Лента новостей
|
16.08.2021 [15:59], Сергей Карасёв
Facebook✴ и Google проложат в Тихом океане интернет-кабель длиной 12 тыс. км и ёмкостью 190 Тбит/сGoogle и Facebook✴ реализуют крупномасштабный проект под кодовым названием Apricot по обеспечению высокоскоростным интернет-доступом ряда стран Азиатско-Тихоокеанского региона. Речь идёт о прокладке подводной магистрали протяжённостью приблизительно 12 тыс. км. В рамках проекта будут проложены две волоконно-оптические линии — Echo и Bifrost. Они свяжут Азиатско-Тихоокеанский регион с Северной Америкой. В настоящее время проект ждёт одобрения со стороны регулирующих органов. Предполагается, что после ввода новых линий в эксплуатацию начальная пропускная способность превысит 190 Тбит/с. Магистраль свяжет Японию, Тайвань, Гуам, Филиппины, Индонезию и Сингапур. 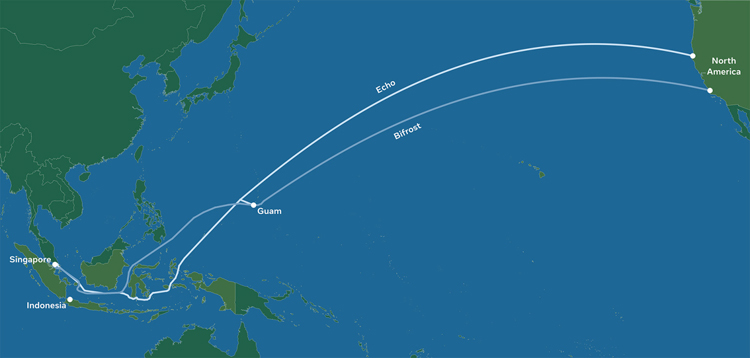 Завершить работы в рамках инициативы Apricot планируется в 2024 году. Проект поможет Google и Facebook✴ улучшить доступность своих многочисленных сервисов для пользователей в регионе. Отмечается, что каналы Echo и Bifrost смогут поддерживать растущие объёмы трафика для сотен миллионов пользователей и миллионов бизнес-структур.
30.07.2021 [21:05], Алексей Степин
Конец эпохи: Intel окончательно прекратила поставки процессоров ItaniumПервая попытка Intel покорить рынок массовых 64-бит систем окончилась неудачей — любопытная сама по себе архитектура Itanium (IA64) была несовместима со сложившейся экосистемой x86. Однако лишь сегодня в истории можно окончательно поставить точку: компания прекратила последние отгрузки процессоров Itanium. Сейчас поддержка 64-бит вычислений привычна и является частью любого достаточно современного процессора. Но так было не всегда: в конце 90-х и начале 2000-х ограничения, накладываемые 32-бит разрядностью хотя и были очевидны, рынок высокопроизводительных 64-бит процессоров для серверов и рабочих станций принадлежал компаниям Sun, Silicon Graphics, DEC и IBM. Все они имели RISC-архитектуру и не имели совместимости с x86. 
Форм-фактор Itanium: нечто среднее между слотовыми Pentium II/III и привычным PGA/LGA Itanium, или IA64, совместная разработка Intel и Hewlett-Packard, должна была вернуть этим компаниям первенство в сфере мощных CPU. И ставка была сделана на уникальную архитектуру EPIC (разновидность VLIW) с явным параллелизмом команд. Сама по себе IA64 обладала рядом преимуществ, однако требовала тонкой проработки ПО на уровне компилятора, поскольку процессоры EPIC во многом полагаются именно на него, а не на аппаратный планировщик. 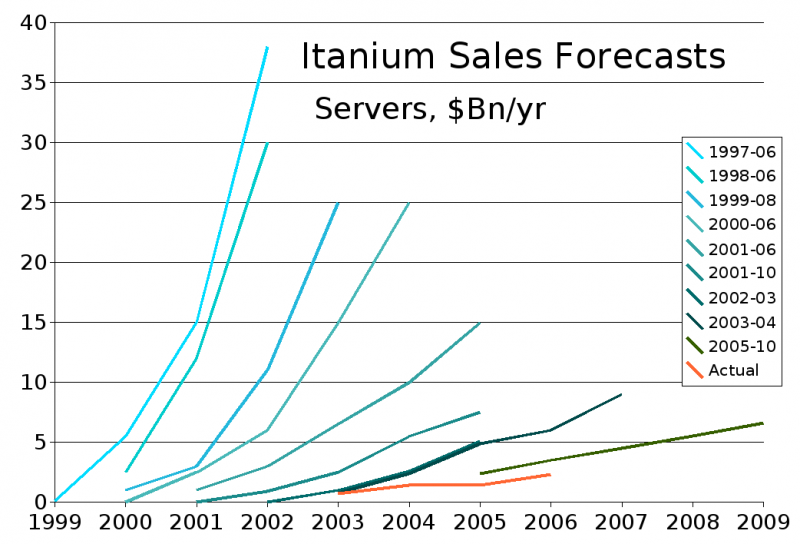
Itanium: радужные надежды и суровая реальность (красная линия) Отказ от последнего позволял потратить освободившийся транзисторный бюджет на более важные, по мнению Intel и HP, цели — например, на увеличение производительности вычислений с плавающей запятой. Но инфраструктура программного обеспечения к моменту анонса Itanium уже была весьма развитой. При этом новое, 64-бит ПО ещё надо было создать и, что гораздо важнее и сложнее, правильным образом оптимизировать, а уже имевшееся на новых CPU работало медленно из-за необходимости эмуляции x86. Компании пытались развивать IA64 до 2017 года, когда были представлены чипы Itanium Kittson с 8 ядрами и частотой до 2,66 ГГц, но то, что затея с новой архитектурой оказалась неудачной, было понятно уже после анонса первых процессоров AMD x86-64, полностью совместимых как с 32-бит, так и с 64-бит приложениями x86. В начале 2021 года Линус Торвальдс объявил о фактической смерти архитектуры и поддержка IA64 была исключена из новых ядер Linux. А сегодня можно говорить об окончательном завершении эры Itanium. 
