Материалы по тегу: s
|
21.02.2026 [14:38], Сергей Карасёв
Nautilus представила универсальный 4-МВт CDUКомпания Nautilus анонсировала блок распределения охлаждающей жидкости EcoCore FCD CDU, разработанный специально для крупномасштабных дата-центров, ориентированных на нагрузки ИИ и НРС. Утверждается, что новинка может быть интегрирована с СЖО любого типа, в том числе прямого и погружного. Мощность решения в зависимости от модификации варьируется от 2 до 4 МВт. Герметичная конструкция исключает риск утечек; говорится о возможности использования пресной, морской и промышленной воды. Опционально доступны дополнительные фильтры. 
Источник изображения: Nautilus Система спроектирована для бесшовной интеграции в существующие машинные залы: это обеспечивает максимально эффективное использование доступного пространства без ущерба для производительности, говорит компания. Допускается подача воды сверху и снизу, что позволяет адаптировать решение к конструктивным особенностям конкретного ЦОД. Благодаря точному контролю температуры достигается стабильное и надёжное охлаждение с учётом предъявляемых требований. Возможно масштабирование: в единой инфраструктуре могут быть объединены до шести модулей EcoCore FCD CDU. Реализованы протоколы Modbus RT, Modbus TCP, OPC UA для удалённого управления и мониторинга. Блок оснащён датчиками расхода, температуры и давления в первичном и вторичном контурах. Поддерживается резервирование по схеме N+2. Используются два источника питания; максимальное заявленное энергопотребление составляет 42 кВт. Габариты системы — 2,7 × 1,7 × 2,1 м, «сухая» масса — 3520–3550 кг.
20.02.2026 [15:59], Сергей Карасёв
Узкие специалисты: Talaas, разрабатывающая оптимизированные под конкретные ИИ-модели ускорители, получила на развитие $169 млнСтартап Taalas, разрабатывающий чипы, специально оптимизированные для работы с конкретными ИИ-моделями, провел раунд финансирования на сумму в $169 млн. В число инвесторов вошли Quiet Capital и Fidelity, а также венчурный капиталист Пьер Ламонд (Pierre Lamond). Таким образом, на сегодняшний день компания получила на развитие в общей сложности более $200 млн. Фирма Taalas вышла из крытого режима (stealth mode) в марте 2023 года. Стартап занимается созданием чипов, предназначенных для определённых LLM. Первым продуктом компании стало изделие, ориентированное на ИИ-модель Llama 3.1 8B. Утверждается, что этот процессор способен генерировать до 17 тыс. выходных токенов в секунду, что в 73 раза больше по сравнению с NVIDIA H200. При этом решение Taalas потребляет в 10 раз меньше энергии. 
Источник изображения: Taalas Оптимизация аппаратных ускорителей под конкретную ИИ-модуль повышает производительность и эффективность благодаря отказу от избыточных компонентов. Однако разработка таких узкоспециализированных изделий представляет собой сложный и дорогостоящий процесс. Компании Taalas удалось решить проблему, создав архитектуру, при которой для «тонкой» настройки требуется кастомизация только двух из более чем 100 слоев, из которых состоят её чипы. Кроме того, Taalas не использует в своих изделиях дорогостоящую память HBM. Это также упрощает конструкцию, позволяя упразднить компоненты, которые необходимы для обеспечения взаимодействия с HBM-модулями. В настоящее время Taalas работает над чипом, предназначенным для запуска ИИ-модели Llama с 20 млрд параметров: выпуск этого решения намечен на лето нынешнего года. Затем появится более мощный чип, ориентированный на LLM высокого уровня.
