Материалы по тегу: облако
|
22.12.2023 [13:16], Сергей Карасёв
Cisco приобретёт компанию IsovalentКорпорация Cisco объявила о заключении соглашения по покупке стартапа Isovalent, специализирующегося на разработке сетевых решений open source для обеспечения безопасности, в том числе в облачных средах. Финансовые условия сделки не раскрываются. Isovalent является участником проекта eBPF (extended Berkeley Packet Filter), нацеленного на использование возможностей ядра Linux для мониторинга активности, обнаружения проблем с производительностью и выявления рисков безопасности различных рабочих нагрузок. Кроме того, Isovalent принимает участие в двух других проектах open source: Cilium и Tetragon. Первый помогает управлять потоками сетевого трафика между контейнерами, а второй дополняет Cilium, предоставляя дополнительные возможности кибербезопасности. Стартап недавно представил решение Cilium Mesh, которое позволяет подключать кластеры Kubernetes к существующей инфраструктуре в гибридных облаках. 
Источник изображения: Cisco Cisco намерена использовать технологии Isovalent для расширения своего набора сервисов в области кибербезопасности. Речь идёт о развитии концепции Cisco Security Cloud — интегрированной облачной платформы безопасности на базе ИИ для организаций любого размера. Данная система позволяет клиентам отделить средства управления безопасностью от мультиоблачной инфраструктуры, обеспечив защиту от возникающих угроз в любом облаке, приложении или рабочей нагрузке. Cisco планирует объединить Cilium Mesh со своими программно-определяемыми сетевыми продуктами. Корпорация Cisco намерена завершить сделку по поглощению Isovalent в III четверти 2024 финансового года, который закончится 27 июля. После этого сотрудники стартапа присоединятся к подразделению Cisco Security Business Group.
12.12.2023 [21:15], Владимир Мироненко
Broadcom отменила бессрочные лицензии VMware, перевела все решения на подписную модель и скорректировала портфолио продуктовПосле завершения сделки по приобретению VMware компания Broadcom приступила к изменению портфеля её текущих предложений. В частности, была прекращена практика заключения контрактов по бессрочному лицензированию ПО. Также было объявлено о прекращении поддержки и продления подписки (SnS) для бессрочных предложений. Broadcom заявила, что предоставляет опцию BYOS (Bring Your Own Subscription, «принеси свою собственную подписку»), обеспечивающую переносимость лицензии на проверенные VMware решения на базе VMware Cloud Foundation. «В рамках нашего перехода на подписку и упрощённый портфель, начиная с сегодняшнего дня, мы больше не будем продавать бессрочные лицензии, — говорится в сообщении Broadcom. — В дальнейшем все предложения будут доступны по подписке». О планах перевести все продукты на подписочную модель Broadcom предупреждала задолго до закрытия сделки. В попытке склонить клиентов к переходу на ежегодную подписку Broadcom снизила стоимость на флагманское корпоративное решение VMware Cloud Foundation, так что формально глава компании сдержал слово. «Чтобы позволить большему количеству клиентов получить выгоду от этого решения, мы снизили прежнюю цену подписки вдвое и добавили более высокие уровни поддержки, включая расширенную поддержку для активации решения и управления жизненным циклом», — сообщила компания. 
Источник изображения: Broadcom Broadcom также представила обновлённую платформу VMware vSphere Foundation, упрощающую обработку рабочих нагрузок среднего и малого бизнеса. VMware vSphere Foundation интегрирует vSphere с «интеллектуальным управлением работой», чтобы клиенты могли добиться максимальной производительности, доступности и эффективности с большей прозрачностью. VMware Cloud Foundation и VMware vSphere Foundation будут иметь опциональные расширения (add-on), которые охватывают хранилища, защиту от программ-вымогателей, аварийное восстановление, сервисы платформы приложений и т.д. Предложения Application Network и Security доступны в качестве дополнений для VMware Cloud Foundation. Также компания планирует добавить сервисы на основе ИИ. Вместе с тем компания намерена отказаться от решений для конечных пользователей, например, VDI-платформы VMware Horizon. Брайан Беттс (Bryan Betts), главный аналитик Freeform Dynamics, говоря о стратегии Broadcom, привёл слова гендиректора Nutanix Раджива Рамасвами (Rajiv Ramaswami). «Если вы посмотрите на её историю, вся бизнес-модель Broadcom заключалась в максимизации приобретённых активов за два-три года, — сказал он. — Это означает сокращение расходов и увеличение доходов».
