Материалы по тегу: инференс
|
14.02.2025 [13:24], Руслан Авдеев
Эксперты прогнозируют охлаждение рынка ИИ-серверов в 2025 годуТехнологические санкции США и подготовка цепочки поставок к поступлению на рынок новейшего оборудования NVIDIA, вероятно, приведут к снижению объёмов продаж ИИ-серверов в 2025 году, сообщает The Register со ссылкой на мнение независимых экспертов. Так, TrendForce сообщает, что поставки ИИ-серверов в прошлом году выросли на 46 %, преимущественно благодаря заказам провайдеров облачных сервисов (CSP). В частности, производитель серверов Foxconn объяснил недавний рекордный рост выручки именно продажами ИИ-серверов. При этом в TrendForce рассматривают несколько вариантов развития событий на рынке серверов в 2025 году из-за неопределённости, царящей в нише ИИ-решений. Наиболее вероятным считается дальнейшее расширение рынка, но с более низким годовым приростом. Впрочем, даже в таких условиях он может превысить 30 % — Microsoft, Meta✴, Amazon и Google намерены увеличить капитальные затраты на ИИ-инфраструктуру. Как ожидается, это будет способствовать поддержке спроса на ИИ-серверы. Наихудшим сценарием, по оценке TrendForce, причём следующим по вероятности, является рост поставок ИИ-серверов до «всего» 20–25 %. Этот прогноз учитывает ужесточение США экспорта ИИ-чипов в Китай, что создаёт большую неопределённость на рынке. Кроме того, не исключены задержки поставок стоечных решений NVIDIA на основе суперчипов Grace Blackwell — их структура довольно сложна, поэтому масштабное развёртывание откладывается на II половину года. 
Источник изображения: Foxconn Более оптимистичный сценарий предполагает, что масштабные проекты в Китае и США (например, Stargate) помогут ускоренному развёртыванию ИИ-серверов. Кроме того, хотя триумф DeepSeek может негативно повлиять на необходимость внедрения большого количества ИИ-ускорителей, он же способен расширить применение искусственного интеллекта, стимулируя рост ИИ на периферии. При удачном стечении обстоятельств поставки ИИ-серверов вырастут в 2025 году почти на 35 %. Недавно глава IBM Арвинд Кришна (Arvind Krishna) уже предсказал, что использование аналогичных решениям DeepSeek экономичных и эффективных технологий не только не приведёт к падению рынка, но, наоборот, значительно увеличит использование оборудования после снижения «порога входа» для применения ИИ-моделей. Схожей позиции придерживаются инвесторы в ИИ-инфраструктуру вроде Blackstone и Brookfield, ожидающие, что спрос на ЦОД и оборудование не уменьшится. В TrendForce ожидают, что влияние DeepSeek будет способствовать переходу облачных операторов на недорогие чипы собственной разработки, поскольку акцент в последнее время смещается с обучения ИИ на инференс. В результате серверы, оптимизированные для запуска моделей, займут большую часть рынка. Вероятно, рынок серверов станет более сегментированным, поскольку крупные облачные игроки продолжат инвестиции в высокопроизводительные решения, а корпоративные заказчики будут отдавать предпочтение более экономичным альтернативам.
13.02.2025 [01:05], Владимир Мироненко
Meta✴ намерена купить разработчика ИИ-ускорителей FuriosaAI, и не одна онаMeta✴ ведет переговоры о приобретении южнокорейского стартапа FuriosaAI, разработчика ИИ-ускорителей, базирующегося в Сеуле (Южная Корея) и Санта-Кларе (США), что позволит ей выпускать собственные кастомные чипы на фоне нехватки ускорителей NVIDIA, сообщил Forbes со ссылкой на информированные источники. По словам одного из источников, сделка может быть заключена уже в этом месяце. Другой источник утверждает, что ещё несколько компаний ведут переговоры о приобретении FuriosaAI. Компанию основал в 2017 году Джун Пайк (June Paik), ранее работавший в Samsung Electronics и AMD и занимающий сейчас пост гендиректора. FuriosaAI привлекла в общей сложности около ₩170 млн (около $115 млн) венчурного финансирования. Среди первых инвесторов были южнокорейский интернет-гигант Naver и базирующаяся в Сеуле DSC Investment. В последнем раунде финансирования, прошедшем на прошлой неделе, FuriosaAI получила ₩2 млрд (около $1,4 млн) от южнокорейской CRIT Ventures. В августе прошлого года FuriosaAI представила энергоэффективный ИИ-ускоритель RNGD, который был разработан в партнёрстве с тайваньским производителем микросхем Global Unichip Corp. По словам компании, RNGD является идеальным выбором для крупномасштабного развёртывания продвинутых моделей генеративного ИИ, таких как Llama 2 и Llama 3, поскольку не уступает передовым ускорителям по производительности, отличаясь при этом низким TDP в пределах 150 Вт. 
