Материалы по тегу: databricks
|
10.02.2026 [16:10], Руслан Авдеев
Databricks завершила раунд финансирования на $7 млрдDatabricks объявила о привлечении акционерного и долгового финансирования на сумму более $7 млрд на дальнейшее развитие. Впервые о привлечении акционерного финансирования сообщалось ещё в конце прошлого года, доля соответствующего капитала в инвестициях составила более $5 млрд, сообщает Silicon Angle. Такого объёма привлечения средств удалось добиться благодаря расширению участия JPMorgan Chase, выступившей в четвёрке ключевых инвесторов последнего раунда. Также к сделке присоединились Microsoft и несколько крупных финансовых структур. По информации Databricks, ещё $2 млрд привлечено в долг при участии JPMorgan Chase, Barclays, Citi, Goldman Sachs и Morgan Stanley. Оценка капитализации компании составила $134 млрд. Полученные средства будут направлены на усовершенствование продуктов Genie и Lakebase — важных элементов стратегии Databricks в сфере ИИ. Первый представляет собой ИИ-помощника для запросов данных на платформе самой компании с использованием естественного языка. Возможна интеграция во внешние сервисы. Помощник генерирует для платформы SQL-запросы, но для распространённых запросов во избежание галлюцинаций со стороны ИИ можно использовать заблаговременно подготовленный SQL-код. 
Источник изображения: airfocus/unsplash.com Lakebase появилось в портфеле компании в 2025 году после покупки стартапа за $1 млрд. Это управляемая база данных на базе PostgreSQL. Lakebase может использоваться ИИ-агентами для хранения данных о конфигурации и информации, которая включается в ответы на промпты. В декабре компания объявила, что сервис насчитывает тысячи клиентов, и тогда же представила функцию, позволяющую полностью отключать инстансы, когда те не используются — это снижает стоимость эксплуатации. Databricks сообщает, что новые инвестиции позволят удвоить усилия по развитию Lakebase, разработчики смогут создавать операционные базы данных для ИИ-агентов. В то же время средства будут вкладываться и в Genie, чтобы каждый сотрудник мог «общаться» со своими данным в чате, получая точные аналитические данные. Кроме того, привлечённые средства также будут потрачены на предоставление ликвидности сотрудникам (фактически выкуп у них долей) и приобретение других компаний. Компания объявила, что в IV квартале прогнозируемый годовой оборот достиг $5,4 млрд, рост составил более 65 % г/г. Она вышла на положительный свободный денежный поток (free cash flow) за последние 12 мес., а прогнозируемый ARR ИИ-продуктов достиг $1,4 млрд. Чистый коэффициент удержания клиентов превысил 140 % — фактически расходы на платформу увеличивают уже действующие клиенты. Разработчик ПО признаёт, что частично рост продаж обусловлен спросом со стороны крупнейших клиентов. Более 800 организаций тратят на решения компании не менее $1 млн/год, а 70 клиентов — более $10 млн.
18.12.2025 [09:50], Владимир Мироненко
Databricks привлекла $4 млрд, увеличив рыночную стоимость до $134 млрдDatabricks объявила о завершении раунда финансирования серии L, в ходе которого она привлекла более $4 млрд с оценкой рыночной стоимости в $134 млрд. Это на $34 млрд больше её оценки после предыдущего раунда финансирования в августе этого года. С момента основания в 2013 году Databricks провела 12 раундов финансирования, в ходе которых привлекла $19 млрд инвестиций. Из них $14 млрд — в течение последних двух лет. Раунд финансирования возглавили Insight Partners, Fidelity Management & Research Company и JP Morgan Asset Management при участии Andreessen Horowitz, фондов и счетов под управлением BlackRock, Blackstone, Coatue, GIC, MGX, NEA, Ontario Teachers Pension Plan, Robinhood Ventures, а также счетов, управляемых T. Rowe Price Associates, Inc., Temasek, Thrive Capital и Winslow Capital. Резкому росту оценки компании способствовал быстрый рост её выручки. Databricks сообщила, что её расчётная годовая выручка (Revenue Run Rate, RRR) в III квартале превысила $4,8 млрд (рост год к году на 55 %), причём более $1 млрд приходится на ИИ-решения и ещё $1 млрд — на платформу для хранения данных Data Warehousing. 
