Материалы по тегу: бенчмарк
|
14.11.2024 [23:07], Владимир Мироненко
Google и NVIDIA показали первые результаты TPU v6 и B200 в ИИ-бенчмарке MLPerf TrainingУскорители Blackwell компании NVIDIA опередили в бенчмарках MLPerf Training 4.1 чипы H100 более чем в 2,2 раза, сообщил The Register. По словам NVIDIA, более высокая пропускная способность памяти в Blackwell также сыграла свою роль. Тесты были проведены с использование собственного суперкомпьютера NVIDIA Nyx на базе DGX B200. Новые ускорители имеют примерно в 2,27 раза более высокую пиковую производительность в вычисления FP8, FP16, BF16 и TF32, чем системы H100 последнего поколения. B200 показал в 2,2 раза более высокую производительность при тюнинге модели Llama 2 70B и в два раза большую производительность при предварительном обучении (Pre-training) модели GPT-3 175B. Для рекомендательных систем и генерации изображений прирост составил 64 % и 62 % соответственно. Компания также отметила преимущества используемой в B200 памяти HBM3e, благодаря которой бенчмарк GPT-3 успешно отработал всего на 64 ускорителях Blackwell без ущерба для производительности каждого GPU, тогда как для достижения такого же результата понадобилось бы 256 ускорителей H100. Впрочем, про Hopper компания тоже не забывает — в новом раунде компания смогла масштабировать тест GPT-3 175B до 11 616 ускорителей H100. 
Источник изображений: NVIDIA Компания отметила, что платформа NVIDIA Blackwell обеспечивает значительный скачок производительности по сравнению с платформой Hopper, особенно при работе с LLM. В то же время чипы поколения Hopper по-прежнему остаются актуальными благодаря непрерывным оптимизациям ПО, порой кратно повышающим производительность в некоторых задач. Интрига в том, что в этот раз NVIDIA решила не показывать результаты GB200, хотя такие системы есть и у неё, и у партнёров. 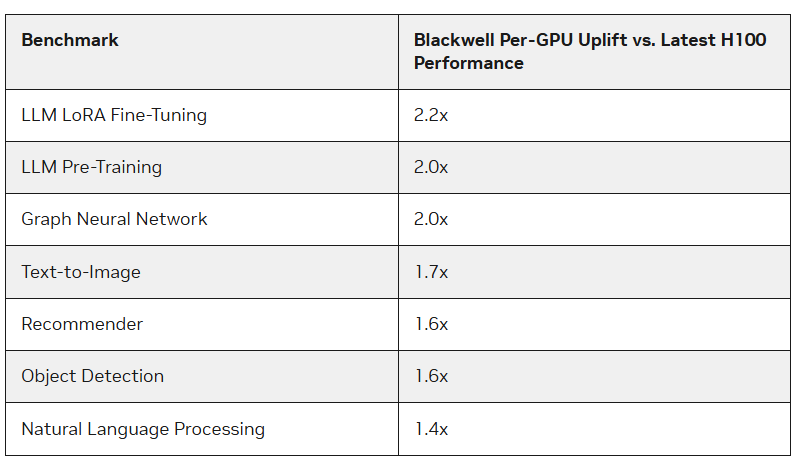 В свою очередь, Google представила первые результаты тестирования 6-го поколения TPU под названием Trillium, о доступности которого было объявлено в прошлом месяце, и второй раунд результатов ускорителей 5-го поколения TPU v5p. Ранее Google тестировала только TPU v5e. По сравнению с последним вариантом, Trillium обеспечивает прирост производительности в 3,8 раза в задаче обучения GPT-3, отмечает IEEE Spectrum.  Если же сравнивать результаты с показателями NVIDIA, то всё выглядит не так оптимистично. Система из 6144 TPU v5p достигла контрольной точки обучения GPT-3 за 11,77 мин, отстав от системы с 11 616 H100, которая выполнила задачу примерно за 3,44 мин. При одинаковом же количестве ускорителей решения Google почти вдвое отстают от решений NVIDIA, а разница между v5p и v6e составляет менее 10 %. 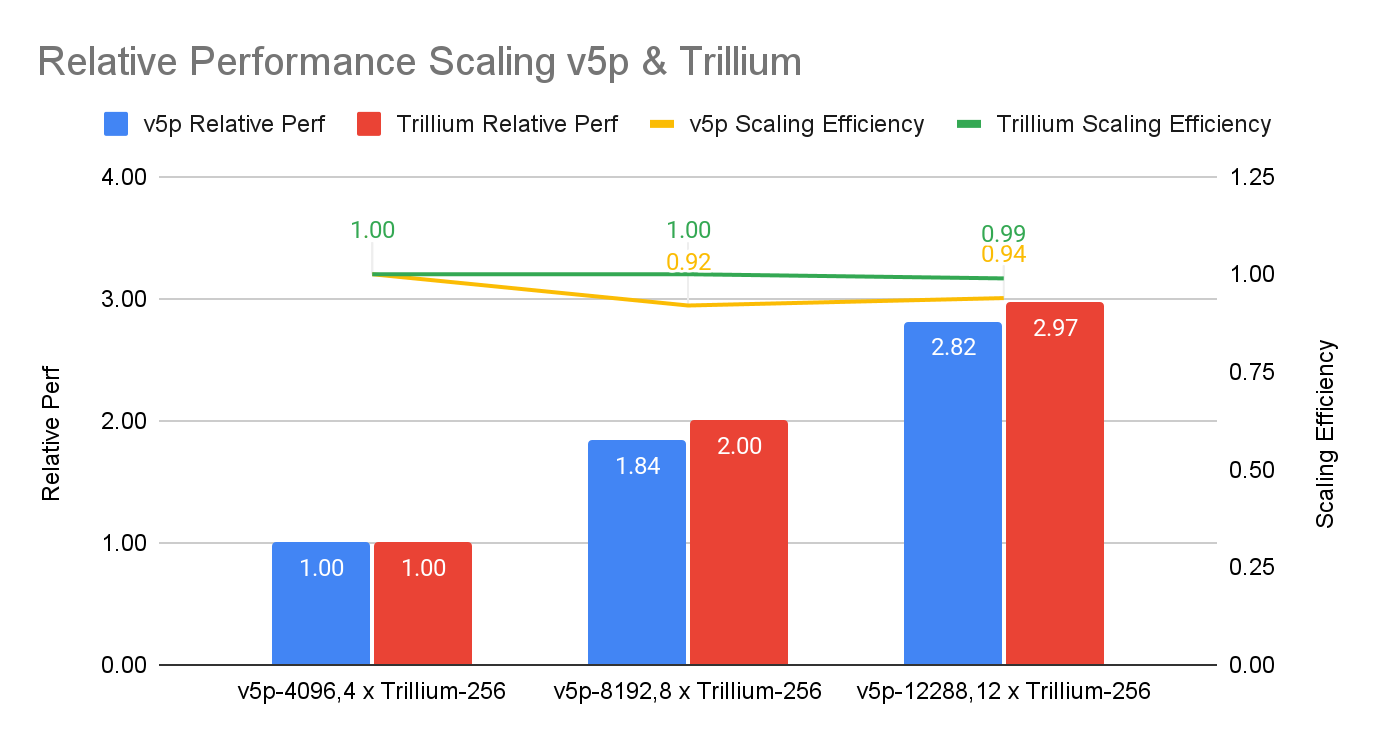
Источник изображения: Google В тесте Stable Diffusion система из 1024 TPU v5p заняла второе место, завершив работу за 2,44 мин, тогда как система того же размера на основе NVIDIA H100 справилась с задачей за 1,37 мин. В остальных тестах на кластерах меньшего масштаба разрыв остаётся примерно полуторакратным. Впрочем, Google упирает на масштабируемость и лучшее соотношение цены и производительности в сравнении как с решениями конкурентов, так и с собственными ускорителями прошлых поколений. Также в новом раунде MLPerf появился единственный результат измерения энергопотребления во время проведения бенчмарка. Система из восьми серверов Dell XE9680, каждый из которых включал восемь ускорителей NVIDIA H100 и два процессора Intel Xeon Platinum 8480+ (Sapphire Rapids), в задаче тюнинга Llama2 70B потребила 16,38 мДж энергии, потратив на работу 5,05 мин. — средняя мощность составила 54,07 кВт.
