Лента новостей
|
22.05.2021 [00:39], Владимир Мироненко
Microsoft будет использовать дождевую воду для охлаждения ЦОД из-за протестов голландских фермеровСтроительство нового дата-центра Microsoft в Холландс-Крон (Hollands Kroon), общине в нидерландской провинции Северная Голландия, вызвало противодействие местных жителей, узнавших о том, что такие объекты могут вызвать нехватку питьевой воды. В связи с этим Организация сельского хозяйства и садоводства (LTO), представляющая интересы более 35 000 сельскохозяйственных предпринимателей, обжаловала выдачу разрешение Microsoft. По данным газеты De Telegraaf, принадлежащие Microsoft и Google дата-центы на территории бизнес-парка Agriport A7 используют 525 м3 питьевой воды в час, что составляет 4,6 млн м3 в год, а для реализации планов по строительству пяти новых объектов потребуется ещё 10 млн м3 воды в год. Как сообщает De Telegraaf, внутренние документы муниципалитета предупреждают, что при экстремальных погодных условиях может возникнуть нехватка пресной воды. Согласно ресурсу Hortidaily, в ответ на критику Microsoft сообщила телеканалу EenVandaag, что она будет охлаждать свои ЦОД дождевой водой, а излишки отдавать местным теплицам. Microsoft обратилась за помощью к компании ECW Energy, которая уже пятнадцать лет занимается вопросами использования дождевой воды. По словам Роберта Кильстра (Robert Kielstra) из ECW Energy, Microsoft требуется лишь около 30 % всего объёма воды, который она могла бы собрать на своих объектах в Agriport для охлаждения, а оставшуюся часть можно было бы поставлять в теплицы. 
Фото: Microsoft Вода в Нидерландах очень дешёвая, и сбор и поставки дождевой воды обойдётся Microsoft гораздо дороже её потребления, но компания предпочла выбрать этот путь, чтобы избавиться от давления со стороны властей и жителей региона — в связи с жалобой фермеров Microsoft потенциально может столкнуться с судебным разбирательством. В настоящее время компания строит свой второй центр обработки данных в Холландс-Крон. Когда речь заходит об экологичности дата-центров, то чаще всего говорят об их энергопотреблении и о переходе на «зелёные» источники энергии. Однако потребление чистой и отвод или очистка отработанной воды ЦОД — не менее острый вопрос. В США Microsoft профинансировала создание установки для очистки и повторного использования воды в её дата-центрах в Массачусетсе, а в Аризоне корпорация строит новый, дружественный к экологии облачный регион. Здесь, согласно планам, к 2030 году Microsoft будет отдавать большей чистой воды, чем потребляет сама.
20.05.2021 [00:35], Владимир Агапов
Google начала перемещать нагрузки между ЦОД для более полного использования «зелёной» энергииВ соответствии с принятой Google стратегией по углеродно-нейтральному статусу своих дата-центров, компания планирует к 2030 году полностью перейти на возобновляемые источники электроэнергии. Сложность перехода заключается в том, что многие такие источники работают не постоянно и зависят от погодных условий и времени суток. Google решает эту проблему, перемещая «подвижные» задачи между ЦОД в разных регионах в зависимости от текущего уровня доступности в них «зелёной» энергии. К «подвижным» Google относит такие задачи, которые не критичны к задержкам или к требованиям национальных законодательств о суверенитете данных. Это, в первую очередь, кодирование, анализ и обработка мультимедийных файлов, загружаемых в YouTube, Google Photos и Gоogle Drive. А вот нагрузки клиентов Google Cloud остаются в том ЦОД, в котором они были запущены. 
