Лента новостей
|
21.10.2022 [13:26], Сергей Карасёв
Meta✴ готова к массовому внедрению СЖО в своих дата-центрахКомпания Meta✴ в ходе саммита OCP (Open Compute Project) рассказала о планах по внедрению жидкостного охлаждения в своих ЦОД. Речь идёт об использовании гибридной системы AALC (Air-Assisted Liquid Cooling), предусматривающей совмещение компонентов воздушного охлаждения и жидкостного контура. Отмечается, что по мере развития машинного обучения и метавселенных всё острее встаёт проблема эффективного отвода тепла от оборудования. Дело в том, что внедряемые алгоритмы требуют больших вычислительных мощностей, что приводит к увеличению энергозатрат. Система AALC предназначена для охлаждения серверов в ЦОД, которые изначально могли быть и не спроектированы под использование СЖО. Отметим, что QCT уже представила аналогичное, полностью интегрированное решение. 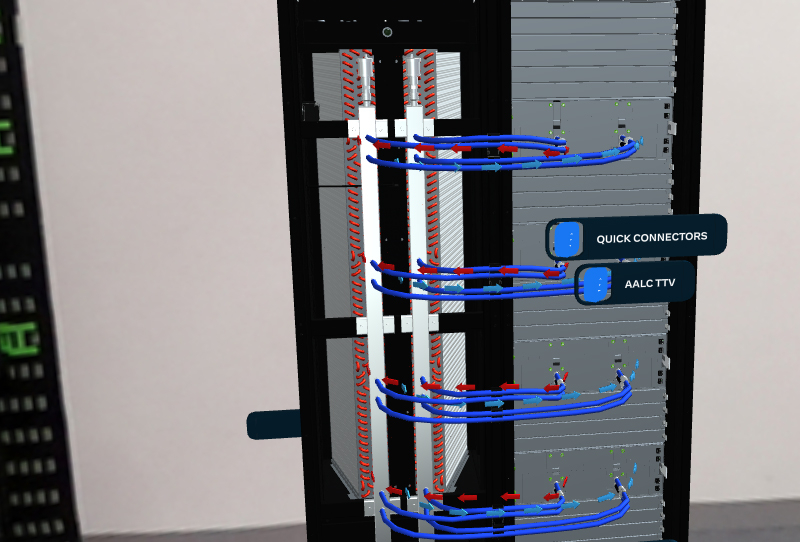
Источник изображений: Meta✴ AALC совместима со стойкой Open Rack v3 (ORV3), которая, впрочем, может интегрироваться и с другими вариантами СЖО. Система AALC в исполнении Meta✴ использует водоблоки для самых горячих компонентов, которые подключаются к отдельной стойке с помпами и прочим оборудованием. На задней панели или двери стойки располагается теплообменник, позволяющий охлаждать жидкость за счёт воздуха, циркулирующего в ЦОД. Прототипы решения справляются с охлаждением оборудования мощностью до 40 кВт на стойку. 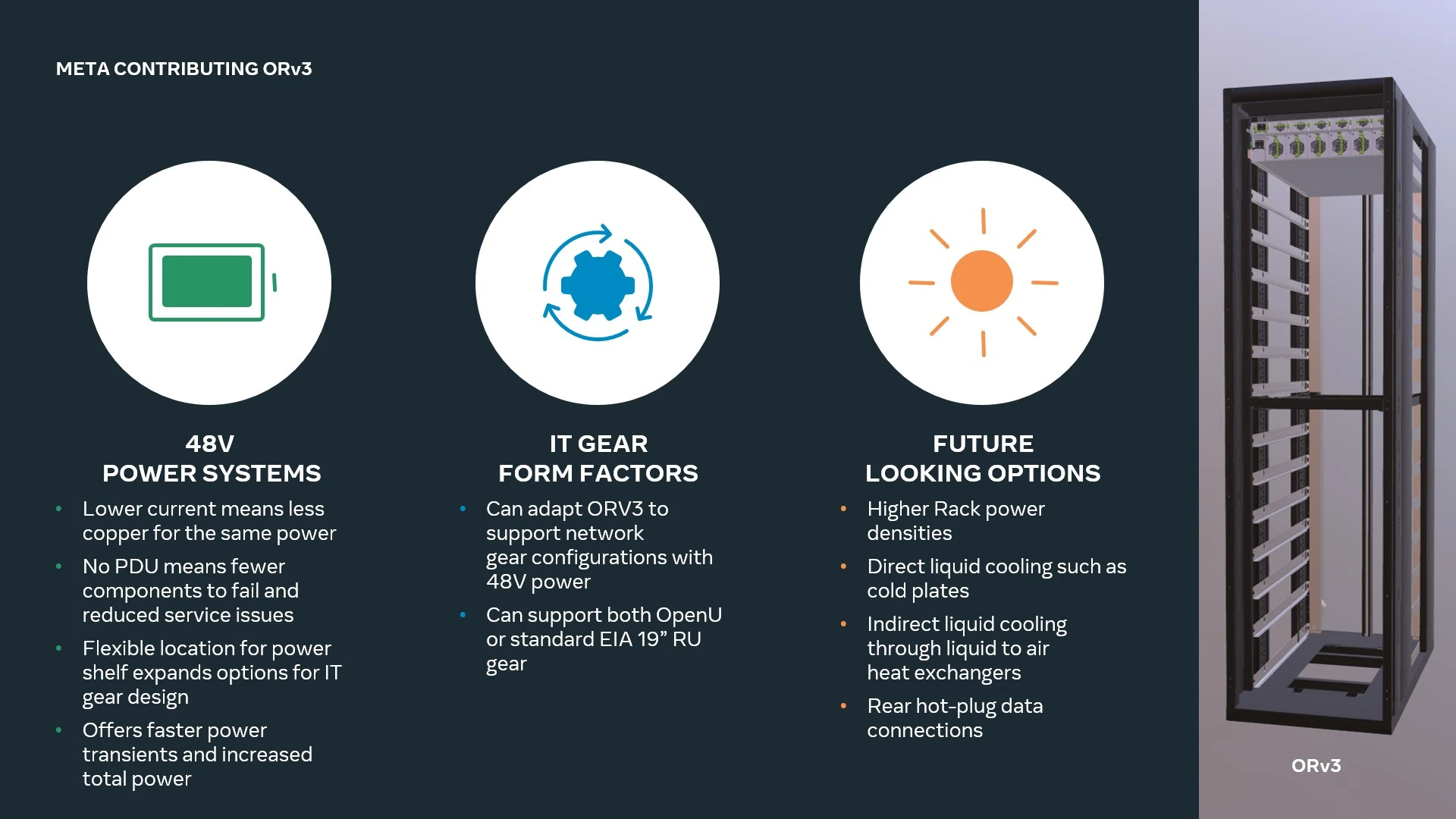 ORV3 также предлагает общую архитектуру стойки и подсистемы питания для устранения разрыва между нынешними и будущими ЦОД. Обеспечивается широкий спектр вариантов использования, включая поддержку Grand Teton. Модуль питания для общей на всю стойку шины 48 В DC не имеет жёстко определённого расположения и может устанавливается в любом месте стойки, что обеспечивает гибкость конфигурации. При этом он может быть не один, так что пиковая мощность может достигать 30 кВт на стойку. Усовершенствованный ИБП обеспечивает работу в течение 4 мин. при мощности 15 кВт (против 1,5 мин. у решения предыдущего поколения). Этот блок также может монтироваться в любом месте стойки, а дополнительно возможно применение второго резервного блока. Всё это позволит Meta✴ уже сейчас развёртывать в ЦОД высокоплотную инфраструктуру для ИИ и иных требовательных к питанию и охлаждению решений.
19.10.2022 [21:48], Сергей Карасёв
