Материалы по тегу: c
|
08.09.2023 [21:25], Сергей Карасёв
Одноплатный компьютер Libre AML-S905X-CC-V2 может устанавливать Linux-образы через интернетКомпания Libre Computer, по сообщению ресурса CNX Software, выпустила одноплатный компьютер AML-S905X-CC-V2 (Sweet Potato) в стиле Raspberry Pi 3B. Особенность устройства заключается в том, что оно позволяет загружать и устанавливать Linux-образы непосредственно через интернет с помощью инструмента Libre Computer OS Tool (LOST). Задействован процессор Amlogic S905X, который объединяет четыре ядра Arm Cortex-A53 с тактовой частотой до 1,5 ГГц, графический узел Arm Mali-450MP и VPU-блок Amlogic Video Engine 10. Объём оперативной памяти DDR4 составляет 2 Гбайт (опционально — 1 Гбайт). 
Источник изображения: CNX Software Плата несёт на борту 16 Мбайт флеш-памяти SPI Flash; кроме того, может быть добавлен модуль eMMC 5.x. Есть слот microSD с поддержкой UHS SDR104, сетевой контроллер 10/100MbE с опциональной реализацией PoE, четыре порта USB 2.0, разъём HDMI 2.0 и порт USB Type-C для подачи питания (5 В / 3 А). Среди прочего упомянуты интерфейсы S/PDIF и I2S, а также 40-контактная колодка (I2C, SPI, PWM, GPIO), совместимая с Raspberry Pi. Плюс к этому предусмотрен инфракрасный приёмник. Приобрести одноплатный компьютер AML-S905X-CC-V2 можно по ориентировочной цене $35. Фактически новинка является слегка обновлённой версией модели Le Potato 2017-го года.
08.09.2023 [11:21], Сергей Карасёв
В Португалии запущен Arm-суперкомпьютер Deucalion с быстродействием более 10 ПфлопсВ рамках проекта European High Performance Computing Joint Undertaking (EuroHPC JU), реализуемого властями Евросоюза, странами-участницами и частными компаниями с целью создания инфраструктуры высокопроизводительных вычислений, запущен суперкомпьютер Deucalion. Комплекс разработан специалистами Fujitsu Technology Solutions. Это первая система EuroHPC, основанная на процессорах с архитектурой Arm. Применены чипы Fujitsu A64FX, а также платформа Bull Sequana от Eviden (Atos). Суперкомпьютер располагается в Португалии: он размещён в Центре передовых вычислений Университета Минью в Гимарайнше. Общий бюджет проекта Deucalion составил €20 млн — средства выделены участниками инициативы EuroHPC и Португальским фондом науки и технологий (FCT). Deucalion — самый мощный суперкомпьютер в Португалии и восьмой вычислительный комплекс, созданный по программе EuroHPC JU. 
Источник изображения: FCT Комплекс обеспечивает производительность более 10 Пфлопс. Использовать систему в числе прочего планируется для исследований и разработок в области метеорологии и моделирования климата, гидродинамики, аэродинамики, а также астрофизики и космологии. Кроме того, суперкомпьютер будет стимулировать инновации в таких областях, как ИИ, персонализированная медицина, фармацевтика и новые материалы, пожаротушение, территориальное планирование, интеллектуальная мобильность и автономные транспортные средства.
07.09.2023 [21:25], Алексей Степин
Cerebras готова к построению масштабных ИИ-кластеров CS-2 с 163 млн ядерНа прошедшей недавно конференции Hot Chips 2023 компания Cerebras, создатель самого большого в мире ИИ-процессора WSE-2, рассказала о своём видении будущего ИИ-систем. По мнению Cerebras, сфокусировать внимание стоит не столько на наращивании сложности отдельных чипов, сколько на решениях проблем, связанных с масштабированием кластеров. Свою презентацию Cerebras начала с любопытных фактов: за прошедшие пять лет сложность ИИ-моделей возросла в 40 тыс. раз. И этот темп явно опережает темпы развития чипов-ускорителей. Хотя налицо прогресс и в техпроцессах (5x), и в архитектуре (14x), и во внедрении более эффективных для ИИ форматов данных, но наибольший прирост производительности обеспечивает именно возможность эффективного масштабирования. 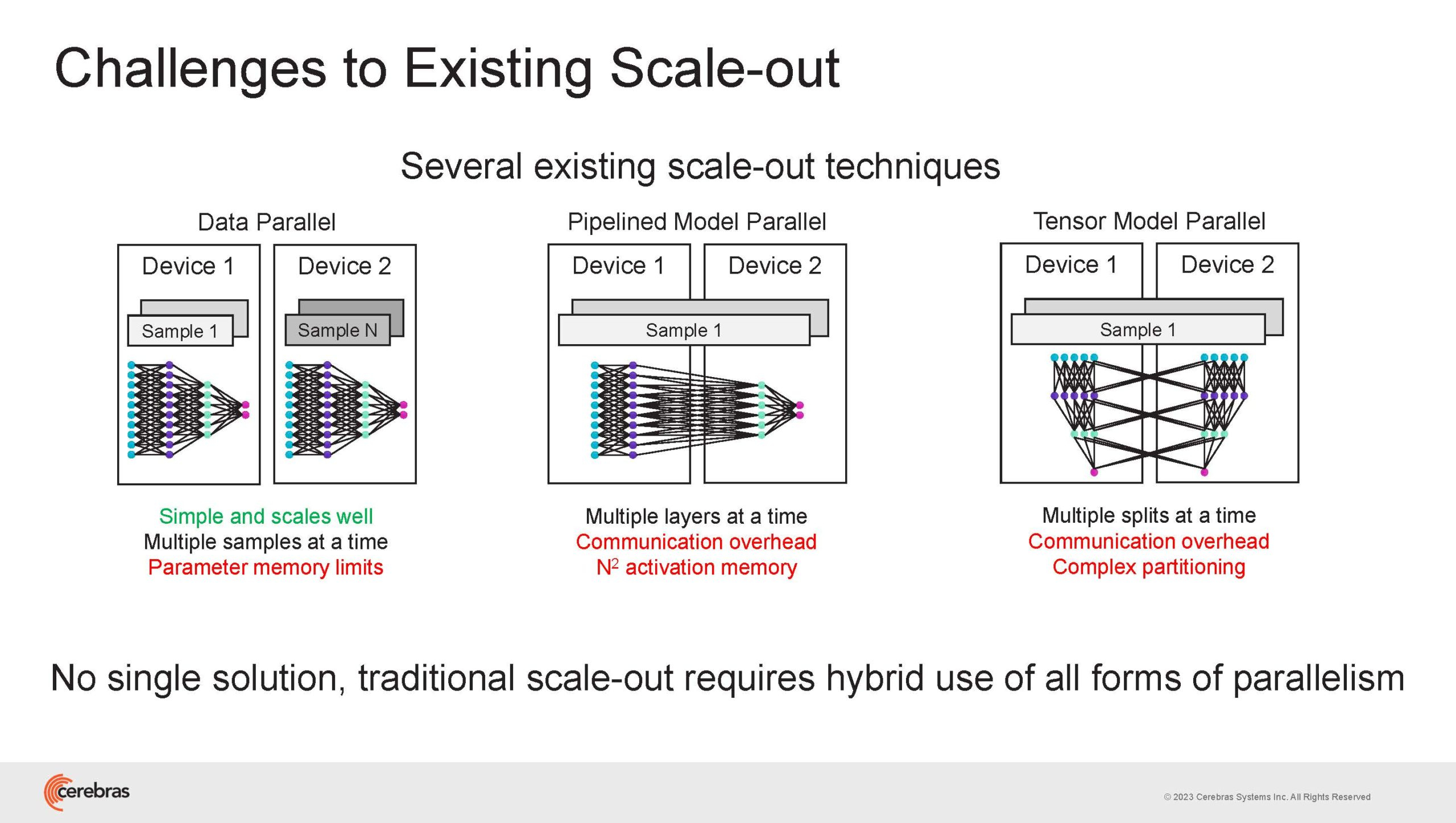
