Лента новостей
|
28.03.2023 [14:37], Владимир Мироненко
TikTok как угроза нацбезопасности: новый ЦОД cоцсети «отобрал» энергию у оборонного предприятия в НорвегииНорвежско-финская компания Nammo, специализирующаяся на производстве боеприпасов, реактивных двигателей и космического оборудования, обвинила сервис TikTok в препятствовании потенциальному расширению её мощностей в связи с нехваткой электроэнергии, поскольку новый ЦОД, назвавший китайскую компанию своим основным клиентом, использует все излишки электроэнергии в регионе. «Мы обеспокоены тем, что нашему будущему росту мешает хранение видео с кошками», — сообщил ресурсу Financial Times исполнительный директор Nammo. Норвежский оператор ЦОД Green Mountain строит для TikTok новый кампус: к ноябрю 2023 года будут возведены три 30-МВт модуля, а к 2025 году планируется достроить ещё два таких же блока. Строительство ведётся в Хамаре, в 25 км от Рауфосса, где находится завод Nammo. Местная энергетическая компания Elvia подтвердила, что в энергосети нет свободных мощностей, они распределяются в порядке очереди и уже обещаны TikTok. 
Изображение: Green Mountain Nammo заявила, что спрос на артиллерийские снаряды сейчас в 15 с лишним раз выше, чем ранее. По её словам, Европа должна инвестировать €2 млрд в новые заводы только для того, чтобы удовлетворить спрос Евросоюза и других стран: «Мы видим необычайный спрос на нашу продукцию, которого никогда не было в нашей истории». В сложившейся ситуации это идёт в разрез с планами Норвегии стать «фантастической площадкой» для размещения дата-центров. Местные власти сообщили, что будут способствовать реализации планов Nammo по расширению, так как обеспечение возможности развития компании — в национальных интересах. Глава Nammo указал на необходимость установления приоритетов в отношении того, какие отрасли будут иметь особый доступ к энергии. «Для Европы это серьезная проблема касательно промышленности: критически важные отрасли должны иметь доступ к энергии», — заявил он. Эксперты прогнозируют обострение борьбы за приоритетный доступ к энергии по всей Европе. Если раньше ЦОД имели возможность пользоваться в скандинавских странах дешевым электричеством, получая выгоду от более холодного климата, позволяющего снизить затраты на охлаждение, то в связи с переходом на экологически чистую энергию компании аккумуляторного сектора и сталелитейной промышленности тоже устремятся в северные страны. А это повлечёт за собой рост конкуренции за доступ к энергии.
24.03.2023 [20:28], Алексей Степин
Kioxia анонсировала серверные SSD на базе XL-FLASH второго поколенияПо мере внедрения новых версий PCI Express растут и линейные скорости SSD. Не столь давно 3-4 Гбайт/с было рекордно высоким показателем, но разработчики уже штурмуют вершины за пределами 10 Гбайт/с. Компания Kioxia, крупный производитель флеш-памяти и устройств на её основе, объявила на конференции 2023 China Flash Market о новом поколении серверных накопителей, способных читать данные со скоростью 13,5 Гбайт/с. Новые высокоскоростные SSD будут построены на базе технологии XL-FLASH второго поколения. Первое поколение этих чипов компания (тогда Toshiba) представила ещё в 2019 году. В основе лежат наработки по BiCS 3D в однобитовом варианте, что позволяет устройствам на базе этой памяти занимать нишу Storage Class Memory (SCM) и служить заменой ушедшей с рынка технологии Intel Optane. 
Источник здесь и далее: Twitter@9550pro Как уже сообщалось ранее, XL-FLASH второго поколения использует двухбитовый режим MLC, но в любом случае новые SSD Kioxia в полной мере раскроют потенциал PCI Express 5.0. Они не только смогут читать данные на скорости 13,5 Гбайт/с и записывать их на скорости 9,7 Гбайт/с, но и обеспечат высокую производительность на случайных операциях: до 3 млн IOPS при чтении и 1,06 млн IOPS при записи. Время отклика для операций чтения заявлено на уровне 27 мкс, против 29 мкс у XL-FLASH первого поколения.  Kioxia полагает, что PCI Express 5.0 и CXL 1.x станут стандартами для серверных флеш-платформ класса SCM надолго — господство этих интерфейсов продлится минимум до конца 2025 года, лишь в 2026 году следует ожидать появления первых решений с поддержкой PCI Express 6.0. Активный переход на более новую версию CXL ожидается в течение 2025 года. Пока неизвестно, как планирует ответить на активность Kioxia другой крупный производитель флеш-памяти, Samsung Electronics, которая также располагает высокопроизводительной разновидностью NAND под названием Z-NAND.
22.03.2023 [22:02], Алексей Степин
AMD и NVIDIA победили: NEC останавливает разработку уникальных векторных процессоров SX-AuroraЯпонская компания NEC была одной из немногих, отстаивавших собственный уникальный путь в сфере развития вычислительных технологий со своими векторными процессорами SX-Aurora. Хотя данное направление до недавних пор активно развивалось, компания, похоже, не выдержала давления со стороны NVIDIA и AMD и объявила о прекращении разработок новых решений в серии Aurora. Работы над усовершенствованием векторной архитектуры NEC продолжались до конца прошлого года, когда компания объявила о подготовке новых вычислительных узлов SX-Aurora TSUBASA C401-8 на базе ускорителей с 16 блоками Vector Engine 3.0 и 96 Гбайт интегрированной памяти HBM2. И хотя в августе этого года в Научном центре Университета Тохоку будет запущен новый суперкомпьютер на их основе, новых разработок в этой сфере не будет. 
Вычислительный модуль SX-Aurora TSUBASA C401-8. Источник изображений здесь и далее: NEC Как отметил Сатоши Мацуока (Satoshi Matsuoka), глава крупнейшего в Японии суперкомпьютерного центра RIKEN, где был создан суперкомпьютер Fugaku, NEC неслучайно объявила об отказе от разработки нового поколения процессоров SX-Aurora. Хотя в целях компании значилось 10-кратное повышение энергоэффективности, теперь NEC считает, что эта цель может быть достигнута с использованием стандартных коммерческих ускорителей. Главной причиной называется появление решений AMD и NVIDIA, на голову превосходящих все наработки NEC. В частности, упоминается AMD Instinct MI300. При этом отмечено, что это решение «похоронило» бы даже новое поколение SX-Aurora, когда речь заходит о ПСП. Целью NEC был показатель 2+ Тбайт/с, в то время как новинка AMD, располагая памятью HBM3 с 8192-бит шиной, может обеспечить 6,8 Тбайт/с. 