Пожар в южнокорейском дата-центре Kakao привёл к остановке 32 тыс. серверов, отказу в обслуживании 45 млн человек, падению акций и отставке топ-менеджера компанииИсполнительный содиректор южнокорейской интернет-компании Kakao Намкун Вон (Namkoong Whon) принял решение подать в отставку после массового сбоя в работе сервисов, спровоцированного пожаром в кампусе ЦОД SK C&C Data Center неподалёку от Сеула, принадлежащем SK Group. Возникшие проблемы вызвали недовольство как со стороны многочисленных пользователей, так и со стороны представителей бизнеса и власти. Пожар начался 15 октября 2022 года с возгорания в аккумуляторной в одном из зданий ЦОД. В результате была нарушена работа мессенджера KakaoTalk, аудитория которого составляет 43–47 млн пользователей в Южной Корее (при населении всей страны в почти 52 млн человек). Кроме того, возникли сбои в работе платёжной системы KakaoPay, почтовой службы, такси и других сервисов компании. Не был затронут только сервис Kakao Bank, который размещался в другом дата-центре. По состоянию на 17 октября работоспособность большинства функций KakaoTalk была восстановлена, однако доступность ряда служб всё же оставалась ограниченной. 
Источник изображения: Yonhap Инцидентом лично заинтересовался президент страны, а стоимость акций Kakao при этом рухнула на 9,5 % — до минимального значения с мая 2020 года. Нарушение работы KakaoTalk негативно сказалось на работе сотен предприятий малого бизнеса, использующих названный мессенджер. Kakao уже сообщила о намерении выплатить компенсации и выяснить причины медленного восстановления работы своих служб. Кроме того, Kakao намерена вложить $325 млн в открытие в 2023 году собственного ЦОД, а в 2024-м будет запущен второй дата-центр. Любопытно, что в том же кампусе находился и дата-центр Naver, ещё одного южнокорейского IT-гиганта, на работу которого инцидент оказал намного меньшее влияние. Основная претензия к Kakao заключается в том, что у компании не были разработаны планы поведения в экстренных ситуациях. В частности, компания оказалась не готова к тому, что ЦОД будет быстро обесточен после начала пожара. При этом, вероятно, это самый крупный инцидент в ЦОД в мире, поскольку речь идёт об остановке сразу 32 тыс. серверов. Нужно отметить, что в течение последнего времени пожары охватили сразу несколько крупных ЦОД. В частности, в марте прошлого года пожар уничтожил дата-центр французской компании OVHcloud в Страсбурге. В результате этого ЧП оказались недоступны в общей сложности 3,6 млн веб-сайтов, в том числе ресурсы ряда правительственных организаций, банков, интернет-магазинов и пр. А пожар, случившийся в ЦОД иранской Telecommunication Infrastructure Company (TIC), практически оставил без доступа в интернет всю страну.
