Материалы по тегу: ускоритель
|
08.09.2025 [17:26], Владимир Мироненко
d-Matrix начала тестирование чипа Pavehawk с поддержкой 3DIMCСтартап d-Matrix объявил о разработке новой реализации технологии 3D-вычислений в памяти (3DIMC), которая обещает в 10 раз ускорить работу ИИ-моделей и в 10 раз повысить энергоэффективность по сравнению с текущим отраслевым стандартом HBM4, пишет ресурс SiliconANGLE. Технический директор Судип Бходжа (Sudeep Bhoja) сообщил в блоге, что первый чип компании с поддержкой 3DIMC, d-Matrix Pavehawk, разработка которого заняла более двух лет, сейчас проходит тестирование. В Pavehawk логический блок, изготовленный с использованием 5-нм техпроцесса TSMC, располагается поверх чипа памяти и интегрирован с ним посредством технологии F2F (face-to-face). По словам Бходжи, отраслевые тесты показывают, что производительность вычислений растёт примерно в 3 раза каждые два года, в то время как пропускная способность памяти — всего в 1,6 раза. Этот разрыв постоянно увеличивается, память уже стала узким местом в масштабировании ИИ. Компания утверждает, что простое увеличение количества ускорителей в ЦОД не решит проблему «стены памяти». 
Источник изображений: d-Matrix/ServeTheHome HPCwire цитирует гендиректора: d-Matrix Сида Шета (Sid Sheth): «Модели быстро развиваются, и традиционные системы памяти HBM становятся очень дорогими, энергоёмкими и ограниченными по пропускной способности». По его словам, узким местом ИИ-инференса является память, а не только количество операций с плавающей запятой, но 3DIMC меняет правила игры. «Стекируя память в трёх измерениях и обеспечивая её более тесную интеграцию с вычислениями, мы значительно сокращаем задержку, увеличиваем пропускную способность и открываем новые возможности повышения эффективности», — подчеркнул он. Компания отметила, что инференс, а не обучение, быстро становится доминирующей рабочей ИИ-нагрузкой. По словам Бходжи, CoreWeave недавно заявила, что 50 % её рабочих нагрузок теперь приходится на инференс, и аналитики прогнозируют, что в течение следующих двух-трех лет инференс будет составлять более 85 % всех корпоративных рабочих ИИ-нагрузок. Он подчеркнул, что компания не занимается перепрофилированием архитектур, созданных для обучения ИИ-моделей, — она с нуля разрабатывает решения, ориентированные на инференс. 