Планы NEC по развитию VE-архитектуры. Похоже, им уже не суждено сбыться Также «естественным врагом» SX-Aurora является NVIDIA Grace Hopper с его мощной процессорной частью и развитой инфраструктурой NVLink, демонстрирующий к тому же выдающуюся энергоэффективность. Примечательно, что оба продукта от AMD и NVIDIA являются APU, то есть гибридными чипами, объединяющими ускорители и CPU собственной разработки, а также быструю память. Финансовый кризис 2009 года ударил по разработкам NEC в области процессоростроения сильно, но ситуацию тогда спасла общая незрелость рынка GPGPU и технологии HBM. Сейчас на это надеяться нельзя, да и ситуация с точки зрения программной экосистемы в мире HPC говорит не в пользу NEC. По всей видимости, прямо на наших глазах ещё одна уникальная вычислительная архитектура становится достоянием истории.  При этом в Японии пока что сохраняется ещё одна уникальная отечественная архитектура — PEZY-SC. Arm-процессоры Fujitsu A64FX, ставшие основой Fugaku, тоже достаточно уникальны, однако их наследники в лице MONAKA переориентированы на более массовый сегмент. Таким образом, собственные массовые HPC-решения сейчас есть только у Китая, которому новейшие американские и британские ускорители достанутся в кастрированном виде.
22.03.2023 [20:32], Алексей Степин
Экспортный китайский вариант NVIDIA H100 получил модельный номер H800В связи с санкционными ограничениями некоторые разновидности сложных микроэлектронных чипов запрещено экспортировать в Китайскую Народную Республику. Однако производители находят выход. В частности, компания NVIDIA анонсировала экспортный вариант ускорителя H100, не нарушающий никаких санкций. Модельный номер у такого варианта изменён на H800. Введённые правительством США в 2022 году санкции сделали «невыездными» два наиболее продвинутых продукта NVIDIA: A100 и H100. Такие процессоры сегодня являются основой наиболее динамично развивающейся вычислительной отрасли — нейросетевой. Именно на кластерах из таких ускорителей «натаскивают» мощные нейросети вроде ChatGPT и подобных. 
Ускоритель Hopper H100 в SXM-исполнении. Источник изображений здесь и далее: NVIDIA Ещё осенью прошлого года NVIDIA анонсировала A800 — экспортный вариант A100, не попадающий под ограничения за счёт некоторого снижения пропускной способности NVLink, с 600 до 400 Гбайт/с. Сейчас пришло время архитектуры Hopper, которая запущена в массовое производство. По аналогии с флагманом Ampere модернизированный чип получил модельный номер H800. Ограничения в нём реализованы схожим образом: как известно, NVLink в H100 имеет производительность 900 Гбайт/с в базовом SXM-варианте. 
H100 также существует в PCIe-варианте Версия H800 использует примерно половину этого потенциала, что, впрочем, не делает её в Китае менее популярной: новинка уже используется китайскими облачными гигантами, такими, как Alibaba, Baidu и Tencent. Есть ли у H800 другие отличия от H100, не говорится — NVIDIA пока отказывается предоставлять такую информацию. Достоверно известно лишь то, что они полностью соответствуют всем санкционным ограничениям. Интересно, появится ли в будущем вариант H800 NVL на базе NVIDIA H100 NVL.
22.03.2023 [00:09], Алексей Степин
NVIDIA показала сдвоенный серверный суперпроцессор Grace SuperchipПроект NVIDIA Grace весьма амбициозен: компания всерьёз намерена ворваться с его помощью на рынок высокопроизводительных серверных процессоров, где всё ещё доминируют решения Intel и AMD. Об этом чипе было объявлено ещё на конференции GTC 2022, а на GTC 2023 глава компании, наконец, показал его вживую. В рамках продолжающегося роста плотности упаковки вычислительных мощностей в современных ЦОД на первый план выдвинулась не голая производительность, а соотношение производительности к уровню энергопотребления и тепловыделения. По сочетанию этих параметров x86 далеко не оптимальна, и тут у NVIDIA есть все шансы. С анонсом Grace Superchip NVIDIA провозглашает (впрочем, уже не в первый раз) смерть «закона Мура» — пришло время оптимизации и отказа от устаревших, по мнению компании, вычислительных архитектур. 