Источник изображения: FuriosaAI RNGD предназначен для инференса и оснащён HBM3-памятью SK hynix. FuriosaAI сообщила, что RNGD показывает в три раза большую производительность в расчёте на 1 Вт, чем ускорители NVIDIA H100 при запуске продвинутых больших языковых моделей (LLM). Как ожидается, массовое производство RNGD начнётся во II половине 2025 года. При этом сама Meta✴ разработала уже два поколения собственных ИИ-ускорителей для инференса. И если от MTIA v1 в итоге было решено отказаться в пользу в первую очередь продуктов NVIDIA, то MTIA v2, судя по всему, активно внедряются, но их всё ещё не хватает для удовлетворения потребностей компании. 
Источник изображения: Meta✴ По данным Forbes, заинтересованность в RNGD также продемонстрировали исследовательская ИИ-лаборатория LG и Saudi Aramco. В сентябре последняя подписала меморандум о взаимопонимании с FuriosaAI и Cerebras Systems, ещё одним производителем ИИ-ускорителей, для «изучения сотрудничества в области суперкомпьютеров и ИИ». Переговоры проходят спустя несколько месяцев после того, как ещё один южнокорейский стартап в сфере ИИ Rebellions, завершил слияние с поддерживаемой SK hynix компанией Sapeon. Объединённая компания, которая осуществляет деятельность под брендом Rebellions, является первым в Южной Корее единорогом в области производства чипов ИИ.
12.02.2025 [08:29], Владимир Мироненко
NXP Semiconductors купила Kinara, разработчика NPU для периферийных вычисленийНидерландский производитель микросхем NXP Semiconductors N.V. сообщил о приобретении за $307 млн калифорнийского стартапа Kinara, специализирующегося на разработке программируемых дискретных нейропроцессорных модулей (NPU) для обработки ИИ-нагрузок на периферии. Как ожидается, сделка будет закрыта во II половине 2025 года после получения одобрения регуляторами. NXP и Kinara являются давними партнёрами, так что интеграция решений не займёт много времени. В пресс-релизе указано, что инновационные NPU и комплексное ПО Kinara обеспечивают высокую производительность в сочетании энергоэффективностью при обработке различных нейронных сетей, включая генеративный ИИ, для удовлетворения быстрорастущих потребностей в интеллектуальных функциях на промышленных и автомобильных рынках. Приобретение Kinara позволит расширить возможности NXP по предложению масштабируемых ИИ-платформ, от облегчённых и оптимизированных вариантов (TinyML) до полноценного генеративного ИИ. 
Источник изображения: NXP Сообщается, что дискретные NPU Kinara, включая Ara-1 и Ara-2, предназначенные для периферийных вычислений, входят в число лидеров отрасли по производительности и энергоэффективности, что делает их предпочтительным решением для новых приложений ИИ в области визуализации, обработки голоса, жестов и множества других многомодальных вариантов генеративного ИИ. Оба чипа имеют инновационную архитектуру, которая отличается не только энергоэффективностью в задачах инференса, но и программируемостью, что позволяет со временем задействовать всё новые модели и сценарии, включая, например, агентный ИИ в будущем. 
Источник изображения: Kinara NPU второго поколения Ara-2 обеспечивает производительность до 40 TOPS, оптимизирован для достижения высокой производительности на системном уровне для генеративного ИИ. NPU Ara-1 и Ara-2 можно легко интегрировать со встраиваемыми системами для расширения их возможностей, включая модернизацию уже развёрнутых систем. Также Kiara предоставляет полный комплект инструментов для разработки ПО, позволяющий клиентам оптимизировать производительность моделей и упростить их развёртывание. Инструмены и библиотеки ИИ Kinara будут интегрированы в среду разработки NXP eIQ AI/ML, чтобы клиенты могли быстро и легко создавать сквозные готовые ИИ-решения.
