Лента новостей
|
01.12.2022 [18:11], Сергей Карасёв
Iceotope и Meta✴ показали возможность иммерсионного охлаждения HDDКомпании Iceotope и Meta✴ продемонстрировали возможность иммерсионного (погружного) охлаждения систем хранения данных (СХД) на основе HDD. В ходе эксперимента было показано, что такой подход обеспечивает ряд преимуществ перед традиционным воздушным охлаждением. В тесте использовалась стандартная коммерческая СХД высокой плотности формата 4OU, содержащая 72 жёстких диска, два односокетных серверных узла, две платы расширения SAS, сетевую карту, модуль распределения питания и другие компоненты. При этом система охлаждения была модифицирована путём добавления специального диэлектрического контура, теплообменника и насоса. Накопители были погружены в непроводящую жидкость.  ✴/Iceotope/ASME " height="441" width="709" /> ✴/Iceotope/ASME " height="441" width="709" />
Источник изображения: Meta✴/Iceotope/ASME Говорится, что применение иммерсионного охлаждения для HDD возможно благодаря тому, что современные диски с заполнением гелием имеют герметичную конструкцию. Результаты эксперимента показали, что в случае погружного охлаждения разница температур между всеми 72 накопителями составила всего 3 °C — независимо от расположения HDD в шасси. Накопители способны надёжно функционировать при температуре жидкости на входе в стойку до +40 °C. 
Нажмите для увеличения / Источник изображения: Iceotope Другим преимуществом иммерсионного подхода является то, что он позволяет сократить уровень вибрации, которая может приводить к некорректной работе накопителей или даже провоцировать их выход из строя. В целом, для работы системы погружного охлаждения требуется менее 5 % мощности, потребляемой самой СХД.
30.11.2022 [16:55], Алексей Степин
AWS представила пятое поколение аппаратных гипервизоров NitroНа днях крупный провайдер облачных услуг, компания Amazon Web Services представила новые варианты инстансов на базе новейших процессоров Graviton3E, но данный чип — не единственная новинка AWS. Одновременно с Graviton3E было представлено и пятое поколение аппаратных гипервизоров Nitro, существенно выигрывающих по ключевым показателям у решений предыдущего, четвёртого поколения. 
Здесь и далее источник изображений: ServeTheHome Главная идея Nitro — сочетание «кремния» гипервизора, DPU и сопроцессора безопасности с поддержкой Root of Trust в едином чипе. В системах AWS плата с чипом Nitro полностью управляет распределением вычислительных ресурсов и памяти, избавляя от этой нагрузки хост-процессоры. По результатам тестов, проведённых AWS, производительность облачных инстансов с использованием ускорителей Nitro практически не отличается от производительности классической bare metal-системы.  AWS Nitro v5 использует кастомный кристалл, разработанный Annapurna Labs. По сравнению с Nitro v4, количество транзисторов было удвоено, но за счёт этого удалось на 60 % поднять скорость обработки сетевых пакетов, на 30 % снизить латентность, а также, благодаря продвинутому техпроцессу, обеспечить лучшую удельную производительность. 
Платы AWS Nitro v5 используют проприетарные разъёмы Улучшились и другие характеристики: на 50 % выросла пропускная способность памяти и вдвое возросла производительность подсистемы PCI Express. Платы Nitro v5 станут сердцем новых инстансов C7gn, где обеспечат полную изоляцию критически важных подсистем, таких, как прошивки BIOS, BMC и накопителей от гостевого доступа извне и позволят обновлять эти прошивки без влияния на клиентские нагрузки.  Также они возьмут на себя обслуживание сетей VPC/EBS, включая переход на использование SRD вместо TCP, и накопителей Nitro SSD. AWS уже объявила о возможности предварительного тестирования систем C7gn на базе Nitro v5 и новейших процессоров Graviton3/3E.
29.11.2022 [18:07], Сергей Карасёв
Служба AWS Time Sync стала доступна в виде публичного NTP-сервисаОблачная платформа Amazon Web Services (AWS) сообщила о том, что система синхронизации часов Time Sync теперь доступна в виде публичного NTP-сервиса. Ранее данная функция действовала только в рамках серверов AWS. Сервис Amazon Time Sync представляет собой высокоточный, надёжный и доступный источник времени для сервисов AWS, включая инстансы EC2. Система компенсирует отклонения, синхронизируя часы с парком резервных спутниковых и атомных часов в каждом регионе AWS. Синхронизация часов важна, в частности, при ведении журналов: дело в том, что сравнение двух файлов журналов на серверах с рассинхронизированными часами делает устранение неполадок гораздо сложнее. 
Изображение: Markus Kammermann/Pixabay Доступность Time Sync в виде публичного NTP-сервиса означает, что воспользоваться системой могут любые серверы и устройства Интернета вещей. Время синхронизируется с точностью до нескольких миллисекунд относительно всемирного координированного времени (UTC). Однако, как отмечается, сервис значительно менее точен, чем у конкурирующего Google, а Meta✴ начала полностью отказываться от NTP. Владелец Facebook✴ заявил, что перейдёт на протокол точного времени (PTP), что обеспечит точность в пределах наносекунд. При этом всем компаниям приходится иметь дело с дополнительной секундой, которая иногда добавляется в шкалу UTC для согласования со средним солнечным временем UT1. Эта практика, действующая с 1972 года, привела к ряду проблем, поэтому с 2000-х годов в международных организациях обсуждается отказ от введения дополнительной секунды.