Источник изображений здесь и далее: NVIDIA Процессор NVIDIA Grace воплощает в себе все современные тенденции, начиная с отказа от монолитного кристалла. Сборка Grace Superchip состоит из двух кристаллов, каждый из которых включает в себя 72 ядра Arm Neoverse V2 (Arm v9), поддерживающих векторные расширения SVE2 и оптимизированные для ИИ форматы BF16/INT8. Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с.  В сборку интегрированы чипы памяти LPDDR5x общим объёмом до 960 Гбайт, причём каждый кристалл имеет свою шину доступа к памяти с производительностью 500 Гбайт/с. При этом с точки зрения ПО Grace Superchip представляется единым 144-ядерным процессором с ПСП на уровне 1 Тбайт/с. 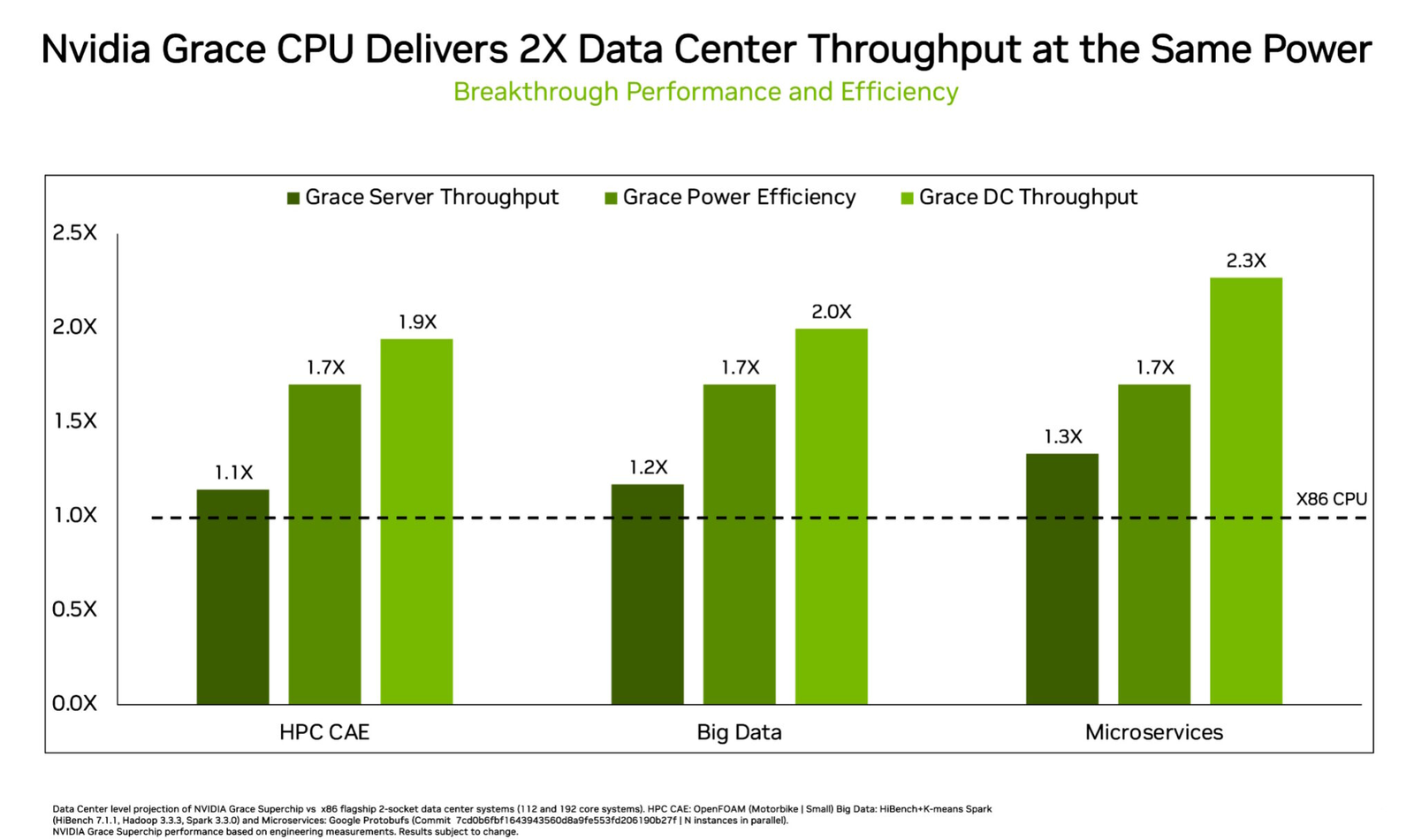 Для достижения схожих параметров в мире x86 требуется двухпроцессорная платформа AMD Genoa, куда более сложная технически и гораздо менее энергоэффективная, но при этом обладающая всеми недостатками NUMA-систем. Достаточно сравнить энергопотребление: 900 Вт против 500 у нового решения NVIDIA. 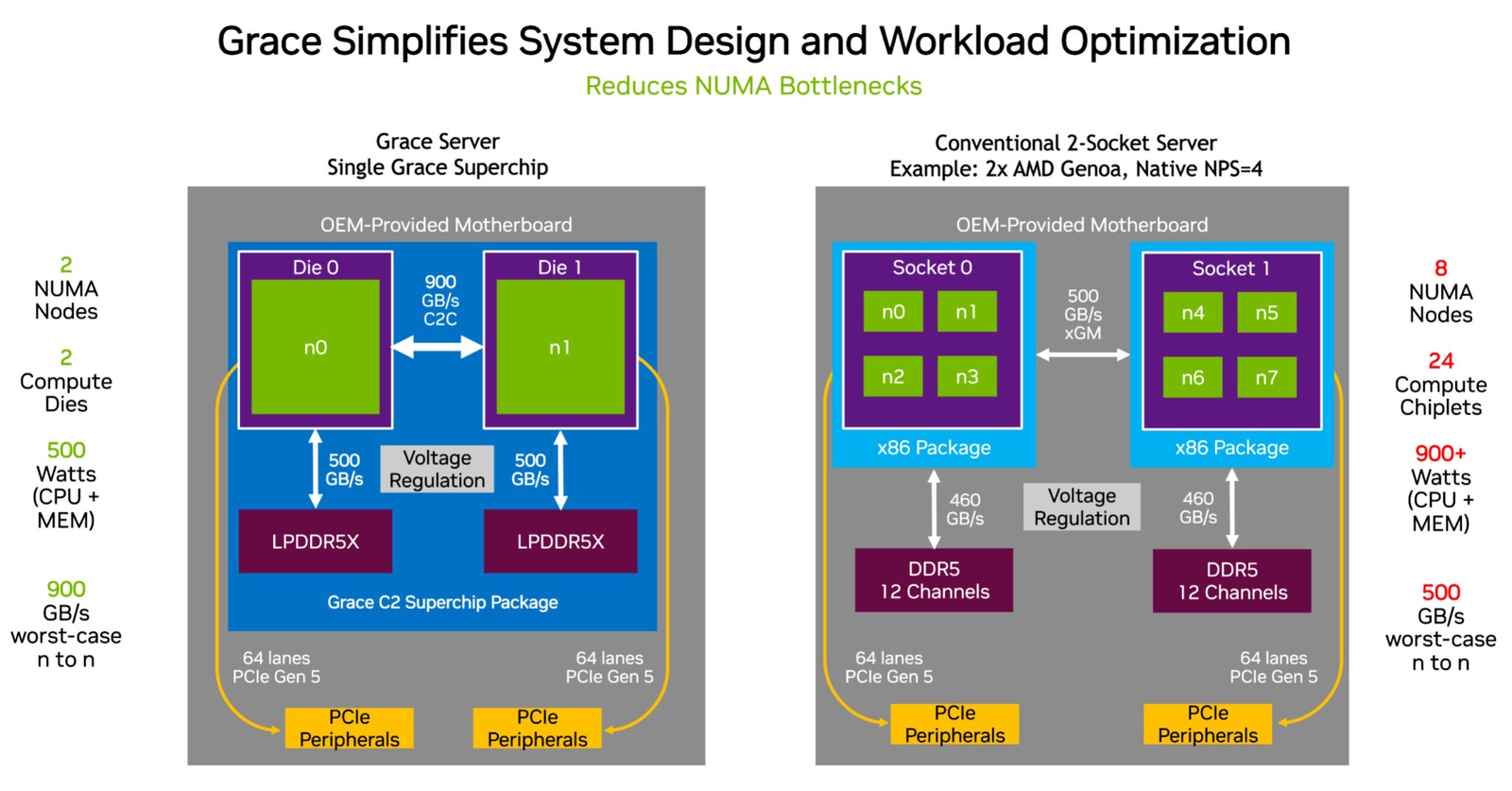 NVIDIA есть чем гордиться: при сопоставимом уровне энергопотребления Grace Superchip превосходит своих конкурентов из мира x86 в 2,3 раза при запуске микросервисов, вдвое опережает их в приложениях с интенсивным обменом данными с памятью и почти вдвое — в задачах симуляции вычислительной гидродинамики. В ряде других научно-технических задач преимущество может быть и более чем двукратным. 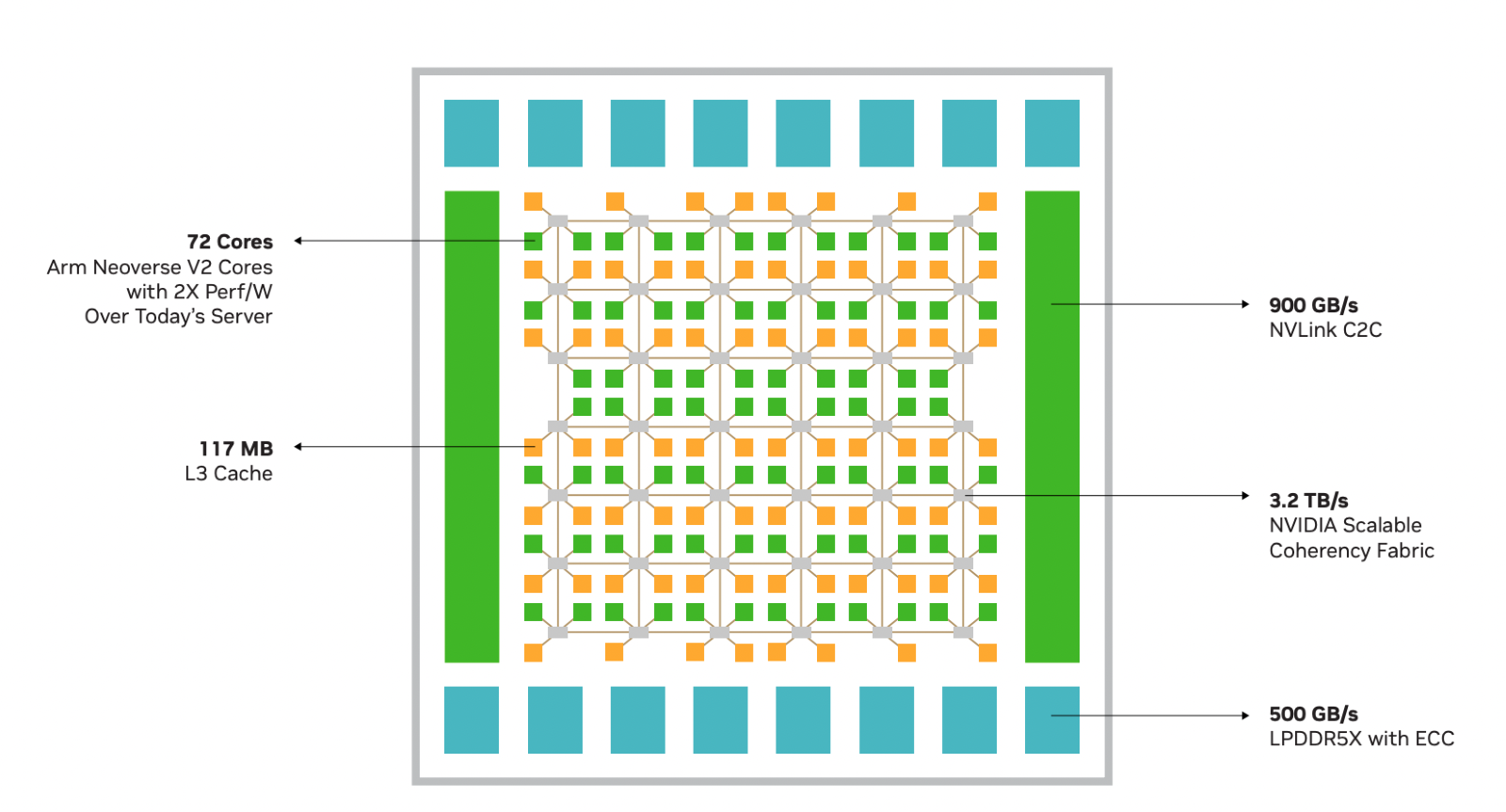 Это достигнуто в том числе благодаря изначальной оптимизации дизайна процессора с упором на максимальную производительность передачи данных. Внутренне Grace организован по принципу меш-сети с распределённой системой кеширования на базе специальных узлов коммутации CSN (Cache Switch Nodes). Называется эта сеть Scalable Coherency Fabric, она имеет пропускную способность 3,2 Тбайт/с, а объём кеша L3 составляет 117 Мбайт на кристалл и 234 Мбайт совокупно.  