Раритет: Supermicro i2DML-iG2 в форм-факторе EATX с поддержкой Itanium 2. Найти такую плату почти невозможно Сама Intel ещё в 2019-ом официально поставила на Itanium крест, но из-за сложившейся экосистемы заказы на процессоры принимались вплоть до 30 января 2020 года. А вчера компания официально объявила о прекращении поставок последних партий Itanium. Теперь ещё одна процессорная архитектура стала достоянием истории, хотя HPE формально будет поддерживать её до 2025 года. Сами CPU нередко встречаются на онлайн-аукционах, например, на Ebay, но даже для энтузиастов они малоинтересны — найти подходящую системную плату невероятно сложно, а стоить она может намного дороже самих процессоров, да и форм-фактор имеет специфический.
28.07.2021 [15:27], Алексей Степин
Pliops анонсировала высокопроизводительный DPU XDP ExtremeКонцепция сопроцессора данных (DPU) продолжает набирать популярность — анонсы новых решений в этой области следуют один за другим. Компания Pliops, ранее представившая ускоритель для СУБД, представила свой новый продукт — XDP Extreme, который имеет более широкую сферу применения и предназначен для разгрузки процессоров современных систем хранения данных, целиком построенных на энергонезависимой памяти. 
Источник изображений: Pliops Внешне новинка выглядит как обычная плата расширения с разъёмом PCIe x8, в основе лежит мощная ПЛИС производства Xilinx. В будущем компания планирует заменить её на более экономичный ASIC-вариант. У XDP Extreme нет сетевых портов, вместо этого разработчики сконцентрировали свои усилия на ускорении общих для СХД задач и повышении эффективности использования пула флеш-памяти. 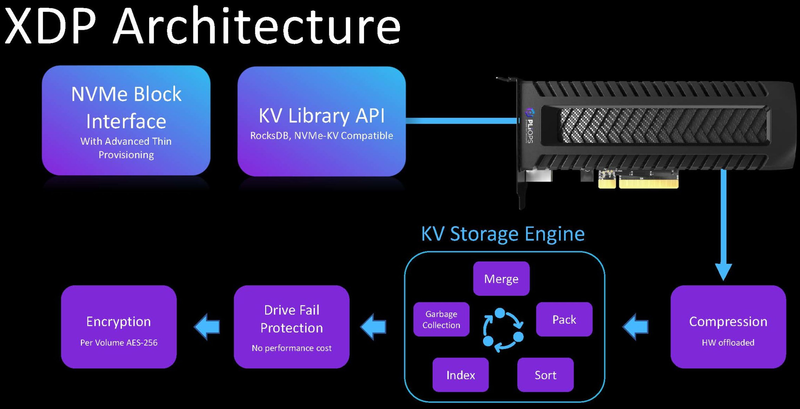 XDP использует так называемый KV Storage Engine — движок, работающий с Key-Value данными. За счёт фирменного API обеспечена совместимость со всеми приложениями, которые используют KV-подход. Уровнем ниже всё так же находится NVMe, как протокол, наиболее отвечающий устройствам на базе флеш-памяти. KV Storage Engine берёт на себя всю обработку ключей БД, включая их сортировку, индексацию и сборку мусора, а значит, этим не придётся заниматься центральным процессорам системы. Также ускоритель обеспечивает разгрузку ЦП при сжатии, отвечает за защиту от сбоев SSD и выполняет шифрование томов с использованием AES-256.  Востребованность XDP высока: KV-движки сегодня используются в подавляющем большинстве баз данных, также они применяются в комплексах машинной аналитики на базе Elastic или Hadoop и в распределённых файловых системах. Эффективность XDP Extreme, если верить данным Pliops, внушает уважение: даже на операциях чтения можно добиться двухкратного прироста линейной производительности, а выигрыш при записи может составлять и три-четыре раза. Более того, флеш-массив под управлением XDP оказывается быстрее, нежели классический RAID0. А снижение коэффициента усиления записи (write amplification) позволяет использовать недорогую, но априори менее надёжную память QLC. Впрочем, с Optane новый DPU тоже прекрасно работает.  Фактически, компания говорит о производительности, сопоставимой с решениями на базе DRAM, но с куда более низкой стоимостью владения. Экономия достигается и за счёт более эффективного использования SSD: в частности, при равном уровне надёжности с классическим массивом RAID 10, система на базе Pliops XDP позволяет обойтись меньшим количеством серверов и накопителей, что, естественно, отразится и на стоимости. Поставки новых ускорителей Pliops XDP Extreme уже развёрнуты.
16.07.2021 [17:31], Алексей Степин
Японский облачный суперкомпьютер ABCI подвергся модернизацииПопулярность идей машинного обучения и искусственного интеллекта приводит к тому, что многие страны и организации планируют обзавестись HPC-системами, специально предназначенными для этого класса задач. В частности, Токийский университет совместно с Fujitsu модернизировал существующую систему ABCI (AI Bridging Cloud Infrastructure), снабдив её новейшими процессорами Intel Xeon и ускорителями NVIDIA. Как правило, когда речь заходит о суперкомпьютерах Fujitsu, вспоминаются уникальные наработки компании в сфере HPC — процессоры A64FX, но ABCI имеет более традиционную гетерогенную архитектуру. Изначально этот облачный суперкомпьютер включал в себя вычислительные узлы на базе Xeon Gold и ускорителей NVIDIA V100, объединённых 200-Гбит/с интерконнектом. В качестве файловой системы применена разработка IBM — Spectrum Scale. Это одна систем, специально созданных для решения задач искусственного интеллекта, при этом доступная независимым исследователям и коммерческим компаниям. 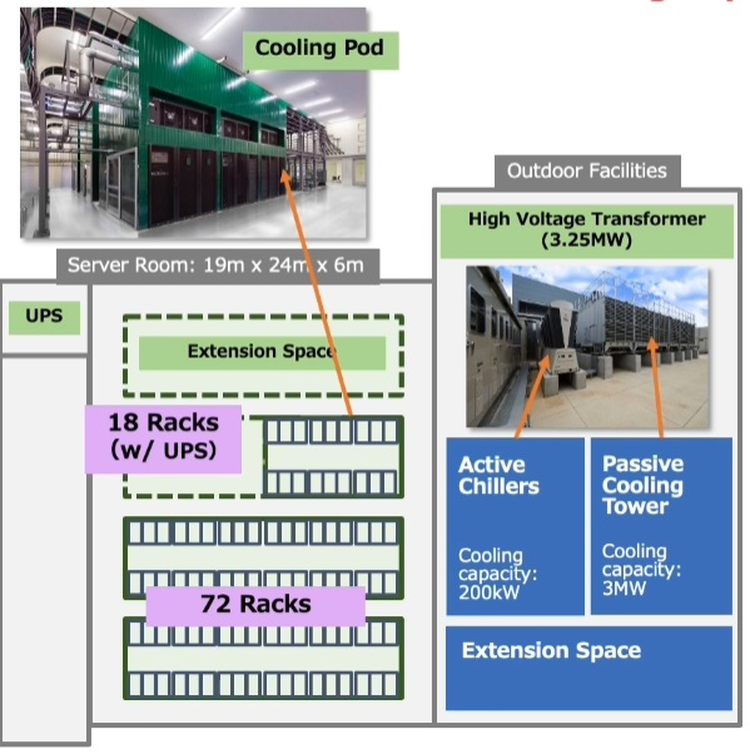 Так, 86% пользователей ABCI не входят в состав Японского национального института передовых технических наук (AIST); их число составляет примерно 2500. Но система явно нуждалась в модернизации. Как отметил глава AIST, с 2019 года загруженность ABCI выросла вчетверо, и сейчас на ней запущено 360 проектов, 60% из которых от внешних заказчиков. Сценарии использования самые разнообразные, от распознавания видео до обработки естественных языков и поиска новых лекарств. 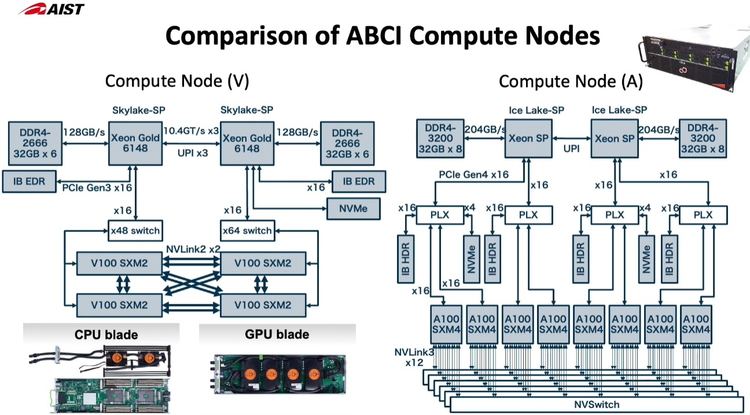
Новые узлы ABCI 2.0 заметно отличаются по архитектуре от старых Как и в большей части систем, ориентированных на машинное обучение, упор при модернизации ABCI был сделан на вычислительную производительность в специфических форматах, включая FP32 и BF16. Изначально в состав ABCI входило 1088 узлов, каждый с четырьмя ускорителями V100 формата SXM2 и двумя процессорами Xeon Gold 6148. После модернизации к ним добавилось 120 узлов на базе пары Xeon Ice Lake-SP и восьми ускорителей A100 формата SXM4. Здесь вместо InfiniBand EDR используется уже InfiniBand HDR. 