18.10.2022 [19:00], Сергей Карасёв
AMD, Google, Microsoft и NVIDIA представили Caliptra — проект по повышению безопасности каждого чипаВ ходе саммита OCP (Open Compute Project) анонсирована открытая спецификация Caliptra 0.5, призванная повысить безопасность процессоров, ускорителей, накопителей и практически любых систем-на-чипе (SoC). Речь идёт об аппаратной реализации технологии Root of Trust (RoT). Она предназначена для проверки целостности и подлинности прошивок и другого встроенного, а также системного программного обеспечения.  RoT гарантирует, что только доверенное ПО может исполняться на чипе. Отмечается, что традиционно средства RoT отделены от SoC и обычно обеспечиваются материнской платой. Однако новые бизнес-модели, предполагающие периферийные и облачные вычисления, предъявляют повышенные требования к обеспечению безопасности. Спецификация Caliptra 0.5 как раз и решает данную проблему. 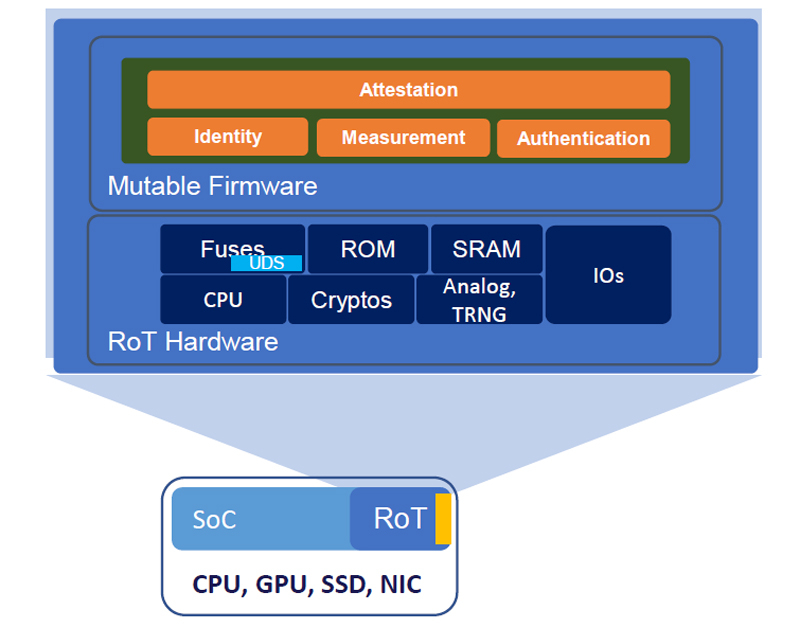
Источник изображений: Caliptra В разработке решения приняли участие AMD, Google, Microsoft и NVIDIA. Спецификация будет поддерживаться различными аппаратными изделиями следующего поколения — CPU, GPU, SSD, NIC и иные ASIC. Отмечается, что Caliptra 0.5 RTL (IP-блоки на базе RISC-V с необходимой обвязкой) распространяется через CHIPS Alliance (Common Hardware for Interfaces, Processors and Systems) — консорциум, который работает над созданием целого спектра открытых решений для SoC и высокоплотных упаковок чипов. 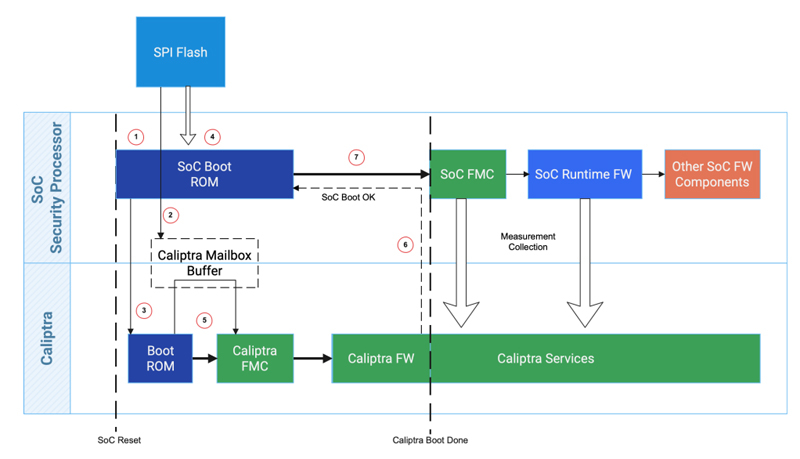 «Существует потребность в улучшенной прозрачности и согласованности низкоуровневой аппаратной безопасности. Мы открываем исходный код Caliptra вместе с нашими партнёрами для удовлетворения этих потребностей», — отмечает Microsoft. Также компания совместно с Google, Infineon и Intel представила Project Kirkland, направленный на создание защищённого канала связи между CPU и TPM с использованием программных средств. 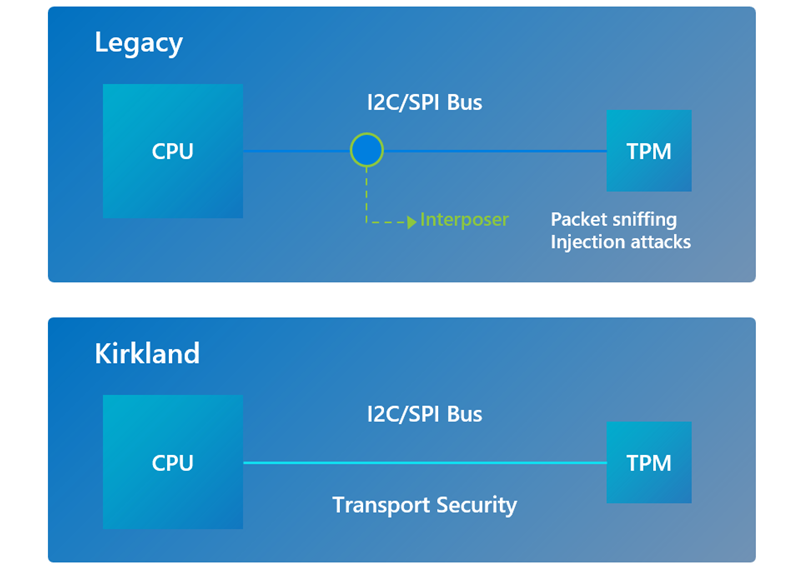
Источник: Microsoft Спецификация Caliptra 0.5 доступна здесь для оценки. На основе отзывов будет выработан окончательный стандарт, отвечающий различным потребностям в зависимости от варианта использования. Кроме того, доступен исходный код, что поможет членам сообщества интегрировать решение в свои микросхемы. Говорится также, что выход спецификации знаменует собой важный шаг вперёд в сторону общеотраслевого сотрудничества в области информационной безопасности.