Источник изображений здесь и далее: Cerebras (via ServeTheHome) Однако и этого недостаточно — 600-кратный прирост от кластеризации явно теряется на фоне 40-тыс. усложнения самих нейросетей. А дальнейший рост масштабов ИИ-комплексов в их классическом виде, состоящих из множества «малых» ускорителей, неизбежно приводит к проблемам с организацией памяти, интерконнекта и вычислительных мощностей. 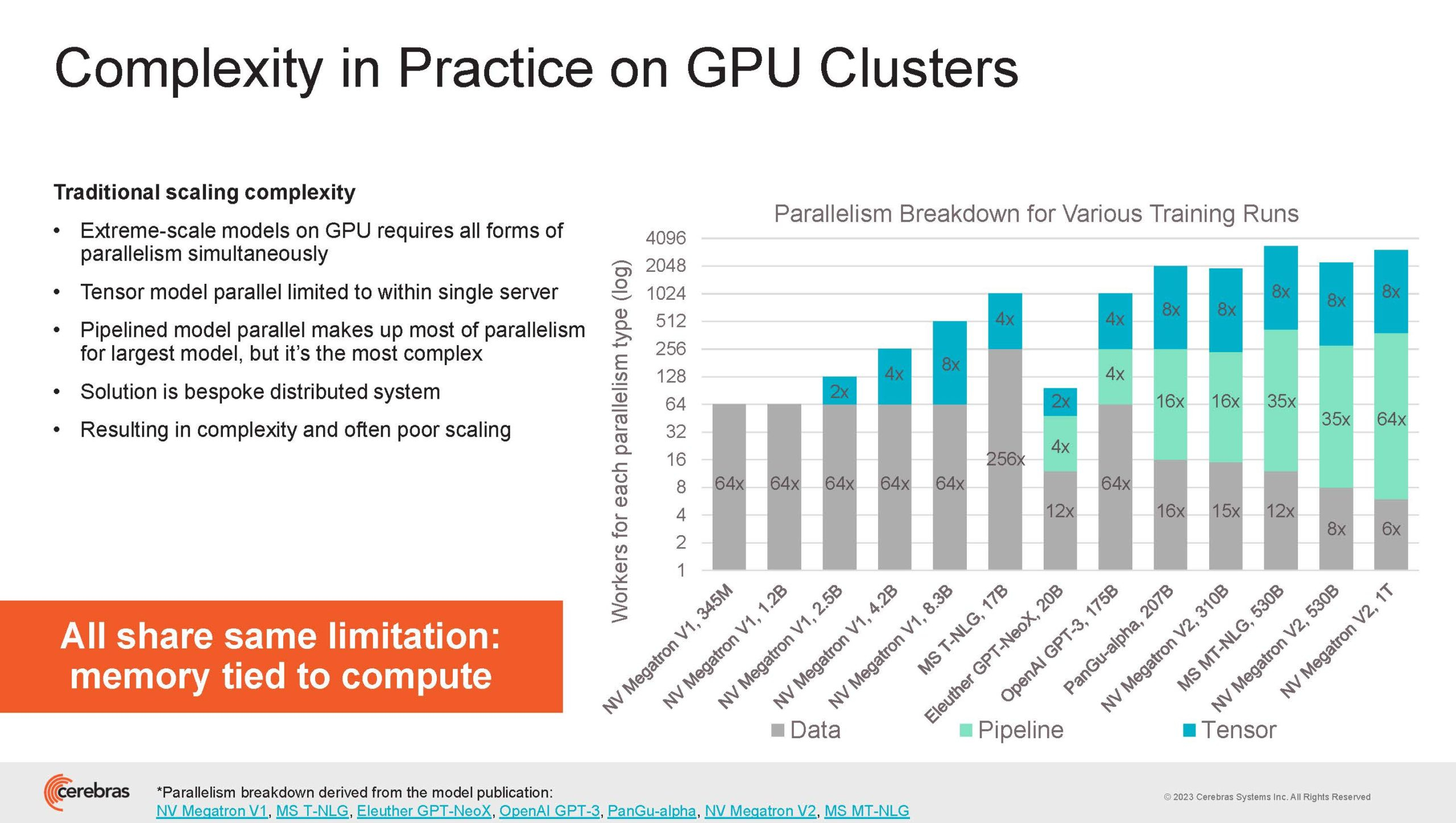 В итоге решение любой задачи в таких системах часто упирается в необходимость тончайшей, но при этом далеко не всегда эффективной оптимизации разделения ресурсов. При этом разные методы масштабирования имеют свои проблемы — узким местом могут оказаться и память, и интерконнект, и конкретный подход к организации кластера. 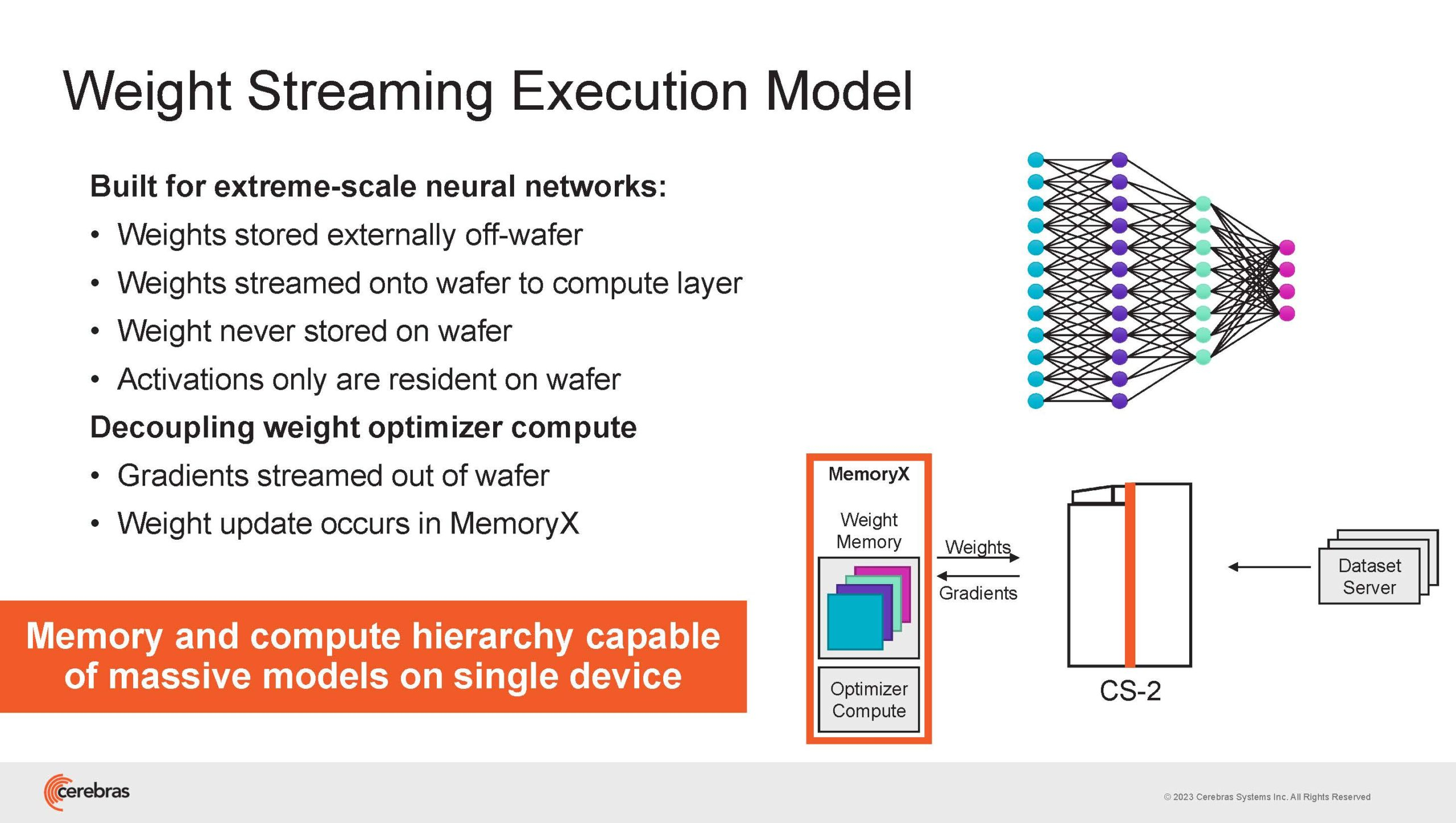 Cerebras же предлагает совершенно иной подход. Выход компания видит в создании огромных чипов-кластеров, таких, как 7-нм Cerebras WSE-2. Этот чип на сегодня можно назвать самым большим в индустрии: его площадь составляет более 45 тыс. мм2, при этом он содержит 2,6 трлн транзисторов и имеет 850 тыс. ядер, дополненных 40 Гбайт сверхбыстрой памяти. Что интереснее, кластер на базе CS-2 представляется с точки зрения исполняемой модели, как единая система. 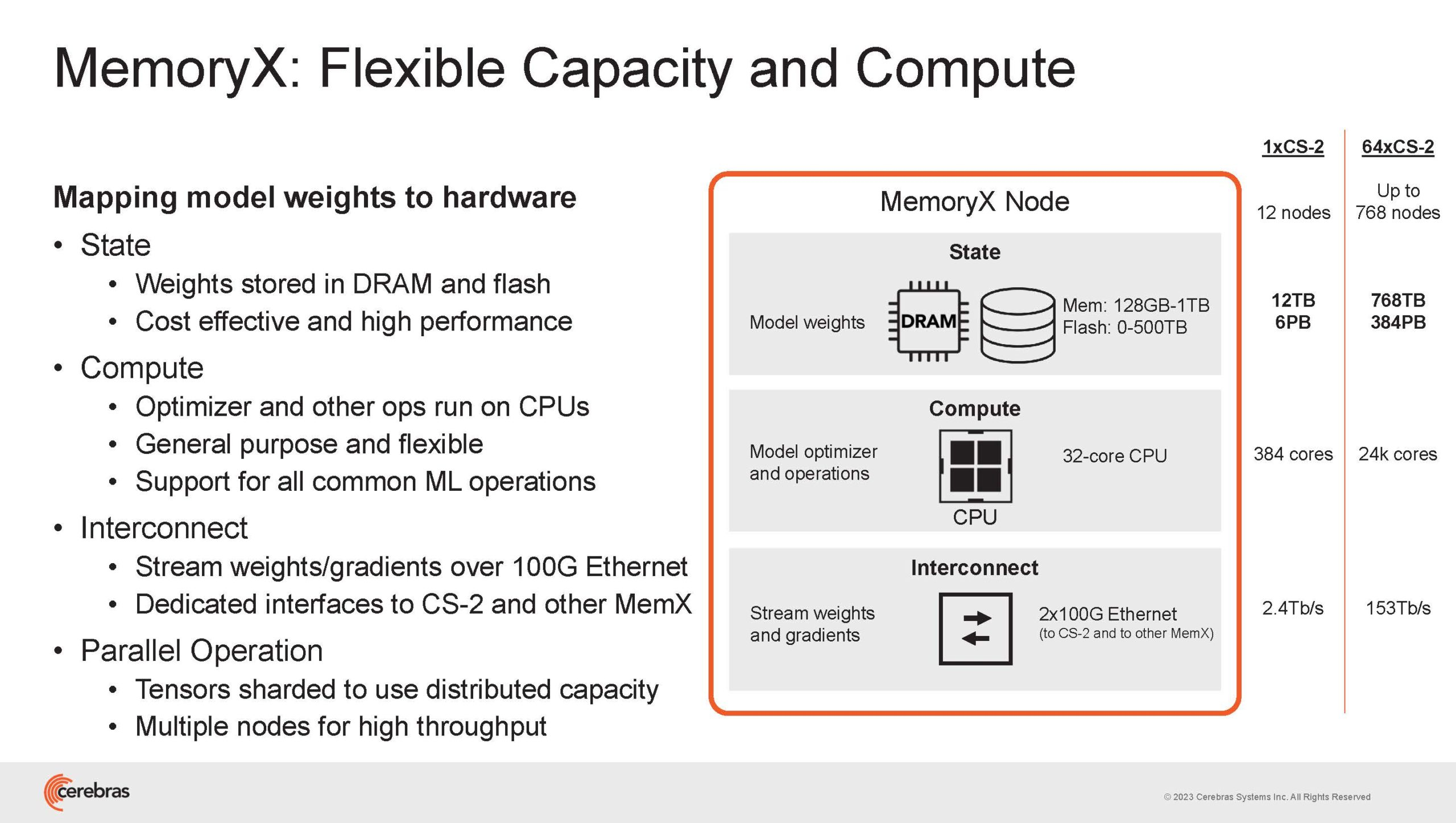 Сама по себе сложность WSE-2 и платформы CS-2 на его основе такова, что позволяет запускать модели практически любых размеров, благо весовые коэффициенты чип в себе не хранит, а подгружает извне с помощью подсистемы MemoryX. При этом сама по себе платформа CS-2 допускает и дальнейшее масштабирование: с помощью интерконнекта SwarmX в единый кластер можно объединить до 192 таких машин, что в теории позволит поднять производительность до 8+ Эфлопс. 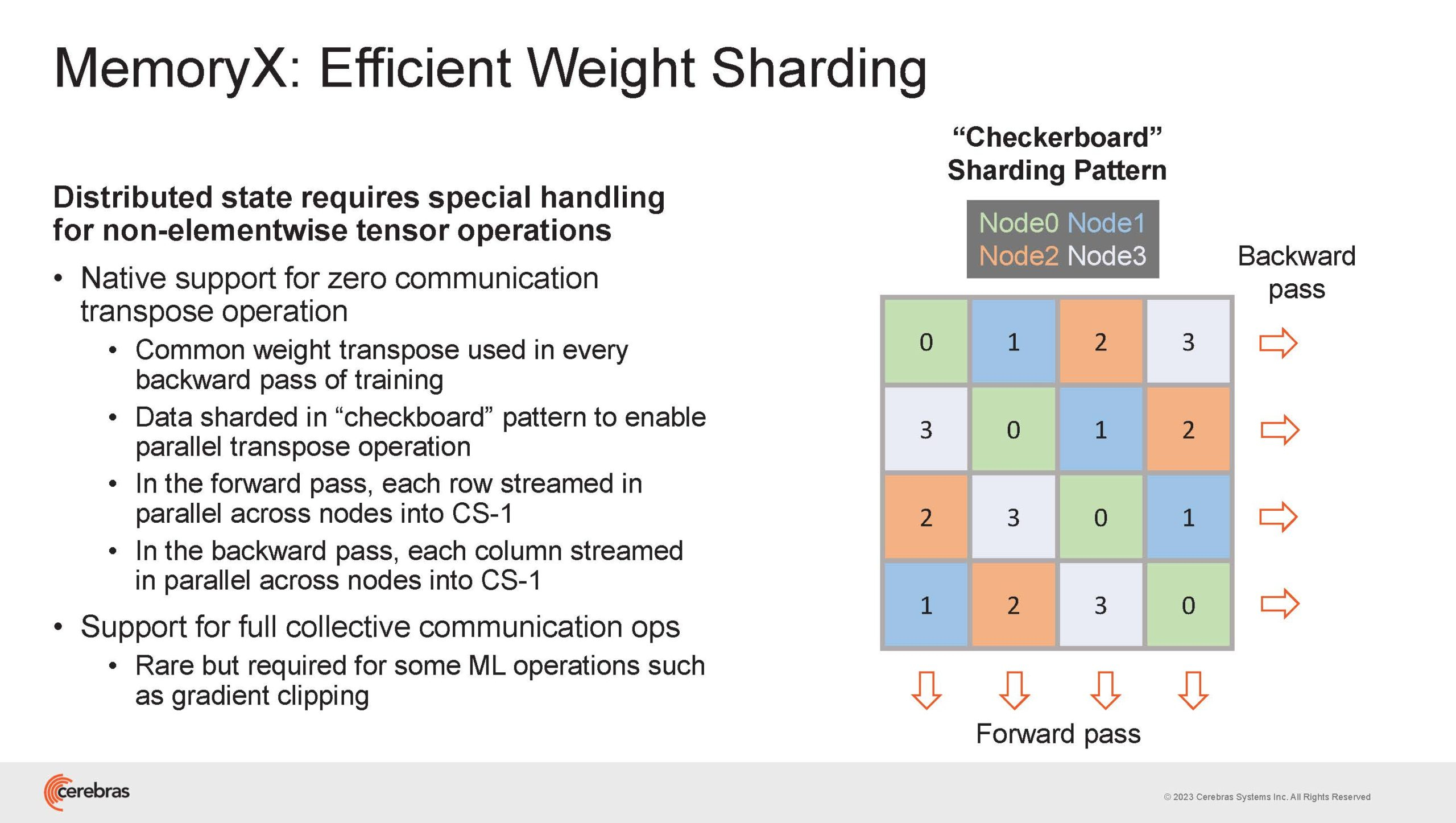 Подсистема MemoryX включает в себя 12 узлов, за оптимизацию модели в ней отвечают 32-ядерные процессоры, а веса хранятся как в DRAM, так и во флеш-памяти — объёмы этих подсистем составляют 12 Тбайт и 6 Пбайт соответственно. Каждый узел имеет по 2 порта 100GbE — один для закачки данных в CS-2, второй для общения с другими MemoryX в кластере. Оптимизация данных производится на процессорах MemoryX, «мегачипы» CS-2 для этого не используются. 