Материалы по тегу: ии
|
21.04.2026 [19:38], Руслан Авдеев
Google и CoreWeave взялись за «мусорные» облигации на миллиарды долларовПоддерживаемая Google рекордная сделка по привлечению инвестиций и дополнительная продажа облигаций компанией CoreWeave обеспечили новое вливание в индустрию ИИ, на этот раз в объёме $6,7 млрд, сообщает Bloomberg. При это речь идёт о высокодоходных, но высокорисковых «мусорных» облигациях. Связанная с Google сделка под руководством Morgan Stanley оценивается в $5,7 млрд, хотя общая сумма заявок от всех желающих составила $19 млрд. Средства пойдут на строительство двух дата-центров в кампусе Meridian Arc HoldCo в округе Салливан (Sullivan, Индиана). Мощности ЦОД будут сданы в аренду неооблаку Fluidstack, а сама сделка поддерживается Google. Тем временем провайдер облачной инфраструктуры CoreWeave продал новый пакет облигаций на сумму $1 млрд под 9,75 % с погашением в 2031 году, всего через неделю после предыдущего размещения ценных бумаг на $1,75 млрд. По данным Datacenter Dynamics, в марте 2026 года CoreWeave получила взаймы $8,5 млрд для поддержки закупок ИИ-ускорителей для Meta✴. Неооблачный провайдер наращивает свою долговую нагрузку для расширения инфраструктуры, к концу 2025 года совокупный долг компании составил $21,6 млрд. Ранее в текущем году она получила $2 млрд инвестиций от NVIDIA. 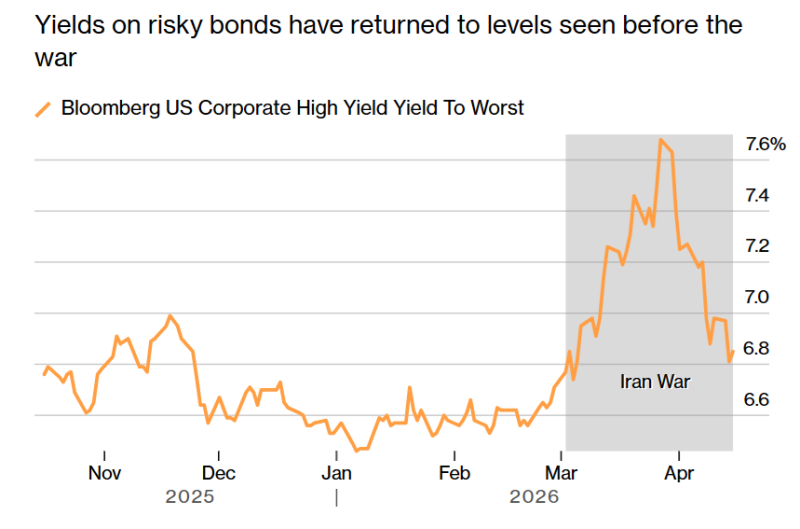
Источник изображения: Bloomberg Быстрое распространение ИИ вызвало беспрецедентный дефицит свободных мощностей ЦОД, ИИ-ускорителей и электроэнергии для обеспечения их работы. Для финансирования компании буквально воюют за все доступные на рынке средства от «мусорных» облигаций до проектного финансирования. За последние недели резиденты Уолл-Стрит обеспечили финансирование на десятки миллиардов долларов, даже несмотря на то, что конфликт на Ближнем Востоке заставил некоторых потенциальных участников снизить активность. Но по мере того как у многих растёт оптимизм относительно перспектив долгосрочного мира, стоимость заёмных средств для компаний всех типов постепенно снижается. Meridian Arc HoldCo представляет собой совместное предприятие Next Frontier и Fluidstack, именно оно выпустило пятилетние облигации для финансирования ЦОД в Индиане; компания поддерживается Google. Заём на $5,7 млрд с доходностью 6,25 % — это крупнейший выпуск высокодоходных облигаций в США, связанных с ИИ. Кроме того, это крупнейшая сделка такого рода, организованная единственной финансовой структурой с Уолл-Стрит. Размещение завершилось всего через день после старта официальной маркетинговой компании. Размещение побило собственный рекорд Morgan Stanley. Ранее рекордным считалось размещение облигаций в интересах криптомайнера TeraWulf в 2025 году на $3,2 млрд, также поддержанное Google и сделанное в интересах Fluidstack. Fluidstack занимается строительством высокопроизводительной вычислительной инфраструктуры, в этой сфере наблюдается бум на фоне взрывного развития ИИ-проектов. Недавно компания анонсировала сделку с Anthropic на $50 млрд, предусматривающую строительство кастомных ЦОД для разработчика ИИ-моделей. В феврале 2026 года Google привлекла со помощью облигаций $32 млрд для поддержки растущих капитальных расходов. Техногигант рассчитывает, что последние составят в 2026 году $185 млрд, большая доля которых пойдёт на ЦОД и ИИ-инфраструктуру. Кроме того, Google снова поддержала Fluidstack, купив облигации на $1,3 млрд.
