Лента новостей
|
25.06.2021 [16:16], Владимир Агапов
Google обновила Transfer Appliance, облачную «флешку» на петабайтСервис Transfer Appliance, доступный в ряде регионов США, ЕС и Сингапуре, позволяет клиентам просто и безопасно перенести петабайты данных из их корпоративных ЦОД и других мест эксплуатации в Google Cloud. Сервис основан на одноимённой специализированной All-Flash СХД, которую клиент может запросить в Google Cloud Console, чтобы перенести на него свою информацию. На днях компания анонсировала новую версию Transfer Appliance. Google Cloud проверяет потребности заказчика, такие как мощность и необходимая ёмкость, и отправляет полностью укомплектованное устройство, включая все необходимые кабели. Доступные для заказа ёмкости находятся в диапазоне от 40 до 300 Тбайт. Имеются также две базовые модификации Transfer Appliance: на 100 и 480 Тбайт. Благодаря встроенным средствам дедупликации и сжатия данных потенциально можно перенести до 1 Пбайт. Кроме того, предприятия могут выбрать вариант исполнения — для монтажа в стойку или автономное устройство. Как только устройство прибывает к заказчику, его можно смонтировать как общий ресурс NFS и приступить к копированию данных. Затем устройство запечатывается для защиты от несанкционированного доступа при траспортировке и отправляется обратно Google. Перед переездом данные шифруются (AES-256), а клиент создаёт пароль и секретную фразу для их дешифровки. Это не только защищает информацию, но и позволяет соблюсти отраслевые стандарты ISO, SOC, PCI и HIPAA. По прибытии устройства в Google специалисты компании осуществляют обратные операции, которые для краткости они называют «регидратацией». О её успешном завершении Google сообщает заказчику как правило в течении 1-2 недель. После миграции клиентам становятся доступны средства для анализа данных BigQuery и Vertex AI. 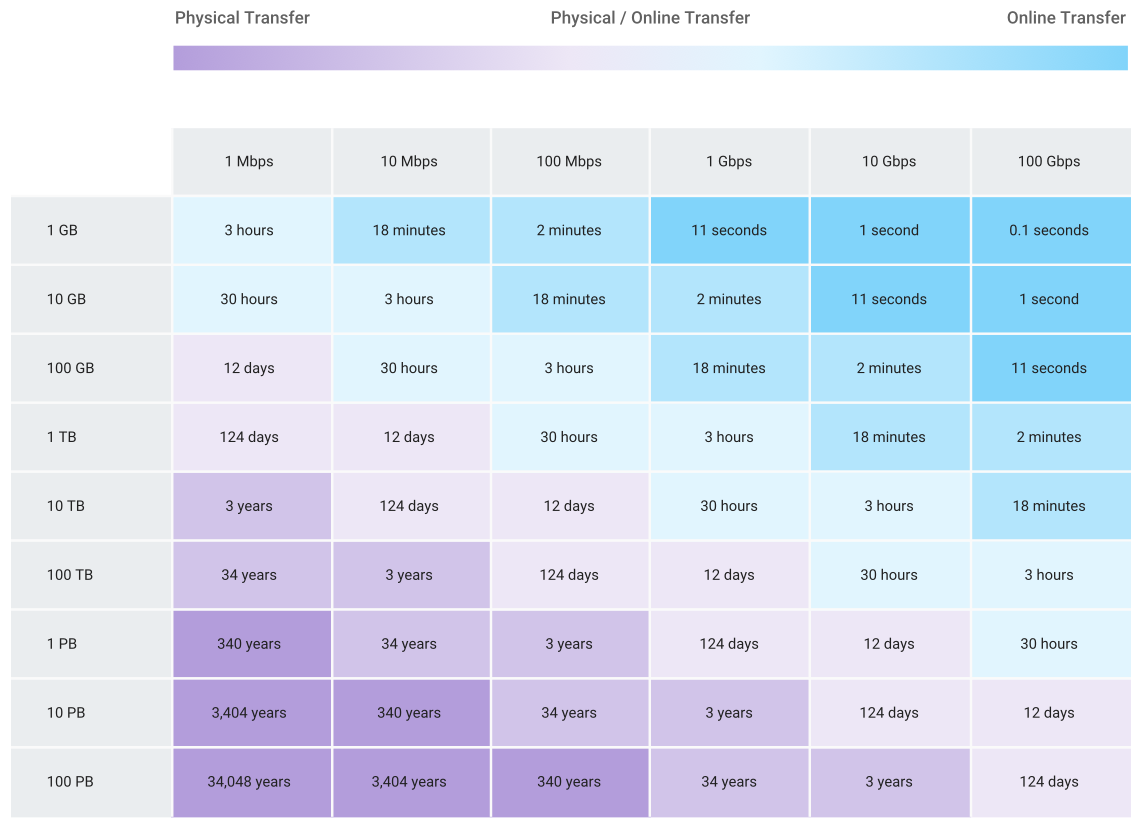 Google рекомендует предприятиям использовать сервис Transfer Appliance в тех случаях, когда для загрузки данных в облако через Интернет потребуется более недели, или когда необходимо перенести более 60 Тбайт данных. Ещё один вариант использования устройства — сбор данных в полевых условиях и на подвижных объектах, таких как корабли. По прибытии в порт их можно легко перенести в облако для последующей обработки или архивирования. Следует отметить, что сервис особенно полезен в условиях недостаточной пропускной способности каналов передачи данных или отсутствия возможности подключения к Интернет. Несмотря на то, что данная концепция не нова и компании десятилетиями отправляли данные на физические устройства для архивирования и аварийного восстановления, она не утратила своей актуальности и сегодня. Аналогичные решения есть у всех крупных облачных провайдеров.
23.06.2021 [00:20], Владимир Агапов
Норвежский дата-центр Green Mountain направит «мусорное» тепло на обогрев омаровНорвежский оператор дата-центров Green Mountain подписал договор с первой в мире наземной омаровой фермой Norwegian Lobster Farm на поставку отработанного тепла из ЦОД DC1-Stavanger. «С практической точки зрения это означает, что мы сможем увеличить масштабы производства, снизить технические риски и сэкономить как на капитальных, так и на эксплуатационных расходах, в дополнение к экологическим преимуществам, конечно» — отметил директор фермы Асбьерн Дренгстинг (Asbjørn Drengstig). Наземное разведение омаров является сложной задачей, но рыночные перспективы очень велики огромны. Особенно с учётом того, что популяция омаров в Европе сокращается. Поэтому технология наземного выращивания омаров разрабатывалась Norwegian Lobster Farm в течении нескольких лет при финансовой поддержке Европейского Союза по программе «Горизонт 2020». 
Источник изображений: Green Mountain В итоге на её предприятиях используется технология рециркуляции аквакультуры (RAS), а также передовая робототехника, системы компьютерного зрения и автоматический непрерывный мониторинг каждого отдельного омара. Благодаря такой заботе омары вырастают размером с тарелку. Для оптимального роста омару необходима температура морской воды 20 °С, и как раз такая температура получается после охлаждения IT-оборудования ЦОД. Поэтому сточные воды СЖО можно направить непосредственно на ферму. 