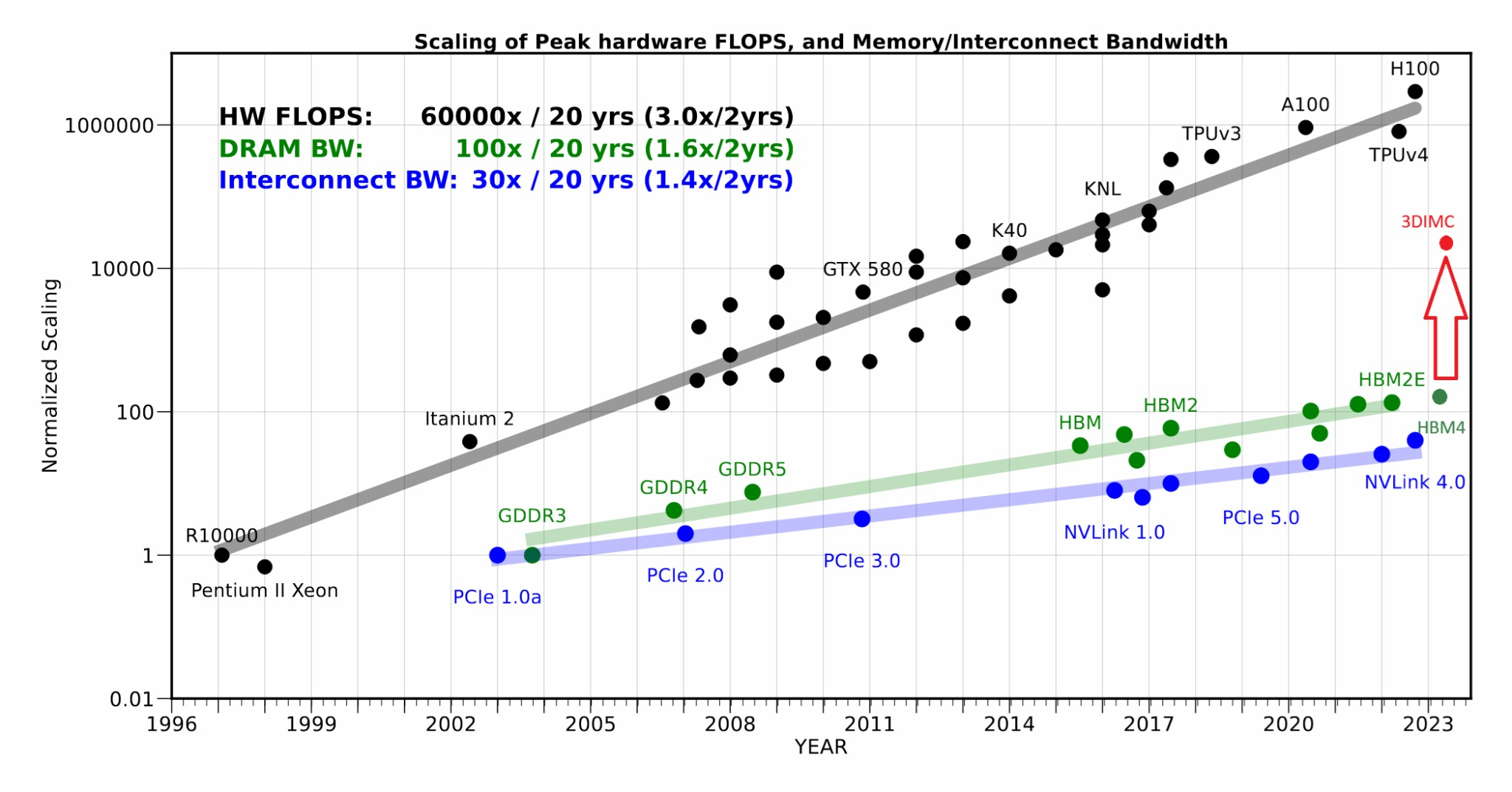 Бходжа сообщил, что первые пользователи ИИ-ускорителей Corsair, среди которых есть и гиперскейлеры, и неооблака, убедились, что архитектура с упором на память может значительно повысить пропускную способность, энергоэффективность и скорость генерации токенов по сравнению с GPU. Он также отметил, что конструкция на основе чиплетов обеспечивает не только большую пропускную способность памяти, но и «невероятную» гибкость, позволяя внедрять технологии памяти нового поколения быстрее и эффективнее, чем монолитные архитектуры. Бходжа заявил, что 3DIMC на порядок увеличит пропускную способность памяти и производительность для задач ИИ-инференса и обеспечит провайдерам сервисов и предприятиям возможность масштабировать их эффективно и экономично по мере появления новых моделей и приложений. С выводом Pavehawk на рынок компания занялось созданием следующего поколения архитектуры обработки в оперативной памяти, использующей 3DMIC, под названием Raptor. 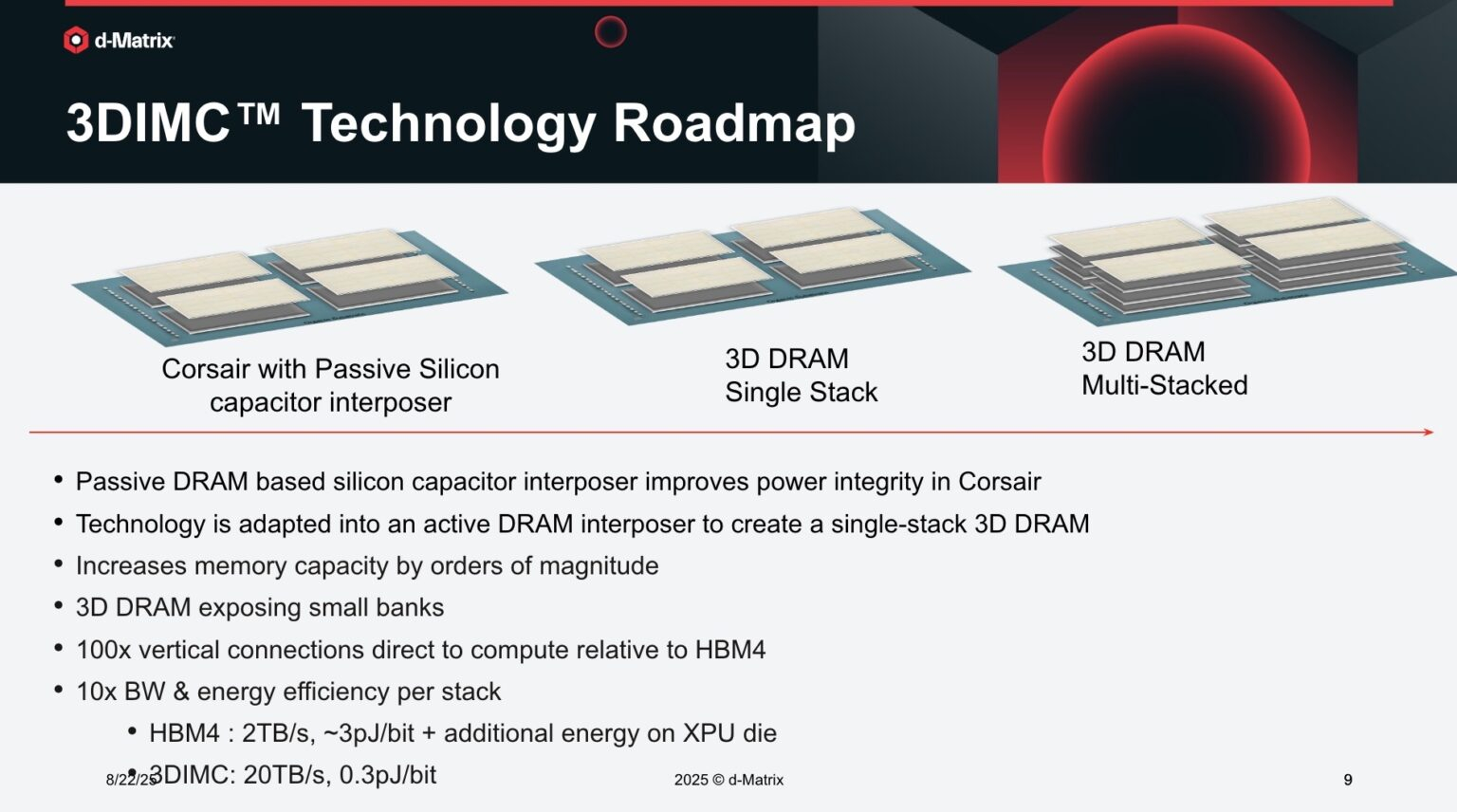 «Наша архитектура следующего поколения Raptor будет включать 3DIMC и опираться на опыт, полученный нами и нашими клиентами в ходе тестирования Pavehawk. Благодаря вертикальному размещению памяти и тесной интеграции с вычислительными чиплетами, Raptor обещает преодолеть барьер в области памяти и выйти на совершенно новый уровень производительности и совокупной стоимости владения», — утверждает Бходжа. Он добавил, что, поставив требования к памяти во главу угла при разработке своих решений — от Corsair до Raptor и далее — компания гарантирует, что инференс будет быстрее, доступнее и стабильнее при масштабировании. d-Matrix провела два раунда финансирования. В раунде A в 2022 году было привлечено $44 млн, а в раунде B в 2023 году – $110 млн, что в общей сложности составляет $154 млн. Компания сотрудничает с поставщиком решений компонуемых систем GigaIO.
