Материалы по тегу: кластер
|
14.10.2025 [20:58], Владимир Мироненко
Oracle анонсировала крупнейший в мире зеттафлопсный ИИ-кластер OCI Zettascale10: до 800 тыс. ускорителей NVIDIA в нескольких ЦОД
800gbe
ethernet
hardware
hpc
nvidia
oracle
oracle cloud infrastructure
stargate
ии
интерконнект
кластер
сша
цод
Oracle анонсировала облачный ИИ-кластер OCI Zettascale10 на базе сотен тысяч ускорителей NVIDIA, размещённых в нескольких ЦОД, который имеет пиковую ИИ-производительность 16 Зфлопс (точность вычислений не указана). OCI Zettascale10 — это инфраструктура, на которой базируется флагманский ИИ-суперкластер, созданный совместно с OpenAI в техасском Абилине (Abilene) в рамках проекта Stargate и основанный на сетевой архитектуре Oracle Acceleron RoCE нового поколения. OCI Zettascale10 использует NVIDIA Spectrum-X Ethernet — первую, по словам NVIDIA, Ethernet-платформу, которая обеспечивает высокую масштабируемость, чрезвычайно низкую задержку между ускорителями в кластере, лидирующее в отрасли соотношение цены и производительности, улучшенное использование кластера и надежность, необходимую для крупномасштабных ИИ-задач. Как отметила Oracle, OCI Zettascale10 является «мощным развитием» первого облачного ИИ-кластера Zettascale, который был представлен в сентябре 2024 года. Кластеры OCI Zettascale10 будут располагаться в больших кампусах ЦОД мощностью в гигаватты с высокоплотным размещением в радиусе двух километров, чтобы обеспечить наилучшую задержку между ускорителями для крупномасштабных задач ИИ-обучения. Именно такой подход выбран для кампуса Stargate в Техасе. Oracle отметила, что помимо возможности создавать, обучать и развёртывать крупнейшие ИИ-модели, потребляя меньше энергии на единицу производительности и обеспечивая высокую надёжность, клиенты получат свободу работы в распределённом облаке Oracle со строгим контролем над данными и суверенитетом ИИ. 
Источник изображения: OpenAI Изначально кластеры OCI Zettascale10 будут рассчитаны на развёртывание до 800 тыс. ускорителей NVIDIA, обеспечивая предсказуемую производительность и высокую экономическую эффективность, а также высокую пропускную способность между ними благодаря RoCEv2-интерконнекту Oracle Acceleron со сверхнизкой задержкой. Acceleron предлагает 400G/800G-подключение со сверхнизкой задержкой, двухуровневую топологию, множественное подключение одного NIC к нескольким коммутатором с физической и логической изоляцией сетевых потоков, поддержку LPO/LRO и гибкость конфигурации. DPU Pensando от AMD в Acceleron место тоже нашлось. 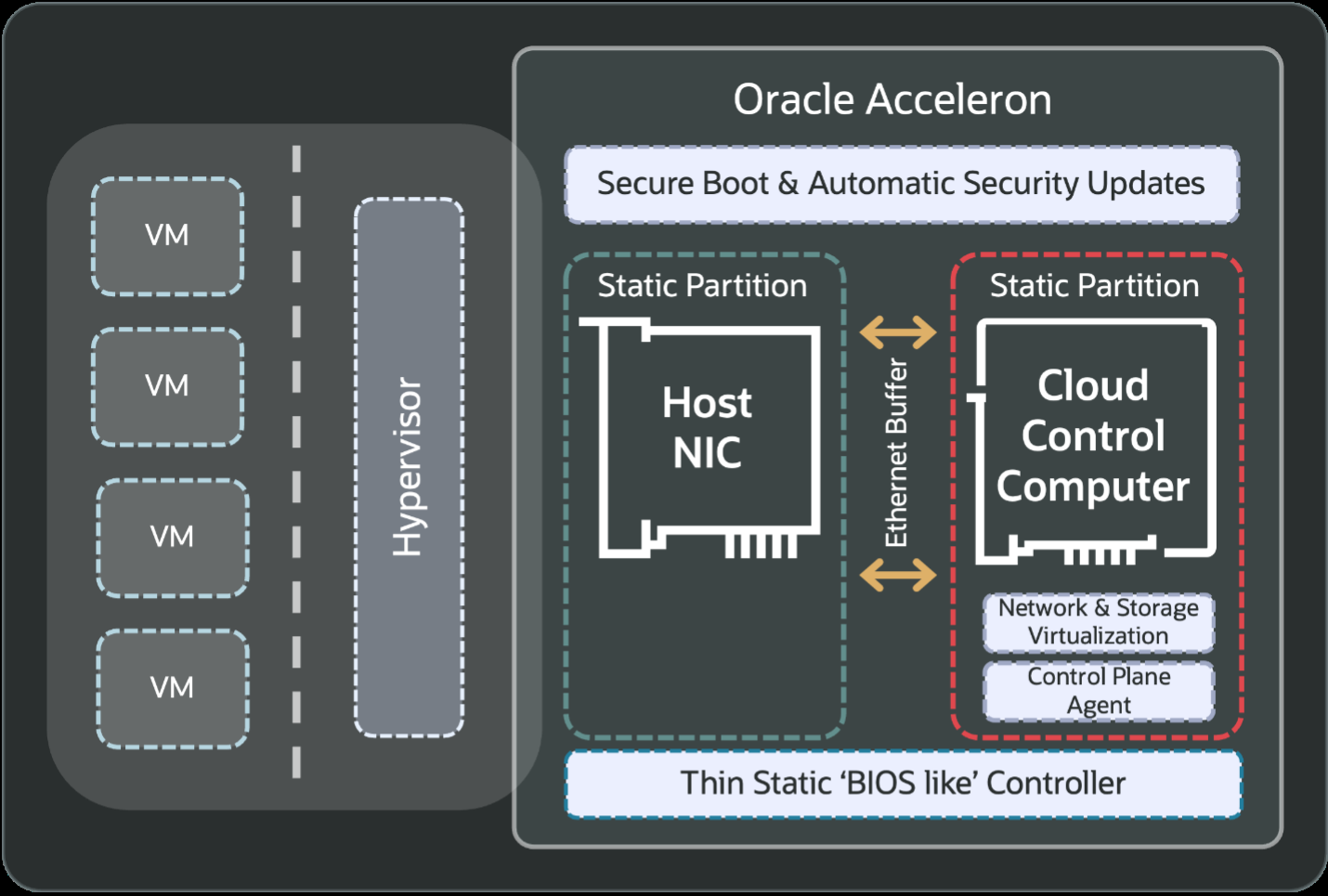