21.04.2026 [18:29], Руслан Авдеев
Глава Microsoft пообещал досрочно ввести в эксплуатацию самый мощный в мире ИИ ЦОД проекта FairwaterМногоцелевой ИИ-кампус Microsoft Fairwater в Висконсине строится ускоренными темпами и будет введён в эксплуатацию раньше запланированного срока, сообщает Datacenter Dynamics. Об этом на днях упомянул глава Microsoft Сатья Наделла (Satya Nadella). По его словам, это самый мощный в мире ИИ ЦОД, объединяющий «сотни тысяч» NVIDIA GB200, а оптоволокна в нём хватит, чтобы «обернуть планету четыре раза». Пока нет данных, готова ли уже площадка Fairwater к эксплуатации или просто будет сдана несколько раньше. О том, что кампус в городке Маунт-Плезант (Mount Pleasant) будет вот-вот достроен, сообщалось ещё осенью 2025 года. Тогда же компания объявила, что суммарные инвестиции в площадку в течение нескольких лет составят $7,3 млрд. Строительство началось ещё в 2023 году на территории производственной площадки Foxconn. Первоначально планировалось застроить более 127 га. Впоследствии компания получила разрешение застроить ещё 405 га, а чуть позже она купила за $43 млн ещё 65 га. В январе 2026 года Microsoft дано разрешение на строительство на территории кампуса ещё 15 зданий ЦОД. На данный момент Fairwater включает три больших объекта общей площадью около 11,5 тыс. м2. Для строительства понадобилось 74,9 км глубоких свай для фундамента, более 12 тыс. т строительной стали, 193 км подземного кабеля среднего напряжения и 116,8 км трубопроводов. 
Источник изображения: Microsoft Похожий кампус Fairwater в Атланте (Джорджия) заработал в ноябре 2025 года, он будет напрямую связан с кампусом в Висконсине. Есть и планы строительства ЦОД в Лидсе (Leeds, Великобритания). По имеющимся данным компания, «близка» к получению разрешения на строительство в Западном Йоркшире. Кампус планируется построить на территории бывшей электростанции, он будет включать три трёхэтажных ЦОД (LBA10, 11 и 12) объекта площадью около 39 тыс. м2 каждый. Также на территории комплекса разместится электроподстанция. Строительство может стартовать в начале 2027 года.