Система мониторинга омаров Наибольшая эффективность может быть достигнута, если ферма будет построена в непосредственной близости от центра обработки данных. Отметим, что совместный прокет Green Mountain и Norwegian Lobster Farm весьма удачно вписывается в инициативу норвежских властей, которые планируют обязать дата-центры и другие промышленные предприятия отдавать «мусорное» тепло на общественные нужды. 
Дата-центр DC1-Stavanger DC1-Stavanger использует для охлаждения морскую воду из фьорда с температурой 8 °С. После прохождения контуров охлаждения ЦОД нагретая вода сбрасывается обратно во фьорд. По словам генерального директора Green Mountain, Кристиана Гиланда ( Kristian Gyland), компания долгое время изучала различные способы повторного использования отработанного тепла, но большая часть из них не подходили из-за особенностей расположения дата-центра. Например, если дата-центры построены в городских жилых районах, вырабатываемое ими тепло можно использовать для обогрева домов. Однако расположение DC1-Stavanger в малонаселённом месте делает централизованное отопление бессмысленной затеей. С другой стороны, проект наземных омаровых ферм в этом случае подходит как нельзя лучше. «Мы надеемся, что сможем распространить эту и подобные концепции и на наши будущие объекты», — прокомментировал Гиланд.
18.06.2021 [13:31], Владимир Агапов
Сингапур и Facebook✴ разработают проект тропического дата-центраВ рамках проекта «Устойчивый тропический дата-центр» (STDC) будут протестированы новые методы охлаждения оборудования ЦОД с целью снижения нагрузки на сингапурскую электросеть. Необходимость в этом назрела, поскольку на Сингапур приходится около 60% центров обработки данных Юго-Восточной Азии и они потребляют уже 7% всей доступной стране электроэнергии. Несмотря на растущий спрос, властям пришлось наложить мораторий на строительство новых объектов. Тестовая площадка STDC, которая разместится на территории кампуса Kent Ridge Национального университета Сингапура (NUS). Она позволит испытать конструкцию теплообменника с влагопоглощающим покрытием и систему StatePoint, которую Facebook✴ и Nortek разработали для тропических районов. Также будет рассмотрен вариант гибридного охлаждения на уровне чипов и система динамического управления охлаждением на основе цифровых двойников и алгоритмов искусственного интеллекта (ИИ). 
newswise.com Исследователи планируют выяснить, может ли теплообменник, покрытый адсорбентом, улучшить непрямое испарительное охлаждение в условиях тропического климата. Тестирование такой системы в реальных условиях эксплуатации необходимо для последующего безопасного внедрения на коммерческих объектах. А гибридное охлаждение чипов должно повысить надёжность, поскольку систему воздушного охлаждения можно использовать во время обслуживания водяного контура. 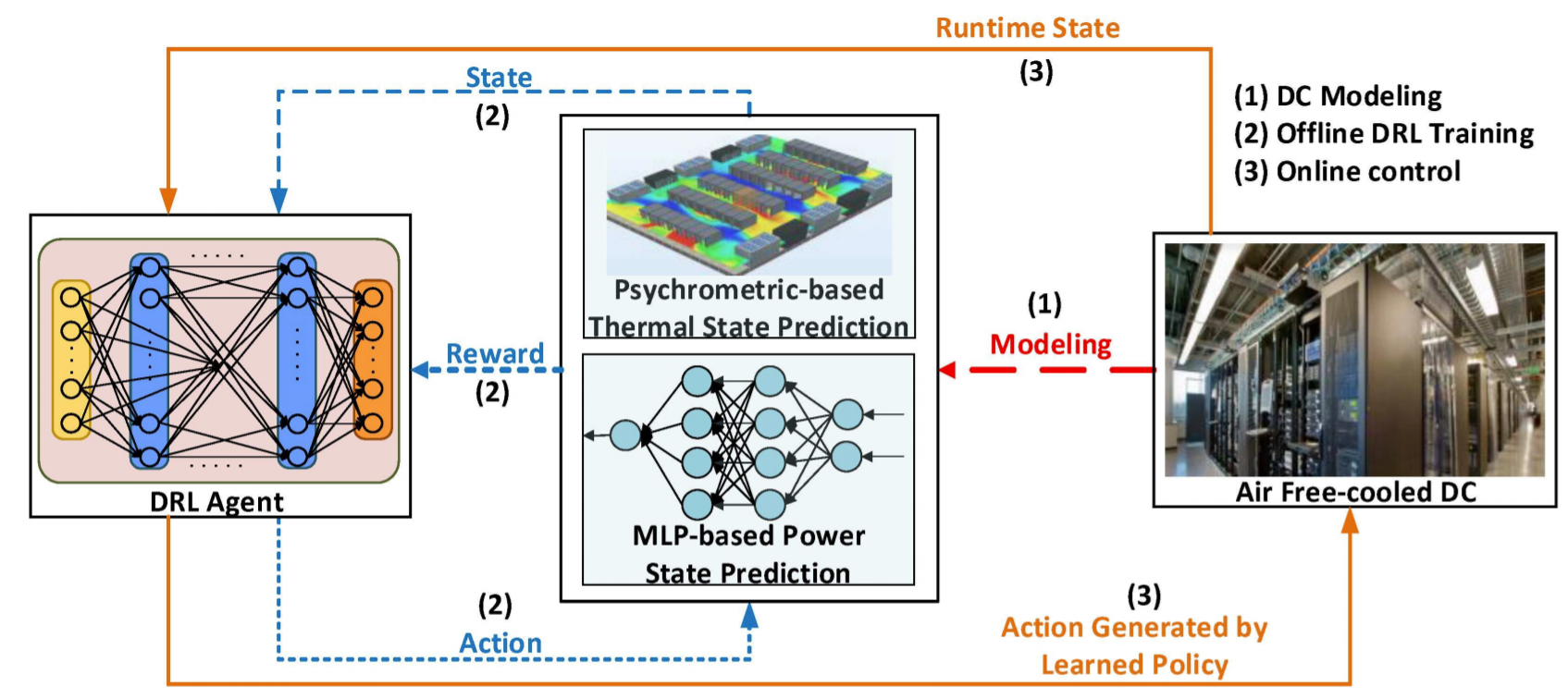
ntu.edu.sg Также будут исследованы возможности «Тропического ЦОД с воздушным охлаждением 2.0» — обновлённой версии системы, проектирование которой было начато в 2017 году. Она способна эффективно работать при повышенных температуре воздуха и влажности, что позволяет снизить энергопотребление оборудования воздухоподготовки. На уровне государства создание стенда для испытаний инновационных систем охлаждения поддержали национальный исследовательский фонд (NRF) и Агентство развития информационных технологий (IMDA). На реализацию проекта суммарно выделено $17 млн. 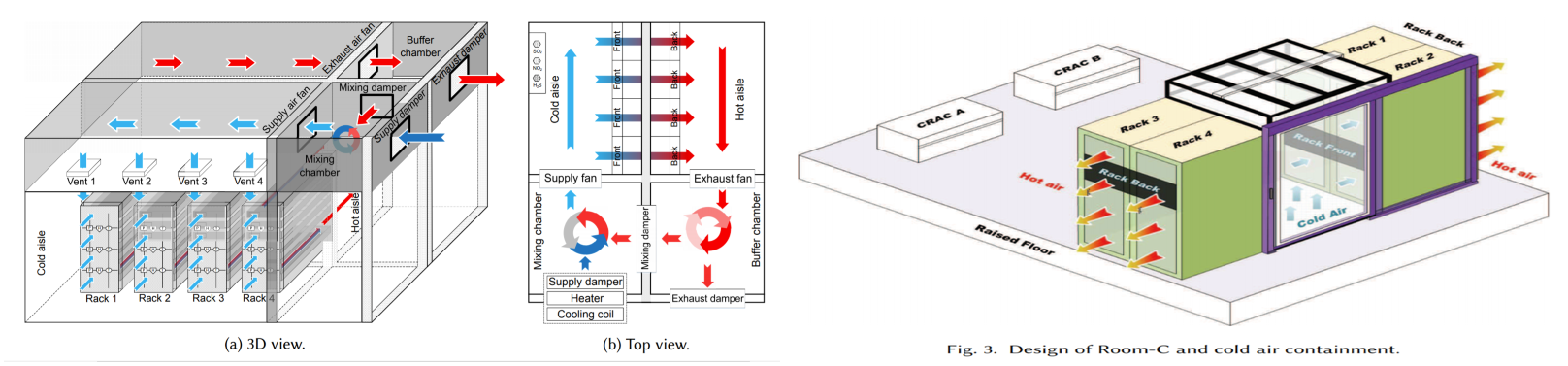
ntu.edu.sg Крупнейшим частным инвестором стала Facebook✴, которая ещё в 2018 году выбрала Сингапур для размещения крупного 11-этажного ЦОД мощностью 150 МВт. Энергию для него предоставят солнечные электростанции местной компании Sunseap, расположенные на крышах домов и воде. Энергоэффективность (PUE) объекта планируется на уровне 1,19. Для этого и нужна будет система жидкостного охлаждения StatePoint. Участники проекта надеются, что все эти технологии в совокупности помогут снизить энергопотребление в индустрии центров обработки данных на 40%, если они будут внедрены во всём тропическом регионе. Учитывая высокую долю ископаемого топлива в местной электроэнергетике, это позволит сократить выбросы парниковых газов на 25%.