Сервер на базе NVIDIA Grace не только может потреблять меньше энергии, но и будет существенно проще конструктивно, поскольку модуль Grace Superchip содержит не только процессорные ядра и память, но также и регуляторы напряжения. От платформы на базе нового процессора требуется только PCIe 5.0 — у нового чипа есть два набора по 64 линии. Причём линии с поддержкой CXL 2.0, так что проблем с расширением доступного объёма памяти новинка испытывать не будет.  Даже компактные серверы высотой 1U смогут вместить две сборки Grace Superchip, что даст 288 ядер и почти 2 Тбайт оперативной памяти — труднодостижимый в таких габаритах показтель для более традиционных конструктивов процессоров и системных плат. Сравнительно невысокий теплопакет позволит таким решениям обходиться традиционным воздушным охлаждением.  При этом есть и вариант Grace Hopper, сочетающий в одном модуле кристалл Grace и новейший GPU H100, причём параметрами PCI Express последний ограничен не будет благодаря NVLink-C2C. NVIDIA уже начала первичные поставки Grace, а начало полномасштабного производства ожидается во второй половине года. Новыми процессорами заинтересовались крупные производители оборудования, включая ASUS, Atos, GIGABYTE, HPE, QCT, Supermicro, Wistron и ZT Systems.  Лос-Аламосская национальная лаборатория объявила, что использует NVIDIA Grace в новом суперкомпьютере Venado, который поможет учёным в исследованиях новых материалов и возобновляемых источников энергии. Ряд крупных европейских и азиатских ЦОД также рассматривает перспективы применения новых процессоров NVIDIA. В частности, одной из систем на базе Grace станет кластер Alps в Швейцарском национальном компьютерном центре.