Источник изображения: Oracle OCI уже принимает заказы на OCI Zettascale10, который поступит в продажу во II половине следующего календарного года. В августе NVIDIA анонсировала решение Spectrum-XGS Ethernet для объединения нескольких ЦОД в одну ИИ-суперфабрику, которым, по-видимому, воспользуется не только Oracle, но и Meta✴.
03.10.2025 [17:24], Руслан Авдеев
UKPN начнёт отапливать дома британских малоимущих кластерами из сотен Raspberry Pi
hardware
raspberry pi
великобритания
кластер
микро-цод
облако
отопление
периферийные вычисления
погружное охлаждение
сжо
экология
Британская UK Power Networks (UKPN) в рамках программы SHIELD (Smart Heat and Intelligent Energy in Low-income Districts) начала устанавливать микро-ЦОД на базе одноплатных компьютеров Raspberry Pi — для отопления домохозяйств, нуждающихся в деньгах для оплаты коммунальных услуг, сообщает The Register. Выбранные домохозяйства оснастят солнечными элементами питания и аккумуляторными системами, треть из них получит и систему HeatHub — сверхкомпактный ЦОД размером с большой тепловой насос, который заменит традиционные газовые котлы. Полученные в рамках пробного развёртывания данные используют для масштабирования SHIELD, к 2030 году UKPN намерена ежегодно развёртывать 100 тыс. систем. Платформа HeatHub разработана компанией Thermify. Она предназначена для запуска облачных контейнеризированных нагрузок. Каждый HeatHub включает до 500 модулей Raspberry Pi CM4 или CM5, погружённых в масло. Полученное тепло передаётся в системы отопления и горячего водоснабжения, а сам HeatHub легко установить вместо бойлера. HeatHub имеет собственное выделенное интернет-подключение. Над внедрением «низкоуглеродных» технологий SHIELD компания UKPN сотрудничает с Power Circle Projects, жилищной ассоциацией Eastlight Community Homes и Essex Community Energy. Также она участвует над установлением нового социального тарифа на отопление на востоке и юго-востоке Англии. Малоимущие клиенты будут платить фиксированную ставку в £5,60 ($7,52) ежемесячно, а SHIELD поможет им сократить счета за электричество на 20–40 %. 