13.06.2021 [20:13], Владимир Мироненко
Blackstone купила оператора ЦОД QTS Realty Trust за рекордную сумму в $10 млрдНа минувшей неделе стало известно о приобретении одного из крупнейших в мире операторов центров обработки данных QTS Realty Trust инвестиционной компанией Blackstone за рекордную для рынка сумму в $10 млрд. Blackstone приобрела акции QTS по цене $78/шт., что на 21 % выше их цены на момент закрытия биржевых торгов в день анонса сделки. Blackstone сообщила, что условия включают 24-процентную премию к средней цене акций QTS за последние три месяца. Условия контракта также включают 40-дневный период, в течение которого QTS вправе рассматривать и принимать более выгодные альтернативные предложения по её покупке. Как ожидается, после завершения сделки QTS сохранит нынешнее руководство и по-прежнему будет базироваться в Оверленд-Парке (Канзас, США). Blackstone заявила, что предоставит QTS все ресурсы и постоянный доступ к капиталу, что позволит расширить спектр услуг для поддержки существующих клиентов и привлечения новых. 
commercialsearch.com Компания отметила, что видит возможности быстрого и значительного роста на рынке дата-центров. Её словам вторит глава QTS Чад Уильямс (Chad Williams): «Мы видим значительную рыночную возможность для роста, поскольку гиперскейлеры и предприятия продолжают использовать нашу инфраструктуру мирового класса для поддержки своих инициатив по цифровой трансформации». Сделка является крупнейшим на сегодняшний день приобретением такого рода на рынке центров обработки данных. По данным Synergy Research Group, до этого объявления крупнейшими сделками по слиянию и поглощению ЦОД были приобретение компанией Digital Realty европейского конкурента Interxion за $8,4 млрд, поглощение Digital Realty в 2017 году DuPont Fabros за $7,6 млрд и последовательный выкуп долей в Global Switch промышленной группой Jiangsu Shagang Group, который в конечном итоге был оценён более чем в $8 млрд по сумме сделок, заключённых на протяжении трёх лет. 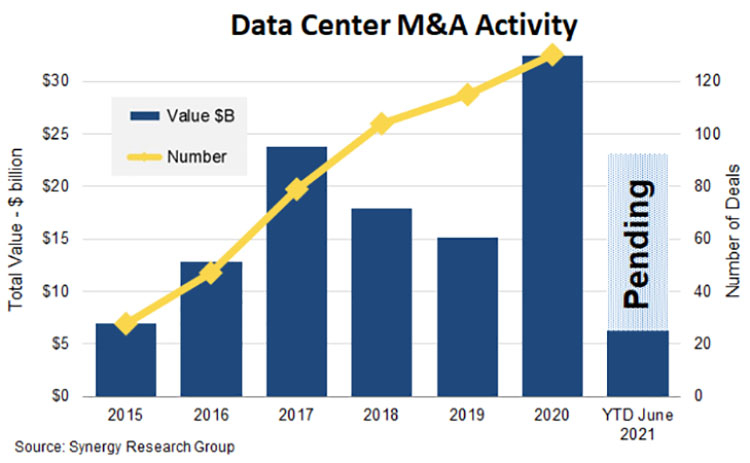 Этот также означает, что в 2021 году годовая стоимость слияний и поглощений на рынке ЦОД приближается к новому рекорду. Менее чем за шесть месяцев в году уже были закрыты или близки к завершению сделки на сумму более $6 млрд. Поскольку общая сумма транзакций вместе со сделкой по покупке QTS приближается к $17 млрд, можно ожидать, что в этом году будет превзойдено рекорд 2020 года — итоговая сумма сделок превысили отметку в $30 млрд.