29.11.2022 [17:12], Алексей Степин
AWS представила Arm-процессор Graviton3E, оптимизированный для задач ИИ и HPCОдин из крупнейших облачных провайдеров, компания Amazon Web Services объявила о доступности новых инстансов EC2 на базе процессора Graviton3E. Новый чип — наследник анонсированного в конце 2021 года Graviton3, 5-нм 64-ядерного процессора на дизайне Arm Neoverse V1 (Zeus) с поддержкой DDR5 и PCI Express 5.0. Graviton3 использует набор команд Armv8.4 c расширениями Neon (4×128 бит) и SVE (2×256 бит) и поддерживает работу с популярными в сфере машинного обучения форматами данных INT8 и BF16. В сравнении c Graviton2 процессор быстрее на 25-60 % при сохранении аналогичного уровня тепловыделения. Дизайн серверов AWS предусматривает наличие трёх процессоров на узел высотой 1U. 
Изображения: AWS Новый процессор Graviton3E представляет собой дальнейшее развитие Graviton3. Чип оптимизирован с учётом потребностей рынка высокопроизводительных вычислений и основное внимание в его архитектуре уделено повышению производительности на операциях с плавающей запятой и вычислениях с использованием векторной математики. AWS, к сожалению, пока не раскрывает деталей относительно архитектуры Graviton3E, но прирост производительности на векторных операциях относительно обычного Graviton3 может достигать 35 %. Помимо классического теста HPL новый процессор хорошо проявляет себя в тестах, имитирующих медико-биологические и финансовые задачи.  Сценарии нагрузок, характерные для HPC, как правило, активно оперируют перемещением крупных объемов данных. Чтобы оптимизировать этот процесс, в новых инстансах AWS использует сеть на базе Elastic Fabric с новыми адаптерами Elastic Network Adapter (ENA). Такая сеть оперирует т. н. Scalable Reliable Datagram (SRD) вместо всем привычных TCP-пакетов. SRD позволяет организовать повторную отправку пакетов за микросекунды вместо миллисекунд в классическом Ethernet. Сердцем же новых инстансов AWS стало пятое поколение аппаратных гипервизоров Nitro 5. В сравнении с предыдущим поколением, Nitro 5 обладает вдвое более высокой вычислительной производительностью, на 50 % повышенной пропускной способностью памяти, а также позволяет обрабатывать на 60 % больше сетевых пакетов при сниженной на 30 % латентности. 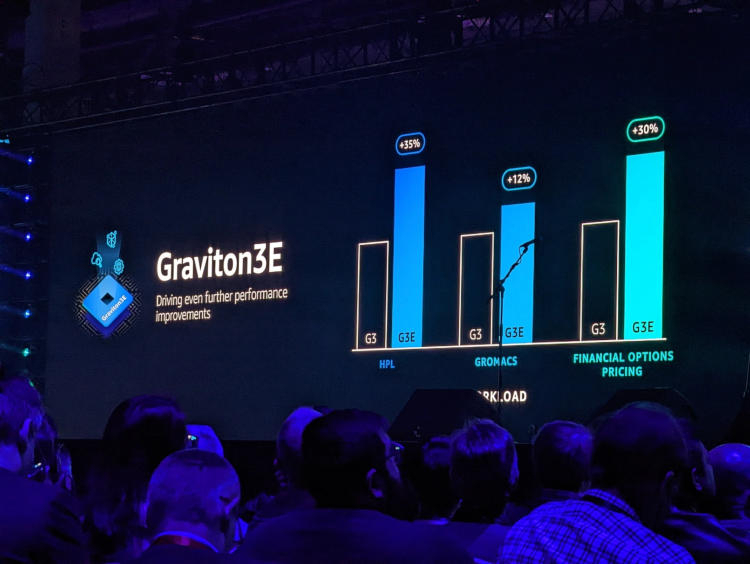
Здесь и далее источник изображений: AWS Инстансы Hpc7g с процессорами Graviton3E получат внутреннюю сеть с пропускной способностью 200 Гбит/с и станут доступны в различных конфигурациях вплоть до 64 vCPU и 128 ГиБ памяти. Аналогичные параметры имеют инстансы C7gn, предназначенные для задач с интенсивным сетевым трафиком: виртуальных маршрутизаторов, сетевых экранов, балансировщиков нагрузки и т.п. Также компания анонсировала инстансы R7iz, в которых используются процессоры Intel Xeon Scalable четвёртого поколения (Sapphire Rapids) с постоянной частотой всех ядер 3,9 ГГц. Они могут иметь конфигурацию до 128 vCPU с 1 ТиБ памяти.
29.11.2022 [12:20], Сергей Карасёв
В Италии официально запущен суперкомпьютер Leonardo — четвёртая по мощности HPC-система в миреСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU и некоммерческий консорциум CINECA, состоящий из 69 итальянских университетов и 21 национальных исследовательских центров, провели церемонию запуска суперкомпьютера Leonardo. В основу комплекса положены платформы Atos BullSequana X2610 и X2135. Система Leonardo состоит из двух секций — общего назначения и с ускорителями вычислений (Booster). Когда строительство системы будет завершено, первая будет включать 1536 узлов, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids с 56 ядрами и TDP в 350 Вт, 512 Гбайт оперативной памяти DDR5-4800, интерконнект NVIDIA InfiniBand HDR100 и NVMe-накопитель на 8 Тбайт. 