21.04.2026 [11:19], Сергей Карасёв
Anthropic получит от AWS до 5 ГВт ИИ-мощностей и до $25 млрд инвестицийКомпании Anthropic и Amazon объявили о расширении сотрудничества в области облачной инфраструктуры и технологий ИИ. В рамках партнёрства Anthropic получит до 5 ГВт мощностей в инфраструктуре AWS для обучения и поддержания работы своих передовых ИИ-моделей семейства Claude. В ответ Amazon инвестирует в Anthropic дополнительные $5 млрд, а в будущем — ещё до $20 млрд в зависимости от достижения определённых коммерческих целей. Ранее Amazon уже вложила $8 млрд в Anthropic. Отмечается, что Anthropic и Amazon тесно работают с 2023 года. В настоящее время более 100 тыс. клиентов используют модели Claude на платформе Amazon Bedrock. Партнёры также запустили Project Rainier — крупнейший в истории AWS и один из самых масштабных вычислительных кластеров в мире. На сегодняшний день Anthropic использует более 1 млн ускорителей AWS Trainium2 для обучения и обслуживания Claude. В рамках расширенного соглашения Anthropic обязуется потратить более $100 млрд в течение следующих десяти лет на вычислительные мощности AWS. Речь идёт об использовании изделий Trainium текущих и будущих поколений, включая Trainium4. Кроме того, будут использоваться «десятки миллионов» ядер Graviton. В общей сложности это даст до 5 ГВт вычислительной мощности. Так, к концу 2026 года будет введено в эксплуатацию около 1 ГВт ресурсов на базе Trainium. 
Источник изображения: Amazon Договор предполагает использование дата-центров в Азии и Европе, что поможет повысить качество обслуживания растущей международной клиентской базы Claude. При этом пользователи смогут получить доступ к полнофункциональной консоли Claude (биллинг, безопасность, управление) непосредственно в облаке AWS — без необходимости управления дополнительными учётными данными или контрактами. Нужно отметить, что Anthropic сотрудничает и с другими поставщиками облачных услуг. В частности, недавно компания объявила о расширении использования инфраструктуры Google Cloud, а также ускорителей Google TPU. Кроме того, Anthropic взяла на себя обязательство приобрести вычислительные мощности Microsoft Azure стоимостью $30 млрд и заключить контракт на поставку дополнительных мощностей объёмом до 1 ГВт.
21.04.2026 [08:49], Руслан Авдеев
Испанцы разрабатывают аппаратный «стоп-кран» для защиты от бэкдоров в зарубежных чипахНа фоне изменчивой геополитической обстановки и сопутствующих проблем Национальный центр суперкомпьютерных вычислений Барселоны (Barcelona Supercomputing Center, BSC) совместно с Политехническим университетом Каталонии (Politècnica de Catalunya, UPC) запустили проект Safe and Secure Technologies, сообщает EE Times. Он предназначен для разработки безопасных чипов для критической инфраструктуры и экстренных служб. Проект обеспечит разработки для сфер, в которых сбои в работе оборудования и угрозы безопасности могут иметь серьёзные последствия. В числе прочего это касается энергосетей, автомобильной промышленности, железнодорожного транспорта, телеком-сектора, гражданской обороны и др. ЕС стремится снизить зависимость от внешних технологий, поэтому Safe and Secure Technologies должен поспособствовать достижению технологического суверенитета. В компании заявляют, что уязвимость часто заключается не в доступности оборудования, а в его происхождении. Проблема в том, что Европа в контексте чипов для критически важных систем во многом зависит от технологий из США, Тайваня и Юго-Восточной Азии в целом. Предполагается, что при определённых условиях сторонние игроки могут, например, использовать недокументированный бэкдор для полного отключения энергосистемы и др. 
Источник изображения: Barcelona Supercomputer Center Акцент в проекте сделан не на создании собственных уникальных решений, а на прозрачности, позволяющей полностью проверить безопасность продуктов. Основным аппаратным компонентом проекта станет т.н. «остров безопасности» (Safety Island), созданный на основе наработок европейских программ De-RISC, SELENE, ISOLDE и FRACTAL — интегрированный модуль обеспечения безопасности. Этот компонент будет устанавливаться в непосредственной близости от процессора и гарантирует, что устройство будет работать в соответствии со спецификации, необходимыми пользователю. Фактически модуль контролирует работу основного процессора, отслеживает выполнение им задач в режиме реального времени и распределение ресурсов. Если эти условия не соблюдаются, модуль способен или сам принять меры, или инициировать прерывание, чтобы ПО или операционная система отреагировали на него в соответствии с пользовательскими запросами. Заявлено, что разработанное «железо» может выйти из строят только в исключительных обстоятельствах. В этому случае оно распознаёт ситуацию и контролируемым образом прерывает исполнение до того, как остальная система получит ошибочные инструкции. 