09.06.2021 [23:00], Илья Коваль
Google соединит Северную и Южную Америку уникальным подводным интернет-кабелем FirminaGoogle объявила о планах проложить новый подводный кабель Firmina, который протянется от восточного побережья США до Лас-Тонинаса в Аргентине. В южной части он получит дополнительные ответвления до Прайя-Гранде (Бразилия) и Пунта-дель-Эсте (Уругвай). Кабель назван в честь бразильской писательницы и аболиционистки XIX века Марии Фирмины дос Рейс (Maria Firmina dos Reis). Кабель будет включать 12 оптоволоконных пар (ёмкость пока не уточняется) и позволит южноамериканским пользователям получить быстрый доступ с малой задержкой к продуктам Google, включая поиск, Gmail, YouTube и облачные сервисы Google Cloud. Этот кабель станет 16-м по счёту, в постройку которого вложилась Google. 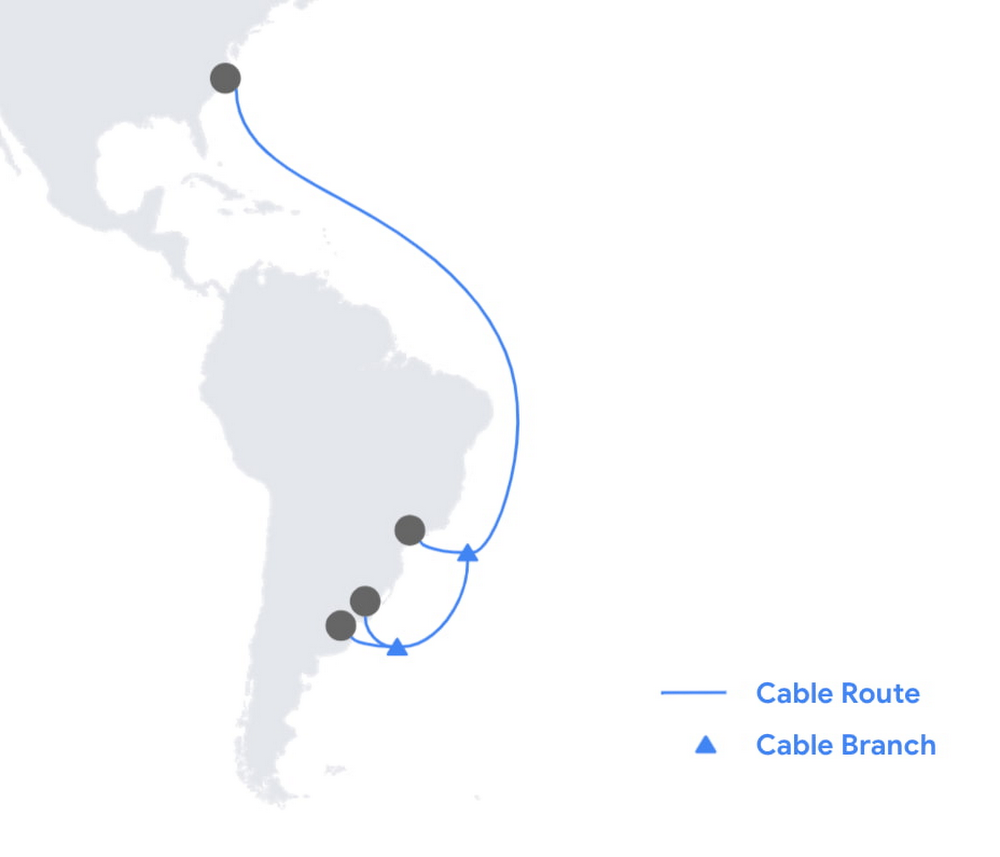 Уникальным Firmina делает то, что он будет самым длинным кабелем в мире, способным работать от одного источника питания на любом из его концов. Даже если один из источников станет временно недоступным, второй сможет обеспечить полную работоспособность кабеля, что повышает устойчивость и надёжность связи. Достигается это за счёт подачи более высокого (+20%) напряжения, чем в аналогичных решениях.  Обычным кабелям требуются дополнительные усилители, которые устанавливаются примерно через каждые 100 км. Для их питания необходимо высокое напряжение, которое подаётся с береговых станций. И если на коротких дистанциях можно организовать питание только с одного конца, то с увеличением длины кабеля и числа волокон это становится всё более трудной задачей.
06.06.2021 [22:07], Владимир Агапов
Nautilus превратит неработающую бумажную фабрику в ЦОД за $300 млнКомпания Nautilus Data Technologies, специализирующаяся на плавучих центрах обработки данных, объявила о том, что построит новый ЦОД на территории бывшей бумажной фабрики в Миллинокете (США, штат Мэн). Его энергетические потребности в 60 МВт полностью будут обеспечены местной гидроэлектростанцией. А система водяного охлаждения, питаемая из резервуара ГЭС, позволит сократить до 70% потребление энергии на охлаждение и до 30% выбросы CO2 в атмосферу. Запатентованная компанией двухконтурная система охлаждения позволит рециркулировать воду без загрязнения водоёма. А для достижения ещё более низкого показателя PUE, ЦОД разместится ниже водохранилища ГЭС, чтобы поток воды для охлаждения поступал под действием силы тяжести, а не требовал дополнительных насосов. 