20.02.2026 [15:23], Владимир Мироненко
Anthropic планирует увеличить к 2029 году расходы на облака до $80 млрдК 2029 году затраты на облачные сервисы ИИ-стартапа Anthropic, согласно его собственным прогнозам, достигнут $80 млрд, сообщил ресурс The Information со ссылкой на свои источники. Расходы будут распределены между Google, Microsoft и Amazon. Помимо оплаты аренды серверов для моделей Claude, Anthropic также делится с облачными провайдерами частью прибыли от продаж своих ИИ-сервисов на их платформах. The Information сообщил со ссылкой на данные стартапа, что в 2024 году эта сумма составила $1,3 млн, и, согласно «самым оптимистичным прогнозам» ресурса, в 2025 году она составила $360 млн, в 2026 году вырастет до $1,9 млрд, а в 2027 году — до $6,4 млрд. Также, по словам источника, Anthropic отчисляет клиентам до 50 % своей валовой прибыли от продаж ИИ-решений на AWS, рассчитываемой на основе выручки за вычетом расходов на облачные ресурсы. Для сравнения, Google обычно получает от 20 % до 30 % чистой выручки после вычета затрат на инфраструктуру от перепродажи ПО своих партнёров. 
Источник изображения: Anthropic Как утверждает генеральный директор Anthropic Дарио Амодеи (Dario Amodei), компания тратит меньше средств на вычислительные мощности ЦОД по сравнению с другими компаниями в сфере ИИ. Он отметил, что чрезмерные расходы могут быть «разорительными» в случае, когда выручка не гарантирована. Anthropic давно пользуется услугами Google Cloud, и в октябре прошлого года заключила сделку, обеспечивающую ей доступ к облачным ресурсам провайдера мощностью более 1 ГВт с возможностью использования до 1 млн TPU от Google. С этим проектом может быть связана сделка Anthropic по поводу $50 млрд инвестиций в вычислительную инфраструктуру в США в сотрудничестве с Fluidstack. Кроме того, у Anthropic очень тесные отношения с AWS, которая много инвестировала в стартап и развернула для него один из крупнейших в мире ИИ-кластеров Project Rainier. Наконец, в прошлом году компания подписала крупное соглашение с Microsoft Azure.
19.02.2026 [12:26], Сергей Карасёв
«НВБС» представила российские серверы «Необайт» на платформах Intel и AMDКомпания «НВБС», российский системный интегратор и производитель технологических решений, анонсировала собственные серверы семейства «Необайт». Дебютировали модели NeoByte NBR220 и NeoByte NBR680 на аппаратной платформе Intel, а также NeoByte NBR685 с процессорами AMD. По словам компании, новинки «сопоставимы с решениями ведущих компаний на рынке, но при этом в среднем стоят на 10–15 % дешевле за счёт широкого пула поставщиков и оптимизированной логистики». Система NeoByte NBR220 типоразмера 2U может нести на борту два чипа Intel Xeon Sapphire Rapids или Emerald Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-4800. В зависимости от конфигурации во фронтальной части возможна установка 12 накопителей LFF/SFF или 24 устройств SFF с интерфейсом SATA/SAS/NVMe. В тыльной зоне корпуса расположены посадочные места ещё для четырёх накопителей LFF/SFF (SATA/SAS/NVMe), тогда как внутри есть два коннектора для SSD формата M.2 (SATA/NVMe). Реализована поддержка до 10 стандартных слотов PCIe и одного слота OCP 3.0. В оснащение входят контроллер AST2600, два сетевых порта 1GbE, выделенный сетевой порт управления 1GbE, четыре порта USB 3.0 (по два спереди и сзади), два интерфейса D-Sub (по одному спереди и сзади) и последовательный порт. Питание обеспечивают два блока с резервированием мощностью 800/1300/1600/2000 Вт. Сервер оптимизирован для ИИ-задач, виртуализации, баз данных и файловых хранилищ. Платформа практически идентична представленным ранее серверам «Аквариус» AQserv T50 D224RS и T50 D212RS. 