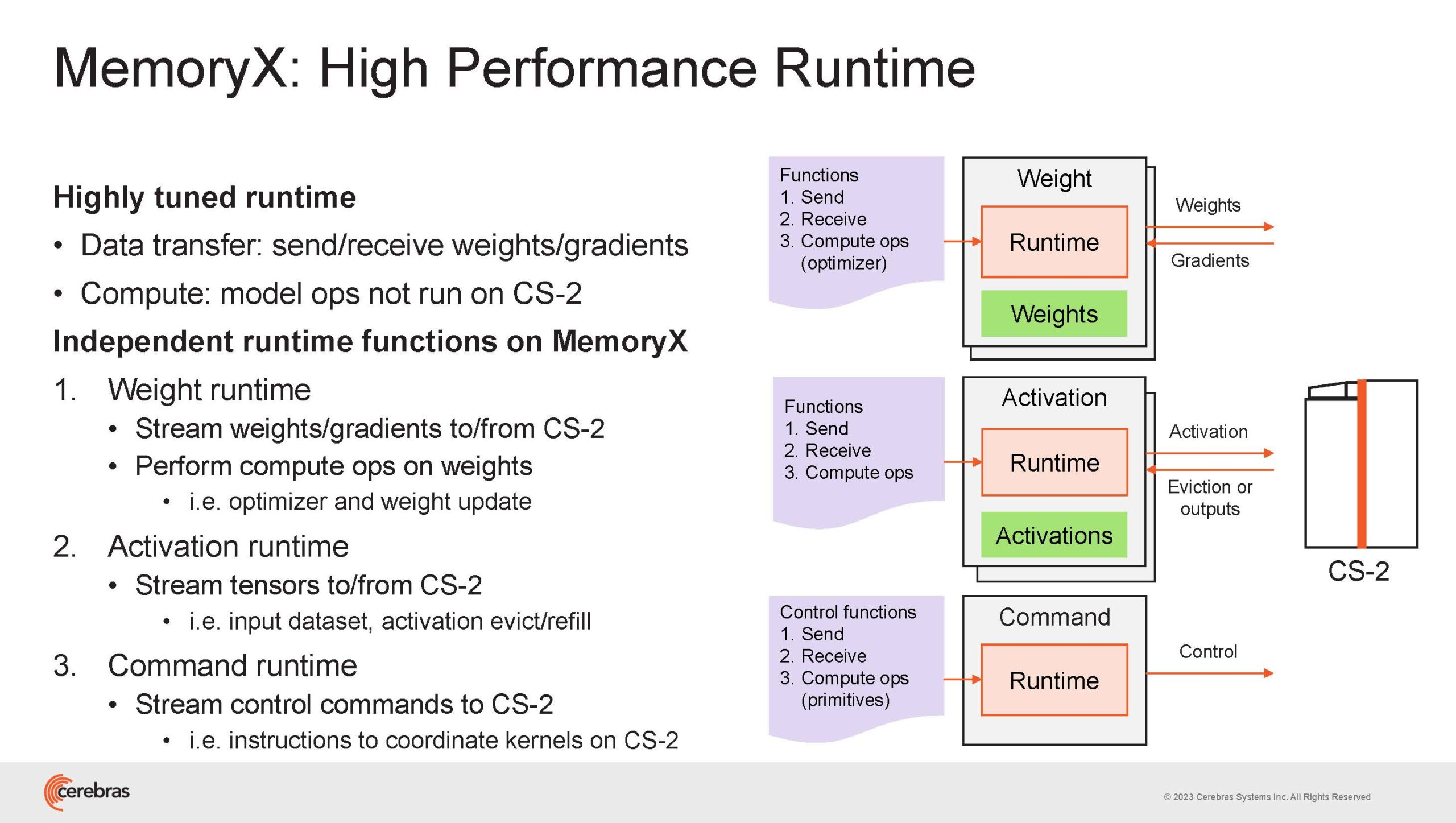 Подсистема интерконнекта SwarmX базируется на 100GbE с поддержкой RoCE DRMA, но имеет ряд особенностей: на каждые четыре системы CS-2 приходтся 12 узлов SwarmX c производительностью интерконнекта 7,2 Тбит/с. Трансляция и редуцирование данных осуществляются с коэффициентом 1:4, причём и здесь используются силы собственных 32-ядерных процессоров, а не ресурсы CS-2. Топологически SwarmX имеет двухслойную конфигурацию spine-leaf и обеспечивает соединение типа all-to-all, при этом каждая CS-2 имеет свой канал с пропускной способностью 1,2 Тбит/с. 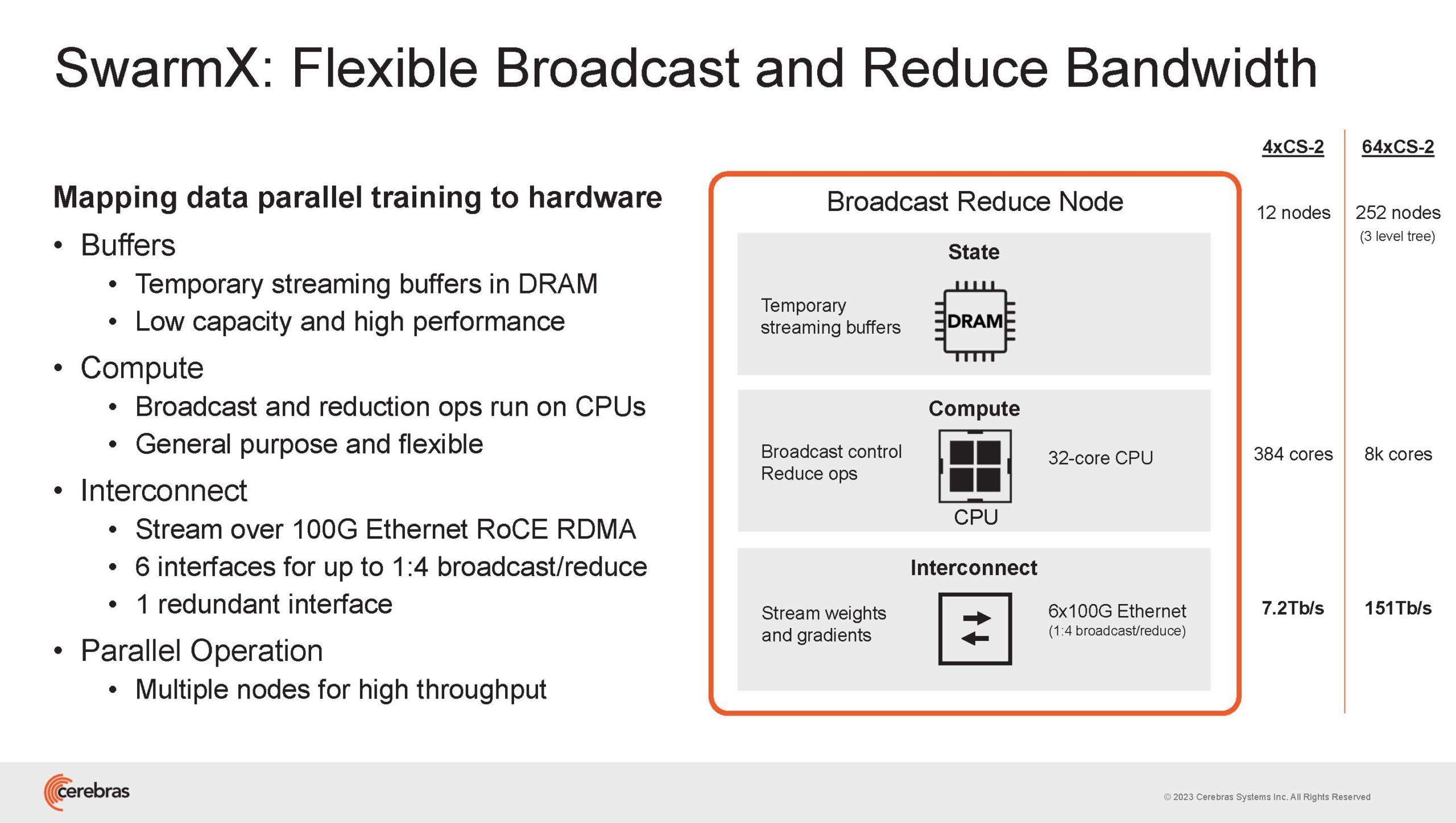 Сочетание MemoryX и SwarmX позволяет делать кластеры на базе CS-2 крайне гибкими: размер модели ограничивается лишь ёмкостью узлов MemoryX, а степень параллелизма — их количеством. При этом интерконнект обладает достаточной степенью избыточности, чтобы говорить об отсутствии единых точек отказа. 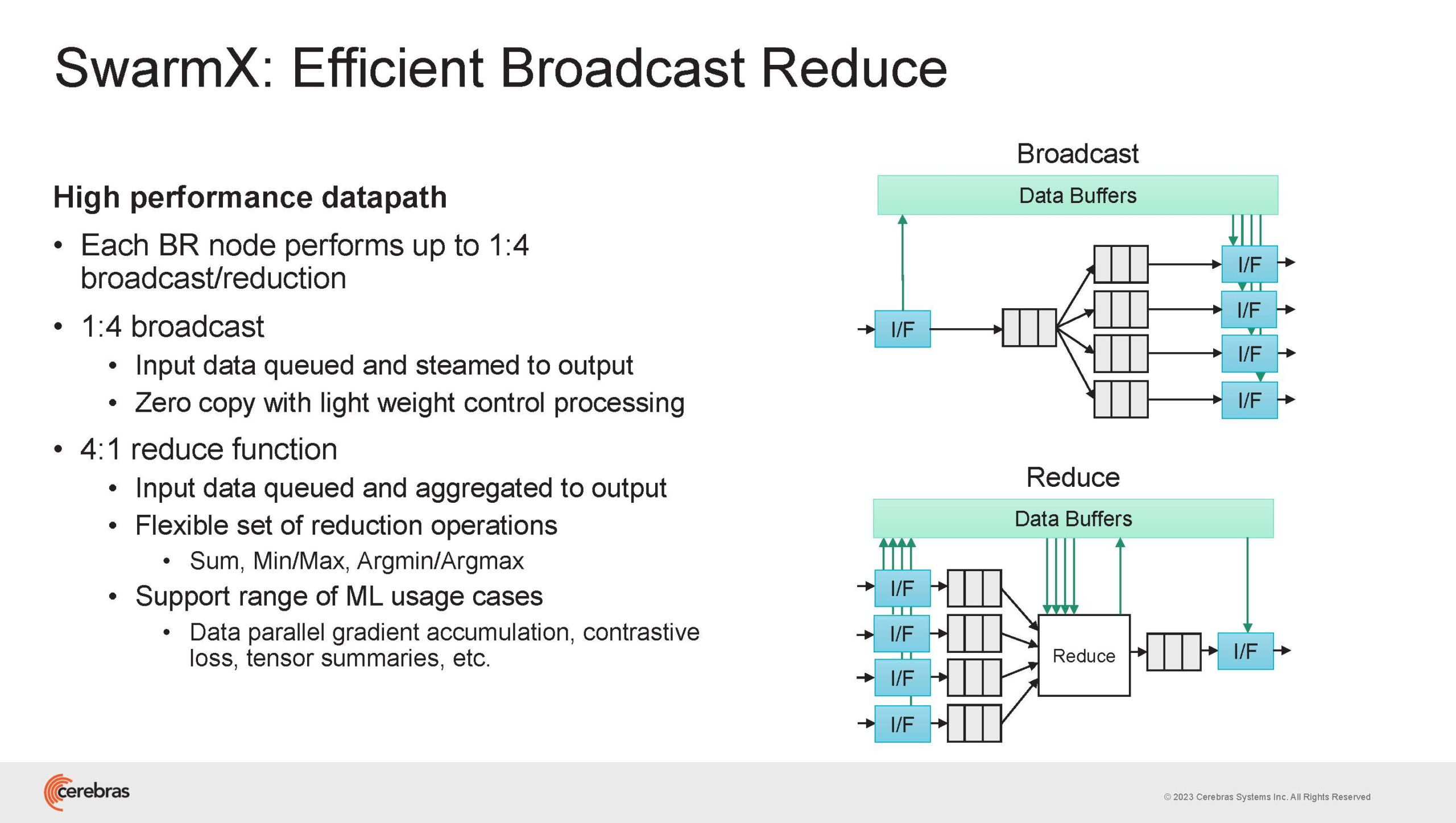 Таким образом, Cerebras имеет на руках всё необходимое для запуска самых сложных моделей искусственного интеллекта. Уже сравнительно немолодой кластер Andromeda, включающий всего 16 платформ CS-2, способен «натаскивать» за считанные недели нейросети размерностью до 13 млрд параметров. При этом масштабирование по размеру модели не требует серьёзного вмешательства в программный код, в отличие от классического подхода для ускорителей NVIDIA. Фактически для сетей и с 1, и со 100 млрд параметров используется один и тот же код. 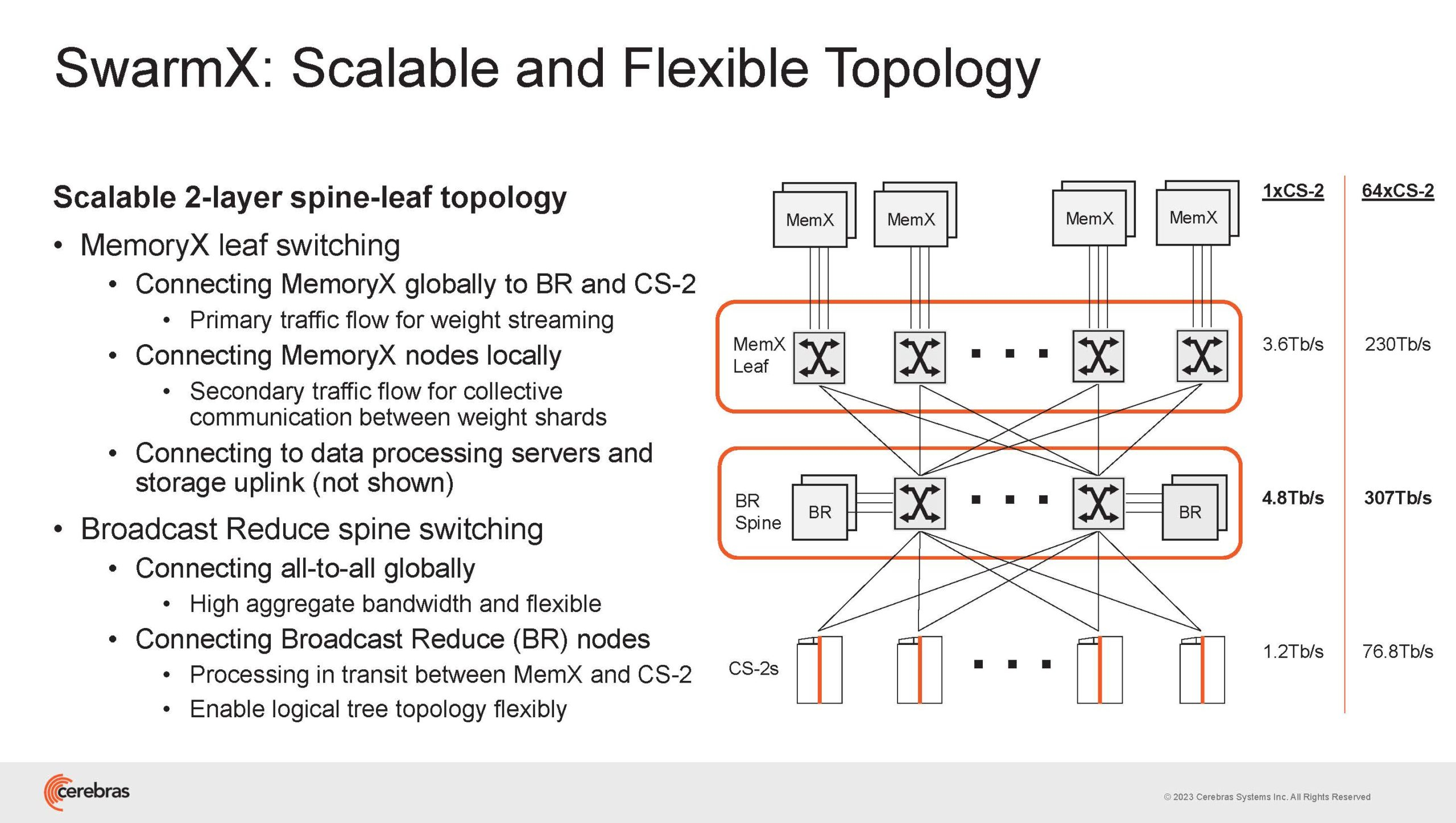 Более мощный 64-узловой комплекс Condor Galaxy 1 (CG-1), располагающий 54 млн ИИ-ядер и развивающий до 4 Эфлопс уже доказал, что подход к масштабированию, продвигаемый Cerebras, оправдывает себя. Он успешно обучил первую публичную модель с 3 млрд параметров, причём по возможностям она приближается к моделям с 7 млрд параметров. И это не предел: напомним, в текущем воплощении сочетание подсистем MemoryX и интерконнекта SwarmX допускает объединение в единый кластер до 192 узлов CS-2. 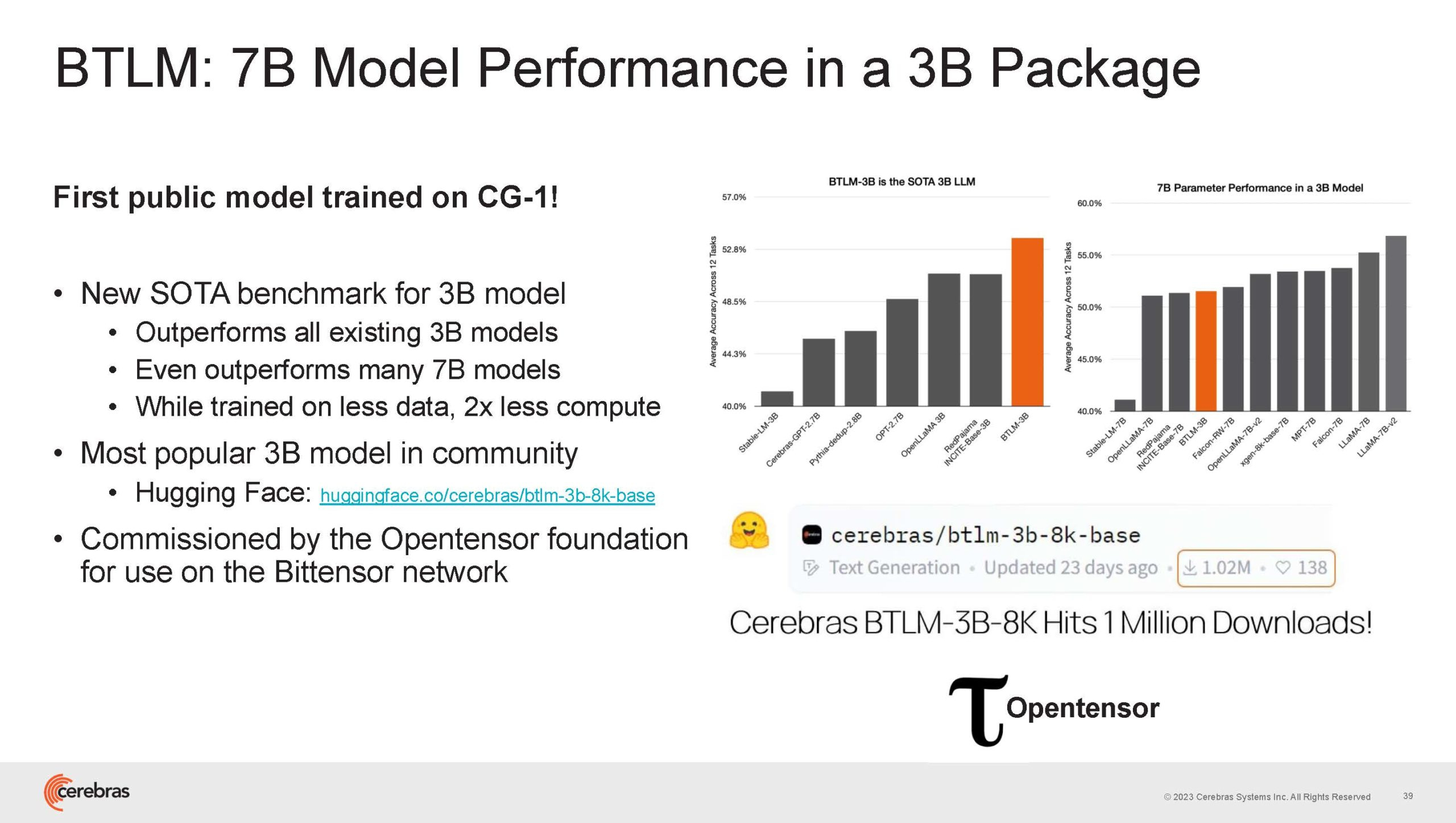 Компания считает, что она полностью готова к наплыву ещё более сложных нейросетей, а предлагаемая ей архитектура в явном виде лишена многих узких мест, свойственных традиционным GPU-архитектурам. Насколько успешным окажется такой подход в более отдалённой перспективе, покажет время.