Wikimedia: The Great Northern Paper Mill in the early 20th century Предприятие получит федеральные налоговые льготы, так как Миллинокет — один из экономически неблагополучных населённых пунктов. Для их преобразования в зоны «благоприятных возможностей» власти применяют финансовые стимулы, вплоть до освобождения от уплаты налогов компаний, инвестирующих в развитие общества. ЦОД Nautilus — первый, который будет построен в подобной зоне. Его клиентами станут местные предприятия: лаборатория Джексона и Торговая палата штата Мэн.  Возможность создания большого кампуса ЦОД вкупе с недорогой электроэнергией, вероятно, привлечет также гиперскейлеров и облачных провайдеров. Местная оптоволоконная сеть Three-Ring Binder, построенная в 2012 году, сможет обеспечить с транзитом через Бостон подключение с низкой задержкой к другим крупным узлам, включая Нью-Йорк, Чикаго и Лондон. Компания Nautilus приобрела комплекс площадью 13 акров, расположенный на месте бывшей фабрики, в 99-летнюю аренду у местной некоммерческой организации Our Katahdin. Первый этап проекта стоимостью $300 млн, как ожидается, будет завершён к концу 2022 года.
04.06.2021 [02:43], Владимир Агапов
В спецификации NVMe 2.0 официально вошла поддержка HDDВчера был опубликован релиз спецификаций NVMe 2.0. Из скромного протокола для блочных устройств хранения данных, использующих PCI Express, NVMe эволюционирует в один из самых важных и универсальных протоколов для хранилищ практически любого типа. Новые спецификации будут способствовать развитию экосистемы устройств NVMe: SSD, карт памяти, ускорителей и даже HDD. Вместо базовой спецификации для типовых PCIe SSD и отдельной спецификации NVMe-over-Fabrics (NVMe-oF), версия 2.0 изначально разработана как модульная и включает целый ряд отдельных стандартов: базовый набор (NVMe Base), отдельные наборы команд (NVM, ZNS, KV), спецификации транспортного уровня (PCIe, Fibre Channel, RDMA, TCP) и спецификации интерфейса управления (NVMe Management Interface). Вместе они определяют то, как программное обеспечение хоста взаимодействует с накопителями и пулами хранения данных через интерфейсы PCI Express, RDMA и т.д. 