Источник изображений: «НВБС» Модель NeoByte NBR680 стандарта 6U имеет аналогичные характеристики подсистем CPU, ОЗУ, хранения данных и интерфейсов ввода/вывода. При этом возможна установка до восьми GPU-ускорителей двойной ширины. Есть пять стандартных слотов PCIe и один слот OCP; передняя панель поддерживает до трёх стандартных слотов PCIe и один слот OCP. Мощность каждого из двух блоков питания — 2700 или 3200 Вт. Машина предназначена для научных исследований и крупных ИИ-проектов.  В свою очередь, GPU-сервер NeoByte NBR685 формата 6U рассчитан на два процессора AMD EPYC 9005 Turin или EPYC 9004 Genoa с показателем TDP до 500 Вт. Предусмотрены 24 слота для модулей оперативной памяти DDR5-4800. Прочие характеристики идентичны версии NeoByte NBR680, включая поддержку восьми GPU-ускорителей двойной ширины. Система подходит для анализа больших данных в реальном времени, криптографии и блокчейна.  Все новинки могут быть опционально укомплектованы контроллером SAS RAID/HBA. Заявлена совместимость с Windows Server 2022 SLES 12.5 и выше, RHEL7.8 и выше, Ubuntu18.04 и выше, CentOS7.6 и выше, Vmware ESXi 7.0 GA и выше. Гарантия производителя достигает пяти лет. Также «НВБС» говорит, что «не зависит от санкций, что снижает риски ограничения поставок».
18.02.2026 [11:29], Сергей Карасёв
AWS внедрила вложенную виртуализацию для инстансов EC2Облачная платформа AWS сообщила о том, что некоторые её инстансы EC2 получили поддержку вложенной виртуализации (Nested Virtualization). Это позволяет решать определённые специфичные задачи, например, работать с эмуляторами мобильных приложений или выполнять моделирование автомобильного оборудования. Вложенная виртуализация даёт возможность запускать гипервизор внутри виртуальной машины, которая сама работает на другом гипервизоре. Иными словами, формируется виртуальная машина внутри виртуальной машины. Такой подход ориентирован на разработку и тестирование различных программных решений без использования физических серверов. Метод может быть полезен в производственной среде для контейнеризированных рабочих нагрузок, где часто применяются инструменты вроде Kubernetes и Docker. 
Источник изображения: AWS AWS внедрила поддержку вложенной виртуализации в инстансы EC2 C8i, M8i и R8i. Все они базируются на платформе Intel Xeon 6 в кастомном исполнении. В этих процессорах реализована усовершенствованная технология Trust Domain Extensions (TDX), которая обеспечивает улучшенную изоляцию между гостевой ОС и гипервизором. Все экземпляры EC2 работают под управлением собственного гипервизора Amazon Nitro. В целом, архитектура вложенной виртуализации состоит из трех уровней. Это физическая инфраструктура AWS и гипервизор Nitro, формирующие нулевой уровень (L0). На первом уровне (L1) функционирует клиентский экземпляр EC2 с гипервизором. Второй уровень (L2) состоит из одной или нескольких виртуальных машин, созданных в инстансе EC2. В качестве гипервизоров уровня L1 в настоящее время могут использоваться Microsoft Hyper-V и KVM. Вложенная виртуализация доступна во всех регионах присутствия AWS.
16.02.2026 [15:49], Владимир Мироненко
Облачные сервисы в 2025 году росли в России самыми быстрыми темпами, опередив ИИ-сегментВ 2025 году рынок облачных инфраструктурных и платформенных сервисов показал самые высокие темпы роста среди сегментов российской IT-индустрии, составив 226,9 млрд руб. (рост год к году — на 36,7 %), сообщается в исследовании MWS Cloud (входит в МТС Web Services). Он опередил по темпам роста даже бурно развивающийся ИИ-рынок, увеличившийся на 35,1 % — до 60,8 млрд руб. Третье место в этом рейтинге занял сегмент ПО для взаимодействия с клиентами, увеличившийся на 26,6 %, от которого ненамного отстал сегмент офисного ПО (26,4 %). Всего российский рынок софта в 2025 года вырос на 23 % — до 1491,8 млрд руб. Согласно исследованию, на втором месте в России по объёму в прошлом год был рынок ПО для управления предприятиями и бухгалтерией — 173,6 млрд руб., на третьем — рынок управления данными — 156,9 млрд руб. Далее следуют рынки ПО для взаимодействия с клиентами — 155,7 млрд руб., информационной безопасности — 146,3 млрд руб., платформенного софта — 142,6 млрд руб., приложений для управления бизнесом — 106,2 млрд руб., офисного ПО — 100,4 млрд руб. 
