Материалы по тегу:
|
03.08.2026 [17:43], Руслан Авдеев
«Т плюс» предложила пристраивать ЦОД к российским ТЭЦОдна из крупнейших генерирующих компаний в России — «Т плюс» выступила с предложением использовать резервные мощности имеющихся ТЭЦ для организации электроснабжения ЦОД. На встрече в Госдуме, посвящённой ликвидации барьеров для инвестиций в ЦОД, представитель компании предложил строить дата-центры при самих электростанциях, сообщают «Ведомости». В условиях дефицита электрических мощностей быстро получить разрешение на подключение дата-центра становится всё труднее. При этом, по данным Минэнерго, резерв мощности ТЭЦ оставляют на уровне 15 %. Тем временем совокупная мощность ЦОД составляет 4,5 ГВт, из которых 77 % — корпоративные проекты, недоступные обычным клиентам. Использование резервов могло бы упростить ситуацию на рынке. Так, совокупная мощность ТЭЦ в России на сегодня составляет 175 ГВт, а годовой потенциал выработки — 1,5 трлн кВт∙ч, но на самом деле выработка на 50 % меньше и составила в 2025 году 751 млрд кВт∙ч. Другими словами, в среднем по стране используется вдвое меньше мощностей, чем могло бы, а оставшиеся не востребованы. Компания предлагает снабжать ЦОД при ТЭЦ энергией в часы, когда энергосистема в ней не нуждается, что позволит избежать конкуренции с прочими потребителями, поскольку им в этой схеме отдаётся приоритет. 
Источник изображения: Adrian Siaril/unsplash.com На долю «Т плюс» приходится около 5 % установленной мощности энергосистемы России (около 14 ГВт) и чуть менее 5 % всей генерации в 2025 году. В Центральном федеральном округе (ЦФО) у компании есть около 4–5 ГВт во Владимирской, Ивановской и Нижегородской областях. Тем временем, как утверждают эксперты, 80 % мощностей российских ЦОД тоже в ЦФО. Впрочем, к Москве и области это не относится, поскольку там резервов уже нет, но можно заняться локальной генерацией. Кроме того, из-за новых регуляций резко выросла стоимость аренды земли для ЦОД. Впрочем, в Минэнерго считают, что сейчас применяется «недискриминационный» принцип подключения к электросетям и фактически дефицит отсутствует уже сегодня. В теории дата-центры уже могут довольно быстро подключиться к электросетям, но в случае необходимости им могут ограничить энергопотребление. Однако в регионах дата-центры девелоперы и операторы массово строять не хотят, а основной спрос со стороны ЦОД приходится именно на Центральную Россию. Одним из выходов может быть перенос мощностей в Беларусь. А в MWS предложили застроить Сибирь и Дальний Восток ИИ ЦОД при участии Китая. Кроме того, отмечают эксперты, инициатива «Т плюс» содержит «системное противоречие» — в основном выработкой энергии в России занимаются ТЭЦ, которые поставляют ещё и тепло, т.е. генерация носит выраженный сезонный характер, тогда как дата-центрам требуется стабильное питание круглый год. В США крупные игроки всё чаще выбирают постройку собственных электростанций, в том числе на базе мобильных турбин.
03.08.2026 [15:17], Руслан Авдеев
Дурной пример заразителен: AWS развернёт 649 дизель-генераторов для питания нового ЦОДПравозащитная группа юристов Southern Environmental Law Center (SELC) обвинила Amazon и Duke Energy в попытках обойти Закон о чистом воздухе (Clean Air Act) США в связи с установкой 649 дизельных генераторов на территории строящегося кампуса ЦОД Amazon в Хэмлете (Hamlet, Северная Каролина), сообщает Datacenter Dynamics. Правозащитники подчёркивают, что одна из богатейших компаний в мире может и должна вести себя лучше. По данным SELC, Amazon подала заявку на установку 592 «экстренных» дизельных генераторов для резервного питания кампуса. Параллельно Duke подала заявку на использование ещё 57 мобильных генераторов на той же площадке для «основного» питания дата-центров до того времени, пока не будет обеспечено присоединение к магистральной электросети. SELC утверждает, что заявки были специально раздельно в попытке избежать соблюдения повышенных требований к защите окружающей среды и увеличить лимиты на загрязнения. Нормы пришлось бы пересмотреть, если бы все генераторы были указаны в одной заявке. В Duke Energy парировали, что 57 ДГУ обеспечат временное электропитание для AWS только на время строительства и тестирования ЦОД. Они не подключены к электросети Duke, а все сопутствующие расходы возложены исключительно AWS, и никак не отражаются на прочих клиентов коммунальной компании. Кроме того, временные генераторы разрешено использовать менее года, говорит компания. Да и вообще установка таких генераторов якобы вообще не требует специального разрешения из-за того, что оборудование находится очень близко от её же электростанции. 