Источник изображений: Databricks В прошлом году, когда компания привлекла $10 млрд в рамках раунда J, у неё было более 500 клиентов с ежегодным регулярным доходом (ARR) более $1 млрд, сообщил ресурс Blocks & Files. Сейчас таких клиентов более 700. Коэффициент удержания клиентов составляет более 140 %, поскольку существующие клиенты со временем тратят больше денег на услуги Databricks. Компания также отметила популярность Lakebase, управляемой базы данных на основе PostgreSQL, запущенной компанией в июне. Компания сообщила, что сервис уже используют тысячи клиентов и и наращивает выручку вдвое быстрее, чем её решение для хранилищ данных. Привлечённые инвестиции Databricks планирует направить на дальнейшую разработку трёх «стратегических продуктов». Первый из них — Lakebase, «первая бессерверная база данных Postgres, специально разработанная для эпохи ИИ». Lakebase идеально подходит для хранения точек данных, которые ИИ-модели используют для принятия решений, пишет SiliconANGLE. Сервис работает со сжатыми версиями бизнес-данных, которые нейронной сети проще обрабатывать, чем исходную информацию, и регулярно обновляет их по мере появления новой информации Например, магазин может преобразовать статистику об активности посетителей веб-сайта в высокоуровневые данные о том, какие товарные объявления вызывают наибольший интерес. Lakebase использует технологии приобретённого за $1 млрд стартапа Neon. Lakebase может предоставлять функции нейронным сетям, развёрнутым как на платформе Databricks, так и во внешней инфраструктуре. 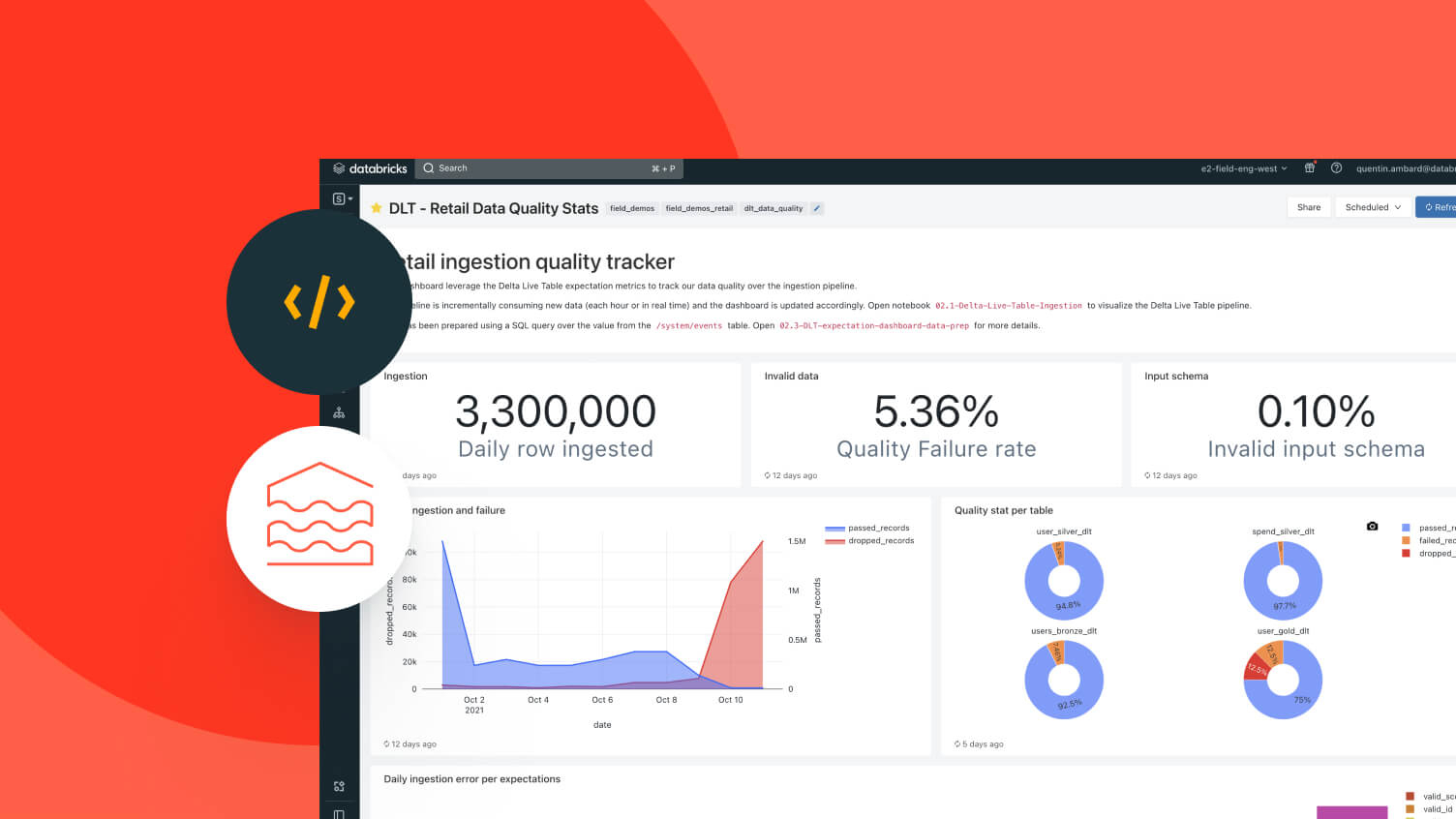 Ещё одно направление инженерных разработок компании — решение Agent Bricks, которое упрощает создание и масштабирование высококачественных агентов на основе их данных. Инструмент генерирует синтетические обучающие данные, которые можно использовать для оптимизации агентов для конкретных задач. Кроме того, он создаёт эталонные тесты для измерения эффективности обучения ИИ и упрощает связанные задачи, такие как разработка системных подсказок. Компании могут превратить ИИ-агентов, созданных с помощью Lakebase и Agent Bricks, в приложения, используя Databricks Apps, третий