Источник изображения: HPCwire Секция Booster объединяет 3456 узлов, каждый из которых содержит один чип Intel Xeon 8358 с 32 ядрами, 512 Гбайт ОЗУ стандарта DDR4-3200, четыре кастомных ускорителя NVIDIA A100 с 64 Гбайт HBM2-памяти, а также два адаптера NVIDIA InfiniBand HDR100. Кроме того, в состав комплекса входят 18 узлов для визуализации: 6,4 Тбайт NVMe SSD и два ускорителя NVIDIA RTX 8000 (48 Гбайт) в каждом. Вычислительный комплекс объединён фабрикой с топологией Dragonfly+. 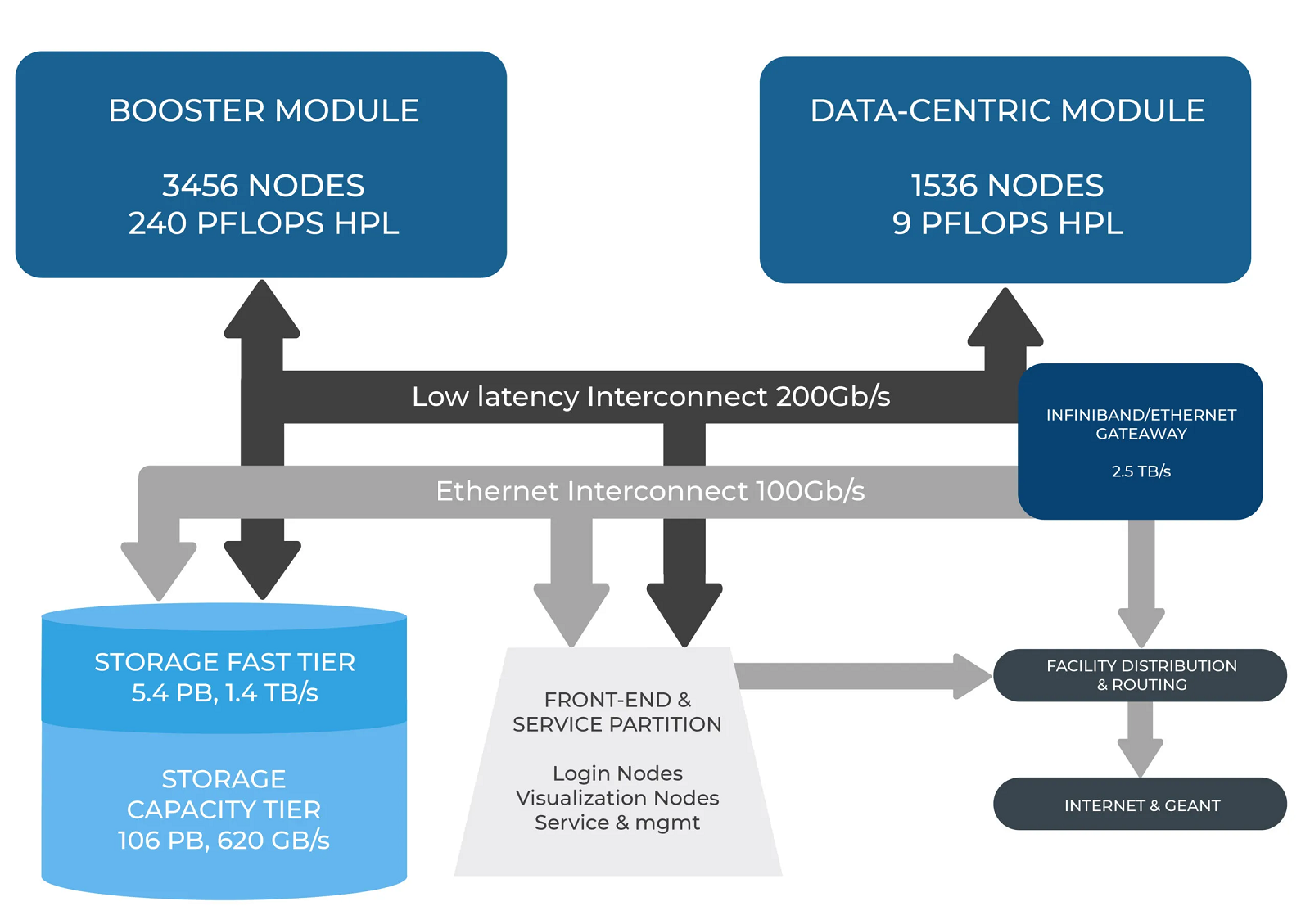
Источник: CINECA Для хранения данных служит двухуровневая система. Производительный блок (5,4 Пбайт, 1400 Гбайт/с) содержит 31 модуль DDN Exascaler ES400NVX2, каждый из которых укомплектован 24 NVMe SSD вместимостью 7,68 Тбайт и четырьмя адаптерами InfiniBand HDR. Второй уровень большой ёмкости (106 Пбайт, чтение/запись 744/620 Гбайт/с) состоит из 31 массива DDN EXAScaler SFA799X с 82 SAS HDD (7200 PRM) на 18 Тбайт и четырьмя адаптерами InfiniBand HDR. Каждый из массивов включает два JBOD-модуля с 82 дисками на 18 Тбайт. Для хранения метаданных используются 4 модуля DDN EXAScaler SFA400NVX: 24 × 7,68 Тбайт NVMe + 4 × InfiniBand HDR. 
Изображение: CINECA В настоящее время Leonardo обеспечивает производительность более 174 Пфлопс. Ожидается, что суперкомпьютер будет полностью запущен в первой половине 2023 года, а его пиковое быстродействие составит 250 Пфлопс. Уже сейчас система занимает четвёртое место в последнем рейтинге самых мощных суперкомпьютеров мира TOP500. В Европе Leonardo является второй по мощности системой после LUMI. Leonardo оборудован системой жидкостного охлаждения для повышения энергоэффективности. Кроме того, предусмотрена возможность регулировки энергопотребления для обеспечения баланса между расходом электричества и производительностью. Суперкомпьютер ориентирован на решение высокоинтенсивных вычислительных задач, таких как обработка данных, ИИ и машинное обучение. Половина вычислительных ресурсов Leonardo будет предоставлена пользователям EuroHPC.