Стойка с новыми вычислительными узлами ABCI 2.0 Согласно предварительным ожиданиям, производительность обновлённого суперкомпьютера должна вырасти практически в два раза на задачах вроде ResNet50, в остальных случаях заявлен прирост производительности от полутора до трёх раз. На вычислениях половинной точности речь идёт о цифре свыше 850 Пфлопс, что вплотную приближает ABCI к системам экза-класса. Разработчики также надеются повысить энергоэффективность системы путём применения специфических ускорителей, включая ASIC, но пока речь идёт о связке Intel + NVIDIA. ABCI и сейчас можно назвать экономичной системой — при максимальной общей мощности комплекса 3,25 МВт сам суперкомпьютер при полной нагрузке потребляет лишь 2,3 МВт. Поскольку система ориентирована на предоставление вычислительных услуг сторонним заказчикам, модернизировано и системное ПО, в котором упор сместился в сторону контейнеризации.
06.07.2021 [23:41], Владимир Мироненко
Пентагон аннулировал облачный контракт JEDI c Microsoft на $10 млрдПентагон аннулировал облачный контракт Joint Enterprise Defense Infrastructure (JEDI) на сумму $10 млрд, заключённый в 2019 году с Microsoft и ставший предметов судебных исков ряда других соискателей, включая Amazon AWS. Amazon считалась главным претендентом на получение контракта JEDI, но получила его Microsoft, обойдя и других конкурентов, включая IBM и Oracle, которые пытались обжаловать формат проведения конкурса. В заявлении военного ведомства указано, что «из-за меняющихся требований, увеличения доступности облачных вычислений и достижений отрасли контракт JEDI Cloud больше не отвечает его потребностям». Министерство обороны США будет придерживаться нового контракта под названием Joint Warfighter Cloud Capability (JWCC), который, как ожидается, будет заключён с Microsoft и Amazon и, возможно, с другими подрядчиками. 
STAFF/AFP/Getty Images Пентагон заявил, что поставщик облачных услуг для нового контракта должен будет соответствовать нескольким критериям, например, работать на всех трёх уровнях классификации (т.е. несекретно, секретно или совершенно секретно), быть доступным по всему миру и иметь средства контроля кибербезопасности высшего уровня. Последней каплей, вероятно, стала очередная судебная жалоба Oracle, поданная на прошлой неделе. «Министерство обороны столкнулось с трудным выбором: продолжить судебную тяжбу, которая может длиться годами, или найти другой путь продвижения вперед, — пишет Тони Таунс-Уитли (Toni Townes-Whitley), президент Microsoft Regulated Industries. — Безопасность США важнее любого отдельного контракта, и мы знаем, что Microsoft преуспеет, когда у страны все будет хорошо <…> мы уважаем и принимаем решение Министерства обороны США двигаться вперёд по другому пути для обеспечения безопасности критически важных технологий». Microsoft и Amazon жёстко конкурируют на рынке облачных вычислений. В прошлом году на конференции компании re: Invent бывший руководитель Amazon Web Services Энди Ясси (Andy Jassy), вступивший на этой неделе в должность генерального директора Amazon, представил статистику, согласно которой доля AWS на рынке облачной инфраструктуры составляет 45%, что более чем вдвое превышает долю Microsoft Azure. Но Microsoft понемногу отвоёвывает долю рынка. В майском отчете Wedbush прогнозируется дальнейший рост Microsoft, поскольку облачные технологии Azure «все ещё находятся на начальном этапе», и компания «имеет твёрдые позиции для увеличения доли рынка по сравнению с AWS в этой гонке облачных вооружений».
04.07.2021 [14:03], Сергей Карасёв
Yotta и Piql запустили сервис долгосрочного хранения данных на фотоплёнкеИндийский оператор центров обработки данных Yotta в партнёрстве с норвежской фирмой Piql запустил сервис долгосрочного хранения информации на плёнке. Система под названием Yotta Preserve ориентирована на компании и организации, которым необходимо создание архивов разнородных сведений. Новая система использует проприетарную плёнку piqlFilm. Её заявленная долговечность составляет от 500 до 1000 лет. 
Здесь и ниже изображения Piql «Yotta Preserve предлагает лучшее из двух миров: архивные данные могут быть защищены на физическом уровне и доступны в цифровом виде», — отмечает Yotta. Плёнка рассчитана на хранение аналоговой и цифровой информации, видео, аудиоматериалов, рукописных документов и «любого другого контента на планете». О том, где физически будет храниться плёнка в рамках сервиса Yotta Preserve и как планируется предоставлять доступ к системе, компании ничего не сообщают.  Система piqlFilm предполагает преобразование данных в некое подобие QR-кодов, которые хранятся на 35-ммй плёнке. Дополнительно могут быть сохранены иллюстрации и рукописные инструкции, объясняющие, как можно расшифровать эти коды — на случай, если технология будет утрачена через несколько поколений. Piql известна тем, что отправила на длительное хранение в специально оборудованную шахту в условиях вечной мерзлоты на острове Шпицберген 21 Тбайт данных с GitHub.