Источник изображения: Barcelona Supercomputer Center Разработка Safe and Secure Technologies ориентирована в первую очередь на интеграцию с продуктами на базе RISC-V, но в целом «ядро», предназначенное для размещения в хост-процессоре, можно интегрировать и с чипами Intel, Arm и AMD. Учитывая будущие нормативные требования и требования к безопасности продуктов, компания намерена поддерживать передовые стандарты криптографии. Строго говоря, продукт не является «криптографическим чипом как таковым», поскольку в его задачи входит контроль над функциями безопасности, но в будущем по запросу клиентов можно добавить даже поддержку «квантовой криптографии». У компании не будет собственных производственных мощностей, основное внимание она будет уделять проектированию, а собственно выпуск поручат контрактным производителям. Сейчас проект работает над привлечением капитала, чтобы поменьше зависеть от государственных субсидий. Хотя возможности для государственного финансирования открыты, они не являются основным драйвером разработок. Переговоры с инвесторами продолжаются, ожидается, что в конечном итоге численность персонала составит несколько десятков человек. Выход на рынок будет зависеть от капитализации, начать работы планируется через 6-12 месяцев, после чего возможно значительное ускорение. Safe and Secure Technologies — уже пятнадцатый проект, «отпочковавшийся» от BSC. Ранее коммерческие предприятия центра уже привлекли €44 млн частного капитала и наняли более 600 специалистов. В феврале сообщалось, что BSC уже активно участвует в гонке за обретением Европой технологического суверенитета. Первый европейский суверенный RISC-V-процессор Cinco Ranch изготовлен по техпроцессу Intel 3. В этом приняла непосредственное участие Лаборатория суперкомпьютерных вычислений (BZL) центра BSC-CNS, а в апреле появилась информация, что процессор готов к началу массового производства.
20.04.2026 [19:29], Сергей Карасёв
AMD поможет в развитии экосистемы ИИ во ФранцииКомпания AMD и власти Франции объявили о расширении сотрудничества в области ИИ. Соответствующий документ подписан в Париже в Министерстве экономики, финансов, промышленности, энергетики и цифрового суверенитета. Речь идёт о реализации Национальной стратегии Франции в области ИИ. Многолетнее сотрудничество с AMD направлено на укрепление местной экосистемы ИИ посредством развития соответствующей вычислительной инфраструктуры, организации исследовательских и образовательных программ. В частности, AMD планирует предоставлять учёным, разработчикам и стартапам оборудование, необходимое ПО и экспертную поддержку в рамках своих инициатив AMD University Program, AMD AI Developer Program и AMD AI Academy. Ещё одним направлением работ станет углубление взаимодействия между AMD, французским национальным агентством высокопроизводительных вычислений (GENCI), французско-нидерландским Консорциумом Жюля Верна и Французской комиссией по альтернативным источникам энергии и атомной энергии (CEA). Стороны реализуют проект суперкомпьютера Alice Recoque — второй в Европе НРС-системы экзафлопсного класса после JUPITER. Ранее сообщалось, что в основу Alice Recoque войдут серверы с 256-ядерными процессорами AMD EPYC Venice и ускорителями Instinct MI430X (432 Гбайт HBM4). Монтаж системы стоимостью более €550 млн начнётся в 2026 году. 
Источник изображения: AMD В рамках проекта Alice Recoque планируется создание Центра передового опыта (Center of Excellence), который обеспечит экспертные знания, обучение и поддержку для максимально эффективного использования ресурсов нового суперкомпьютера. Появление центра также будет способствовать развитию более широкой экосистемы ИИ-фабрик во Франции.