Фото: Google Перемещение данных между дата-центрами в режиме реального времени требует сложного ПО и большого запаса пропускной способности. Распределение нагрузки между регионами происходит с помощью интеллектуальной платформы Google, которая составляет прогнозы на день вперёд: насколько сильно тот или иной ЦОД будет нуждаться в электроэнергии из традиционных источников, каковы средняя почасовая «углеродоемкость» местной электросети и ее изменения в течение дня. На основе этих данных система перераспределяет нагрузку на ЦОД, расположенных в регионах с временным избытком «зелёной» энергии. При этом такие перемещения остаются прозрачными и незаметными для конечных пользователей — они могут продолжать выполнять необходимые им задачи (смотреть потоковое видео, загружать фотографии, пользоваться картами и т.д.) в обычном режиме. 
Фото: Google Google заявила, что поделится своей методологией и результатами работы с отраслью в ближайших научных публикациях. «Мы надеемся, что наши результаты вдохновят другие организации на развертывание собственных версий платформы, учитывающей углеродные выбросы, и вместе мы сможем стимулировать переход к экологически чистой энергетике во всем мире», — заявили в компании. В прошлом году компания Microsoft также объявила о планах по снижению выбросов углекислого газа к 2030 году и начала отслеживать влияние на климат своих поставщиков, а Amazon и Apple закупили значительное количество возобновляемой энергии для своих центров обработки данных. Сама же Google пытается освоить новые источники «зелёные» энергии — геотермальные.
17.05.2021 [18:26], Сергей Карасёв
Иран запустил Simurgh, свой самый мощный суперкомпьютерВ Иране введён в эксплуатацию самый мощный в стране вычислительный комплекс: система получила название Simurgh — в честь фантастического существа в иранской мифологии, царя всех птиц. Суперкомпьютер разработан специалистами Технологического университета имени Амира Кабира (Amirkabir University of Technology). Смонтирована система в Иранском исследовательском центре высокопроизводительных вычислений (IHPCRC). В настоящее время быстродействие комплекса составляет 0,56 Пфлопс. В дальнейшем мощность суперкомпьютера планируется довести до 1 Пфлопс — на доработку системы потребуется около двух месяцев. Конфигурация суперкомпьютера не раскрывается, а появление его в публичных рейтингах производительности вряд ли стоит ожидать. 
Суперкомпьютер Simurgh. Фото: Maryam Kamyab / MEHR Новый суперкомпьютер, по словам представителей власти, по мощности приблизительно в 100 раз превосходит системы высокопроизводительных вычислений, до сих пор применявшиеся в Иране. Система будет использоваться для задач в области генетики, Big Data, ИИ, интернета вещей и так далее. Часть мощностей будет выделена для облачных систем. 
Суперкомпьютер Simurgh. Фото: Maryam Kamyab / MEHR Интернет-источники отмечают, что Simurgh, по всей видимости, построен с использованием комплектующих, приобретённых на «чёрном» рынке, поскольку официально Иран не может закупать многие современные технологии из-за санкций — несколько лет назад ZTE получила крупный штраф из-за нелегальных поставок оборудования в страну. Тем не менее, Ирану периодически удаётся получить необходимые компоненты: в начале века был построен кластер из Pentium III/IV, а в 2007 году был построен суперкомпьютер на базе AMD Opteron.
15.04.2021 [21:24], Игорь Осколков