06.09.2025 [14:47], Владимир Мироненко
Broadcom получила нового клиента с заказом на $10 млрд — акции взлетели на 15 %Компания Broadcom сообщила результаты III квартала 2025 финансового года, завершившегося 3 августа. Основные показатели компании за квартал превысили прогнозы Уолл-стрит благодаря сохраняющемуся высокому спросу на ИИ-решения. Хок Тан (Hock Tan, на фото ниже), президент и гендиректор Broadcom, которому, согласно поданным в марте в регулирующие органы документам, в этом году исполнилось 73 года, заявил, что намерен возглавлять компанию как минимум ещё пять лет. Как сообщает Reuters, эта новость была позитивно воспринята инвесторами. Ещё больше восторга вызвало заявление Тана о том, что компания получила заказ от нового клиента на разработку и поставку кастомного ИИ-чипа на сумму более $10 млрд, после чего акции компании взлетели в пятницу на 15 %, пишет CNBC. По мнению аналитиков, речь идёт об OpenAI. Это подтвердил со ссылкой на информированные источники ресурс The Financial Times, сообщивший, что новый чип, созданный в результате партнёрства двух компаний, выйдет в 2026 году. 
Источник изображений: Broadcom Ранее в этом году Тан намекал, что у компании в дополнение к трём существующим крупным клиентам есть ещё четыре крупных потенциальных клиента, проявляющих интерес к разработке кастомных ИИ-решений. Хотя Broadcom не раскрывает названия своих крупных клиентов в сфере ИИ-технологий, ещё в прошлом году аналитики утверждали, что это Google, Meta✴ и ByteDance (TikTok). «Один из этих потенциальных клиентов разместил заказ на производство в Broadcom, и мы охарактеризовали его как квалифицированного клиента для XPU», — сообщил, по данным ресурса SiliconANGLE, Тан. Он добавил, что этот заказ стал основанием для повышения прогноза Broadcom по выручке от ИИ-решений в следующем году, когда начнутся поставки. Выручка Broadcom в III финансовом квартале составила $15,95 млрд, превысив на 22 % результат аналогичного квартала годом ранее и консенсус-прогноз аналитиков, опрошенных LSEG, в размере $15,83 млрд. Скорректированная прибыль (Non-GAAP) на акцию равняется $1,69, что выше целевого показателя Уолл-стрит в $1,65 на акцию. Чистая прибыль (GAAP) составила $4,14 млрд или $0,85 на акцию, тогда как годом ранее у компании были убытки в $1,88 млрд или $0,40 на акцию, вызванные единовременным налоговым возмещением в размере $4,5 млрд, связанным с передачей интеллектуальной собственности в США.  Скорректированный показатель EBITDA увеличился на 30 % до $10,70 млрд с $8,22 млрд в прошлом году, составив 67 % выручки. «Свободный денежный поток составил рекордные $7,0 млрд, увеличившись на 47 % по сравнению с аналогичным периодом прошлого года», — отметила в пресс-релизе Кирстен Спирс (Kirsten Spears), финансовый директор Broadcom. Тан сообщил, что выручка от ИИ-продуктов выросла год к году на 63 % до $5,2 млрд, добавив, что в IV финансовом квартале компания ожидает получить выручку по этому направлению в размере $6,2 млрд, «что обеспечит одиннадцать кварталов роста подряд,». Вместе с тем Тан отметил слабость в сегменте полупроводников, не связанных с ИИ: продажи корпоративных решений в области сетей и хранилищ последовательно снизились. Объём продаж группы полупроводниковых решений Semiconductor Solutions составил $9,17 млрд (+26 % г/г), а выручка от инфраструктурного ПО выросла до $6,79 млрд (+17 % г/г) благодаря VMware. В IV финансовом квартале Broadcom ожидает получить выручку в размере $17,4 млрд, что выше прогноза Уолл-стрит в $17,02 млрд. Как сообщает ресурс Converge! Network Digest, Broadcom также ожидает, что рост выручки от ИИ-чипов на уровне около 60 % в годовом исчислении в текущем финансовом году сохранится и в 2026 финансовом году благодаря росту потребности в рабочих нагрузках обучения и инференса. Компания также подтвердила свои предыдущие прогнозы по развёртыванию многомиллионных ИИ-кластеров тремя основными клиентами в 2027 году.