Источник изображения: İsmail Enes Ayhan/unsplash.com Доля облачных решений на рынке софта России выросла с 10,7 % в 2021 году до 15,2 % в 2025 году, и, как ожидают в MWS Cloud, в 2026 года составит 15,8 %. Исследователи отметили, что доля Топ-5 облачных провайдеров на облачном рынке также растёт: с 63 % в 2022 году до 71 % в 2024-м и 72 % — в 2025-м. В 2026 году, как ожидается, она достигнет 74 %. Сообщается, что основной спрос формируется за счёт масштабирования ранее внедрённых облачных решений, оптимизации эксплуатационных затрат и перехода компаний от капитальной модели инвестиций к операционной. В структуре облачного рынка доля IaaS превышает 80 % совокупного объёма, что отражает продолжающуюся миграцию базовых ИТ-систем и вычислительных ресурсов в облако. В свою очередь, сегмент PaaS и платформенных сервисов отличается более высокими темпами роста при сравнительно небольшой текущей базе. Аналитики ожидают дальнейшего ускорения роста сегмента PaaS в текущем году на фоне распространения платформенных инструментов разработки, роста числа проектов с контейнеризацией и микросервисной архитектурой, а также стремления компаний сократить нагрузку на ИТ-команды за счёт использования управляемых сервисов.
16.02.2026 [11:16], Руслан Авдеев
Попутного ветра: AWS резко сократила развёртывание СЖО для Trainium3, решив обойтись преимущественно воздушным охлаждениемAmazon Web Services (AWS) резко увеличит долю воздушного охлаждения в серверах на базе ускорителей Trainium3. Производство серверов намерены нарастить во II квартале 2026 года, но жидкостное охлаждение в них будут применять далеко не так активно, как ожидалось, сообщает DigiTimes. Если ранее планировалось применять системы жидкостного и воздушного охлаждения с соотношением 1:1, то теперь на первые будет приходиться лишь 10 % от общего числа, что способно замедлить внедрение СЖО в ЦОД. При этом ранее отраслевые эксперты прогнозировали, что проникновение СЖО на рынок ИИ-серверов вырастет с менее 20 % в 2025 году до более 50 % в 2026-м. Это должно было случиться за счёт расширения поставок GPU- и ASIC. AWS даже смогла разработать в рекордно короткие сроки собственную платформу СЖО, что привело к падению акций Vertiv, одного из бенефициаров ИИ-бума. Новый подход к оборудованию Trainium3 ставит под вопрос будущее и динамику перехода к жидкостному охлаждению. Тем не менее, рост производства Tranium 3 в любом случае поддержит спрос на продукцию ключевых партнёров AWS: Wiwynn, Accton, Auras, Taiwan Microloops и Nan Juen International (Repon). Вероятно, спрос позволит загрузить производственные мощности до конца 2026 года. По мнению аналитиков, решение AWS во многом связано с TDP ускорителей на уровне 800 Вт (хотя раньше говорили об 1000 Вт) — для них, вероятно, достаточно и для современного воздушного охлаждения, что снижает необходимость перехода на более дорогие и сложные СЖО. 
Источник изображений: AWS По данным AWS, Trainium3 приблизительно на 40 % производительнее в сравнении с ускорителями предыдущего поколения. Также компания объявила о капитальных затратах до $200 млрд на расширение ИИ-инфраструктуры, в т.ч. производство собственно ускорителей — на 2027 год запланированы поставки уже Trainium4. Так или иначе, даже после снижения доли СЖО спрос на компоненты у партнёров должен увеличиться за счёт роста производства в целом. Рост популярности жидкостного охлаждения в ИИ ЦОД в последние годы во многом обусловлен ростом TDP ускорителей NVIDIA. Если у H200 показатель был на уровне около 700 Вт, то у B200 — порядка 1000 Вт, а у B300 — уже 1400 Вт. Для будущих архитектур с двумя чипами значения будут ещё выше. В результате операторам ЦОД требуется эффективный отвод тепла, что могут обеспечить СЖО. Кроме того, это позволяет повысить плотность размещения оборудования.  