14.10.2022 [17:17], Сергей Карасёв
OVHcloud разрабатывает технологию гибридного иммерсионного охлаждения серверовКомпания OVHcloud, европейский поставщик облачных услуг, сообщила о разработке системы гибридного иммерсионного (погружного) охлаждения серверов в центрах обработки данных (ЦОД). Технология призвана повысить эффективность расхода электроэнергии и высвободить площади, занимаемые традиционным оборудованием. Суть метода сводится к использованию двух типов СЖО. На центральных процессорах и ускорителях монтируются стандартные водоблоки, которые образуют отдельный контур. При этом всё шасси целиком вместе с теплообменником помещают в резервуар со специальной нелетучей диэлектрической углеводородной жидкостью. Для каждого сервера применяется собственный резервуар, что, по словам создателей, обеспечивает хорошую масштабируемость, гибкость развёртывания и удобство мониторинга. 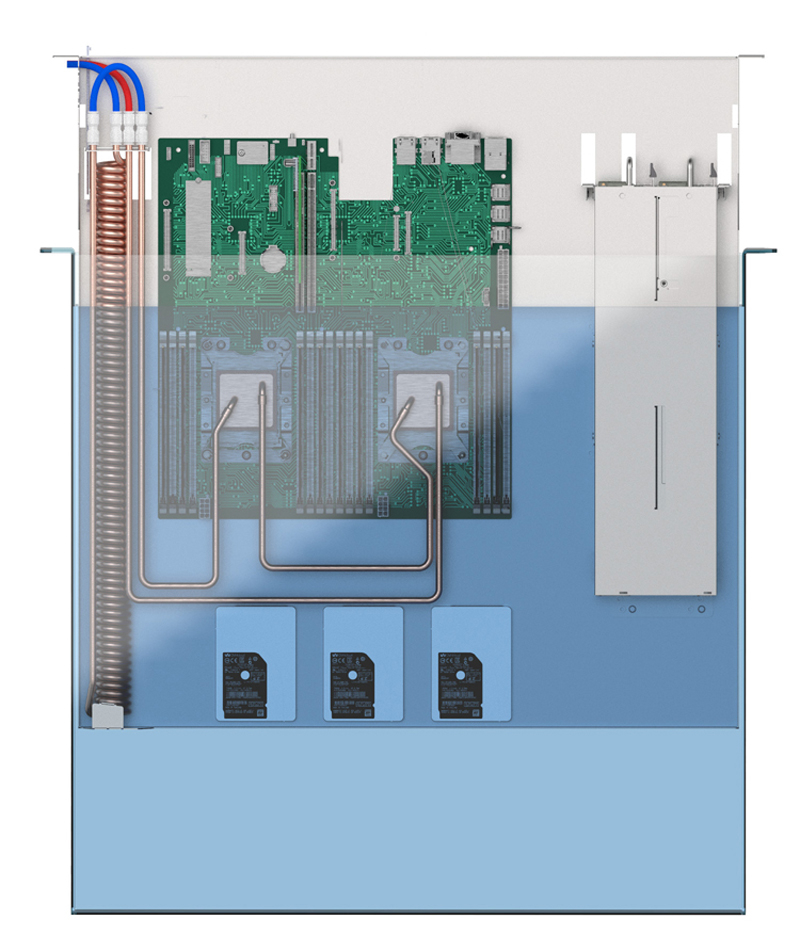
Изображения: OVHcloud Для системы предусмотрено применение трёхуровневой стойки библиотечного типа с возможностью монтажа 48 серверов формата 1U или 24 серверов стандарта 2U. Сами стойки имеют пассивный дизайн, то есть не содержат ни помп, ни вентиляторов, а значит, не затрачивают энергию на охлаждение. Потребление электроэнергии и капитальные затраты дополнительно снижаются за счёт исключения системы испарительного охлаждения в ЦОД, расположенных в регионах с температурой окружающего воздуха ниже +43 °С.  Утверждается, что новое решение позволяет сократить энергетические затраты дата-центра на охлаждение на 20,7 % по сравнению с обычным жидкостным охлаждением. Энергопотребление серверов снижается на 20 % в год по сравнению с воздушными системами охлаждения. Частичный коэффициент PUE (pPUE) заявлен на отметке 1,004, а коэффициент WUE — 0 для климатических зон с температурой окружающего воздуха ниже +43 °С. Отметим, что похожую систему охлаждения ранее представила Iceotope.
12.10.2022 [22:54], Сергей Карасёв
NEC готовит новые векторные ускорители серии SX-Aurora TSUBASAКомпания NEC Corporation сообщила о подготовке нового узла в серии SX-Aurora TSUBASA — модели C401-8, рассчитанной на центры обработки данных, на базе которых осуществляется сложное моделирование, выполняются научные расчёты и другие ресурсоёмкие задачи. Основой новинки станут неназванные пока векторные ускорители — судя по всему, это обещанные ранее Vector Engine 3.0 (VE30). Новинки получили 16 векторных блоков с частотой 1,7 ГГц, тогда как прошлое поколение имело до 10 блоков с частотой 1,6 ГГц. Также появился L3-кеш. Пропускная способность HBM-памяти увеличилась в 1,6 раза — с 1,53 до 2,45 Тбайт/с, а её объём вырос вдвое — с 48 до 96 Гбайт. Итоговая производительность в FP64-вычислениях, как утверждается, выросла приблизительно в 2,5 раза по сравнению с предшественниками и превысила 5 Пфлопс. При этом по энергоэффективности готовящийся ускоритель, по словам NEC, в два раза превосходит традиционные изделия. 
Источник изображения: NEC В августе 2023 года суперкомпьютер на базе SX-Aurora TSUBASA C401-8 начнёт использоваться в Научном центре Университета Тохоку в Японии. В общей сложности будут задействованы 4032 векторных ускорителя NEC, а быстродействие составит до 21 Пфлопс. Использовать комплекс планируется для масштабных научных исследований. Месяцем позже заработает ещё одна HPC-система на базе C401-8, которую получит метеослужба Германии.