07.12.2023 [21:04], Сергей Карасёв
Google представила Cloud TPU v5p — свой самый мощный ИИ-ускорительКомпания Google анонсировала свой самый высокопроизводительный ускоритель для задач ИИ — Cloud TPU v5p. По сравнению с изделием предыдущего поколения TPU v4 обеспечивается приблизительно 1,7-кратный пророст быстродействия на операциях BF16. Впрочем, для Google важнее то, что она наряду с AWS является одной из немногих, кто при разработке ИИ не зависит от дефицитных ускорителей NVIDIA. К этому же стремится сейчас и Microsoft. Решение Cloud TPU v5p оснащено 95 Гбайт памяти HBM с пропускной способностью 2765 Гбайт/с. Для сравнения: конфигурация TPU v4 включает 32 Гбайт памяти HBM с пропускной способностью 1228 Гбайт/с. 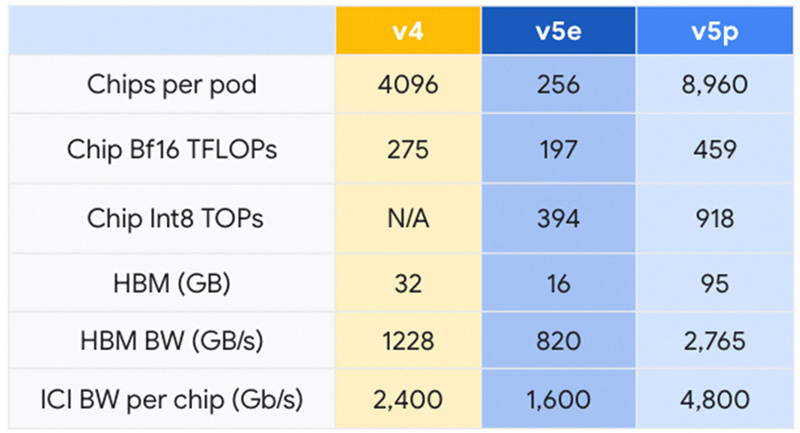
Источник изображений: Google Кластер на базе Cloud TPU v5p может содержать до 8960 чипов, объединённых высокоскоростным интерконнектом со скоростью передачи данных до 4800 Гбит/с на чип. В случае TPU v4 эти значения составляют соответственно 4096 чипов и 2400 Гбит/с. Что касается производительности, то у Cloud TPU v5p она достигает 459 Тфлопс (BF16) против 275 Тфлопс у TPU v4. На операциях INT8 новинка демонстрирует результат до 918 TOPS. 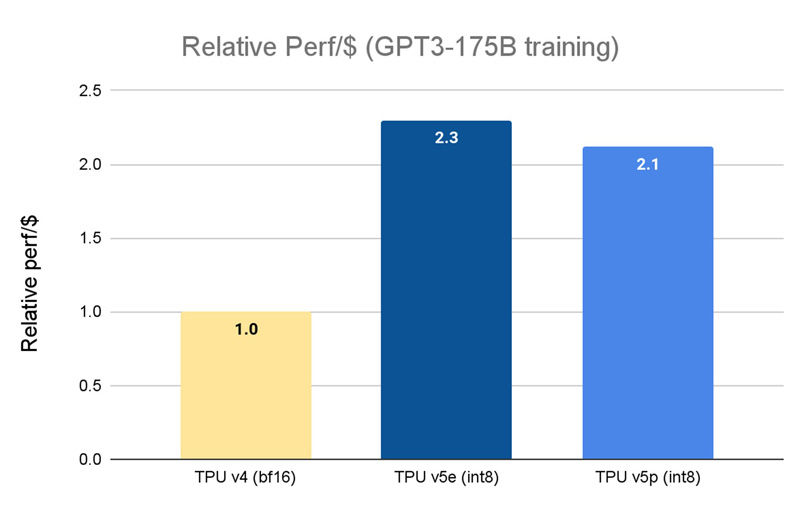 В августе нынешнего года Google представила ИИ-ускоритель TPU v5e, созданный для обеспечения наилучшего соотношения стоимости и эффективности. Это изделие с 16 Гбайт памяти HBM (820 Гбит/с) показывает быстродействие 197 Тфлопс и 394 TOPS на операциях BF16 и INT8 соответственно. При этом решение обеспечивает относительную производительность на доллар на уровне $1,2 в пересчёте на чип в час. У TPU v4 значение равно $3,22, а у новейшего Cloud TPU v5p — $4,2 (во всех случаях оценка выполнена на модели GPT-3 со 175 млрд параметров). 