продукт, который компания планирует усовершенствовать. Databricks Apps ускоряет разработку приложений за счет автоматизации ряда ручных задач. Это включает в себя процесс внедрения функций аутентификации, контроля доступа и других мер кибербезопасности. «Благодаря интеграции транзакционных данных в Lakebase, интуитивно понятному интерфейсу и возможности создания передовых многоагентных систем с помощью Agent Bricks, мы предоставляем клиентам единую основу для построения надёжных, высокопроизводительных приложений для обработки данных в масштабе предприятия», — заявил соучредитель и генеральный директор Databricks Али Годси (Ali Ghodsi).  Компания сообщила, что будет использовать новый капитал, чтобы помочь клиентам создавать приложения и агентов на основе ИИ, используя Lakebase в качестве системы учёта, Databricks Apps в качестве уровня пользовательского интерфейса и Agent Bricks для работы с многоагентными системами. Также сообщается, что новое финансирование позволит обеспечить ликвидность для сотрудников, чтобы они могли реализовать свои акции, и, как ожидается, будет способствовать дальнейшим приобретениям и исследования в области ИИ.
01.12.2025 [12:43], Сергей Карасёв
Databricks рассчитывает привлечь $5 млрд при оценке $134 млрдКомпания Databricks, занимающаяся разработкой решений в сфере аналитики данных и ИИ, по информации ресурса SiliconANGLE, ведёт переговоры о привлечении нового финансирования в размере $5 млрд. В случае проведения соответствующего инвестиционного раунда оценка фирмы может достичь $134 млрд, что примерно в 32 раза превысит ожидаемую выручку в объёме $4,1 млрд в 2026 году (по данным Reuters). Databricks была основана в 2013 году. Компания создала единую платформу для обработки данных, аналитики и машинного обучения. Кроме того, Databricks предлагает специализированные инструменты корпоративного класса, обеспечивающие полный цикл разработки ИИ — от проектирования функций и обучения моделей до оценки и развёртывания. У Databricks более 20 тыс. клиентов по всему миру: в их число входят OpenAI Group PBC, Block, Shell, Siemens AG, Toyota Motor, AT&T, Walgreens Boots Alliance и Rivian Automotive. 
