решений, например, в AR/VR и других сферах. Спрос на такую связь может быть очень высоким уже в ближайшие годы. 
Источник изображения: Jackson David/unsplash.com Решение Fujitsu и NEC инвестировать в собственные чипы отражает их стратегическую позицию относительно эволюции телекоммуникационного рынка. Разрабатывая собственные 6G-микросхемы, компании намерены получить преимущества в области производительности, надёжности и себестоимости предлагаемых систем. Кроме того, технологическая автономность играет чрезвычайно важную роль для любых стран. При этом Япония готова развивать не только рынок собственных телекоммуникаций, но и внести вклад в мировой технологический прогресс. Впрочем, впереди компании ожидают и определённые трудности. Создание передовых чипов требует больших финансовых вливаний в исследования, разработку и тестирование. Более того, чтобы успешно конкурировать на рынке, следует обеспечить соответствие продукции международным стандартам, которые пока даже не приняты. Разумеется, соответствующие разработки ведутся не только в Японии. Например, в октябре появилась информация об открытии 6G-лаборатори Nokia в Индии, Россия намерена увеличить инвестиции в создание оборудования 5G и 6G. Подобные сети будут весьма кстати. Ещё в начале прошлого года в Credit Suisse прогнозировали, что в ближайшие 10 лет трафик вырастет минимум в 20 раз.
27.12.2023 [15:19], Сергей Карасёв
Спрос на модульные ЦОД в России в 2023 году взлетел на 40 %Исследование, проведённое компанией GreenMDC, говорит о том, что в России быстро растёт спрос на модульные дата-центры. В 2023 году продажи таких комплексов подскочили приблизительно на 40 % по сравнению с предыдущим годом (абсолютные цифры не раскрываются). GreenMDC выделяет несколько факторов, способствующих увеличению продаж модульных ЦОД. На фоне сложившейся геополитической обстановки из России ушли многие зарубежные компании, а поставки импортного оборудования сократились. Это способствует развитию российских предприятий: появляются новые и расширяются существующие производства, для поддержания работы которых требуются дополнительные вычислительные ресурсы. 
Источник изображения: GreenMDC Кроме того, продолжается активное развитие государственных сервисов для граждан, в том числе в регионах. Для этого необходимы новые IT-мощности. Наконец, в условиях импортозамещения ПО поставщикам софта, которые ранее использовали иностранные серверы, нужны альтернативные российские площадки. Для ускорения развёртывания новых мощностей заказчики всё чаще выбирают именно модульные дата-центры. Если на создание обычного ЦОД необходимо 1,5–2 года, то модульный можно развернуть за 6–9 месяцев. Это позволяет быстрее ввести мощности в эксплуатацию, а также сократить возможные издержки — за время строительства капитального дата-центра удорожание проекта с учётом инфляции, валютных колебаний и непредвиденных расходов составляет в среднем 20 %. В исследовании GreenMDC также говорится, что в сегменте модульных ЦОД в России наблюдается смещение интереса заказчиков в сторону крупных масштабируемых площадок (на 50 и более стоек). Если несколько лет назад их доля составляла только около 10 %, то в 2023 году показатель достиг 40–50 %. Небольшие модульные ЦОД на 5–15 шкафов, которые раньше пользовались наибольшей популярностью, теперь занимают 20–30 % сегмента. Ещё около 30 % — это решения на 20–30 шкафов.
24.12.2023 [14:10], Сергей Карасёв
TYAN представила широкий ассортимент серверов на базе Intel Xeon Emerald RapidsКомпания TYAN, подразделение корпорации MiTAC Computing Technology Corporation, весной этого года выкупившей у Intel бизнес по производству серверов, анонсировала первые продукты на новейшей аппаратной платформе Intel Xeon Emerald Rapids. Дебютировали системы в разных форматах, в том числе башенного типа, а также материнские платы. Одна из новинок — модель Thunder HX FT65T-B5652. Это односокетный башенный сервер с возможностью применения четырёх двухслотовых ускорителей с интерфейсом PCIe 5.0 x16. Доступны восемь разъёмов для модулей оперативной памяти DDR5-5600. Возможна установка шести LFF-накопителей SATA-3, двух устройств NVMe U.2 с поддержкой горячей замены, а также одного SSD формата M.2 2280 (NVMe). 
