Материалы по тегу: dpu
|
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
21.07.2023 [23:10], Алексей Степин
Microsoft предлагает протестировать DPU MANA с Azure BoostКрупные облачные провайдеры давно осознали пользу, которую могут принести DPU и активно применяют подобного рода решения. В частности, AWS давно использует платформу Nitro, Google разработала DPU при поддержке Intel, а Microsoft активно готовит к запуску собственную платформу под названием MANA. Основой MANA является кастомный чип SoC, разработанный специально с учётом обеспечения высокой пропускной способности, стабильности подключения и низкой латентности. DPU на его основе обеспечивает пропускную способность до 200 Гбит/с, а также поддерживает подключение удалённого хранилища данных на скоростях до 10 Гбайт/с при производительности до 400 тыс. IOPS. Отметим, что ранее AMD заявила о появлении DPU Pensando в облаке Azure, а сама Microsoft в прошлом году поглотила разработчика DPU Fungible. 
Изображение: Microsoft MANA является частью услуги Azure Boost и берёт на себя управление всеми аспектами виртуализации, включая работу с сетью и данными, а также функции управления хост-системой. Перенос этих функций на отдельную платформу не просто улучшает производительность и масштабируемость, но и обеспечивает дополнительный слой безопасности. MANA уже задействованы в инфраструктуре Azure и подтвердили высочайшую скорость при работе с внешними хранилищами данных для инстансов Ebsv5, а также отличную пропускную способность и низкую латентность сетевого канала для всех инстансов семейств Ev5 и Dv5. MANA поддерживает Windows и Linux, а для более тонкой работы с аппаратной частью ускорителя можно задействовать DPDK. В части информационной безопасности следует отметить наличие криптоядра, соответствующего стандартам FIPS 140. В настоящее время сервис Azure Boost доступен в качестве превью. Компания приглашает к сотрудничеству партнёров и клиентов с высокими запросами к характеристикам сетевого канала и хранилищ.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения.
28.01.2023 [21:20], Алексей Степин
Ускоритель Pliops XDP получил новые возможности: XDP-RAIDplus, XDP-AccelDB и XDP-AccelKVКомпания Pliops, разработавшая собственный вариант DPU-ускорителя XDP, объявила о расширении его функциональности. Нововведения должны повысить производительность NVMe SSD, продлить им жизнь и ускорить процесс восстановления в случае сбоя. Анонс Pliops говорит о новых службах XDP-RAIDplus, XDP-AccelDB и XDP-AccelKV, назначение которых понятно из названия. XDP-RAIDplus предназначена для максимизации скорости ввода-вывода накопителей с интерфейсом NVMe, а также позволяет создавать защищённые массивы без потери эффективной ёмкости. Заявляется о 26,6 % прироста по объёму при использовании 6 дисков ёмкостью 15 Тбайт в сравнении с обычным RAID5. При этом в случае сбоя ускоритель перестраивает массив только в части, затронутой отказавшим и заменённым накопителем, а не целиком, что ускоряет процесс перестройки на 65 %, при этом меньше страдает производительность и минимизируется время простоя. Благодаря сочетанию этих функций стоимость владения флеш-массивом может снижаться на величину до 50 %. 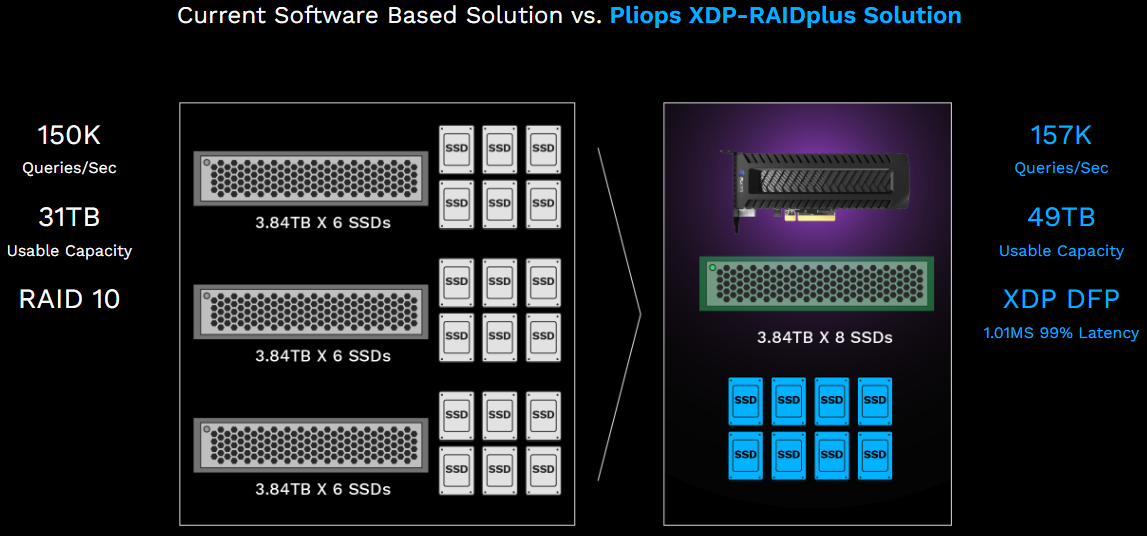
Преимущества XDP-RAIDplus в сравнении с классическими решениями. Источник: Pliops Функция XDP-AccelDB представляет собой движок-ускоритель для СУБД (MySQL/MariaDB, MongoDB) и программно определяемых хранилищ. Движок поддерживает атомарную запись, умную буферизацию и выравнивание данных, что позволяет говорить о 3,2-кратном увеличении количества транзакций за единицу времени, а также о трёхкратном снижении латентности. Наконец, XDP-AccelKV — ускоритель Key-Value хранилищ, предназначенный для решений типа RocksDB или WiredTiger. В сравнении с полностью программными решениями он, как утверждается, способен повысить производительность на порядок.
10.01.2023 [17:11], Сергей Карасёв
Microsoft подтвердила поглощение DPU-разработчика Fungible, но сумму сделки так и не назвалаКорпорация Microsoft официально объявила о заключении соглашения по покупке компании Fungible — молодого разработчика DPU (Data Processing Unit). О сумме сделки ничего не сообщается. Слухи о том, что редмондский гигант проявляет интерес к Fungible, появились в середине декабря 2022 года. Тогда говорилось, что приобретение стартапа обойдётся Microsoft приблизительно в $190 млн. Решения Fungible помогут Microsoft поднять производительность её дата-центров. По условиям соглашения, команда Fungible присоединится к подразделению разработки ЦОД-инфраструктур Microsoft. Специалисты компании сосредоточатся на создании нескольких специализированных DPU, а также на сетевых инновациях и улучшении аппаратных систем. «Технологии Fungible помогают создать высокопроизводительную, масштабируемую, дезагрегированную, горизонтально масштабируемую инфраструктуру ЦОД с высокими показателями надёжности и безопасности», — говорится в заявлении Microsoft. 