29.08.2024 [01:00], Владимир Мироненко
NVIDIA вновь показала лидирующие результаты в ИИ-бенчмарке MLPerf InferenceNVIDIA сообщила, что её платформы показали самые высокие результаты во всех тестах производительности уровня ЦОД в бенчмарке MLPerf Inference v4.1, где впервые дебютировал ускоритель семейства Blackwell. Ускоритель NVIDIA B200 (SXM, 180 Гбайт HBM) оказался вчетверо производительнее H100 на крупнейшей рабочей нагрузке среди больших языковых моделей (LLM) MLPerf — Llama 2 70B — благодаря использованию механизма Transformer Engine второго поколения и FP4-инференсу на Tensor-ядрах. Впрочем, именно B200 заказчики могут и не дождаться. Ускоритель NVIDIA H200, который стал доступен в облаке CoreWeave, а также в системах ASUS, Dell, HPE, QTC и Supermicro, показал лучшие результаты во всех тестах в категории ЦОД, включая последнее дополнение к бенчмарку, LLM Mixtral 8x7B с общим количеством параметров 46,7 млрд и 12,9 млрд активных параметров на токен, использующую архитектуру Mixture of Experts (MoE, набор экспертов). 
Источник изображения: NVIDIA Как отметила NVIDIA, MoE приобрела популярность как способ привнести большую универсальность в LLM, поскольку позволяет отвечать на широкий спектр вопросов и выполнять более разнообразные задачи в рамках одного развёртывания. Архитектура также более эффективна, поскольку активируются только несколько экспертов на инференс — это означает, что такие модели выдают результаты намного быстрее, чем высокоплотные (Dense) модели аналогичного размера. Также NVIDIA отмечает, что с ростом размера моделей для снижения времени отклика при инференсе объединение нескольких ускорителей становится обязательными. По словам компании, NVLink и NVSwitch уже в поколении NVIDIA Hopper предоставляют значительные преимущества для экономичного инференса LLM в реальном времени. А платформа Blackwell ещё больше расширит возможности NVLink, позволив объединить до 72 ускорителей. 
Источник изображения: NVIDIA Заодно компания в очередной раз напомнила о важности программной экосистемы. Так, в последнем раунде MLPerf Inference все основные платформы NVIDIA продемонстрировали резкий рост производительности. Например, ускорители NVIDIA H200 показали на 27 % большую производительность инференса генеративного ИИ по сравнению с предыдущим раундом. А Triton Inference Server продемонстрировал почти такую же производительность, как и у bare-metal платформ. Наконец, благодаря программным оптимизациям в этом раунде MLPerf платформа NVIDIA Jetson AGX Orin достигла более чем 6,2-кратного улучшения пропускной способности и 2,5-кратного улучшения задержки по сравнению с предыдущим раундом на рабочей нагрузке GPT-J LLM. По словам NVIDIA, Jetson способен локально обрабатывать любую модель-трансформер, включая LLM, модели класса Vision Transformer и, например, Stable Diffusion. А вместо разработки узкоспециализированных моделей теперь можно применять универсальную GPT-J-6B модель для обработки естественного языка на периферии.