05.09.2025 [11:39], Сергей Карасёв
AMD готовит суперускоритель Mega Pod с 256 ускорителями Instinct MI500Компания AMD, по сообщению ресурса Tom's Hardware, готовит платформу MI500 Scale Up MegaPod для наиболее ресурсоёмких нагрузок ИИ. Эта система, как ожидается, выйдет в 2027 году и составит конкуренцию стоечным решениям NVIDIA следующего поколения. Известно, что в основу MI500 Scale Up MegaPod лягут 64 процессора EPYC поколения Verano и 256 ускорителей серии Instinct MI500. Для сравнения: платформа AMD Helios, выход которой запланирован на 2026 год, сможет объединять до 72 ускорителей Instinct MI400, тогда как в состав системы NVIDIA NVL576 на основе стойки Kyber войдут 144 ускорителя поколения Rubin Ultra. В конструктивном плане MI500 Scale Up MegaPod, согласно имеющейся информации, будет представлять собой платформу с тремя серверными стойками. В боковых разместятся по 32 вычислительных лотка с одним процессором EPYC Verona и четырьмя ИИ-ускорителями Instinct MI500, тогда как центральная стойка получит 18 лотков, предназначенных для коммутаторов UALink. В целом, в состав системы войдут 64 узла, насчитывающих в общей сложности 256 ускорителей. 
Источник изображения: AMD По сравнению с NVIDIA NVL576 со 144 ускорителями новая платформа AMD обеспечит примерно на 78 % больше карт в расчёте на систему. Однако пока не ясно, сможет ли AMD MI500 Scale Up MegaPod превзойти решение NVIDIA по производительности: NVL576, как ожидается, получит 147 Тбайт памяти HBM4, тогда как быстродействие этой системы будет достигать 14 400 Пфлопс на операциях FP4. Отмечается также, что для AMD MI500 Scale Up MegaPod предусмотрено использование исключительно жидкостного охлаждения — как для вычислительных, так и для сетевых узлов. Предполагается, что система поступит в продажу в конце 2027 года — примерно в то же время, когда, вероятно, дебютирует NVIDIA NVL576.
03.09.2025 [09:47], Владимир Мироненко
Гибридный суперчип NVIDIA GB10 оказался технически самым совершенным в семействе BlackwellNVIDIA поделилась подробностями о суперчипе GB10 (Grace Blackwell), который ляжет в основу рабочих станций DGX Spark (ранее DIGITS) для ИИ-задач, пишет ресурс ServeTheHome. 
Источник изображений: NVIDIA via Wccftech Ранее сообщалось, что GB10 был создан NVIDIA в сотрудничестве MediaTek. GB10 объединяет чиплет CPU от MediaTek (S-Dielet) с ускорителем Blackwell (G-Dielet) с помощью 2.5D-упаковки. Оба кристалла изготавливаются по 3-нм техпроцессу TSMC. Как отметил ServeTheHome, GB10 технически является самым передовым продуктом на архитектуре Blackwell на сегодняшний день.  CPU включает 20 ядер на базе архитектуры Armv9.2, которые разбиты на два кластера по десять ядер (Cortex-X925 и Cortex-A725). На каждый кластер приходится 16 Мбайт кеш-памяти L3. Унифицированная оперативная память LPDDR5X-9400 ёмкостью 128 Гбайт подключена напрямую к CPU через 256-бит интерфейс с пропускной способностью 301 Гбайт/с. Объёма памяти достаточно для работы с моделями с 200 млрд параметров.  