07.09.2023 [19:51], Руслан Авдеев
Федеральная комиссия по связи США предлагает запретить IoT-модули китайских Quectel и FibocomФедеральная комиссия по связи США (FCC) предложила объявить китайские компании Quectel and Fibocom Wireless бизнесами, представляющими неприемлемый риск для государственной безопасности страны. По данным Reuters, обе компании выпускают решения для Интернета вещей, поставляемые на американский и другие рынки. При этом на долю китайских Quectel, Fibocom и Sunsea по итогам 2022 года приходилось порядка 50 % мировых продаж IoT-модулей. В августе американские парламентарии обратились к FCC с просьбой добавить эти компании в список вендоров, продукция которых запрещена для сертификации FCC и которые не могут претендовать на американское федеральное финансирование. По словам законотворцев, китайские модули сотовой связи уже используются в американском медицинском оборудовании, транспорте и сельхозоборудовании — современные модели можно контролировать и отключать дистанционно, потенциально даже напрямую из Китая. 
Источник изображения: TheDigitalArtist/pixabay.com Fibocom ещё не прокомментировала новость. Quectel же заявила, что не имеет никакого доступа к данным пользователей после того, как модули связи поставлены, а удалённое управление устройствами возможно только с помощью платформ OEM-производителей, в которых эти модули используются. Дополнительно в компании сообщили, что проведёт аудит безопасности своих модулей у независимой компании Finite State. FCC направила письма ФБР, Министерству юстиции, АНБ и иным ведомствам с призывом к сотрудничеству. Допускается возможность включения оборудования Quectel и Fibocom в т.