Материалы по тегу: кластер
|
25.05.2026 [10:18], Сергей Карасёв
Представлен 48-узловой ИИ-сервер Firefly CSC2-N48SPK3 с архитектурой RISC-VКомпания Firefly анонсировала многоузловой сервер CSC2-N48SPK3, предназначенный для решения ИИ-задач. Суммарная заявленная производительность этой системы, выполненной на архитектуре RISC-V, достигает 2880 TOPS на операциях INT4. Устройство получило форм-фактор 2U с 48 вычислительными узлами. Каждый из них содержит процессор SpacemiT Key Stone K3 с восемью 64-бит ядрами RISC-V X100M с тактовой частотой до 2,4 ГГц, 8/16/32 Гбайт оперативной памяти LPDDR5 и флеш-накопитель UFS 2.2 вместимостью 128 Гбайт. Говорится о полной поддержке профиля RVA23. Кроме того, в состав сервера входит один узел управления с процессором Rockchip RK3588: он содержит по четыре ядра Cortex-A76 (2,4 ГГц) и Cortex-A55 (1,8 ГГц), а также графический блок Arm Mali-G610 и нейропроцессорный узел (NPU) с производительностью до 6 TOPS. Объём ОЗУ этого узла равен 8 Гбайт. Реализован консольный порт RJ45. 
Источник изображения: Firefly Новинка располагает интерфейсом HDMI с поддержкой видео 1080p60, четырьмя сетевыми разъёмами 10GbE SFP+, двумя портами USB 3.0 и сенсорным дисплеем во фронтальной части, на котором отображаются различные параметры (температура, скорость вращения вентиляторов, сетевые данные и пр.). Опционально предлагается возможность установки до 48 накопителем формата M.2 2280 с интерфейсом PCIe (NVMe): при использовании SSD вместимостью 16 Тбайт суммарная ёмкость подсистемы хранения может достигать 768 Тбайт. Габариты составляют 724 × 430 × 88,8 мм, масса — 23,1 кг. Питание обеспечивают два блока с резервированием и возможностью горячей замены. Сервер Firefly CSC2-N48SPK3 доступен для заказа по цене $38 829 в комплектации с 48 вычислительными узлами, оборудованными 16 Гбайт оперативной памяти каждый.
18.05.2026 [20:00], Руслан Авдеев
NVIDIA представила платформу Fleet Intelligence для мониторинга парка ИИ-ускорителей
dcim
nvidia
software
ии
информационная безопасность
кластер
конфиденциальность
мониторинг
облако
оркестрация
телеметрия
цод
NVIDIA представила управляемую платформу Fleet Intelligence, предназначенную для мониторинга состояния крупных кластеров ускорителей, используемых в ИИ-инфраструктуре. Сервис уже доступен бесплатно для клиентов, использующих продукты NVIDIA на основе ускорителей семейств Hopper, Blackwell и Vera Rubin. NVIDIA позиционирует платформу как независимый слой телеметрии и мониторинга, позволяющий отслеживать работу с гетерогенными инфраструктурными средами, независимо от стека оркестрации или планировщика задач. Платформа применяет «лёгкий», интегрируемый в хост-систему агент, который передаёт телеметрию с ИИ-ускорителей в облачную службу Fleet Intelligence, работающую в экосистеме платформы NGC (NVIDIA GPU Cloud). Агент применяет несколько технологий NVIDIA, включая службу мониторинга ускорителей — GPUd, инструмент управления и диагностики чипов DCGM (NVIDIA Data Center GPU Manager) и средства проверки целостности оборудования и ПО NVIDIA Attestation SDK. Компания также выложила код агента Fleet Intelligence на GitHub, что позволит операторам ИИ-инфраструктуры самостоятельно оценить механизмы телеметрии. Fleet Intelligence ведёт сбор данных о степени загруженности ускорителей, пропускной способности памяти, энергопотреблении системы, состоянии интерконнектов NVLink, температуре системы, ошибках ECC, а также показателях состояния аппаратной составляющей. Это помогает операторам ЦОД организовать раннее выявление недоиспользованных ресурсов и ошибок и снизить простои крупных ИИ-кластеров. 