Источник изображения: Thermify Куратор SHIELD со стороны Eastlight Community Homes заявил, что результаты пилотного проекта обнадёживают, его планируют опробовать ещё в сотнях домов. Это поможет семьям поддерживать комфортные условия проживания, не беспокоясь о росте цен на энергию. Для обычных пользователей у Thermify иные условия — модуль для типового дома с тремя спальнями обойдётся в £2500 ($3365), ещё £500 ($673) возьмут за установку, а за отопление будут брать £50/мес. ($67/мес.). В особых случаях плата может быть снижена вдвое, а в экстремальных ситуациях тепло будет предоставляться бесплатно. Это уже не первый проект подобного рода. Так, Heata — изначально принадлежавшая British Gas, предлагает использовать серверы в качестве домашних водонагревателей, что позволяет сократить расходы на электричество для домовладельцев. Тепло вырабатывается за счёт рабочих нагрузок облачного оператора Civo. Также пару лет назад начала работать британская Deep Green — она обеспечивает теплом предприятия и бассейны с помощью мини-ЦОД, размещаемых на их территории.
29.09.2025 [14:00], Руслан Авдеев
315 млн ИИ-ядер и 1,4 квадрлн транзисторов: Cerebras открыла в США 10-МВт ЦОД на царь-чипах WSE-3Разработчик ИИ-ускорителей Cerebras Systems развернул новый дата-центр в Оклахома-Сити — столице штата Оклахома (США). Объект мощностью 10 МВт создан совместно со Scale Datacenters, сообщает Datacenter Dynamics. На объекте применяются замкнутые системы прямого жидкостного охлаждения. По данным компании, каждый потреблённый киловатт-час компенсируется покупкой энергии из возобновляемых источников. По словам представителя Cerebras, в 2023 году компания построила свой первый ИИ-суперкомпьютер Andromeda с 13,5 млн ИИ-ядер, на тот момент — крупнейший в своём роде. Новый кластер в Оклахома-Сити на базе систем CS-3 с царь-чипами WSE-3 обеспечивает ИИ-производительность 44 Эфлопс (точность вычислений не указана) и поддерживает крупнейшие из когда-либо созданных ИИ-моделей. Кластер включает 315 млн ИИ-ядер и 1,4 квадрлн транзисторов. 
Источник изображений: Cerebras Scale Datacenter подготовила для Cerebras саму площадку и сопутствующую инфраструктуру. В Scale подчеркнули, что рады сотрудничеству с Cerebras, оно позволит создать в Оклахома-Сити ИИ-инфраструктуру мирового класса. В мае 2025 года появилась информация о покупке Scale Datacenter ЦОД площадью 7,6 тыс. м2 в Оклахома-Сити у компании Expand Energy.  Ранее Cerebras объявила о намерении запустить шесть новых ИИ ЦОД в Северной Америке и Европе, в том числе с использованием более 300 систем CS-3 на объекте в Оклахома-Сити. У Cerebras есть кластеры для инференса в Санта-Кларе (Santa Clara) и Стоктоне (Stockton) в Калифорнии, последний расположен на барже-ЦОД Nautilus. Также имеется объект в Далласе (Dallas, Техас). Компания занимается созданием собственных кластеров в Миннеаполисе (Minneapolis, Миннесота), Монреале (Montreal, Канада — на объекте Bit Digital), а также в некоторых локациях на Среднем Западе США и в Европе. Cerebras уже разместила оборудование в Эдинбургском университете, Сандийских национальных лабораториях (США), лабораториях Лос-Аламоса, мощностях G42/Core42, и др.