21.03.2023 [20:45], Владимир Мироненко
NVIDIA запустила облачный сервис DGX Cloud — доступ к ИИ-супервычислениям прямо в браузереNVIDIA запустила сервис ИИ-супервычислений DGX Cloud, предоставляющий предприятиям доступ к инфраструктуре и программному обеспечению, необходимым для обучения передовых моделей для генеративного ИИ и других приложений. DGX Cloud предлагает выделенные ИИ-кластеры NVIDIA DGX в сочетании с фирменным набором ПО NVIDIA. С его помощью предприятие сможет получить доступ к облачному ИИ-суперкомпьютеру, используя веб-браузер и без надобности в приобретении, развёртывании и управлении собственной HPC-инфраструктурой. Правда, удовольствие это всё равно не из дешёвых — стоимость инстансов DGX Cloud начинается от $36 999/мес., причём деньги получает в первую очередь сама NVIDIA. Для сравнения — полностью укомплектованная система DGX A100 в Microsoft Azure обойдётся примерно в $20 тыс. Облачные кластеры DGX предлагаются предприятиям на условиях ежемесячной аренды, что гарантирует им возможность быстро масштабировать разработку больших рабочих нагрузок. «DGX Cloud предоставляет клиентам мгновенный доступ к супервычислениям NVIDIA AI в облаках глобального масштаба», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 
Источник изображения: NVIDIA Развёртыванием инфраструктуры DGX Cloud компания NVIDIA будет заниматься в сотрудничестве с ведущими поставщиками облачных услуг. Первым среди них стала платформа Oracle Cloud Infrastructure (OCI), предлагающая суперкластер (SuperCluster) с объединёнными RDMA-сетью (в том числе на базе BlueField-3 и Connect-X7) системами DGX (bare metal), которые дополняет высокопроизводительное локальное и блочное хранилище. Cуперкластер может включать до 32 768 ускорителей, но этот рекорд был поставлен с использованием DGX A100, а вот предложение DGX H100 пока что ограничено. В следующем квартале похожее решение появится в Microsoft Azure, а потом в Google Cloud и у других провайдеров. 
Источник изображения: NVIDIA Первыми пользователями DGX Cloud стали Amgen, одна из ведущих мировых биотехнологических компаний, лидер рынка страховых технологий CCC Intelligent Solutions (CCC) и провайдер цифровых бизнес-платформ ServiceNow. «Мощные вычислительные и многоузловые возможности DGX Cloud позволили нам в 3 раза ускорить обучение белковых LLM с помощью BioNeMo и до 100 раз ускорить анализ после обучения с помощью