Источник изображения: Fungible Добавим, что Fungible была основана в 2015 году выходцами из Xerox PARC Прадипом Синдху (Pradeep Sindhu, сооснователь и бывший глава Juniper Networks) и Бертраном Серле (Bertrand Serlet, работал в Apple и Parallels, основал Upthere). Стартап привлёк более $300 млн инвестиций, но в последнее время дела у него шли не слишком хорошо. По слухам, после неудачной попытки продать компанию Meta✴ стартап был вынужден уволить часть сотрудников и сократить портфолио решений. Fungible, как и ряд аналогичных проектов, по мере развития перешёл от создания сверхбыстрых хранилищ к идее переноса на DPU иных инфраструктурных задач по примеру AWS Nitro (собственная разработка Amazon). Однако, как утверждают некоторые источники, сложность разработки ПО негативно сказалась на популярности решений Fungible. Например, Google пошла по другому пути и заручилась поддержкой Intel.
30.11.2022 [16:55], Алексей Степин
AWS представила пятое поколение аппаратных гипервизоров NitroНа днях крупный провайдер облачных услуг, компания Amazon Web Services представила новые варианты инстансов на базе новейших процессоров Graviton3E, но данный чип — не единственная новинка AWS. Одновременно с Graviton3E было представлено и пятое поколение аппаратных гипервизоров Nitro, существенно выигрывающих по ключевым показателям у решений предыдущего, четвёртого поколения. 
Здесь и далее источник изображений: ServeTheHome Главная идея Nitro — сочетание «кремния» гипервизора, DPU и сопроцессора безопасности с поддержкой Root of Trust в едином чипе. В системах AWS плата с чипом Nitro полностью управляет распределением вычислительных ресурсов и памяти, избавляя от этой нагрузки хост-процессоры. По результатам тестов, проведённых AWS, производительность облачных инстансов с использованием ускорителей Nitro практически не отличается от производительности классической bare metal-системы.  AWS Nitro v5 использует кастомный кристалл, разработанный Annapurna Labs. По сравнению с Nitro v4, количество транзисторов было удвоено, но за счёт этого удалось на 60 % поднять скорость обработки сетевых пакетов, на 30 % снизить латентность, а также, благодаря продвинутому техпроцессу, обеспечить лучшую удельную производительность. 
Платы AWS Nitro v5 используют проприетарные разъёмы Улучшились и другие характеристики: на 50 % выросла пропускная способность памяти и вдвое возросла производительность подсистемы PCI Express. Платы Nitro v5 станут сердцем новых инстансов C7gn, где обеспечат полную изоляцию критически важных подсистем, таких, как прошивки BIOS, BMC и накопителей от гостевого доступа извне и позволят обновлять эти прошивки без влияния на клиентские нагрузки.  Также они возьмут на себя обслуживание сетей VPC/EBS, включая переход на использование SRD вместо TCP, и накопителей Nitro SSD. AWS уже объявила о возможности предварительного тестирования систем C7gn на базе Nitro v5 и новейших процессоров Graviton3/3E.
19.06.2022 [13:32], Алексей Степин
Alibaba Cloud представила свой вариант DPU — Cloud Infrastructure Processing Unit (CIPU)С учётом стремительно наступающей эры DPU/IPU не вызывает удивления, что такой китайский гигант, как Alibaba Cloud, представил своё видение «универсального сетевого сопроцессора», использовав схожий термин Cloud Infrastructure Processing Unit (CIPU). На ежегодном саммите компании Alibaba Cloud анонсировала новый чип, являющийся дальнейшим развитием идей, ранее воплощённых в умном сетевом адаптере X-Dragon, разрабатывавшемся как аналог AWS Nitro. Пока об архитектуре Alibaba CIPU известно не так много, но физически это обычная двухслотовая плата расширения с интерфейсом PCI Express. 
Источник: @ogawa_tter Судя по имеющимся данным, в основе лежит четвёртое поколение архитектуры X-Dragon, обеспечившее 20% прирост производительности в сравнении с предыдущим поколением этих процессоров. Что более интересно, в основе новой итерации X-Dragon лежит дуэт технологий Elastic RDMA (eRDMA) и Shared Memory Communications over RDMA (SMC-R). Он позволяет новому ускорителю обращаться к памяти хост-системы напрямую на уровне ядра фирменных ОС Alibaba Cloud Linux 3 и Anolis OS. Для приложений, использующих TCP, всё выглядит прозрачно, но латентность при этом удалось понизить до 5 мкс. 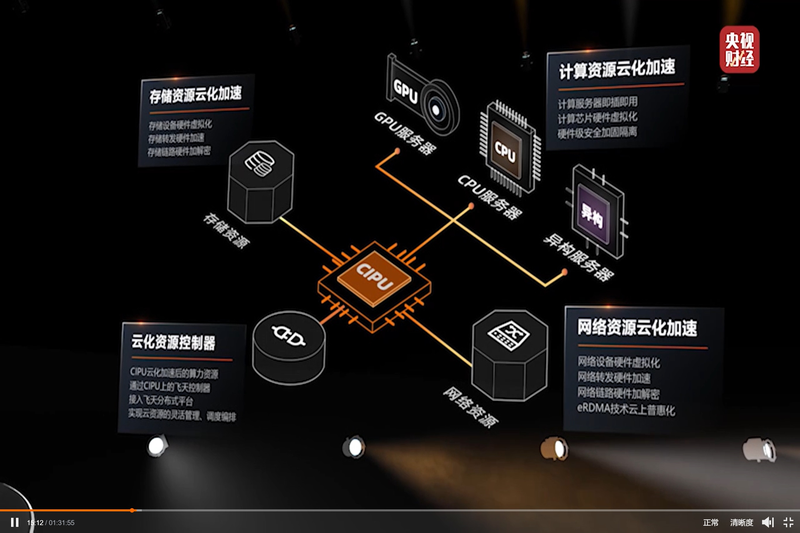
Источник: @ogawa_tter Новые сопроцессоры полностью совместимы со стеком технологий RDMA over Converged Ethernet (RoCE), причём поддерживается даже iWARP, довольно редкий вариант, встречавшийся ранее в адаптерах Intel и Chelsio. Реализации iWARP могут быть сложнее RoCE, т.к. используют многослойную архитектуру и ряд твиков, а в итоге нередко показывают менее высокую производительность. Но благодаря поддержке обеих технологий новое решение Alibaba получилось поистине универсальным. 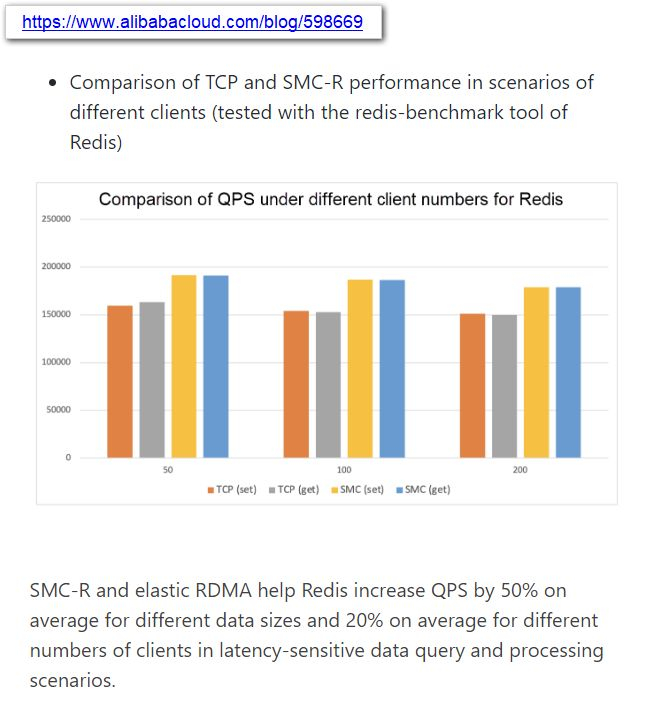
Источник: @ogawa_tter Результаты тестов весьма обнадёживают: в частности, для Redis ускорители CIPU за счёт SMC-R позволили поднять количество обрабатываемых запросов на 50%, а в сценариях с данными, чувствительными к латентности, прирост составил 20%. Исходя из опубликованных в японском блоге Tadashi Ogawa, это действительно полноценный IPU, могущий стать мостом между сетью, подсистемами хранения данных, CPU, GPU и прочими ускорителями. Компания активно развивает собственную аппаратную инфраструктуру и в прошлом году уже представила 128-ядерный 5-нм процессор Yitian 710 на базе набора инструкций Armv9 c 8 каналами DDR5, поддержкой PCIe 5.0 (96 линий) и при этом способный работать на частотах до 3,2 ГГц.
28.04.2022 [22:54], Алексей Степин
Chelsio представила седьмое поколение сетевых чипов Terminator: 400GbE и PCIe 5.0 x16Компания Chelsio Communications анонсировала седьмое поколение своих сетевых процессоров Terminator с поддержкой 400GbE. От предшественников T7 отличает более развитая вычислительная часть общего назначения, включающая в себя до 8 ядер Arm Cortex-A72, так что их уже можно назвать DPU. Всего представлено пять вариантов 5 чипов (T7, N7, D7, S74 и S72), которые различаются между собой набором движков и ускорителей. Референсная платформа T7 будет доступна в мае, первых же адаптеров на базе новых DPU следует ожидать в III квартале 2022 года. Для задач сжатия, дедупликации или криптографии есть отдельные сопроцессоры. Никуда не делся и привычный для серии Unified Wire встроенный L2-коммутатор. Для подключения к хосту T7 теперь использует шину PCIe 5.0 x16, причём он же содержит и root-комплекс. Более того, имеется и набортный коммутатор+мост PCIe 4.0, и NVMe-интерфейс, и даже поддержка эмуляции NVMe. Всё это, к примеру, позволяет легко и быстро создать NVMe-oF хранилище или мост NVMe-NVMe для компрессии и шифрования данных на лету. Новинка предлагает ускорение работы RoCEv2 и iWARP, FCoE и NVMe/TCP, iSCSI и iSER, а также RAID5/6. Сетевая часть поддерживает разгрузку Open vSwitch и Virt-IO. 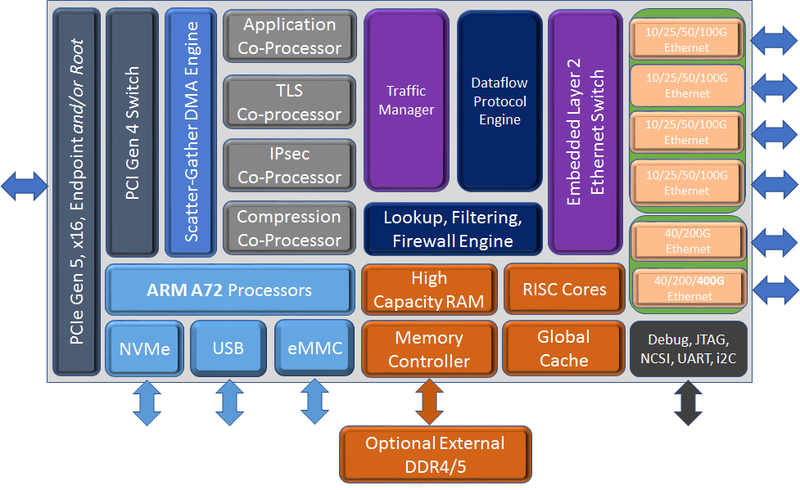
Блок-схема старшего варианта T7 (Изображения: Chelsio Communcations) Впрочем, поддержки P4 тут нет — Chelsio продолжает использовать собственные движки для обработки трафика. Но наработки, сделанные для серий T5 и T6, будет проще перенести на новое поколение чипов. Кроме того, появилась и практически обязательная нынче «глубокая» телеметрия всего проходящего через DPU трафика для повышения управляемости и его защиты. Если и этого окажется мало, то к T7 (и D7) можно напрямую подключить FPGA, а набортную память расширить банками DDR4/5. В пресс-релизе также отмечается, что T7 сможет стать достойной заменой InfiniBand в HРC-системах. 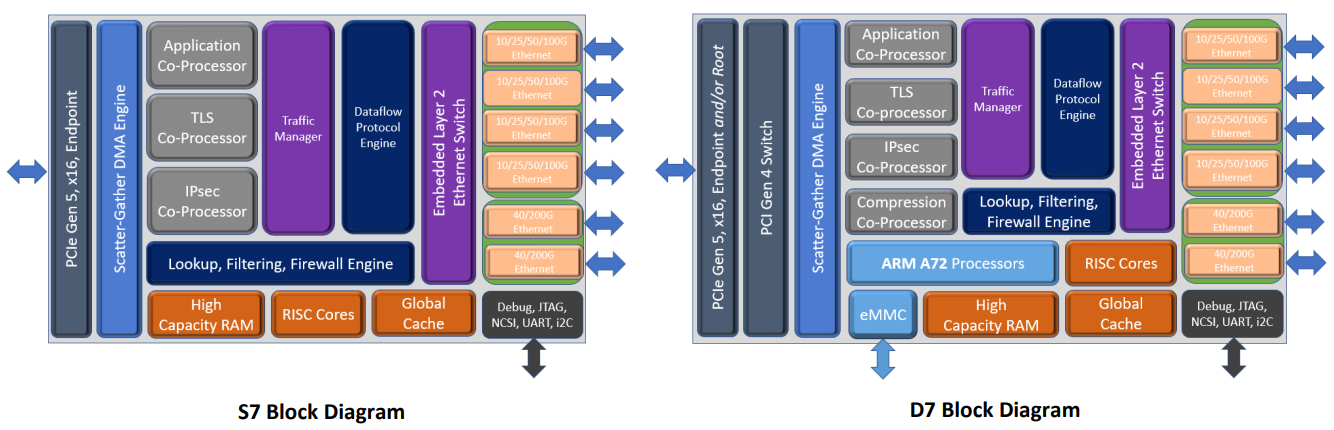 Вариант D7 наиболее близок к T7, но предлагает только 200GbE-подключение, лишён некоторых функций и второстепенных интерфейсов, да и в целом рассчитан на создание СХД. N7, напротив, лишён Arm-ядер и всех функций для работы с хранилищами, нет у него и PCIe-коммутатора и моста. Предлагает он только 200GbE-интерфейсы. Наконец, чипы серии S7 лишены целого ряда второстепенных функций и предоставляют только 100/200GbE-подключение. Они относятся скорее к SmartNIC, поскольку начисто лишены Arm-ядер и некоторых функций. Но зато они и недороги. Кроме того, в седьмом поколении Termintator появилась возможность обойтись без набортной DRAM с сохранением всей функциональности. Так что использование памяти хоста позволит дополнительно снизить стоимость конечных решений, которые будут создавать OEM-производители. Сами чипы производятся с использованием техпроцесса TSMC 12-нм FFC, так что даже у старшей версии чипов типовое энергопотребление не превышает 22 Вт.
19.12.2021 [18:06], Алексей Степин
Nebulon поможет HCI-решениям освоить рынок периферийных вычисленийПо мере внедрения 5G-сетей объёмы данных, добываемых и обрабатываемых на периферии, будут только расти, и здесь новое решение Nebulon для микро-ЦОД окажется весьма к месту. Компания Nebulon была основана лишь 2018 году, а в 2020 году она представила свои первые решения, концептуально очень схожие с тем, что сейчас принято называть DPU. Изначально это были ускорители под названием SPU (Storage Processing Unit), однако впоследствии первое слово заменили на Service, поскольку речь шла уже об облачных системах, и данные платы стали частью того, что сама Nebulon называет «умной инфраструктурой» (Smart Infrastructure). 
Nebulon SPU. Изображения: Nebulon Но у SPU нашлось и ещё одно применение, связанное с периферийной серверной инфраструктурой. Её особенности таковы, что требуют максимальной компактности оборудования, и это, по мнению Nebulon, затрудняет использование классических решений для гиперконвергентной инфраструктуры (HCI), поскольку, по словам Nebulon, она обычно для арбитража, который необходим для стабильности работы, требует наличия в системе минимум трёх узлов. 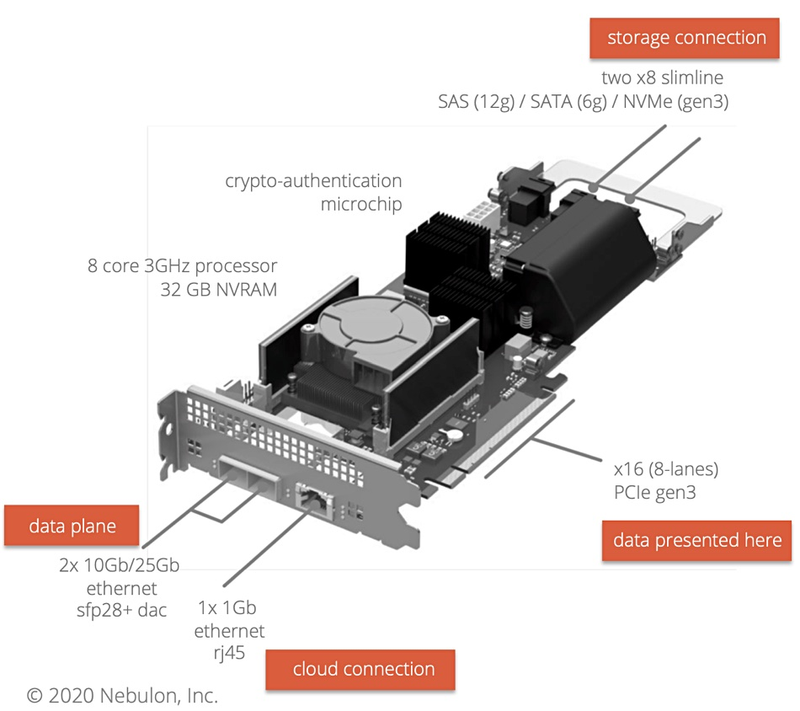 Такой «узел-арбитр» (quorum witness, QW) гарантирует бесперебойную работу системы в том случае, если какой-либо из её основных узлов испытывает проблемы с сетевым подключением. Но в условиях периферии третьему узлу бывает просто негде разместиться, а ведь нужен ещё и сетевой коммутатор. Тут-то на помощь и может прийти ускоритель Nebulon SPU, который можно назвать полноценным «сервером на плате»: он несёт на борту восьмиядерный CPU и 32 Гбайт DRAM. Основным интерфейсом SPU является PCIe 3.0 x16 (8 линий) + ещё два набора по 8 линий могут обслуживать NVMe SSD (но есть и поддержка SAS/SATA). С такой платой HCI-кластер может иметь в составе всего два узла. Коммутатор не требуется, поскольку плата располагает двумя портами 10/25GbE. Интеграцию такого HCI-кластера с облаком, автоматизацию и арбитраж посредством Nebulon ON также берёт на себя SPU. Компания-разработчик назвала данную технологию smartEdge.
