После того, как ИИ-индустрия немного отошла от шока, вызванного неожиданным триумфом китайской DeepSeek, эксперты пришли к выводу, что отрасли, возможно, придётся пересмотреть методики обучения моделей. Так, исследователи DeepMind заявили о модернизации распределённого обучения, сообщает The Register.
Недавно представившая передовые ИИ-модели DeepSeek вызвала некоторую панику в США — компания утверждает, что способна обучать модели с гораздо меньшими затратами, чем, например, OpenAI (что оспаривается), и использованием относительно небольшого числа ускорителей NVIDIA. Хотя заявления компании оспариваются многими экспертами, индустрии пришлось задуматься — насколько эффективно тратить десятки миллиардов долларов на всё более масштабные модели, если сопоставимых результатов можно добиться в разы дешевле, с использованием меньшего числа энергоёмких ЦОД.
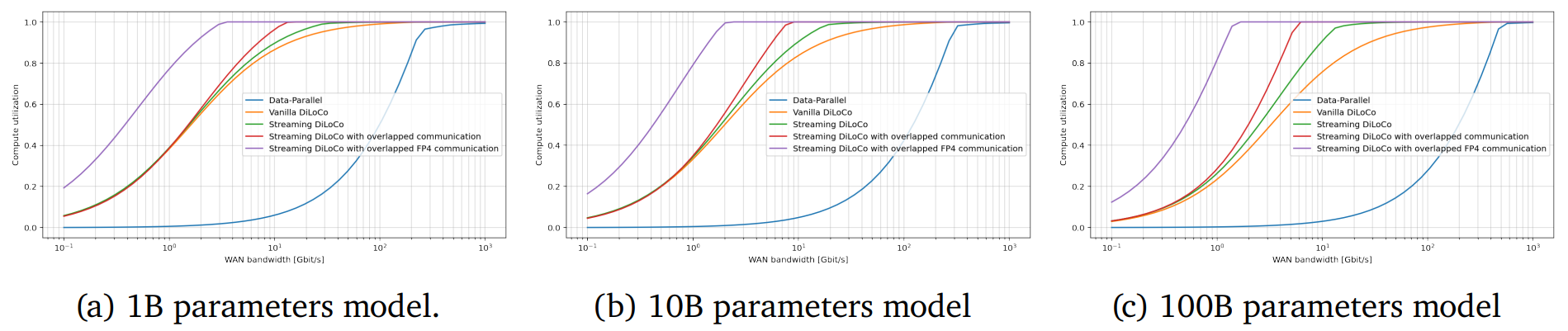
Дочерняя структура Google — компания DeepMind опубликовала результаты исследования, в котором описывается методика распределённого обучения ИИ-моделей с миллиардами параметров с помощью удалённых друг от друга кластеров при сохранении необходимого уровня качества обучения. В статье «Потоковое обучение DiLoCo с перекрывающейся коммуникацией» (Streaming DiLoCo with overlapping communication) исследователи развивают идеи DiLoCo (Distributed Low-Communication Training или «распределённое обучение с низким уровнем коммуникации»). Благодаря этому модели можно будет обучать на «островках» относительно плохо связанных устройств.

Источник изображения: Igor Omilaev/unsplash.com
Сегодня для обучения больших языковых моделей могут потребоваться десятки тысяч ускорителей и эффективный интерконнект с большой пропускной способностью и низкой задержкой. При этом расходы на сетевую часть стремительно растут с увеличением числа ускорителей. Поэтому гиперскейлеры вместо одного большого кластера создают «острова», скорость сетевой коммуникации и связность внутри которых значительно выше, чем между ними.
DeepMind же предлагает использовать распределённые кластеры с относительно редкой синхронизацией — потребуется намного меньшая пропускная способность каналов связи, но при этом без ущерба качеству обучения. Технология Streaming DiLoCo представляет собой усовершенствованную версию методики с синхронизацией подмножеств параметров по расписанию и сокращением объёма подлежащих обмену данных без потери производительности. Новый подход, по словам исследователей, требует в 400 раз меньшей пропускной способности сети.
Источник изображения: DeepMind
Важность и потенциальную перспективность DiLoCo отмечают, например, и в Anthropic. В компании сообщают, что Streaming DiLoCo намного эффективнее обычного варианта DiLoCo, причём преимущества растут по мере масштабирования модели. В результате допускается, что обучение моделей в перспективе сможет непрерывно осуществляться с использованием тысяч разнесённых достаточно далеко друг от друга систем, что существенно снизит порог входа для мелких ИИ-компаний, не имеющих ресурсов на крупные ЦОД.
В Gartner утверждают, что методы, уже применяемые DeepSeek и DeepMind, уже становятся нормой. В конечном счёте ресурсы ЦОД будут использоваться всё более эффективно. Впрочем, в самой DeepMind рассматривают Streaming DiLoCo лишь как первый шаг на пути совершенствования технологий, требуется дополнительная разработка и тестирование. Сообщается, что возможность объединения многих ЦОД в единый виртуальный мегакластер сейчас рассматривает NVIDIA, часть HPC-систем которой уже работает по схожей схеме.
Источник:

