Материалы по тегу: h200
|
17.09.2024 [23:07], Игорь Осколков
Швейцария ввела в эксплуатацию гибридный суперкомпьютер Alps: 11 тыс. NVIDIA GH200, 2 тыс. AMD EPYC Rome и щепотка A100, MI250X и MI300AШвейцарская высшая техническая школа Цюриха (ETH Zurich) провела церемонию официального запуска суперкомпьютера Alps в Швейцарском национальном суперкомпьютерном центре (CSCS) в Лугано. Система, построенная HPE, уже заняла шестую строчку в последнем рейтинге TOP500 и имеет устоявшеюся FP64-производительность 270 Пфлопс (теоретический пик — 354 Пфлопс). К ноябрю будут введены в строй остальные модули машины, и её максимальная производительность составит порядка 500 Пфлопс. 
Источник изображений: CSCS В июньском рейтинге TOP500 участвовал раздел из 2688 узлов HPE Cray EX254n с «фантастической четвёркой» NVIDIA Quad GH200. Если точнее, это всё же «старый» вариант ускорителя с H100 (96 Гбайт HBM3), 72-ядерным Arm-процессором Grace и 128 Гбайт LPDDR5x — суммарно 10 752 Grace Hopper. Данный раздел потребляет 5,2 МВт и в Green500 находится на 14 месте. Узлы, конечно же, используют СЖО. Это основной, но не единственный раздел суперкомпьютера. Ещё в 2020 году HPE развернула 1024 двухпроцессорных узла с 64-ядерными AMD EPYC 7742 (Rome) и 256/512 Гбайт RAM. Его производительность составляет 4,7 Пфлопс. Кроме того, в состав Alps входят 144 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя NVIDIA A100 (80 или 96 Гбайт HBM2e).  Наконец, машина получит 24 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя AMD Instinct MI250X (128 Гбайт HBM2e) и 128 узлов с четырьмя гибридными ускорителями AMD Instinct MI300A. Большая часть узлов будет объединена интерконнектом HPE Slingshot-11: 200G-подключение на узел или ускоритель. Более точную конфигурацию системы раскроют в ноябре. Lustre-хранилище для будущей машины обновили ещё в прошлом году. Основной СХД является Cray ClusterStor E1000 с подключением Slingshot-11. Так, было добавлено 100 Пбайт полезной HDD-ёмкости (8480 × 16 Тбайт) с пропускной способностью 1 Тбайт/с (300 тыс. IOPS на запись, 1,5 млн IOPS на чтение) и 5 Пбайт SSD, а также резервные ёмкости. За архивное хранение отвечают две ленточные библиотеки объёмом 130 Пбайт каждая.  Особенностью системы является её геораспределённость (фактически узлы размещены в четырёх местах) и облачная модель использования. Так, метеослужба страны MeteoSwiss получила в своё распоряжение выделенный виртуальный кластер, что уже позволило перейти на использование метеомодели более высокого разрешения, которая лучше отражает сложный рельеф Швейцарии. Кроме того, для подстраховки часть узлов Alps размещена на территории Федеральной политехнической школы Лозанны (EPFL). Alps приходит на смену суперкомпьютеру Piz Daint (Cray XC50/40, 21,2 Пфлопс), о завершении жизненного цикла которого было объявлено в конце июля 2024 года. В CSCS пока останутся машины Arolla + Tsa (для нужд MeteoSwiss) и Blue Brain 5 (решает задачи реконструкции и симуляции мозга). Alps же помимо традиционных HPC-нагрузок, будет использоваться для разработки ИИ-решений.
10.09.2024 [14:55], Сергей Карасёв
TACC ввёл в эксплуатацию Arm-суперкомпьютер Vista на базе NVIDIA GH200 для ИИ-задачТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) объявил о том, что мощности нового НРС-комплекса Vista полностью доступны открытому научному сообществу. Суперкомпьютер предназначен для решения ресурсоёмких задач, связанных с ИИ. Формальный анонс машины Vista состоялся в ноябре 2023 года. Тогда говорилось, что Vista станет связующим звеном между существующим суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Vista состоит из двух ключевых частей. Одна из них — кластер из 600 узлов на гибридных суперчипах NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель H100/H200. Обеспечивается производительность на уровне 20,4 Пфлопс (FP64) и 40,8 Пфлопс на тензорных ядрах. Каждый узел содержит локальный накопитель вместимостью 512 Гбайт, 96 Гбайт памяти HBM3 и 120 Гбайт памяти LPDDR5. Интероконнект — Quantum 2 InfiniBand (400G). Второй раздел суперкомпьютера объединяет 256 узлов с процессорами NVIDIA Grace CPU Superchip, содержащими два кристалла Grace в одном модуле (144 ядра). Узлы укомплектованы 240 Гбайт памяти LPDDR5 и накопителем на 512 Гбайт. Интерконнект — Quantum 2 InfiniBand (200G). Узлы произведены Gigabyte, а за интеграцию всей системы отвечала Dell. 