DPU BlueField — третий столп будущего NVIDIAВо время открытия GTC’21 наибольшее внимание привлёк, конечно, анонс собственного серверного Arm-процессора NVIDIA — Grace. Говорят, из-за этого даже акции Intel просели, хотя в последних решениях самой NVIDIA процессоры x86-64 были нужны уже лишь для поддержки «обвязки» вокруг непосредственно ускорителей. Да, теперь у NVIDIA есть три точки опоры, три столпа для будущего развития: GPU, DPU и CPU. Причём расположение их именно в таком порядке неслучайно. 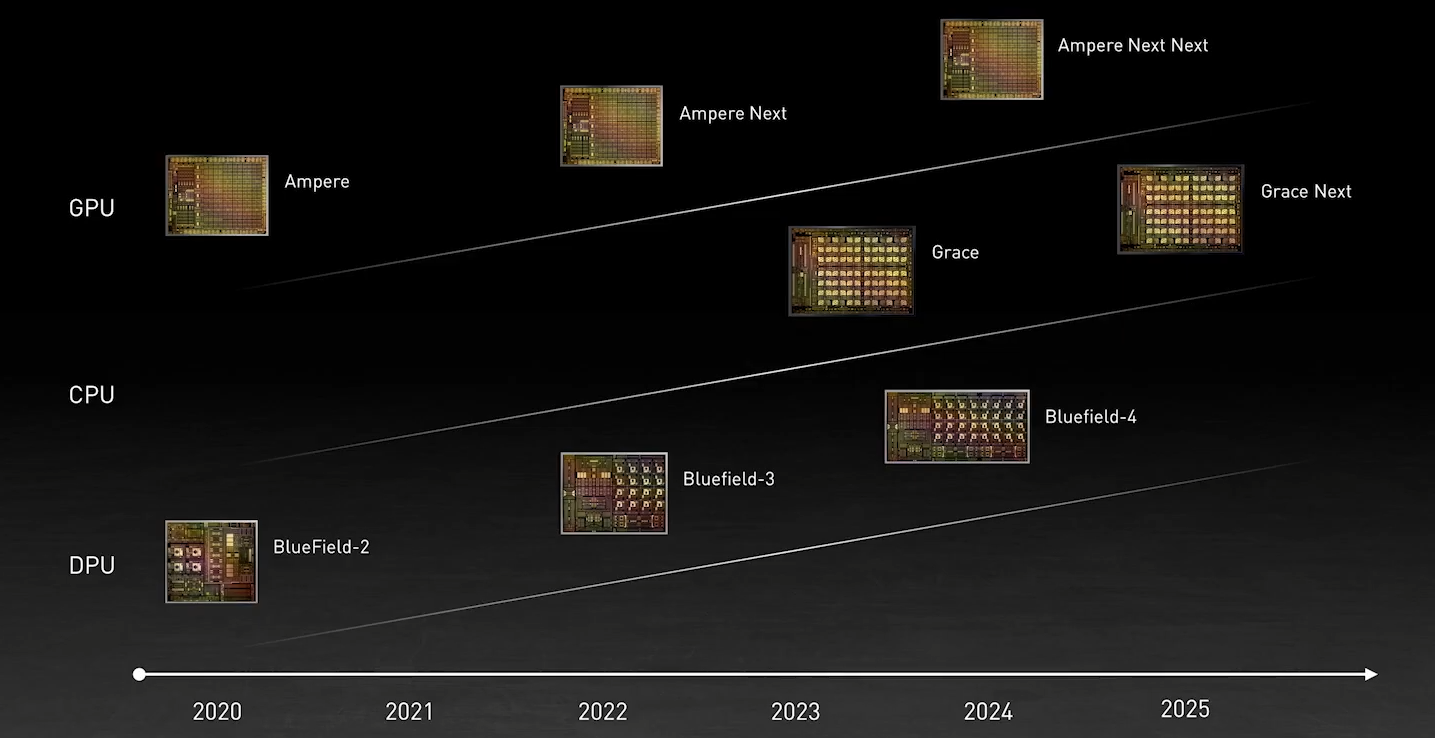 У процессора Grace, который выйдет только в 2023 году, даже по современным меркам «голая» производительность не так уж высока — в SPECrate2017_int его рейтинг будет 300. Но это и неважно потому, что он, как и сейчас, нужен лишь для поддержки ускорителей (которые для краткости будем называть GPU, хотя они всё менее соответствуют этому определению), что возьмут на себя основную вычислительную нагрузку. 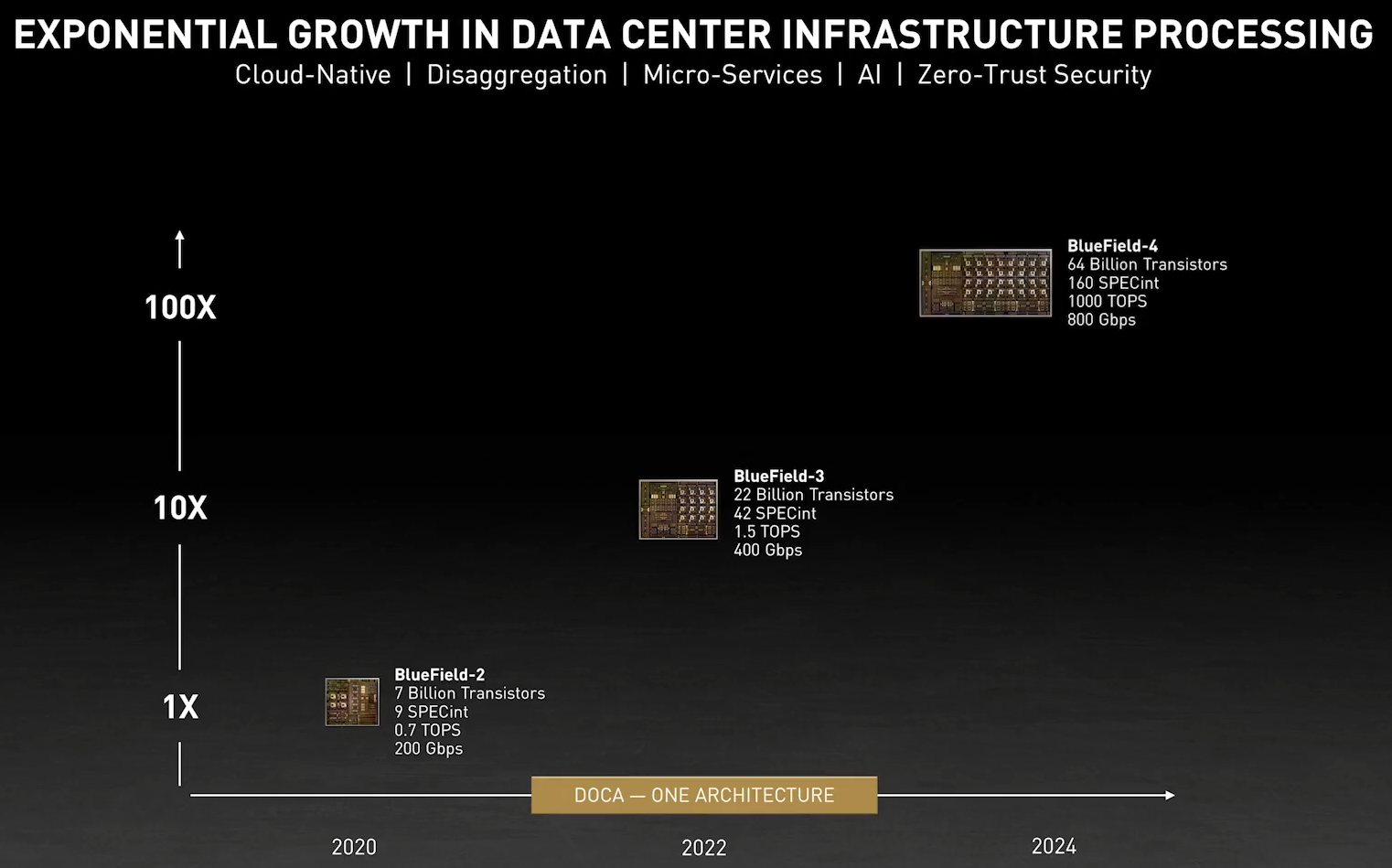 Гораздо интереснее то, что уже в 2024 году появятся BlueField-4, для которых заявленный уровень производительности в том же SPECrate2017_int составит 160. То есть DPU (Data Processing Unit, сопроцессор для данных) формально будет всего лишь в два раза медленнее CPU Grace, но при этом включать 64 млрд транзисторов. У нынешних ускорителей A100 их «всего» 54 млрд, и это один из самых крупных массово производимых чипов на сегодня.  Значительный объём транзисторного бюджета, очевидно, пойдёт не на собственной сетевую часть, а на Arm-ядра и различные ускорители. Анонсированные в прошлом году и ставшие доступными сейчас DPU BlueField-2 намного скромнее. Но именно с их помощью NVIDIA готовит экосистему для будущих комплексных решений, где DPU действительно станут «третьим сокетом», как когда-то провозгласил стартап Fubgible, успевший анонсировать до GTC’21 и собственную СХД, и более общее решение для дата-центров. Однако подход двух компаний отличается. 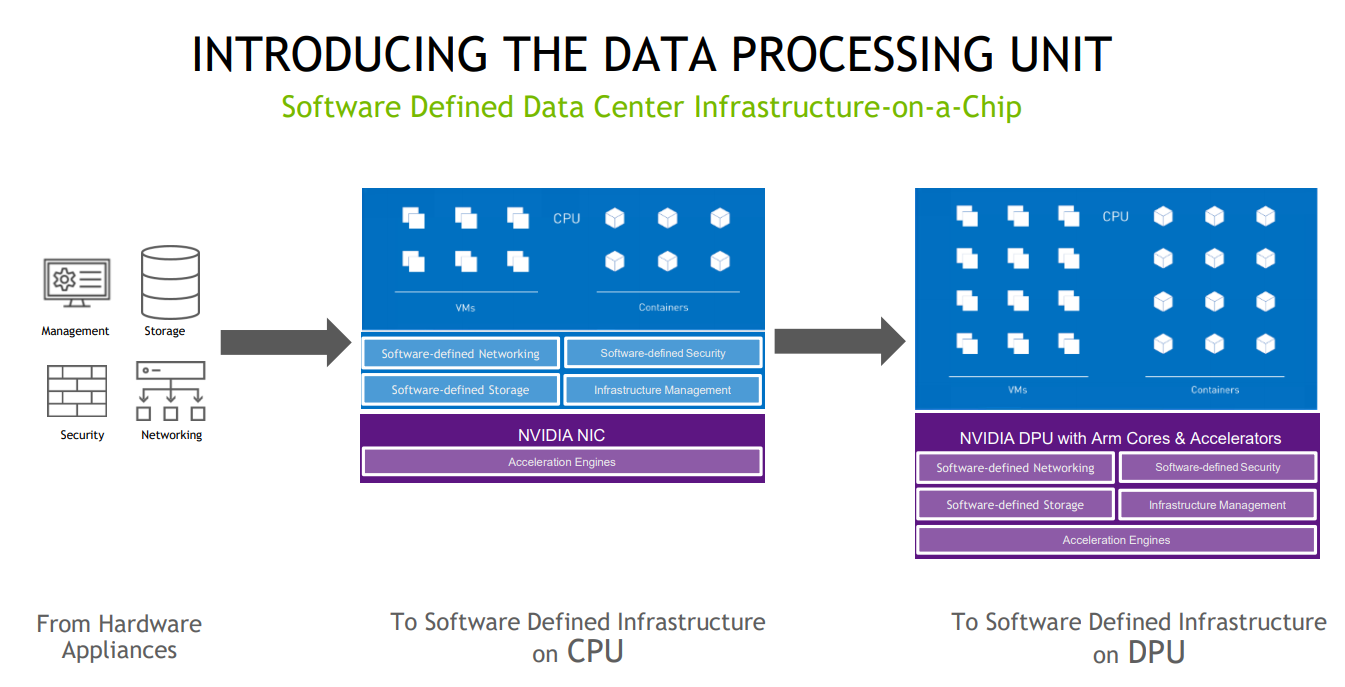 Напомним основные характеристики BlueField-2. Сетевая часть, представленная Mellanox ConnectX-6 Dx, предлагает до двух портов 100 Гбит/с, причём доступны варианты и с Ethernet, и с InfiniBand. Есть отдельные движки для ускорения криптографии, регулярных выражений, (де-)компрессии и т.д. Всё это дополняют 8 ядер Cortex-A78 (до 2,5 ГГц), от 8 до 32 Гбайт DDR4-3200 ECC, собственный PCIe-свитч и возможность подключения M.2/U.2-накопителя. Кроме того, будет вариант BlueField-2X c GPU на борту. Характеристики конкретных адаптеров на базе BlueField-2 отличаются, но, в целом, перед нами полноценный компьютер. А сама NVIDIA называет его DOCA (DataCenter on a Chip Architecture), дата-центром на чипе. 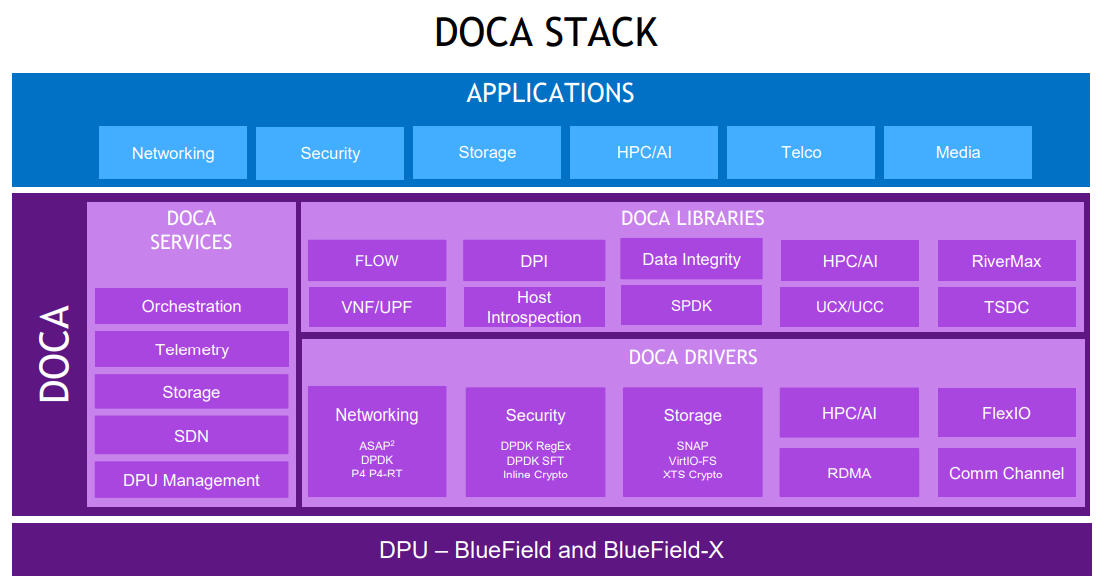 Для работы с ним предлагается обширный набор разработчика DOCA SDK, который включает драйверы, фреймворки, библиотеки, API, службы и собственно среду исполнения. Все вместе они покрывают практически все возможные типовые серверные нагрузки и задачи, а также сервисы, которые с помощью SDK относительно легко перевести в разряд программно определяемых, к чему, собственно говоря, все давно стремятся. NVIDIA обещает, что DOCA станет для DPU тем же, чем стала CUDA для GPU, сохранив совместимость с последующими версиями ПО и «железа». 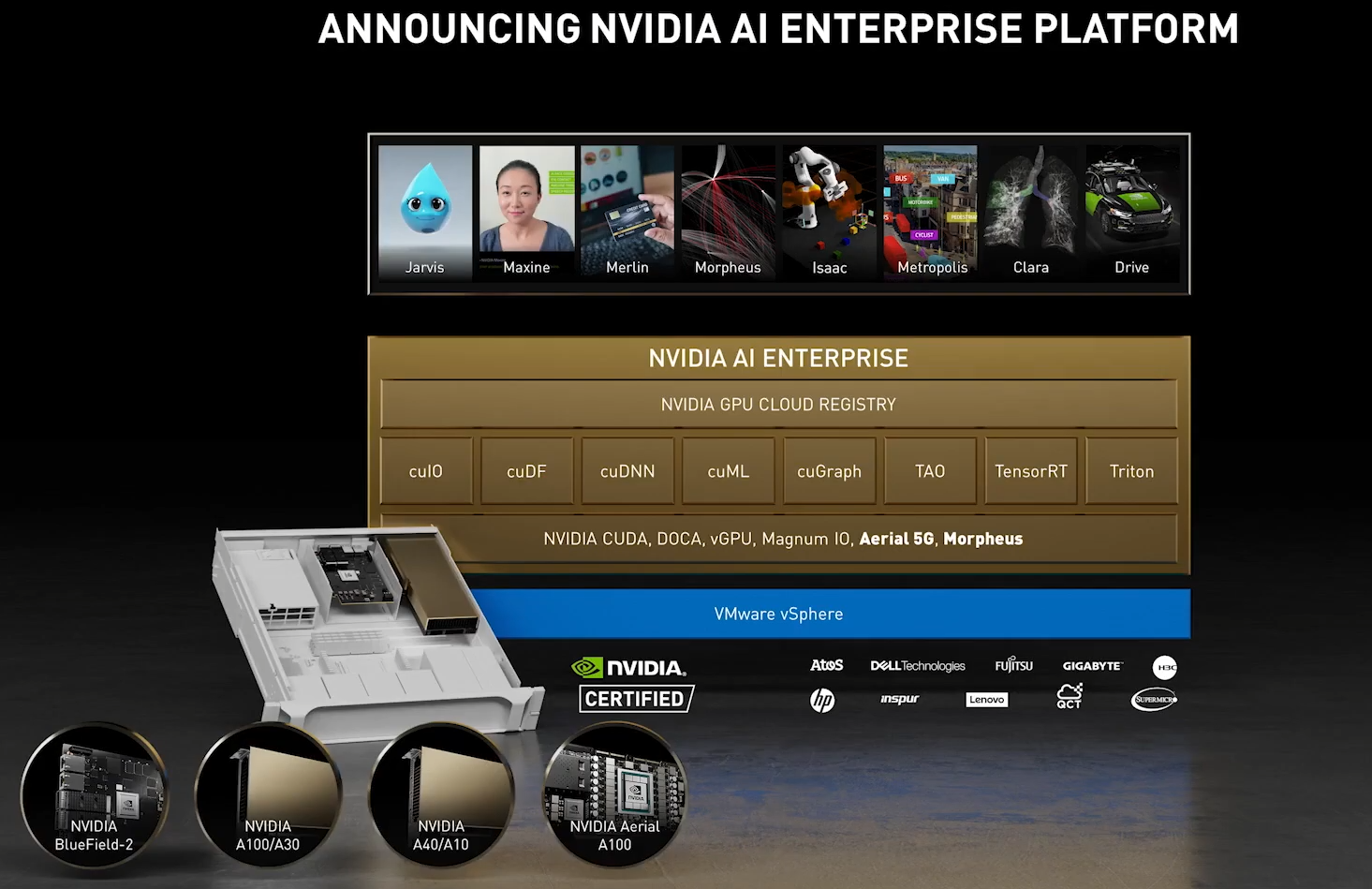 На базе этого программно-аппаратного стека компания уже сейчас предлагает несколько решений. Первое — платформа NVIDIA AI Enterprise для простого, быстрого и удобного внедрения ИИ-решений. В качестве основы используется VMware vSphere, где развёртываются виртуальные машины и контейнеры, что упрощает работу с инфраструктурой, при этом производительность обещана практически такая же, как и в случае bare-metal. 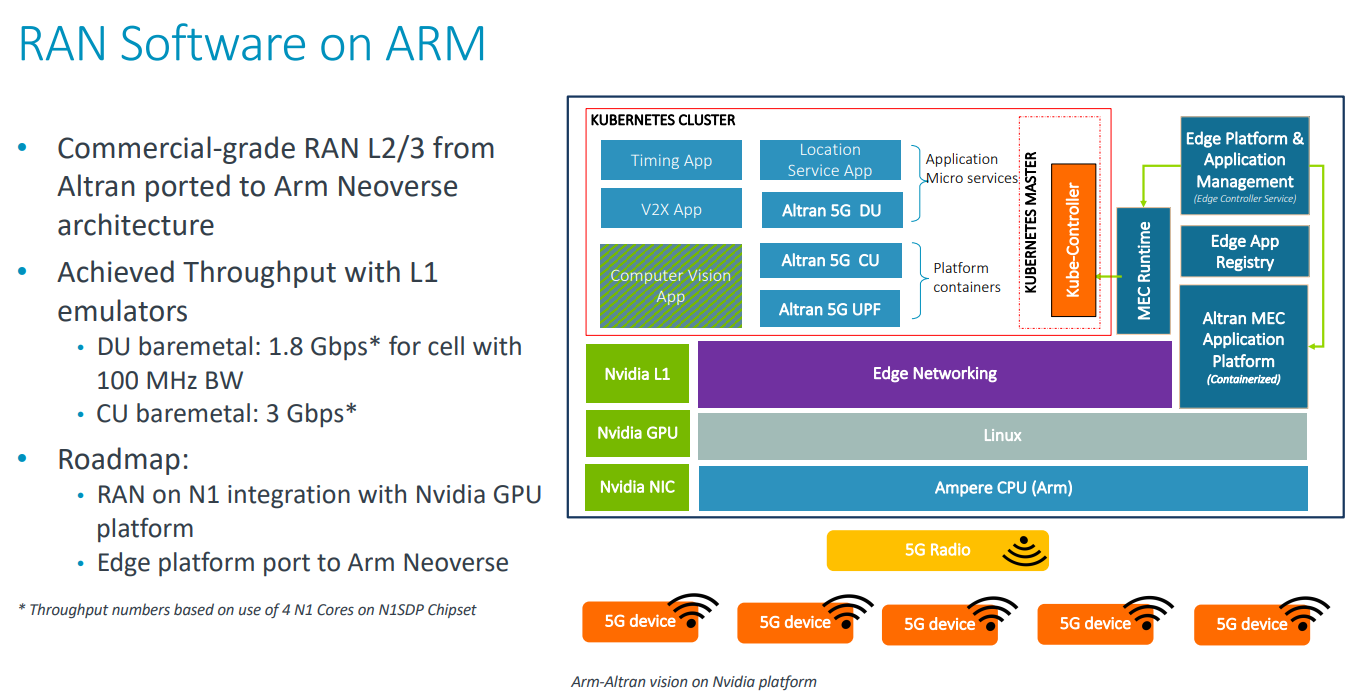 DPU и в текущем виде поддерживают возможность разгрузки для некоторых задач, но VMware вместе с NVIDIA переносят часть типовых задач гипервизора с CPU непосредственно на DPU. Кроме того, VMware продолжает работу над переносом своих решений с x86-64 на Arm, что вполне укладывается в планы развития Arm-экосистемы со стороны NVIDIA. Одним из направлений является 5G, причём работа ведётся по нескольким направлениям. Во-первых, сама Arm разрабатывает периферийную платформу на базе Ampere Altra, дополненных GPU и DPU. 
NVIDIA Aerial A100 Во-вторых, у NVIDIA конвергентное решение — ускоритель Aerial A100, который объединяет в одной карте собственно A100 и DPU. При этом он может использоваться как для ускорения работы собственно радиочасти, так и для обработки самого трафика и реализации различных пограничных сервисов. Там же, где не требуется высокая плотность (как в базовой станции), NVIDIA предлагает использовать более привычную EGX-платформу с раздельными GPU (от A100 и A40 до A30/A10) и DPU. 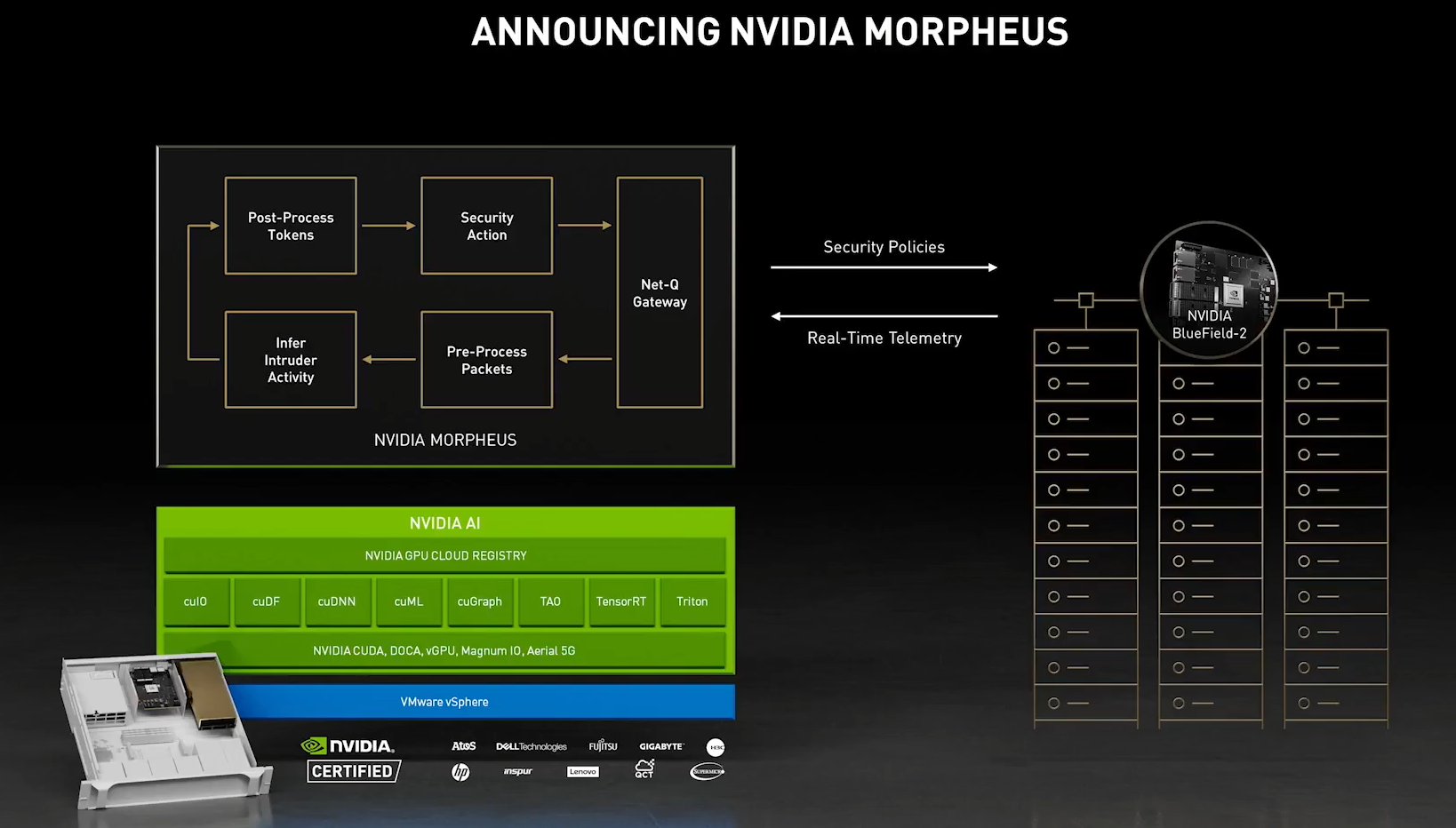 Одним из вариантов комплексного применения таких платформ является проект Morpheus. В его рамках предполагается установка DPU в каждый сервер в дата-центре. Мощностей DPU, в частности, вполне хватает для инспекции трафика, что позволяет отслеживать взаимодействие серверов, приложений, ВМ и контейнеров внутри ЦОД, а также, очевидно, применять различные политики в отношении трафика. DPU в данном случае выступают как сенсоры, данных от которых стекаются в EGX, и, вместе с тем локальными шлюзами безопасности. 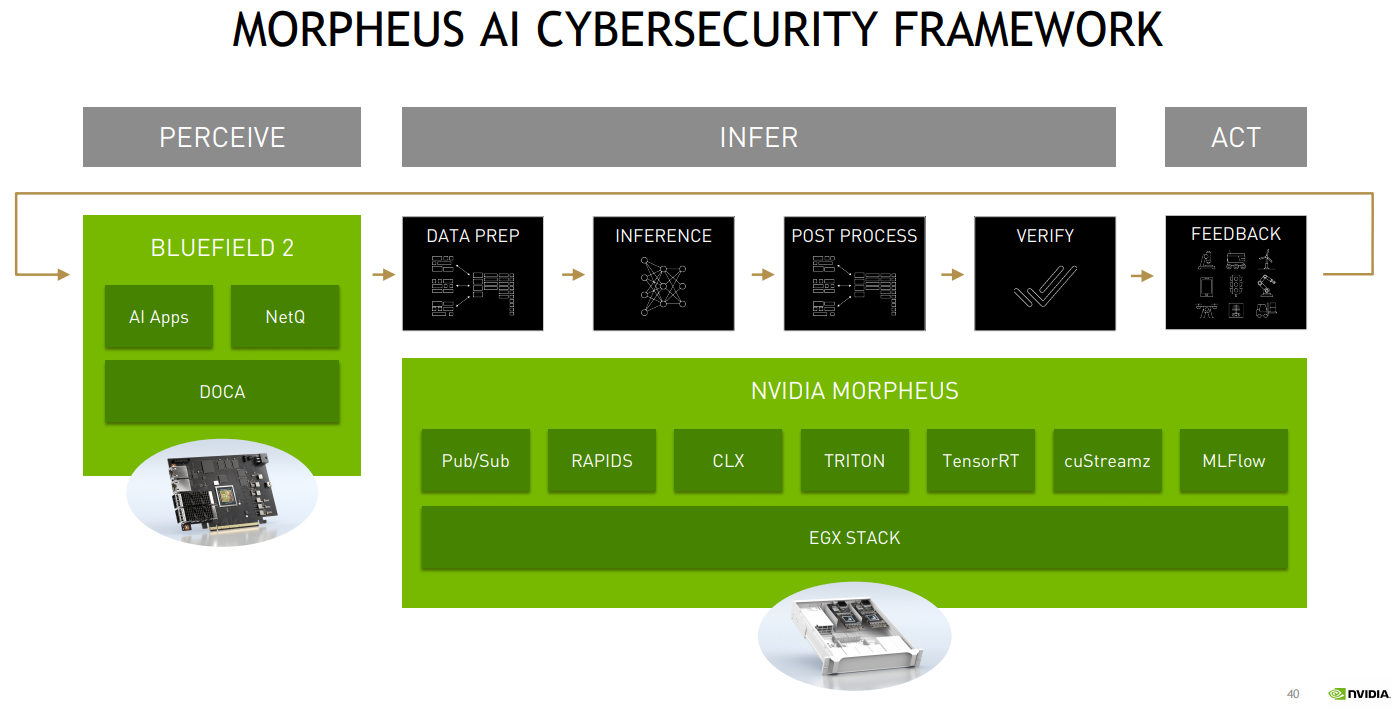 Ручная настройка политик и отслеживание поведения всего парка ЦОД возможны, но не слишком эффективны. Поэтому NVIDIA предлагает как возможность обучения, так и готовые модели (с дообучением по желанию), которые исполняются на GPU внутри EGX и позволяют быстро выявить аномальное поведение, уведомить о нём и отсечь подозрительные приложения или узлы от остальной сети. В эпоху микросервисов, говорит компания, более чем актуально следить за состоянием инфраструктуры внутри ЦОД, а не только на его границе, как было раньше, когда всё внутри дата-центра по умолчанию считалось доверенной средой. 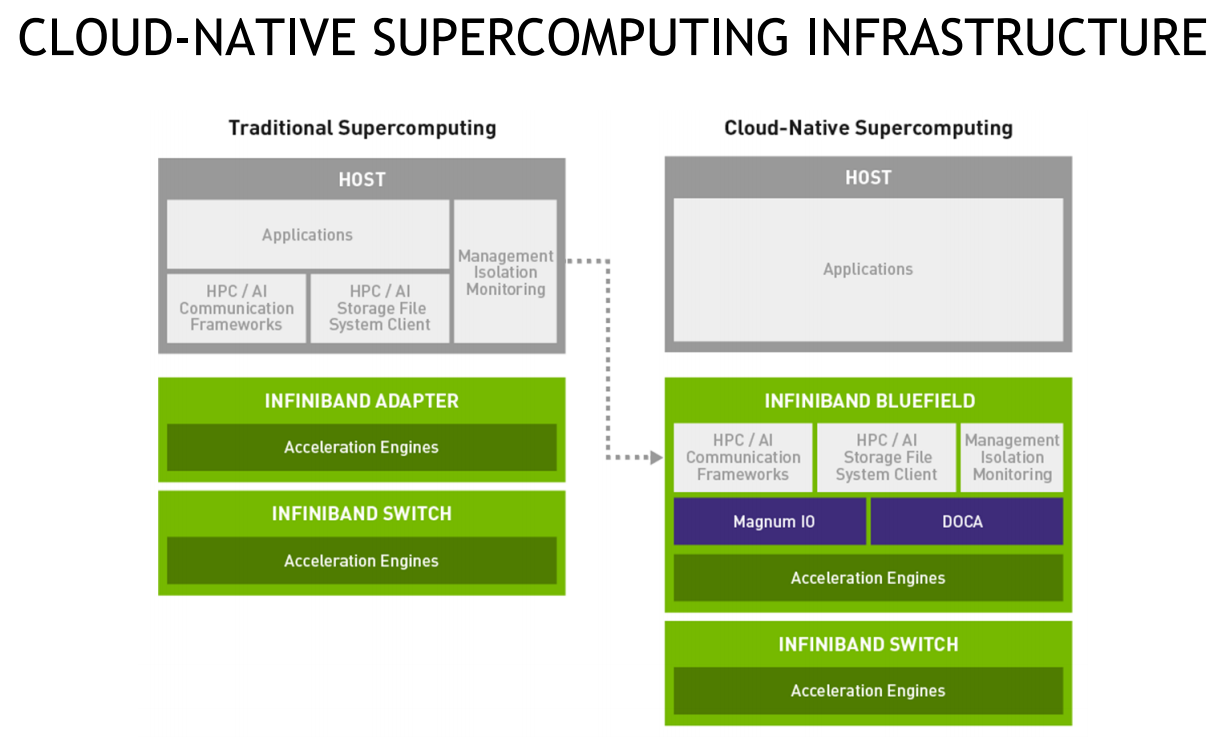 Кроме того, с помощью DPU и DOCA можно перевести инфраструктуру ЦОД на облачную модель и упростить оркестрацию. Но не только ЦОД — обновлённая суперкомпьютерная платформа DGX SuperPOD for Enterprise теперь тоже обзавелась DPU (с InfiniBand) и ПО Base Command, которые позволяют «нарезать» машину на изолированные инстансы с необходимой конфигурацией, упрощая таким образом совместное использование и мониторинг. А это, в свою очередь, повышает эффективность загрузки суперкомпьютера. Base Command выросла из внутренней системы управления Selene, собственным суперкомпьютером NVIDIA, на котором, например, компания обучает модели. 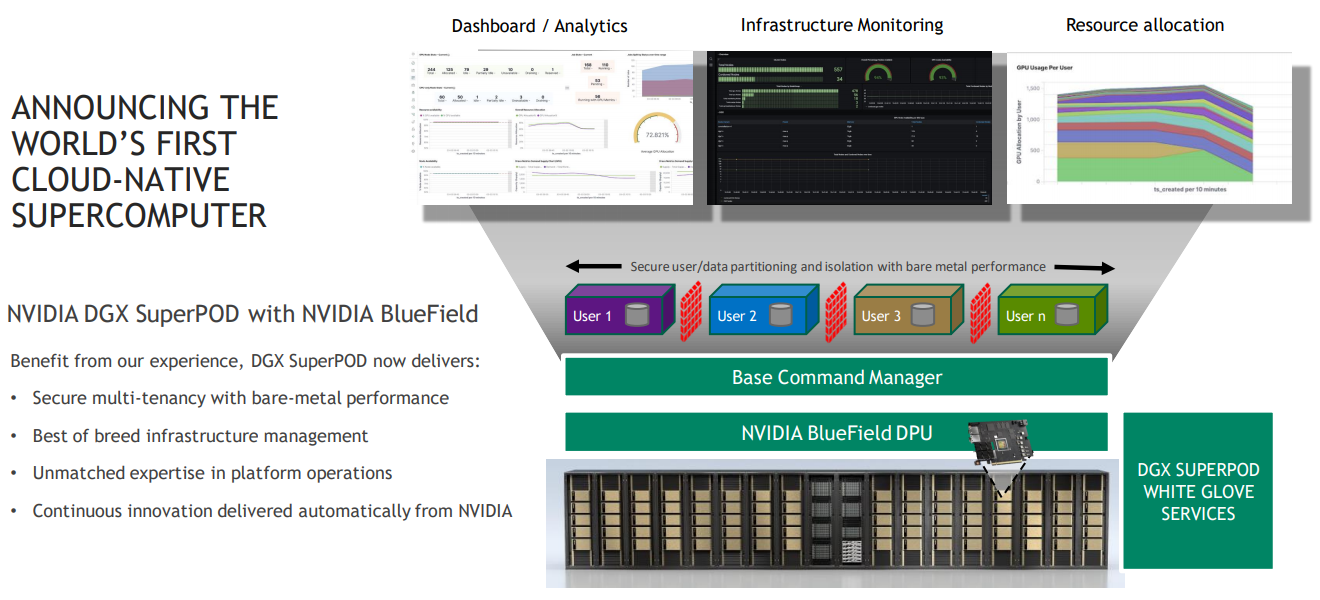 DPU доступны как отдельные устройства, так и в составе сертифицированных платформ NVIDIA и решений партнёров компании, причём спектр таковых велик. Таким образом компания пытается выстроить комплексный подход, предлагая программно-аппаратные решения вкупе с данными (моделями). Аналогичный по своей сути подход исповедует Intel, а AMD с поглощением Xilinx, надо полагать, тоже будет смотреть в эту сторону. И «угрозу» для них представляют не только GPU, но теперь и DPU. А вот новые CPU у NVIDIA, вероятно, на какое-то время останутся только в составе собственных продуктов, в независимости от того, разрешат ли компании поглотить Arm.
15.04.2021 [15:39], Владимир Мироненко
Dell объявила о выделении VMware в отдельную компанию, но их сотрудничеству это не помешаетDell Technologies объявила о планируемом отделении VMware. В результате сделки появятся две отдельные компании, которые продолжат совместно разрабатывать решения для клиентов в рамках заключённого коммерческого соглашения. Во владении Dell сейчас находится 80,6-% доля в VMware, при этом разница в рыночной оценке стоимости обеих компаний велика, и она не в пользу Dell. Ожидается, что данная сделка будет завершена в четвёртом квартале 2021 года при соблюдении определённых условий, включая получение положительного судебного решения Налогового управления США с заключением о том, что сделка будет квалифицирована как не облагаемая федеральным подоходным налогом для акционеров Dell Technologies. Более простым вариантом была бы прямая продажа акций VMware, но в этом случае Dell будет вынуждена выплатить многомиллиардные отчисления государству. После всестороннего анализа возможных стратегических вариантов стороны определили, что выделение VMware упростит структуру капитала и создаст дополнительную долгосрочную стоимость. При закрытии сделки VMware распределит специальные денежные дивиденды в размере $11,5–12 млрд среди всех акционеров VMware, включая саму Dell Technologies. Исходя из того, что в настоящее время Dell Technologies владеет 80,6 % акций VMware, она получит примерно $9,3–9,7 млрд. Компания намерена использовать полученные средства для выплаты долга, что обеспечит ей высокие инвестиционные рейтинги.  При закрытии сделки акционеры Dell Technologies получат примерно 0,44 акции VMware за каждую принадлежащую им акцию Dell Technologies, исходя из количества акций, находящихся в обращении сегодня. VMware перейдёт от многоклассовой к одноклассовой структуре акций, в то время как структура акций Dell Technologies останется прежней. Сообщается, что Dell Technologies и VMware заключат коммерческое соглашение, которое сохранит уникальные и дифференцированные подходы компаний к совместной разработке критически важных решений и согласованию продаж и маркетинговой деятельности. VMware продолжит использовать финансовые сервисы Dell Financial Services для поддержки клиентов в проведении цифровой трансформации. После завершения выделения Майкл Делл (Michael Dell) останется председателем и главным исполнительным директором Dell Technologies, а также председателем совета директоров VMware. Зейн Роу (Zane Rowe) останется временным генеральным директором VMware, а совет директоров VMware оставят без изменений. Dell Technologies в будущем сосредоточится на:
15.04.2021 [01:31], Владимир Мироненко
TSMC остановит выпуск Arm-процессоров Phytium — судьба китайского экзафлопсного суперкомпьютера Tianhe-3 под вопросомТайваньская компания Taiwan Semiconductor Manufacturing Company (TSMC) приостановила поставку чипов по новым заказам китайской компании Phytium, которая на прошлой неделе была добавлена властями США в «чёрный» список Министерства торговли. Внесение компаний в этот перечень означает запрет для американских компаний на работу с ними и предоставление продуктов или услуг без получения соответствующих лицензий. Иностранные компании, такие как TSMC, теоретически могут продолжать работать с компаниями из «чёрного списка», но США могут оказывать на них давление через их американских поставщиков. Например, когда США занесли Huawei в «чёрный» список, TSMC была вынуждена отказаться от сотрудничества с ней, поскольку многие ключевые технологии, лежащие в основе её производственных процессов, были разработаны американскими фирмами. Пока неясно, оказывалось ли сейчас подобное давление на TSMC, и были ли ею прекращены поставки остальным шести суперкомпьютерным китайским фирмам из «чёрного» списка. Как сообщает South China Morning Post, TSMC выполнит заказы, размещённые Phytium до внесения в «чёрный список», но больше поставлять ей чипы не будет. 
Прототип Tianhe-3. Фото: Xinhua Предполагается, что Phytium стоит за развёртыванием систем высокопроизводительных вычислений для китайского военно-промышленного комплекса, использующего её разработки при создании гиперзвуковых ракет. Компания сотрудничает с Оборонным научно-техническим университетом Народно-освободительной армии Китая (NUDT), который ранее создал суперкомпьютеры Tianhe-1 и Tianhe-2, в своё время занимавшие первые строчки рейтинга TOP500. Tianhe-3, один из трёх проектов китайских суперкомпьютеров экзафлопсного класса, должен был быть закончен в прошлом году, однако осенью было объявлено, что из-за пандемии коронавируса сроки сдвигаются. Летом 2020 года в распоряжении исследователей уже был прототип новой машины, имевший теоретическую производительность 3,146 Пфлопс. Он включал 512 плат с тремя процессорами Phytium MT2000+ и 128 плат с четырьмя Phytium FT2000+. Точные параметры этих 7-нм Arm-чипов не приводятся, но в одной из свежих научных публикаций упоминается, что на каждый 64-ядерный FT2000+ в прототипе Tianhe-3 приходилось 64 Гбайт RAM. А каждый MT2000+ можно поделить на четыре NUMA-узла с 32 ядрами и 16 Гбайт RAM, то есть, судя по описанию, это 128-ядерный чип, о котором ранее ничего не было известно. Теперь же судьба этих CPU и суперкомпьютера Tianhe-3 и вовсе под вопросом.
12.04.2021 [20:00], Сергей Карасёв
NVIDIA представила младшие серверные ускорители A10 и A30Компания NVIDIA в рамках конференции GPU Technology Conference 2021 анонсировала ускорители A10 и A30, предназначенные для обработки приложений искусственного интеллекта и других задач корпоративного класса. Модель NVIDIA A10 использует 72 ядра RT и может оперировать 24 Гбайт памяти GDDR6 с пропускной способностью до 600 Гбайт/с. Максимальное значение TDP составляет 150 Вт. Новинка выполнена в виде полноразмерной карты расширения с интерфейсом PCIe 4.0: в корпусе сервера устройство займёт один слот расширения. Производительность в вычислениях одинарной точности (FP32) заявлена на уровне 31,2 терафлопса. Новинку можно рассматривать как замену NVIDIA T4.  Модель NVIDIA A30, в свою очередь, получила исполнение в виде двухслотовой карты расширения с интерфейсом PCIe 4.0. Задействованы 24 Гбайт памяти HBM2 с пропускной способностью до 933 Гбайт/с. Показатель TDP равен 165 Вт. Обе новинки используют архитектуру Ampere с тензорными ядрами третьего поколения.  Решения подходят для применения в серверах массового сегмента, рабочих станциях, а также в составе платформы NVIDIA EGX и для периферийных вычислений. 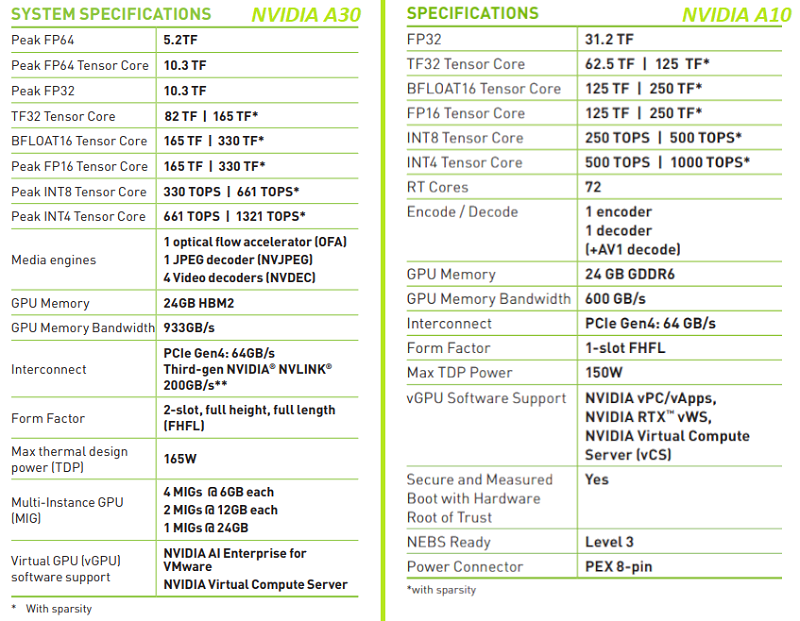
12.04.2021 [19:26], Игорь Осколков
NVIDIA анонсировала серверные Arm-процессоры Grace и будущие суперкомпьютеры на их базеВ рамках GTC’21 NVIDIA анонсировала Arm-процессоры Grace серверного класса, которые станут компаньонами будущих ускорителей компании. Это не означает полный отказ от x86-64, но это позволит компании предложить клиентам более глубоко оптимизированные, а, значит, и более быстрые решения. NVIDIA говорит, что новый CPU позволит на порядок повысить производительность систем на его основе в ИИ и HPC-задачах в сравнении с современными решениями. Процессор назван в честь Грейс Хоппер (Grace Hopper), одного из пионеров информатики и создательницы целого ряда основополагающих концепций и инструментов программирования. И это имя нам уже встречалось в контексте NVIDIA — в конце 2019 года компания зарегистрировала торговую марку Hopper для MCM-решений.  Компания не готова раскрыть полные технически характеристики новинки, которая станет доступна в начале 2023 года, но приводит некоторые интересные детали. В частности, процессор будет использовать Arm-ядра Neoverse следующего поколения (надо полагать, уже на базе ARMv9), которые позволят получить в SPECrate2017_int_base результат выше 300. Для сравнения — система с парой современных AMD EPYC 7763 в том же бенчмарке показывает результат на уровне 800. Вторая особенность Grace — использование памяти LPDRR5X (с ECC, естественно). В сравнении с DDR4 она будет иметь вдвое большую пропускную способность (ПСП) и в 10 раз меньшее энергопотребление. Число и скорость каналов памяти не уточняются, но говорится о суммарной ПСП в более чем 500 Гбайт/с на процессор. А у того же EPYC 7763 теоретический пик ПСП чуть больше 200 Гбайт/с. Очевидно, что другие процессоры к моменту выхода NVIDIA Grace тоже увеличат и производительность, и пропускную способность памяти. Гораздо более интересный вопрос, сколько линий PCIe 5.0 они смогут предложить. Если допустить, что у них будет 128 линий, то общая скорость для них составит чуть больше 500 Гбайт/с. 