Источник изображений: TYAN Ещё один башенный сервер — вариант Thunder HX FT65T-B7130 для двух чипов Xeon Emerald Rapids с показателем TDP до 250 Вт. Есть 16 слотов для модулей DDR5-5600, а также три посадочных места для полноразмерных ускорителей PCIe 5.0 x16 (два — двойной ширины и один — одинарной). Могут быть задействованы восемь LFF- и два SFF-накопителя SATA-3, а также SSD M.2 2280 (NVMe). Представлены стоечные серверы стандарта 2U для различных сценариев использования. Так, модель Thunder CX TD76-B5658 — это четырёхузловая система для облачных сервис-провайдеров. Каждый узел рассчитан на один процессор Xeon Emerald Rapids. Есть 16 разъёмов DDR5-4800, по одному слоту PCIe 5.0 x16 и OCP 3.0 LAN, а также два коннектора NVMe M.2.  В число новинок вошли двухсокетные серверы Thunder HX TS75-B7132 и Thunder HX TS75A-B7132 типоразмера 2U. Они получили 32 слота для модулей DDR5-4800, пять разъёмов PCIe 5.0, слот OCP 3.0 и два коннектора NVMe M.2. Доступны опции с двумя сетевыми портами 10GbE или 1GbE. Серверы рассчитаны соответственно на восемь LFF- и 26 SFF-накопителей (во фронтальной части). Кроме того, представлены двухсокетные 2U-серверы Thunder SX TS70-B7136 и Thunder SX TS70A-B7136. Они наделены 16 слотами DDR5-5600, двумя портами 10GbE, пятью разъёмами PCIe 5.0, слотом OCP 3.0 и двумя коннекторами NVMe M.2. Первая из этих моделей получила 12 фронтальных отсеков для LFF-накопителей, вторая — 18 отсеков для SFF-устройств. У обеих версий есть два тыльных посадочных места для SFF-накопителей.  В сегменте 1U-серверов дебютировали варианты Thunder CX GC79A-B7132 и Thunder CX GC68A-B7136 с поддержкой двух процессоров Xeon Emerald Rapids. Первый располагает 32 слотами DDR5-5600, 12 фронтальными отсеками для накопителей NVMe U.2, двумя слотами для карт PCIe 5.0 x16 FHHL, одним слотом PCIe 5.0 x16 OCP 3.0 и двумя коннекторами NVMe M.2 22110/2280. Второй из этих серверов оснащён 16 слотами DDR5-5600, 12 отсеками для SFF-накопителей (восемь NVMe U.2 и четыре SATA), двумя слотами PCIe 5.0 x16 FHHL, одним слотом PCIe 5.0 x16 OCP 3.0 и двумя разъёмами NVMe M.2 2280. В ассортимент материнских плат с поддержкой Xeon Emerald Rapids вошли такие модели, как Tempest HX S5652 для GPU-систем (четыре слота PCIe 5.0 x16 и слот PCIe 5.0 x4), а также Tempest CX S7136 Tempest HX S7130 для двухсокетных серверов.
23.12.2023 [02:11], Владимир Мироненко
В Испании официально запустили 314-Пфлопс суперкомпьютер MareNostrum 5, который вскоре объединится с двумя квантовыми компьютерами21 декабря в Суперкомпьютерном центре Барселоны — Centro Nacional de Supercomputación (BSC-CNS) — в торжественной обстановке официально запустили европейский суперкомпьютер MareNostrum 5 производительностью 314 Пфлопс. В церемонии, посвящённой машине, созданной в рамках проекта European High Performance Computing Joint Undertaking (EuroHPC JU), принял участие председатель правительства Испании. MareNostrum 5 представляет собой крупнейшую инвестицию, когда-либо сделанную Европой в научную инфраструктуру Испании — суммарно €202 млн, из которых €151,4 млн ушло на приобретение суперкомпьютера. Финансирование было проведено EuroHPC JU через Фонд ЕС «Соединение Европы» и программу исследований и инноваций «Горизонт 2020», а также государствами-участниками: Испанией (через Министерство науки, инноваций и университетов и правительство Каталонии), Турцией и Португалией. С запуском MareNostrum 5 заметно укрепились позиции BSC в качестве одного из ведущих суперкомпьютерных центров мира с более чем 900 сотрудниками, занимающимися исследования в области информатики, наук о жизни и о Земле, а также вычислительных систем для науки и техники. Обладая максимальной общей производительностью 314 Пфлопс, MareNostrum 5 присоединяется к двум другим системам EuroHPC: Lumi (Финляндия) и Leonardo (Италия), тоже являющихся суперкомпьютерами предэкзафлопсного класса, единственными системами такого уровня в Европе. 