Источник изображений: NVIDIA Одними из основных свойств платформы стали возможности проверки целостности и аттестации на основе технологий защищённых вычислений NVIDIA Confidential Computing. Fleet Intelligence проводит криптографическую валидацию прошивок ИИ-ускорителей и целостность среды выполнения с помощью корневых сертификатов доверия NVIDIA, а также сервиса удалённой проверки оборудования NRAS (NVIDIA Remote Attestation Service). Платформа может подтвердить, что ускорители используют утверждённую прошивку и использует манифесты целостности Reference Integrity Manifests, привязанные к определённым версиям vBIOS. 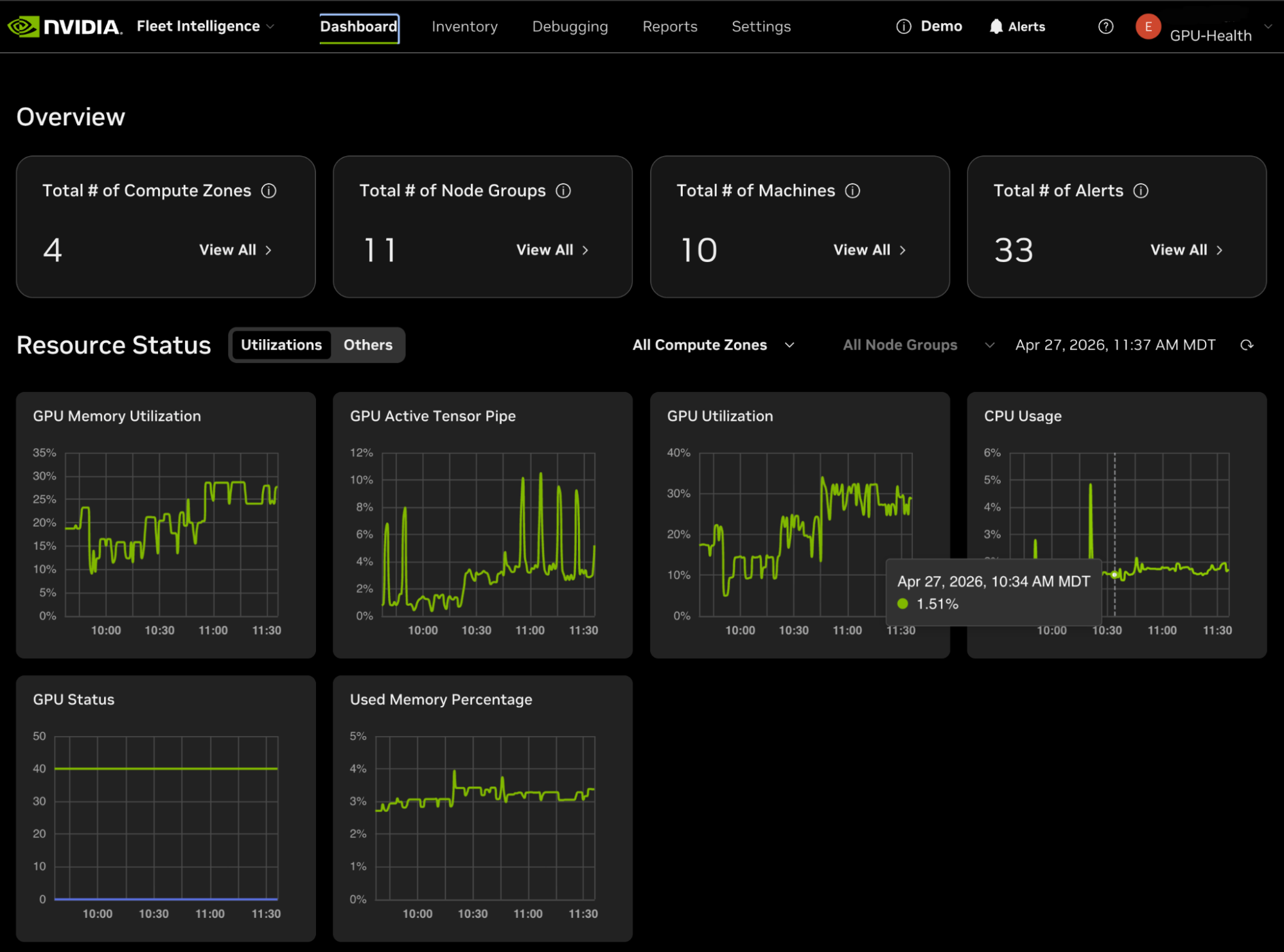 По словам NVIDIA, при разработке Fleet Intelligence применяли опыт эксплуатации облачных платформ NVIDIA DGX Cloud, использовавших сотни тысяч ИИ-ускорителей. В числе корпоративных пользователей, получивших ранний доступ к платформе — Lambda и Iren, обе предоставляли обратную связь в ходе работ. Премьера Fleet Intelligence свидетельствует, что амбиции NVIDIA простираются далеко