Источник изображения: Viktoriya/unsplash.com Тем не менее, Duke говорит, что специально упомянула дизель-генераторы в заявке для действующей газовой электростанции. Более того, выбросы от последней вместе с выбросами генераторов всё ещё меньше, чем установленные для обеспечения экологической безопасности лимиты. Площадка AWS находится буквально через дорогу от принадлежащей Duke Energy газовой электростанции Smith Energy Complex мощностью 1,247 ГВт, построенной в 2001 году. В рамках сделки с Amazon Duke рассчитывает нарастить мощность электростанции на 240 МВт, установив новую газовую турбину. Amazon начала строительство кампуса ЦОД в октябре 2025 года, хотя информация об этом появилась ещё раньше. Предполагалось, что тот будет вмещать 20 зданий, каждое площадью более 18 580 м2. Непосредственно строительство должно стартовать в конце 2027 года, эксплуатацию планируется начать в конце 2029-го. По словам SELC, столь крупный массив ДГУ вредит жителями округа Ричмонд (Richmond County), в котором находится Хэмлет. Это один из самых экономически неблагополучных округов в Северной Каролине. Всевозможные юридические «трюки» с энергетикой — всё более обыденное дело для бизнеса, связанного с индустрией ЦОД. На днях сообщалось, что SpaceX/xAI избавится от «полулегальных» газовых турбин, питающих её ЦОД. Вместо этого она развернёт стационарную электростанцию… которая тоже будет состоять из десятков газовых турбин.
03.08.2026 [13:05], Сергей Карасёв
Renesas представила платформу третьего поколения DDR5 MRDIMM-16000Компания Renesas Electronics анонсировала чипсет третьего поколения для модулей оперативной памяти DDR5 Multiplexed Rank Dual In-Line Memory Module (MRDIMM). Изделия ориентированы на применение в системах для ИИ ЦОД, облачных платформ и других инфраструктур, рассчитанных на ресурсоёмкие задачи. В состав решения Renesas входят такие компоненты, как MRCD (Multiplexed Registering Clock Driver) для управления тактовыми сигналами, MDB (Multiplexed Data Buffer) для работы с буфером данных, PMIC (Power Management IC) для управления питанием, датчики температуры и пр. Кроме того, реализован инструментарий Device Equalization Self-Train Mode (DESTM) Quality Indication Status, который в числе прочего помогает точнее настраивать тайминги, чтобы максимально раскрыть потенциал системы. 
Источник изображения: Renesas Electronics Чипсет Renesas третьего поколения обеспечивает скорость до 16 000 МТ/с. Это, как утверждается, что 25 % больше по сравнению с изделиями предыдущего поколения. При этом используется существующая инфраструктура DDR5. Таким образом, производители и интеграторы могут увеличить производительность подсистемы памяти серверного оборудования на четверть без внесения каких-либо изменений на уровне аппаратной платформы. Кроме того, говорится о высокой энергетической эффективности. Renesas уже начала пробные поставки компонентов MRDIMM Gen 3 MRCD (RRG5013x) и MDB (RRG5103x) некоторым клиентам, включая ведущих производителей памяти DRAM. Предполагается, что на коммерческом рынке модули DDR5-16000 MRDIMM появятся во II половине следующего года.