В сегменте ASIC рост TDP заметно ниже. Так, для Trainium2 речь шла об около 500 Вт, у Trainium3 — всего 800 Вт, поэтому воздушное охлаждение — вполне рабочий вариант, за исключением некоторых сценариев, например, с высокой плотностью размещения оборудования. Также источники в цепочке поставок подчёркивают, что жидкостные системы дороже устанавливать и обслуживать в сравнении с современными воздушными вариантами. При этом экосистема производства и обслуживания СЖО часто оценивается как «менее зрелая». Благодаря этому организовать поставки серверов с воздушным охлаждением можно быстрее, и они будут более стабильными. Беспокойство операторов ЦОД может вызывать и репутация жидкостных систем. Например, в конце января Wave Power объявила о том, что некоторые проданные компоненты СЖО для ИИ-систем привели к повреждению оборудования, поэтому компании пришлось выложить $4,5 млн, чтобы заключить мировое соглашение. По мнению экспертов, утечки в СЖО — довольно распространённое явление, не привязанное к конкретному вендору, но каждый подобный инцидент свидетельствует о потенциальных проблемах, которые заказчикам приходится принимать в расчёт.  Хотя системы жидкостного охлаждения технически предпочтительнее для самых энергоёмких нагрузок благодаря высокой эффективности теплоотвода, потенциалу снижения показателя PUE и способности обеспечить экономию пространства, на примере Trainium3 можно оценить, как совокупность факторов, включая совокупную стоимость владения (TCO) и операционные риски влияют на сроки внедрения СЖО. Изменение планов AWS может повлиять на всю индустрию ИИ ЦОД, которая может замедлить повсеместный переход на жидкостное охлаждение, по крайней мере, в краткосрочной перспективе. Вместе с тем даже для ИИ-платформ нынешнего поколения гиперскейлеры разработали гибридные варианты охлаждения, позволяющие использовать современные системы в старых ЦОД, не рассчитанных изначально на крупномасштабные СЖО. Так, Meta✴ «растянула» суперускорители NVIDIA GB200 на шесть стоек вместо одной, чтобы разместить там теплообменники, а Microsoft с той же целью «пристроила» к стойке с оборудованием модуль шириной в ещё пару стоек. Google же предпочитает для своих TPU именно СЖО.
16.02.2026 [10:11], Сергей Карасёв
Китайская Montage Technology выпустила серверные процессоры Jintide на базе Intel Xeon 6Китайская компания Montage Technology, на днях осуществившая первичное публичное размещение акций (IPO) на Гонконгской фондовой бирже, выпустила серверные процессоры Jintide следующего поколения, в основу которых положена архитектура Intel Xeon 6, доработанная под требования заказчиков в КНР. В частности, вышли изделия Jintide C6P, которые фактически представляют собой процессоры Intel Xeon 6 семейства Granite Rapids-SP на базе производительных ядер P-core. Их количество в китайских чипах достигает 86 с возможностью одновременной обработки до 172 потоков инструкций, а максимальный объем кеша L3 составляет 336 Мбайт. Реализована 8-канальная подсистема памяти DDR5 с поддержкой модулей RDIMM-6400 и MRDIMM-8000. Процессоры Jintide C6P могут применяться в одно- и двухсокетных конфигурациях. Говорится о поддержке 88 линий PCIe 5.0 и протокола CXL 2.0. Пропускная способность шины UPI достигает 24 ГТ/с. Обеспечивается полная совместимость с набором инструкций x86. Чипы ориентированы на дата-центры и облачные инфраструктуры с высокой вычислительной нагрузкой. 