30.06.2021 [22:59], Владимир Агапов
Не только омары: второй дата-центр Green Mountain обогреет форелевую ферму в НорвегииС тех пор, как норвежская компания Green Mountain придумала направлять отработанное тепло своего ЦОД DC1-Stavenger на ферму по разведению омаров, концепция утилизации «мусорного» тепла получила дальнейшее развитие. Теперь оператор дата-центров хочет обогреть и крупнейшую в мире наземную форелевую ферму Hima Seafood. Ожидается, что предприятие сможет производить до 9000 т форели в год, а выбросы углекислого газа от его работы будут минимальными. Форелевое хозяйство разместится в 800 м от дата-центра DC2-Telemark в Рьюкане (Норвегия) и будет подключено системой трубопроводов к его контурам охлаждения. С помощью теплообменников Hima использует тепло ЦОД для получения нужной температуры в системе RAS и вернёт обратно остывшую воду, создав таким образом технологию замкнутого цикла. 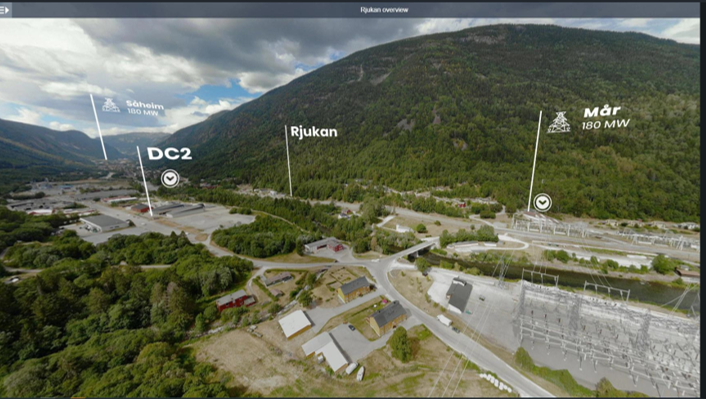
Источник изображений: Green Mountain По словам генерального директора компании Hima, Джо МакЭлви (Joe McElwee), обеспечение постоянной и стабильной температуры воды является ключом ко всему производству рыбной продукции мирового уровня и возможность её получения от ЦОД является беспроигрышным решением для обеих сторон. Строительство начнётся в этом году, а ввод в эксплуатацию намечен на 2023 году. 
Hima Seafood «Хотя наши дата-центры и работают на 100% возобновляемой гидроэнергии, мы не хотим, чтобы какая-либо её часть расходовалась впустую. Этот проект является примером циркулярной экономики, когда продукция одной компании может приносить не только экономическую, но и экологическую выгоду для другой. Мы стремимся к новым экологическим стандартам и надеемся, что наше совместное предприятие будет этому способствовать" — добавил генеральный директор Green Mountain Тор Кристиан Гюланд (Tor Kristian Gyland).
30.06.2021 [22:44], Алексей Степин
Marvell анонсировала 5-нм DPU Octeon 10: 36 ядер ARM Neoverse N2, 400GbE, PCIe 5.0 и DDR5Концепция ускорителя для работы с данными, выделенного DPU, продолжает набирать популярность. В последнее время целый ряд компаний представил свои решения. А на днях очередь дошла до крупного разработчика микроэлектроники, компании Marvell, которая анонсировала DPU серии Octeon 10. Новые сопроцессоры построены на основе наиболее совершенного 5-нм техпроцесса TSMC и должны на равных сражаться с такими соперниками, как ускорители NVIDIA BlueField. Сама Marvell известна разработкой собственных вычислительных ядер, однако в Octeon 10 от этого подхода компания отошла, вернувшись к лицензированию ядер ARM — в основу новой серии чипов легли ядра Neoverse N2. 