10.02.2025 [19:33], Сергей Карасёв
Groq развернула в Саудовской Аравии почти 20 тыс. ИИ-ускорителей LPUКомпании Groq и Aramco Digital объявили об открытии крупнейшего в Европе, на Ближнем Востоке и в Африке (EMEA) вычислительного ИИ-центра, ориентированного на задачи инференса. Площадка располагается в Даммаме в Саудовской Аравии. Groq занимается разработкой ускорителей LPU (Language Processing Unit) для работы с большими языковыми моделями (LLM). Утверждается, что они могут успешно конкурировать с ИИ-ускорителями NVIDIA, AMD и Intel. Aramco Digital, подразделение нефтегазового и химического гиганта Aramco, и Groq сообщили о намерении создать в Саудовской Аравии крупнейший в мире центр по развитию ИИ в марте 2024 года. Тогда говорилось, что Aramco Digital будет сдавать мощности Groq LPU в аренду клиентам на Ближнем Востоке. Предполагается также, что партнёрство с Groq поможет Aramco Digital вывести на рынок управляемую голосом ИИ-модель Norous. 
Источник изображения: Twitter/@sundeep Как теперь сообщается, на базе нового ИИ-центра заработал облачный регион GrogCloud, включающий 19 725 LPU. Инвестиции в проект составили $1,5 млрд — совместно от Groq и Aramco Digital. Джонатан Росс (Jonathan Ross), генеральный директор Groq, сообщил, что к концу I квартала 2025 года компания развернёт сможет генерировать не менее 25 млн токенов в секунду. В перспективе планируется повышение данного показателя вплоть до 1 млрд токенов в секунду. 
Источник изображения: Twitter/@sundeep С момента запуска GroqCloud в марте 2024 года более 800 тыс. разработчиков по всему миру начали использовать эту платформу на базе LPU Inference Engine через программный интерфейс Groq API. Облако, как утверждается, обеспечивает инференс в реальном времени с меньшей задержкой и большей пропускной способностью, чем у конкурентов. GroqCloud подходит для генеративных и разговорных приложений ИИ. 
Источник изображения: Twitter/@sundeep В целом, Groq создаёт высокопроизводительную инфраструктуру ИИ, предназначенную для обслуживания более 4 млрд человек в Саудовской Аравии, на Ближнем Востоке, в Африке и за пределами этого региона. Сделка с Groq является частью крупномасштабного плана Vision-2030, предполагающего переход Саудовской Аравии к инновационной экономике на базе ИИ, которая призвана снизить зависимость страны от добычи нефти и газа.
03.02.2025 [09:20], Руслан Авдеев
The Register: Успех DeepSeek показал важность обдуманных инвестиций в ИИ, но потребность в развитии инфраструктуры никуда не денетсяШок, вызванный недавним триумфом китайского ИИ-стартапа DeepSeek, представившего дешёвые и эффективные ИИ-модели, заставил многих усомниться в результативности масштабных вложений в инфраструктуру на базе дорогих ИИ-ускорителей, сообщает The Register. Тем не менее эксперты уверены, что отказываться от инвестиций было бы нецелесообразно. На прошлой неделе акции ряда крупнейших американских ИИ-брендов после дебюта весьма эффективной модели DeepSeek R1, использующей, со слов создателей, сравнительно мало ускорителей NVIDIA, буквально обрушились в цене. Из-за этого многие эксперты усомнились в том, что траты миллиардов на аппаратную инфраструктуру для ИИ себя оправдывают, если Китай способен добиться хороших результатов, используя не самое мощное оборудование. Например, NVIDIA «в моменте» потеряла $600 млрд рыночной стоимости. Настоящая истерия наложилась на растущее беспокойство в связи с тем, что всё больше денег тратится на инфраструктуру и её поддержку, а особенной отдачи пока не видно. Впрочем, паника может быть неуместной, поскольку обрушение акций прекратилось, а DeepSeek обвиняется в использовании ИИ-моделей Anthropic и OpenAI. Как отмечает The Register, нет и реальных подтверждений того, что производительность моделей DeepSeek находится на уровне лучших из актуальных моделей, а также того, что на обучение китайского ИИ ушло всего $6 млн. По оценкам SemiAnalysis, доступная DeepSeek инфраструктура гораздо больше, чем утверждает компания, и стоит более чем $1,5 млрд. 