25.11.2022 [16:33], Алексей Степин
Meta✴ переходит на использование протокола синхронизации времени PTPВ отличие от широко известного протокола сетевой координации времени NTP, разработанный изначально для локальных сетей, PTP (Precision Time Protocol, IEEE 1588) способен обеспечивать точность синхронизации в пределах десятков наносекунд, тогда как у NTP это значение находится в диапазоне единиц или десятков миллисекунд. С точки зрения владельцев крупных ЦОД возможность повысить точность синхронизации может представлять существенный интерес, поскольку позволяет точнее привести серверы к единому времени. И такой возможностью заинтересовалась компания Meta✴, которая в течение некоторого времени тестировала PTP локально, а в настоящее время заявила о переводе всех серверов на новый стандарт синхронизации. 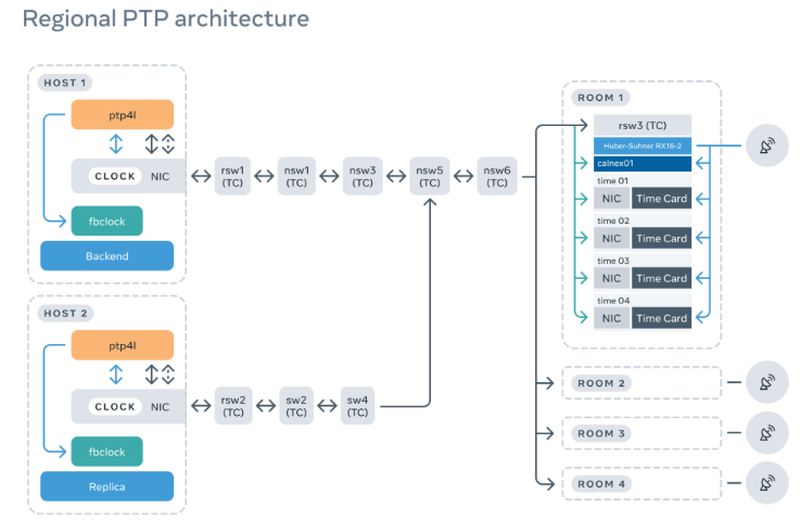 Поскольку масштабы сети серверов Meta✴ действительно велики, влияние неточностей при использовании NTP может накапливаться и приводить к задержкам, сбоям или даже сетевым отказам. Тем более сверхточная синхронизация важна для проекта метавселенной, в котором огромная виртуальная вселенная должна функционировать как единое целое. Однако внедрение PTP требует поддержки со стороны не только программного, но и аппаратного обеспечения, поэтому компания разработала в рамках OCP систему Open Time Server, в основе которой лежит плата точного времени Facebook✴ Time Card с приёмником сигналов GNSS. Требований со стороны сервера немного: использование сетевых интерфейсов с поддержкой PPS и Hardware Timestamps и процессоров с VT-d. 
Facebook✴ Time Card Программная часть состоит из ОС Linux с драйвером ocp_ptp и демонов Chrony/NTPd и ptp4u/ptp4l, работающих с устройствами dev/ptpX карты времени и сетевого адаптера. В официальном репозитории Open Time Server приведена подробная информация на этот счёт. На уровне ЦОД это означает появление выделенных стоек PTP, оснащённых соответствующим оборудованием. Подчёркивается также важность наличия качественной антенны для приёма GNSS-сигналов, гарантирующей точность позиционирования менее 10 м — лишь при такой точности можно вести речь о наносекундном уровне синхронизации. Каждая стойка PTP также содержит устройство Calnex Sentinel 2.0, ответственное за мониторинг состояния системы: расхождение между Time Card и сетевым адаптером должно укладываться в окно размером не более 50 нс.
17.11.2022 [00:56], Руслан Авдеев
Сухо и комфортно: для экономии воды в ЦОД Meta✴ подняла температуру и снизила влажность в машинных залахНа мероприятии 7×24 Exchange Fall Conference Meta✴ поделилась секретами сбережения воды при эксплуатации дата-центров. Компания повысила температуру в серверных до +32,2 °C, а влажность, наоборот, снизила — до 13 %. Ожидается, что это позволит сэкономить миллиарды литров воды ежегодно. Попутно компания также внедряет передовую систему обработки и фильтрации воды, а в перспективе Meta✴ намерена «восстанавливать» больше воды для окружающей среды, чем потребляет. Для оптимизации работы собственных площадок Meta✴ прибегла к эксперименту — на половине территории некоторых ЦОД задавались различные значения температуры и влажности, после чего оценивались и сравнивались различные показатели, включая, например, процент отказов оборудования. Делается это всё ради уменьшение затрат энергии и воды на охлаждение. Поскольку у Meta✴ площадь ЦОД составляет более 3,7 млн м2, даже небольшие улучшения ведут к большой экономии. 
Источник изображения: Erda Estremera/unsplash.com Это не первое повышение температуры и понижение влажности в дата-центрах компании. Ранее Meta✴ увеличила температуру до +29,4 °C, а влажность вообще планировалось поддерживать на уровне 20–30 %. Однако практические испытания показали, что оборудованию достаточно комфортно в новых условиях, и нет проблем, например, со статическими разрядами. Изначально все эти меры были предприняты для снижения энергопотребления, но они заодно помогают экономить и воду. Также в компании обновили процессы промышленной обработки воды, используемой в ЦОД — от фильтрации до «смягчения». Одним из важных изменений стал процесс оптимизации т.н. «обратной промывки» загрязнённых фильтров — в Meta✴ смогли организовать его таким образом, что фильтрационные системы стали использовать намного меньше воды. Помогла и оптимизация процесса смягчения воды в некоторых ЦОД. 