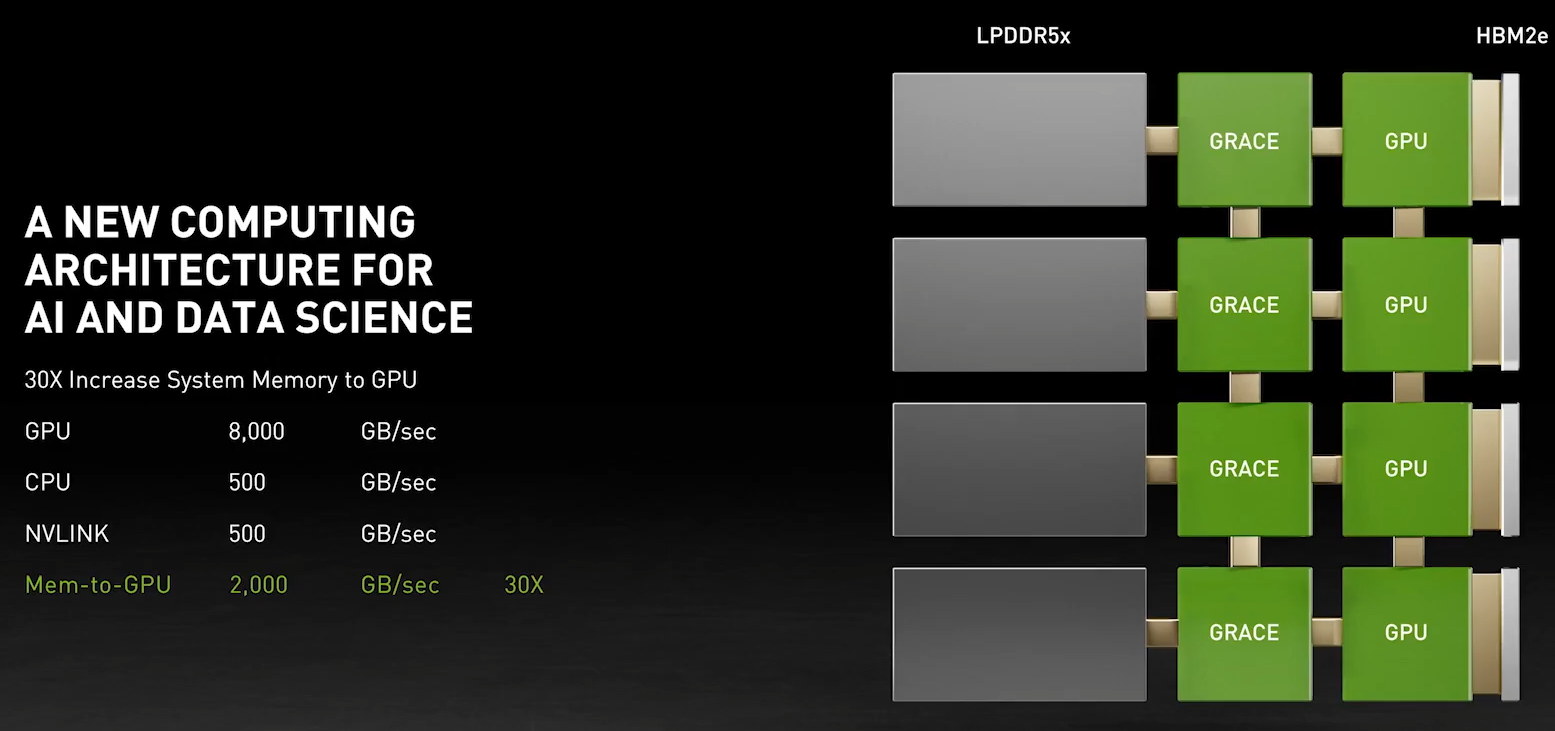 И NVIDIA этого мало — процессоры Grace получат прямое, кеш-когерентное подключение к GPU по NVLInk 4.0 (14x) с суммарной пропускной способностью боле 900 Гбайт/с. GPU тоже, как и прежде, будут общаться напрямую друг с другом по NVLink. Скорость связи между двумя CPU превысит 600 Гбайт/с, а в сборке из четырёх модулей CPU+GPU суммарная скорость обмена данными между системной памятью процессоров и GPU в такой mesh-сети составит 2 Тбайт/с. Но самое интересное тут то, что у памяти CPU (LPDDR5X) и GPU (HBM2e) в такой системе будет единое адресное пространство. Собственно говоря, таким образом компания решает давно назревшую проблему дисбаланса между скоростью обмена данными и доступным объёмом памяти в различных частях вычислительного комплекса. Для сравнения можно посмотреть на архитектуру нынешних DGX A100 или HGX. У каждого ускорителя A100 есть 40 или 80 Гбайт набортной памяти HBM2e (1555 или 2039 Гбайт/с соответственно) и NVLInk-подключение на 600 Гбайт/c, которое идёт к коммутатору NVSwitch, имеющего суммарную пропускную способность 1,8 Тбайт/с. Всего таких коммутаторов шесть, а объединяют они восемь ускорителей. Внутри этой NVLInk-фабрики сохраняется достаточно высокая скорость обмена данными, но как только мы выходим за её пределы, ситуация меняется. 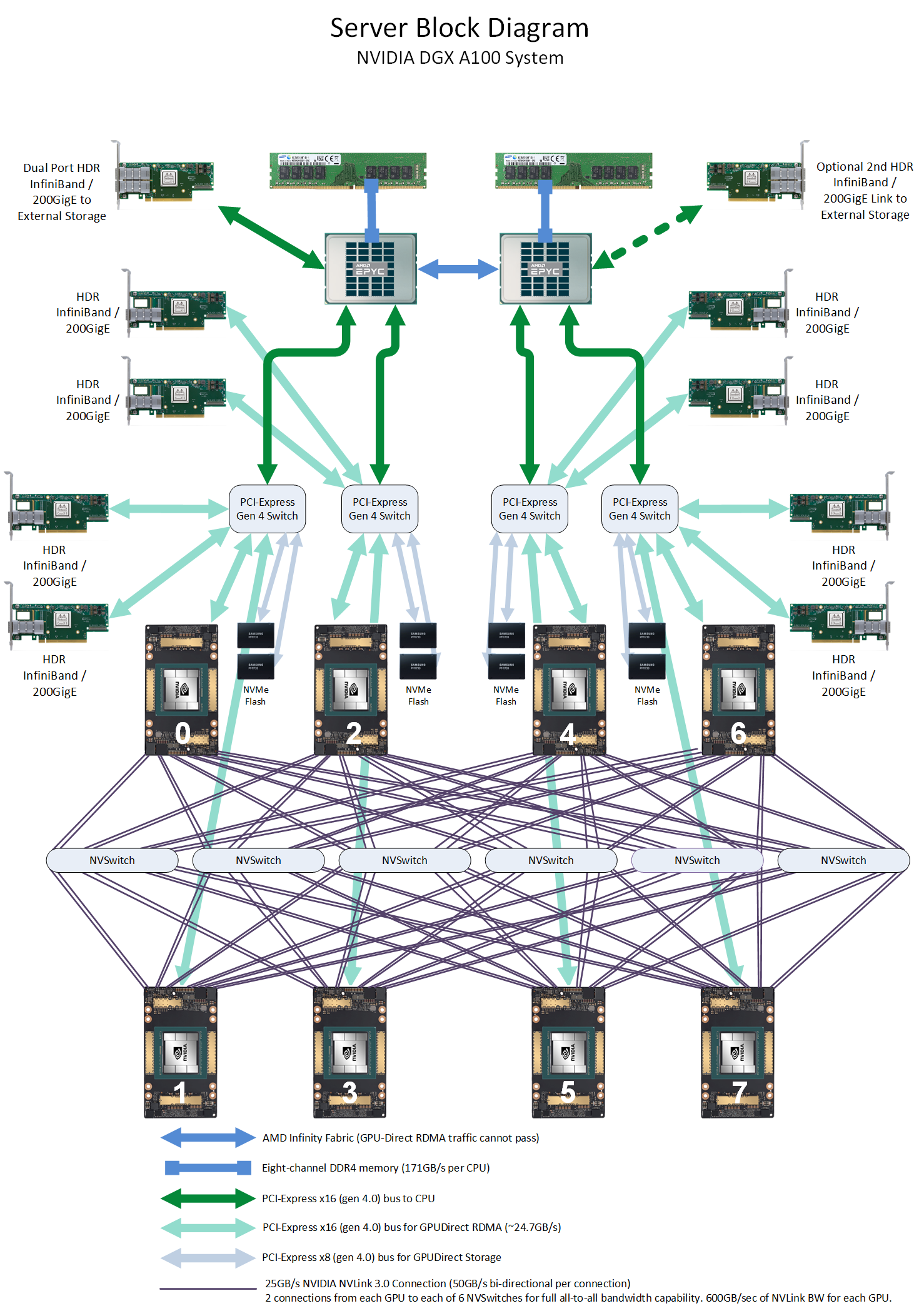
Схема NVIDIA DGX A100. Источник: Microway Каждый ускоритель A100 имеет второй интерфейс — PCIe 4.0 x16 (64 Гбайт/с), который уходит к PCIe-коммутатору, каковых в DGX A100 имеется четыре. Коммутаторы, в свою очередь, объединяют между собой сетевые 200GbE-адаптеры (суммарно в дуплексе до 1,6 Тбайт/с для связи с другими DGX A100), NVMe-накопители и CPU. У каждого CPU может быть довольно много памяти (от 512 Гбайт), но её скорость ограничена упомянутыми выше 200 Гбайт/c.  Узким местом во всей этой схеме является как раз PCIe, поэтому переход исключительно на NVLInk позволит NVIDIA получить большой объём памяти при сохранении приемлемой ПСП, не тратясь лишний раз на дорогую локальную HBM2e у каждого GPU. Впрочем, если компания не переведёт на NVLink и собственные будущие DPU Bluefield-3 (400GbE), которые будут скармливать связке CPU+GPU по, например, GPUDirect Storage данные из внешних NVMe-oF хранилищ и объединять узлы DGX POD, то PCIe 5.0 в составе Grace стоит ждать. Это опять-таки упростит и повысит эффективность масштабирования.  В целом, всё это необходимо из-за быстрого роста объёма ИИ-моделей — в GPT-3 уже 175 млрд параметров, а в течение пары лет можно ожидать модели уже с 0,5-1 трлн параметров. Им потребуются не только новые решения для обучения, но и для инференса. То же касается и физических расчётов — модели становятся всё больше и требовательнее + ИИ здесь тоже активно внедряется. Параллельно с разработкой Grace NVIDIA развивает программную экосистему вокруг Arm и своих решений, готовя почву для будущих систем на их основе.  Одной из такой систем станет суперкомпьютер Alps в Швейцарском национальном компьютерном центре (Swiss National Computing Centre, CSCS), который придёт на смену Piz Daint (12 место в нынешнем рейтинге TOP500). Этот суперкомпьютер серии HPE Cray EX, в частности, сможет в семь раз быстрее обучить модель GPT-3, чем машина NVIDIA Selene (5 место в TOP500). Впрочем, на нём будут выполняться и классические HPC-задачи в области метеорологии, физики, химии, биологии, экономики и так далее. Ввод в эксплуатацию намечен на 2023 год. Тогда же в США появится аналогичная машина от HPE в Лос-Аламосской национальной лаборатории (LANL). Она дополнит систему Crossroads, использующую исключительно процессоры Intel Xeon Sapphire Rapids.
12.04.2021 [19:21], Алексей Степин
NVIDIA анонсировала DPU BlueField-3: 400 Гбит/с, 16 ядер Cortex-A78 и PCIe 5.0Идея «сопроцессора данных», озвученная всерьёз в 2020 году компанией Fungible, продолжает активно развиваться и прокладывать себе дорогу в жизнь. На конференции GTC 2021 корпорация NVIDIA анонсировала новое поколение «умных» сетевых карт BlueField-3, способное работать на скорости 400 Гбит/с. Изначально серия ускорителей BlueField разрабатывалась компанией Mellanox, и одной из целей создания столь продвинутых сетевых адаптеров стала реализация концепции «нулевого доверия» (zero trust) для сетевой инфраструктуры ЦОД нового поколения. Адаптеры BlueField-2 были анонсированы в начале прошлого года. Они поддерживали два 100GbE-порта, микросегментацию, и могли осуществлять глубокую инспекцию пакетов полностью автономно, без нагрузки на серверные ЦП. Шифрование TLS/IPSEC такие карты могли выполнять на полной скорости, не создавая узких мест в сети. 