Источник изображения: Etienne Girardet/unsplash.com По словам экспертов Omdia, опасения относительно «сокрушительных» инноваций DeepSeek сильно преувеличены. В компании подтверждают, что китайский стартап использовал некоторые «гениальные инновации», но они приведут лишь к массовому использованию аналогичных решений и строительству новой ИИ-инфраструктуры. В Omdia прогнозируют, что в ближайшие годы рынок ИИ-инфраструктуры, скорее всего, значительно вырастет. В компании полагают, что до 2028 года поставки серверов для инференса будут расти на 17 % ежегодно. В TrendForce придерживаются несколько иного мнения и предполагают, что в будущем организации всё же станут более строго оценивать инвестиции в инфраструктуру ИИ и станут применять более эффективные модели для того, чтобы снизить зависимость от доступности ускорителей. Также не исключается, что чаще будут использоваться кастомные ASIC вместо сторонних ИИ-ускорителей и спрос на «классические» модели может претерпеть с 2025 года заметные изменения. Если раньше индустрия полагалась в первую очередь на масштабирование моделей, увеличение объёмов данных и повышение производительности оборудования, то теперь стратегия меняется. DeepSeek прибегла к «дистилляции» моделей, повышению скорости инференса и снижения зависимости от оборудования. Не так давно генеральный директор IBM Арвинд Кришна (Arvind Krishna) объявил, что деятельность DeepSeek подтвердила правильность подхода к ИИ его собственной компании, считающей, что модели могут быть меньше, как и время их обучения. При использовании подобных подходов затраты на инференс могут снизиться в 30 раз, что очень хорошо для корпоративных клиентов. Ещё в 2023 году компания начала развивать серию «экономичных» базовых моделей Granite. Вероятно, по этому пути пойдут и другие. 