н. перечень Covered List, куда уже попали десять китайских и одна российская компания, включая Huawei, ZTE, Hytera, Hikvision и Dahua. В отдельном письме законотворцам FCC сообщила, что вопрос нуждается в дальнейшем изучении, подчеркнув, что может отозвать авторизацию только по указанию агентств, отвечающих за безопасность США. FCC уже приняла ряд мер для ограничения использования китайского оборудования в американских телекоммуникационных сетях. В частности, в прошлом году комиссия проголосовала за запрет деятельности в США китайского подразделения China Unicom в лице Pacific Networks и компании ComNet. В FCC подчёркивают, что обеспечивают все компании, принимающие решения о покупке на телеком-рынке, «чёткими сигналами» о безопасности тех или иных продуктов.
07.09.2023 [13:14], Сергей Карасёв
SSSTC представила индустриальные M.2 SSD семейства CL6Компания Solid State Storage Technology Corporation (SSSTC, «дочка» Kioxia) анонсировала безбуферные SSD серии CL6, рассчитанные на применение в коммерческой сфере и промышленной отрасли. Это, в частности, могут быть индустриальные компьютеры, встраиваемые системы, сетевые терминалы и пр. Устройства доступны в трёх форматах — M.2 2280, M.2 2242 и M.2 2230. В них, по словам разработчиков, впервые для накопителей такого класса используются микрочипы флеш-памяти Kioxoa BiCS Flash 3D шестого поколения. Для обмена данными задействован интерфейс PCIe 4.0 x4 (спецификация NVMe 1.4). Вне зависимости от варианта исполнения накопители доступны в модификациях вместимостью 256 и 512 Гбайт, а также 1 и 2 Тбайт. Скорость последовательного чтения/записи информации достигает соответственно 4000 / 3000 Мбайт/с, 4800 / 4000 Мбайт/с, 6000 / 5000 Мбайт/с и 6000 / 5300 Мбайт/с. Показатель IOPS на операциях произвольного чтения/записи данных блоками по 4 Кбайт — до 350 тыс. / 700 тыс., 650 тыс. / 850 тыс., 650 тыс. / 800 тыс. и 900 тыс. / 900 тыс. 
Источник изображения: SSSTC Показатель MTBF (среднее время безотказной работы) достигает 3 млн часов. Говорится о поддержке TCG-Opal 2.01 и шифрования XTS-AES 256. Диапазон рабочих температур простирается от 0 до +40 °C. Энергопотребление в обычном режиме — около 4,5 Вт. На изделия предоставляется трёхлетняя гарантия.