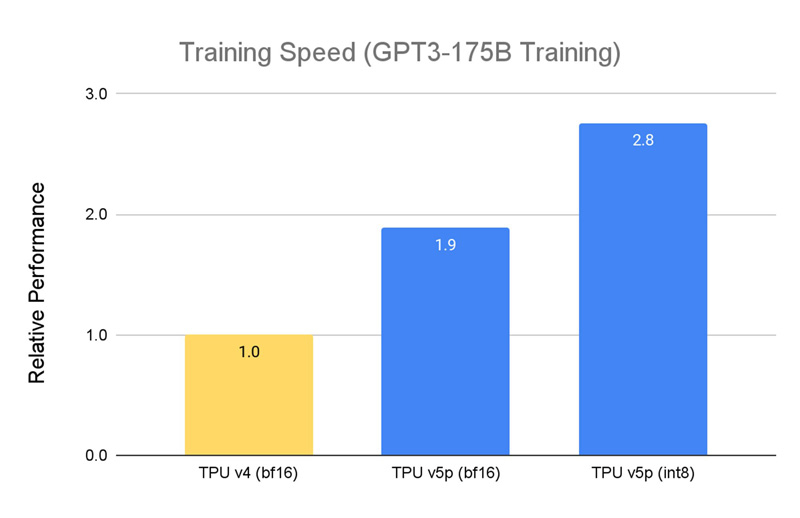 По заявлениям Google, чип Cloud TPU v5p может обучать большие языковые модели в 2,8 раза быстрее по сравнению с TPU v4. Более того, благодаря SparseCores второго поколения скорость обучения моделей embedding-dense увеличивается приблизительно в 1,9 раза. На базе TPU и GPU компания предоставляет готовый программно-аппаратный стек AI Hypercomputer для комплексной работы с ИИ. Система объединяет различные аппаратные ресурсы, включая различные типы хранилищ и оптический интерконнект Jupiter, сервисы GCE и GKE, популярные фреймворки AX, TensorFlow и PyTorch, что позволяет быстро и эффективно заниматься обучением современных моделей, а также организовать инференс.
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
04.10.2023 [14:59], Сергей Карасёв
Без гиперскейлеров: NVIDIA хочет арендовать ЦОД для облачного сервиса DGX CloudКомпания NVIDIA, по сообщению ресурса The Information, ведёт переговоры об аренде площадей у одного из операторов ЦОД, но о ком именно идёт речь, не сообщается. Предполагается, что площадка будет использоваться для поддержания работы собственного облачного сервиса DGX Cloud, предназначенного для обучения передовых моделей для генеративного ИИ. О доступности облака DGX Cloud компания NVIDIA объявила в июле нынешнего года. Тогда сообщалось, что соответствующая вычислительная инфраструктура достанется в первую очередь США и Великобритании. Стоимость доступа к DGX Cloud начинается с $36 999 в месяц. Говорилось, что NVIDIA намерена продвигать DGX Cloud в партнёрстве с ведущими гиперскейлерами. Первым сервис появился в облаке Oracle Cloud Infrastructure (OCI), на очереди Microsoft Azure, Google Cloud Platform и другие. Большая часть выручки в этом случае достаётся именно NVIDIA, а не облакам. 
Источник изображения: NVIDIA Теперь же, судя по всему, NVIDIA решила частично отказаться от услуг облачных провайдеров и развернуть DGX Cloud на арендованных ЦОД-площадях. Впрочем, как отмечается, переговоры всё ещё находятся на начальной стадии, а поэтому говорить о том, что NVIDIA сама превратится в гиперскейлера, преждевременно. При этом компания неоднократно упрекали в том, что в последнее время она более благосклонна к небольшим и специализированным облачным провайдерам, которые не пытаются создавать собственные ИИ-ускорители, могущие составить прямую конкуренцию продуктам NVIDIA.