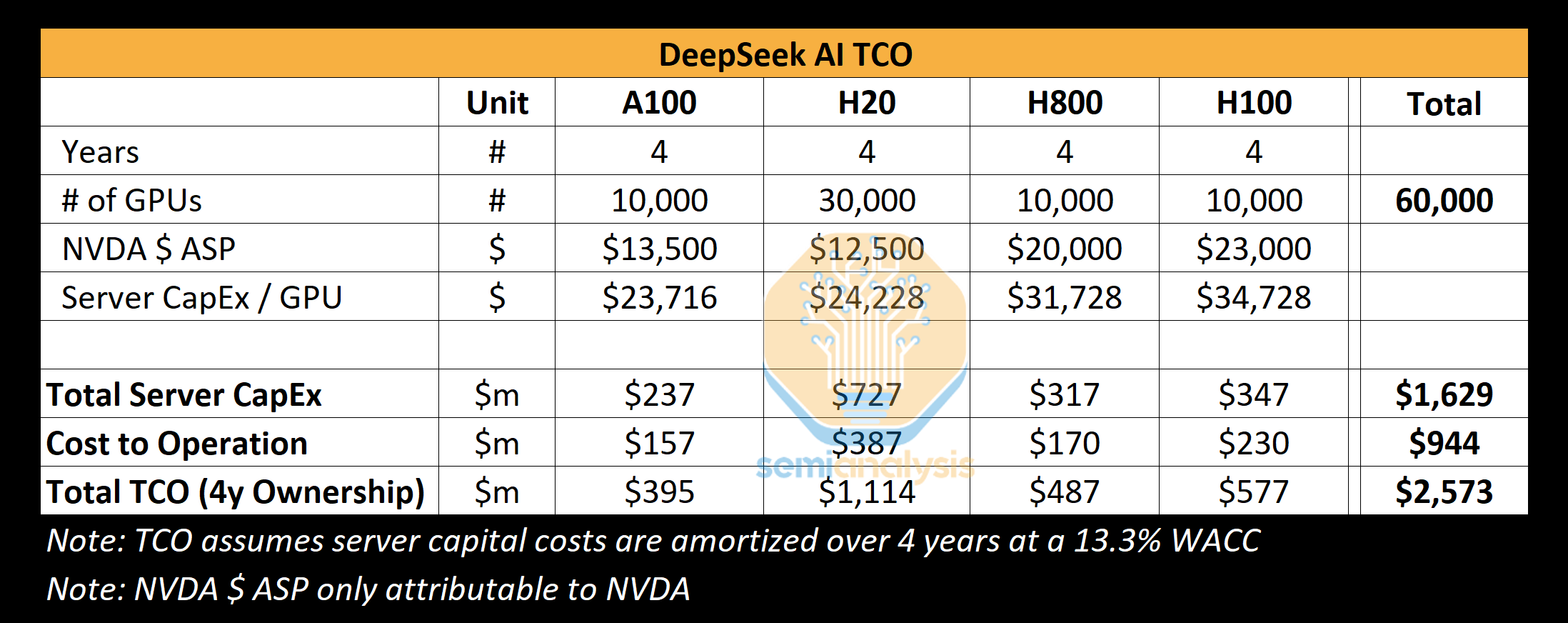
Источник изображения: SemiAnalysis Gartner также сообщает, что именно эффективное масштабирование ИИ будет целесообразнее простого наращивания вычислительных ресурсов. Впрочем, китайский ИИ не устанавливает новый стандарт эффективности моделей, поскольку те соответствуют показателям уже существующих, но не превосходят их. Кроме того, нет доказательств, что добавление дополнительных вычислительных ресурсов и данных не имеет значения. The Register прогнозирует, что продукты и технологии DeepSeek не вызовут резкого падения спроса на ИИ-инфраструктуру, поэтому инвесторам NVIDIA и строителям ЦОД, вероятно, можно не бояться того, что «пузырь» ИИ лопнет, как этого ожидают некоторые эксперты. Во всяком случае одни из крупнейших инвесторов в сектор ЦОД — Blackstone и Brookfield — заявили, что следят за успехами DeepSeek, но отказываться от инвестиций не собираются. Тем не менее, успех китайского стартапа напоминает о том, что «всегда можно сделать ещё лучше» и экстенсивное вливание денег и вычислительных ресурсов не всегда лучший вариант.
01.02.2025 [15:23], Сергей Карасёв