05.09.2023 [11:48], Сергей Карасёв
ASRock выпустила мини-компьютеры 4X4 Box 7040 на процессорах AMD Ryzen 7040UКомпания ASRock Industrial анонсировала компьютеры небольшого форм-фактора 4X4 Box 7040, рассчитанные на использование в промышленной и коммерческой сферах, а также в области IoT. В основу новинок положены процессоры AMD семейства Ryzen 7040U. В серию вошли модели 4X4 Box-7640U и 4X4 Box-7840U. Первая несёт на борту чип Ryzen 5 7640U (6 ядер; 12 потоков; до 4,9 ГГц), вторая — Ryzen 7 7840U (8 ядер; 16 потоков; до 5,1 ГГц). Доступны два слота SO-DIMM для модулей оперативной памяти DDR5-5600 суммарным объёмом до 64 Гбайт. 
Источник изображения: ASRock Industrial В оснащение входят адаптеры Wi-Fi 6E 802.11ax и Bluetooth 5.2, сетевые контроллеры 1GbE (Realtek RTL8111EPV) и 2.5GbE (Realtek RTL8125BG), звуковой кодек Realtek ALC256. Есть коннектор M.2 Key M 2242/2260/2280 для SSD с интерфейсом PCIe 4.0 x4 и порт SATA-3. Применена система активного охлаждения с вентилятором. На фронтальную панель выведены порт USB 3.2 Gen2 Type-A и два порта USB 4 (DP1.4a), а также стандартное аудиогнездо. Сзади расположены два коннектора RJ-45 для сетевых кабелей, два интерфейса HDMI 1.4b, два порта USB 2.0 и DC-гнездо для подачи питания. Размеры составляют 117,5 × 110,0 × 47,85 мм, вес — около 1 кг. Диапазон рабочих температур — от 0 до +40 °C. Допускается монтаж при помощи крепления VESA. Гарантирована совместимость с Windows 10/11.
03.09.2023 [12:38], Сергей Карасёв
Расходы на публичные облака в Европе в 2023 году превысят $140 млрдКомпания International Data Corporation (IDC) опубликовала свежий прогноз по европейскому рынку публичных облаков. Аналитики полагают, что данный сектор продолжит расти, несмотря на кризис, макроэкономические проблемы, высокий уровень инфляции в еврозоне и массовые увольнения в технологической отрасли. По итогам 2023 года, по мнению IDC, затраты на публичные облака в Европе составят приблизительно $142 млрд. К 2027-му этот показатель достигнет $291 млрд. Если эти ожидания оправдаются, значение CAGR (среднегодовой темп прироста в сложных процентах) в период 2022–2027 гг. окажется на уровне 20 %. Отмечается, что на сервисы SaaS будет по-прежнему приходиться основная часть расходов, в то время как услуги PaaS останутся самой быстрорастущей сферой. К концу 2023 года около 55 % европейских компаний перейдут в облако, стремясь повысить производительность работы, усилить безопасность и стимулировать автоматизацию с использованием ИИ. 
Изображение: Growtika / Unsplash Банковское дело, розничная торговля и телекоммуникации будут ответственны за наибольшие расходы в публичном облаке в 2023 году: на их долю придётся около 26 % от общего объёма рынка. Отмечается, что телеком-сегмент в меньшей степени пострадал от повышения цен на энергоносители, нежели другие отрасли, а поэтому в 2024-м в нём ожидается существенный рост инвестиций. В долгосрочной перспективе ПО и информационные услуги будут иметь самый высокий среднегодовой темп роста среди всех отраслей в Европе. Показатель CAGR в 2022–2027 гг. здесь прогнозируется на уровне 27 %.
01.09.2023 [21:45], Руслан Авдеев
Новый суперкомпьютер «МГУ-270» с ИИ-производительностью 400 Пфлопс поможет создать российский аналог ChatGPT и решить массу научных задач1 сентября ректор Московского государственного университета им. Ломоносова (МГУ) Виктор Садовничий объявил о запуске суперкомпьютера «МГУ-270» с ИИ-производительностью 400 Пфлопс (точность вычислений не указывается). Как сообщает пресс-служба МГУ, уже объявлено о начале выполнения тестовых задач новой машиной. Комплекс станет частью объединённой сети научных суперкомпьютерных центров России и позволит создавать российские языковые модели, аналогичные ChatGPT. Суперкомпьютер, как сообщается, разрабатывался с 2020 года с участием факультета ВМК МГУ. Система включает около сотни самых современных ускорителей, уточняет ТАСС. Машина использует неназванный 200-Гбит/с интерконнект, который также охватывает СХД. Для управления и интеграции с внешней инфраструктурой использована сеть с пропускной способностью 100 Гбит/с. Кроме того, машина получила новые инженерные системы, причём при создании всего комплекса широко применялись узлы и компоненты российского производства. «МГУ-270» составит единый вычислительный кластер с введённым ранее в эксплуатацию суперкомпьютером «Ломоносов-2». Иные технические характеристики названы не были, поэтому можно только гадать, какие именно ускорители используются в новой системе. Если предположить, что речь идёт о 400 Пфлопс в FP8-расчётах (с разреженностью), то для получения такого уровня производительности хватит около ста новейших ускорителей NVIDIA H100 в форм-факторе SXM или же, вероятно, неподсанкционных H800. 
Источник изображения: МГУ Как сообщало агентство ТАСС со ссылкой на Садовничего, задачи «МГУ-270» в основном будут связаны с развитием технологий искусственного интеллекта (ИИ) и подготовкой кадров в этой области. По данным пресс-службы МГУ, исследователи займутся «разработкой математических методов машинного обучения для обработки текстовой научной информации большого объема, интеллектуальным анализом изображений для высокопроизводительного фенотипирования растений и точного земледелия, прогнозированием качества гетерогенных каналов в сетях передачи данных на основе вероятностных моделей и методов машинного обучения» и исследованиям в других сферах, например, в области материаловедения. Строительство «МГУ-270» предусмотрено программой развития МГУ до 2030 года. По словам декана факультета ВМК МГУ Игоря Соколова, «МГУ-270» уже начал выполнять первые тестовые задачи, итоги работ подведут в декабре. В частности, они связаны с анализом изображений и медицинскими исследованиями, а в будущем модель, возможно, поможет ускорить появление средства для более эффективного контроля внимания младших школьников на уроках. Суперкомпьютер будет применяться для поддержки курсов в области ИИ, разработки магистерских программ, для автоматизации и цифровизации учебного процесса и проведения соревнований в формате хакатонов.
01.09.2023 [16:26], Алексей Степин
Cornelis Networks ускорит Omni-Path Express до 1,6 Тбит/сИнтерконнекту Omni-Path прочили в своё время светлое будущее, но в 2019 году компания Intel отказалась от своего детища и свернула поставки OPA-решений. Однако эстафету подхватила Cornelis Networks, так что технология не умерла — совсем недавно The Next Platform были опубликованы планы по дальнейшему развитию Omni-Path. В 2012 году Intel выкупила наработки по TruScale InfiniBand у QLogic, позднее дополнив их приобретением у Cray интерконнектов Gemini XT и Aries XC. Задачей было создание единого интерконнекта, могущего заменить PCIe, FC и Ethernet, а в основу была положена технология Performance Scale Messaging (PSM). PSM считалась более эффективной и пригодной в сравнении с verbs InfiniBand, однако самой технологии более 20 лет. В итоге Cornelis Networks отказалась от PSM и теперь развивает новый программный стек на базе libfabric. 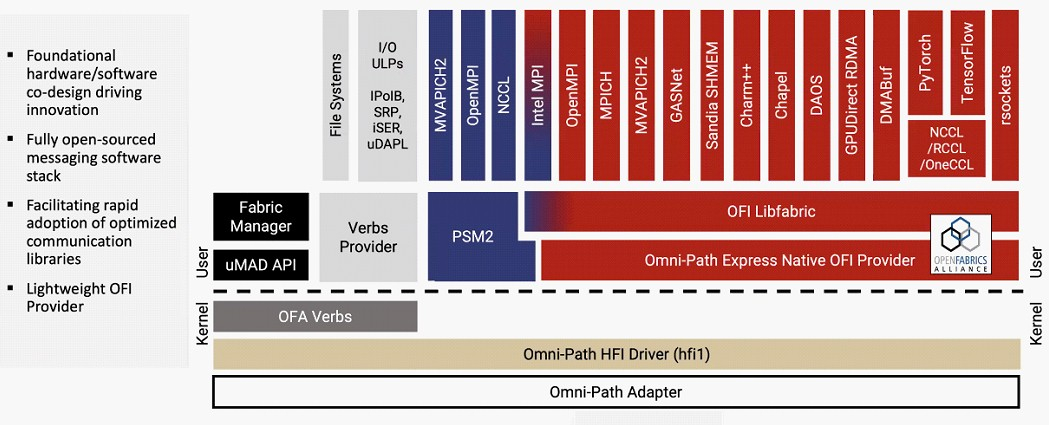
Источник изображений здесь и далее: Cornelis Networks (viaThe Next Platform) Уже первое поколение Omni-Path Express (OPX), работающее со скоростью 100 Гбит/с могло работать под управлением нового стека бок о бок с PSM2, а для актуальных 400G-продуктов Omni-Path Express CN5000 вариант OFI станет единственным. Скорее всего, в этом поколении будет также убрано всё, что работает на основе кода OFA Verbs. Останутся только части, выделенные на слайде выше красным. Как отмечает Cornelis Networks, главным отличием OPX от InfiniBand станет использование стека на базе полностью открытого кода с апстримом драйвера OFI в ядро Linux. 