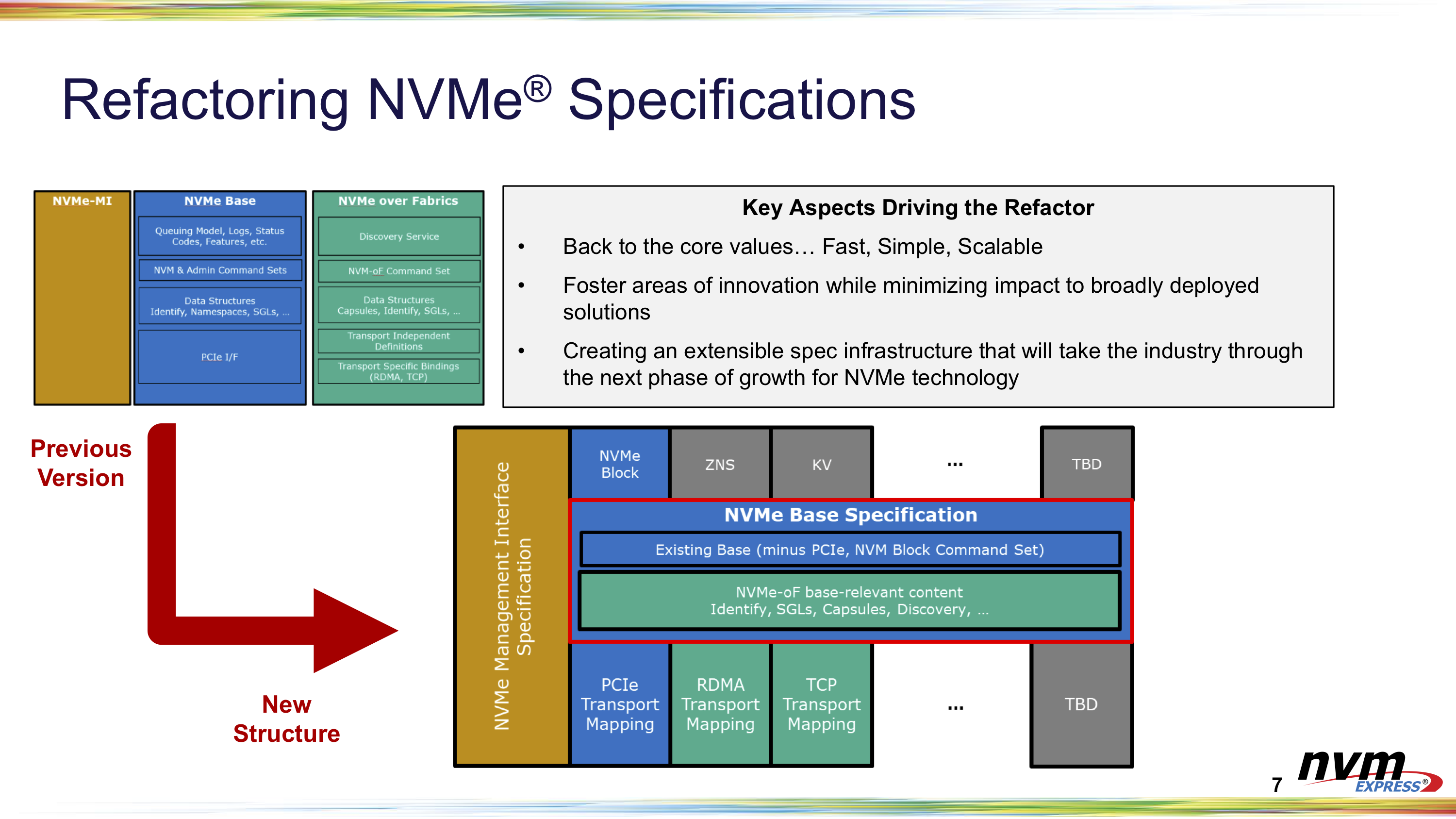 Базовая спецификация теперь охватывает и локальные устройства, и NVMe-oF, но является намного более абстрактной и не привязанной к реальному миру — было изъято столько всего, что её уже недостаточно для определения всей функциональности, необходимой для реализации даже простого SSD. Реальные устройства должны ссылаться ещё как минимум на одну спецификацию транспортного уровня и на одну спецификацию набора команд. В частности, для типовых SSD, к которым все привыкли, это означает использование спецификации транспорта PCIe и набора команд блочного хранилища. 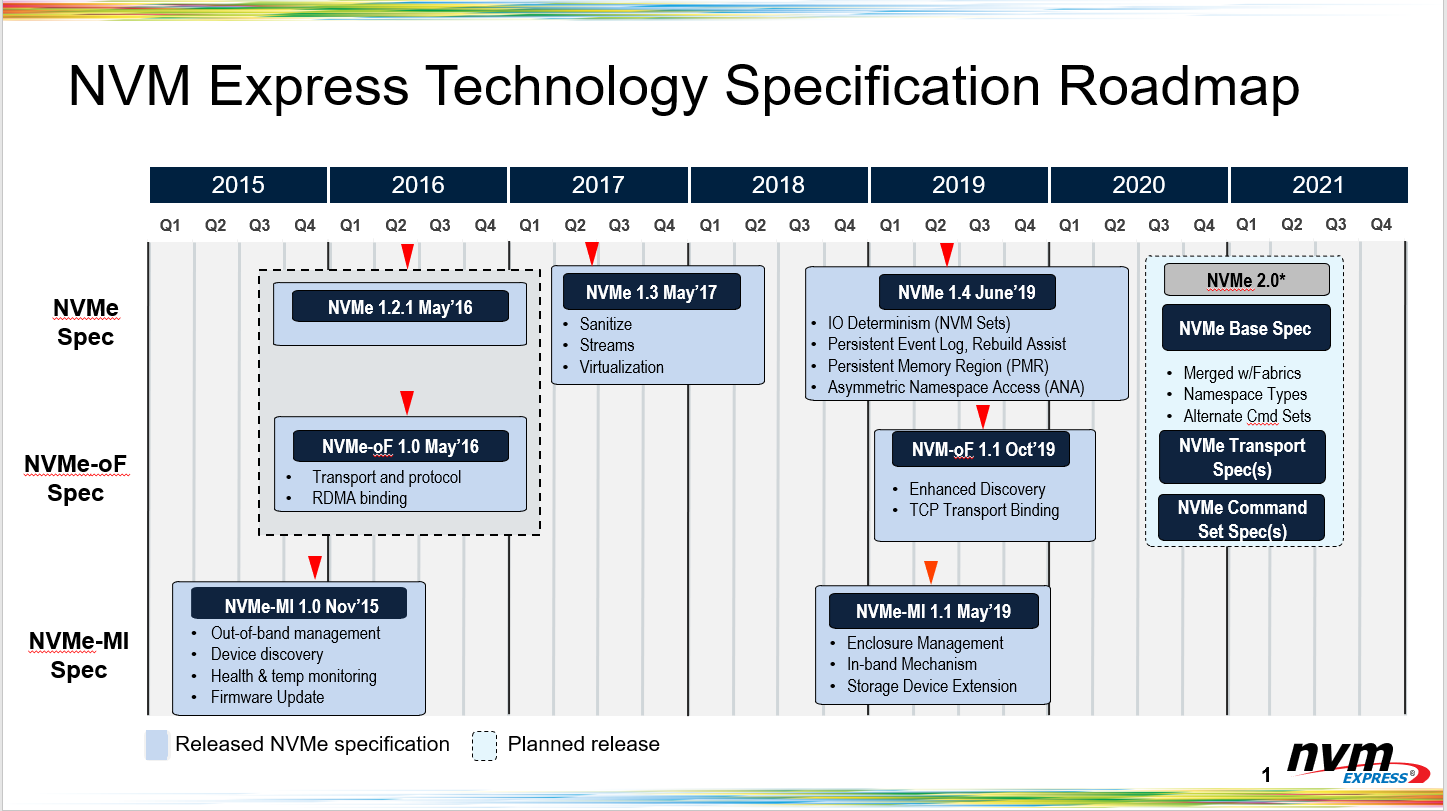 Три стандартизированных набора команд (блочный доступ, ZNS и Key-Value) охватывают области применения от простых твердотельных накопителей с «тонкими» абстракциями над базовой флеш-памятью до относительно сложных интеллектуальных накопителей, которые берут на себя часть задач по управлению хранением данных, традиционно выполнявшихся программным обеспечением на хост-системе. При этом различным пространствам имен, расположенным за одним контроллером, дозволено поддерживать разные наборы команд. 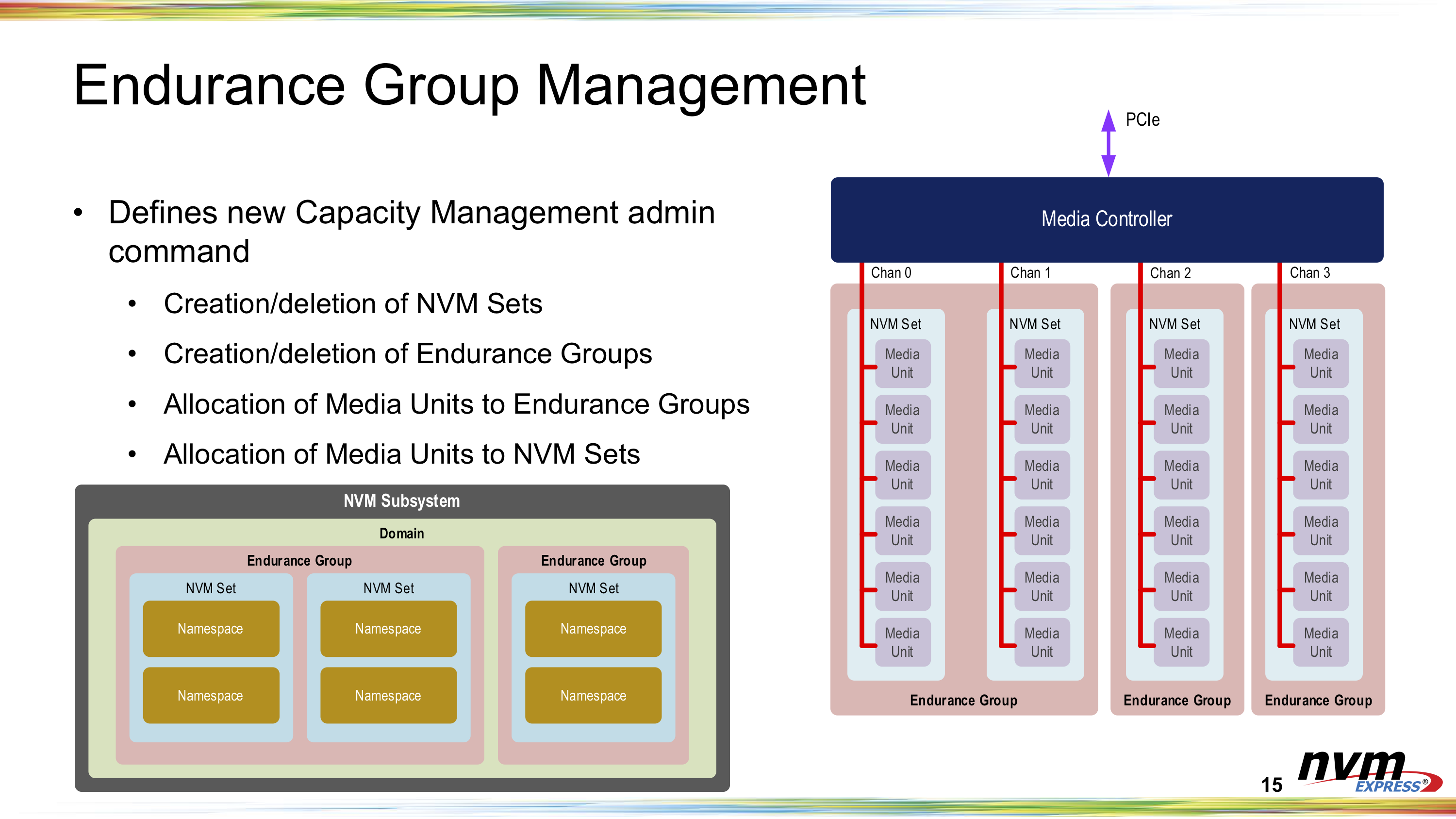 В NVMe 2.0 также добавлен стандартный механизм управления пулами хранения данных, который позволяет более тонко управлять нагрузкой в зависимости от производительности, ёмкости и выносливости конкретных устройств. Иерархия пулов также была расширена ещё одним уровнем доменов, внутри которых теперь существуют группы, где, в свою очередь, находятся отдельные наборы NVM-устройств.  Будущие наборы команд, например для вычислительных накопителей (computational storage), все еще находятся в стадии разработки и пока не готовы к стандартизации, но новый подход NVMe 2.0 позволит легко добавить их при необходимости. В принципе, в состав NVMe мог бы войти и стандарт Open Channel, но отрасль считает, что парадигма зонированного хранения обеспечивает более разумный баланс, и интерес к Open Channel SSD ослабевает в пользу ZNS-решений. 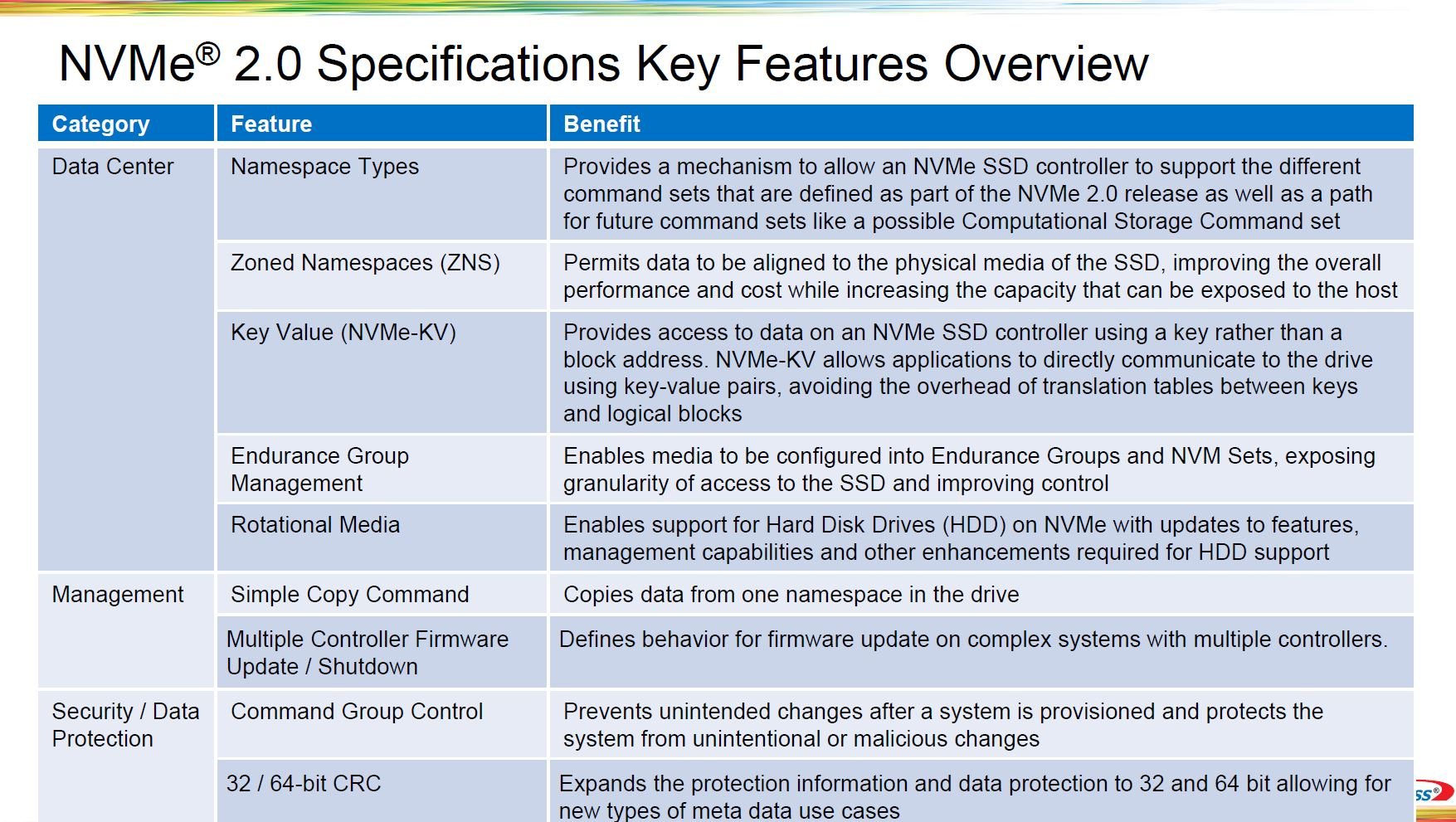 Из прочих изенений в NVMe 2.0 можно отметить поддержку 32-бит и 64-бит CRC, новые правила безопасного отключения устройств в составе общих хранилищ (при доступе через несколько контроллеров), более тонкое управление правами доступа — можно разрешить чтение и запись, но запретить команды, меняющие настройки или состояние накопителя — и дополнительные протоколы, касающиеся обновления прошивок.  