Самый быстрый инференс DeepSeek R1 в мире: ИИ-платформа Cerebras снова поставила рекорд производительностиАмериканский стартап Cerebras Systems объявил о том, что его инференс-платформа позволила установить мировой рекорд производительности при использовании «рассуждающей» ИИ-модели DeepSeek R1 в модификации с 70 млрд параметров (DeepSeek-R1-Distill-Llama-70B). DeepSeek R1 может содержать до 671 млрд параметров. Однако, как отмечает Cerebras, развёртывание модели со способностью к рассуждению столь большого масштаба представляет значительные проблемы. Версия с 70 млрд параметров позволяет совместить возможности рассуждений более крупной модели с MoE с широко поддерживаемой архитектурой Meta✴ Llama. 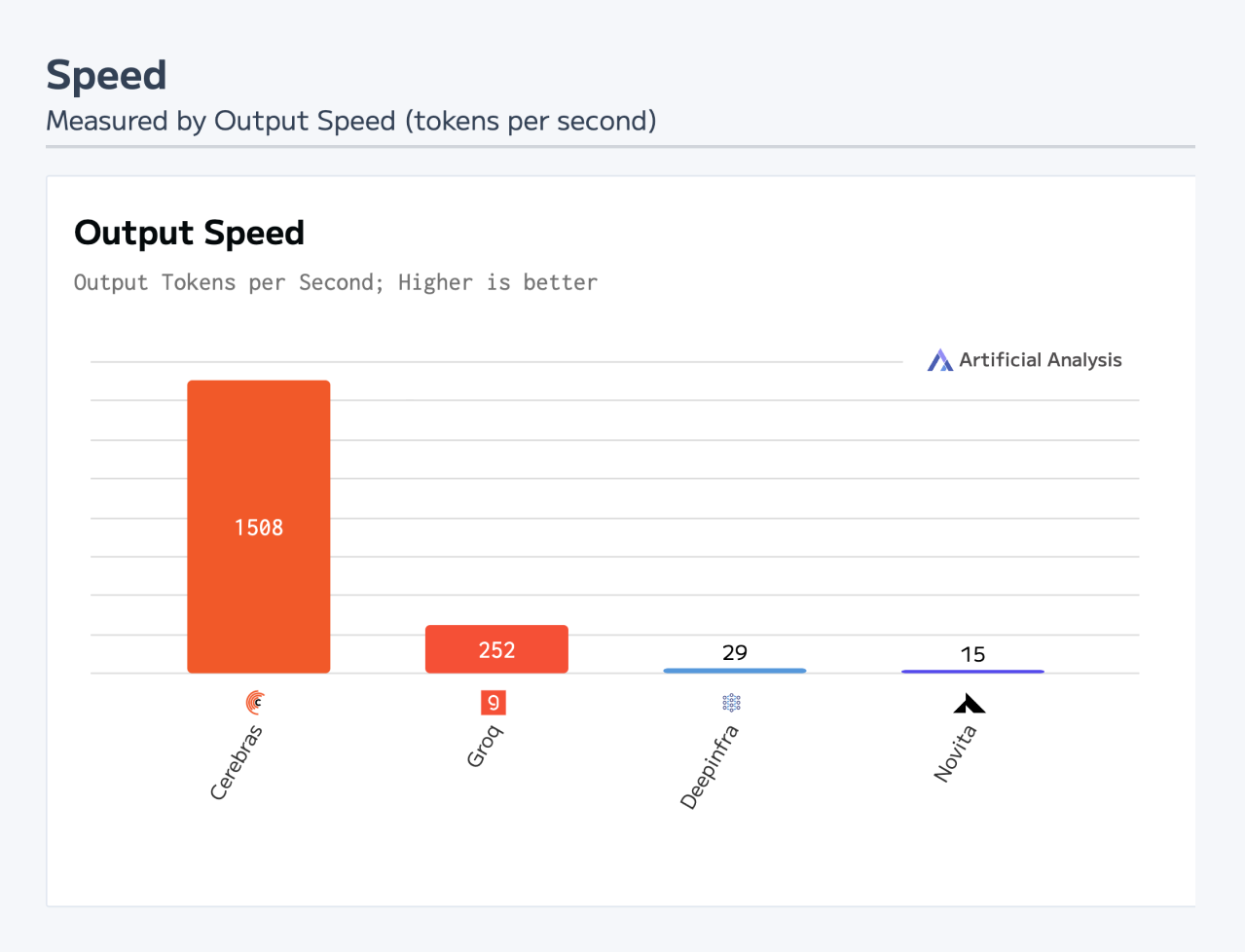
Источник изображений: Cerebras Основой платформы Cerebras являются царь-ускорители собственной разработки WSE (Wafer Scale Engine). Производительность DeepSeek R1 при работе на инфраструктуре Cerebras достигает 1508 токенов в секунду — это значительно быстрее по сравнению с конкурирующими решениями. В частности, в случае Groq показатель составляет 252 токена в секунду. Стандартный запрос на генерацию кода, который, как утверждает компания, занимает 22 секунды на конкурирующих платформах, в случае Cerebras завершается всего за 1,5 секунды, что соответствует 15-кратному повышению производительности. Cerebras подчёркивает, что DeepSeek-R1-Distill-Llama-70B превосходит как GPT-4o, так и o1-mini в сложных математических задачах и генерации кода. 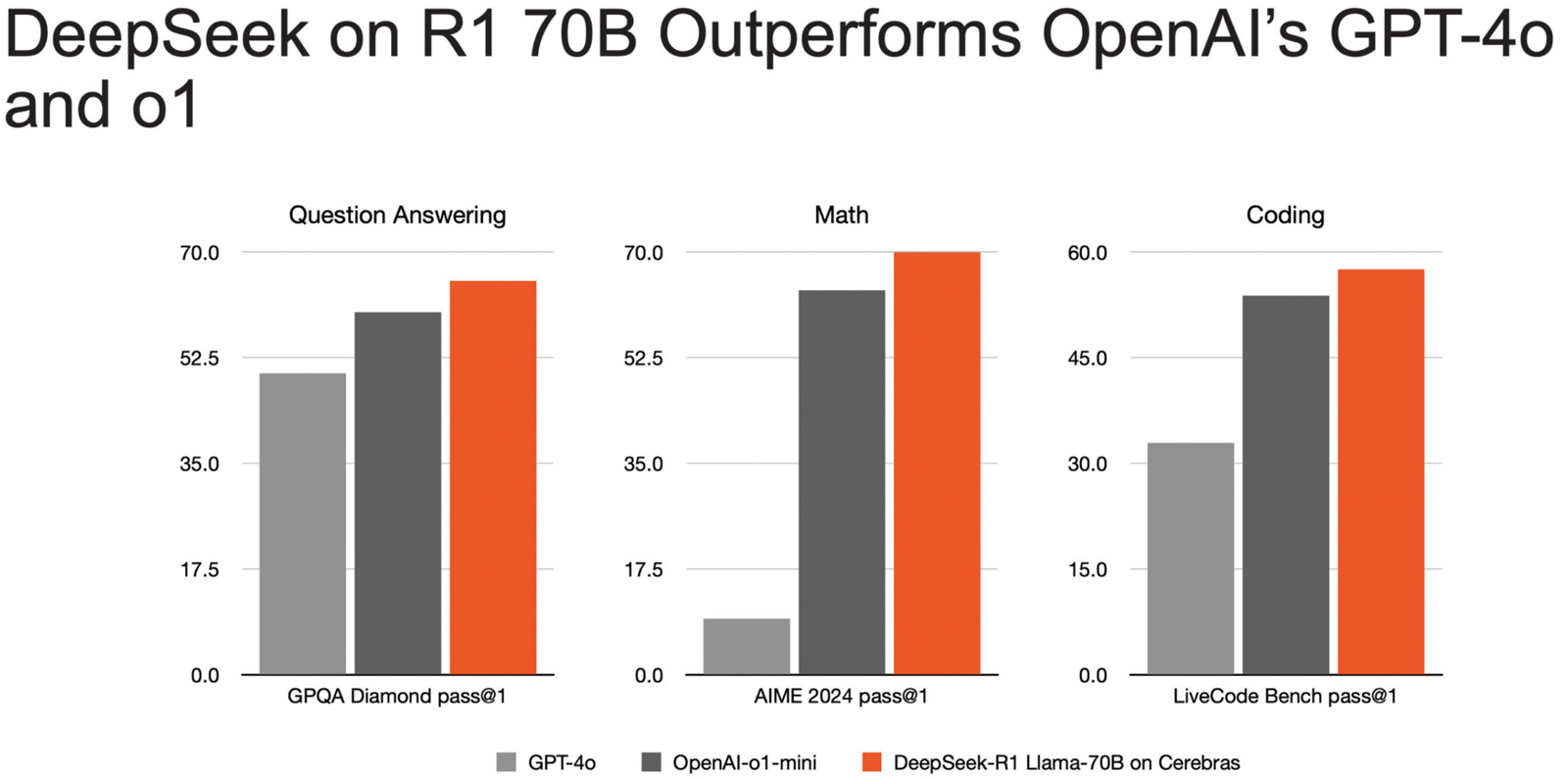 Cerebras также отмечает, что все вычисления осуществляются на базе ИИ-инфраструктуры в США, развёрнутой в собственных дата-центрах компании. При этом никакие данные не сохраняются, что гарантирует полную безопасность для клиентов. Кроме того, модель DeepSeek R1 может быть развёрнута локально в ЦОД заказчика для обеспечения максимального контроля.