26.09.2025 [10:33], Руслан Авдеев
Media Stream AI построит в Манчестере 2-МВт ИИ ЦОД с охлаждением водой из местного каналаБританская медиакомпания Media Stream AI (MSAI) намерена открыть в Солфорде (Salford, Большой Манчестер) дата-центр в популярном «творческом» районе Media City. Объект мощностью 2 МВт будет использовать для охлаждения воду из канала Рочдейл (Rochdale), сообщает Datacenter Dynamics. Система охлаждения будет состоять из замкнутого контура с теплообменниками и драйкулеров. При поддержке Lenovo объект стоимостью £50 млн ($67,3 млн) сможет обеспечить плотность стоек на уровне 30–60 кВт при PUE менее 1,2. На площадке планируется разместить 1,1 тыс. ускорителей NVIDIA H200 в составе серверов Lenovo ThinkSystem с СЖО Neptune. В будущем возможно расширение до 2,3 тыс. ускорителей. Объект должен заработать в I квартале 2026 года. Компания намерена создать там же собственную виртуальную продакшн-студию и робототехническую лабораторию. Media Stream AI рассчитывает предоставлять ИИ-сервисы медиакомпаниям и работникам творческих профессий. На сайте стартапа объявлено, что он намерен предоставить доступ к ускорителям NVIDIA L4, A10G, A4000, A5000, A100, H100 и L40. Также компания намерена развернуть к концу 2026 года площадки в Германии и Франции. Более того, MSAI заключила соглашение с властями Ямайки о строительстве и эксплуатации первого на острове ИИ ЦОД. 
Источник изображения: Jonny Gios/unsplash.com Прецеденты использования похожих систем охлаждения есть. Например, Digital Realty использует для охлаждения ЦОД во Франции и Великобритании проточную речную воду. Green Mountain намерена развернуть систему охлаждения речной водой на своём новом объекте в Германии. Речное охлаждение также используют Denv-R во Франции и Nautilus в Калифорнии. Наконец, сеть европейских супермаркетов Lidl объявила, что один из её ЦОД в Германии тоже использует охлаждение речной водой, а норвежский оператор дата-центров Polar утверждает, что для охлаждения одного из своих ЦОД намерен использовать близлежащую реку. Участвуют в подобных проектах и гиперскейлеры. Площадка Google в Финляндии использует для охлаждения и морскую воду.
19.09.2025 [14:44], Руслан Авдеев
Meta✴ свернула работу пяти действующих ЦОД, чтобы сделать из них один крупный ИИ-кластерКомпания Meta✴ создала крупный ИИ-кластер из 129 тыс. ускорителей NVIDIA H100, использующий пять расположенных близко к друг другу ЦОД. Для его создания она переместила из дата-центров имевшиеся стойки, сообщает Datacenter Dynamics. По словам компании, сворачивать работу действующих ЦОД невероятно дорого, поскольку речь идёт об уже сделанных крупных инвестициях. Кроме того, эти дата-центры обслуживали актуальные рабочие нагрузки, так что пришлось отключать их настолько быстро, насколько это возможно, при этом стараясь не вызывать заметных пользователям сбоев. Для того, чтобы проделать все работы быстро, пришлось переделать погрузочные платформы в дата-центрах. Более того, построили новых роботов для перемещения стоек массой более 400 кг и даже переделала упаковку для самих стоек, чтобы ускорить перемещения. Сеть в ЦОД разрослась вчетверо, для чего пришлось даже прорыть новые коммуникационные траншеи, чтобы связать пять зданий в единую высокоскоростную сеть. Все эти работы были выполнены всего за несколько месяцев. 
Источник изображения: Glenov Brankovic/unsplash.com Объясняется, что решение о создании суперкластера на основе действующих ЦОД было принято, поскольку у существующих площадок было достаточно энергетических мощностей для столь большого проекта. Компания не раскрыла местоположения нового ИИ-кластера и признала, что её знания и многолетний опыт создания крупных IT-систем, в том числе дата-центров, из-за стремительного прогресса ИИ устарели. Теперь Meta✴ готова инвестировать «сотни миллиардов долларов в вычисления. Гигаваттный кластер Prometheus должен заработать в следующем году, а Hyperion на 5 ГВт должны ввести в эксплуатацию до конца десятилетия.
06.08.2025 [10:10], Сергей Карасёв
Кластер на ладони: Sipeed NanoCluster позволяет объединять до семи модулей Raspberry Pi CM4/CM5Компания Sipeed, по сообщению CNX-Software, начала продажи изделия NanoCluster — специализированной платы, которая позволяет формировать мини-кластеры на основе таких вычислительных модулей (SoM), как Raspberry Pi CM4, Raspberry Pi CM5, Sipeed LM3H, Sipeed M4N и др. Новинка оснащена семью сдвоенными коннекторами M.2 M-Key для подключения SoM. В случае CM4, CM5 и M4N установка осуществляется через специальные адаптеры, на обратной стороне которых имеется слот для SSD в форм-факторе M.2 с интерфейсом PCIe. Таким образом, в максимальной конфигурации могут быть объединены до семи вычислительных модулей и до семи твердотельных накопителей. 
Источник изображения: CNX-Software NanoCluster располагает интерфейсом HDMI (подключён к слоту №1), сетевым портом 1GbE (RJ45), двумя портами USB 2.0 Type-A, а также разъёмом USB Type-C PD (до 60 Вт). За обмен данными между вычислительными модулями отвечает 8-портовый коммутатор JL6108 Gigabit Ethernet на базе RISC-V. Опционально может быть реализована поддержка PoE с бюджетом мощности 60 Вт. Предусмотрен 2-контактный коннектор для вентилятора охлаждения диаметром 60 мм. Размеры платы NanoCluster составляют 88 × 57 мм, а полная сборка с установленными SoM и кулером имеет габариты 100 × 60 × 60 мм. Несмотря на наличие семи слотов, при работе с Raspberry Pi CM5 рекомендуется использовать только четыре–пять модулей из-за проблем с питанием и охлаждением, особенно при подключении M.2 SSD. В частности, может наблюдаться троттлинг. Мини-кластер подходит для обучения и экспериментов с распределёнными и периферийными вычислениями, Kubernetes, Docker и пр. Цена собственно платы NanoCluster составляет около $50, а, например, комплект с четырьмя модулями Sipeed M4N обойдётся в $700.
28.07.2025 [13:35], Сергей Карасёв
Huawei представила ИИ-систему CloudMatrix 384 — конкурента NVIDIA GB200 NVL72Компания Huawei, по сообщению Reuters, представила на Всемирной конференции по искусственному интеллекту (WAIC) в Шанхае (Китай) систему CloudMatrix 384 для ресурсоёмких ИИ-нагрузок. Участники ранка рассматривают эту платформу в качестве прямого конкурента NVIDIA GB200 NVL72. Информация о характеристиках CloudMatrix 384 появилась в апреле нынешнего года: система объединяет 384 ускорителя Huawei Ascend 910C. Для сравнения: NVIDIA GB200 NVL72 содержит в одной стойке 18 узлов 1U, каждый из которых включает два ускорителя GB200 — в сумме это даёт 72 чипа B200 и 36 процессоров Grace. Быстродействие CloudMatrix 384 достигает 300 Пфлопс (BF16) против 180 Пфлопс у NVIDIA GB200 NVL72. Кроме того, решение Huawei в 3,6 раза превосходит конкурирующую платформу по объёму памяти HBM и в 2,1 раза по пропускной способности памяти. Однако для достижения таких показателей потребовалось в пять с лишним раз больше ускорителей. Таким образом, по производительности и энергоэффективности отдельные карты Ascend 910C существенно уступают изделиям NVIDIA GB200. 
Источник изображения: MyDrivers По данным сетевых источников, на коммерческий рынок система CloudMatrix 384 может поступить под именем Atlas 900 A3 SuperPoD. Компания Huawei, не вдаваясь в подробности, отмечает, что машина использует архитектуру «суперузлов», которая позволяет ИИ-ускорителям взаимодействовать на сверхвысоких скоростях. Обещаны ультранизкие задержки. Выход системы призван укрепить позиции Китая в сфере ИИ на фоне американских санкций. Власти США наложили запрет на поставки в КНР передовых решений в сфере ИИ. Тем не менее, за три месяца действия новых правил по ужесточению контроля над экспортом таких ускорителей в Китай всё равно попали изделия NVIDIA на сумму не менее $1 млрд. А сама компания NVIDIA между тем рассчитывает возобновить отгрузки ИИ-ускорителей H20 китайским заказчикам.