01.08.2024 [23:55], Алексей Степин
Arm-процессоры AWS Graviton4 успешно конкурируют с актуальными Intel Xeon, а иногда обгоняют даже AMD EPYCВсего за пять лет Amazon успела разработать и внедрить четыре поколения серверных Arm-процессоров Graviton. 4-нм Graviton4 получили 96 ядер и 12 каналов памяти DDR5-5600, а также поддержку PCIe 5.0. Всё это дало AWS основание утверждать, что Graviton4 производительнее предшественника на 30 %, а пропускная способность памяти у него выше на 75 %. Насколько это соответствует истине, выяснил ресурс Phoronix, который заодно сравнил новинки с другими современными процессорами. В тестировании Phoronix приняли участие следующие модели Graviton:

Источник: AWS Платформа Graviton в последней итерации выглядит вполне достойно. Она использует современный набор инструкций Arm, а по количеству ядер и каналов памяти сопоставима с новейшими решениями Intel и AMD. Производительность по мере смены поколений у Graviton растёт практически линейно, за исключением перехода от первого поколения ко второму, что легко объясняется возросшим сразу вчетверо количеством ядер. Что касается Graviton4, то новые процессоры в среднем быстрее Graviton3 примерно в 1,55 раза, а первенца серии они превосходят в 10,4 раза. В некоторых случаях выигрыш выходит далеко за рамки теоретических 1,5x, поскольку у Graviton4 более совершенная архитектура, новее набор инструкций, вдвое больший объем кеша на ядро и существенно более производительная подсистема памяти. Такое поведение, к примеру, характерно для тестов srsRAN, задач криптографии и особенно работы с базами данных. 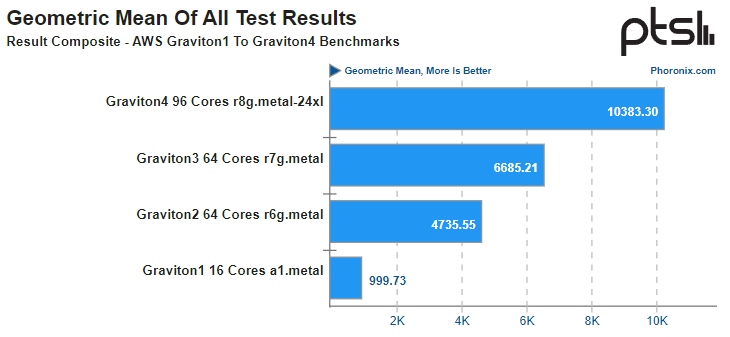
Источник здесь и далее: Phoronix В другом исследовании Phoronix процессорам Graviton4 довелось столкнуться с серьёзными соперниками из мира x86, включая 128-ядерный AMD EPYC 9754 (Bergamo) и 144-ядерные Intel Xeon 67xx (Sierra Forest), а также с ближайшим конкурентом по Arm-платформе, 128-ядерным процессором Ampere Altra Max. К сожалению, метрик энергопотребления в текущей версии инстанса r8g.metal-24xl получить не удалось, но и без этого результаты получены весьма интересные. С первых тестов очевидно, что Altra Max уже не соперник современным решениям, несмотря на сопоставимое количество ядер — сказывается не самая новая архитектура. А вот Graviton4 чувствует себя неплохо и в тестах на компиляцию может опережать даже AMD EPYC 9754. Хороша новинка и в базах данных, она лишь немного уступает процессорам Genoa и зачастую опережает 144-ядерное решение Intel c E-ядрами. И даже в HPC-нагрузках, для которых характерно активное использование FP-вычислений у Graviton4 всё хорошо! Неплохо себя детище AWS чувствует и в сценариях (де-)компрессии данных и кодировании видео. 