Источник изображения: Stephen Dawson/unsplash.com Всего компания использовала 2,57 млрд литров воды в 2021 году, но водные затраты на электроэнергию составили ещё 3,31 млрд литров. Проекты по восстановлению воды позволили «компенсировать» 2,33 млрд литров, а новые технологии, как ожидается, в перспективе обеспечат «возврат» более 3,2 млрд литров воды ежегодно, так что в Meta✴ рассчитывают стать «водно-положительной» к 2030 году — заявление сделали после критики нового ЦОД в одном из засушливых штатов США.
15.11.2022 [19:08], Сергей Карасёв
Cerebras построила ИИ-суперкомпьютер Andromeda с 13,5 млн ядерКомпания Cerebras Systems сообщила о запуске уникального вычислительного комплекса Andromeda для выполнения «тяжёлых» ИИ-нагрузок. В основу Andromeda положен кластер из 16 блоков Cerebras CS-2, объединённых 96,8-Тбит/с фабрикой. Каждый из них содержит чип WSE-2, насчитывающий 850 тыс. ядер. Таким образом, общее число ядер достигает 13,5 млн. Кроме того, непосредственно в состав каждого чипа входят 40 Гбайт сверхбыстрой памяти. Система уже доступна коммерческим заказчикам, а также различным научным организациям. 
Источник изображения: Cerebras Systems Суперкомпьютер также использует 284 односокетных сервера с процессорами AMD EPYC 7713. Суммарное количество вычислительных ядер общего назначения составляет 18 176. Каждый из этих серверов несёт на борту 128 Гбайт оперативной памяти, NVMe-накопитель вместимостью 1,92 Тбайт и две сетевые карты 100GbE. Эти узлы отвечают за предварительную обработку информации. 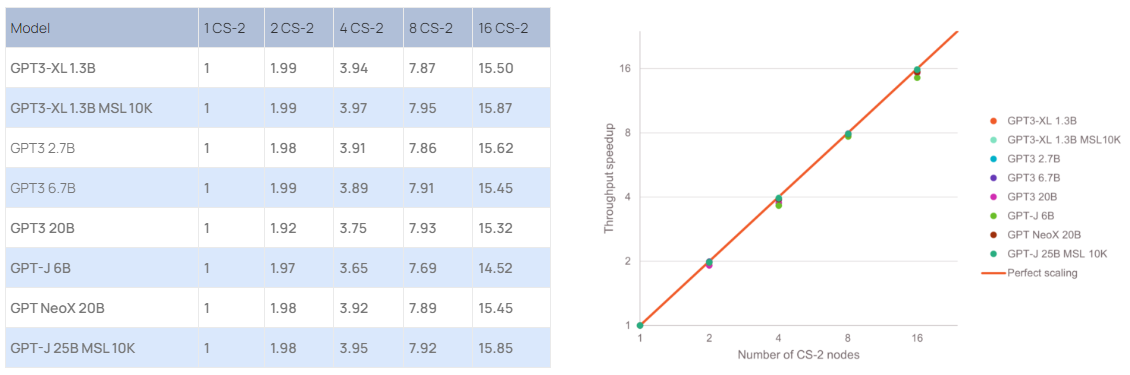
Источник: Cerebras Systems По заявлениям Cerebras, производительность системы превышает 1 Эфлопс на т.н. разреженных вычислениях и достигает 120 Пфлопс при обычных FP16-вычислениях. Это первый в мире суперкомпьютер, который обеспечивает практически идеальное линейное масштабирование при работе с GPT-моделями, в частности, GPT-3, GPT-J и GPT-NeoX. Иначе говоря, при каждом удвоении числа комплексов CS-2 время обучения моделей сокращается почти в два раза.  Суперкомпьютер смонтирован в дата-центре Colovore в Санта-Кларе (Калифорния, США). Стоимость системы составила приблизительно $30 млн, а на её развёртывание потребовалось всего три дня. Использовать ресурсы Andromeda могут одновременно несколько клиентов.
14.11.2022 [00:00], Игорь Осколков
Игра по новым правилам: AMD представила Genoa, четвёртое поколение серверных процессоров EPYCВсего за десять лет AMD совершила почти невозможное — практически полностью потеряла серверный рынок, а теперь не просто успешно его отвоёвывает, но и предлагает комплексное портфолио решений. Анонс четвёртого поколения процессоров EPYC под кодовым именем Genoa — это не технологическая победа над Intel, поскольку AMD даже не думала бороться с Sapphire Rapids и уж тем более с Ice Lake-SP, а ориентировалась на Granite Rapids. Но годовая задержка с выпуском Sapphire Rapids позволила AMD не только в более спокойном темпе доделывать чипы Genoa, которые вышли на полгода позже, чем задумывалось ранее, но и поработать с разработчиками и заказчиками. Компании удалось вернуть их доверие — победа в умах гораздо важнее, чем просто технологическое превосходство. А оно неоспоримо. 