Источник изображений: BSC Eviden (Atos) была выбрана в качестве основного поставщика, но в создании машины приняли участие Lenovo, IBM, Intel и NVIDIA, а также Partec. Как отмечено в пресс-релизе, уникальная архитектура MareNostrum 5 была создана для того, чтобы предоставить исследователям лучшие из доступных технологий. Это гетерогенная машина, сочетающая в себе две отдельные системы: раздел общего назначения (GPP), предназначенный для классических вычислений, и GPU-раздел (ACC), ориентированный на ИИ. Обе системы по отдельности входят в первую двадцатку TOP500, занимая 19-е и 8-е места соответственно. Раздел общего назначения (GPP) является крупнейшим в мире x86-кластером на базе Intel Xeon Sapphire Rapids. Эта часть суперкомпьютера имеет пиковую производительность 45,9 Пфлопс. Система, произведённая Lenovo, специально разработана для решения сложных научных задач с разделением ресурсов, что обеспечивает большую гибкость и повышает эффективность системы, поскольку разные пользователи или проекты могут использовать её одновременно. GPP имеет 6408 стандарных узлов следующей конфигурации:
Дополнительно система имеет 72 узла с двумя 56-ядерными Xeon Max (1,7 ГГц) и набортной памятью HBM2e объёмом 128 Гбайт.  GPU-раздел (ACC) производства Eviden является третьим по мощности в Европе и восьмым в мире по версии TOP500, с пиковой производительностью 260 Пфлопс. Он основан на 4480 ускорителях NVIDIA H100. Раздел имеет 1120 узлов, каждый из которых включает:
Общая ёмкость хранилища MareNostrum 5 составляет 650 Пбайт, из которых, 402 Пбайт приходятся на LTO, 248 Пбайт — на HDD, а остальное — на NVMe SSD. Задействована ФС IBM Spectrum Scale. Машина использует интерконнект InfiniBand NDR200, объединяющий более 8000 узлов. Можно заметить, что NVIDIA предоставила BSC не совсем стандартные решения. В будущем ожидается появление ещё одного GPP-раздела на базе NVIDIA Grace, а вот расширение ACC узлами с Xeon Emerald Rapids и Rialto Bridge не состоится. 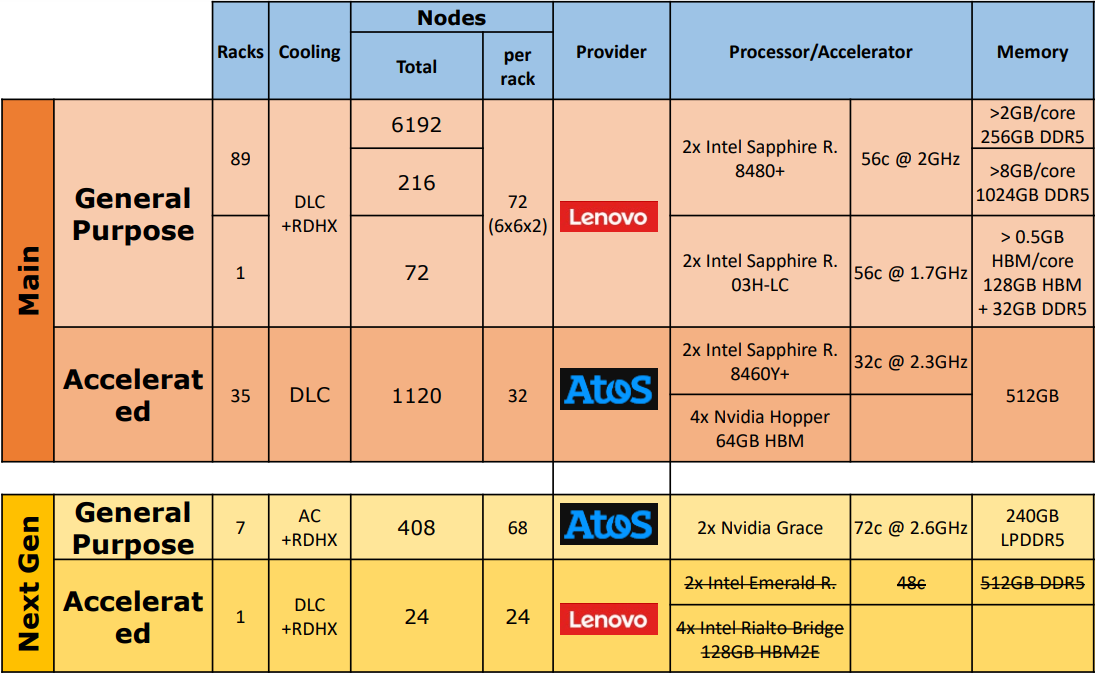 Благодаря увеличенной вычислительной мощности MareNostrum 5 позволяет решать всё более сложные задачи. Например, климатические модели получат более высокое разрешение, что сделает прогнозы гораздо более точными и надёжными. Также появится возможность решать гораздо более сложные проблемы в области ИИ и Big Data. Отдельное внимание уделено поддержке европейских медицинских исследований в области создания новых лекарств, разработки вакцин и моделирования распространения вирусов. Суперкомпьютер также станет важнейшим инструментом для материаловедения и инженерии, включая проектирование и оптимизацию самолётов, развитие более безопасной, экологически чистой и эффективной авиации. Аналогичным образом, машина будет использоваться для моделирования процессов энергогенерации, включая ядерный синтез. В ближайшие месяцы MareNostrum 5 объединится с двумя квантовыми компьютерами: первой системой испанской суперкомпьютерной сети (RES), которая является частью инициативы Quantum Spain, и одним из первых европейских квантовых компьютеров EuroHPC JU. Оба квантовых компьютера будут одними из первых, которых запустили в Южной Европе.