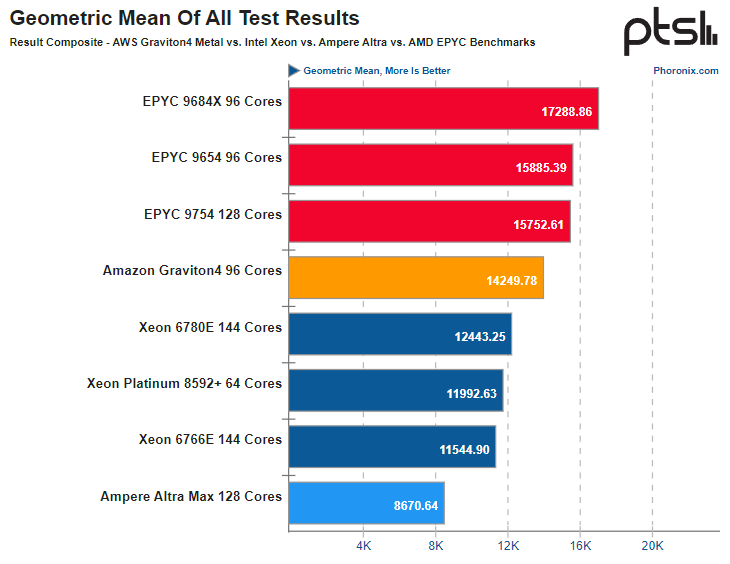 В итоговом зачёте AWS Graviton4 уверенно занимает место в середине таблицы, опережая оба Xeon — и 64-ядерный Platinum 8592+ (Emerald Rapids), и 144-ядерный Xeon 6780E, но до уровня AMD EPYC 9754 всё же несколько недотягивая. Это вполне даёт основание считать, что платформа AWS Graviton достигла зрелости. Она вполне конкурентоспособна даже на фоне x86-монстров. Более того, на сегодня Graviton4 можно считать самым продвинутым серверным процессором с архитектурой AArch64. Впрочем, вскоре предстоят сражения с Granite Rapids, Turin и AmpereOne (а на подходе ещё и Aurora с HBM).
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 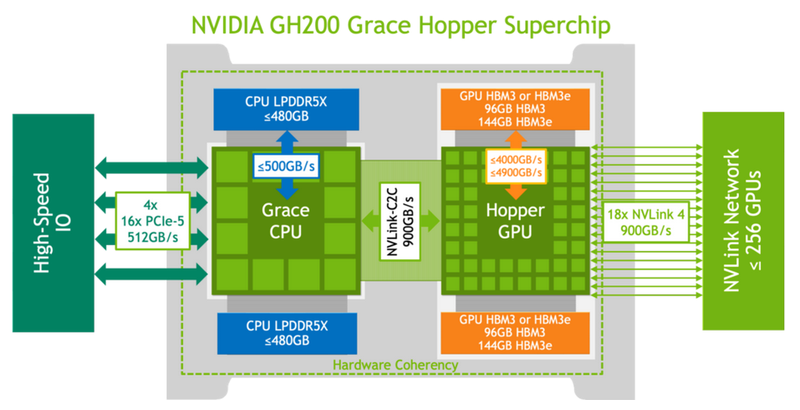
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 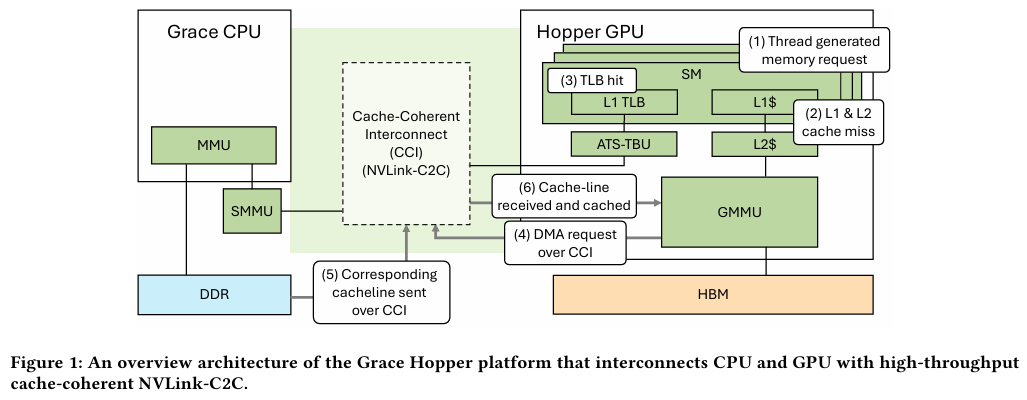
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 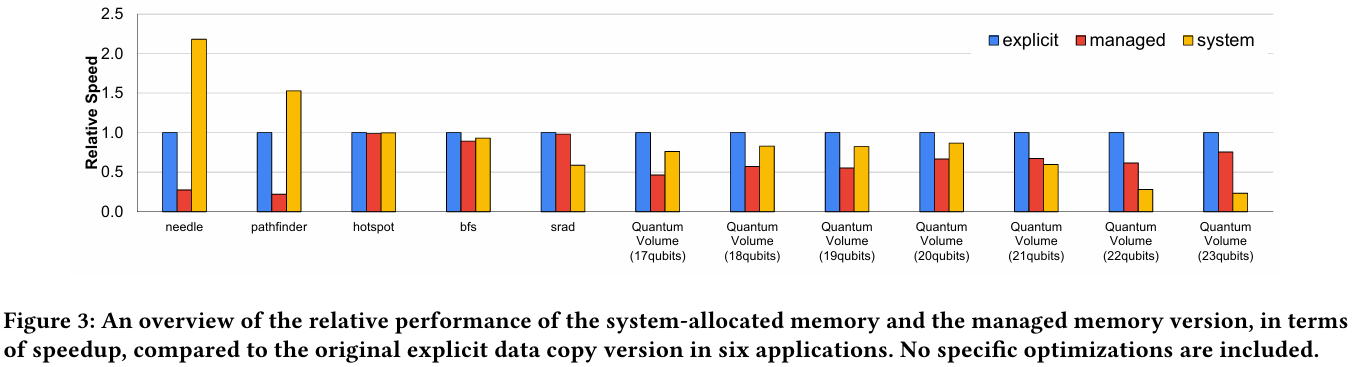
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
25.07.2024 [10:12], Владимир Мироненко
AMD показала превосходство чипов EPYC над Arm-процессорами NVIDIA Grace в серии бенчмарков, но не всё так простоAMD провела серию тестов, чтобы доказать преимущество своих нынешних процессоров AMD EPYC над Arm-процессорами NVIDIA Grace Superchip. Как отметила AMD, в связи с растущей востребованностью ЦОД некоторые компании начали предлагать альтернативные варианты процессоров, «часто обещающие преимущества по сравнению с обычными решениями x86». «Обычно их представляют с большой помпой и заявлениями о значительных преимуществах в производительности и энергоэффективности по сравнению с x86. Слишком часто эти утверждения довольно сложно воплотить в реальные сценарии конкурентной рабочей нагрузки — с использованием устаревших, недостаточно оптимизированных альтернатив или плохо документированных предположений», — отметила AMD. С помощью серии стандартных отраслевых тестов AMD, по её словам, продемонстрировала преимущество EPYC над решениями на базе Arm. «Благодаря проверенной архитектуре x86-64, впервые разработанной AMD, вы можете получить всё это без дорогостоящего портирования или изменений в архитектуре», — подчеркнула компания. Иными словами, тесты AMD могут быть просто попыткой развеять опасения, что архитектура x86 «выдыхается» и что Arm берёт верх. 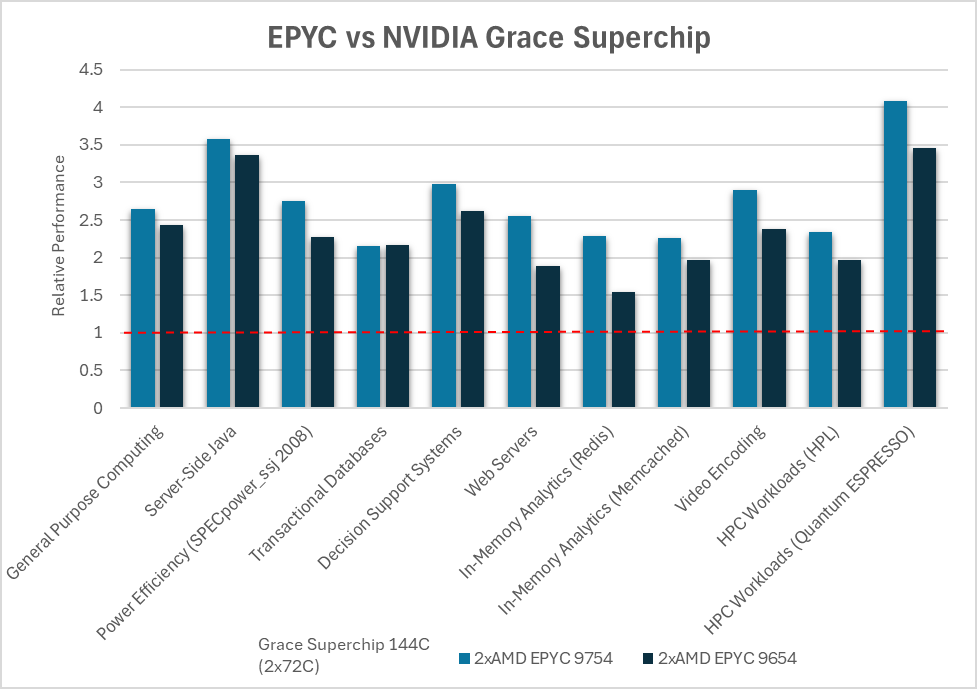
Источник изображений: AMD AMD сравнила производительность AMD EPYC и NVIDIA Grace CPU в десяти ключевых рабочих нагрузках, охватывающих вычисления общего назначения, Java, транзакционные базы данных, системы поддержки принятия решений, веб-серверы, аналитику, кодирование видео и нагрузки HPC. Согласно представленному выше графику, 128-ядерный процессор EPYC 9754 (Bergamo) и 96-ядерный EPYC 9654 (Genoa) более чем вдвое превзошли NVIDIA Grace CPU Superchip по производительности при обработке вышеуказанных нагрузок. Напомним, что Grace CPU Superchip содержит два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2, соединённых шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работает как единый 144-ядерный процессор. В свою очередь, ресурс The Register отметил, что речь идёт о версии с 480 Гбайт памяти LPDDR5x, а не с 960 Гбайт. 