Также в NVMe 2.0 появилась явная поддержка жёстких дисков. Хотя маловероятно, что HDD в ближайшее время перейдут на использование PCIe вместо SAS или SATA, поддержка таких носителей означает, что в будущем предприятия смогут унифицировать свои SAN c помощью NVMe-oF и отказаться от старых протоколов, таких как iSCSI. В целом, NVMe 2.0 приносит не та уж много новых функций, как это было с прошлыми версиями. Однако сама реорганизация спецификации поощряет итеративный подход и эксперименты с новыми функциями. Так что в ближайшие несколько лет, вероятно, обновления будут менее масштабными и станут выходить чаще.
02.06.2021 [19:14], Игорь Осколков
Южная Корея намерена разработать собственные CPU и ИИ-чипы для суперкомпьютеров и серверовЮжная Корея намерена добиться большей независимости в сфере разработки и производства чипов для серверов и суперкомпьютеров, в первую очередь для нужд внутри страны. По сообщению Министерства науки и ИКТ Южной Кореи, пять гиперскейлеров подписали меморандум о взаимопонимании с пятью производителями микросхем. Меморандум предполагает расширение использования отечественных технологий, в частности, ИИ-ускорителей в центрах обработки данных на территории страны. Производители и разработчики чипов — SK Group, Rebellions, FuriosaAI и Исследовательский институт электроники и телекоммуникаций — также согласились создать для этого новый технологический центр в Кванджу на юго-западе страны. 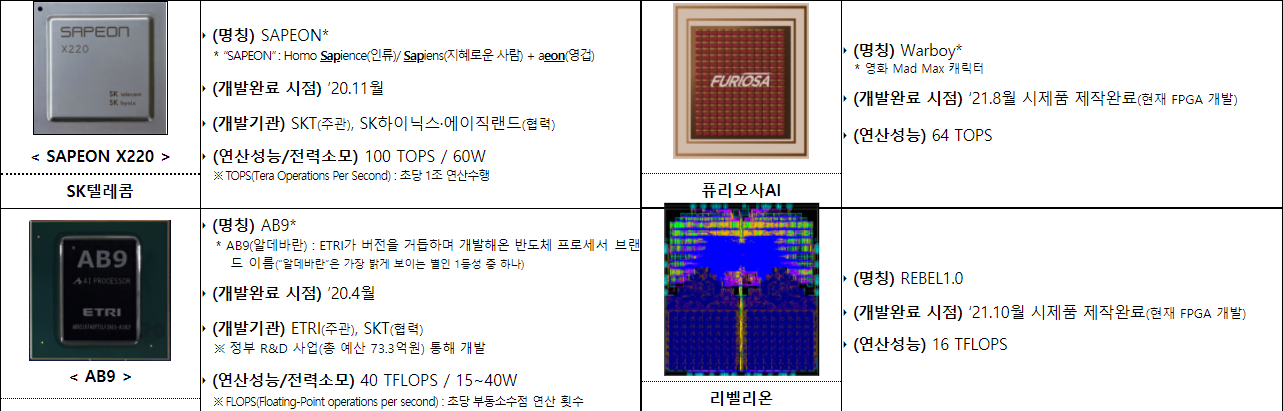 Отечественные чипы получат компании Naver Cloud, Douzone Bizon, Kakao Enterprise, NHN и KT. Все они являются крупными игроками на местном рынке и, каждая в своей области, довольно успешно конкурируют с зарубежными IT-гигантами. Это во многом напоминает ситуацию в Китае и Японии, которые также имеют сильных локальных игроков и вкладываются в разработку собственной микроэлектроники, чтобы быть менее зависимыми от США, как минимум, в области суперкомпьютинга. Несколько недель назад правительство объявило о пакете поддержки в размере 510 трлн вон ($451 млрд) для увеличения производства микросхем в стране, что принесёт пользу не только Samsung и SK Hynix, но и небольшим компаниям. Также ранее сообщалось, что Южная Корея намерена к 2030 году построить суперкомпьютер экзафлопсного класса на базе преимущественно «домашних» компонентов.