за пределы простой разработки ИИ-ускорителей, компания развивает ПО и инструменты управления для ИИ-фабрик. Это дополнение уже имеющегося стека компании, включающего системы DGX, интерконнекты NVLink, сетевые продукты Spectrum-X, платформу оркестрации Mission Control и решения для защищённых вычислений. 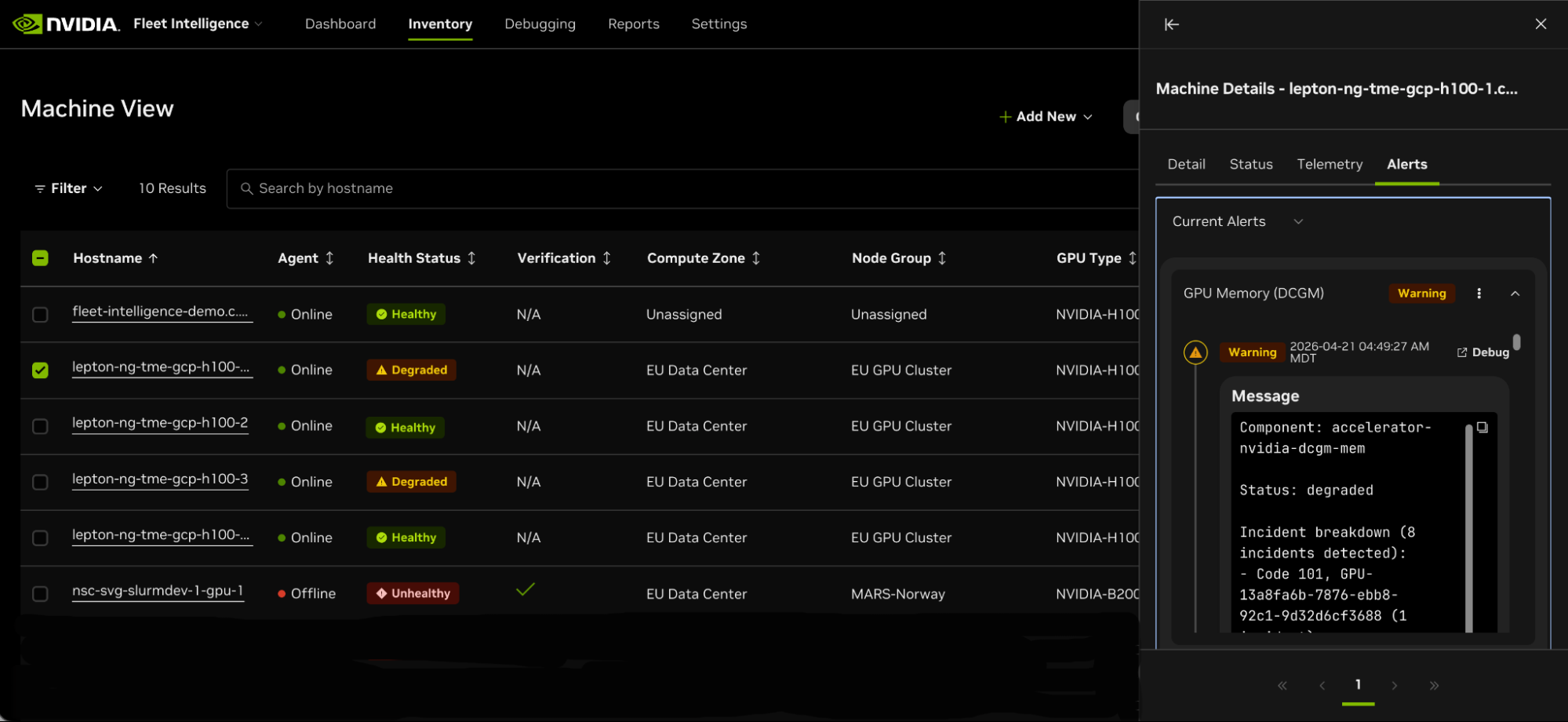 Добавление масштабной телеметрии и предиктивной аналитики отражает растущий спрос гиперскейлеров и корпоративных клиентов на максимальное использование ресурсов ускорителей. Кроме того, премьера платформы является отражением роста конкуренции на рынке систем мониторинга и эксплуатации ИИ-инфраструктуры. Облачные операторы и другие компании, включая AMD, Intel и т.п., строят собственные платформы для телеметрии, диагностики и управления крупными ИИ-кластерами. Возможность NVIDIA интегрировать аппаратную телеметрию, проверку надёжности прошивок и операционную аналитику напрямую в инфраструктурный стек усиливает позиции компании в роли вертикально интегрированного поставщика ИИ-инфраструктуры.