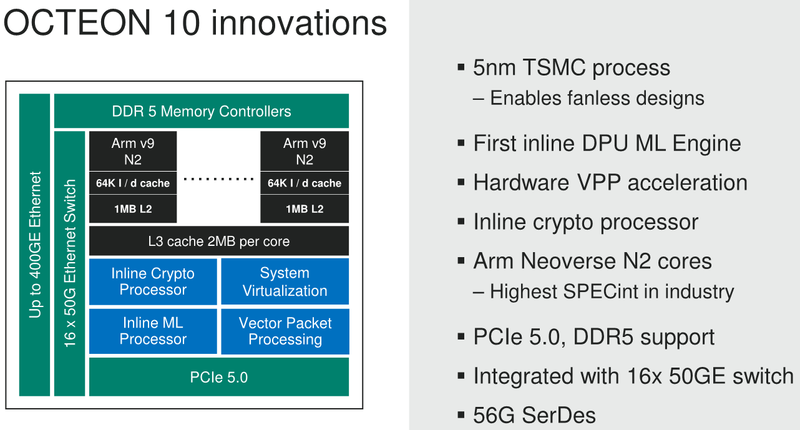 В основе данной архитектуры лежит набор команд ARM v9, появившийся не так уж давно. В сравнении с решениями на базе ARM v8.x эта архитектура может обеспечивать до 40% прироста в производительности, в том числе, за счёт поддержки 128-битных векторных расширений SVE2 и развитой подсистемы кешей. Процессорные ядра в Octeon 10 располагают по 1 и 2 Мбайт кешей второго и третьего уровня на каждое ядро. 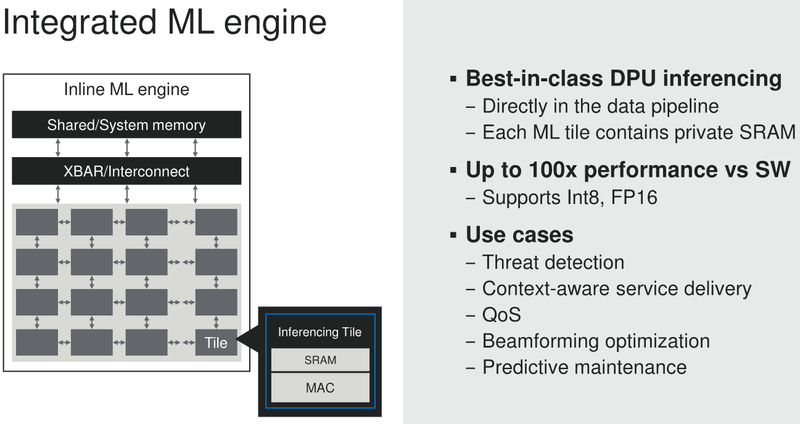 В составе новой SoC также присутствуют блоки ускорения сетевых задач и криптографические акселераторы. Кроме этого, кремний Octeon 10 получил и сетевой коммутатор, обеспечивающий работу 16 портов Ethernet со скоростью 50 Гбит/с. «Прокормить» столь требовательную «семью» непросто, но в плане подсистем ввода-вывода новые DPU также отвечают современным реалиям: они рассчитаны на работу с памятью DDR5-5200 и поддерживают интерфейс PCI Express 5.0, блоки SerDes относятся к поколению 56G. 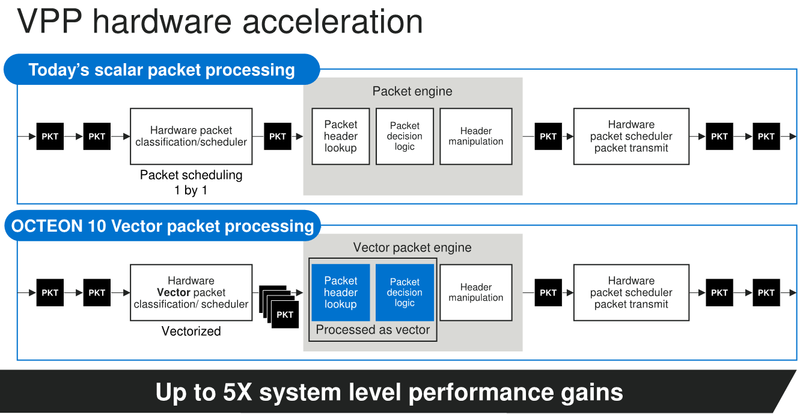 Отдельного упоминания заслуживает движок векторной обработки пакетов (Vector Packet Processing Engine), способный объединять в единую серию сетевые пакеты и «переваривать» их одновременно, как векторные данные. Такой подход позволяет серьёзно снизить латентность, что для DPU очень важно. Имеются в составе Octeon 10 и средства для работы с алгоритмами машинного обучения, причём каждый «тайл», поддерживающий INT8 и FP16, имеет свой объём SRAM. 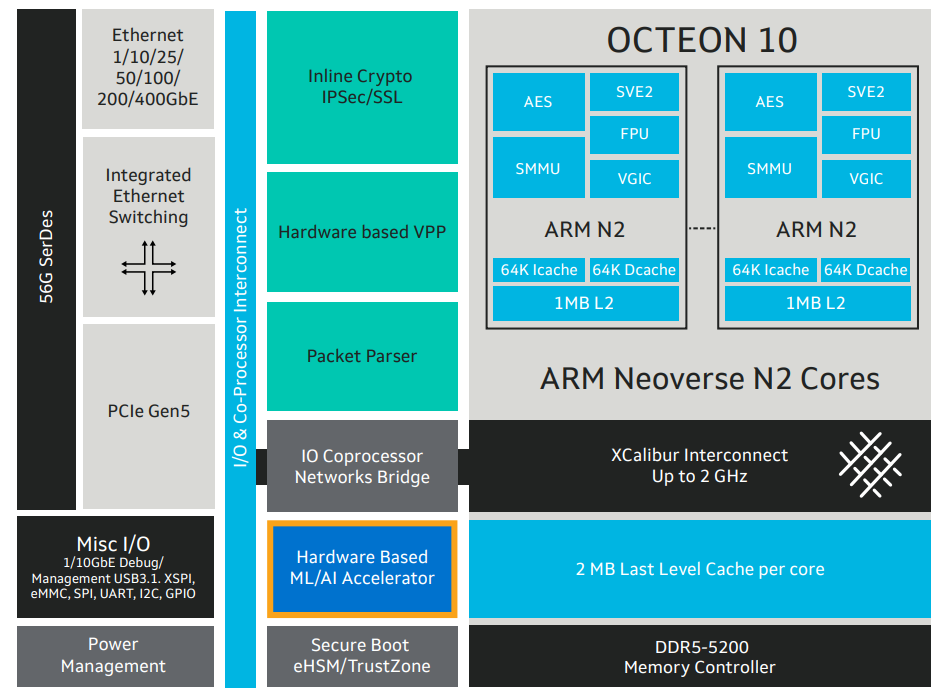 Пока семейство Octeon 10 представлено четырьмя моделями, младшая из которых может содержать до 8 ядер Neoverse N2, а старшая — до 36 таких ядер, причём о масштабировании подсистемы памяти разработчики также подумали и число контроллеров DDR5 в новых чипах варьируется от 2 до 12. Несмотря на столь солидные характеристики, теплопакеты удалось удержать в разумных рамках, и даже у наиболее мощной версии DPU400 TDP составляет всего 60 Ватт. 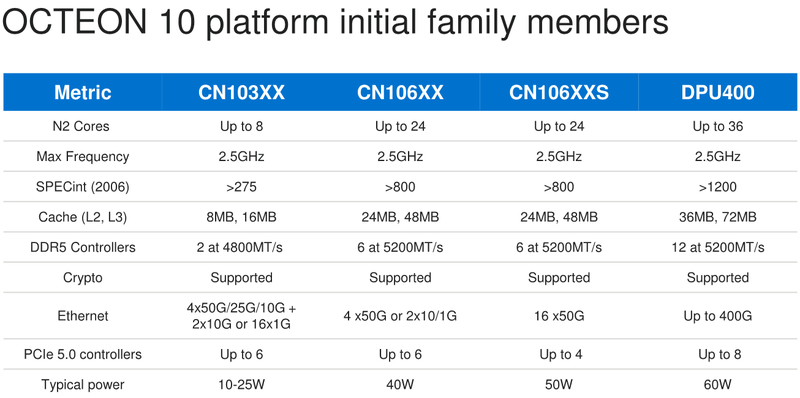 В настоящее время Marvell Octeon 10 уже находится в производстве, первые же партии новых чипов должны поступить к заказчикам во второй половине этого года. Столь многогранные DPU должны найти применение в самых разных сценариях, от поддержания инфраструктуры 5G RAN до работы в составе облачных систем, а также в высокопроизводительных маршрутизаторах.
29.06.2021 [17:49], Алексей Степин