29.10.2021 [02:28], Игорь Осколков
Intel объявила о совместной работе с Google над IPU Mount Evans и анонсировала IPDKIntel в рамках мероприятия Innovation раскрыла имя партнёра по разработке IPU Mount Evans — им оказалась компания Google. Впрочем, это не означает, что новинки будут доступны только ей и окажутся оптимизированы только под её задачи. IPU хоть и ориентированы в первую очередь на гиперскейлеров (среди возможных заказчиков называют и Facebook✴), но, по мнению Intel, будут интересны и менее крупным игрокам. Более того, было, наконец, прямо сказано, что ведётся работа и над Project Monterey от VMware. 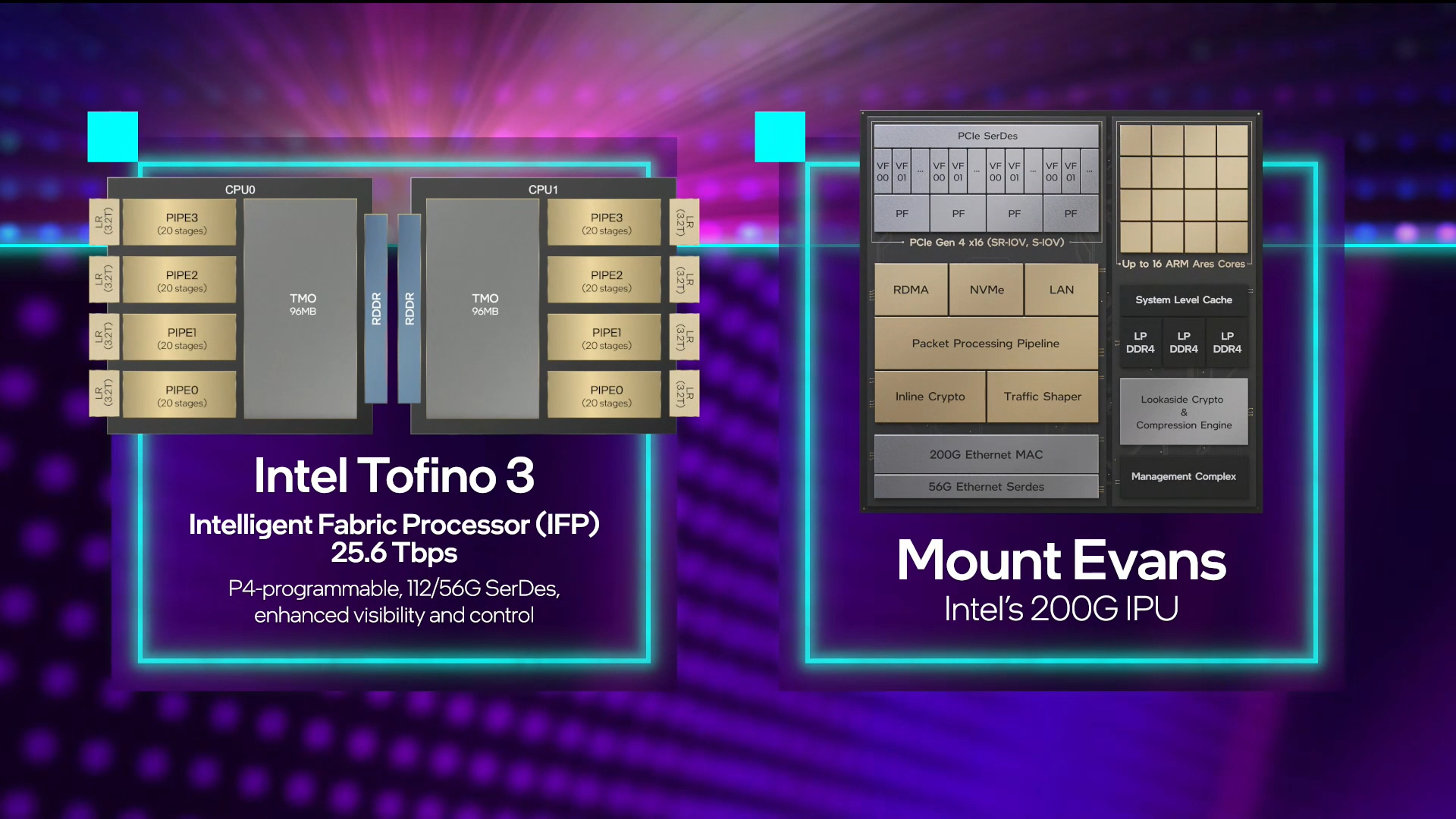 Как пояснил Гвидо Аппенцеллер (Guido Appenzeller), технический директор подразделения Data Platforms Group Intel, название IPU (Infrastructure Processing Unit) было выбрано в противовес всё ещё относительно новому, но более привычному термину DPU (Data Processing Unit) именно потому, что IPU охватывает более широкий спектр задач по работе именно с инфраструктурой, а не только c данными. 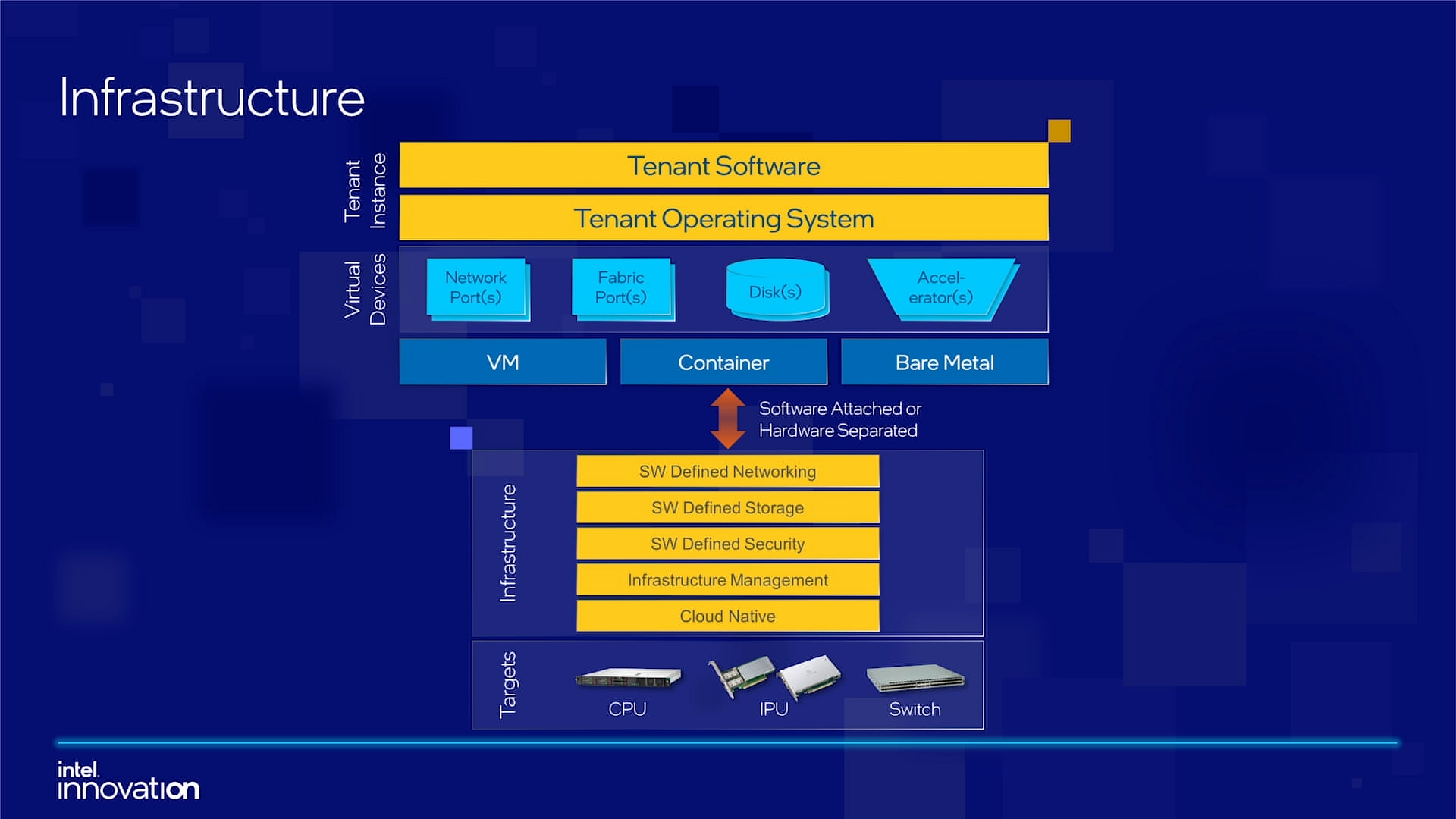 Справедливости ради отметим, что и сами DPU, поначалу чаще ориентированные именно на ускорение работы с СХД и устранению узких мест в передаче данных, уже расширили свою функциональность и практически являются IPU именно в терминологии Intel — этот класс сопроцессоров независим от хост-системы и занимается обслуживанием инфраструктуры, включая работу с сетью и хранилищем, изоляцию и телеметрию, управление нагрузками и т.д. 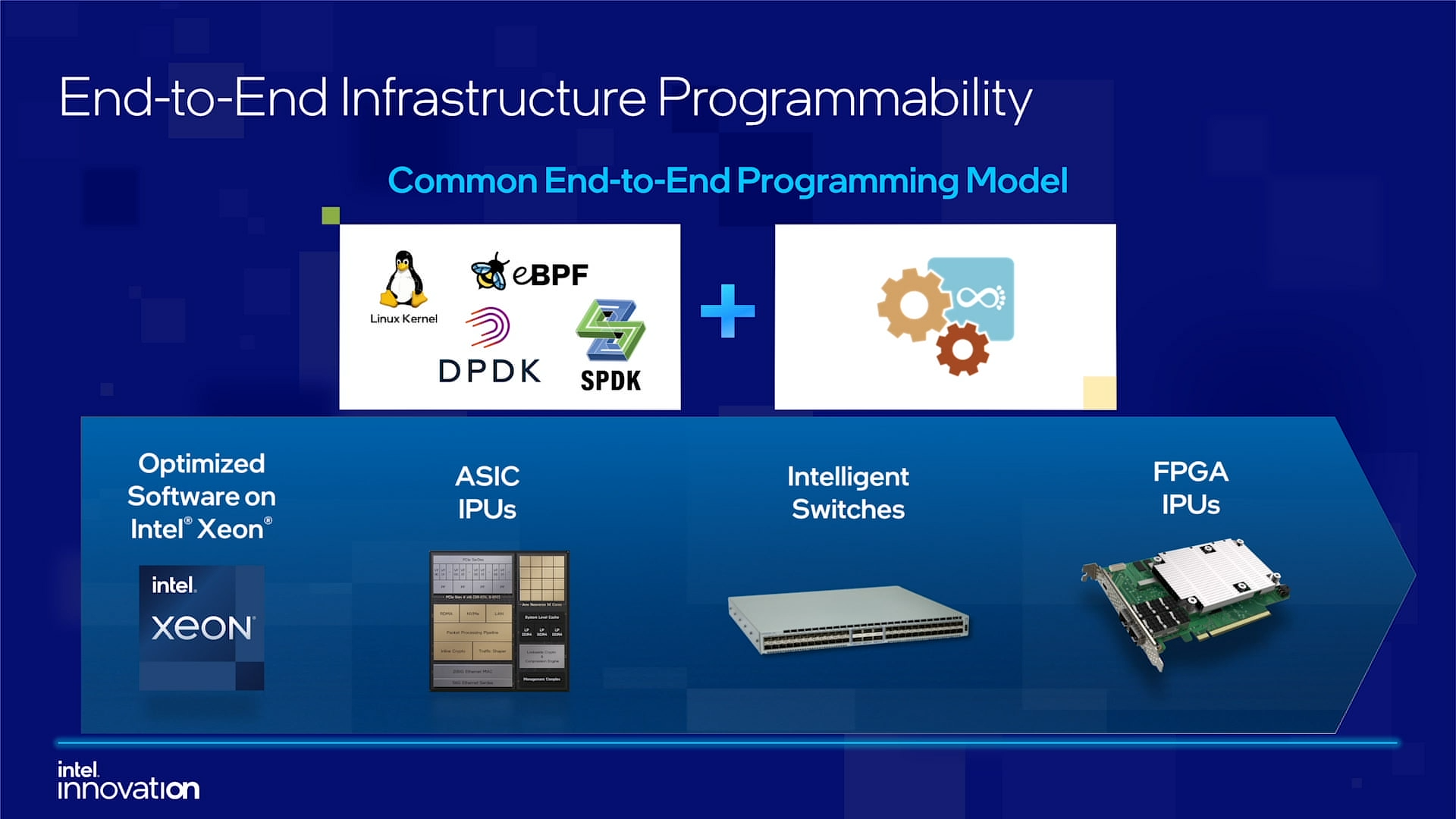 У Intel достаточно богатый опыт работы по сетевому направлению с гиперскейлерами. По словам Аппенцеллера, семь из восьми крупнейших компаний этого класса используют решения Intel во всей или хотя бы в некоторых частях своей инфраструктуры. Так, Microsoft, Baidu и