28.05.2021 [15:28], Сергей Карасёв
Marvell Bravera SC5 — первый в мире SSD-контроллер с поддержкой PCIe 5.0Компания Marvell анонсировала контроллеры Bravera SC5, предназначенные для построения серверных SSD нового поколения с интерфейсом PCIe 5.0. Представлены изделия MV-SS1331 и MV-SS1333 с восемью и шестнадцатью каналами доступа к NAND-памяти (до 1600 МТ/с) соответственно. В семейство Bravera впоследствии войдут и другие продукты. Здесь и ниже изображения Marvell Заявленная скорость последовательного чтения информации может достигать 14 Гбайт/с, скорость последовательной записи — 9 Гбайт/с. Производительность случайного чтения достигает 2 млн IOPS, записи — 1 млн IOPS. Задержка составляет менее 6 мкс, а функция Elastic SLA Enforcer позволит более тонко управлять приоритетами и очередями, а также собирать телеметрию на аппаратном уровне.  В составе изделий задействованы наборы ядер ARM Cortex-R8, Cortex-M7 и Cortex-M3. Есть аппаратные движки для шифрования и обеспечения безопасности. Контроллер поддерживает ECC-память DDR4-3200 и LPDDR4x-4266, а также NAND-чипы SLC/MLC/TLC/QLC от крупнейших производителей: Kioxia, Micron, Samsung, SK hynix, Western Digital и YMTC. Партнёрами в рамках запуска названы AMD, Intel и Renesas. 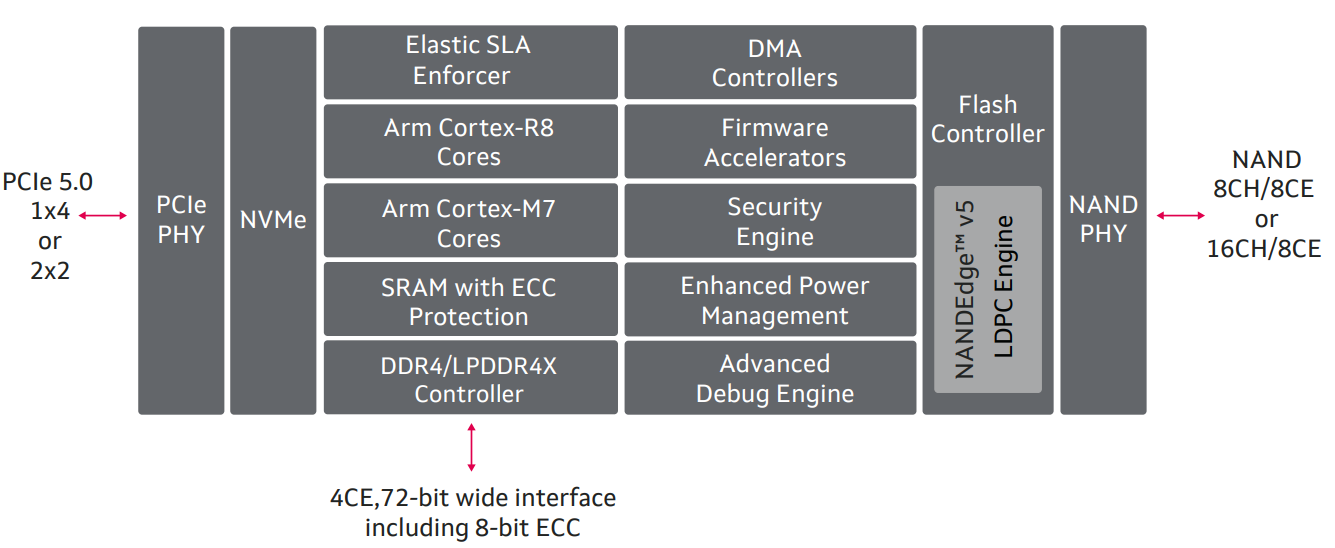 Контроллер поддерживает спецификации NVMe 1.4b и предлагает четыре линии PCIe 5.0 (x4 или два порта x2). Компания постаралась сделать его как можно более универсальным и подходящим как для нужд гиперскейлеров, так и для корпоративных решений. Он поддерживает стандарты ZNS, >Open Channel SSD, Kioxia SEF.  Пробные поставки образцов контроллеров уже начались. Первыми заказчиками стали Facebook✴ и Microsoft, развивающие стандарт OCP Cloud SSD, который несколько шире спецификаций NVMe. Именно на них ориентирована старшая, 16-канальная версия контроллера, которая благодаря своим габаритам (20 × 20 мм) позволяет создавать накопители в форм-факторе EDSFF E1.S. Правда, энергопотребление у неё выше, чем у 8-канальной — 9,8 Вт против 8,7 Вт.
28.05.2021 [00:33], Владимир Мироненко
Perlmutter стал самым мощным ИИ-суперкомпьютером в мире: 6 тыс. NVIDIA A100 и 3,8 ЭфлопсВ Национальном вычислительном центре энергетических исследований США (NERSC) Национальной лаборатории им. Лоуренса в Беркли состоялась торжественная церемония, посвящённая официальному запуску суперкомпьютера Perlmutter, также известного как NERSC-9, созданного HPE в партнёрстве с NVIDIA и AMD. Это самый мощный в мире ИИ-суперкомпьютер, базирующийся на 6159 ускорителях NVIDIA A100 и примерно 1500 процессорах AMD EPYC Milan. Его пиковая производительность в вычислениях смешанной точности составляет 3,8 Эфлопс или почти 60 Пфлопс в FP64-вычислениях. Perlmutter основан на платформе HPE Cray EX с прямым жидкостным охлаждением и интерконнектом Slingshot. В состав системы входят как GPU-узлы, так и узлы с процессорами. Для хранения данных используется файловая система Lustre объёмом 35 Пбайт скорость обмена данными более 5 Тбайт/с, которая развёрнута на All-Flash СХД HPE ClusterStor E1000 (тоже, к слову, на базе AMD EPYC). 
Perlmutter (Phase 1). Фото: NERSC Установка Perlmutter разбита на два этапа. На сегодняшней презентации было объявлено о завершении первого (Phase 1) этапа, который начался в ноябре прошлого года. В его рамках было установлено 1,5 тыс. вычислительных узлов, каждый из которых имеет четыре ускорителя NVIDIA A100, один процессор AMD EPYC Milan и 256 Гбайт памяти. На втором этапе (Phase 2) в конце 2021 года будут добавлены 3 тыс. CPU-узлов c двумя AMD EPYC Milan и 512 Гбайт памяти., а также ещё ещё 20 узлов доступа и четыре узла с большим объёмом памяти. 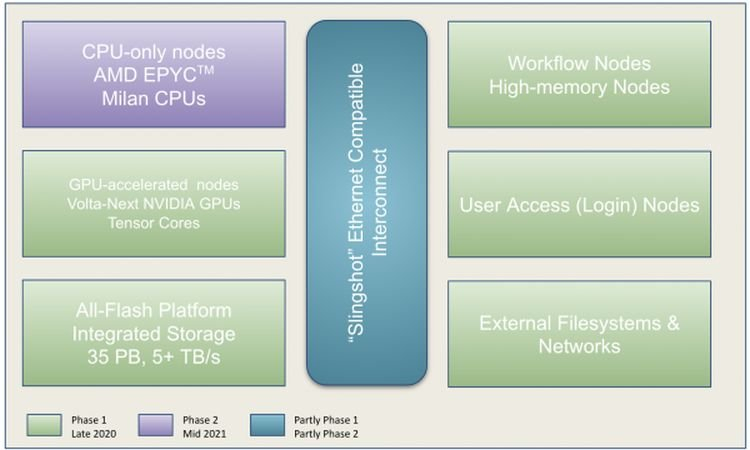
NERSC Также на первом этапе были развёрнуты служебные узлы, включая 20 узлов доступа пользователей, на которых можно подготавливать контейнеры с приложениями для последующего запуска на суперкомпьютере и использовать Kubernetes для оркестровки. Среда разработки будет включать NVDIA HPC SDK в дополнение к наборам компиляторов CCE (Cray Compiling Environment), GCC и LLVM для поддержки различных средств параллельного программирования, таких как MPI, OpenMP, CUDA и OpenACC для C, C ++ и Fortran. 
Фото: DESI Сообщается, что для Perlmutter готовится более двух десятков заявок на вычисления в области астрофизики, прогнозирования изменений климата и в других сферах. Одной из задач для новой системы станет создание трёхмерной карты видимой Вселенной на основе данных от DESI (Dark Energy Spectroscopic Instrument). Ещё одно направление, для которого задействуют суперкомпьютер, посвящено материаловедению, изучению атомных взаимодействий, которые могут указать путь к созданию более эффективных батарей и биотоплива. |
|