Cornelis Networks подняла упавшее знамя Intel Omni-PathОт собственной технологии интерконнекта Omni-Path (OPA) компания Intel довольно неожиданно отказалась летом 2019 года, хотя на тот момент OPA-решения составляли достойную конкуренцию InfiniBand EDR, Ethernet и проприетарным интерконнектам как по скорости, так и по уровню задержки и поддержки необходимых для высокопроизводительных вычислений (HPC) функций. В конце прошлого года все наработки по OPA перешли к компании Cornelis Networks, образованной выходцами из Intel. В арсенале Intel были процессоры Xeon и Xeon Phi со встроенным интерфейсом Omni-Path, PCIe-адаптеры, коммутаторы и сопутствующее ПО. Казалось бы, у технологии большое будущее, однако второе поколение шины OPA, поддерживающее скорость 200 Гбит/с, так и не было выпущено, а компания сосредоточилась на Ethernet. При этом NVIDIA уже анонсировала InfiniBand NDR (400 Гбит/c), да и 200GbE-решениями сейчас никого не удивить.  Однако идеи, заложенные в Omni-Path, не умерли, и упавшее знамя нашлось, кому подхватить. Cornelis Networks быстро принялась за дело — через месяц после представления компании уже были представлены новые машины с Omni-Path, причём как на базе Intel, так и на базе AMD. А на ISC 2021 Cornelis Networks анонсировала полный спектр собственных решений под брендом Omni-Path Express, реализующих все основные достоинства технологии.  Конечно, процессоров с разъёмом Omni-Path мы по понятным причинам уже не увидим, но компания предлагает низкопрофильные хост-адаптеры с пропускной способностью до 25 Гбайт/с (100 Гбит/с в каждом направлении). Они поддерживают открытый фреймворк Open Fabrics Interface (OFI) и предлагают коррекцию ошибок с нулевой латентностью. В качестве разъёма используется популярный в индустрии QSFP28.  Также представлен ряд коммутаторов. В серии CN-100SWE есть модели с поддержкой горячей замены, которые имеют 48 портов и общую пропускную способность до 1,2 Тбайт/с при латентности, не превышающей 110 нс. Поддерживается организация виртуальных линий Omni-Path Express и фреймы большого размера, от 2 до 10 Кбайт. При этом коммутаторы компактны и занимают всего 1 слот в стандартной стойке.  Директор CN-100SWE предназначен для крупных кластерных систем. Он является модульным и может занимать от 7U до 20U, реализуя при этом от 288 до 1152 портов Omni-Path Express со скоростью 100 Гбит/с на порт. Латентность при этом не превышает 340 нс. Для сравнения, сети на базе Ethernet, как правило, оперируют значениями в десятки миллисекунд в лучшем случае.  Технологиями Cornelis Networks уже заинтересовался крупный российский поставщик HPC-систем, группа компаний РСК, которая и ранее поставляла кластеры и суперкомпьютеры с Omni-Path, в том числе с коммутаторами, снабжёнными фирменной СЖО. РСК получила наивысший партнёрский статус Elite+ у Cornelis и уже готова интегрировать Omni-Path Express в системы «РСК Торнадо» на базе третьего поколения процессоров Xeon Scalable.