07.10.2022 [19:02], Руслан Авдеев
Google запустила оптоволоконный подводный кабель Grace Hopper — между США и Европой появился канал на 350 Тбит/сКомпания Google ввела в эксплуатацию новый подводный оптоволоконный кабель Grace Hopper, который обеспечивает соединение сетевой инфраструктуры США, Великобритании, а также Испании. Как сообщает DataCenter Dynamics, кабель проложен от Нью-Йорка до британского города Бьюд в графстве Корнуолл, а ответвление также идёт в испанский Бильбао. Grace Hopper, названный в честь американской учёной и контр-адмирала Грейс Брюйстер Мюррей Хоппер (Grace Brewster Murray Hopper), состоит из 16 оптоволоконных пар и обеспечивает пропускную способность 350 Тбит/с по основной магистрали протяжённостью 6354 км. Как сообщают средства массовой информации, новый кабель начал работать 27 сентября, о чём Google уже оповестила Федеральную комиссию связи США (FCC). Это первый подводный кабель, построенный для связи США и Великобритании с 2003 года, дополнительно имеется ответвление в испанский Бильбао для обеспечения связи с облачным регионом в Мадриде. 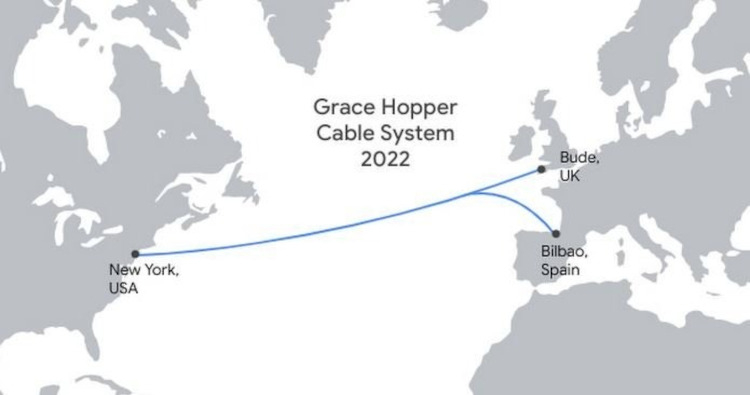
Источник изображения: Google В реализации проекта участвовала Lumen Technologies, помимо инвестиций ответственная за наземные узлы связи на обоих концах кабеля и наземную инфраструктуру. Для обеспечения оптимального качества связи при сбоях различной природы кабель Grace Hopper использует оптоволоконную коммутацию. Предусмотрена связь и с другими кабелями Google. 10 сентября прошлого года выход кабеля на сушу обеспечен в Испании, 14 сентября 2021 года — в Корнуолле.
04.10.2022 [22:57], Алексей Степин
Intel Labs представила нейроморфный ускоритель Kapoho Point — 8 млн электронных нейронов на 10-см платеКомпания Intel уже не первый год развивает направление нейроморфных процессоров — чипов, имитирующих поведение нейронов головного мозга. Уже во втором поколении, Loihi II, процессор получил 128 «ядер», эквивалентных 1 млн «цифровых нейронов», однако долгое время этот чип оставался доступен лишь избранным разработчикам Intel Neuromorphic Research Community через облако. Но ситуация меняется, пусть и спустя пять лет после анонса первого нейроморфного чипа: компания объявила о выпуске платы Kapoho Point, оснащённой сразу восемью процессорами Loihi II. Напомним, что они производятся с использованием техпроцесса Intel 4 и состоят из 2,3 млрд транзисторов, образующих асинхронную mesh-сеть из 128 нейроморфных ядер, модель работы которых задаётся на уровне микрокода. 