Источник изображений: Montage Technology Кроме того, дебютировали решения Jintide C6E — это модифицированные изделия Intel Xeon 6 Sierra Forest-SP с энергоэффективными ядрами E-core: их количество достигает 144. Размер кеша L3 составляет до 108 Мбайт. Процессоры имеют восемь каналов памяти DDR5-6400 и до 88 линий PCIe 5.0. Упомянута поддержка CXL 2.0 и шины UPI с пропускной способностью до 24 ГТ/с. Решения Jintide C6E могут устанавливаться в одно-и двухсокетные системы.  Компания также анонсировала чип Jintide M88STAR5(N), на основе которого реализуются различные функции безопасности. Изделие, использующее технологию Mont-TSSE (Trust & Security System Extension), отвечает за аппаратное шифрование/дешифрование данных в соответствии с местными стандартами и доверенные вычисления. На кристалле присутствуют нескольких генераторов случайных чисел, а общая пропускная способность достигает 160 Гбит/с через PCIe 5.0 х8. Упомянута поддержка стандартов TPM, TCM и TPCM, а также интерфейсов SMBus, I3C, UART, SPI и GPIO. 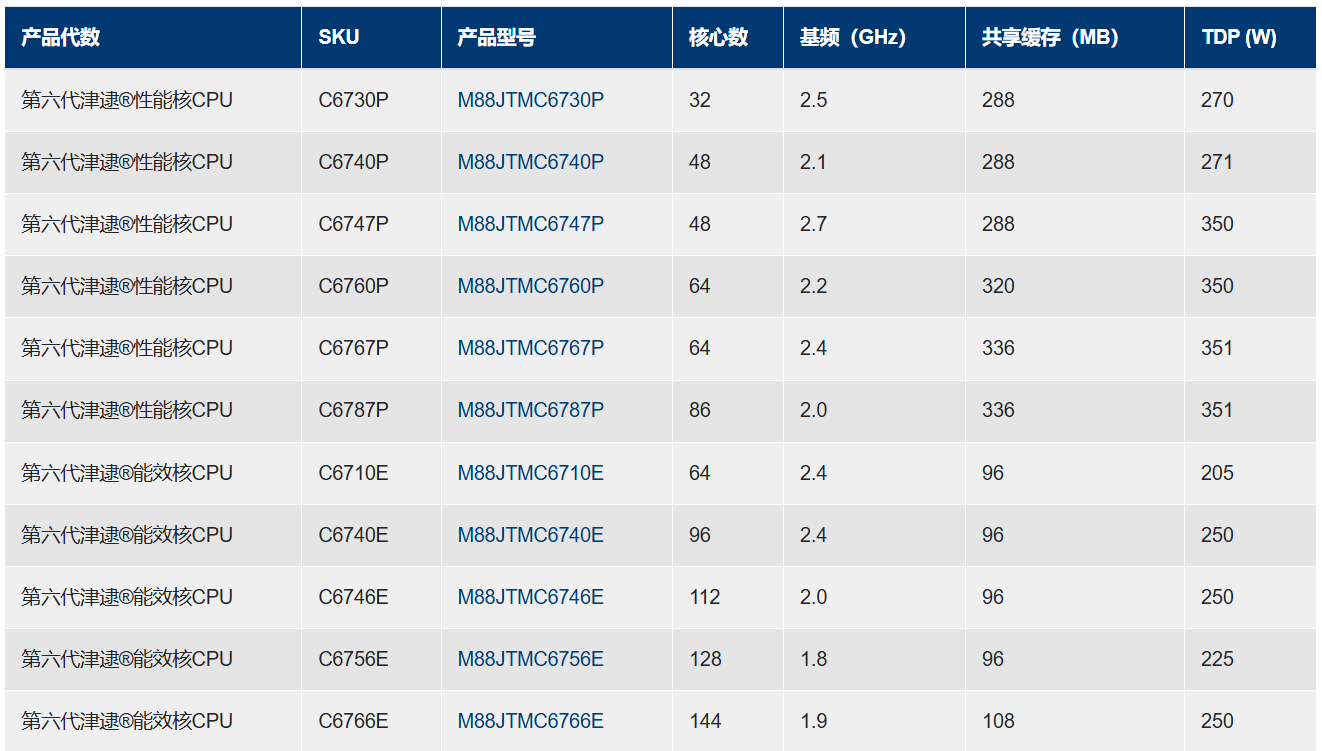 Наконец, Montage Technology представила чип Jintide M88IO3032 IOH (I/O Hub), предназначенный для использования с CPU нового поколения. Изделие обеспечивает поддержку PCIe 3.0, SATA 3.2 (до 20 портов; RAID 0/1/5/10), USB 3.2/2.0 и пр.