28.06.2021 [13:22], Алексей Степин
Обновление NVIDIA HGX: PCIe-вариант A100 с 80 Гбайт HBM2e, InfiniBand NDR и Magnum IO с GPUDirect StorageНа суперкомпьютерной выставке-конференции ISC 2021 компания NVIDIA представила обновление платформы HGX A100 для OEM-поставщиков, которая теперь включает PCIe-ускорители NVIDIA c 80 Гбайт памяти, InfiniBand NDR и поддержку Magnum IO с GPUDirect Storage. В основе новинки лежат наиболее продвинутые на сегодняшний день технологии, имеющиеся в распоряжении NVIDIA. В первую очередь, это, конечно, ускорители на базе архитектуры Ampere, оснащённые процессорами A100 с производительностью почти 10 Тфлопс в режиме FP64 и 624 Топс в режиме тензорных вычислений INT8.  HGX A100 предлагает 300-Вт версию ускорителей с PCIe 4.0 x16 и удвоенным объёмом памяти HBM2e (80 Гбайт). Увеличена и пропускная способность (ПСП), в новой версии ускорителя она достигла 2 Тбайт/с. И если по объёму и ПСП новинки догнали SXM-версию A100, то в отношении интерконнекта они всё равно отстают, так как позволяют напрямую объединить посредством NVLink только два ускорителя.  В качестве сетевой среды в новой платформе NVIDIA применена технология InfiniBand NDR со скоростью 400 Гбит/с. Можно сказать, что InfiniBand догнала Ethernet, хотя не столь давно её потолком были 200 Гбит/с, а в плане латентности IB по-прежнему нет равных. Сетевые коммутаторы NVIDIA Quantum 2 поддерживают до 64 портов InfiniBand NDR и вдвое больше для скорости 200 Гбит/с, а также имеют модульную архитектуру, позволяющую при необходимости нарастить количество портов NDR до 2048. Пропускная способность при этом может достигать 1,64 Пбит/с.  Технология NVIDIA SHARP In-Network Computing позволяет компании заявлять о 32-крантом превосходстве над системами предыдущего поколения именно в области сложных задач машинного интеллекта для индустрии и науки. Естественно, все преимущества машинной аналитики используются и внутри самого продукта — технология UFM Cyber-AI позволяет новой платформе исправлять большинство проблем с сетью на лету, что минимизирует время простоя.  Отличным дополнением к новым сетевым возможностями является технология GPUDirect Storage, которая позволяет NVMe-накопителям общаться напрямую с GPU, минуя остальные компоненты системы. В качестве программной прослойки для обслуживания СХД новая платформа получила систему Magnum IO с поддержкой вышеупомянутой технологии, обладающую низкой задержкой ввода-вывода и по максимуму способной использовать InfiniBand NDR. 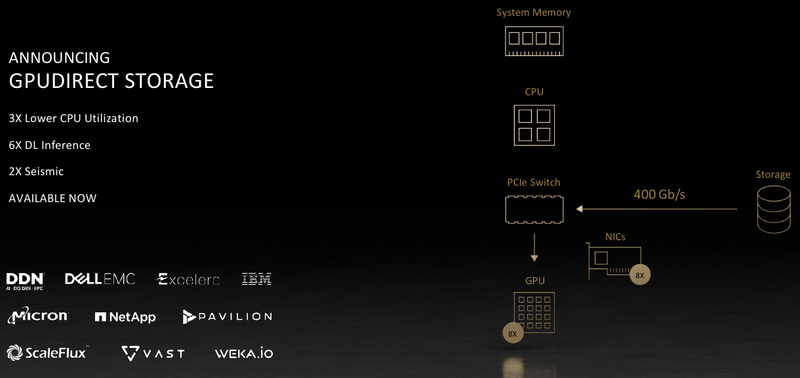 Три новых ключевых технологии NVIDIA помогут супервычислениям стать ещё более «супер», а суперкомпьютерам следующего поколения — ещё более «умными» и производительными. Достигнуты договорённости с такими крупными компаниями, как Atos, Dell Technologies, HPE, Lenovo, Microsoft Azure и NetApp. Решения NVIDIA используются как в индустрии — в качестве примера можно привести промышленный суперкомпьютер Tesla Automotive, так и в ряде других областей.  В частности, фармакологическая компания Recursion использует наработки NVIDIA в области машинного обучения для поиска новых лекарств, а национальный научно-исследовательский центр энергетики (NERSC) применяет ускорители A100 в суперкомпьютере Perlmutter при разработке новых источников энергии. И в дальнейшем NVIDIA продолжит своё наступление на рынок HPC, благо, она может предложить заказчикам как законченные аппаратные решения, так и облачные сервисы, также использующие новейшие технологии компании. |
|