03.08.2026 [13:03], Руслан Авдеев
DeepSeek построит собственный гигаваттный ИИ ЦОД во Внутренней МонголииКитайская DeepSeek, стоящая за разработкой передовых ИИ-моделей, способных конкурировать с западными «флагманами», намерена построить большой дата-центр во Внутренней Монголии (Китай). Компания рассчитывает на создание кампуса ИИ ЦОД мощностью 1 ГВт в городском округе Уланчаб (Ulanqab), сообщает Bloomberg. По данным источников, локация расположена в 350 км к северо-востоку от Пекина. DeepSeek рассчитывает построить собственный объект, одновременно арендуя дополнительные мощности у других компаний. По некоторым данным, что в Уланчабе планируют реализовать проекты более дюжины компаний. DeepSeek намерена ввести в эксплуатацию хотя бы часть мощностей нового кампуса к концу следующего года или в начале 2028-го. Пока неизвестно, на какие ускорителях будет работать оборудование. Наиболее распространёнными в индустрии являются чипы NVIDIA, но в Китае безусловным «чемпионом» в этой сфере называется Huawei. Кроме того, ранее ходили слухи, что DeepSeek работает над собственными ускорителями, но в данном случае речь идёт скорее о чипах для обучения, а не инференса. Хотя лидерами в сфере ИИ считаются западные компании вроде OpenAI и Anthropic, тратящие десятки миллиардов долларов на вычислительные мощности, китайские конкуренты с DeepSeek в том числе стараются нагнать их. 1-ГВт кампус ЦОД будет значительно крупнее любого современного китайского проекта, хотя он и будет отставать от 3–5-ГВт инициатив американских компаний. Китайская Z.AI (ранее Zhipu) также работает над 1-ГВт объектом, оснащать который рассчитывают только ускорителями китайского производства. 
Источник изображения: Charles MingZ/unsplash.com Со среднегодовыми температурами около +5 °C, Уланчаб якобы обеспечивает благоприятную для ЦОД прохладу, помогающую снизить энергопотребление объекта за счёт экономии на охлаждении оборудования, благодаря чему локация может быть привлекательная для китайских IT-гигантов вроде China Mobile, пишет Bloomberg. DeepSeek — один из ключевых игроков в китайской стратегии, нацеленной на конкуренцию на мировом рынке ИИ. Ранее в прошлом году компания потрясла технологическую индустрию, представив ИИ-модель с передовыми характеристиками, созданную с помощью относительно небольших вычислительных ресурсов в сравнении с другими передовыми моделями. DeepSeek также — один из лидеров в предложении недорогих, open source сервисов и продуктов, угрожающих бизнес-планам американских компаний вроде OpenAI и Anthropic. Китайские ИИ-сервисы нередко обходятся пользователям в десять и более раз дешевле, чем американские альтернативы. В июле к гонке присоединилась китайская Moonshot, дебютировавшая с моделью Kimi K3, тоже способной тягаться с западными флагманскими моделями в бенчмарках. Китайские достижения вызывают у западного бизнеса опасения, что ключевой геополитический соперник США ускоренными темпами устраняет разрыв в сфере критически важных технологий. Помимо DeepSeek, Moonshot и Z.AI, существует множество агрессивных игроков, включая Alibaba Group Holding и MiniMax Group. DeepSeek начала готовиться к IPO и может подать соответствующую заявку ещё до конца 2026 года. Новости появились после того, как она привлекла рекордные $7 млрд в ходе последнего раунда финансирования, капитализация составила около $50 млрд. В администрации президента США считают, что она сумела обойти американские экспортные ограничения, использовав ускорители NVIDIA Blackwell в ЦОД во Внутренней Монголии, которые фактически не продаются в Китай официально. Тем временем OpenAI и Anthropic обвиняют китайского конкурента в «дистилляции» — использовании их моделей для обучения собственной с аналогичными возможностями. Проект DeepSeek во Внутренней Монголии может быть знаком того, что китайские компании наращивают финансовую поддержку строительства ИИ-инфраструктуры — в этой сфере исторически лидировали бизнесы из Кремниевой долины благодаря доступ к американским рынкам капитала. По оценкам главы NVIDIA Дженсена Хуанга (Jensen Huang), создание 1-ГВт ЦОД, оснащённого самыми передовыми ускорителями, потребует около $50 млрд инвестиций. Стоимость разных ЦОД может сильно отличаться в зависимости от разных факторов, с учётом локации и чипов, которые те используют. При этом ИИ ЦОД в Китае обычно обходятся значительно дешевле, чем в США. Автономный район Внутренняя Монголия — одна из перспективных китайских провинций, отмеченных в программе Eastern Data, Western Compute. Последний предполагает размещение больших вычислительных мощностей на относительно малоосвоенном западе КНР. Впрочем, программа не вполне оправдала себя — дата-центры простаивают, а для продажи их мощностей приходится прикладывать усилия.