NVIDIA RAPIDS по сравнению с альтернативными платформами», — сообщил представитель Amgen. Для управления нагрузками в DGX Cloud предлагается NVIDIA Base Command. Также DGX Cloud включает в себя набор инструментов NVIDIA AI Enterprise для создания и запуска моделей, который предоставляет комплексные фреймворки и предварительно обученные модели для ускорения обработки данных и оптимизации разработки и развёртывания ИИ. DGX Cloud предоставляет поддержку экспертов NVIDIA на всех этапах разработки ИИ. Клиенты смогут напрямую работать со специалистами NVIDIA, чтобы оптимизировать свои модели и быстро решать задачи разработки с учётом сценариев отраслевого использования.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 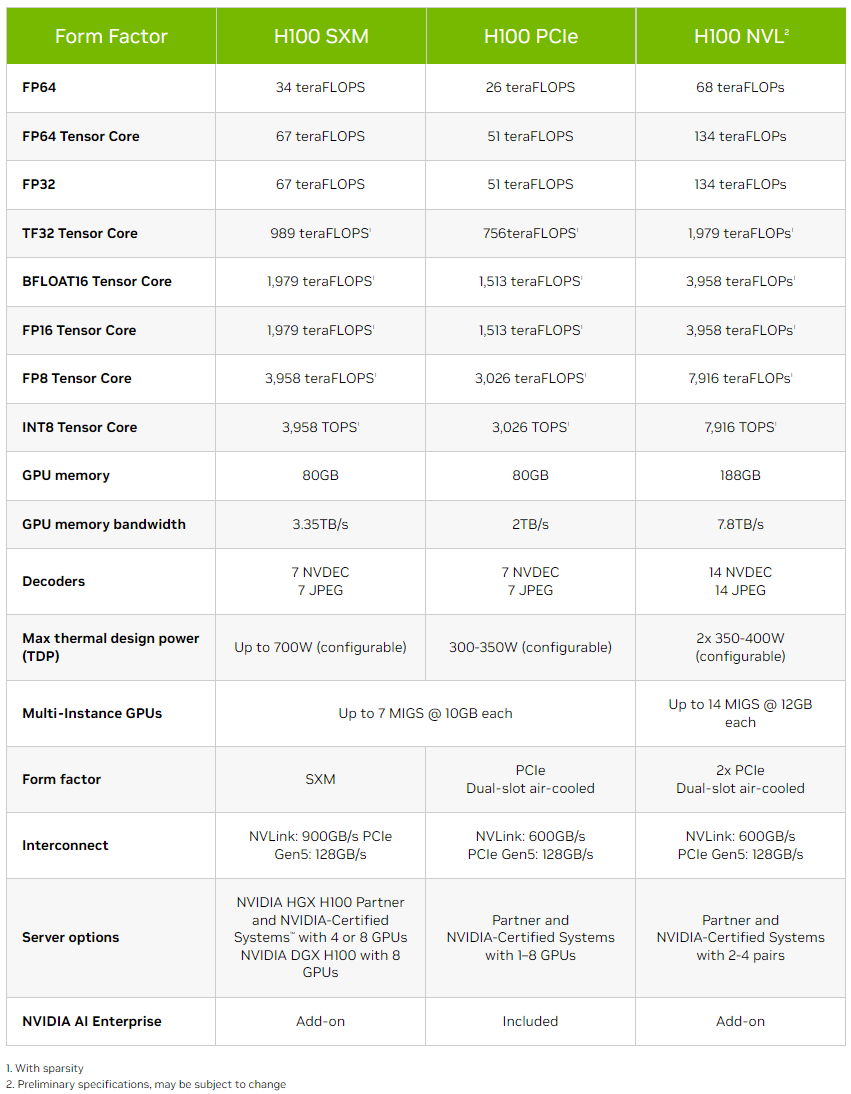 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 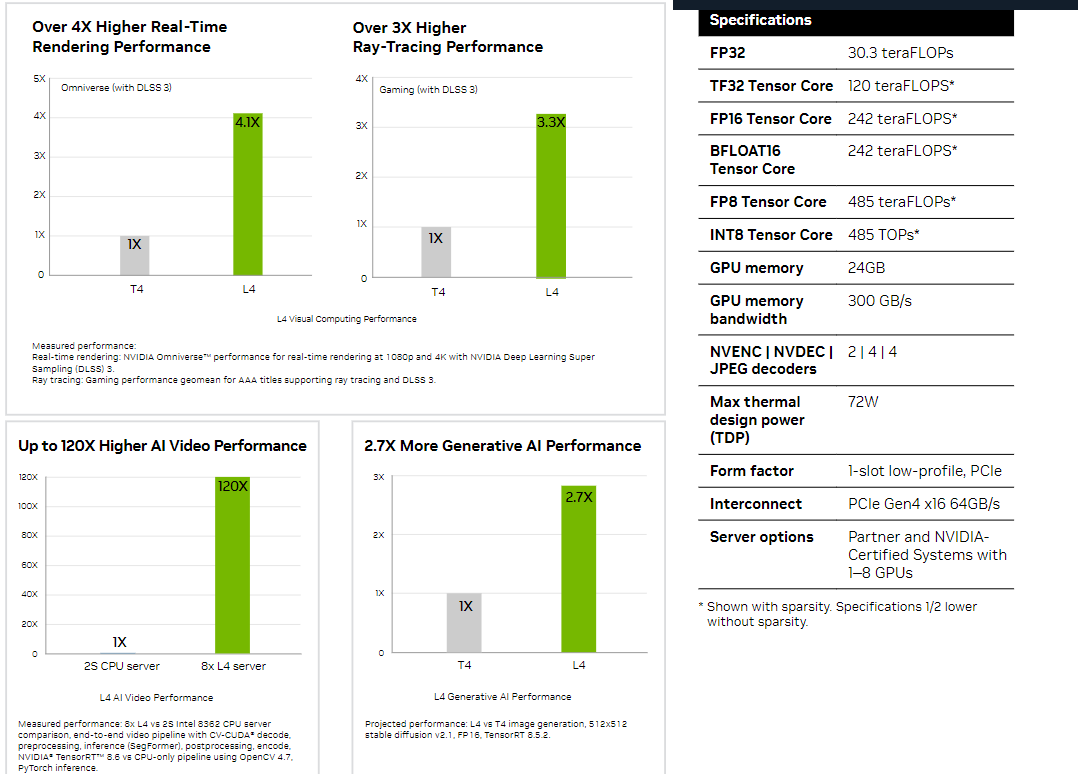
21.03.2023 [19:15], Сергей Карасёв
NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычисленийКомпания NVIDIA в партнёрстве с Quantum Machines анонсировала DGX Quantum — первую систему, объединяющую GPU и квантовые вычисления. Решение использует новую открытую программную платформу CUDA Quantum. Утверждается, что система предоставляет революционно архитектуру для исследователей, работающими с гибридными вычислениями с низкой задержкой. NVIDIA DGX Quantum объединяет средства ускоренных вычислений на базе Grace Hopper (Arm-процессор + ускоритель H100), модели программирования с открытым исходным кодом CUDA Quantum и передовую квантовую управляющую платформу Quantum Machines OPX+. Такая комбинация позволяет создавать ресурсоёмкие приложения, сочетающие квантовые вычисления с современными классическими вычислениями. При этом в числе прочего обеспечивается работа гибридных алгоритмов и коррекция ошибок. 
Источник изображения: NVIDIA Представленное решение предполагает соединение Grace Hopper и Quantum Machines OPX+ посредством интерфейса PCIe. Это обеспечивает задержку менее микросекунды между ускорителем и блоками квантовой обработки (QPU). Отмечается, что OPX+ — это универсальная система квантового управления. Таким образом, можно максимизировать производительность QPU и предоставить разработчикам новые возможности при использовании квантовых алгоритмов. Системы Grace Hopper и OPX+ можно масштабировать в соответствии с потребностями — от QPU с несколькими кубитами до суперкомпьютера с квантовым ускорением. 