29.04.2026 [01:23], Владимир Мироненко
Tenstorrent представила ИИ-серверы Galaxy Blackhole для быстрой генерации токенов и без дезагрегацииTenstorrent представила вычислительную систему Galaxy Blackhole на базе ускорителей Blackhole с архитектурой RISC-V, которая позиционируется как системная ИИ-платформа, способная конкурировать с другими решениями за счёт стабильной производительности инференса, высокоскоростного доступа к памяти и масштабируемой сети — трёх факторов, которые всё чаще определяют эффективность развёртывания ИИ в реальных условиях, пишет Forbes. 6U-сервер Tensorrent Galaxy Blackhole с воздушным охлаждением основан на 32 ИИ-ускорителях Blackhole суммарной производительностью 23 Пфлопс в режиме FP8. Система включает 6,2 Гбайт SRAM (суммарно 2,9 Пбайт/с) и 1 Тбайт GDDR6 (суммарно 16 Тбайт/с). Высокоскоростную связь между узлами при горизонтальном масштабировании обеспечивают 800GbE-порты — до 56 портов на систему с общей пропускной способностью 11,2 Тбайт/с (в дуплексе). Стоимость системы Tensorrent Galaxy Blackhole составляет $110 тыс. Восьмичиповые системы NVIDIA DGX будут производительнее, но и обойдутся в три-пять раз дороже, сообщил The Register. Базовый суперкластер Galaxy Supercluster стоимостью в $440 тыс. включает четыре системы Blackhole. При этом архитектура Tenstorrent поддерживает масштабирование до 32 узлов с 1024 ускорителями. Mesh-сеть Tenstorrent не ограничивается одним узлом. Подобно кластерам TPU от Google или Trainium2 от Amazon, её можно расширить для поддержки более крупных моделей, более высокой пропускной способности или большей интерактивности, добавив больше узлов и отрегулировав параллелизм тензоров и конвейеров. 
Источник изображений: Tenstorrent Как сообщает Tenstorrent, для DeepSeek V3 её четырёхузловые суперкластеры Blackhole Galaxy Supercluster могут обрабатывать запрос на 100 тыс. токенов — эквивалент 166 страниц текста — менее чем за четыре секунды. Tenstorrent заявила, что кластеры Galaxy Blackhole могут генерировать видео быстрее, чем в реальном времени, а также очень быстро генерировать токены LLM. Демонстрационные версии систем Tenstorrent настроены на обычный режим с генерацией текста с удобочитаемой скоростью, и режим Blitz, обеспечивающий максимально быструю обработку данных, подходящую для таких приложений, как генерация кода и агентный ИИ. В режиме Blitz MoE-модель DeepSeek-671B обеспечивает «до 350 т/с на пользователя со временем получения первого токена менее 4 с», сообщила компания. Ресурс EE Times протестировал этот режим за несколько дней до официального запуска, получив 255 т/с на пользователя для коротких запросов в стиле чат-бота. Этот режим поддерживает пакетную обработку от 8 до 64 и длину контекста до 128 тыс токенов. Он работает на 16 серверах Galaxy (512 чипов) с использованием конвейерного параллелизма на этапе декодирования.  Компания отметила, что её системы не нуждаются в дезагрегации. «Мы можем выполнять и [предварительное заполнение, и декодирование] на одном узле, — сообщил генеральный директор Tenstorrent Джим Келлер (Jim Keller) изданию EE Times. — Мы создаём большой кластер, на котором можно запускать предварительное заполнение и декодирование LLM, генерацию видео, агентный ИИ… мы не специализируемся на чём-то одном. У нас много чипов, большой объём SRAM, но все чипы имеют DRAM, и все они тесно связаны между собой, поэтому наша платформа гораздо более универсальна».
24.04.2026 [11:15], Руслан Авдеев
Tesla развернула ИИ-кластер Cortex 2 на территории Gigafactory в ТехасеTesla ввела в эксплуатацию кластер Cortex 2 для обучения ИИ, расположенный на территории кампуса Gigafactory Texas. Это знаменует новый шаг на пути компании к расширению собственных вычислительных мощностей для создания систем автономного вождения, робототехники и других задач в сфере ИИ, сообщает Converge Digest. В презентации для акционеров, посвящённой итогам I квартала 2026 года, компания указала, что кластер Cortex 2 находится на стадии «раннего масштабирования». Установленная годовая производительность составляет эквивалент более 130 тыс. ИИ-ускорителей NVIDIA H100. Кроме того, имеется ещё и кластер Cortex 1, эквивалентный 100 тыс. H100. По данным Tesla, Cortex 2 уже выполняет задачи обучения моделей. Кроме того, компания разрабатывает и архитектуру Dojo 3 для суперкомпьютеров нового поколения, чтобы снизить затраты на обучение в будущем. Развитие ИИ-инфраструктуры Tesla напрямую связывается с с масштабированием планов по созданию роботизированных такси и Optimus. В материалах отчёта также упоминается, что расширение вычислительных мощностей осуществляется в рамках более масштабного плана развития в сфере аккумуляторных технологий, материалов и сервисов мобильности. 