03.08.2026 [09:48], Владимир Мироненко
Рынок облачных услуг во II квартале показал самый высокий темп роста за восемь летСогласно данным Synergy Research Group, затраты на облачные инфраструктурные услуги во II квартале 2026 года выросли год к году более чем на $43 млрд, достигнув $143 млрд. В предыдущем квартале объём глобального рынка облачных инфраструктур, темпы роста которого в годовом исчислении увеличиваются 11-й квартал подряд, составил $128,6 млрд — за всё это время рынок увеличился вдвое. Рост во II квартале достиг 43 %, что является самым высоким показателем за последние восемь лет. И основным драйвером этого ускоренного роста рынка стал генеративный ИИ. Среди ведущих провайдеров облачных услуг по-прежнему лидирует Amazon. За ней следуют Microsoft и Google, которые продолжают демонстрировать значительно более высокие темпы роста. Доля глобального рынка этих компаний во II квартале составила 28 %, 20 % и 15 % соответственно. Во втором эшелоне провайдеров облачных услуг самые высокие темпы роста были у CoreWeave, OpenAI, Oracle, Crusoe, Nebius, Anthropic и Nscale. 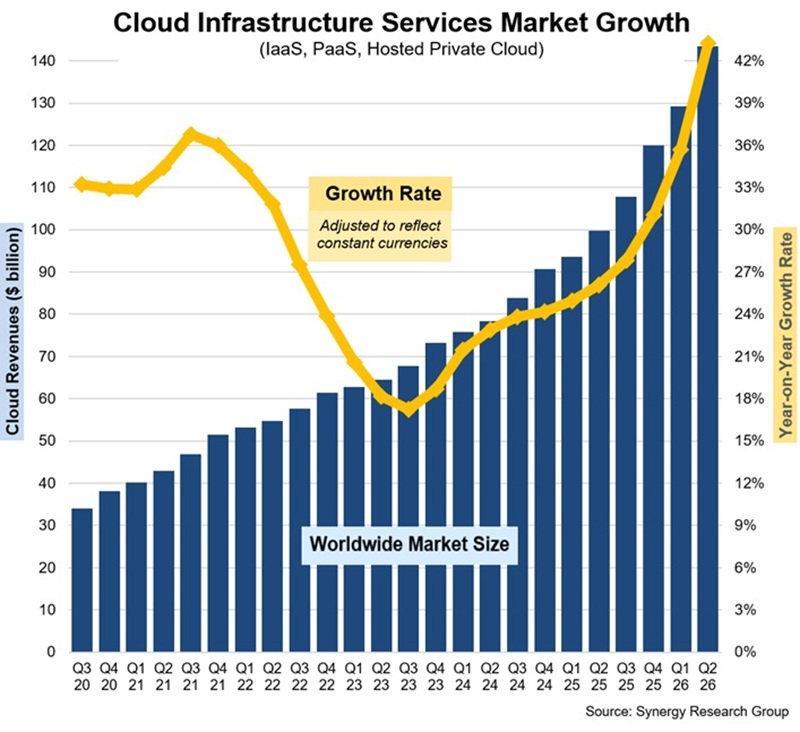
Источник изображения: Synergy Research Group Девять неооблаков вошли в число 40 крупнейших поставщиков облачных услуг исходя из доходов. Как сообщил Джон Динсдейл (John Dinsdale), главный аналитик Synergy Research Group, ИИ-технологии подстегнули облачный рынок и сейчас обеспечивают беспрецедентный рост. Основная часть рынка облачных инфраструктурных услуг приходится на публичные IaaS и PaaS, объёмы которых увеличились на 47 %. В сегменте публичных облаков на долю трёх лидеров приходится 67 % рынка. За последние два квартала доля США на мировом рынке увеличилась, что отражает масштабное развитие инфраструктуры в США как гипескейлерами, так и неооблаками. Впрочем, облачный рынок продолжает расти во всех регионах мира. Наиболее высокий рост показали Индия, Индонезия, Ирландия, Таиланд и Малайзия, темпы роста которых значительно превышают среднемировые. С большим отрывом лидируют США, которые намного превосходят по масштабам весь Азиатско-Тихоокеанский регион. Рынок США вырос на 49 % за минувший квартал, что значительно превышает среднемировой показатель. В Европе по-прежнему лидируют Великобритания и Германия, хотя наиболее высокий рост отмечен у Ирландии, Норвегии, Дании и Финляндии.