20.04.2026 [17:38], Владимир Мироненко
Ещё капельку: XPO-модули повысят плотность сетей в ИИ ЦОД, но CPO всё равно не избежатьЭкосистема XPO (eXtra-dense Pluggable Optics) набирает обороты после презентации на OFC 2026, поскольку производители объединяются вокруг нового формата подключаемых 12,8-Тбит/с модулей, разработанного для ИИ-инфраструктуры, сообщил ресурс Converge Digest. Инициатива, возглавляемая Arista Networks и поддерживаемая растущей группой поставщиков оптических и кремниевых компонентов, ориентирована на следующее поколение ИИ-кластеров, где плотность портов, полоса пропускания и тепловые ограничения будут основными факторами, ограничивающими производительность. Модуль XPO помещает 64 200G-канала (224 Гбит/с PAM4) в то же пространство, что и два модуля OSFP. В 1OU помещается 16 модулей XPO, что даёт 204,8 Тбит/с на юнит или 6,5 Пбит/с на ORv3-стойку. Это примерно вчетверо больше в сравнении 1.6T-модулями OSFP 1,6T, сообщил ресурс The Next Platform. XPO поддерживает интегрированное жидкостное охлаждение (водоблок), позволяет использовать любые типы оптики, а также предлагает значительное повышение отказоустойчивости. XPO поддерживает оптические стандарты SR, DR, FR, LR и ZR/ZR+, а также совместим с LPO. 
Источник изображений: Arista Networks По словам Андреаса Бехтольсхайма (Andreas Bechtolsheim), соучредителя и главного архитектора Arista, в ИИ ЦОД мощностью 400 МВт с 1024 стойками, в каждой из которых размещено по 128 GPU, из расчёта 12,8 Тбит/с на вертикальное масштабирование и 1,6 Тбит/с для горизонтального масштабирования на каждый GPU при использовании коммутаторов с OSFP плотностью 1,6 Пбит/с на стойку потребуется более 1400 стоек. XPO позволит сократить количество стоек на 75 %, попутно сэкономив 44 % площади ЦОД.  Бехтольсхайм отметил, что крупные ИИ ЦОД будут охлаждаться жидкостью, и коммутаторы, используемые в них, также должны изначально поддерживать СЖО. Он допустил, что можно добавить охлаждающие пластины с жидкостным охлаждением на модули OSFP с плоской верхней панелью, но это не улучшит существенно тепловые характеристики. В случае XPO водоблок интегрируется внутрь модуля и способен отводить более 400 Вт как от маломощных, так и высокопроизводительных модулей, таких как 8×1.6T-ZR/ZR+, утверждает Бехтольсхайм.  Еще одно дополнительное преимущество заключается в том, что при жидкостном охлаждении компонентов XPO они работают с температурой на 20–25 °C ниже в ZR-модуле на 12,8 Тбит/с, чем в модуле OSFP-ZR на 1,6 Тбит/с с воздушным охлаждением. Кроме того, модули XPO конструктивно значительно проще, чем модули OSPF, что также повышает надёжность. «Каждая 32-канальная плата имеет только один микроконтроллер и один набор преобразователей напряжения, что на 75 % меньше общих компонентов по сравнению с четырьмя модулями OSPF», — сообщил Бехтольсхайм.  Вместе с тем повышение плотности размещения ведёт и к повышению энергопотребления. По оценкам Arista, 1,6-Пбит/с стойка с OSFP потребляет порядка 32 кВт, тогда как 6,5-Пбит/с XPO-стойка требует уже 128 кВт. Однако XPO-модули рассчитаны на питание 48/50 В DC непосредственно от общей шины всей стойки и уже сами отдают трансиверам 3,3 В, что способствуют упрощению всей конструкции, повышению компактности и снижению энергопотерь.  Arista объявила о заключении многостороннего соглашения (MSA) на поставку XPO, к которому присоединились около 45 ведущих поставщиков оптических модулей, включая Lightmatter, Eoptolink Technology и TeraHop. Ожидается, что серийное производство XPO начнётся в 2027 году. Впрочем, XPO можно рассматривать как временное решение до начала действительно массового внедрения интегрированной оптикой (CPO).