Источник изображения: Tesla Кроме того, в отчёте указано на запуск в апреле системы FSD (Supervised) версии 14.3, улучшении «обучения с подкреплением» и обработки в системах машинного зрения, задержка инференса сокращена на 20 %. Кроме того, т.н. Digital Optimus обозначен как следующий этап развития ИИ-платформы Tesla. Также раскрыты планы компании в полупроводниковой отрасли. Было заявлено, что Tesla расширяет сферу производства и намерена заняться выпуском полупроводников, начиная с мощностей Research Fab на территории Gigafactory в Техасе. Сообщалось, что в апреле компания окончательно завершила разработку чипа нового поколения AI5. Также объявлено, что партнёрство со SpaceX направлено на создание «крупнейшего в истории» завода по выпуску чипов, с вертикальной интеграцией, включающей логические микросхемы, память и передовые технологии упаковки. Утверждение о масштабе, конечно, является словами самой Tesla, но оно косвенно свидетельствует о том, насколько агрессивно компания сейчас связывает ИИ-вычисления, разработку чипов и производственную стратегию.
08.04.2026 [22:38], Владимир Мироненко
Alibaba и China Telecom запустили ИИ-кластер на базе 10 тыс. ИИ-ускорителей ZhenwuAlibaba объявила о развёртывании в сотрудничестве с мобильным оператором China Telecom вычислительного ИИ-кластера из 10 тыс. ИИ-ускорителей Zhenwu, разработанных подразделением Alibaba T-Head. По словам Alibaba Cloud, передовые вычислительные мощности Китая «переходят от высокопроизводительных прорывов к крупномасштабному промышленному внедрению». ИИ-кластер размещён в дата-центре оператора China Telecom в Шаогуане (Shaoguan, провинция Гуандун). Как отметило облачное подразделение Alibaba, этот «полностью отечественный» кластер стал первым проектом такого масштаба на базе чипов Zhenwu в районе Большого залива (Greater Bay Area, GBA) — одном из ключевых стратегических регионов в планах национального развития Китая. По данным Alibaba Cloud, новый кластер обеспечивает сверхнизкую задержку в 4 мс и позволяет 10 тыс. чипам работать как единая система, способная обучать ИИ-модели с сотнями миллиардов параметров. China Telecom и Alibaba заявили, что вычислительный ИИ-кластер может использоваться в различных отраслях, от здравоохранения до разработки передовых материалов. Также сообщается, что в дальнейшем он будет расширен до 100 тыс. чипов. 
Источник изображения: www.alibabagroup.com Запуск ИИ-кластера на базе чипов Zhenwu является ещё одним свидетельством того, что Китай удваивает усилия по развитию собственной инфраструктуры для ускорения быстро развивающихся ИИ-технологий и удовлетворения растущего спроса на фоне обострения конкуренции в области ИИ с американскими соперниками, включая Meta✴, Microsoft и xAI, пишет South China Morning Post. Объявление Alibaba о создании ИИ-кластера последовало за запуском в конце прошлого месяца первого в стране интеллектуального вычислительного кластера на базе 10 тыс. чипов Huawei Ascend 910C общей ИИ-производительностью 11 Эфлопс в Шэньчжэне (Shenzhen, провинция Гуандун). В прошлом году компания запустила ИИ-кластер с производительностью 3 Эфлопс. По данным Shenzhen Special Zone Daily, почти 50 организаций подписали рамочные соглашения на использование вычислительных мощностей нового кластера, в результате чего общий уровень бронирования по обоим кластерам достиг 92 %.