Источник изображения: NVIDIA О намерении интегрировать CUDA Quantum в свои платформы уже заявили компании по производству квантового оборудования Anyon Systems, Atom Computing, IonQ, ORCA Computing, Oxford Quantum Circuits и QuEra, разработчики ПО Agnostiq и QMware, а также некоторые суперкомпьютерные центры.
17.03.2023 [14:10], Сергей Карасёв
Разработчики Linux отказались принимать апдейты от «Байкал Электроникс»Сообщество разработчиков ядра Linux отказалось принимать от российской компании «Байкал Электроникс» патчи для ядра. О запрете, как отмечает ресурс Phoronix, сообщил Якуб Кичиньский (Jakub Kicinski), занимающийся поддержкой сетевой подсистемы Linux. «Нам некомфортно принимать патчи от вашей организации или обновления, связанные с произведённым вами оборудованием», — заявил господин Кичиньский в переписке с Сергеем Сёминым, сотрудником «Байкал Электроникс». Дело в том, что российский разработчик процессоров и SoC с архитектурами MIPS и Arm находится под европейскими и американскими санкциями. В этой связи Якуб Кичиньский посоветовал «Байкал Электроникс» воздержаться от внесения изменений в сетевую подсистему ядра Linux «до дальнейшего уведомления». Отметим, что именно благодаря «Байкал Электроникс» в ядре Linux появилась полноценная поддержка Warrior P5600 — именно это решение лежит в основе чипа «Байкал-Т1». 
Источник изображения: «Байкал Электроникс» Как уточняет Phoronix, отказ принимать патчи последовал после того, как «Байкал Электроникс» предложила ряд исправлений для сетевого драйвера STMMAC. Он предназначен для Ethernet-контроллеров Synopsys, которые используются в решениях российской компании. «Серия исправлений, о которой идёт речь, не относится непосредственно к решениям "Байкал Электроникс", а представляет собой всего лишь исправления для сетевого драйвера Synopsys, используемого несколькими различными аппаратными платформами/организациями», — подчёркивается в публикации.
14.03.2023 [15:56], Алексей Степин
AMD анонсировала процессоры EPYC Embedded 9004 для промышленных системВстраиваемые решения AMD привлекают не так много внимания как настольные или серверные, но в арсенале компании представлены широко — от экономичных Ryzen Embedded для индустриальных и встраиваемых ПК до мощных EPYC Embedded. Именно о последних сегодня пойдет речь, поскольку на выставке Embedded World 2023 компания представила новую серию процессоров EPYC Embedded 9004 (Genoa). Свою родословную новые EPYC Embedded ведут от обычных серверных чипов EPYC Genoa. AMD позиционирует новинки в качестве решений для автоматизации в промышленности, телекоммуникациях, (I)IoT и периферийных вычислениях — везде, где требуется сочетание высокой удельной производительности с энергоэффективностью. 