Источник: AMD EPYC Genoa заключены в корпус 72×75 мм, содержат до 90 млрд транзисторов и состоят из 13 чиплетов: 12 CCD, изготовленных по 5-нм техпроцессу TSMC плюс один, изрядно увеличившийся в размерах, IO-блок, сделанный там же, но уже по 6-нм нормам. Отказ от услуг GlobalFoundries, которая так и не смогла освоить тонкие техпроцессы, случился как нельзя кстати, поскольку IO-блок становится крайне важным компонентом при таком количестве ядер, которые необходимо вовремя накормить данными. И Genoa интересны в первую очередь с точки зрения полноты и разнообразия IO, а не рекордного количества ядер. IO-чиплет оснащён новыми SerDes-блоками, которые обслуживают и PCIe 5.0, и Infinity Fabric 3.0 (IF/GMI3). Формально каждому чипу полагается 128 линий PCIe 5.0, но реальная конфигурация чуть сложнее. Во-первых, у каждого чипа есть ещё восемь (2 x4) бонусных линий PCIe 3.0 для подключения нетребовательных устройств и обвязки, но в 2S-конфигурации таких линий будет только 12. Во-вторых, для 2S можно задействовать три (3Link) или четыре (4Link) IF-подключения, получив 160 или 128 свободных линий PCIe 5.0 соответственно. 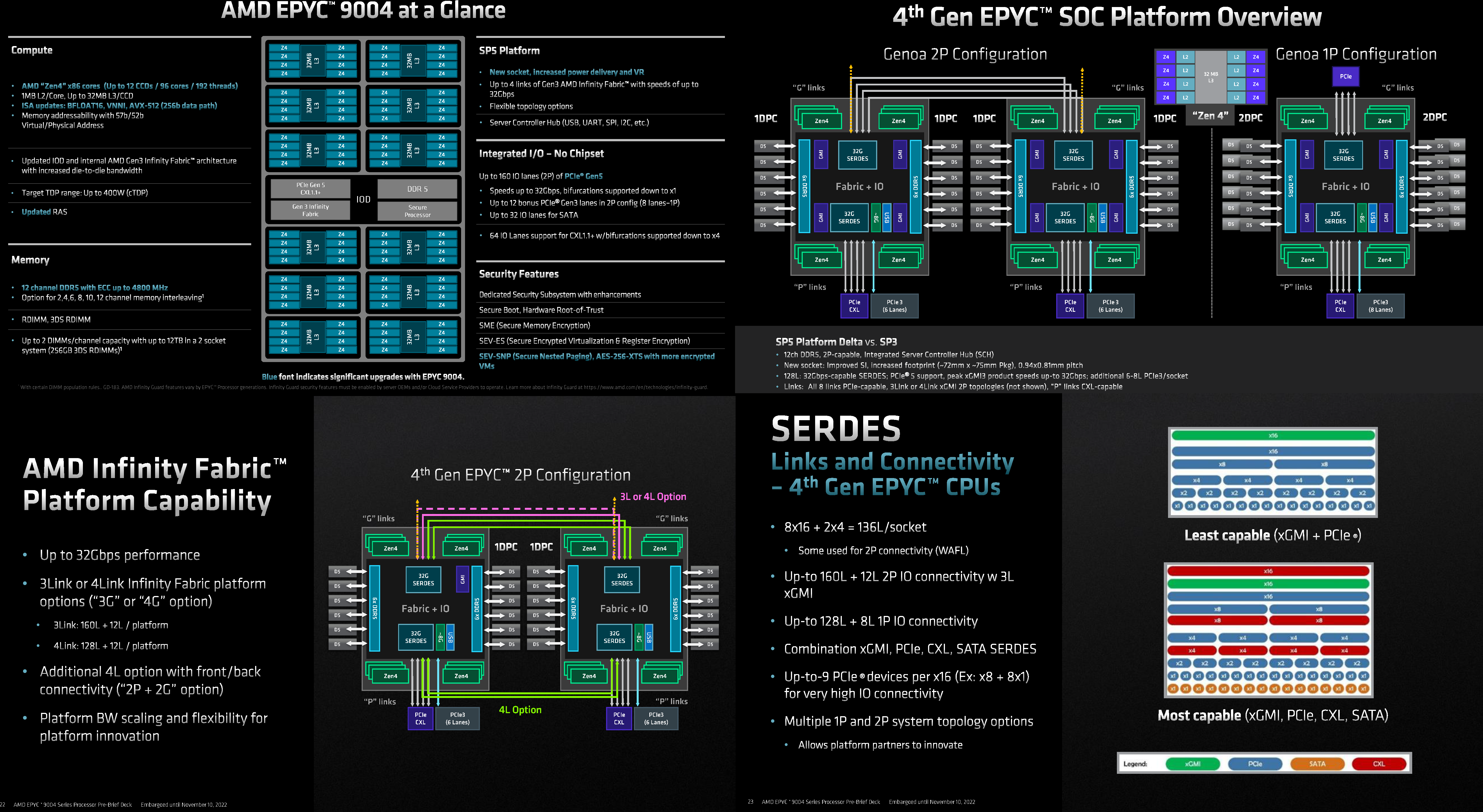
Изображения: AMD (via SemiAnalysis) В-третьих, каждый root-комплекс x16 может быть поделён между девятью устройствами (вплоть до x8 + восемь x1). Часть линий можно отдать на SATA (до 32 шт.), хотя это довольно расточительно. Но главное не это! Из 128 линий 64 поддерживают в полном объёме CXL 1.1 и частично CXL 2.0 Type 3, причём возможна бифуркация вплоть до x4. Ради такой поддержки CXL выход Genoa задержался на два квартала, но оно того определённо стоило — к процессору можно подключать RAM-экспандеры. И решения SK Hynix уже валидированы для новой платформы. CXL-память будет выглядеть как NUMA-узел (без CPU) — задержки обещаны примерно те же, что и при обращении к памяти в соседнем сокете, а пропускная способность одного CXL-подключения x16 почти эквивалентна двум каналам DDR5. При этом для CXL-памяти прозрачно поддерживаются всё те же функции безопасности, включая SME/SEV/SNP (теперь ключей стало аж 1006, а алгоритм обновлён до 256-бит AES-XTS). Отдельно для CXL-памяти внедрена поддержка SMKE (secure multi-key encryption), с помощью которой гипервизор может оставлять зашифрованными выбранные области SCM-устройств (до 64 ключей) между перезагрузками. 