25.07.2025 [17:41], Сергей Карасёв
SoftBank развернула крупнейшую в мире ИИ-платформу на базе NVIDIA DGX B200Японский холдинг SoftBank объявил о расширении вычислительной ИИ-инфраструктуры на платформе NVIDIA DGX SuperPOD: развёрнуты системы DGX B200, насчитывающие в общей сложности 4 тыс. ускорителей поколения Blackwell. О планах SoftBank по созданию первого в мире ИИ-суперкомпьютер на базе NVIDIA DGX B200 стало известно в конце прошлого года. Вычислительная система использует интерконнект Quantum-2 InfiniBand и поддерживается программной платформой NVIDIA AI Enterprise. Холдинг SoftBank изначально внедрил DGX SuperPOD с более чем 2 тыс. ускорителями поколения NVIDIA Ampere в сентябре 2023 года: на тот момент производительность достигала 0,7 Эфлопс на операциях ИИ (точность вычислений не раскрывается). В октябре 2024 года завершился первый этап модернизации, в ходе которого были добавлены 4000 ускорителей семейства NVIDIA Hopper. В результате, суммарное быстродействие поднялось до 4,7 Эфлопс. После установки DGX B200 показатель вырос до 13,7 Эфлопс. 
Отмечается, что на сегодняшний день новая вычислительная инфраструктура SoftBank является крупнейшей в мире ИИ-платформой на основе DGX B200. При этом в общей сложности задействованы свыше 10 тыс. ускорителей. Изначально систему будет использовать SB Intuitions Corp. — дочерняя структура SoftBank, которая специализируется на разработке собственных больших языковых моделей (LLM), адаптированных для Японии. SB Intuitions уже создала LLM с примерно 460 млрд параметров, а в текущем 2025 финансовом году, который заканчивается 31 марта 2026-го, компания планирует представить коммерческую ИИ-модель Sarashina mini с 70 млрд параметров. Нужно отметить, что ранее SoftBank и OpenAI объявили о формировании совместного предприятия SB OpenAI для развития корпоративных ИИ-сервисов в Японии. Кроме того, SoftBank участвует в мегапроект Stargate — это совместное предприятие с OpenAI и Oracle по развитию ИИ-инфраструктуры в США. Предполагается, что суммарные затраты на реализацию Stargate достигнут $500 млрд. Впрочем, пока проект продвигается с большим трудом.
22.06.2025 [23:30], Руслан Авдеев
Meta✴ ведёт переговоры о покупке венчурного фонда NFDG, у которого есть собственный ИИ-кластер AndromedaMeta✴ Platforms решила обновить свои компетенции в сфере ИИ, наняв ведущих отраслевых игроков — Ната Фридмана (Nat Friedman) и Дэниэла Гросса (Daniel Gross). Также компания намерена выкупить их венчурный фонд NFDG, сообщает The Information. Марк Цукерберг (Mark Zuckerberg) сначала пытался купить ИИ-стартап Safe Superintelligence (SSI) бывшего «главным учёным» OpenAI Ильи Суцкевера (Ilya Sutskever). После отказа Цукерберг попросту собрался нанять генерального директора SSI — Гросса. Ранее тот руководил ИИ-разработками в Apple и был партнёром Y Combinator. Фридман был главой GitHub и советником Midjourney. Гросс и Фридман были соучредителями инвестиционного фонда NFDG. NFDG имеет доли в в известных ИИ-компаниях, включая SSI, Perplexity и Character.ai. Ранее компания инвестировала в Weights & Biases, которую приобрела CoreWeave. NFDG занимается не только финансированием компаний, но и предлагает программу грантов, в рамках которой стартапам предоставляется финансирование на $250 тыс., а также $250 тыс. в виде облачных кредитов Microsoft Azure. В период дефицита ИИ-ускорителей NFDG построил собственный суперкомпьютер. Кластер Andromeda изначально включал 2512 ускорителей NVIDIA H100. С тех пор он вырос до 3 200 H100 в 400 узлах и ещё 432 H100 в 54 узлах, связанных 400G-интерконнектом InfiniBand, а также 768 A100 с 200G InfiniBand. Теперь Andromeda могут арендовать и компании, которые не относятся к NFDG, за $2,4–$3 за ускоритель в час. Сейчас можно арендовать до 2 тыс. H100 и получить доступ к ним в течение нескольких часов. 