JD полагаются на SmartNIC на базе FPGA. Партнёрство же с Google будет выгодно для обеих компаний. Intel получит заказы, а Google, наконец, обретёт то, что давно есть у Amazon — аналог Nitro. На масштабе в миллионы серверов это очень важно. 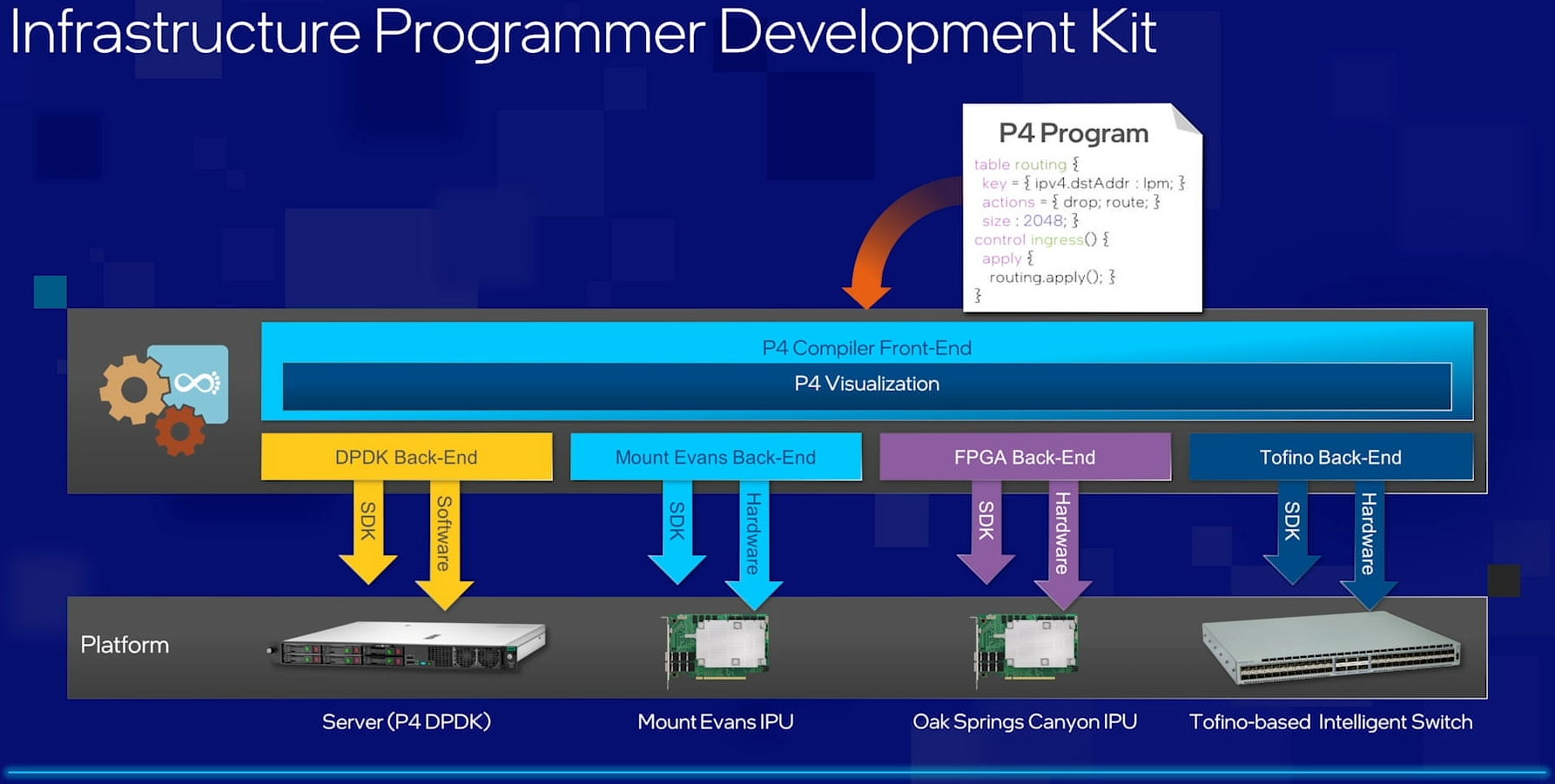 Однако IPU (как аппаратные устройства) — только часть общей картины. Для полноты не хватает как минимум ещё двух компонентов: программного стека и сопутствующей инфраструктуру. Tofino-3 — анонсированный ранее чип или, как его называет сама Intel, Intelligent Fabric Processor — не только поддерживает коммутацию на скорости 25,6 Тбит/с с параллельным сбором телеметрии, но и является полностью P4-программируемым. А это позволяет организовать сквозные мониторинг, управление и оптимизацию трафика для конкретных задач. 