31.01.2025 [19:44], Руслан Авдеев
Blackstone внимательно следит за успехами DeepSeek, но отказываться от крупных инвестиций в ЦОД не собираетсяИнвестиционная компания Blackstone не намерена отказываться от своих вложений в дата-центры даже после того, как китайская DeepSeek произвела настоящий фурор на рынке ИИ, выпустив недорогие и эффективные модели, обученные с минимумом ресурсов. В ходе последнего отчёта о доходах она объявила о продолжении инвестиций в сектор, сообщает Datacenter Dynamics. В октябре компания сообщала, что располагает портфолио в соответствующем секторе на $70 млрд и готова увеличить его ещё на $100 млрд. После того, как Morgan Stanley задала вопрос о вероятных проблемах расширения инфраструктуры, связанных с успехом DeepSeek, поскольку многие усомнились в целесообразности строительства новых ИИ ЦОД для обучения всё более крупных моделей — вроде проекта Stargate. Представитель Blackstone заявил, что компания потратила немало времени на изучения феномена китайского успеха, но пока не видит для себя проблем, поскольку многие из крупнейших компаний заключили долгосрочные контракты на аренду дата-центров, а BlackStone не строит ЦОД «спекулятивно». Blackstone через QTS и другие свои активы намерена продолжить тратить большие средства на строительство новых объектов с учётом спроса со стороны арендаторов. В компании уверены, что рынок ЦОД по-прежнему остаётся важным сегментом и Blackstone внимательно следит за тем, что на нём происходит. 