03.08.2026 [09:36], Руслан Авдеев
SpaceX/xAI построит четвёртый ЦОД в Мемфисе и избавится от «нелегальных» газовых турбин, заменив их на точно такие жеИлон Маск (Elon Musk) подтвердил строительство SpaceX/xAI (SpaceXAI) четвёртого ЦОД в Мемфисе (Теннесси). Попутно компания согласилась убрать 69 временных газовых турбин, питающих ЦОД в этом районе, сообщает Datacenter Dynamics. Не так давно экоактивисты подали против компании иск, заявив, что турбины установлены без правильно оформленных разрешений и их использование противоречит природоохранному закону Clean Air Act. Подконтрольная Маску xAI начала строить дата-центры в районе Мемфиса и Саутхейвена (Southaven) на границе штатов Теннеси и Миссури в 2024 году для размещения суперкомпьютеров Colossus. Компания в кратчайшие сроки возвела два дата-центра, а затем взялась за третий. В марте сообщалось, что SpaceXAI подала заявку на строительство ещё одного, четырёхэтажного здания площадью 28 985 м2 стоимостью $659 млн. Кроме того, компания намерена построить ещё один ИИ ЦОД в Техасе. Маск ответил на пост пользователя социальной сети X, опубликовавшего фото новой стройки на территории кампуса ЦОД xAI. По словам бизнесмена, на фото справа находится MINIHARD, который получит 220 тыс. NVIDIA GB300 с 800G-адаптерами, как и MACROHARDRR, но в улучшенной, более плотной конфигурации. Оба названия являются шуточной отсылкой к Microsoft. 
Источник изображения: S.E. Robinson, Jr./x.com Пока нет данных, хватит ли компании электроэнергии для дополнительных 220 тыс. ИИ-ускорителей GB300, на обслуживание которых, вероятно, потребуется 400 МВт. Компания заявляет, что в ЦОД близ Мемфиса она располагает 1 ГВт вычислительных мощностей, но сделанные в январе спутниковые снимки показали, что установленное охладительное оборудование рассчитано лишь на 350 МВт. В проспекте, выпущенном SpaceX перед IPO, заявлялось, что следующая фаза развития кампуса предусматривает внедрение ещё 220 тыс. ИИ-ускорителей и более 400 МВт вычислительной мощности. Размещение в районе Мемфиса дата-центров уже вызвало недовольство местных жителей и экоактивистов, в первую очередь из-за использования газовых турбин для обеспечения дата-центров энергией. Хотя именно это позволило компании быстро ввести в строй ЦОД, активисты жалуются, что из-за них ухудшилось качество воздуха в беднейших районах. Теперь заявляется, что компания уберёт со своей площадки 69 временных мобильных турбин в течение следующего года, как раз перед установкой постоянной электростанции мощностью 1,2 ГВт, разрешение на которую получено в марте. Временные турбины начнут убирать уже в августе, хотя для местных жителей мало что изменится — «постоянная электростанция» также будет состоять из 41 газовой турбины. В заявлении SpaceX сообщалось, что компания «выпустила согласованное распоряжение» с Департаментом качества окружающей среды Миссисипи, устанавливающее фиксированный график демонтажа 69 турбин. Также подчёркивается, что организована перенастройка электрооборудования для снижения уровня шума от объекта и минимизации воздействия на местных жителей. Примечательно, что буквально на днях сообщалось, что фактически xAI продолжает наращивать свою полузаконную газовую электростанцию для Colossus.
02.08.2026 [14:46], Сергей Карасёв
Supermicro представила серверные стойки со статической нагрузкой до 2500 кгSupermicro расширила ассортимент серверных стоек, анонсировав десять моделей для систем высокой плотности, ориентированных на ресурсоёмкие задачи ИИ и другие критические нагрузки. Дебютировали решения на базе стандартов OCP ORv3 и NVIDIA MGX, а также традиционные 19″ варианты. Новинки входят в продуктовое семейство Supermicro Data Center Building Block Solutions (DCBBS). Стойки могут поставляться в предварительно сконфигурированном виде, что упрощает и ускоряет развёртывание: заказчикам и интеграторам не нужно монтировать на объекте вычислительные узлы, сетевые компоненты, а также элементы подсистем питания и охлаждения. Все анонсированные устройства рассчитаны на статическую нагрузку до 2500 кг. Это позволяет размещать мощные ИИ-серверы с ускорителями на базе GPU, высокопроизводительное силовое оборудование и пр. Изделия проходят испытания на вибро- и сейсмическую устойчивость. Говорится о гибких возможностях в плане применения жидкостного охлаждения: стойки совместимы с блоками распределения охлаждающей жидкости (CDU) различных типов, теплообменниками на задней двери (RDHx) и пр. Силовые и сетевые кабели полностью изолированы. 