22.12.2025 [12:28], Сергей Карасёв
Китайская Sugon представила ИИ-платформу ScaleX с 10 тыс. ускорителейКитайский разработчик суперкомпьютеров Sugon (Dawning Information Industry), по сообщению газеты South China Morning Post, анонсировал платформу ScaleX для решения ресурсоёмких задач в области ИИ. Система призвана составить конкуренцию продуктам NVIDIA и Huawei. По заявлениям Sugon, ScaleX представляет собой первый в КНР суперкластер, объединяющий около 10 тыс. ускорителей. ИИ-производительность превышает 5 Эфлопс (точность вычислений не называется). Платформа может применяться для работы с ИИ-моделями, насчитывающими триллионы параметров. В основу суперкластера положены 16 стоек Sugon ScaleX640, каждая из которых может нести на борту до 640 ускорителей. Таким образом, общее количество ИИ-карт в составе платформы достигает 10 240. Конструкция стоек предполагает использование иммерсионного жидкостного охлаждения с фазовым переходом и высоковольтных источников питания постоянного тока (DC). Стойки связаны друг с другом высокоскоростным интерконнектом ScaleFabric. Sugon отмечает, что для моделей ИИ с триллионами параметров ScaleX640 обеспечивает повышение производительности на 30–40 % на задачах обучения и инференса по сравнению с традиционными НРС-системами. 
Источник изображения: Sugon Предполагается, что ScaleX будет соперничать с будущими решениями Huawei, в частности, с суперкластерами Atlas 950 и Atlas 960. В их основу лягут ИИ-ускорители Ascend нового поколения, о подготовке которых стало известно в сентябре уходящего года. Система Atlas 950 SuperCluster, выход которой ожидается к концу 2026 года, будет содержать в общей сложности более 500 тыс. NPU, а Atlas 960 SuperCluster — свыше 1 млн. Сейчас у Huawei есть платформа CloudMatrix 384, которая объединяет 384 ускорителя Huawei Ascend 910C.
04.12.2025 [12:21], Руслан Авдеев
Скромно, но со вкусом: Vultr при поддержке AMD построит за $1 млрд ИИ-кластер с 24 тыс. Instinct MI355XОблачный провайдер Vultr строит кластер мощностью 50 МВт из ИИ-ускорителей AMD в дата-центре в Огайо. Новый проект призван обеспечить дополнительные вычислительные мощности по сниженным ценам, сообщает Bloomberg. Поддерживаемая AMD компания намерена инвестировать в объект более $1 млрд, клиенты смогут обучать и эксплуатировать ИИ-модели. Ввод в эксплуатацию запланирован на I квартал 2026 года. Vultr входит в группу облачных провайдеров, желающих заработать на ажиотажном спросе на ИИ. Новый кластер гораздо меньше гигантских объектов Microsoft, Meta✴ и Google. При этом вычислительные мощности, по словам компании, будут предлагаться по более доступным тарифам. Облако Vultr, как правило, вдвое дешевле, чем предложения гиперскейлеров, сообщают в компании. Утверждается, что её 50-МВт ЦОД с 24 тыс. AMD Instinct MI355X сопоставим с некоторыми гигаваттными проектами по эффективности. Vultr одной из первых получила MI355X, а вскоре перейдёт на MI450. Кластер называют «беспрецедентным» для облачной компании такого масштаба, но для него пока нет готовых к подписанию соглашений клиентов, хотя активные переговоры уже ведутся. По имеющимся данным, действующие клиенты вроде Clarifai Inc. и LiquidMetal AI, а также биотехнологическая MindWalk Holdings уже пользуются сервисами Vultr на базе решений AMD. В общей сложности компания обслуживает «сотни тысяч» клиентов в 185 странах. 
Источник изображения: Vultr Vultr была основана в 2014 году и многие годы предлагала доступ к решениям на базе CPU. В 2021 году Vultr начала закупать GPU. В последние пару лет ИИ-инфраструктура стала самой быстрорастущей частью бизнеса компании, т.ч. теперь она обеспечивает большую часть выручки. В 2026 году бизнес намерен уделять ИИ ещё больше внимания. В прошлом году компания привлекла $333 млн, в ходе раунда, возглавленного LuminArx Capital Management и AMD, её капитализация составила $3,5 млрд. В июне 2025 года дополнительно получены $329 млн кредитного финансирования, преимущественно от JPMorgan Chase, Bank of America и Wells Fargo. В эту сумму вошли $74 млн, обеспеченных активами компании, в т.ч. ИИ-ускорителями. Vultr значительно расширила кредитную линию для финансирования кластера AMD. Разрабатывающие ИИ-инфраструктуру компании всё чаще опасаются, что отрасль ожидает формирование пузыря. Также не исключается, что ИИ-ускорителя быстро обесценятся, что тоже способно привести рынок к кризису. В Vultr уверены, что ИИ-инфраструктура всё ещё остаётся «крайне неразвитой», даже если некоторые, чрезвычайно разросшиеся на этом рынке IT-гиганты, вероятно, потерпят неудачу. Что касается времени «обесценивания» технологий, Vultr уверена, что срок службы в шесть лет для ИИ-ускорителей — «разумная, консервативная оценка».