Источник изображения: TACC Общее CPU-быстродействие Vista находится на отметке 4,1 Пфлопс. В состав комплекса входит NFS-хранилише VAST Data вместимостью 30 Пбайт. Суперкомпьютер будет использоваться для разработки и применения решений на основе генеративного ИИ в различных секторах, включая биологические науки и здравоохранение.
09.09.2024 [11:08], Сергей Карасёв
Gigabyte представила серверы с ускорителями NVIDIA HGX H200 и СЖО
amd
coolit systems
emerald rapids
epyc
genoa
gigabyte
h200
hardware
intel
nvidia
sapphire rapids
xeon
сервер
Компания Giga Computing, подразделение Gigabyte, анонсировала серверы G593-ZD1-LAX3 и G593-SD1-LAX3, предназначенные для ресурсоёмких нагрузок, связанных с ИИ. Устройства, оснащённые системой прямого жидкостного охлаждения (DLC) от CoolIT, могут нести на борту до восьми ускорителей NVIDIA HGX H200. 
Источник изображений: Gigabyte Модель G593-ZD1-LAX3 выполнена в форм-факторе 5U. Допускается установка двух процессоров AMD EPYC 9004 поколения Genoa с показателем TDP до 400 Вт. Предусмотрены 24 слота для модулей оперативной памяти DDR5-4800. Во фронтальной части расположены отсеки для восьми SFF-накопителей (NVMe/SATA/SAS-4). Есть два коннектора М.2 для SSD типоразмера 2280/22110 с интерфейсом PCIe 3.0 x4 и PCIe 3.0 x1.  Доступны восемь слотов PCIe 5.0 x16 для низкопрофильных карт расширения и четыре разъёма PCIe 5.0 x16 для карт FHHL. В оснащение входят два порта 10GbE (Intel X710-AT2), два выделенных сетевых порта управления 1GbE, два разъёма USB 3.2 Gen1. В свою очередь, сервер G593-SD1-LAX3 рассчитан на два процессора Intel Xeon Emerald Rapids или Sapphire Rapids, величина TDP которых может достигать 350 Вт. Для модулей ОЗУ DDR5-4800/5600 предусмотрены 32 слота. Прочие характеристики (за исключением разъёмов М.2) аналогичны модели на платформе AMD.  Новые серверы укомплектованы шестью блоками питания мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Присутствует контроллер Aspeed AST2600. Диапазон рабочих температур — от 10 до +35 °C. Система DLC предназначена для отвода тепла от ускорителей NVIDIA HGX H200. При этом в области материнской платы и слотов PCIe установлены вентиляторы охлаждения.
19.08.2024 [10:10], Сергей Карасёв
Gigabyte представила ИИ-серверы с ускорителями NVIDIA H200 и процессорами AMD и IntelКомпания Gigabyte анонсировала HGX-серверы G593-SD1-AAX3 и G593-ZD1-AAX3, предназначенные для задач ИИ и НРС. Устройства, выполненные в форм-факторе 5U, включают до восьми ускорителей NVIDIA H200. При этом используется воздушное охлаждение. 