Источник изображения: Supermicro В число новинок входят стойки для платформ NVIDIA VR200/GB300 MGX в форматах 48U и 52U с вариантами ширины 600 и 750 мм. Кроме того, выпущены решения 44OU и 48OU стандарта ORv3 (типоразмера 21″). В традиционном 19″ исполнении доступны варианты 48U и 52U. Компания Supermicro отмечает, что её производственных возможностей достаточно для выпуска примерно 3 тыс. таких стоек в месяц. Из них около 2 тыс. могут комплектоваться СЖО.
02.08.2026 [14:37], Владимир Мироненко
Arm объявила о растущем спросе на её процессор для ЦОД, но акции упали из-за ожидаемого снижения роялти от смартфоновArm Holdings сообщила результаты за I квартал 2027 финансового года, завершившийся 30 июня 2026 года. Выручка компании выросла год к году на 22 % до $1,29 млрд благодаря росту спроса на разработанные ею чипы для ИИ ЦОД, что привело к рекордным для I квартала показателям лицензирования и роялти. Выручка Arm превысила прогноз аналитиков, опрошенных FactSet, в размере $1,26 млрд (согласно данным The Wall Street Journal). Скорректированная прибыль составила 45¢ на акцию. Аналитики, опрошенные FactSet, прогнозировали 40¢ на акцию. Чистая прибыль достигла $270 млн или 25¢ на акцию, по сравнению со $130 млн, или 12¢ на акцию годом ранее. Выручка от роялти выросла на 22 % до $715 млн благодаря более чем двукратному увеличению роялти на технологии для чипов для ЦОД, а выручка от лицензирования увеличилась на 23 % до $574 млн. Росту выручки также способствовало продолжающееся внедрение технологий Arm с более высокими ставками роялти за чип, таких как Armv9 и Arm CSS. Генеральный директор Рене Хаас (Rene Haas) заявил, что спрос на CPU Arm AGI превзошёл ожидания, и превысил $2 млрд в 2027 и 2028 финансовых годах, что более чем вдвое превышает прогнозируемый компанией в прошлом квартале потенциальный объём в $1 млрд. Он добавил, что компания уже поставила первые чипы нескольким клиентам, включая Oracle. IDC сообщила, что расходы на ускоренные серверные платформы на базе Arm почти удвоились за последние два квартала и превысили расходы на платформы x86. 
Источник изображения: Arm Arm сообщила, что продолжает привлекать новых клиентов, в том числе нескольких в США и Китае, в то время как общая стоимость портфеля заказов продолжает расти. Также компания отметила, что обеспечила производственные мощности, необходимые для поддержки потенциала в $1 млрд, обозначенного в предыдущем квартале, в период с 2027 по 2028 финансовый год и работает с партнёрами над дальнейшим расширением производства. Компания заявила, что переход ИИ-инфраструктуры на Arm продолжает набирать обороты. Эту архитектуру используют крупные провайдеры облачных услуг и производители микросхем, включая NVIDIA, AWS, Google, Microsoft и Qualcomm. Процессор Vera от NVIDIA, построенный на архитектуре Arm, запущен в полномасштабное производство, а AWS объявила о многолетнем соглашении с Meta✴ о развёртывании десятков млн ядер Graviton5 на базе Arm для рабочих ИИ-нагрузок. Поставки процессоров Neoverse для ЦОД уже превысили 1,5 млрд ядер. Во II финансовом квартале компания прогнозирует скорректированную прибыль в диапазоне от 43¢ до 51¢ на акцию при выручке от $1,33 до $1,43 млрд. Аналитики, опрошенные LSEG, прогнозируют скорректированную прибыль в размере 44¢ на акцию при выручке в $1,34 млрд. Несмотря на то, что прогноз компании по выручке за II финансовый квартал оказался выше ожиданий Уолл-стрит, её акции упали на 9 %, сообщило агентство Reuters. Акции упали после того, как Arm заявила, что ожидает снижения роялти от продаж смартфонов в следующем квартале.