14.11.2025 [08:56], Руслан Авдеев
Microsoft запустила второй «самый передовой» ИИ ЦОД в мире по проекту Fairwater в рамках создания ИИ-суперфабрикиMicrosoft запустила в Атланте (Джорджия) второй ИИ ЦОД по проекту Fairwater, подключенный к первому ИИ ЦОД такого типа в Висконсине для создания вычислительного суперкластера. Связь ЦОД осуществляется с помощью выделенной оптоволоконной сети AI Wide Area Network (AI WAN), специально предназначенной для выполнения ИИ-задач. Размеры и мощность нового ЦОД пока не раскрываются, но дата-центры этой серии станут крупнейшими объектами за всю историю Microsoft, а, возможно, и в мире. В дата-центре используется замкнутая система жидкостного охлаждения, которую обслуживает одна из крупнейших в мире система чиллеров. Объект поддерживает стойки мощностью порядка 140 кВт (1360 кВт на ряд). В целом он использует сотни тысяч новейших ИИ-ускорителей NVIDIA GB200/GB300 NVL72, объединённых двухуровневой 800GbE-сетью с коммутаторами под управлением SONiC. Дата-центр в Атланте имеет два этажа, чтобы сократить расстояние между стойками во всех трёх измерениях. 
Источник изображения: Microsoft Для AI WAN компания совместно с OpenAI, NVIDIA и другими партнёрами создала и внедрила протокол Multi-Path Reliable Connected (MRC) для оптимальной связи между несколькими дата-центрами класса Fairwater во время обучения сверхкрупных моделей, которые «не помещаются» в один ЦОД. Общая протяжённость каналов AI WAN составляет более 193 тыс. км. 
Источник изображения: Microsoft В Microsoft отметили, что благодаря надёжной электросети Атланты удалось отказаться от проектов локальной генерации электроэнергии, специальных ИБП и двух линий питания, что сократило время запуска ЦОД и стоимость его эксплуатации. По словам компании, им удалось добиться доступности 99,99 % по цене 99,9 %. 
Источник изображения: Microsoft Дополнительно разработаны уникальные программные и аппаратные решения для управления энергопотреблением, сглаживающие колебания нагрузок на сеть, вызванные работой ИИ, в том числе за счёт введения вспомогательных заданий во время простоя, самоограничения мощности GPU и использования накопителей энергии на площадке. 
Источник изображения: Microsoft Microsoft вводит в эксплуатацию всё больше дата-центров проекта Fairwater и намерена объединить их в целую сеть, превратив дата-центры в распределённый виртуальный суперкомпьютер, способный решать проблемы способами, недоступные отдельны объектам. Как считают в компании, если традиционный дата-центр предназначен для запуска миллионов приложений для многочисленных клиентов, то «ИИ-суперфабрика» выполняет одну сложную задачу в миллионах ускорителей.  У Microsoft стремительно растут капитальные затраты на ЦОД и ускорители. При этом топ-менеджеры Microsoft признают, что «на самом деле никто не хочет иметь дата-центр у себя на заднем дворе». Жители большинства регионов опасаются роста стоимость коммунальных услуг, ущерба экологии и др.
30.10.2025 [16:18], Руслан Авдеев
Полмиллиона ускорителей Trainium2: AWS развернула для Anthropic один из крупнейших в мире ИИ-кластеров Project RainierAWS объявила о запуске одного из крупнейших в мире ИИ-кластеров Project Rainier. Фактически амбициозный проект представляет собой распределённый между несколькими ЦОД ИИ-суперкомпьютер — это важная веха в стремлении AWS к развитию ИИ-инфраструктуры, сообщает пресс-служба Amazon. Платформа создавалась под нужды Anthropic, которая буквально на днях подписала многомиллиардный контракт на использование Google TPU. В рамках Project Rainier компания AWS сотрудничала со стартапом Anthropic. В проекте задействовано около 500 тыс. чипов Trainium2, а вычислительная мощность в пять раз выше той, что Anthropic использовала для обучения предыдущих ИИ-моделей. Project Rainier применяется Anthropic для создания и внедрения моделей семейства Claude. К концу 2025 года предполагается использование более миллиона чипов Trainium2 для обучения и инференса. В рамках Project Rainier в AWS уже создали инфраструктуру на основе Tranium2, на 70 % превосходящую любую другую вычислительную ИИ-платформу в истории AWS. Проект охватывает несколько дата-центров в США и не имеет аналогов среди инициатив AWS. Он задуман как гигантский кластер EC2 UltraCluster из серверов Trainium2 UltraServer. UltraServer объединяет четыре физических сервера, каждый из которых имеет 16 чипов Trainium2. Они взаимодействуют через фирменный интерконнект NeuronLink, обеспечивающий быстрые соединения внутри системы, что значительно ускоряет вычисления на всех 64 чипах. Десятки тысяч UltraServer объединяются в UltraCluster посредством фабрики EFA. Эксплуатация такого ЦОД требует повышенной надёжности. В отличие от большинства облачных провайдеров, AWS создаёт собственное оборудование и может контролировать каждый компонент, от чипов до систем охлаждения и архитектуру дата-центров в целом. Управляющие ЦОД команды уделяют повышенное внимание энергоэффективности, от компоновки стоек до распределения энергии и выбора методов охлаждения. Кроме того, в 2023 году вся энергия, потребляемая Amazon, полностью компенсировалась электричеством из возобновляемых источников. В Amazon утверждают, что в последние пять лет компания является крупнейшим покупателем возобновляемой энергии и стремится к достижению нулевых выбросов к 2040 году. 