Источник изображений: Gigabyte Модель G593-SD1-AAX3 рассчитана на два процессора Intel Xeon Emerald Rapids с показателем TDP до 350 Вт, а версия G593-ZD1-AAX3 располагает двумя сокетами для чипов AMD EPYC Genoa с TDP до 300 Вт. Доступны соответственно 32 и 24 слота для модулей оперативной памяти DDR5.  Серверы наделены восемью фронтальными отсеками для SFF-накопителей NVMe/SATA/SAS-4, двумя сетевыми портами 10GbE на основе разъёмов RJ-45 (выведены на лицевую панель) и выделенным портом управления 1GbE (находится сзади). Есть четыре слота FHHL PCIe 5.0 x16 и восемь разъёмов LP PCIe 5.0 x16. Модель на платформе AMD дополнительно располагает двумя коннекторами М.2 для SSD с интерфейсом PCIe 3.0 x4 и x1.  Питание у обоих серверов обеспечивают шесть блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. Габариты новинок составляют 447 × 219,7 × 945 мм. Диапазон рабочих температур — от +10 до +35 °C. Есть два порта USB 3.2 Gen1 и разъём D-Sub. Массовое производство серверов Gigabyte серии G593 запланировано на II половину 2024 года. Эти системы станут временной заменой (G)B200-серверов, выпуск которых задерживается.
15.07.2024 [09:23], Владимир Мироненко
HPE построит самый мощный в Японии ИИ-суперкомпьютер ABCI 3.0 на базе NVIDIA H200Японский национальный институт передовых промышленных наук и технологий (AIST) объявил о планах по строительству в Касива (Kashiwa, префектура Тиба) нового суперкомпьютера AI Bridging Cloud Infrastructure 3.0 (ABCI 3.0), представляющего собой очередное обновление ИИ-платформы ABCI, запущенной в 2018 году. Новый суперкомпьютер будет предлагаться в качестве облачного сервиса как государственным, так и частным организациям страны, сообщается в блоге NVIDIA. В качестве подрядчика выступает HPE, которая построит систему с использованием платформы Cray XD с ускорителями NVIDIA H200, объединённых 200G-интерконнектом NVIDIA Quantum-2 InfiniBand. HPE не стала раскрывать подробности об общем количестве узлов, стоимости системы и сроках её ввода в эксплуатацию. Как полагает ресурс The Register, речь идёт о системе с 5U-узлами Cray XD670, способными вместить восемь ускорителей NVIDIA H200/H100 и пару Intel Xeon Emerald Rapids. Кроме того, готовится машина ABCI-Q на базе ускорителей NVIDIA H100, ориентированная на исследования в области квантовых и гибридных вычислений. 
Источник изображения: AIST HPE сообщила, что ABCI 3.0, как ожидается, станет самым быстрым ИИ-суперкомпьютером в Японии — примерно 6,2 Эфлопс (FP16?) или 410 Пфлопс (FP64). Проект ABCI 3.0 реализуется при поддержке Министерства экономики, торговли и промышленности Японии (METI) с целью укрепления вычислительных ресурсов страны через Фонд экономической безопасности. Это часть более широкой инициативы METI стоимостью $1 млрд, которая включает в себя как программу ABCI, так и инвестиции в облачные вычисления на базе ИИ.
03.07.2024 [08:32], Владимир Мироненко
Крупный европейский криптомайнер Northern Data обдумывает вывод на биржу подразделений ЦОД и ИИКомпания Northern Data, деятельность которой связана с майнингом криптовалюты, предоставлением услуг высокопроизводительных вычислений (HPC) и ИИ, обдумывает возможность проведения IPO подразделений Taiga и Ardent, предоставляющих услуги облачных вычислений и ЦОД соответственно, пишет Bloomberg. По данным источников Bloomberg, IPO может состояться на площадке Nasdaq. В настоящее время компания ведёт переговоры с банками для проведения публичного размещения акций. По оценкам банков, капитализация этих подразделений может составить $10–$16 млрд. Как и многие компании, занимающиеся майнингом криптовалют, Northern Data рассматривает HPC и ИИ как прибыльное дополнение к своей основной деятельности. В прошлом году Northern Data разделила свой бизнес на три подразделения — Arden, Taiga и Peak Mining, сосредоточив в последнем все операции по майнингу криптовалют. Согласно информации на сайте компании, у неё имеется 11 дата-центров. Peak Mining, американское подразделение компании по майнингу биткоинов, строит и разрабатывает дата-центры суммарной ёмкостью почти 700 МВт, что в случае реализации всех планов сделает его одним из крупнейших майнеров криптовалюты в США. Taiga уже владеет 24,5 тыс. ускорителей NVIDIA, включая H100, A100 и A6000. Они в основном находятся в трёх ЦОД в Швеции и Норвегии и на 100 % запитаны от «зелёных» источников энергии. В понедельник компания объявила, что первой в Европе приобрела 2 тыс. ускорителей NVIDIA H200, дополненных DPU BlueField-3 и ConnectX-7. Они будут размещены в одном из европейских ЦОД с PUE менее 1,2. Запуск первого кластера намечен на IV квартал, а его производительность составит порядка 32 Пфлопс (точность вычислений не указана). Пиковая теоретическая FP64-производительность такого количества ускорителей H200 составляет 68 Пфлопс. 