Кристалл BlueField-3 не уступает в сложности современным многоядерным ЦП — 22 млрд транзисторов Но на сегодня 100 и даже 200 Гбит/с уже не является пределом мечтаний — провайдеры и разработчики ЦОД активно осваивают скорости 400 и 800 Гбит/с. Столь скоростные сети требуют нового уровня производительности от DPU, и NVIDIA вскоре сможет предложить такой уровень: на конференции GTC 2021 анонсировано новое, третье поколение карт BlueField. 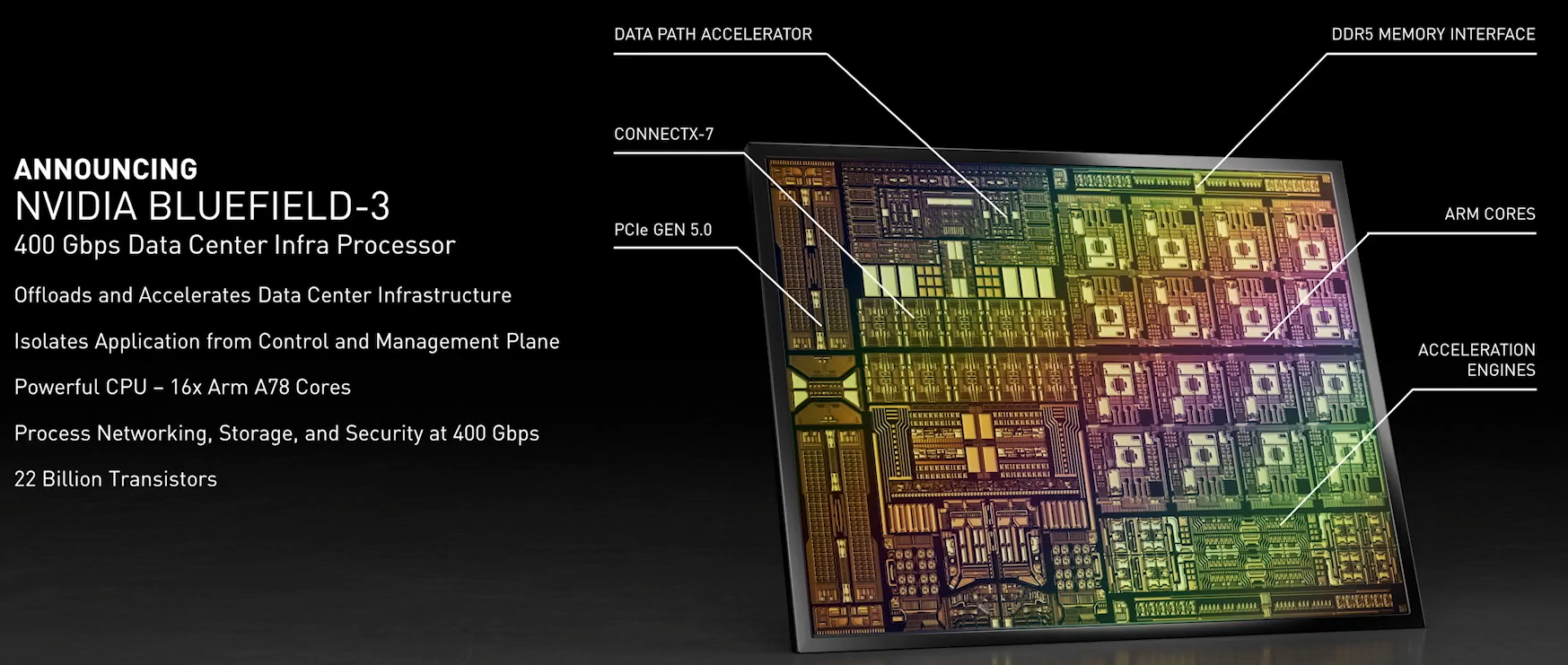 Если BlueField-2 могла похвастаться массивом из восьми ядер ARM Cortex-A72, объединённых когерентной сетью, то BlueField-3 располагает уже шестнадцатью ядрами Cortex-A78 и в четыре раза более мощными блоками криптографии и DPI. Совокупно речь идёт о росте производительности на порядок, что позволяет новинке работать без задержек на скорости 400 Гбит/с — и это первый в индустрии адаптер класса 400GbE со столь продвинутыми возможностями, поддерживающий, к тому же, стандарт PCI Express 5.0. Известно, что столь быстрым сетевым решениям PCIe 5.0 действительно необходим.  С точки зрения поддерживаемых возможностей BlueField-3 обратно совместим с BlueField-2, что позволит использовать уже имеющиеся наработки в области программного обеспечения для DPU. Одновременно с анонсом нового DPU компания представила и открытую программную платформу DOCA, упрощающую разработку ПО для таких сопроцессоров, поскольку они теперь занимаются не просто обработкой сетевого трафика, а оркестрацией работы серверов, приложений и микросервисов в рамках всего дата-центра. 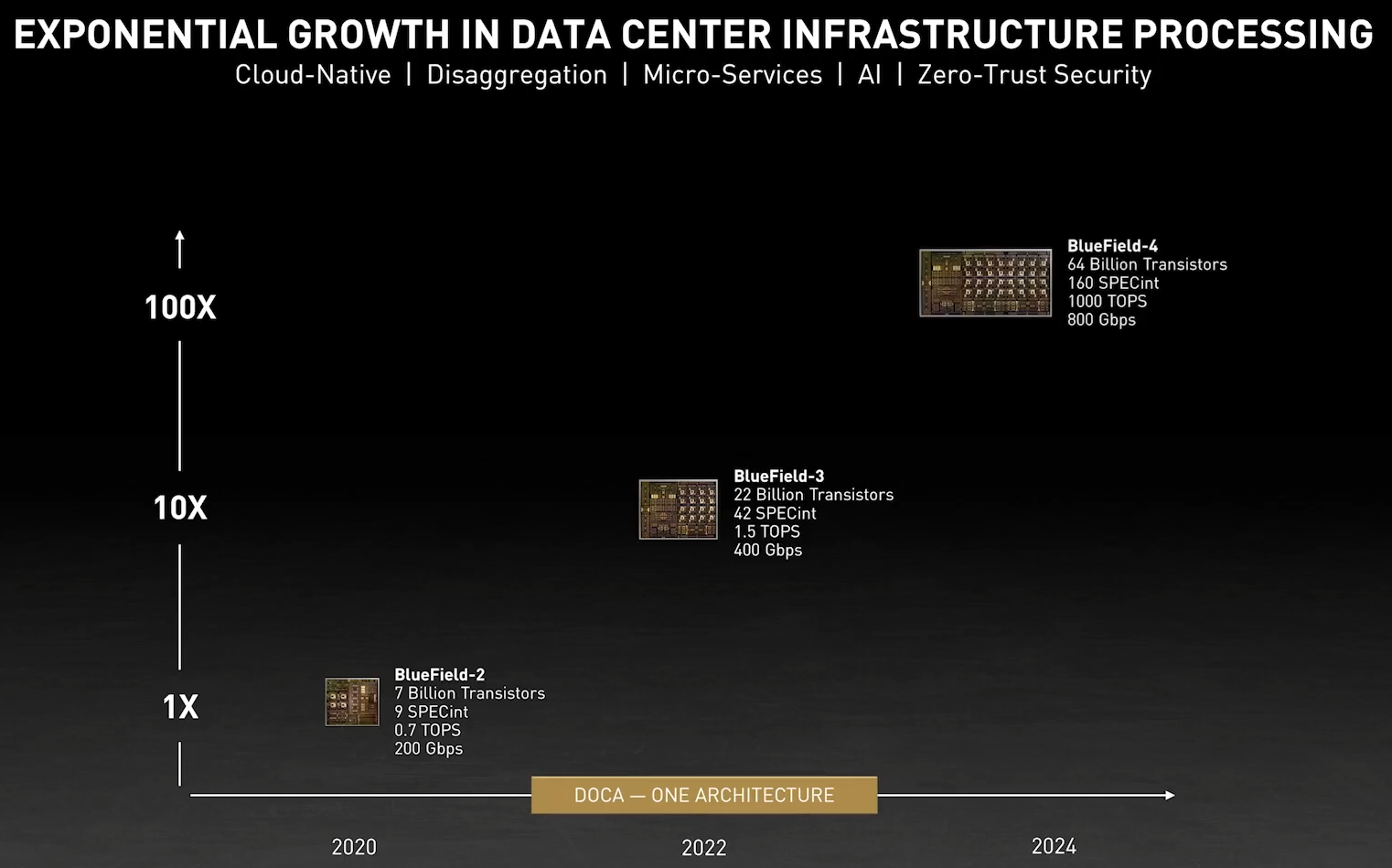 В настоящее время NVIDIA сотрудничает с такими крупными поставщиками серверных решений, как Dell EMC, Inspur, Lenovo и Supermicro, со стороны разработчиков ПО интерес к BlueField проявляют Canonical, VMWare, Red Hat, Fortinet, NetApp и ряд других компаний. О массовом производстве BlueField-3 речи пока не идёт, поставка малыми партиями ожидается в первом квартале 2022 года, но карты BlueField-2 доступны уже сейчас. А в 2024 году появятся BlueField-4 с портами 800 Гбит/с.
02.03.2021 [13:45], Сергей Карасёв
Cisco закрыла сделку по покупке разработчика оптических компонентов AcaciaАмериканская компания Cisco, один из крупнейших в мире поставщиков сетевого оборудования, завершила сделку по поглощению Acacia Communications — разработчика оптических компонентов. Слияние позволит Cisco укрепить позиции на рынке кремниевой фотоники. Напомним, что Cisco сообщила о планах по покупке Acacia ещё в 2019 году. Тогда говорилось, что сумма сделки составит приблизительно $2,6 млрд. Однако первоначальные условия впоследствии изменились. Так, в январе нынешнего года Acacia объявила о расторжении договора с Cisco: причиной стало то, что сделка в обозначенные сроки не получила одобрения Государственного управления по регулированию рынка Китайской Народной Республики (SAMR). В свою очередь, Cisco обратилась в суд, настаивая на завершении слияния. 
Источник изображения: Cisco Позднее компании смогли найти общий язык, правда, сумма сделки значительно выросла, составив $4,5 млрд. И вот теперь сообщается, что слияние завершено. Поглощение поможет Cisco расширить ассортимент продукции для построения высокоскоростных сетей передачи данных. Речь, в частности, идёт об оборудовании класса 400G и выше. |
|