Источник изображений: Intel Labs Площадь кристалла нейроморфоного процессора Intel второго поколения составляет всего 31 мм2. Судя по всему, активного охлаждения Loihi II не требует: даже в первой реализации в виде PCIe-платы Oheo Gulch кулером оснащалась только управляющая ПЛИС, но не сам нейроморфный чип. В своём интервью ресурсу AnandTech Майк Дэвис (Mike Davies), глава проекта, отметил, что в реальных сценариях, выполняемых в человеческом масштабе времени, речь идёт о цифре порядка 100 милливатт, хотя в более быстром масштабе чип, естественно, может потреблять и больше. 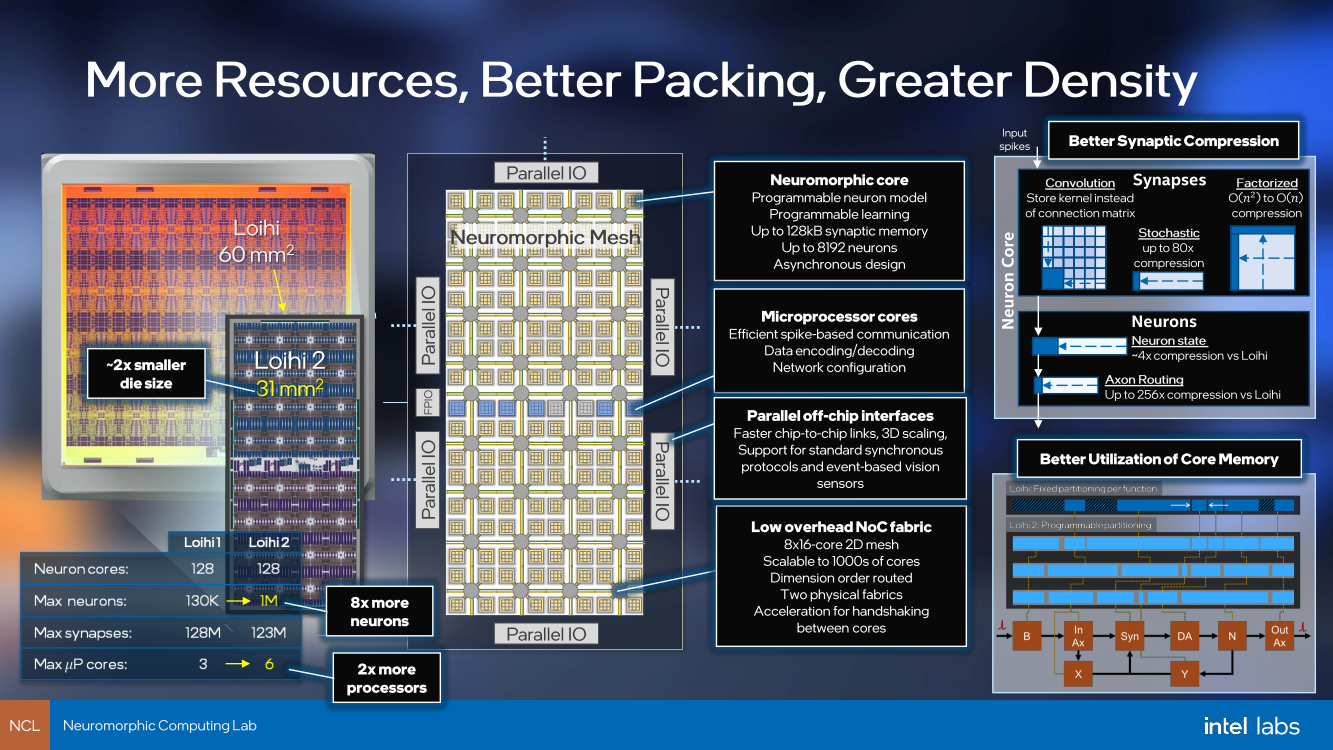
Архитектура и особенности строения Loihi II. По нажатию открывается полноразмерная версия Новый модуль, по словам компании, способен эмулировать до 1 млрд синапсов, а в задачах оптимизации с большим количеством переменных (до 8 миллионов, эквивалентно количеству «нейронов»), где нейроморфная архитектура Intel очень сильна, он может опережать традиционные процессоры в 1000 раз. Каждое ядро имеет свой небольшой пул быстрой памяти объёмом 192 Кбайт. Шесть выделенных ядер отвечают за управление нейросетью Loihi II; также в составе чипа имеются аппаратные ускорители кодирования-декодирования данных. Новинка изначально создана модульной: благодаря интерфейсному разъёму несколько плат Kapoho Point можно устанавливать одна над другой. Поддерживаются «бутерброды» толщиной до 8 плат, в деле опробован, однако, вдвое более тонкий вариант, но даже четыре Kapoho Point дают 32 миллиона нейронов в совокупности. Для коммуникации с внешним миром используется интерфейс Ethernet: в чипе реализована поддержка скоростей от 1 (1000BASE-KX) до 10 Гбит/с (10GBase-KR). Размеры каждой платы невелики, всего 4×4 дюйма (102×102 мм). 
Платы Kapoho Point позволяют легко расширять нейросеть на базе Loihi II В отличие от первого поколения Loihi, доступ к которому можно было получить лишь виртуально, через облако, системы на базе Kapoho Point уже доставлены избранным клиентам Intel, и речь идёт о реальном «железе». В число первых клиентов входит Исследовательская лаборатория ВВС США (Air Force Research Laboratory, AFRL), для задач которой такие достоинства Loihi II, как компактность и экономичность являются решающими. 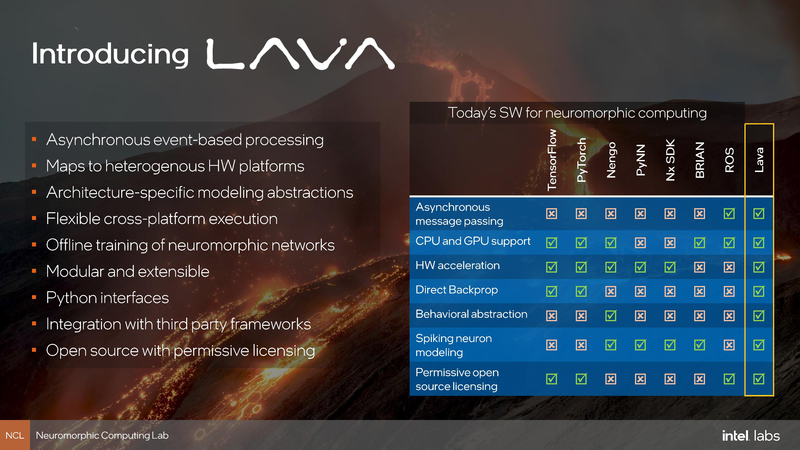
Возможности SDK Lava Одновременно с анонсом Kapoho Point компания Intel обновила и фреймворк Lava. В отлчиие от SDK первого поколения Nx новая открытая программная платформа разработки сделана аппаратно-независимой, что позволит разрабатывать нейро-приложения не только на платформе, оснащённой чипами Loihi II.