20.04.2026 [17:14], Андрей Крупин
Релиз российской облачной платформы KeyStack 2026.1: расширенная Enterprise-функциональность и архитектура Secure by DefaultКомпания «Ключевые ИТ-решения» (ITKey) объявила о выходе релиза KeyStack 2026.1 — платформы для построения частных и публичных облаков в корпоративном и государственном сегментах. Ключевой особенностью KeyStack версии 2026.1 стало использование OpenStack Epoxy как базового слоя. Это обеспечило продукту поддержку технологии GPU passthrough (прямое подключение к GPU-устройству) для ИИ-нагрузок без дополнительных расходов ресурсов гипервизора, поддержку OVN Southbound Relay для построения масштабируемых SDN-сетей между географически распределёнными центрами обработки данных, а также возможность обновления программного комплекса без остановки сервисов. Дополнительно платформа получила ряд доработок, усиливающих контроль, мониторинг и безопасность облачной инфраструктуры. В KeyStack 2026.1 реализован сквозной аудит с передачей реального IP-адреса пользователя в SIEM, детализированная история операций в AdminUI с возможностью фильтрации и экспорта, централизованный планировщик задач, а также механизм резервного копирования с автоматической проверкой восстановления и SHA256-валидацией. 
Основные компоненты, на которых базируется KeyStack (источник изображения: keystack.ru) Отдельное внимание специалистами ITKey было уделено интеграции с системами Prometheus, Grafana и AlertManager, позволяющими расширить возможности мониторинга облачных сред и оптимизировать потребление вычислительных ресурсов. С точки зрения информационной безопасности в новой версии платформы реализован комплексный подход Secure by Default, подразумевающий использование строгих настроек и протоколов сразу после установки платформы. В систему встроены механизмы автоматической ротации mTLS-сертификатов и учётных данных, контроль выполнения задач через белые списки, а также сквозной аудит в формате CADF. Это снижает риски утечек данных, несанкционированных действий и ошибок эксплуатации без усложнения управления системой. По словам разработчика, новая функциональность KeyStack ориентирована на крупные организации с распределённой IT-инфраструктурой и повышенными требованиями к надёжности и защите данных. В числе таковых называются банки, государственные структуры, телеком-операторы, ритейл и промышленные предприятия.
20.04.2026 [10:46], Руслан Авдеев
Еврокомиссия выбрала поставщиков суверенных облачных услуг, которые разделят €180 млнЕврокомиссия отобрала поставщиков облачных услуг на сумму €180 млн ($212 млн). В октябре 20265 года она объявила тендер на предоставление локальных сервисов, способных обеспечить суверенные облачные услуги сроком на шесть лет агентствам и ведомствам ЕС, сообщает Datacenter Dynamics. На днях Еврокомиссия сообщила о заключении контракта с Post Telecom (при участии партнёров CleverCloud и OVHcloud), StackIT, Scaleway и Proximus, взаимодействующей с S3NS, Clarence и Mistral. Сделка должна поддержать «более масштабные усилия Еврокомиссии по укреплению собственного суверенитете, укреплению стратегического контроля над ключевыми технологиями и инфраструктурой». Соглашение о поставке услуг заключены с учётом стратегических, юридических, операционных и экологических соображений. Кроме того, в расчёт принималась прозрачность цепочки поставок, технологическая открытость, безопасность и соответствие законодательству Евросоюза. Сейчас Еврокомиссия завершает разработку обновлённого варианта Cloud Sovereignty Framework — рамочной программы обеспечения суверенитета облачных технологий, включающей поддающиеся контролю критерии оценки суверенитета. Параллельно комиссия внедряет критерии внутри собственных структур, чтобы оценивать и укреплять суверенитет цифровых сервисов, используемых её департаментами и иными ведомствами Евросоюза. 