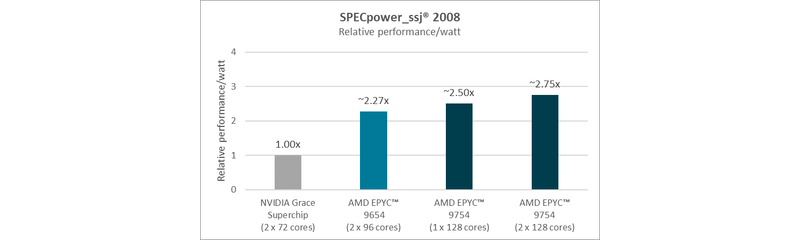 В тесте SPECpower-ssj2008, по данным AMD, одно- и двухсокетные системы на базе AMD EPYC 9754 превосходят систему NVIDIA Grace CPU Superchip по производительности на Вт примерно в 2,50 раза и 2,75 раза соответственно, а двухсокетная система AMD EPYC 9654 — примерно в 2,27 раза. Помимо производительности и эффективности, ещё одним важным фактором для операторов ЦОД является совместимость, сообщила AMD. По оценкам, во всем мире существуют триллионы строк программного кода, большая часть которого написана для архитектуры x86. EPYC основаны на архитектуре x86-64, впервые разработанной AMD, и эта архитектура является наиболее широко используемой и поддерживаемой в индустрии ЦОД, заявила компания, добавив, что изменения в архитектуре сложны, дороги и чреваты риском. AMD также отметила, что экосистема AMD EPYC включает более 250 различных конструкций серверов и поддерживает около 900 уникальных облачных инстансов. Также процессоры AMD EPYC установили более 300 мировых рекордов производительности и эффективности в широком спектре тестов. В то же время лишь немногие Arm-решения доказали свою эффективность. В свою очередь, ресурс The Register отметил, что ситуация не так проста, как AMD пытается всех убедить. В феврале сайт The Next Platform сообщил, что исследователи из университетов Стоуни-Брук и Буффало сравнили данные о производительности суперчипа NVIDIA Grace CPU Superchip и нескольких процессоров x86, предоставленные несколькими НИИ и разработчиком облачных решений. 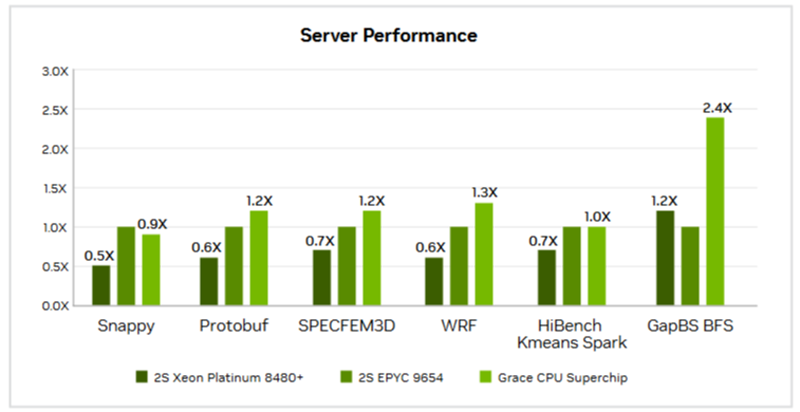
Источник изображений: NVIDIA Большинство этих тестов были ориентированы на HPC, включая Linpack, HPCG, OpenFOAM и Gromacs. И хотя производительность системы Grace сильно различалась в разных тестах, в худшем случае она находилась где-то между Intel Skylake-SP и Ice Lake-SP, превосходя AMD Milan и находясь в пределах досягаемости от показателей Xeon Max. Данные результаты отражают тот факт, что самые мощные процессоры AMD EPYC Genoa и Bergamo могут превзойти первый процессор NVIDIA для ЦОД — при правильно выбранном тесте. 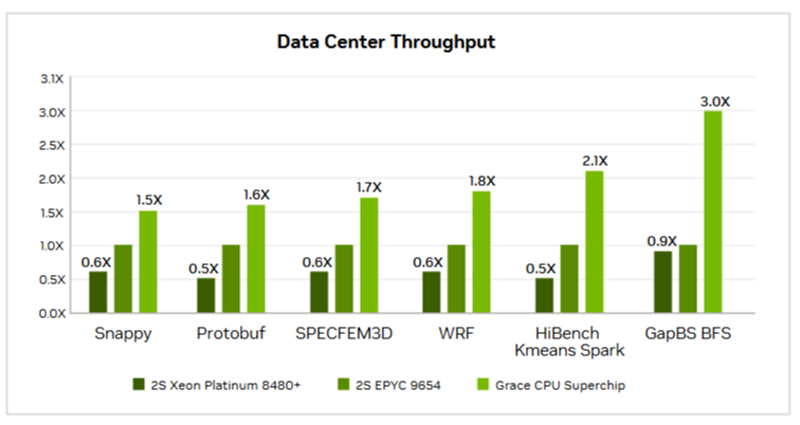 В техническом описании Grace CPU Superchip компания NVIDIA сообщает, что этот чип обеспечивает от 0,9- до 2,4-кратного увеличения производительности по сравнению с двумя 96-ядерными EPYC 9654 и предлагает до трёх раз большую пропускную способность в различных облачных и HPC-сервисах. NVIDIA отмечает, что Superchip предназначен для «обработки массивов для получения интеллектуальных данных с максимальной энергоэффективностью», говоря об ИИ, анализе данных, нагрузках облачных гиперскейлеров и приложениях HPC.