Источник изображения: Databricks На сегодняшний день Databricks провела 15 раундов финансирования, в ходе которых было получено в общей сложности около $15,7 млрд. В частности, в январе нынешнего года компания закрыла инвестиционную программу Series J, в ходе которой на развитие привлечено $10 млрд (плюс дополнительное долговое финансирование на сумму $5,25 млрд). При этом рыночная стоимость Databricks достигла $62 млрд. В августе этот показатель увеличился до $100 млрд: тогда компания сообщила о выполнении условий привлечения венчурного капитала в рамках раунда Series K. В число инвесторов Databricks входят Andreessen Horowitz, Insight Partners LP, MGX Capital, Thrive Capital Management, WCM Investment Management, The Blackstone Group, Apollo Global Management, Blue Owl Capital, JPMorgan Chase & Co., Barclays, Citigroup, Goldman Sachs Group и Morgan Stanley.
29.09.2025 [12:35], Сергей Карасёв
Databricks и OpenAI помогут клиентам в развёртывании приложений на базе передовых ИИ-моделейСтартап Databricks, специализирующийся на создании решений в сфере аналитики данных и ИИ, и компания OpenAI объявили о заключении многолетнего соглашения о сотрудничестве. Партнёры помогут клиентам в развёртывании агентов на базе передовых ИИ-моделей. В рамках соглашения модели OpenAI, включая GPT-5, будут тесно интегрированы со средой ИИ-разработки Databricks Agent Bricks. Заказчики получат возможность создавать готовые к использованию ИИ-приложения непосредственно на основе управляемых данных на платформе Databricks Data Intelligence. Цель сотрудничества Databricks и OpenAI в том, чтобы предоставить организациям единую инфраструктуру для разработки, оценки и масштабирования ИИ-агентов — систем, способных выполнять задачи автономно, практически без участия человека. Это могут быть агенты рассуждений для поддержки принятия решений в той или иной сфере, анализа финансовых рисков, проверки контрактов и планирования логистики. В качестве других примеров названы агенты повышения производительности для поддержки пользователей, а также агенты-разработчики для отладки систем, модернизации устаревших приложений и создания готового к использованию программного кода. 
Источник изображения: unsplash.com / Rolf van Root Клиенты Databricks смогут запускать большие языковые модели (LLM) на основе собственных корпоративных данных, доступных через SQL-запросы или API, и безопасно развёртывать их в нужном масштабе с помощью встроенных средств управления и мониторинга. Сотрудничество также охватывает каталог Databricks Unity Catalog, который используется для управления данными и моделями ИИ. По заявлениям Databricks, он помогает отслеживать происхождение данных, контролировать доступ и обеспечивать соблюдение нормативных требований. В целом, партнёрство направлено на ускорение внедрения ИИ в корпоративном секторе. Ожидается, что в рамках сотрудничества Databricks и OpenAI получат более $100 млн выручки. В марте нынешнего года Databricks заключила аналогичное соглашение с компанией Anthropic PBC (разработчик LLM семейства Claude), которая была основана в 2021 году выходцами из OpenAI.