На кристалле CPU также находятся контроллеры HSIO для PCIe, USB и Ethernet. Для адаптера ConnectX-7 с поддержкой RDMA и GPUDirect выделено всего восемь линий PCIe 5.0, что не позволит работать обоим имеющимся портам в режиме 200GbE. Именно этот адаптер позволяет объединить две системы DGX Spark в пару для работы с ещё более крупными моделями.  G-Die имеет ту же архитектуру, что и B100. Ускоритель оснащён тензорными ядрами пятого поколения и RT-ядрами четвёртого поколения и обеспечивает производительность 31 Тфлопс в FP32-вычислениях. ИИ-производительность в формате NVFP4 составляет 1000 TOPS. Ускоритель подключён к CPU через шину NVLink C2C с пропускной способностью 600 Гбайт/с. G-Die оснащён 24 Мбайт кеш-памяти L2, которая также доступна ядрам CPU в качестве кеша L4, что обеспечивает когерентность памяти между CPU и GPU на аппаратном уровне. 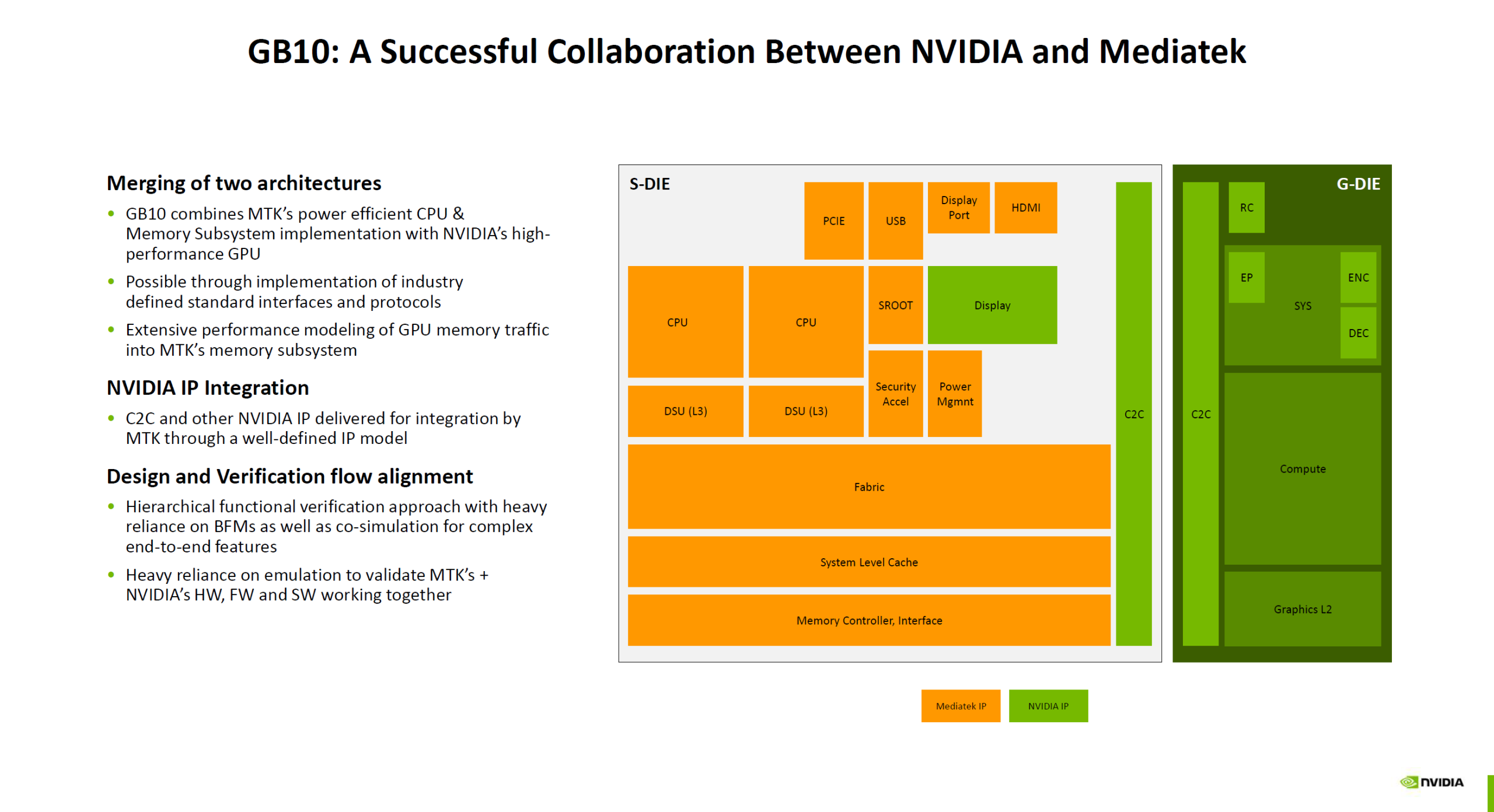 Поддерживается технология SR-IOV, интегрированы движки NVDEC и NVENC. Возможно подключение до четырёх дисплеев: три DisplayPort Alt-mode (4K@120 Гц) и один HDMI 2.1a (8K@120 Гц). Что касается безопасности, есть выделенные процессоры SROOT и OSROOT, а также поддержка fTPM и дискретного TPM (по данным Wccftech). TDP GB10 составляет 140 Вт.
31.08.2025 [15:51], Руслан Авдеев
Alibaba разработала собственный ИИ-ускоритель для инференсаНа фоне нарастающего давления со стороны китайских властей, стремящихся избавиться от зависимости от ИИ-чипов NVIDIA и и других западных аналогов, Alibaba разработала собственный ИИ-ускоритель. В пятницу появились данные, что новейший чип китайского IT-гиганта ориентирован на инференс, сообщает The Register. Подразделения Alibaba T-Head довольно давно работает над собственными ИИ-решениями. В 2019 году он представила вариант Hanguang 800, но в отличие от современных моделей NVIDIA и AMD, он в первую очередь предназначен для классических ML-моделей машинного обучения (таких как ResNet), а не для современных больших языковых моделей (LLM). Утверждается, что новый чип будет справляться с более разнообразными нагрузками. В обозримом будущем для обучения Alibaba, вероятно, будет по-прежнему использовать ускорители NVIDIA. По имеющимся данным, в отличие от ускорителей Huawei Ascend, продукт Alibaba совместим с программной платформой NVIDIA, что позволяет лишь немного переработать используемый код. При этом использование инструментов CUDA не является необходимым для инференса. Alibaba, вероятно, ориентируется на более высокоуровневые варианты вроде PyTorch или TensorFlow. Так или иначе, чип придётся выпускать в Китае из-за санкций США. Кто именно займётся непосредственно выпуском не указывается, но весьма вероятно, что речь идёт о SMIC. Кроме того, Китаю запрещено продавать высокоскоростную память HBM2e и более новые версии — если они уже не интегрированы в готовый ускоритель. Это значит, что Alibaba или будет использовать «медленную» память GDDR или LPDDR, а также накопленные запасы HBM, пока не появятся собственные аналоги. 