15.05.2024 [14:18], Руслан Авдеев
PUE у вас неправильный: NVIDIA призывает пересмотреть методы оценки энергоэффективности ЦОД и суперкомпьютеровОператорам дата-центров и суперкомпьютеров не хватает инструментов для корректного измерения энергоэффективности их оборудования и оценки прогресса на пути к экоустойчивым вычислениям. Как утверждает NVIDIA, нужна новая система оценки показателей при использовании оборудования в реальных задачах. Для оценки эффективности ЦОД существует как минимум около трёх десятков стандартов, некоторые уделяют внимание весьма специфическим критериям вроде расхода воды или уровню безопасности. Сегодня чаще всего используется показатель PUE (power usage effectiveness), т.е. отношение энергопотребления всего объекта к потреблению собственно IT-инфраструктуры. В последние годы многие операторы достигли практически идеальных значений PUE, поскольку, например, на преобразование энергии и охлаждение нужно совсем мало энергии. В эпоху роста облачных сервисов оценка PUE показала довольно высокую эффективность, но в эру ИИ-вычислений этот индекс уже не вполне соответствует запросам отрасли ЦОД — оборудование заметно изменилось. NVIDIA справедливо отмечает, что PUE не учитывает эффективность инфраструктуры в реальных нагрузках. С таким же успехом можно измерять расход автомобилем бензина без учёта того, как далеко он может проехать без дозаправки. При этом среднемировой показатель PUE дата-центров остаётся неизменным уже несколько лет, а улучшать его всё дороже. 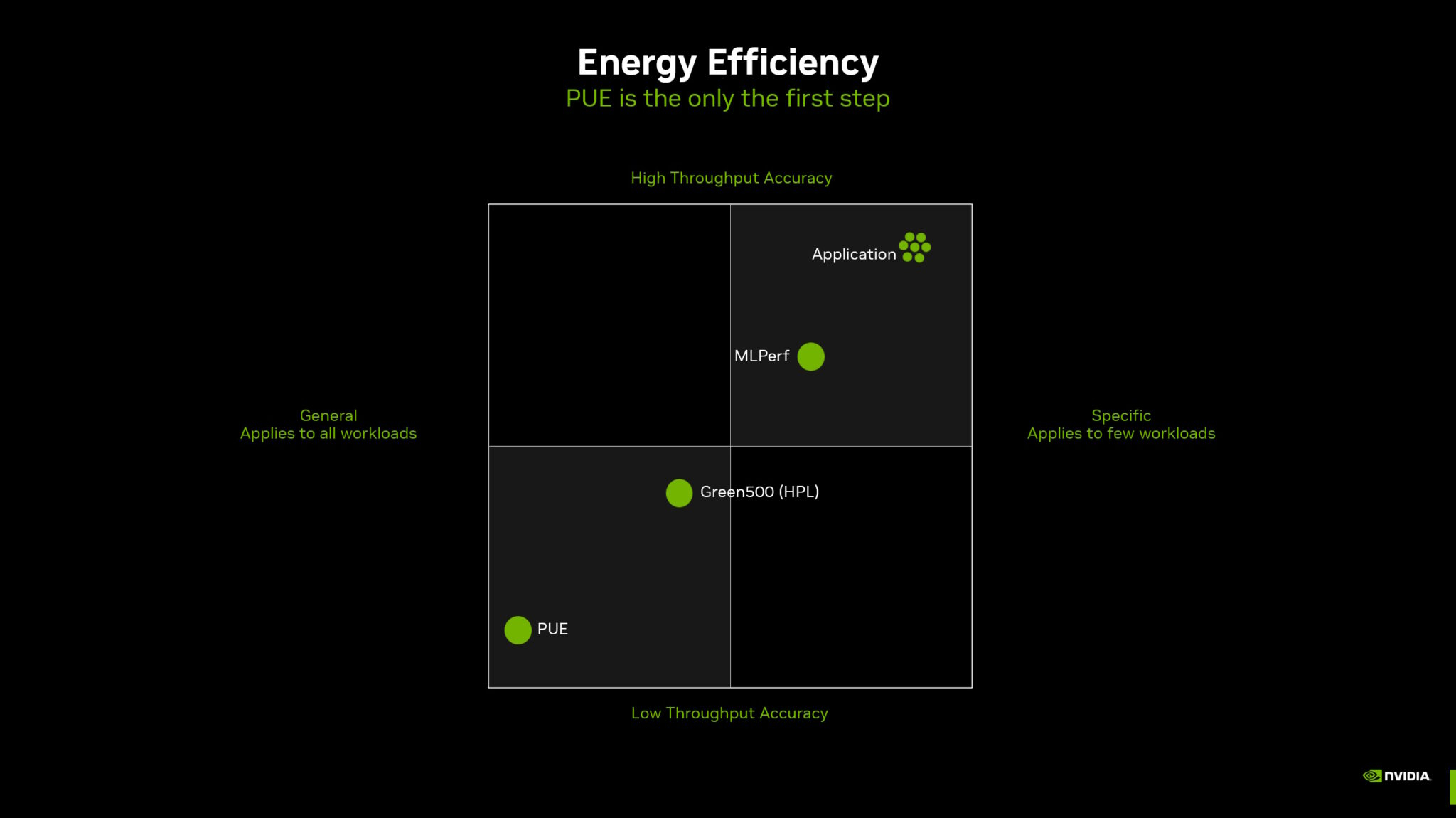
Источник изображений: NVIDIA Что касается энергопотребления, разное оборудование при одинаковых затратах может давать самые разные результаты. Другими словами, если современные ускорители потребляют больше энергии, это не значит, что они менее эффективны, поскольку они дают несопоставимо лучший результат в сравнении со старыми решениями. NVIDIA неоднократно приводила подобные сравнения и между своими GPU с обычными CPU, а теперь предлагает распространить этот подход на ЦОД целиком, что справедливо, учитывая стремление NVIDIA сделать минимальной единицей развёртывания целую стойку. 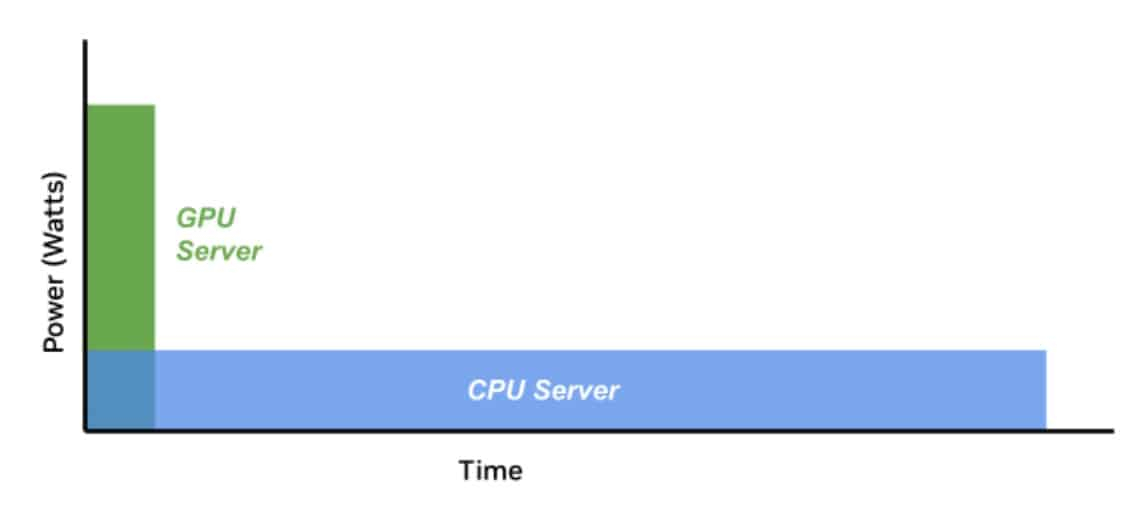 Как считают в NVIDIA, оценивать качество ЦОД можно только с учётом того, сколько энергии тратится для получения результата. Так, ЦОД для ИИ могут полагаться на MLPerf-бенчмарки, суперкомпьютеры для научных исследований могут требовать измерения других показателей, а коммерческие дата-центры для стриминговых сервисов — третьих. В идеале бенчмарки должны измерять прогресс в ускоренных вычислениях с использованием специализированных сопроцессоров, ПО и методик. Например, в параллельных вычислениях GPU намного энергоэффективнее обычных процессоров Отмечается, что с 2003 года производительность ускорителей выросла приблизительно в 7 тыс. раз, а соотношение цены и производительности стало в 5,6 тыс. раз лучше. А с учётом того, что современные ЦОД достигли PUE на уровне приблизительно 1,2, подобная метрика практически исчерпала себя, теперь стоит ориентироваться на другие показатели, релевантные актуальным проблемам. Хотя напрямую сравнить некоторые аспекты невозможно, сегментировав деятельность ЦОД на типы рабочих нагрузок, возможно, удалось бы получить некоторые результаты. В частности, операторам ЦОД нужен пакет бенчмарков, измеряющих показатели при самых распространённых рабочих ИИ-нагрузках. Например, неплохой метрикой может стать Дж/токен. Впрочем, NVIDIA грех жаловаться на недостойные оценки — в последнем рейтинге Green500 именно её системы заняли лидерские позиции.