Изображения: AMD (via SemiAnalysis) Такая гибкость при работе с памятью крайне важна для тех же гиперскейлеров. DDR5 по сравнению с DDR4 вчетверо плотнее, вполовину быстрее и… пока значительно дороже. И здесь AMD снова пошла им навстречу, добавив поддержку 72-бит памяти, а не только стандартной 80-бит, сохранив и расширив механизмы коррекции ошибок. 10-% разница в количестве DRAM-чипов при сохранении той же ёмкости на масштабах в десятки и сотни тысяч серверов выливается в круглую сумму. Кроме того, в Genoa сглажена разница в производительности между одно- и двухранговыми модулями с 25 % (в случае Milan) до 4,5 %. Что примечательно, AMD удалось сохранить сопоставимый уровень задержки обращений к памяти между поколениями CPU: 118 нс против 108 нс, из которых только 3 нс приходится на IO-блок, а 10 нс уже на саму память. Теоретическая пиковая пропускная способность памяти составляет 460,8 Гбайт/с на сокет. Однако тут есть нюансы. Genoa имеет 12 каналов памяти DDR5-4800, которые способны вместить до 6 Тбайт RAM. Однако сейчас фактически доступен только режим 1DPC, а вот 2DPC, судя по всему, появится только в следующем году. Genoa поддерживает модули (3DS) RDIMM и предлагает чередование с шагом в 2, 4, 6, 8, 10 или 12 каналов. 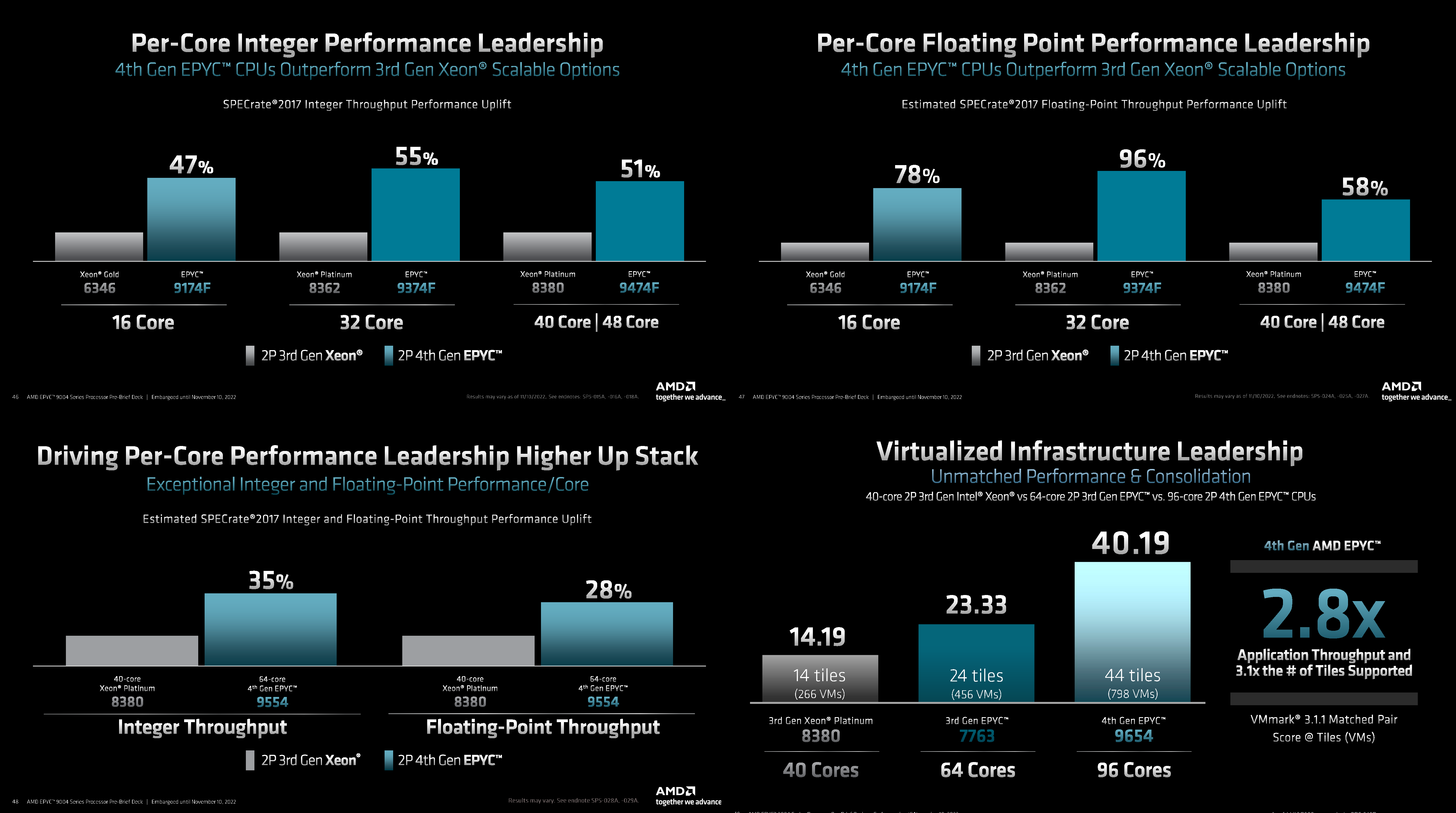
Изображения: AMD (via SemiAnalysis)
Каждый чип можно разбить на два (NPS2) или четыре (NPS4) равных NUMA-домена, а при большом желании и «прибить» L3-кеш к ядрам в том же CCD, получив уже 12 доменов. Но, по словам AMD, это нужно лишь в редких случаях, чтобы выжать ещё несколько процентов производительности. И это снова возвращает нас к особенностям IO-блока. Дело в том, что у каждого CCD есть сразу два GMI-порта. Но в конфигурациях с 8 и 12 CCD используется только один из них, а вот в случае 4 CCD — оба. Интересно, задействует ли AMD «лишние» порты для подключения других блоков. Впрочем, AMD, имея столь гибкие возможности конфигурации моделей, ограничилась относительно скромным начальным набором CPU, которые включает всего 18 моделей с числом ядер от 16 до 96, из которых четыре имеют индекс P (односокетные, чуть дешевле) и четыре — F (выше частота, больше объём L3-кеша). Модельный ряд условно делится на три группы: повышенная производительность на ядро (F-серия), повышенная плотность ядер и повышенный показатель TCO (с относительно малым количеством ядер). 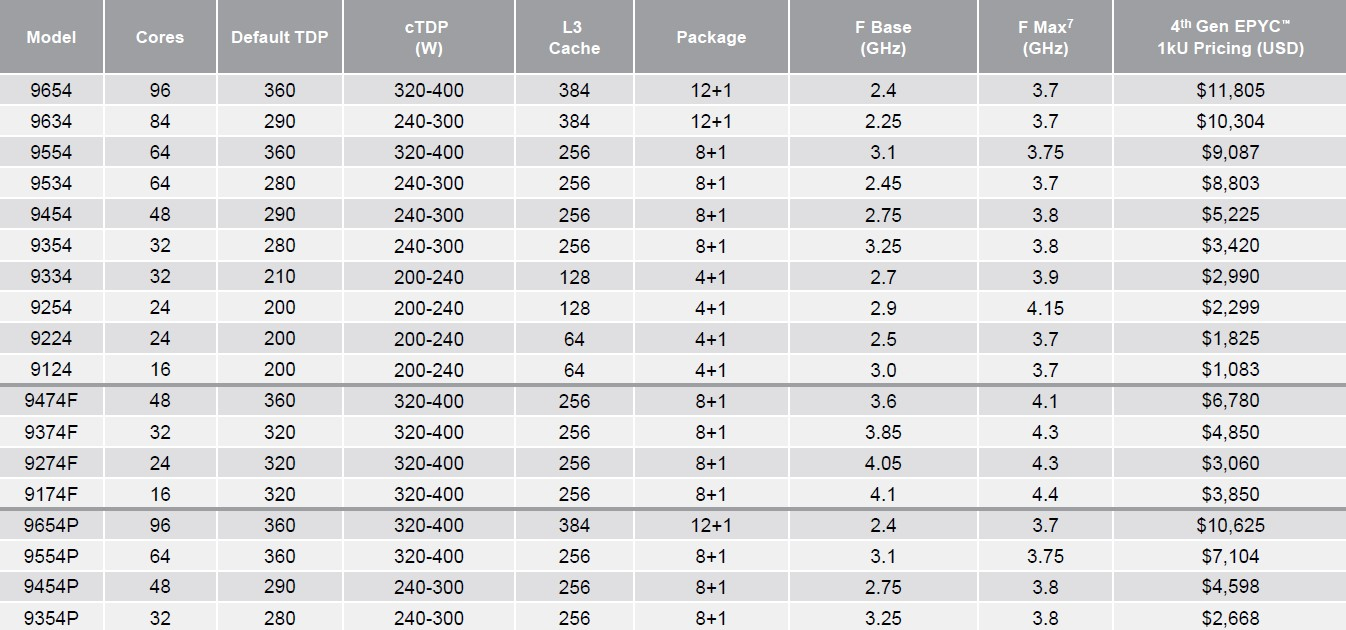