01.08.2026 [15:49], Сергей Карасёв
Xcena представила вычислительную память MX1 для генеративного ИИЮжнокорейский стартап Xcena анонсировал продукты семейства MX1, призванные решить проблему дефицита памяти в масштабных платформах, ориентированных на задачи генеративного ИИ. По мере того как генеративный ИИ требует всё более крупных моделей, более длинных контекстных окон и стремительно растущих объёмов KV-кеша, память становится главным ограничивающим фактором для инфраструктуры ИИ. Изделия HBM остаются крайне дорогими при ограниченной ёмкости, тогда как расширение путём добавления серверов приводит к формированию избытка вычислительных ресурсов и росту совокупной стоимости владения, говорит Xcena. Устройства MX1 призваны переломить ситуацию. Речь идёт об использовании вычислительной памяти. Идея заключается в том, чтобы увеличить основную память системы, добавив модули DDR5 DIMM вкупе с ядрами RISC-V. Реализована поддержка PCIe 6.0 и CXL 3.2, а технология NDP (Near Data Processing) сводит к минимуму задержку при перемещении данных между интерфейсами. В результате, значительно ускоряется выполнение ресурсоёмких задач при одновременном снижении нагрузки на CPU. 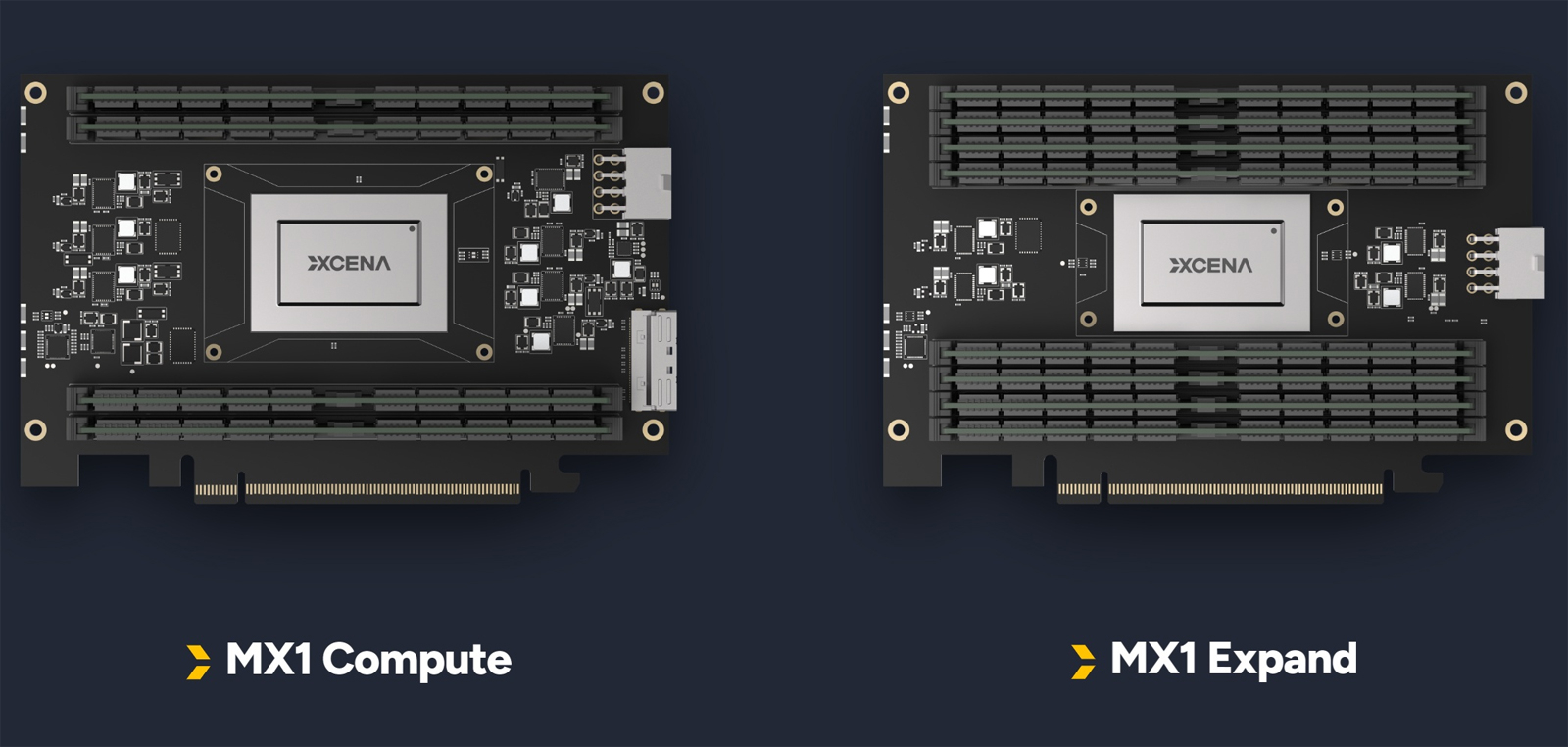
Источник изображения: Xcena В семейство входят изделия MX1 Compute и MX1 Expand. Первое представляет собой CXL-решение с 2048 ядрами RISC-V и четырьмя слотами DRAM, что позволяет выполнять вычисления рядом с памятью. Благодаря этому устраняется перемещения данных между CPU и памятью, что повышает производительность инференса и сокращает энергопотребление. В свою очередь, MX1 Expand предоставляет восемь слотов DRAM для эффективного масштабирования пула памяти.
01.08.2026 [15:39], Сергей Карасёв
10 DWPD для ИИ: ScaleFlux представила SSD-платформу для инференсаКомпания ScaleFlux анонсировала специализированную программно-аппаратную платформу на основе SSD для ресурсоёмких нагрузок ИИ-инференса. Предложенное решение может применяться в рамках архитектуры NVIDIA CMX — системы хранения данных, предназначенной для ускорения работы с контекстом в ИИ-инфраструктурах. Платформа ScaleFlux рассчитана на задачи с интенсивным использованием KV-кеша. Отмечается, что KV-блоки часто перезаписываются, хранятся разное время и могут асинхронно аннулироваться. Поэтому при инференсе, когда активно используется KV-кеш, создаётся повышенная нагрузка на SSD, что приводит к быстрому износу чипов флеш-памяти и к тому, что операторы дата-центров и гиперскейлеры вынуждены тратить огромные средства на закупку дополнительных накопителей и замену выходящих из строя устройств. 