Источник изображения: Northern Data В свою очередь Ardent занимается дизайном и строительством высокоплотных ЦОД, ориентированных на HPC- и ИИ-нагрузки. Компания использует СЖО, а заявленный уровень PUE не превышает 1,15. При этом Ardent обещает 100 % доступность своих площадок. Как сообщается, Northern Data в ноябре получила кредитное финансирование на сумму €575 млн от компании Tether Group, занимающейся стейблкоинами, а в январе завершила приобретение у Tether компании Damoon за €400 млн, рассчитавшись с помощью облигаций, конвертируемых в акции, выпущенные Northern Data AG. В результате Tether стала основным инвестором Northern Data. Полученные средства Northern Data использует для закупок самых востребованных чипов NVIDIA. Благодаря этому к концу лета компанией будет развёрнуто около 20 тыс. NVIDIA H100.
20.06.2024 [14:54], Владимир Мироненко
HPE и NVIDIA представили совместные решения для ускорения внедрения ИИHewlett Packard Enterprise (HPE) и NVIDIA представили платформу NVIDIA AI Computing by HPE — портфель совместно разработанных решений для ускорения внедрения генеративного ИИ. Ключевым в портфеле является предложение HPE Private Cloud AI. Как указано в пресс-релизе, это первое в своём роде комплексное решение, которое обеспечивает самую глубокую на сегодняшний день интеграцию вычислительных технологий, сетей и ПО NVIDIA с хранилищем, вычислительными ресурсами и облачной платформой HPE GreenLake. Решение предоставляет предприятиям любого размера возможность быстрой и эффективной разработки и развёртывания приложений генеративного ИИ. Решение HPE Private Cloud AI с новой функцией OpsRamp AI Copilot, которая позволяет повысить эффективность ИТ-операций и обработки рабочих нагрузок, включает в себя облачную среду самообслуживания с полным управлением жизненным циклом. Оно доступно в четырёх конфигурациях (Small, Medium, Large и Extra Large) для поддержки рабочих нагрузок ИИ различной сложности. 
Источник изображения: SiliconANGLE HPE Private Cloud AI также поддерживает инференс, точную настройку моделей и их дообучение посредством RAG с использованием собственных данных. Решение сочетает в себе средства контроля конфиденциальности, безопасности, прозрачности и управления данными, в том числе средства ITOps и AIOps. AIOps использует машинное обучение и анализ данных для автоматизации и улучшения ИТ-операций. ITOps включает в себя ряд инструментов, обеспечивающих бесперебойное функционирование ИТ-инфраструктуры организации. 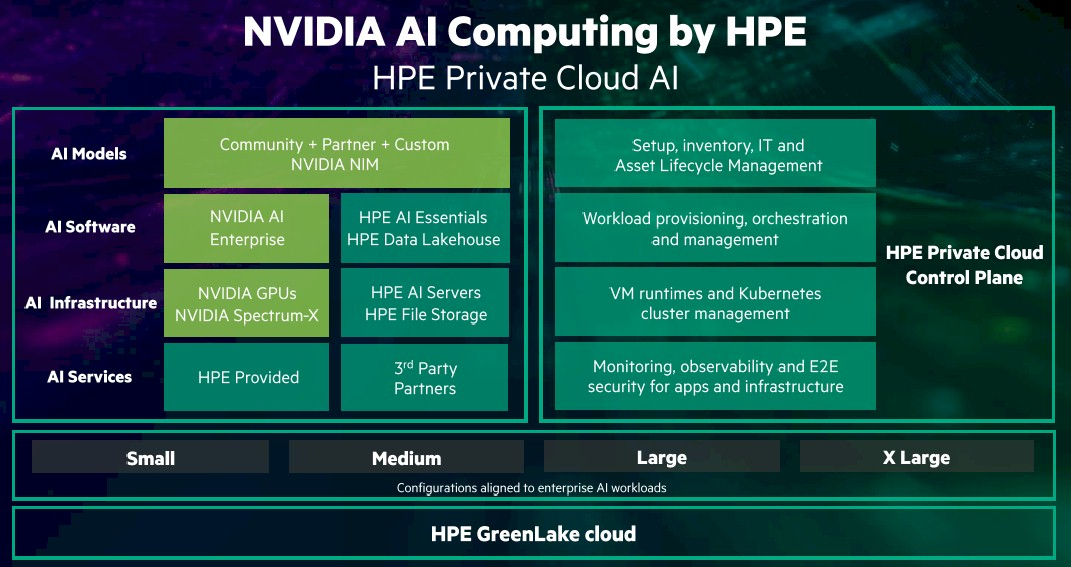
Источник изображения: The Next Platform Конфигурация HPE Private Cloud AI Small, предназначенная для инференса, включает от четырёх до восьми ускорителей NVIDIA L40S, до 248 Тбайт дискового пространства и 100GbE-подключение в стойке мощностью 8 кВт. Конфигурация Medium, предназначенная для инференса и RAG, включает до 16 ускорителей NVIDIA L40S, до 390 Тбайт дискового пространства и 200GbE-подключение в стойке мощностью 17,7 кВт. 