24.08.2025 [00:23], Владимир Мироненко
Оценка Databricks выросла до $100 млрд после очередного раунда инвестиций, но на биржу компания не спешитСтартап Databricks, специализирующийся на создании решений в сфере аналитики данных и ИИ, сообщил о выполнении условий привлечения венчурного капитала в рамках раунда серии K, который планирует вскоре завершить. В результате его рыночная стоимость Databricks теперь оценивается более чем в $100 млрд. Компания не назвала участников раунда, лишь указав, что он прошёл при поддержке существующих инвесторов. Напомним, что в предыдущем раунде финансирования серии J на сумму $10 млрд с привлечением долгового финансирования на сумму в $5,25 млрд и оценкой её стоимости в $62 млрд, приняли участие Thrive Capital, Qatar Investment Authority, Temasek, Macquarie Capital и Meta✴ Platforms. Привлечённые в нынешнем раунде средства компания намерена направить на ускорение реализации своей стратегии в области ИИ — дальнейшую разработку Agent Bricks, набора инструментов для автоматизации разработки и развёртывания автономных агентов на основе ИИ, инвестиций в Lakebase, новый тип открытой базы данных для OLTP на базе Postgres, оптимизированной для использования ИИ-агентов, а также на стимулирование глобального роста. 
Источник изображения: Marek Studzinski / Unsplash Джаеш Чаурасия (Jayesh Chaurasia), старший аналитик Forrester Research заявил ресурсу SiliconANGLE, что результаты раунда отражают уверенность инвесторов в конвергенции ИИ и платформы данных, а также их стратегическую ценность для достижения корпоративных результатов. По мнению Скотта Бикли (Scott Bickley), консультанта Info-Tech Research Group, время объявления о раунде, возможно, было обусловлено скорее рекламными целями, чем финансированием. Он считает, что компании также важно, чтобы в центре внимания была оценка в $100 млрд и её планы развития, а не объём инвестиций. Али Годси (Ali Ghodsi), соучредитель и генеральный директор отметил огромный интерес инвесторов, подчеркнув, что «Databricks выигрывает от беспрецедентного мирового спроса на ИИ-приложения и ИИ-агенты, превращая данные компаний в золотую жилу». За последние два квартала компания заключила или расширила партнёрские соглашения с Microsoft, Google, Anthropic, SAP и Palantir. Databricks сообщила, что более 15 тыс. клиентов по всему миру, в том числе более 60 % компаний из списка Fortune 500, используют платформу Databricks Data Intelligence Platform для аналитики, ИИ-приложений и ИИ-агентов. 
Источник изображения: Databricks В отличие от ближайшего конкурента Snowflake, компания не спешит с выходом на биржу. Бикли сообщил, что у Databricks есть веские причины не торопиться с IPO. «Выход на биржу очень затратен и требует целого процесса регулирования, — сказал он. — Сейчас им не нужно беспокоиться обо всём этом. У них есть полная гибкость». Представитель Databricks заявил: «Мы выйдем на биржу, когда это будет уместно. Во многих отношениях мы уже действуем как публичная компания и будем готовы, когда придёт время». Аналитик Gartner Дипак Сет (Deepak Seth) утверждает, что оба конкурента работают над во многом схожими платформами, но «Databricks ориентирована на ИИ, в то время как Snowflake по-прежнему ориентирована на данные, и прямо сейчас рынок поощряет использование ИИ». По мнению Сета, стратегия Databricks нацелена на предприятия, ценящие открытость и гибкость, в то время как «Snowflake по-прежнему обладает непревзойдёнными возможностями в работе со структурированными данными». «Обе компании активно работают над изменением того, как выглядит единая корпоративная платформа обработки данных и ИИ», — говорит он.
23.01.2025 [12:13], Сергей Карасёв
Databricks закрыла раунд финансирования на $10 млрд, получив оценку в $62 млрдКомпания Databricks, основанная в 2013 году, объявила об окончательном закрытии раунда финансирования Series J, в ходе которого на развитие привлечено $10 млрд. Кроме того, Databricks получила дополнительное долговое финансирование на сумму $5,25 млрд. Databricks разработала платформу машинного обучения, анализа и обработки данных. Компания предоставляет функции, которые позволяют предприятиям настраивать или кастомизировать модели ИИ. Databricks также помогает заказчикам в развёртывании собственных приложений на базе генеративного ИИ. 