Источник изображения: George Liapis/unsplash.com Как заявили в Scaleway, на каждый €1, потраченный вместе с компанией, €0,68 реинвестируется в Европейскую экономику, тогда как в случае с международными гиперскейлерами речь идёт лишь о €0,20. При этом европейские поставщики облачных услуг вкладывают средства в местные проекты и гарантируют, что активы, опыт и инновации останутся в Европе. При этом ситуация с импортозамещением остаётся печальной — доля локальных облачных игроков не европейском рынке годами остаётся на уровне 15 %, и никакие инициативы не помогли увеличить её. В последние годы вопросы цифрового суверенитета обсуждаются всё активнее, особенно в европейском государственном секторе. Многие местные правительства нередко зависят от американских облачных провайдеров, их данные подпадают под действие Закона об облачных технологиях (CLOUD Act), позволяющего американским властям запрашивать у американских компаний доступ к любым данным в их хранилищах. В 2025 году Microsoft признала, что не может обеспечить настоящий суверенитет данных в Европе. Впрочем, Google, AWS и Microsoft неоднократно пытались заверить клиентов из Европы в суверенитете их данных. Также Еврокомиссия готовит пакет Tech Sovereignty — он включает стратегию, касающуюся Open Source-разработок, закон Chips Act 2, план Strategic Roadmap for Digitalisation and AI in Energy, а также закон Cloud and AI Development Act (CADA), посвящённый развитию облаков и ИИ. Последний предполагает «гармонизацию» понятий суверенитета для облаков и ИИ-сервисов означает на едином рынке. Предполагается расширить возможности для суверенных облачных предложений, в том числе через госзакупки, а также поддержать выход на рынок расширенного круга поставщиков облачных и ИИ-сервисов. UPD 21.04.2026: к списку поставщиков облачнух услуг присоединились DEEP (POST Luxembourg Group), OVHcloud и Clever Cloud.
20.04.2026 [09:00], Сергей Карасёв
ФГУП «ГлавНИВЦ» развивает сотрудничество с российским разработчиком «Базис»ФГУП «ГлавНИВЦ» Управления делами Президента Российской Федерации подписал соглашение о сотрудничестве с компанией «Базис». Соглашение позволит сформировать дополнительные возможности по использованию решений экосистемы разработчика при создании специализированных отраслевых продуктов. Новые отраслевые продукты ФГУП «ГлавНИВЦ» планируется разработать для подведомственных организаций Управления делами Президента РФ. Они должны учитывать единые требования к безопасности и управляемости ИТ-инфраструктуры. ФГУП «ГлавНИВЦ» Управления делами Президента РФ развивает сотрудничество с «Базис» и анализирует технологические решения на основе экосистемы программных продуктов для управления динамической ИТ-инфраструктурой. В рамках соглашения ГлавНИВЦ получит доступ к экспертизе «Базиса» с целью развития собственной линейки продуктов и услуг. Партнёрство предусматривает сопровождение решений на всём жизненном цикле — от проектирования и внедрения до дальнейшего развития и эксплуатации. Это возможность ускорить создание специализированных продуктов и обеспечить более высокий уровень технологической независимости и отказоустойчивости инфраструктуры организация, относящихся к Управлению делами Президента РФ. В периметр Управления делами Президента РФ входят учреждения различного профиля, в том числе медицинские, санаторно-курортные, научные, образовательные, культурные, транспортные и гостиничные организации. Такой состав требует гибкого подхода к построению цифровой инфраструктуры: с одной стороны, с учётом отраслевой специфики, с другой — с соблюдением единых требований к стабильности, защищённости и централизованному администрированию. 
Источник изображения: «Базис» / Денис Насаев «Сотрудничество с "Базисом" позволит расширить инструментарий зрелых отечественных решений, которые служат технологической подосновой для интеграции в продуктовую линейку ГлавНИВЦ. Для нас принципиально важно унифицировать инфраструктурные подходы, адаптировать и развивать продукцию ГлавНИВЦ под конкретные отраслевые сценарии применения с учётом государственной специфики. Это даёт основу для более эффективного масштабирования, сопровождения и дальнейшего развития широкого спектра цифровых сервисов», — подчеркнул Александр Ковчев, директор ФГУП «ГлавНИВЦ» Управления делами Президента РФ. «Комплексный подход особенно востребован там, где заказчику необходимо не просто внедрить отдельный продукт, а построить на его основе собственное решение, соответствующее требованиям конкретной инфраструктуры и модели эксплуатации. В этом смысле партнёрство с ФГУП "ГлавНИВЦ" имеет хорошие перспективы, где опыт создания отечественных платформенных решений может лечь в основу специализированных, тиражируемых и устойчивых ИТ-решений», — сообщил Давид Мартиросов, генеральный директор «Базиса».