Источник изображения: The Next Platform Конфигурации Large и Extra Large предлагают дополнительные возможности по обработке нагрузок ИИ и ML, а также тонкой настройке ИИ-модели. Конфигурация Large включает до 32 ускорителей NVIDIA H100 NVL, до 1,1 Пбайта дискового пространства и 400GbE-интерконнект в двух стойках мощностью 25 кВт каждая. В свою очередь, конфигурация Extra Large включает до 24 ускорителей NVIDIA GH200 NVL2, до 1,1 Пбайта дискового пространства и 800GbE-интeрконнект в двух стойках мощностью 25 кВт каждая. Стойки могут управляться клиентом самостоятельно или обслуживаться HPE. Каждая конфигурация может работать как автономное локальное решение ИИ или в составе гибридного облака. Используется программная платформа NVIDIA AI Enterprise, включающая микросервисы инференса NIM. Её дополняет ПО HPE AI Essentials. Кроме того, поддержку новых ускорителей NVIDIA получили три аппаратные платформы:
HPE также объявила, что её облачная платформа HPE GreenLake for File Storage прошла сертификацию Nvidia DGX BasePOD и валидацию хранилища NVIDIA OVX, HPE Private Cloud AI, а также анонсированное оборудование будут доступны этой осенью за исключением платформы Cray XD670 на базе NVIDIA H200 NVL, который поступит в продажу этим летом. А после станут доступны и решения на базе Blackwell.
17.06.2024 [22:49], Илья Коваль
Три квантовых компьютера, NVIDIA DGX Quantum, немножко HPC и облако: в Израиле открыт уникальный центр квантовых вычислений IQCC
aws
gh200
grace
hardware
hpc
nvidia
quantum machines
израиль
квантовые вычисления
квантовый компьютер
облако
разработка