Источник изображения: Databricks В раунде Series J приняли участие Thrive Capital, Qatar Investment Authority, Temasek, Macquarie Capital и Meta✴ Platforms. Полученные средства будут использованы для разработки новых ИИ-продуктов, приобретения сторонних фирм и расширения международных операций с целью усиления рыночных позиций. Инвестиции со стороны Meta✴ Platforms укрепят сотрудничество двух компаний в области ИИ, которое сфокусировано на больших языковых моделях семейства Llama. После привлечения финансирования Databricks получила рыночную оценку в $62 млрд. Вместе с тем долговое финансирование на $5,25 млрд включает нефинансируемый возобновляемый кредит на $2,5 млрд и срочный кредит на $2,75 млрд. В этой программе участвуют JPMorgan Chase, Barclays, Citi, Goldman Sachs и Morgan Stanley, а также ряд других финансовых учреждений. Отмечается, что на сегодняшний день более 10 тыс. организаций по всему миру, включая Block, Comcast, Condé Nast, Rivian, Shell и свыше 60 % компаний из списка Fortune 500, используют платформу Databricks Data Intelligence. Она помогает в решении комплексных задач, таких как раннее выявление и лечение заболеваний, разработка новых способов борьбы с изменением климата, обнаружения финансового мошенничества, создание фармацевтических препаратов и пр. Штаб-квартира Databricks расположена в Сан-Франциско (Калифорния, США), а представительства действуют по всему миру.
16.12.2024 [19:04], Руслан Авдеев
Databricks завершает раунд мегафинансирования на сумму $10 млрд [Обновлено]Основанная в 2013 году авторами Apache Spark компания Databricks завершает один из рекордных для венчурного капитала раундов финансирования, сообщает Reuters. Сообщается, что компания получит практически вдвое больше, чем рассчитывала — более $9,5 млрд. Но и эта сумма может вырасти, поскольку инвесторы горят желанием приобрести часть перспективной компании. Капитализация Databricks, которая предлагает инструментарий для анализа и обработки больших массивов данных, после завершения раунда, вероятно, превысит $60 