22.12.2023 [22:56], Сергей Карасёв
IDC прогнозирует стремительный рост мирового рынка генеративного ИИ: $150+ млрд в 2027 годуПо оценкам International Data Corporation (IDC), глобальные затраты в сфере генеративного ИИ по итогам 2023 года составят более $19,4 млрд. Эта цифра учитывает расходы на ПО в соответствующей сфере, инфраструктурные решения, а также на IT- и бизнес-сервисы. Аналитики говорят, что, несмотря на сложную макроэкономическую обстановку и различные препятствия на рынке IT, компании и организации активно внедряют генеративный ИИ для ускорения цифровой трансформации. Такие инструменты позволяют повысить эффективность сотрудников и удовлетворённость клиентов. 
Источник изображения: pixabay.com По оценкам IDC, в 2024 году объём мирового рынка генеративного ИИ вырастет более чем вдвое по сравнению с 2023-м: если этот прогноз оправдается, затраты окажутся на уровне $40 млрд. В дальнейшем ожидается показатель CAGR (среднегодовой темп роста в сложных процентах) в размере 86,1 %. В результате, в 2027-м расходы достигнут $151,1 млрд. Инфраструктурный сектор будет представлять собой крупнейшую область инвестиций на этапе развертывания генеративного ИИ в течение 2023–2027 гг. Этот сегмент включает оборудование, платформы IaaS и сопутствующий софт. Однако к концу рассматриваемого периода платформы генеративного ИИ и прикладное ПО обгонят инфраструктурные решения с показателем CAGR на уровне 99,6 %. По направлению услуг ожидается среднегодовой темп роста в 94,2 %. В целом, к 2027 году расходы на генеративный ИИ составят около 29,0 % от общих затрат на ИИ-рынке. Для сравнения: в 2023 году этот показатель оценивается в 10,8 %.
21.12.2023 [14:51], Сергей Карасёв
Германия построит суперкомпьютер Herder экзафлопсного уровняЦентр высокопроизводительных вычислений HLRS в Штутгарте (Германия) объявил о заключении соглашения с компанией HPE по созданию двух новых суперкомпьютеров — систем Hunter и Herder. Они, как утверждается, предоставят «инфраструктуру мирового класса» для моделирования, ИИ, анализа данных и других ресурсоёмких задач в различных областях. Hunter заменит нынешний флагманский суперкомпьютер HLRS под названием Hawk. В основу Hunter ляжет платформа HPE Cray EX4000: в общей сложности планируется задействовать 136 таких узлов, каждый из которых будет оснащён четырьмя адаптерами HPE Slingshot. Архитектура Hunter предусматривает применение СХД нового поколения Cray ClusterStor, специально разработанной с учётом жёстких требований к вводу/выводу. Кроме того, будет задействована среда HPE Cray Programming Environment, которая предоставляет полный набор инструментов для разработки, портирования, отладки и настройки приложений. 
Источник изображения: HLRS Суперкомпьютер Hunter получит ускорители AMD Instinct MI300A. Утверждается, что это позволит сократить энергопотребление по сравнению с Hawk примерно на 80 % при пиковой производительности. Быстродействие Hunter составит около 39 Пфлопс против 26 Пфлопс у Hawk. Систему планируется ввести в эксплуатацию в 2025 году. Суперкомпьютер экзафлопсного класса Herder заработает не ранее 2027 года. Архитектура предусматривает применение ускорителей, но окончательная конфигурация комплекса будет определена только к концу 2025-го. 