Источник изображения: Amina Atar/unspalsh.com Помимо возможного найма Гросса и Фридмана, Meta✴ ведёт переговоры, конечной целью которых является выкуп значительной части активов NFDG и вывод из него партнёров за сумму более $1 млрд. При этом сделка не даст Meta✴ контроля над фондом или информации о бизнесе. Кому достанется Andromeda, не уточняется. Если сделка будет завершена, она войдёт в число более масштабных реформ в Meta✴, связанных с ИИ. Цукерберг планирует сформировать новую лабораторию по разработке «суперинтеллекта» и пересмотреть стратегию выкупа продуктов. В этом месяце Meta✴ уже подтвердила, что намерена потратить порядка $14 млрд на долю в Scale AI, специализирующейся на разметке данных для обучения ИИ.
17.04.2025 [00:10], Владимир Мироненко
Суперускоритель Huawei CloudMatrix 384 оказалася быстрее NVIDIA GB200 NVL72, но значительно прожорливееHuawei анонсировала на конференции Huawei Cloud Ecosystem Conference 2025 собственный суперускоритель CloudMatrix 384, который позиционируется в качестве отечественной альтернативы системы NVIDIA GB200 NVL72. Решение Huawei отличается более высокой общей производительностью — 300 Пфлопс против 180 Пфлопс. Но в то же время оно уступает решению NVIDIA по производительности на чип и имеет значительно более высокое энергопотребление, пишет SemiAnalysis. Система Huawei CloudMatrix 384 использует 384 ускорителя Huawei Ascend 910C, в то время как в GB200 NVL72 задействовано 36 процессоров Grace в сочетании с 72 ускорителями B200 (Blackwell). То есть, чтобы вдвое превзойти по производительности GB200 NVL72, потребовалось примерно в пять раз больше ускорителей Ascend 910C, что не очень хорошо с точки зрения использования самих ускорителей, но отлично на уровне развёртывания системы, отметил ресурс SemiAnalysis. Как утверждает SemiAnalysis, Huawei отстает от NVIDIA на поколение по производительности чипов, но опережает в проектировании и развёртывании масштабируемых систем. 
Источник изображения: TechPowerUp Если сравнивать отдельные ускорители, то NVIDIA GB200 явно превосходит Huawei Ascend 910C, обеспечивая более чем в три раза большую производительность в вычислениях в формате BF16 (2500 против 780 Тфлопс) и больший HBM на чипе (192 против 128 Гбайт) с более высокой пропускной способностью памяти (ПСП, 8 против 3,2 Тбайт/с). Другими словами, у NVIDIA есть преимущество в чистой мощности и на уровне чипа. Но на уровне системы эффективность CloudMatrix CM384 выходит вперёд. Он выдаёт в 1,7 раза больше Пфлопс, имеет в 3,6 раз больше HBM, обеспечивает в 2,1 раза большую ПСП и объединяет более чем в пять раз больше ускорителей, чем GB200 NVL72. Однако эта масштабируемость имеет обратную сторону, поскольку система Huawei потребляет почти в четыре раза больше энергии — 145 кВт против ~560 кВт. Для Huawei CloudMatrix 384 требуется в 3,9 раза больше энергии, чем для GB200 NVL72: в 2,3 раза больше энергии на 1 флопс, в 1,8 раза — на 1 Тбайт/с ПСП и в 1,1 раза — на 1 Тбайт HBM. SCMP со ссылкой на данные самой Huawei сообщает, что CloudMatrix CM384 показал производительность на уровне 800 Пфлопс в BF16-вычислениях без разреженности или 1920 токенов/с на модели DeepSeek-R1. Суперускоритель размещается в 16 стойках, из которых четыре отведено только под интерконнект — всего 6912 400G-порта. Остальные стойки содержат по 32 ускорителя Ascend 910C в четырёх узлах (8×4) и ToR-коммутатор. Как отметил SemiAnalysis, было бы заблуждением говорить, что Ascend 910C и CloudMatrix 384 производятся в Китае: HBM в них от Samsung, пластины от TSMC, а само оборудование из США, Нидерландов и Японии. Хотя у китайской SMIC уже есть 7-нм техпроцесс, подавляющее большинство Ascend 910B/910C было втайне сделано по 7-нм технологии TSMC. Предполагается, что Huawei смогла обойти санкции США, заказав чипы на $500 млн при посредничестве Sophgo. Сама TSMC прекратила поставки Huawei в 2020 году. |
|