15.02.2026 [15:46], Владимир Мироненко
Legrand приобрела Kratos и инвестировала в Accelsius для расширения предложений для ИИ ЦОДLegrand, французский поставщик решений для электротехнической и цифровой инфраструктуры зданий, обслуживающей жилой, коммерческий, промышленный рынки и ЦОД, объявил о приобретении Kratos Industries из Арвады (Arvada, штат Колорадо), производителя низковольтного (НВ) и средневольтного (СВ) силового оборудования. Также Legrand сообщила об участии в раунде финансирования серии B компании Accelsius, специализирующейся на двухфазном прямом жидкостном охлаждении. «В совокупности эти шаги значительно расширяют возможности Legrand в области распределения электроэнергии и передового управления тепловыми процессами, позволяя ЦОД удовлетворять растущие потребности в ИИ и высокоплотных вычислительных средах», — отметила Legrand в пресс-релизе. «Принимая Kratos в состав Legrand, мы расширяем наши возможности по обслуживанию всей системы электропитания ЦОД, гарантируя нашим клиентам наличие единого, надёжного партнёра для всей их экосистемы электропитания», — заявила компания. Kratos использует вертикально интегрированную модель с подходом «проектирование под заказ». Благодаря её приобретению Legrand может предложить более надёжный портфель решений для критически важных систем электропитания на рынке ЦОД, охватывая весь спектр решений от кабельных лотков с нагрузочными стендами до шинопроводов и блоков распределения питания (PDU) для стоек. 
Источник изображения: Legrand Что касается инвестиций Legrand в Accelsius, то в рамках партнёрства компании планируют совместные инициативы по разработке СЖО для интеграции в инфраструктуру на уровне стоек, ориентированные в ИИ-фабрики и другие высокопроизводительные вычислительные среды. Хотя большая часть бизнеса Legrand приходится на электротехнические решения для жилых и коммерческих зданий, ИИ оказал преобразующее воздействие на компанию, заявил генеральный директор Legrand Бенуа Кокар (Benoit Coquart) агентству Reuters. По его словам, на решения для ЦОД приходится 26 % выручки компании в 2025 году, и этот показатель может достичь 40 %. Выручка Legrand в 2025 году составила €9,48 млрд ($11,26 млрд, рост год к году на 9,6 %), что немного выше прогноза аналитиков, равного €9,46 млрд. Скорректированная операционная прибыль компании выросла год к году на 10,5 % до $1,96 млрд, что соответствует ожиданиям аналитиков. Legrand ожидает рост продаж в 2026 году на 10–15 %, скорректированную операционную маржу на уровне 20,5–21 %.
15.02.2026 [15:10], Сергей Карасёв
Siemens наращивает выручку и объём заказов на фоне бума ИИНемецкий конгломерат Siemens отрапортовал о работе в I четверти 2026 финансового года, которая была закрыта 31 декабря 2025-го. Выручка за трёхмесячный период достигла €19,14 млрд, что на 4 % больше по сравнению с результатом за аналогичный период предыдущего финансового года, когда было получено €18,35 млрд. Общий объём заказов в годовом исчислении увеличился на 7 % — с €20,07 млрд до €21,37 млрд. При этом чистая прибыль сократилась на 43 %, составив €2,22 млрд против €3,87 млрд годом ранее. Однако в результаты I квартала 2025 финансового года включена прибыль в размере €2,1 млрд евро (после уплаты налогов) от продажи Innomotics — подразделения по производству двигателей и приводов. 