Источник изображения: HPE Общая стоимость Hunter и Herder оценивается в €115 млн. Финансирование будет осуществляться через Центр суперкомпьютеров Гаусса (GCS), альянс трёх национальных суперкомпьютерных центров Германии. Половину средств предоставит Федеральное министерство образования и исследований Германии (BMBF), оставшуюся часть — Министерство науки, исследований и искусств земли Баден-Вюртемберг. Нужно отметить, что в 2024 году в Юлихском исследовательском центре (FZJ) в Германии заработает вычислительный комплекс Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Кроме того, систему такого уровня намерена создать Великобритания.
21.12.2023 [12:09], Сергей Карасёв
В 2024 году EuroHPC запустит как минимум два новых квантовых компьютераЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило конкурс по выбору организаций, которым предстоит заняться интеграцией и эксплуатацией новых квантовых компьютеров. Заявки принимаются до 31 марта 2024 года. Сообщается, что в наступающем году EuroHPC JU планирует ввести в эксплуатацию как минимум две новые квантовые системы — комплексы EuroQCS-Poland и Euro-Q-Exa. Европейский союз выделит на эти проекты €20 млн, а дополнительное финансирование поступит от государств-участников EuroHPC JU. 
Источник изображения: pixabay.com EuroQCS-Poland — квантовый компьютер на основе ловушек ионов. Система будет размещена в Познаньском суперкомпьютерном и сетевом центре (PSNC) в Польше и интегрирована в местную НРС-инфраструктуру. Комплекс будет доступен широкому кругу европейских пользователей — от научного сообщества до промышленности и государственного сектора. Общая стоимость проекта оценивается в €15,5 млн. В свою очередь, Euro-Q-Exa будет представлять собой квантовый компьютер, основанный на сверхпроводящих кубитах. На первом этапе конфигурация предусматривает использование 50 физических кубитов с последующим расширением до 100 кубитов или более. Система будет смонтирована в Суперкомпьютерном центре Лейбница (LRZ) в Германии. Затраты на проект составят приблизительно €42,71 млн. В 2022 году, напомним, предприятие EuroHPC JU приняло решение о размещении первых квантовых компьютеров в Чехии, Германии, Испании, Франции, Италии и Польше. А в октябре 2023-го был объявлен тендер на создание платформы для бесшовного объединения всех европейских суперкомпьютеров и квантовых систем, а также инфраструктуры хранения данных.
21.12.2023 [10:06], Сергей Карасёв
Greenliant представила чипы eMMC NANDrive серии EX с повышенной надёжностьюКомпания Greenliant анонсировала флеш-чипы eMMC NANDrive серий EX, MX и VX, рассчитанные на использование в промышленной и коммерческой сферах. Изделия могут применяться в сетевых устройствах, индустриальном и автомобильном оборудовании, а также в других системах, которые эксплуатируются в жёстких условиях. Чипы eMMC NANDrive EX выполнены по технологии EnduroSLC (один бит информации в ячейке). Доступны версии, рассчитанные на 75 000, 150 000 и 400 000 циклов записи/стирания. Чипы подходят для интенсивных рабочих нагрузок. Для изделий eMMC NANDrive EX заявлена скорость последовательного чтения информации до 170 Мбайт/с и скорость последовательной записи до 137 Мбайт/с. Диапазон рабочих температур простирается от -40 до +85 °C. Предусмотрены версии в исполнениях 100-ball LBGA (2–4 Гбайт) и 153-ball LFBGA (2–32 Гбайт). Чипы включены в программу долгосрочной доступности Greenliant со сроком до 10 лет. 
Источник изображения: Greenliant Решения eMMC NANDrive MX (два бита информации в ячейке), в свою очередь, обеспечивают скорость последовательного чтения до 145 Мбайт/с и скорость последовательной записи до 31 Мбайт/с. Заявленный ресурс — до 5000 циклов записи/стирания. Изготавливаются варианты в исполнениях 100-ball LBGA (8 Гбайт) и 153-ball LFBGA (8–64 Гбайт). Температурный диапазон — от -40 до +85 °C. Чипы eMMC NANDrive VX (три бита информации в ячейке) получили исполнение 153-ball TFBGA. У них диапазон рабочих температур находится в пределах от -25 до +85 °C. Ёмкость варьируется от 16 до 64 Гбайт. Количество циклов записи/стирания достигает 3000. Скорость последовательного чтения информации составляет до 318 Мбайт/с и скорость последовательной записи — до 227 Мбайт/с. Greenliant предлагает клиентам образцы накопителей eMMC NANDrive VX и планирует начать их серийное производство в январе 2024 года. Изделия eMMC NANDrive EX доступны для заказа. |
|