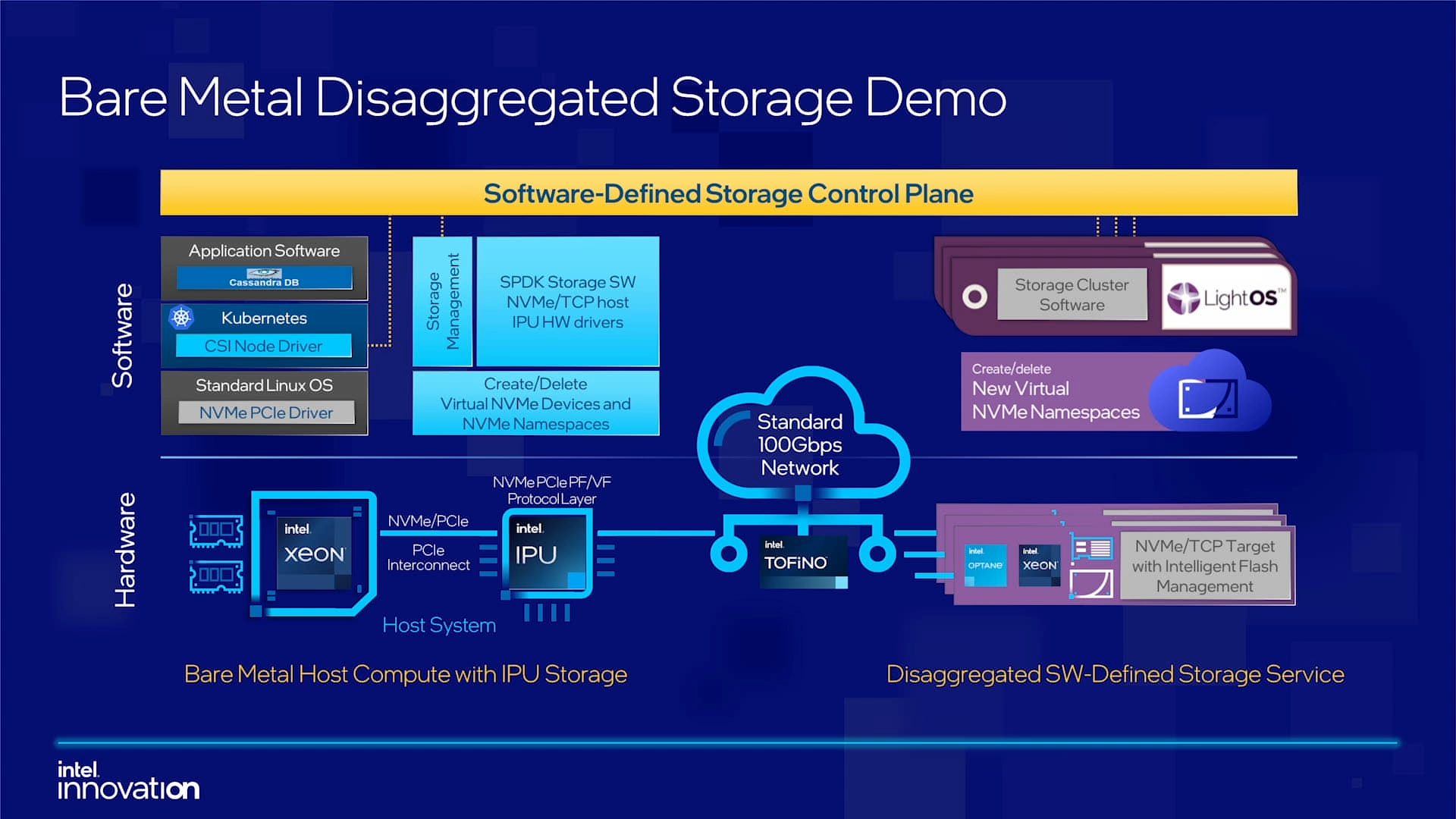 Или, иными словам, IPU и подходящие коммутаторы позволяют сделать всю инфраструктуру практически полностью программно определяемой, но с аппаратной разгрузкой части функций и близкой к bare metal итоговой производительностью. Правда, в качестве демо Intel опять же приводит «классические» примеры с СХД и Open vSwitch, а также сценарии глубокого мониторинга производительности и быстрого поиска проблемных мест в сети. Но этим потенциальные возможности не ограничиваются. 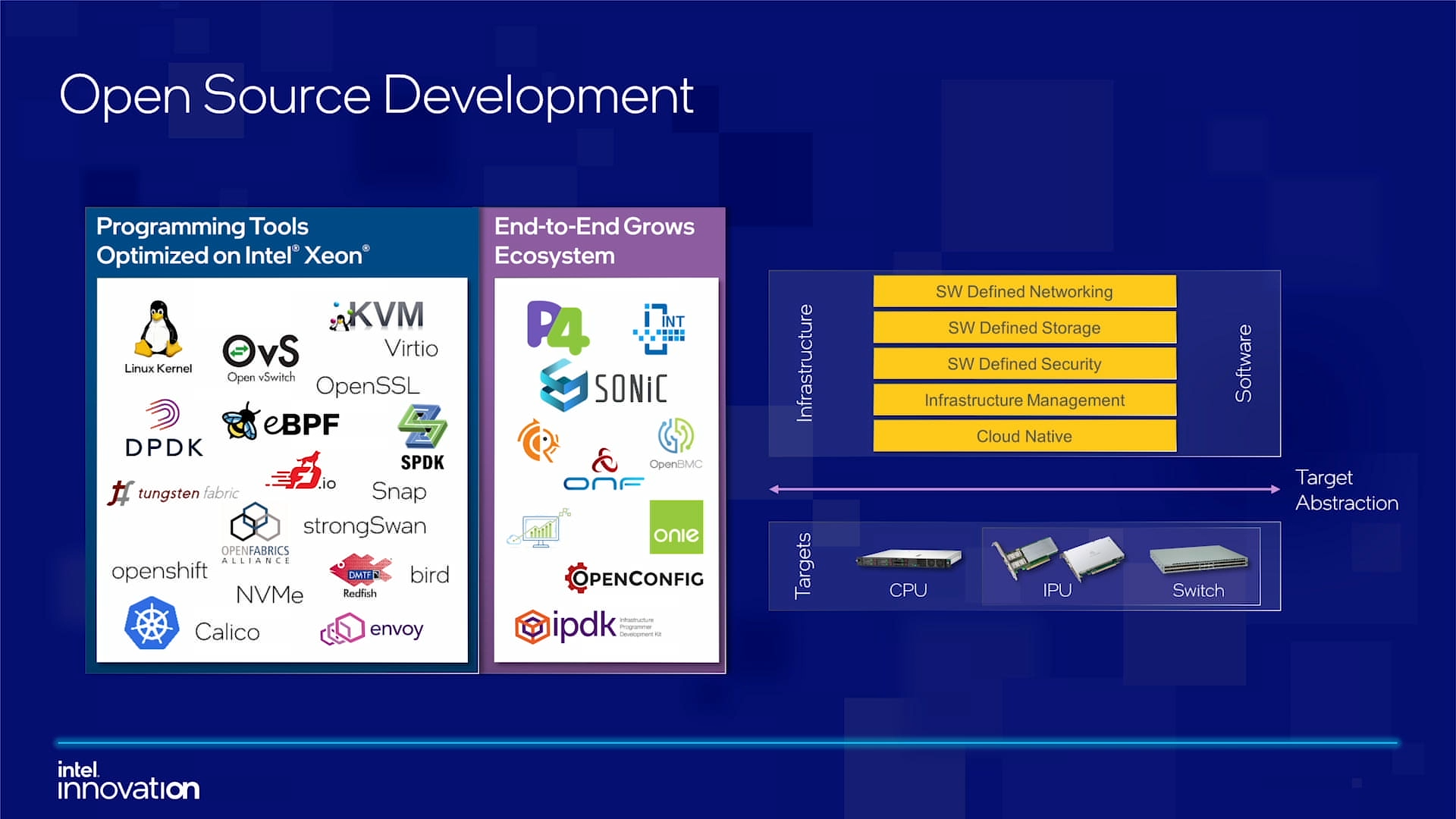 Более того, со стороны ПО и средств разработки жёсткой привязки именно к «железу» Intel нет. Компания представила open source фреймворк IPDK (Infrastructure Programmer Development Kit) для упрощения переноса и, что важно, оптимизации наиболее тяжёлых или нетривиально реализуемых функций ПО на SmartNIC (с FPGA или иной программируемой логикой), IPU/DPU, коммутаторы или CPU. IPDK дополняет уже имеющиеся решения вроде DPDK, SPDK и т.д. возможностями работы с P4. |
|