13.07.2022 [16:13], Алексей Степин
128-ядерный Arm-процессор Alibaba T-Head Yitian 710 показал отличные результаты в SPEC CPU2017Не секрет, что китайские гиганты, такие, как Huawei и Alibaba Cloud, разрабатывают собственные серверные процессоры на базе архитектуры Arm. Однако информации об этих чипах, как правило, не очень много и пользоваться общепринятыми на западе тестами и рейтингами разработчики не спешат, что, к слову, характерно и для китайских суперкомпьютеров. Alibaba Cloud представила чип Yitian 710 ещё осенью прошлого года. Этот процессор построен на базе архитектуры Armv9 и максимально может иметь 128 ядер с частотой до 3,2 ГГц. Однако результаты проверки чипа в популярном тесте SPEC CPU2017 были опубликованы только сейчас. 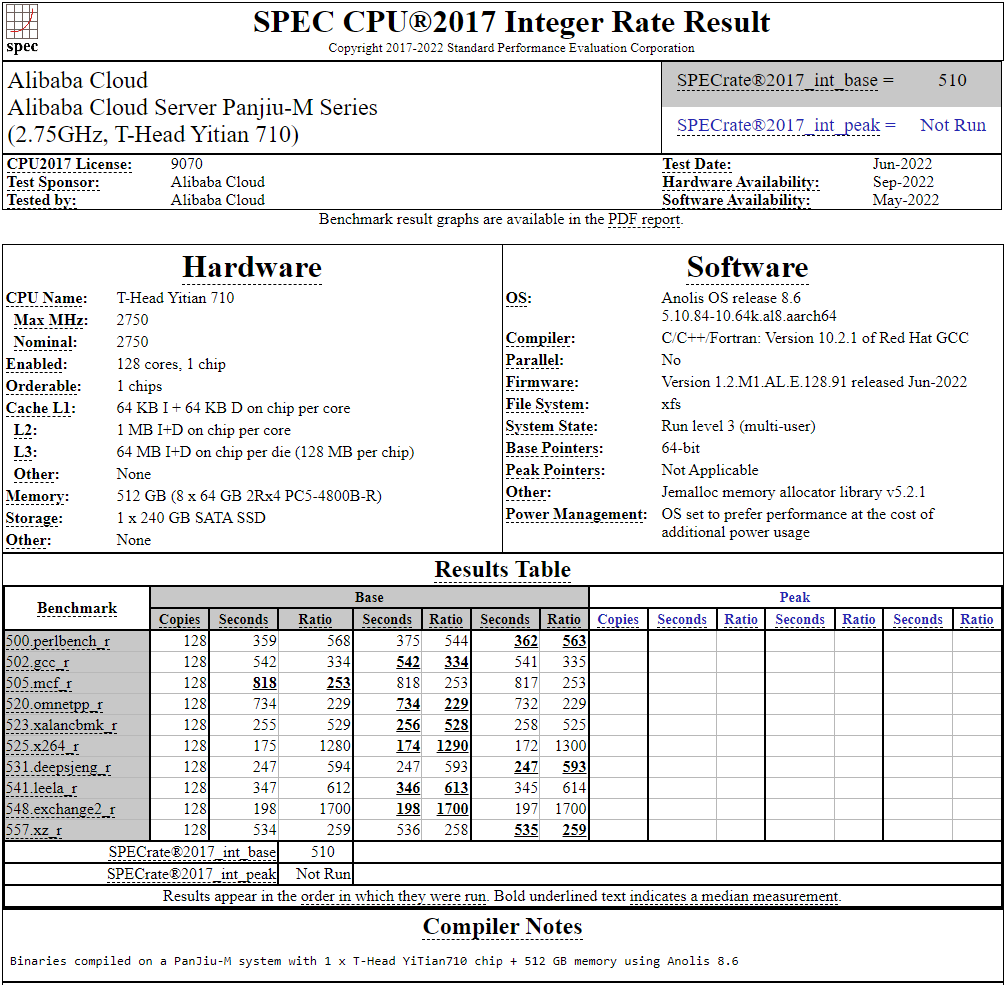 Процессор тестировался в составе референс-сервера Panjiu. Применялась 128-ядерная версия с частотой 2,75 ГГц, 1 Мбайт кеша L2 на ядро и 64 Мбайт кеша L3 на кристалл (128 Мбайт на сборку). Последнее позволяет говорить о том, что Alibaba также использует в своих процессорах чиплетную компоновку. 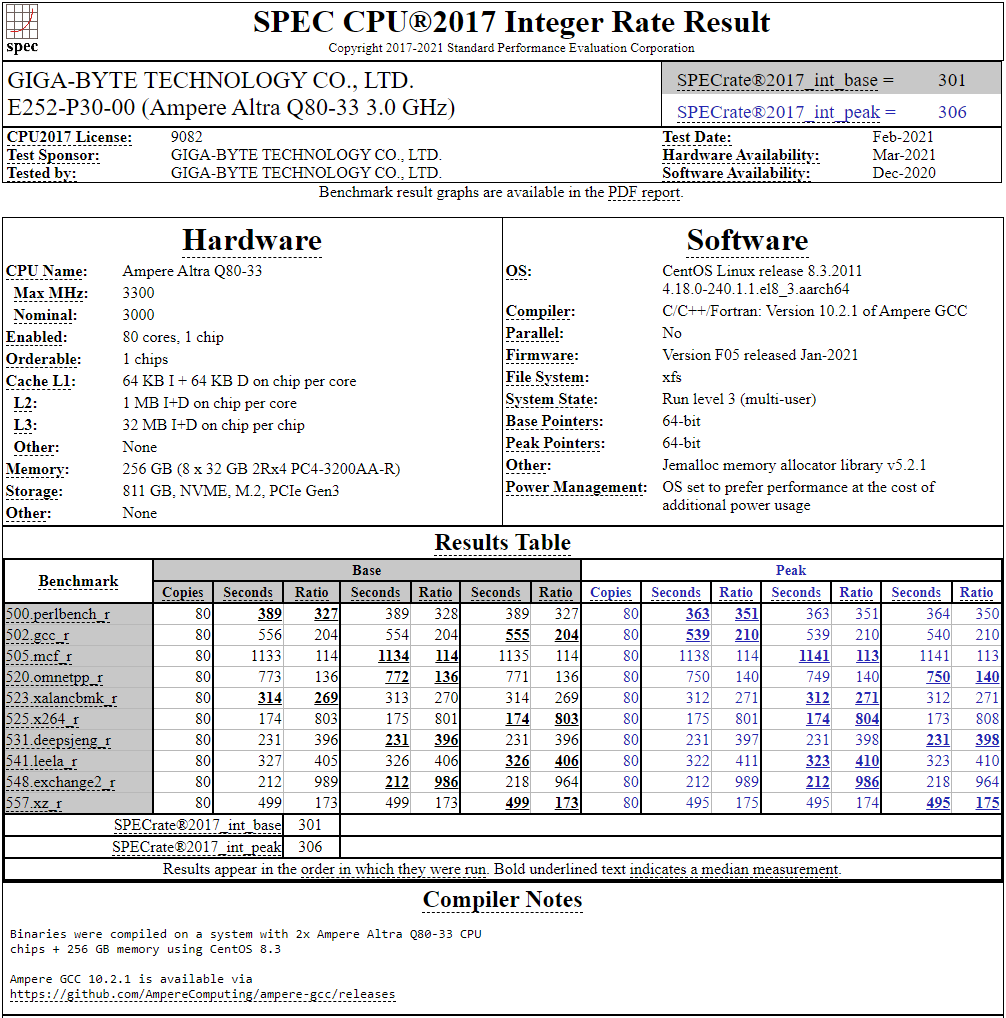 Результаты оказались существенно более высокими, нежели у Ampere Altra Q80-33; правда, стоит сделать скидку на то, что у Ampere использовалась 80-ядерная