Источник изображений: Siemens Увеличение выручки Siemens связывает с бумом ИИ, который спровоцировал расширение глобальной инфраструктуры дата-центров. В подразделении промышленных решений Siemens Digital Industries квартальная выручка поднялась на 12 % — с €4,05 млрд до €4,53 млрд, тогда как объём заказов увеличился с €4,21 млрд до €4,85 млрд, то есть, на 15 %. В сегменте умных инфраструктур Siemens Smart Infrastructure продажи выросли на 5 % — с €5,29 млрд до €5,53 млрд, а объём заказов прибавил 16 %, достигнув €7,17 млрд против €6,20 млрд годом ранее. В целом, индустриальный бизнес Siemens в I квартале 2026 финансового года обеспечил прибыль в размере €2,90 млрд против €2,52 млрд годом ранее. 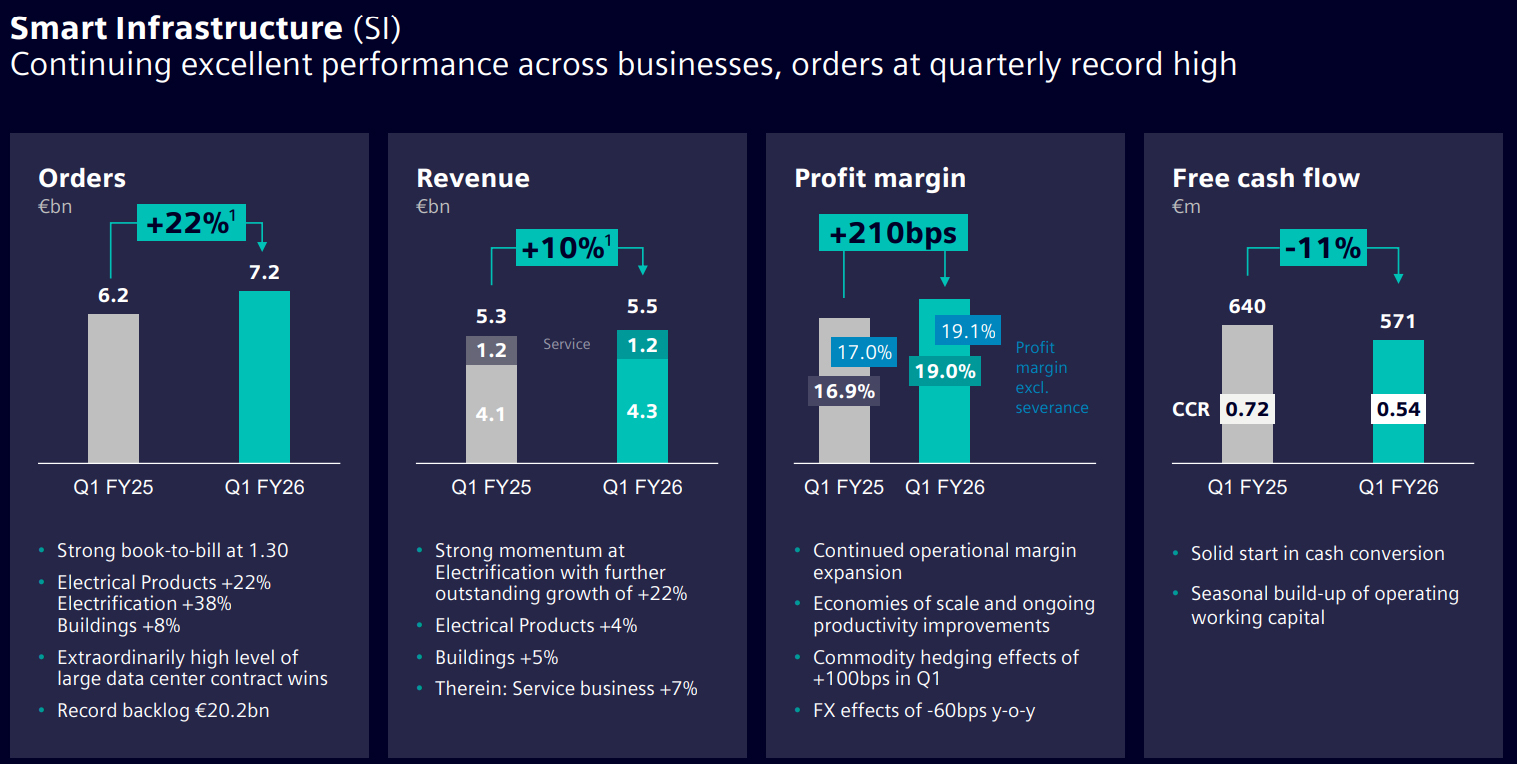 Siemens ожидает, что стремительное развитие ИИ в промышленном секторе и высокий спрос на соответствующие продукты для дата-центров и платформ автоматизации продолжат оказывать положительное влияние на финансовые показатели компании. Siemens, в частности, говорит о значительной динамике в США и Китае. Кроме того, Siemens наряду наряду с Caterpillar, GE Vernova и Mitsubishi Heavy Industries выиграла от резко возросшего спроса на газовые турбины для питания ИИ ЦОД. |
|