Источник изображения: AWS Миллиарды долларов инвестируются в ядерную энергетику и АКБ, а также крупные проекты в области возобновляемой энергетики для ЦОД. В 2024 году компания объявила о внедрении новых компонентов для ЦОД, сочетающих технологии электропитания, охлаждения и аппаратного обеспечения, причём не только для строящихся, но и уже для имеющихся объектов. Новые компоненты, предположительно, позволят снизить энергопотребление некоторых компонентов до -46 % и сократить углеродный след используемого бетона на 35 %. 
Источник изображения: AWS Для новых объектов, строящихся в рамках Project Rainier и за его пределами, предусмотрено использование целого ряда новых технологий для повышения энергоэффективности и экоустойчивости. Некоторые технологии связаны с рациональным использованием водных ресурсов. AWS проектирует объекты так, чтобы использовать минимум воды, или вовсе не использовать её. Один из способов — отказ от её применения в системах охлаждения на многих объектах большую часть года, с переходом на охлаждение наружным воздухом. 
Источник изображения: AWS Так, один из объектов Project Rainier в Индиане будет максимально использовать именно уличный воздух, а с октября по март дата-центры вовсе не станут использовать воду для охлаждения, с апреля по сентябрь в среднем вода будет применяться по несколько часов в день. Согласно отчёту Национальной лаборатории им. Лоуренса в Беркли (LBNL), стандартный показатель WUE для ЦОД 0,375 л/кВт·ч. В AWS этот показатель равен 0,15 л/кВт·ч, что на 40 % лучше, чем в 2021 году.
21.10.2025 [21:50], Владимир Мироненко
Nebius запустила первый в Израиле ИИ ЦОД с NVIDIA HGX B200Компания Nebius объявила о доступности платформы Nebius AI Cloud в своем новом ЦОД в Израиле, запущенном на площадке в Модиине (Modiin). Сообщается, что это один из крупнейших в стране ИИ-кластеров и первый на архитектуре NVIDIA Blackwell. Кластер включает 4 тыс. ускорителей в составе HGX B200, объединённых интерконнектом NVIDIA Quantum InfiniBand, и предоставляет доступ к стеку NVIDIA AI Enterprise, в том числе к микросервисам NVIDIA NIM и инструментам управления ИИ-агентами NeMo. Запуск в Израиле последовал за аналогичными развёртываниями Nebius в Европе и США. Новая площадка объединяет передовую аппаратную и программную инфраструктуру, включая усовершенствованные системы охлаждения, системы управления энергопотреблением и механизмы управления данными, разработанные для интенсивных рабочих ИИ-нагрузок. Nebius — партнёр NVIDIA по облачным технологиям (NCP). «Запуск Nebius крупнейшего в Израиле облака ИИ на базе Blackwell знаменует собой начало развития инфраструктуры ИИ в стране», — сообщил директор представительства NVIDIA в Израиле, отметив, что благодаря суверенному доступу к передовым вычислительным, сетевым технологиям и ПО, израильские компании и разработчики смогут внедрять инновации, развёртывать и масштабировать следующее поколение агентного и физического ИИ. 
Источник изображения: Nebius Nebius входит в число первых партнёров NCP, получивших сертификат Exemplar Cloud для учебных рабочих нагрузок на базе NVIDIA H100, продемонстрировав производительность в пределах 95 % от референсной архитектуры NVIDIA. Платформа Nebius AI Cloud получила сертификацию SOC2 Type II, включая HIPAA, и обеспечивает сквозное шифрование, а также полное соответствие стандартам защиты данных GDPR и CCPA. |
|