Планы Cornelis Networks по развитию Omni-Path Планы компании простираются достаточно далеко: на 2024 год запланировано пятое поколение Omni-Path, включающее в себя не только адаптеры, но и необходимую инфраструктуру — 48-портовые коммутаторы и 576-портовые директоры. Предел масштабирования возрастёт практически на порядок, с 36,8 тыс. подключений для Omni-Path 100 до 330 тыс. Латентность при этом составит менее 1 мкс при потоке до 1,2 млрд сообщений в секунду. Появится поддержка топологий Dragonfly и Megafly, оптимизированных для применения в крупных HPC-системах, и динамическая адаптивная маршрутизация на базе данных телеметрии. 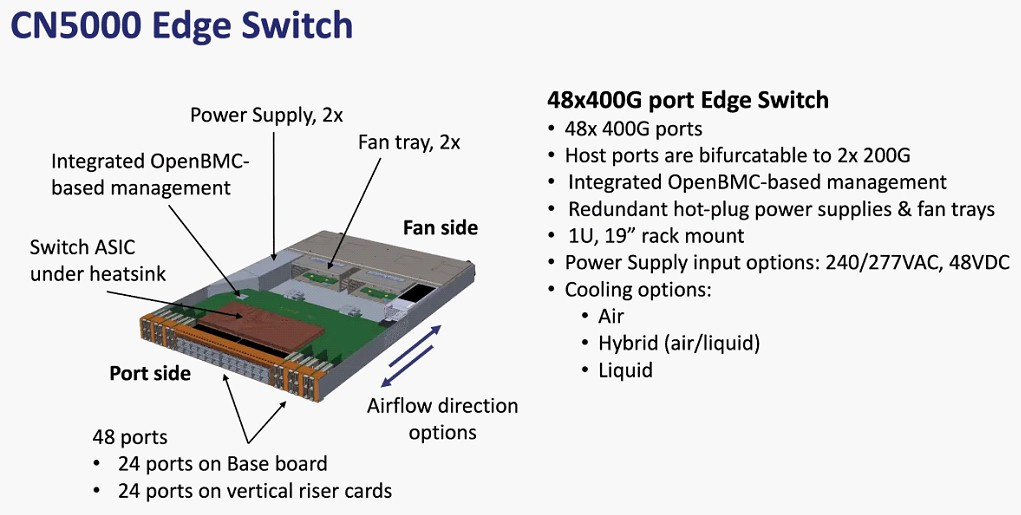 Характеристики и внутреннее устройство коммутаторов пятого поколения CN5000 компания публикует уже сейчас. Обычный периферийный коммутатор займёт высоту 1U, но при этом будет поддерживать как воздушное, так и жидкостное охлаждение, а модульный коммутатор класса director будет занимать 17U и получит внутренний интерконнект с топологией 2-tier Fat Tree. В нём будет предусмотрена горячая замена модулей и опция жидкостного охлаждения.  Базовый адаптер CN5000 выглядит как обычная плата расширения с интерфейсом PCIe 5.0 x16. Будут доступны варианты с одним и двумя портами 400G. Что интересно, опция жидкостного охлаждения предусмотрена и здесь. В 2026 году должно появиться шестое поколение решений Omni-Path CN6000 со скоростью 800 Гбит/с, включающее в себя не только базовые адаптеры и коммутаторы, но и первый в мире DPU для OPA, построенный на базе архитектуры RISC-V и поддерживающий CXL. Благодаря DPU будут реализованы более продвинутые опции разгрузки хост-системы и ускорения конкретных приложений. 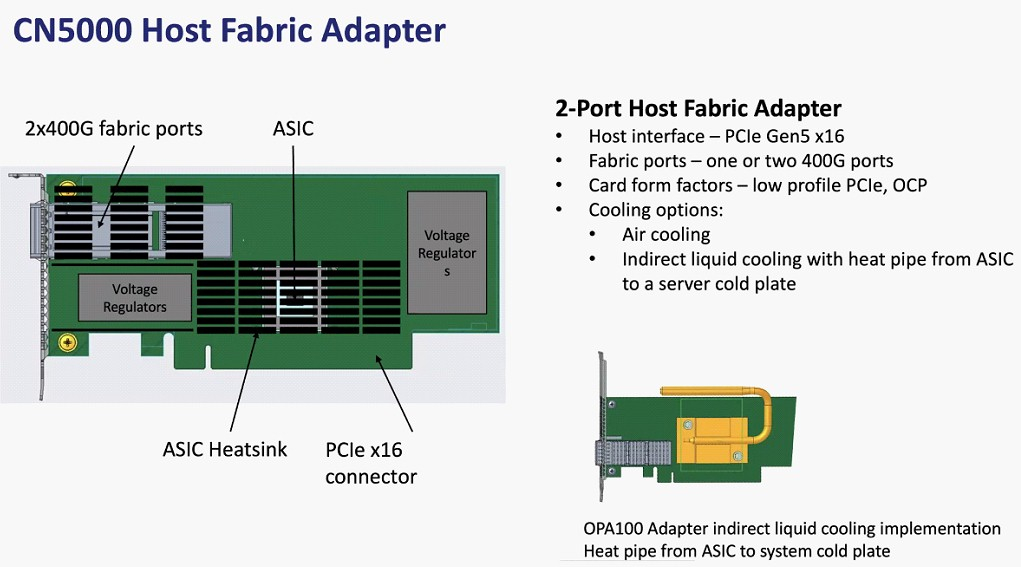 Наконец, в 2028 году в седьмом поколении CN7000 скоростной потолок поднимется с 800 до 1600 Гбит/с. Будет внедрена перспективная для крупномасштабных сетей поддержка топологии HyperX. Также ожидается появление чиплетов с интерфейсом UCIe и интегрированной фотоникой, что позволит интегрировать Omni-Path в решения сторонних производителей. Одной из главных целей Cornelis Networks, напомним, заявлено создание системы интерконнекта для суперкомпьютеров нового поколения экзафлопного класса. Разработка финансируется в рамках инициативы Exascale Computing Initiative (ECI). А первым суперкомпьютером, использующим Omni-Path пятого поколения (400G), станет техасский Stampede3.
01.09.2023 [14:05], Сергей Карасёв
В Лос-Аламосской лаборатории запущен суперкомпьютер Crossroads на базе Intel Xeon Sapphire RapidsЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США сообщила о запуске суперкомпьютера Crossroads — первого в мире крупного вычислительного комплекса, полагающегося исключительно на процессоры Intel Xeon Sapphire Rapids, в том числе с HBM-памятью. Система будет применяться для решения сложных научных задач, связанных с ядерным арсеналом США. О создании 165-Пфлопс машины впервые было объявлено в конце 2020 года, а первая фаза установки Crossroads была завершена в октябре 2022 года. Тогда говорилось, что по FP64-производительности новый суперкомпьютер превзойдёт существующую систему LANL Trinity в четыре раза. Отличительной чертой машины является то, что она полагается исключительно на CPU Intel. Как теперь сообщается, в июне оставшееся оборудование, включая компоненты системы жидкостного охлаждения, было доставлено в Стратегический вычислительный комплекс (Strategic Computing Complex), где размещены HPC-системы LANL. После этого специалисты HPE произвели монтаж узлов и обеспечили подключение Crossroads к сети лаборатории. В настоящее время проводится первоначальная диагностика систем Crossroads. Суперкомпьютер станет доступен пользователям нынешней осенью. 
Источник изображения: LANL Утверждается, что Crossroads обеспечит в четыре–восемь раз более высокую производительность по сравнению с Trinity при решении сложных задач моделирования. Но точные показатели быстродействия пока не раскрываются. Известно, что в состав суперкомпьютера входят узлы с HBM-версией Sapphire Rapids (Intel Max), а также подсистема хранения данных типа All-Flash. |
|