Источник изображения: Alibaba Новости об очередных полупроводниках китайского производства появились на фоне призывов китайского правительства не использовать ускорители NVIDIA H20 из соображений безопасности. Впрочем, NVIDIA, которой не так давно вновь разрешили поставлять H20 в Китай, все обвинения решительно отрицает. По некоторым данным, ведётся разработка нового ускорителя семейства Blackwell, специально для Китая. Впрочем, в текущем квартале компания всё равно не рассчитывает на доходы в КНР, поскольку механизмы возобновления продажи и взимания 15-процентной экспортной пошлины ещё не отработаны. Тем временем китайские лидеры ИИ-отрасли ищут альтернативы продуктам компании. DeepSeek переориентировала свои модели на использование нового поколения китайских чипов. Компания не назвала поставщика, но, по некоторым данным, перенести обучение на Ascend не удалось. Впрочем, сама Huawei старается ускорить и инференс. Стартап Enflame, поддерживаемый Tencent, разрабатывает новый ускоритель L600, который получит 144 Гбайт (3,6 Тбайт/с) и поддержку FP8-вычислений. MetaX анонсировала модель C600 со 144 Гбайт HBM3e, но производство, вероятно, будет ограничено имеющимися резервами памяти. Наконец, Cambricon Technologies также работает над собственным ускорителем Siyuan 690, который, как ожидается, будет лучше NVIDIA H100.
27.08.2025 [15:17], Руслан Авдеев
Малайзия анонсировала первый собственный ИИ-ускоритель SkyeChip MARS1000Малайзия анонсировала собственный 7-нм ИИ-ускоритель SkyeChip MARS1000, сообщает Bloomberg. Новый чип — первый в стране ускоритель для периферийных ИИ-вычислений. По данным Ассоциации полупроводниковой промышленности Малайзии (Malaysia Semiconductor Industry Association) этот компонент будет применяться в самых разных устройствах от автомобилей до роботов. Чип для периферийных ИИ-вычислений намного слабее, чем передовые решения компаний вроде NVIDIA, которые стоят за работой ИИ ЦОД, обучением больших ИИ-моделей и др. Тем не менее это ключевой шаг на пути создания передовых технологий в соответствующей сфере. Пока нет данных, где именно будет производиться ускоритель. Малайзия давно стремится стать более значимым игроком в мировой цепочке поставок полупроводников, получая выгоду от бума ИИ. Страна уже давно стала ключевым игроком в области упаковки чипов и является производственным хабом для множества поставщиков IT-оборудования. Местные власти поставили долговременную задачу по развитию разработки микросхем, производства полупроводниковых пластин и строительству дата-центров. Правительство обязалось потратить на рост значимости Малайзии в глобальной цепочке «создания стоимости» не менее RM25 млрд ($6 млрд). 
Источник изображения: CK Yeo/unsplash.com Попутно Малайзия стремится стать региональным IT-хабом на фоне дефицита мощностей и площадей в соседнем Сингапуре. Правда, усилия осложняются позицией руководства США, которое предложило ограничить поставки ИИ-полупроводников в Малайзию и Таиланд, подозревая, что контрабандисты будут использовать эти страны как перевалочные базы для перепродажи ИИ-ускорителей в государства, находящиеся под западными санкциями — в первую очередь, в Китай. Недавно Малайзия приняла меры по ужесточению реэкспорта ИИ-ускорителей, в которых применяются американские технологии. Власти заявили, что «не потерпят» использования своего государства для незаконной (с точки зрения США) торговли. Не так давно они уже объявляли, что китайская Huawei якобы обеспечит создание суверенной ИИ-инфраструктуры в стране, но вскоре новость была опровергнута на высшем уровне, по мнению экспертов — под давлением Соединённых Штатов.
27.08.2025 [14:20], Сергей Карасёв
«Байкал Электроникс» готовит ИИ-чип BE-AI1000 с HBM3E и PCIe 5.0На сайте Государственной информационной системы промышленности (ГИСП) появилась информация о микропроцессоре BE-AI1000, который готовит к выпуску российская компания «Байкал Электроникс». Чип представляет собой «систему на кристалле», предназначенную для применения в качестве специализированного ускорителя для задач ИИ. Изделие выполнено в корпусе с размерами 55 × 55 мм (1738 выводов) по технологии «кремний на сапфире». Применяется литография EBL (E-Beam Lithography). Тактовая частота достигает 3,2 ГГц; реализована системная шина с когерентным кешем L2 в объёме 32 Мбайт. Процессор использует память HBM3E ёмкостью до 512 Гбайт с пропускной способностью до 2 Тбайт/с. Упомянуты четыре периферийных таймера и поддержка GPIO с возможностью реконфигурации (UART, QSPI, eSPI, I2C/SMBus). Могут быть использованы до 120 линий PCIe 5.0, а также интерфейсы USB 3.0 и 10GbE. Говорится о поддержке RoCE (RDMA over Converged Ethernet). Потребляемая мощность составляет 200 Вт. 