Источник: AMD (via ServeTheHome) На первый взгляд может показаться, что и цены на новинки заметно выросли, но это не совсем так. Например, у топовых моделей условная стоимость одного ядра (а их стала в полтора раза больше) так и крутится около «магического» значения в $123. Но с учётом возросшей производительности на ценовую политику AMD просто грех жаловаться. Прирост IPC между Zen3 и Zen4 составил 14 %, в том числе благодаря увеличению L2-кеша до 1 Мбайт на ядро (L1 и L3 остались без изменений), но не только. Есть и другие улучшения. Например, обновлённый контроллер прерываний AVIC позволяет практически полностью насытить не только 200G, но 400G NIC. С учётом чуть возросших частот и просто катастрофической разнице в количестве ядер топовый вариант Genoa не только значительно обгоняет Milan, но и в два-три раза быстрее старшего Ice Lake-SP. Дело ещё в и том, что Genoa обзавелись поддержкой AVX-512, в том числе инструкций VNNI (DL Boost), которыми так долго хвасталась Intel, а также BF16. Но реализация сделана иначе. У Intel используются «полноценные» 512-бит блоки, дорогие с точки зрения энергопотребления и затрат кремния. AMD же пошла по старому пути, используя 256-бит операции и несколько циклов, что позволяет не так агрессивно сбрасывать частоты. 
Изображения: AMD (via SemiAnalysis) Переход на новый техпроцесс, а также обновлённые подсистемы мониторинга и управления питанием позволили сохранить TDP в разумных пределах от 200 Вт до 360 Вт (cTDP до 400 Вт), что всё ещё позволяет обойтись воздушным охлаждением — всего + 80 Вт для старших процессоров при полуторакратном росте числа ядер. Таким образом, AMD имеет полное право заявлять, что Genoa лидирует по производительности, плотности размещения вычислительных мощностей, энергоэффективности и, в целом, по уровню TCO. У Intel же пока преимущество в более высокой доступности продукции в сложившейся геополитической обстановке. Отдельный вопрос, как AMD будет распределять имеющиеся мощности по выпуску Genoa между гиперскейлерами, корпоративным сектором и HPC-сегментом. Впрочем, компания в любом случае меняет рынок, иногда неожиданным образом. В частности, VMware, которая когда-то из-за EPYC изменила политику лицензирования, была вынуждена дополнительно оптимизировать свои продукты для Genoa. В конце концов, где вы раньше видели 2S-платформу со 192 ядрами и 384 потоками?
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
|
|