Источник изображений здесь и далее: AMD Новая платформа представлена в одно- и двухсокетных вариантах. Максимальное количество процессорных ядер Zen 4 составляет 96 (SMT2), а объём кеша L3 может достигать внушительных 384 Мбайт. 12-канальный контроллер памяти с поддержкой DDR5-4800 ECC (3DS) RDIMM и NV-DIMM (важно для устойчивости к потере питания и быстрого восстановления работоспособности) тоже никуда не делся. 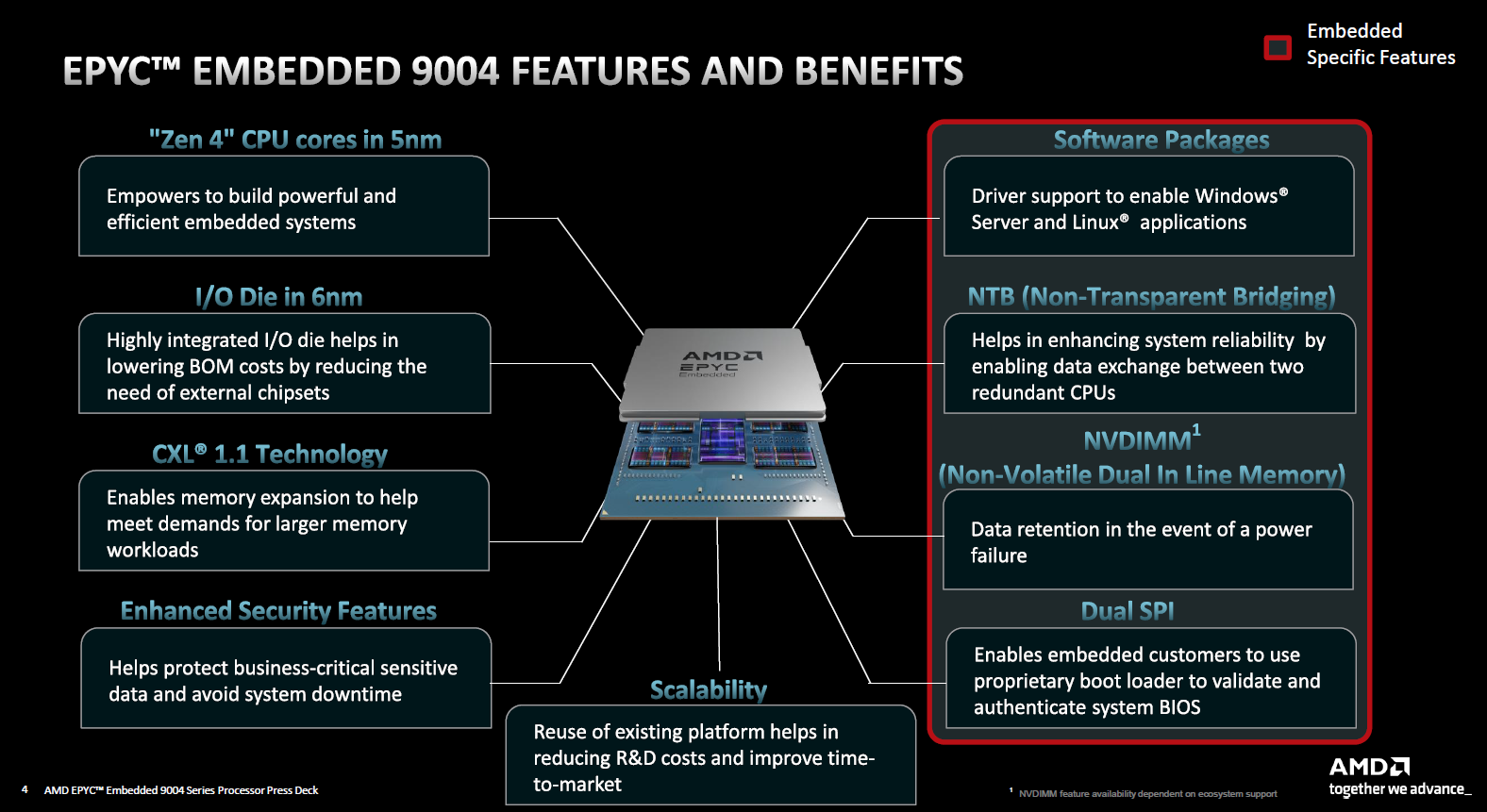 Всего в новой серии AMD представила 10 моделей EPYC Embedded 9004, с числом ядер от 16 до 96, различными частотными формулами, объёмами кеша L3 и теплопакетами в диапазоне от 200 до 360 Вт (cTDP до 400 Вт). Варианты для однопроцессорных систем располагают 128 линиями PCIe 5.0, а 2S-системы предлагают до 160 линий. Поддерживается CXL 1.1, включая устройства CXL.mem. Сокет CPU всё тот же — 6096-контактный SP5. 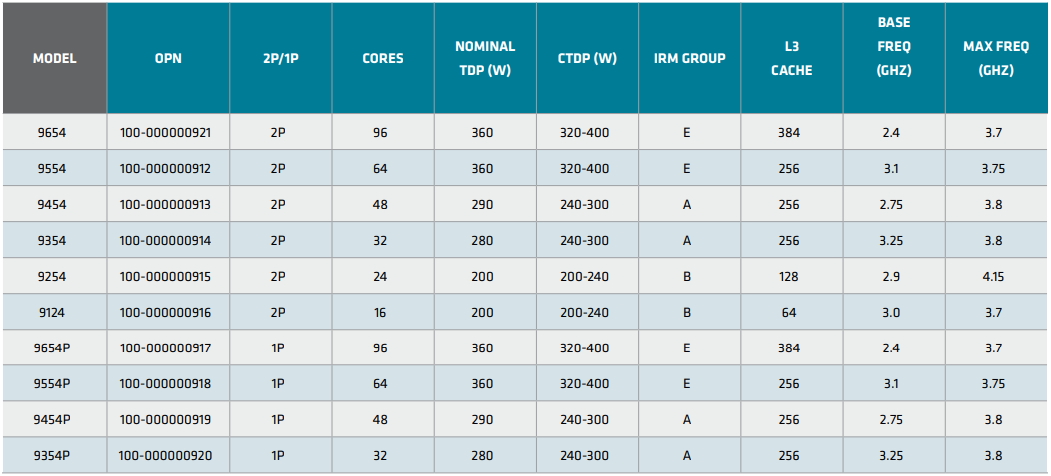 Кое-чем новые EPYC Embedded отличаются от своих обычных собратьев. В частности, отдельно отмечается поддержка Non-Transparent Bridge (NTB), что важно для формирования двухконтроллерных платформ, а также наличие технологии Scalable Control Fabric, которая позволяет более тонко конфигурировать межсоединения между чиплетами. Кроме того, например, сообщается о наличии второго канала SPI, что позволяет обеспечить дополнительную защиту и верификацию образов BIOS/UEFI. 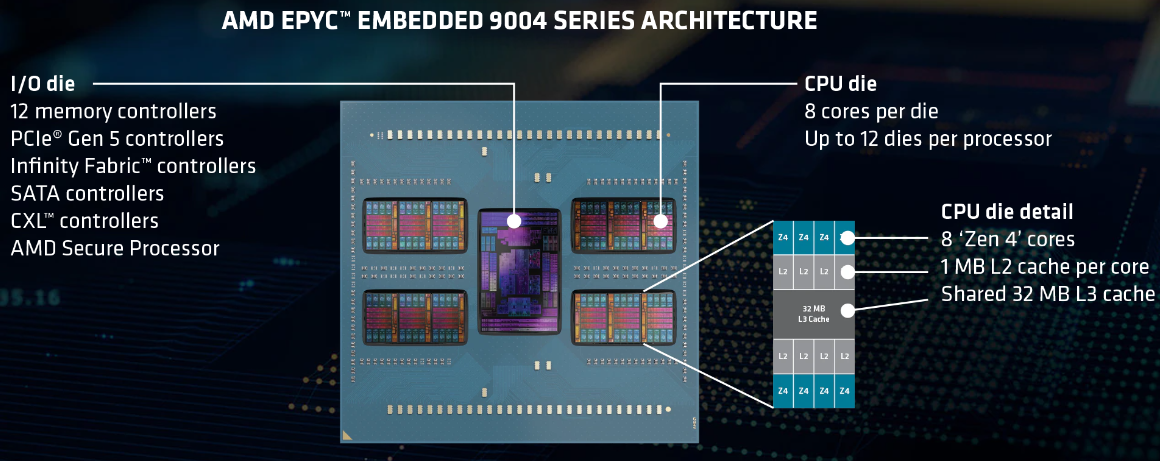 В числе главных партнёров AMD по внедрению новой платформы EPYC Embedded числятся компании Advantech и Siemens, уже анонсировавшие решения на базе новых процессоров. В качестве примера можно привести новый сервер Siemens SIMATIC IPC RS-828A или системную плату Advantech ASMB-831. Процессоры AMD EPYC Embedded 9004 уже доступны в небольших пробных партиях, но и начало массовых поставок не за горами, оно намечено уже на апрель текущего года.  В настоящее время «пробный комплект разработчика», в который входит референс-плата с процессором, полный комплект документации и программный инструментарий, доступен избранным партнёрам AMD. Также стоит отметить, что у новой платформы расширенный жизненный цикл, составляющий 7 лет, и без поддержки в ближайшее десятилетие оборудование на базе EPYC Embedded 9004 не останется. |
|