Источник изображения: ГИСП Основной сферой применения чипа названа серверная инфраструктура, ориентированная на обучение больших языковых моделей (LLM) и инференс. Ключевыми преимуществами изделия заявлены отечественное происхождение, энергоэффективность, контролируемый стек программного обеспечения, а также использование оригинальных технологических подходов, дающих низкую себестоимость по сравнению с зарубежными конкурирующими решениями. Код изделия по ОКПД 2 — «26.11.3. Схемы интегральные электронные». Код по ТН ВЭД — «8542 31. Схемы электронные интегральные: процессоры и контроллеры, объединенные или не объединенные с запоминающими устройствами, преобразователями, логическими схемами, усилителями, синхронизаторами или другими схемами».
24.08.2025 [23:18], Сергей Карасёв
NeuReality готовит чип NR2 для оркестрации инференсаКомпания NeuReality раскрыла предварительную информацию об изделии NR2 — чипе второго поколения, предназначенном специально для оркестрации инференса. Изделие представляет собой более эффективную альтернативу связке CPU и NIC в высокопроизводительных системах ИИ. Чип первого поколения NR1 дебютировал в июне нынешнего года. Изделие может применяться в связке с любым GPU или ИИ-ускорителем. При этом, как утверждается, NR1 позволяет повысить эффективность использования GPU почти до 100 % по сравнению со средним показателем в 30–50 % при традиционном сочетании CPU и NIC в современных серверах. В состав NR1 входят четыре декодера видео/изображений, 16 DSP для аудио/речи, 16 векторных DSP общего назначения, два порта 10/25/50/100GbE и пр. Характеристики NR2 на данный момент полностью не раскрываются. Известно, что в основу решения положена платформа Arm Neoverse Compute Subsystems (CSS) V3. Чип может объединять до 128 ядер, оптимизированных для масштабных рабочих нагрузок обучения моделей ИИ и инференса. По сравнению с оригинальной версией в NR2 реализована более глубокая интеграция между CPU-блоком и NIC для координации ИИ-моделей в реальном времени, дезагрегации на основе микросервисов, потоковой передачи токенов, оптимизации KV-кеша и оркестровки. 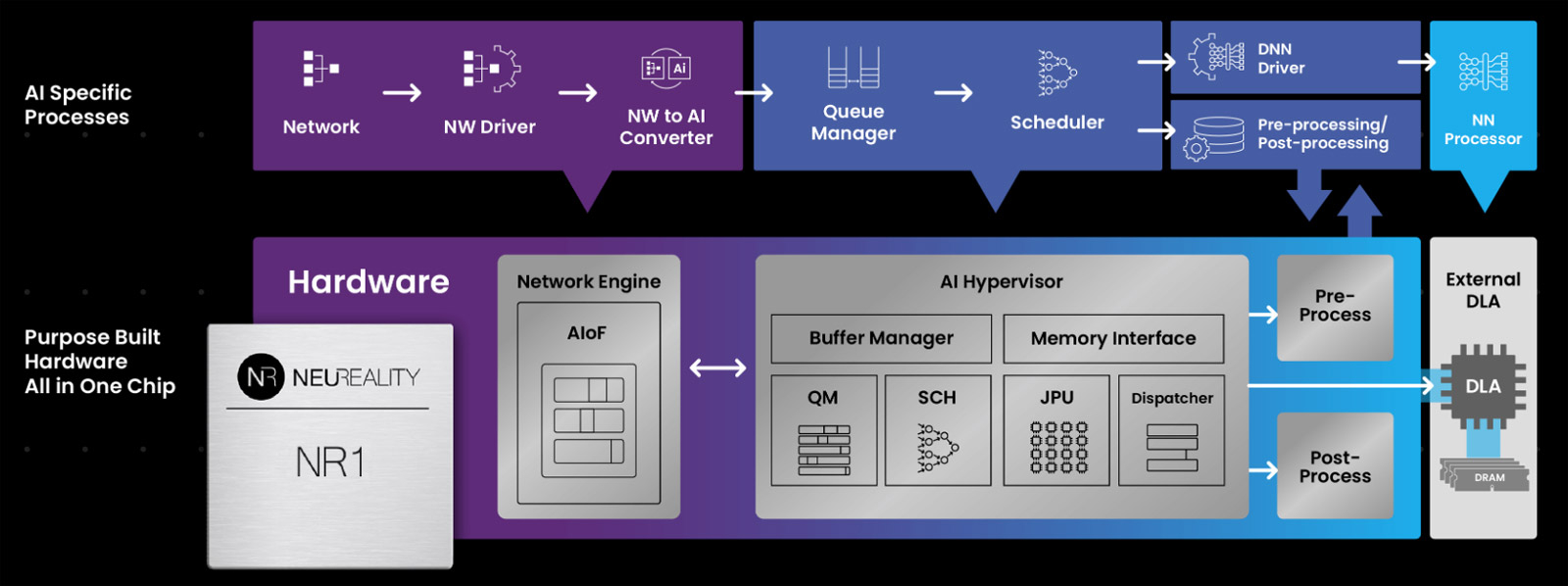
Источник изображения: NeuReality В целом, как отмечает NeuReality, чипы серии NR представляют собой качественно новый класс изделий, способных управлять рабочими нагрузками инференса с непревзойдённой эффективностью. Гипервизор ИИ в сочетании с ядрами Arm Neoverse обеспечивает оптимальную оркестровку и максимальную загрузку доступных ресурсов.