28.09.2022 [12:37], Алексей Степин
AMD анонсировала Ryzen Embedded V3000 — процессоры для встраиваемых систем с архитектурой Zen 3Семейство процессоров AMD Ryzen Embedded V получило долгожданное обновление: компания представила чипы V3000 с архитектурой Zen 3. Процессоры предназначены для широкого круга задач и могут использоваться в системах хранения данных, маршрутизаторах, сетевых брандмауэрах и коммутаторах — для этого у них достаточно как производительности, так и возможностей подсистем ввода-вывода. Новые чипы отличаются высокой энергоэффективностью: их номинальный теплопакет составляет от 15 до 45 Ватт в зависимости от модели; более тонкая настройка TDP позволяет регулировать потребление в диапазоне 10-54 Ватта. Это очень полезная возможность для периферийных систем, часто обходящихся пассивным охлаждением в виде оребренного корпуса. 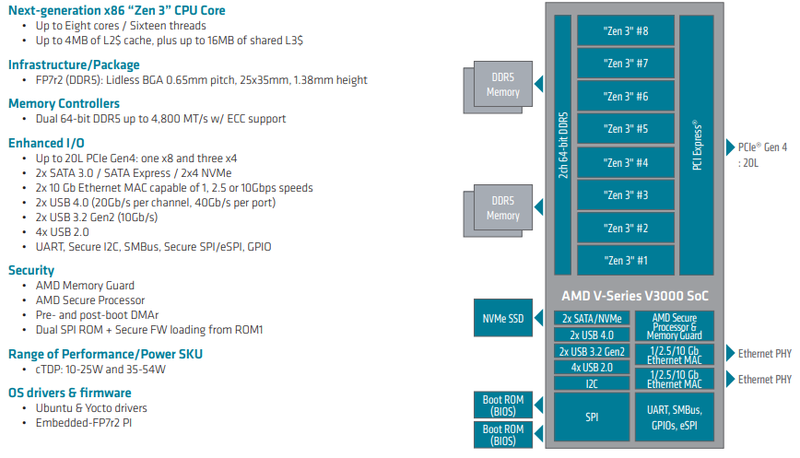
Источник изображений здесь и далее: AMD Всего в серии Ryzen Embedded V3000 представлено пять новых процессоров с количеством ядер от четырёх до восьми. Они отличаются базовой частотой от 1,9 до 3,5 ГГц, объёмами кешей, а также диапазоном рабочих температур: например, в серии есть модель V3C18I, способная функционировать в окружающей среде с температурой от -40 до +105 °C. В остальном новые процессоры очень похожи: все они используют компактные корпуса BGA, у всех максимальная частота в турборежиме составляет 3,8 ГГц, все чипы способны работать с памятью DDR5-4800, имеют 20 линий PCIe 4.0 и два интегрированных MAC-блока 10GbE. 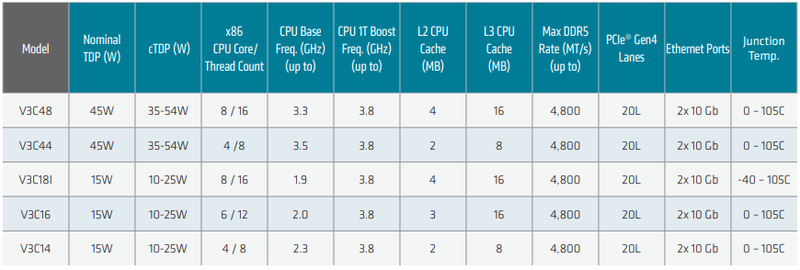
Модельный ряд Ryzen Embedded V3000 Новые процессоры AMD могут похвастаться повышенной защищённостью за счёт поддержки технологий AMD Memory Guard и AMD Platform Secure Boot. Компания-производитель рассчитывает на долгую службу новинок — жизненный цикл Ryzen Embedded V3000 составляет 10 лет. Также они будут иметь драйверную поддержку для будущих версий Linux Ubuntu и Yocto. Поставки новых чипов Ryzen Embedded V3000 ведущим OEM- и ODM-производителям оборудования уже начаты. AMD считает, что эти процессоры станут идеально сбалансированным выбором для СХД и сетевых устройств, как сочетающие в себе достаточно высокую производительность и низкий уровень тепловыделения, особенно важный в ограниченном пространстве серверных стоек.
23.09.2022 [19:58], Алексей Степин
Google заявила, что использует процессоры SiFive Intelligence X280 на RISC-V вместе со своим TPUАрхитектура RISC-V продолжает понемногу набирать популярность и завоевывать внимание ведущих игроков на рынке информационных технологий. На мероприятии AI Hardware Summit в совместном выступлении ведущего архитектора SiFive и архитектора Google TPU было отмечено, что Google уже использует процессоры с ядрами Intelligence X280. Эти ядра — один из вариантов воплощения архитектуры RISC-V, из продвигаемых SiFive. Анонс Intelligence X280 состоялся ещё в апреле 2021 года, когда SiFive выпустила апдейт 21G1, основной упор в котором был сделан на максимизацию характеристик уже существующих ядер RISC-V в области операций с плавающей запятой. 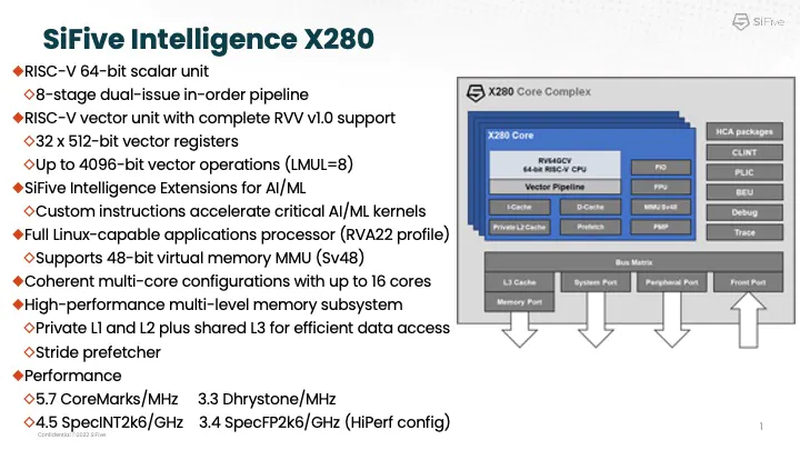
Процессорное ядро Intelligence X280 и его возможности. Источник: SiFive Как следует из названия, данный вариант процессора оптимизирован под задачи машинного интеллекта: ядра RISC-V в нём дополнены векторными конвейерами RISC-V Vector (RVV) с производительностью 4,5 Тфлопс BF16 и 9,2 Топс INT8 на ядро. Одной из самых интересных технологий в Intelligence X280 является интерфейс Vector Coprocessor Interface eXtension (VCIX). 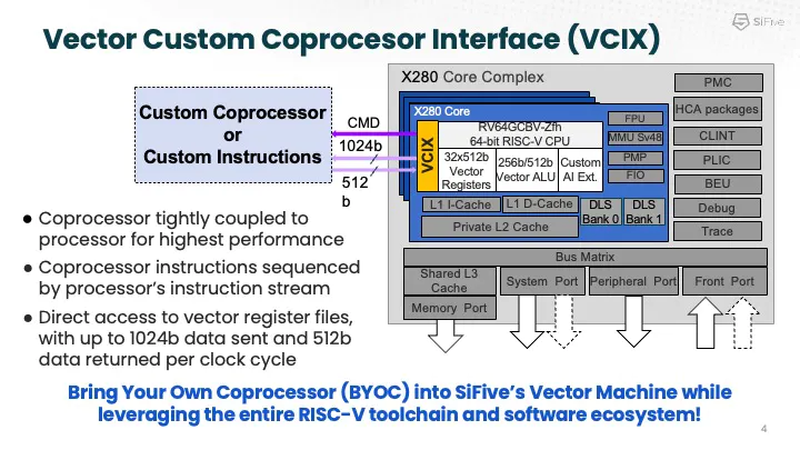