25.09.2023 [12:00], Владимир Мироненко
Oracle завершила миграцию всех своих облачных сервисов на Arm и представила инстансы Ampere A2 c процессорами AmpereOneOracle представила инстансы Ampere A2 следующего поколения на базе 192-ядерных Arm-процессоро AmpereOne, которые станут доступны для клиентов компании позднее в этом году. Как сообщает Oracle, новые инстансы обеспечивают на 44 % лучшее соотношение цены и производительности по сравнению с предложениями на архитектуре x86 и идеально подходят для ИИ-инференса, работы с базами данных, веб-сервисами, рабочих нагрузок транскодирования мультимедиа и поддержки среды выполнения для таких языков, как GO и Java. Инстансы OCI Ampere A2 предлагают до 320 ядер в случае bare metal и до 156 ядер в рамках одной виртуальной машины. Обладая большим объёмом приватного кеша, стабильной рабочей частотой, однопоточными ядрами и новыми функциями управления памятью, инстансы нового поколения позволяют обеспечить ещё более предсказуемую производительность за счёт снижения влияния внешних помех, как происходит в случае SMT, и одновременно предлагают безопасную микроархитектуру для многопользовательских облачных сред. 
Источник изображений: Ampere «То, что происходит с OCI и Ampere, является отражением значительных перемен, происходящих в нашей отрасли, — сказала гендиректор Ampere Рене Джеймс (Renee James). — Времена использования мощности в качестве показателя производительности переходят в эру высокопроизводительных вычислений с низким энергопотреблением. Такие клиенты, как 8X8 и другие, признают, что существует необходимость снизить затраты на инфраструктуру и в то же время сократить выбросы углекислого газа без ущерба для производительности. В нашу эру компьютеров с ИИ новая сила — это меньшая мощность». Клэй Магоуирк (Clay Magouyrk), исполнительный вице-президент Oracle Cloud Infrastructure Development, сообщил, что в связи с быстрым ростом Oracle подошла к пределам доступной мощности, и для дальнейшего масштабирования облака ей необходим рост эффективности в дополнение к производительности: «Вот почему мы используем Ampere для всего: от базы данных Oracle до приложений Fusion, а теперь и для всех наших сервисов OCI. С развитием ИИ-обработки этот сдвиг в вычислениях стал ещё более важным. Ampere — это решение OCI для устойчивого облака». СУБД Oracle Database полностью поддерживается процессорами Ampere. Кроме того, все сервисы OCI, число которых исчисляется сотнями, теперь тоже работают на CPU Ampere. Конечные клиенты могут перенести все свои рабочие нагрузки на платформу Ampere, в том числе задачи инференса, которые поддерживаются библиотеками AI Optimizer от Ampere.
02.09.2023 [11:28], Сергей Карасёв
Биржа Nasdaq продолжает перенос сервисов в облако AWSАмериканская биржа Nasdaq, по сообщению ресурса Datacenter Dynamics, завершила ещё один этап переноса своих рабочих нагрузок на облачную платформу Amazon Web Services (AWS): речь идёт о системе работы с ценными бумагами Nasdaq Bond Exchange. О планах по переводу части служб на платформу AWS биржа Nasdaq объявила в конце 2021 года. Тогда сообщалось, что будет применяться решение AWS Outposts, которое позволяет развернуть локальную инфраструктуру AWS практически в любом дата-центре или на колокейшн-площадке. Это необходимо для обеспечения минимального времени отклика. Перенос системы опционов Nasdaq MRX на платформу AWS был завершен в декабре 2022 года. А сервисы Nasdaq Bond Exchange начали функционировать на базе данного облака в конце августа нынешнего года. 
Источник изображения: Nasdaq Ожидается, что полный переход Nasdaq на AWS займёт около десяти лет. Он включает в себя перемещение некоторых рабочих нагрузок в основной дата-центр Nasdaq — на площадку Equinix NY11, которая располагается в Картерете (штат Нью-Джерси). В рамках проекта предполагается модернизация ЦОД: размер нынешнего одноэтажного комплекса, обеспечивающего колокейшн-площадь около 8500 м2, будет увеличен в два раза. Объект, построенный в 2000 году, входит в число 24 центров обработки данных, купленных компанией Equinix в 2016 году у Verizon.