19.08.2025 [23:10], Руслан Авдеев
NVIDIA готовит для Китая урезанный ИИ-ускоритель на архитектуре BlackwellNVIDIA работает над новым ИИ-ускорителем, предназначенным специально для китайского рынка. Модель на основе новейшей архитектуры Blackwell будет мощнее модели H20, допущенной для продаж в КНР, сообщает Reuters со ссылкой на осведомлённые источники. Как сообщают источники, новый чип, предварительно названный B30A, будет представлять собой однокристальную систему, которая, вероятно, обеспечит половину чистой вычислительной мощности флагманской модели NVIDIA B300 на двух кристаллах. Новый чип получит высокоскоростную память и поддержку технологии NVIDIA NVLink. Впрочем, эти функции имеются и в H20, основанном на устаревшей архитектуре Hopper. Источники сообщают, что окончательные характеристики чипа не определены, но NVIDIA рассчитывает предоставить китайским клиентам образцы для тестирования уже в следующем месяце. Компания подчёркивает, что рассматривает выпуск различных продуктов в той мере, в какой это позволяет американское правительство. Всё, что предлагается, одобрено компетентными органами и предназначено исключительно для коммерческого использования. В прошлом году на долю Китая пришлось 13 % выручки NVIDIA, поэтому глава компании Дженсен Хуанг (Jensen Huang) жёстко раскритиковал американские запреты. Ускоритель H20 был разработан специально для КНР ещё в 2023 году, но в апреле 2025 года он попал под санкции. AMD также разработала для Китая ослабленные ускорители MI308, которые тоже попали под санкции. Теперь уже сам Китай говорит, что H20 может представлять опасность для национальной безопасности и призывает отказаться от использования этих чипов. 
Источник изображения: Boudewijn Huysmans/unsplash.com На прошлой неделе США допустили возможность продажи в Китай урезанных чипов нового поколения. Информация появилась после сделки, в результате которой NVIDIA и AMD будут отдавать правительству США 15 % выручки от продаж ИИ-ускорителей в Китае. По данным CNBC, Трамп заявлял, что сначала он рассчитывал на 20 %, но позже согласился и на меньшее. Тем не менее, американские парламентарии обеспокоены продажей даже ослабленных чипов в Китай. Предполагается, что это помешает США добиться мирового лидерства в сфере ИИ. NVIDIA и другие компании уверены, что интерес Китая к американской продукции необходимо сохранить, иначе бизнесы из Поднебесной перейдут на продукцию местных конкурентов. Ранее сообщалось, что NVIDIA готовит для Китая чипы на архитектуре Blackwell, предназначенные для инференса. В мае Reuters сообщало, что ускоритель на базе RTX6000D (возможно, B30/B40) будет дешевле H20. Он разработан с учётом ограничений, введённых американскими властями, и использует обычную память GDDR с пропускной способностью 1398 Гбайт/сек, т.е. чуть ниже установленного регуляторами «экспортного» порога в 1,4 Тбайт/с — якобы именно из-за этого H20 и попал под запрет. Один из источников сообщает, что поставки небольших партий в Китай NVIDIA намеревается начать уже в сентябре 2025 года.
16.08.2025 [15:16], Сергей Карасёв
Inspur представила суперускоритель Metabrain SD200 для ИИ-моделей с триллионами параметровКитайская компания Inspur создала суперускоритель Metabrain SD200 для наиболее ресурсоёмких задач ИИ. Система, как утверждается, может работать с моделями, насчитывающими более 1 трлн параметров. Платформа Metabrain SD200 объединяет 64 карты в единый суперузел с унифицированной памятью. В основу положены открытая архитектура 3D Mesh и проприетарные коммутаторы Open Fabric Switch. Иными словами, ускорители на базе GPU, распределённые по разным серверам, объединяются посредством высокоскоростного интерконнекта в единый домен. Суперускоритель предоставляет доступ к 4 Тбайт VRAM и 64 Тбайт основной RAM. Благодаря этому возможен одновременный запуск четырёх китайских ИИ-моделей с открытым исходным кодом, включая DeepSeek R1 и Kimi K2. Кроме того, поддерживается совместная работа нескольких ИИ-агентов в режиме реального времени. 
Источник изображения: Inspur Для Metabrain SD200 заявлена низкая задержка при передаче данных, которая исчисляется «сотнями наносекунд». В распространённых сценариях инференса, предполагающих обработку небольших пакетов данных, по величине задержки система превосходит распространённые отраслевые решения. В составе новой платформы задействованы средства оптимизации. В частности, инструмент Smart Fabric Manager автоматически формирует оптимальные маршруты данных на основе характеристик нагрузки. Metabrain SD200 совместим с распространёнными фреймворками, такими как PyTorch, vllm и SGLang: благодаря этому возможен быстрый перенос существующих моделей и ИИ-агентов без необходимости переписывать программный код с нуля. Таким образом, значительно снижается стоимость миграции. В целом, реализованная технология удалённого vGPU позволяет ускорителям, распределённым по разным серверам, взаимодействовать столь же эффективно, как если бы они находились на одном хосте. При этом достигается восьмикратное расширение адресного пространства, что обеспечивает полную загрузку ресурсов и эффективную работу даже при использовании ИИ-моделей с триллионами параметров. |
|