Стартап Quantum Machines, разработчик систем управления квантовыми компьютерами, открыл Израильский центр квантовых вычислений (Israeli Quantum Computing Center, IQCC). Площадка, создание которой было частично профинансировано правительством страны, располагается в Тель-Авивском университете. По словам основателей, это первый в мире центр, располагающий квантовыми компьютерами разных типов, которые интегрированы с системой NVIDIA DGX Quantum, HPC-инфраструктурой и облаком. 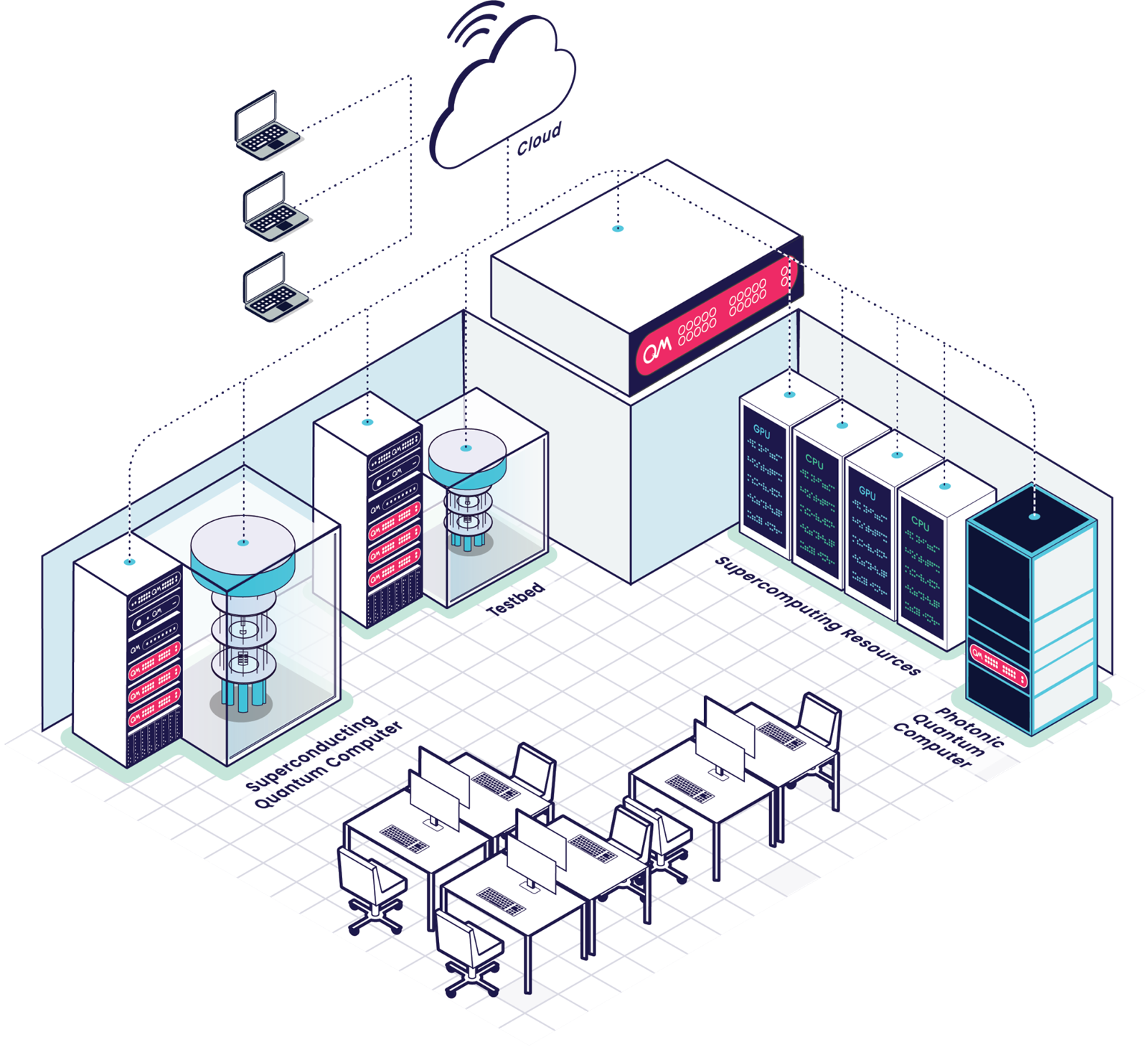
Источник изображений: Quantum Machines Приоритетный доступ со скидкой получат исследовательские организации Израиля, но в целом центр будет открыт для компаний со всего света. Как говорят создатели, IQCC — это лучший в мире полигон для создания новых технологий в области квантовых вычислений, а открытая архитектура площадки позволяет регулярно проводить обновления и упрощает дальнейшее масштабирование возможностей и вычислительных мощностей. Сейчас в IQCC установлены 21-кубитный компьютер Galilee от Quantware на сверхпроводящих кубитах (ещё один такой же используется в качестве тестовой платформы) и фотонный компьютер Negev от ORCA (8 кумод). Системы управляются контроллерами OPX1000 от самой Quantum Machines. HPC-инфраструктура представлена DGX A100, четырьмя GH200 и 128 vCPU на базе AMD EPYC 9334 (Genoa). Дополнительные ресурсы можно арендовать в облаке AWS.  Для Galilee и Negev доступна интеграция с DGX Quantum, платформой для гибридных квантово-классических вычислений, которая была создана NVIDIA и Quantum Machines и впервые в мире развёрнута именно в IQCC. Управлять компьютерами и разрабатывать ПО можно с использованием Qiskit, QUA, OpenQASM3, QBridge, а также Classiq. К системе организован облачный доступ. В ближайшие месяцы в IQCC будут развёрнуты ещё несколько квантовых компьютеров и QPU.
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс. |
|