30.08.2023 [16:04], Алексей Степин
Google Cloud анонсировала новое поколение собственных ИИ-ускорителей TPU v5eКак известно, Google Cloud использует в своей инфраструктуре не только сторонние ускорители, но и TPU собственной разработки. Эти кастомные ASIC компания продолжает активно развивать — она анонсировала предварительную доступность виртуальных машин с новейшими TPU v5e, разработка которых заняла более двух лет. Сам чип TPU v5e позиционируется Google как эффективный со всех точек зрения ускоритель, предназначенный для обучения нейросетей или инференс-систем среднего и большого классов. В сравнении с TPU v4 он, по словам Google, обеспечивает вдвое более высокую производительность в пересчёте на доллар для обучения больших языковых моделей (LLM) и генеративных нейросетей. Для инференс-систем преимущество по тому же критерию составляет 2,5x. В сравнении с аналогичными решениями на базе других чипов, например, GPU, выигрыш может составить и 4x. Каждый чип TPU v5e включает четыре блока матричных вычислений, по одному блоку для скалярных и векторных расчётов, а также HBM2-память. 
Источник изображения: Google Компания отмечает, что не экономит на технических характеристиках TPU v5e в угоду рентабельности. Кластеры могут включать до 256 чипов TPU v5e, объединённых высокоскоростным интерконнектом с совокупной пропускной способностью более 400 Тбит/с. Производительность такой платформы составляет 100 Попс (Петаопс) в INT8-вычислениях. Правда, здесь есть нюанс: INT8-производительности TPU v5e составляет 393 Тфлопс против 275 Тфлопс у v4, но вот BF16-производительность у TPU v4 составляет те же 275 Тфлопс, тогда как у v5e этот показатель равен уже 197 Тфлопс. 
Источник изображения: Google В настоящее время для предварительного тестирования доступно уже восемь вариантов инстансов на базе v5e, а в зависимости от конфигурации количество TPU может составлять от 1 до более чем 250. В рамках платформы обеспечена полная интеграция с Google Kubernetes Engine, собственной платформой Vertex AI, а также с большинством современных фреймворков, включая PyTorch, TensorFlow и JAX. Работа с TPU v5e будет значительно дешевле, чем с TPU v4 — $1,2/час против $3,4/час (за чип). 
Источник изображения: Google В настоящее время машины с TPU v5e доступны только в североамериканском регионе (us-west4), но в дальнейшем возможность их использования появится в регионах EMEA (Нидерланды) и APAC (Сингапур). Также Google предлагает опробовать технологию Multislice, позволяющей объединять в единый комплекс десятки тысяч TPU v5e или TPU v4, где каждый «слайс» может содержать до 3072 чипов TPU (v4). В максимальной конфигурации можно развернуть 64 инстанса, работающих с 256 кластерами TPU v5e. Сама компания уже использует новые чипы для своего поисковика и Google Photos.
21.07.2023 [23:10], Алексей Степин
Microsoft предлагает протестировать DPU MANA с Azure BoostКрупные облачные провайдеры давно осознали пользу, которую могут принести DPU и активно применяют подобного рода решения. В частности, AWS давно использует платформу Nitro, Google разработала DPU при поддержке Intel, а Microsoft активно готовит к запуску собственную платформу под названием MANA. Основой MANA является кастомный чип SoC, разработанный специально с учётом обеспечения высокой пропускной способности, стабильности подключения и низкой латентности. DPU на его основе обеспечивает пропускную способность до 200 Гбит/с, а также поддерживает подключение удалённого хранилища данных на скоростях до 10 Гбайт/с при производительности до 400 тыс. IOPS. Отметим, что ранее AMD заявила о появлении DPU Pensando в облаке Azure, а сама Microsoft в прошлом году поглотила разработчика DPU Fungible. 
Изображение: Microsoft MANA является частью услуги Azure Boost и берёт на себя управление всеми аспектами виртуализации, включая работу с сетью и данными, а также функции управления хост-системой. Перенос этих функций на отдельную платформу не просто улучшает производительность и масштабируемость, но и обеспечивает дополнительный слой безопасности. MANA уже задействованы в инфраструктуре Azure и подтвердили высочайшую скорость при работе с внешними хранилищами данных для инстансов Ebsv5, а также отличную пропускную способность и низкую латентность сетевого канала для всех инстансов семейств Ev5 и Dv5. MANA поддерживает Windows и Linux, а для более тонкой работы с аппаратной частью ускорителя можно задействовать DPDK. В части информационной безопасности следует отметить наличие криптоядра, соответствующего стандартам FIPS 140. В настоящее время сервис Azure Boost доступен в качестве превью. Компания приглашает к сотрудничеству партнёров и клиентов с высокими запросами к характеристикам сетевого канала и хранилищ. |
|