Устройство VCIX. Источник: SiFive Он позволяет подключать внешние ускорители векторных операций напрямую к регистровому файлу X280, минуя основную шину и кеши. Такой подход минимизирует накладные расходы и не требует использования специальных средств при программировании системы, поскольку связка из X280 и подключённого по VCIX ускорителя работает полностью прозрачно в рамках стандартных средств разработки SiFive. 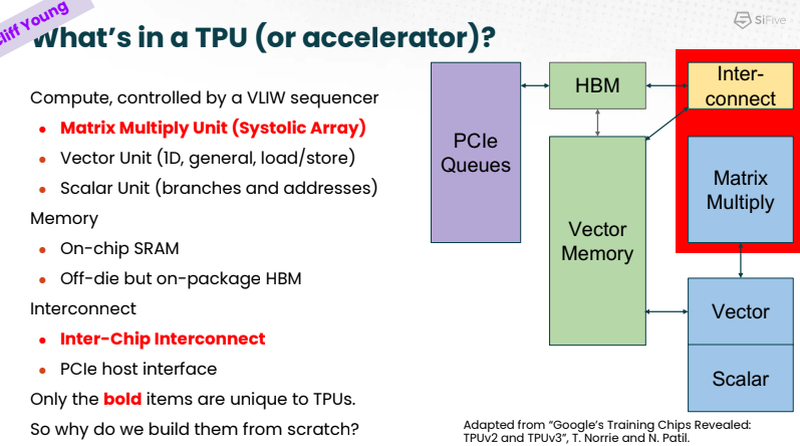
Сильные стороны Google TPU. Источник: SiFive На саммите в Санта-Кларе разработчики SiFive и Google TPU рассказали, что процессоры Intelligence X280 используются в качестве хост-процессоров к ускорителям систолической векторной математики Google MXU; правда, о масштабах внедрения RISC-V в Google сведений приведено не было. 
Разделение труда Intelligence X280 и Google TPU. Источник: SiFive Ранее уже появлялась информация, что Google активно тестирует ASIC сторонних разработчиков в связке со своим TPU, в частности, чипы Broadcom, дабы разгрузить его от второстепенных задач и сделать упор на сильных сторонах — матричной математике и быстром интерконнекте. Похоже, SiFive Intelligence X280 решает задачу интеграции подобного рода задач более изящно: как отметил в выступлении Клифф Янг (Cliff Young), архитектор Google TPU, с помощью VCIX можно построить машину, позволяющую усидеть на двух стульях (build a machine that lets you have your cake and eat it too).
21.09.2022 [19:39], Алексей Степин
NVIDIA представила новые сверхкомпактные модули Jetson Orin NanoКомпания NVIDIA полна решимости занять лидирующие позиции на рынке робототехники: помимо новой платформы IGX, предназначенной для «умной» промышленности и медицины, на конференции GTC 2022 она представила и другие новинки в этой сфере. В частности, анонсированы новые модули в серии Jetson. Если в основу IGX лёг старший вариант, Jetson AGX Orin (Arm Cortex-A78AE + 1792 ядра Ampere + 56 тензорных ядер), то для более простых сценариев, требующих пониженного энергопотребления, он подходит не лучшим образом. Но именно для таких случаев предназначено пополнение серии — Jetson Orin Nano. 
NVIDIA Jetson Orin Nano 8GB (слева) и 4GB. Здесь и далее источник изображений: NVIDIA Архитектурно Orin Nano похож на старшего собрата, но вычислительных ресурсов у него поменьше: 6 ядер Arm Cortex-A78AE и кластер GPC Ampere, состоящий из 1024 ядер CUDA и 32 тензорных ядер. Имеется отдельный процессор управления питанием, широко развиты подсистемы различных шин, от SPI, CAN и I2C до USB 3.2 Gen2, Ethernet и PCIe 3.0. 
Архитектура процессора Orin Nano Доступны новые модули будут в самом начале следующего года по цене от $199, причём изначально компания планирует выпустить два варианта, с 4 и 8 Гбайт оперативной памяти LPDDR5. Старший вариант будет сконфигурирован в рамках теплопакета 7–15 Вт, его пиковая производительность в INT8 составит 40 Топс. Младший вариант с усечённой вдвое конфигурацией GPU будет ограничен 5–10 Вт и 20 Топс. 
Характеристики семейства Jetson Orin Nano Модули Orin Nano совместимы по контактам с Orin NX и имеют тот же форм-фактор, 70 × 45 мм SODIMM, но за счёт использования более продвинутой архитектуры в задачах инференса новинки могут опережать предшественников в 80 раз. Благодаря обновлению фирменного SDK начать разработку приложений под Orin Nano заказчики смогут уже сейчас, пусть и в режиме эмуляции. |
|