млрд. Раунд, вероятно, будет возглавлен новым инвестором Thrive Capital, также участие примут Andreessen Horowitz, Insight Partners и GIC, уже снабжавшие компанию деньгами. Помимо прямых инвестиций обсуждается и долговое финансирование на $4,5 млрд, в том числе кредит на $2,5 млрд. При этом выручка компании в следующем финансовом году, по прогнозам, составит всего $3,8 млрд. 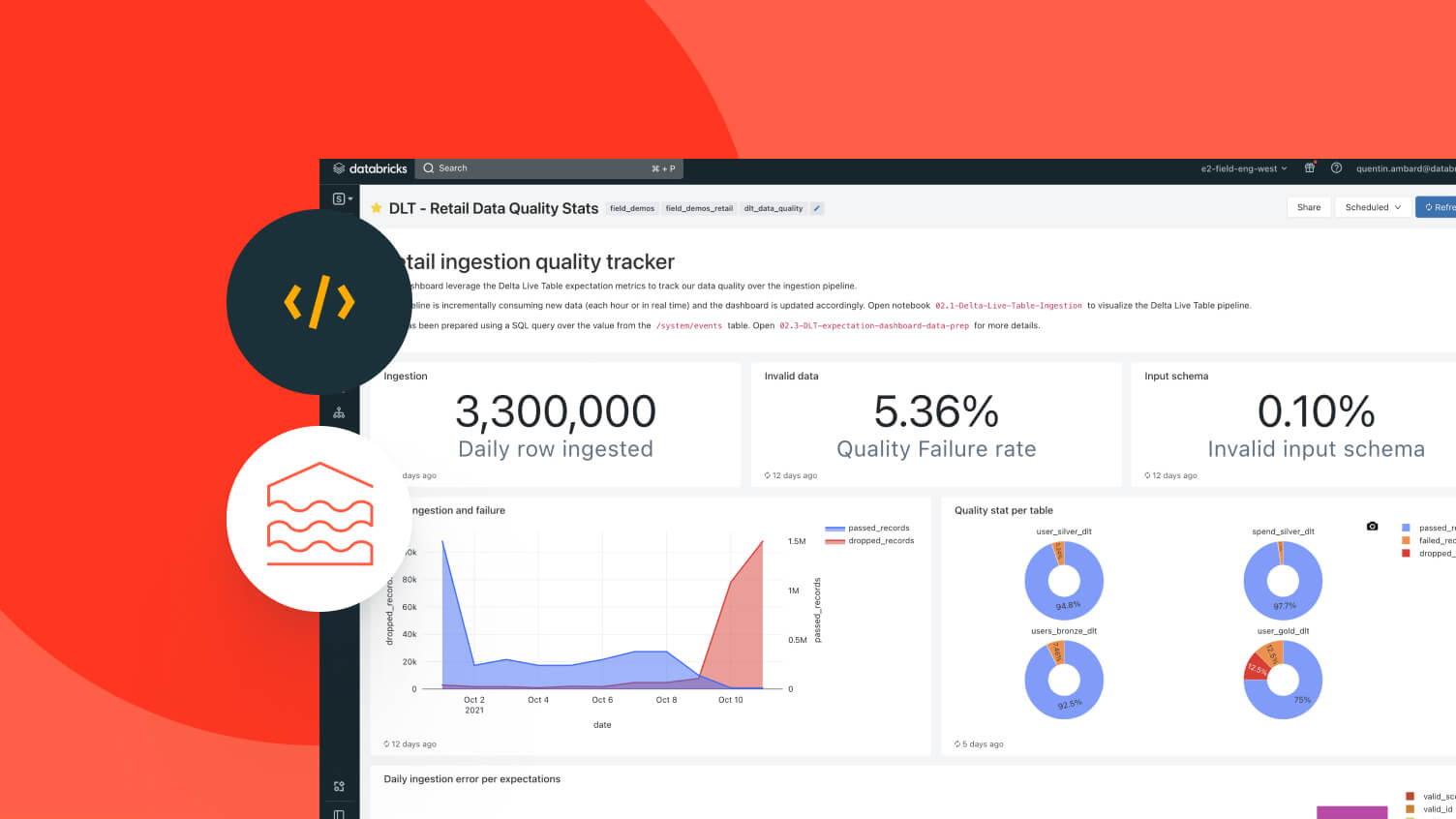
Источник изображения: Databricks Компания начинала деятельность с анализа больших данных, а затем вышла на рынок ИИ, создав облачную платформу для управления информацией, необходимой ИИ-приложениям, и семейство собственных LLM Dolly и DBRX. В сентябре стоимость компании оценивалась в $43 млрд. От бума систем искусственного интеллекта компания только выиграла. Платформа используется клиентами для хранения растущих объёмов данных, предназначенных для обучения ИИ. Если раунд финансирования завершится удачно, немало выиграют её первые сотрудники — полученные средства используют для выкупа акций с ограниченным сроком действия и покрытия налоговых затрат на покупки. Позже компания намерена выпустить для инвесторов привилегированные акции. По имеющимся данным, раунд организовали для решения вопросов с принадлежащими сотрудникам опционами с истекающим сроком действия. Нечто подобное в своё время провела платёжная компания Stripe Inc., в прошлом году получившая таким образом $6,5 млрд для выкупа акций. Databricks является конкурентом Snowflake, рыночная капитализация которой составляет $56 млрд (в пике было $120 млрд). IPO последней в своё время было названо крупнейшим за всю историю софтверной индустрии. Предполагается, что в Databricks пока не очень спешат с выходом на биржу, хотя эксперты прогнозируют серию выходов на IPO в следующем году. UPD 18.12.2024: Databricks объявила, что в ходе раунда J намерена собрать $10 млрд и уже получила $8,6 млрд при оценке капитализации в $62 млрд. В случае успешного завершения раунда общий объём инвестиций с момента основания компании в 2013 году составит $14 млрд. |
|