Источник изображения: ScaleFlux Новая технология ScaleFlux призвана решить проблему. Платформа базируется на трёх ключевых принципах: анализ реального поведения рабочей нагрузки, разделение блоков KV-кеша с разными жизненными циклами и поддержание интенсивных рабочих нагрузок записи без чрезмерного увеличения ёмкости SSD или расходов на их замену. Основным элементом системы ScaleFlux является функция Flexible Data Placement (FDP): она позволяет группировать данные по их жизненному циклу (например, по сессии, вероятности повторного использования) и размещать их в отдельных физических областях накопителя. Это минимизирует внутреннее перемещение данных, а следовательно, снижает износ флеш-памяти. Платформа поддерживает более 200 потоков FDP-записи на один накопитель, обеспечивая гибкое разделение данных по типам нагрузок. Ещё одной составляющей решения ScaleFlux является телеметрия Context-Insight: она фиксирует ключевые метрики работы накопителя — задержки, глубину очереди, распределение размеров запросов, возраст данных, интервалы между записью и первым чтением, интенсивность повторного использования и пр. Для первоначального анализа рабочей нагрузки инструмент Context-Insight может использоваться в режиме «только SSD» — без внесения изменений в вышестоящие программные слои. При более глубокой интеграции система сопоставляет телеметрию SSD с метаданными приложения, включая идентификаторы сеансов и рабочих процессов, принадлежность KV-блоков, состояние жизненного цикла и т.д. Это позволяет операторам соотносить задержку и ресурс накопителей с конкретными классами рабочих нагрузок. В предварительных тестах применение платформы ScaleFlux с поддержкой FDP позволило сократить коэффициент усиления записи (Write Amplification) более чем в два раза по сравнению с традиционными хранилищами. С аппаратной точки зрения применяемые в составе системы ScaleFlux накопители рассчитаны на 7–10 и более полных перезаписей в сутки (DWPD) на протяжении пяти лет для нагрузок с использованием KV-кеша. |
|