20.04.2026 [00:50], Владимир Мироненко
Строительство гигантского ИИ ЦОД им. Трампа застопорилось: заказчиков нет, гендиректор сбежал, акции падаютКрупнейший в мире проект по строительству кампуса ИИ ЦОД Project Matador (HyperGrid), поддерживаемый союзниками Трампа и формально носящий его имя (The President Donald J. Trump Advanced Energy and Intelligence Campus), застопорился из-за задержек в реализации и логистических проблем, сообщил ресурс Axios. Вдобавок в пятницу стало известно, что свой пост внезапно покинул генеральный директор стоящей за проектом компании Fermi America Тоби Нойгебаргер (Toby Neugebarger). Это привело к резкому падению акций компании на внебиржевых торгах, которые уже потеряли 75 % своей стоимости за последние шесть месяцев. За день до этого Нойгебаргер в интервью Axios защищал проект, признавая при этом существование некоторых недостатков, т.е. ничто не предвещало его скорого ухода. Он сообщил, что недооценил сложности реализации таких проектов, особенно систем охлаждения, необходимых для отвода тепла от ИИ-чипов. Также Нойгебаргер отметил, что, возможно, «неправильно понял, где находится цепочка поставок» оборудования для охлаждения: «Я приму это как неудачу». Одной из главных проблем, стоящих перед компанией, является отсутствие публично подтверждённого якорного арендатора — как правило, крупного провайдера, — наличие которого считается необходимым для дальнейшего развития проекта, в том числе и в отношении таких компонентов, как система охлаждения. Препятствия в продвижении проекта указаны в независимом отчёте аналитической компании Cleanview, предоставленном Axios, а также в финансовых отчётах, публичных документах и комментариях руководителей компании. 
Источник изображения: Fermi America Источник изображения: Fermi America Нойгебаргер признал в интервью Axios, что проект не может двигаться вперед без арендатора, вместе с тем отметив, что вопрос арендаторов «не является проблемой» для компании. Один из потенциальных арендаторов отказался от участия в проекте в декабре прошлого года, и инвесторы подали в связи с этим к компании коллективный иск. Вопрос об отсутствии публично объявленных арендаторов был снова поднят аналитиками во время годового финансового отчёта Fermi. Нойгебаргер тогда ответил, что компания подписывает новые письма о намерениях, но он не может публично разглашать подробности, пока не будет окончательного решения. При этом финансовый директор Майлз Эверсон (Miles Everson) сообщил аналитикам, что дальнейшее строительство не будет продолжено до тех пор, пока не будет заключено окончательное соглашение с арендатором и обеспечено финансирование проекта. Согласно отчёту Cleanview, даже если Fermi сейчас найдёт якорного арендатора и будет следовать другим аналогичным срокам строительства крупных ЦОД, первые здания в Амарилло (Amarillo, Техас) будут введены в эксплуатацию только в мае 2027 года — примерно на год позже, чем первоначально предполагалось. Ранее компания планировала ввести в эксплуатацию около 1,1 ГВт к концу 2026 года, но в недавнем заявлении для SEC она сообщила об отказе от этой цели. Компания преодолела ряд ключевых препятствий, в том числе получение разрешения на выбросы в атмосферу в начале этого года. Вместе с тем она столкнулась с задержкой с подтверждением систем охлаждения, которые обычно проектируются арендаторами и должны быть окончательно утверждены до начала строительства. «Я думаю, что это более серьёзное препятствие, чем мы первоначально предполагали», — сказал Нойгебаргер аналитикам. При этом компания уже заказала четыре ядерных реактора для питания своих дата-центров. |
|