версия, а не более новая 128-ядерая Altra Max. Но в аутсайдерах оказался также и AMD EPYC 7773X (64 ядер/128 потоков, 2,2-3,5 ГГц, 768 Мбайт L3), показавший 440 очков против 510 у Yitian 710. Увеличенный объём кеша не слишком помог детищу «красных». 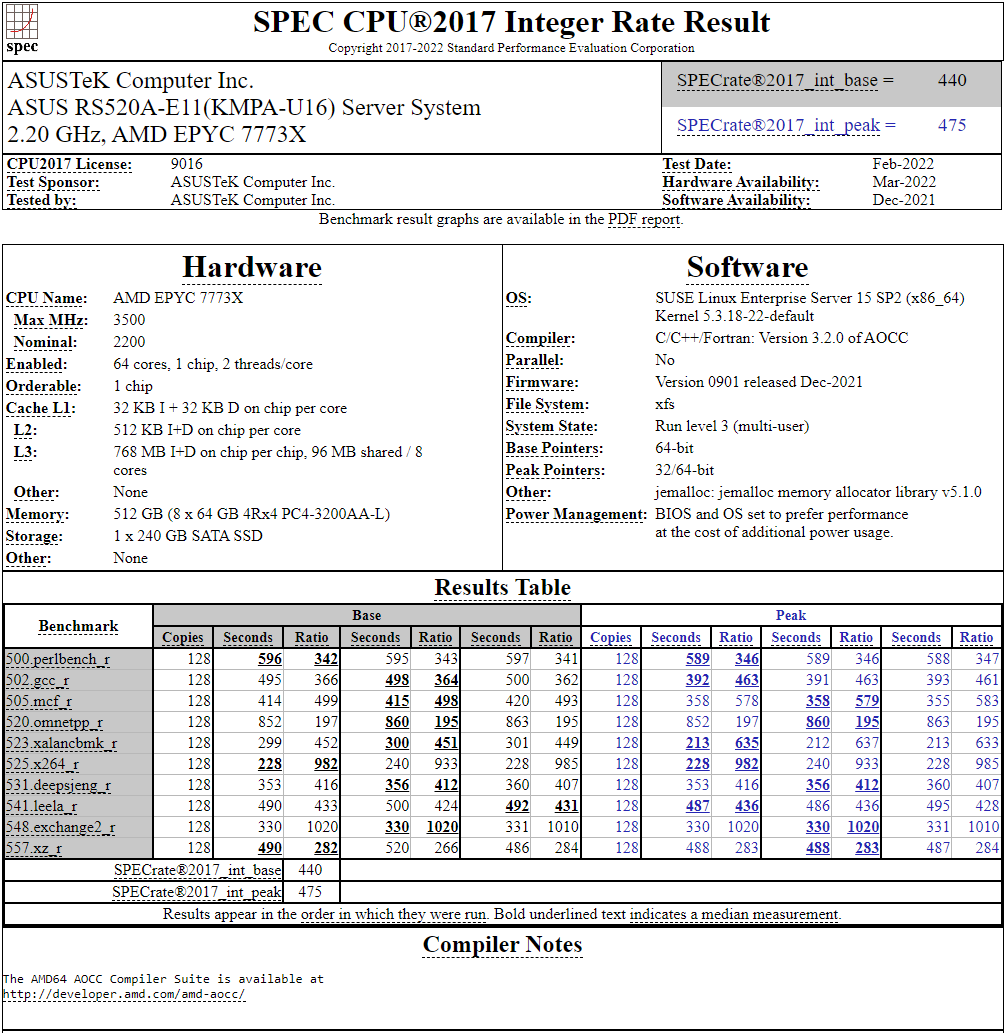 Таким образом, процессор на базе архитектуры Armv9 занял первое место там, где традиционно господствовали решения с архитектурой x86 — достаточно взглянуть на Топ-20 в рейтинге CPU2017 Integer. Можно сказать, что 128-ядерный процессор не вполне корректно сравнивать с 64-ядерным с поддержкой SMT, однако если технологии и архитектура позволяют разместить вдвое больше полноценных ядер в сопоставимом по размеру с AMD EPYC корпусе, так ли это важно? 
Текущий Tоп-20 целочисленной производительности в SPEC CPU2017 К сожалению, пока речь идёт только о целочисленных вычислениях. По неизвестной причине, Alibaba Cloud не опубликовала результаты CPU2017 Floating Point, где сравнение вышло бы существенно интереснее. В любом случае, монополия AMD на первые места пошатнулась; что же касается Intel, то в классе однопроцессорных систем самым мощным вариантом является 36-ядерный Xeon Platinum 8351N, который заведомо проиграет 64-128 ядерным монстрам AMD, Ampere, а теперь уже и Alibaba Cloud. |
|