Источник изображения: Becca Tapert/unsplash.com Эксперты считают, что успех DeepSeek стал частью более широкой тенденции, в рамках которой существенно снижается стоимость разработки ИИ-моделей. Тем не менее это, вероятно, не приведёт к сокращению рынка ИИ ЦОД. Если на обучение будут тратить меньше ресурсов, то масштабы инференса, наоборот, будут только расти. Другими словами, потребность в дата-центрах никуда не делась и по-прежнему острая, может измениться лишь формат их использования. Совсем недавно в Fortune опровергли опасения относительно того, что успех DeepSeek в долгосрочной перспективе негативно скажется на IT-рынке. Приводится т. н. «парадокс Джевонса», предполагающий рост потребления ресурса в случае, если его использование становится более эффективным и доступным. Другими словами, ожидается, что рынок будет только расширяться.
28.01.2025 [18:40], Владимир Мироненко
«Рынки ошибаются»: DeepSeek не угрожает NVIDIA и другим американским IT-гигантам
deepseek
fortune
hardware
nvidia
анализ рынка
ии
инференс
китай
прогноз
санкции
сша
ускоритель
финансы
Рост популярности ИИ-технологий способствовал росту рыночной стоимости NVIDIA выше $3 трлн. Однако её акции обрушились в понедельник на 17 %, вызвав падение рыночной стоимости компании почти на $600 млрд, после анонса китайским стартапом DeepSeek ИИ-моделей V3 и R1, способных соперничать с лучшими моделями любой американской компании, хотя и были обучены за малую часть стоимости на менее продвинутых чипах NVIDIA H800 и A100, пишет Fortune. Также в начале недели приложение AI Assistant стартапа DeepSeek вышло на первое место в рейтинге самых популярных бесплатных приложений в интернет-магазине в Apple App Store в США, опередив ИИ-чат-бот ChatGPT от OpenAI. Более того, модель DeepSeek R1, призванная бросить вызов модели «рассуждений» OpenAI o1, можно запустить на рабочей станции, а не в ЦОД. Поскольку мощные ускорители NVIDIA являются одной из самых больших статей расходов на разработку самых передовых моделей ИИ, инвесторы начали пересматривать свои представления относительно вложений в ИИ-бизнес. Да, DeepSeek явно потряс рынок ИИ, однако разговоры о крахе NVIDIA могут быть преждевременными, равно как и заявления о том, что успех DeepSeek означает, что США следует отказаться от политики, направленной на ограничение доступа Китая к самым передовым ИИ-чипам, предупреждают аналитики Fortune. DeepSeek утверждает, что использует 10 тыс. ускорителей NVIDIA A100, а также чипы H800, что на порядок меньше, чем используют американские компании для обучения своих самых передовых ИИ-моделей. Например, Xai Илона Маска (Elon Musk) построила вычислительный кластер Colossus в Теннесси на базе 100 тыс. ускорителей NVIDIA H100, его планирует расширить до 1 млн чипов. 
Источник изображения: Heather Wilde / Unsplash Это дало повод некоторым экспертам утверждать, что введение ограничений США подстегнуло инновации в Китае. В Fortune считают такие умозаключения недальновидными и утверждают, что влияние DeepSeek может, как это ни парадоксально звучит на первый взгляд, увеличить спрос на передовые чипы ИИ — как NVIDIA, так и её конкурентов. Причина отчасти заключена в феномене, известном как парадокс Джевонса (Jevons Paradox). Парадокс Джевонса, также известный как эффект отскока, назван в честь британского экономиста XIX века Уильяма Стэнли Джевонса (William Stanley Jevons), который заметил: когда технический прогресс делает использование ресурса более эффективным, общее потребление этого ресурса имеет тенденцию к увеличению. Это имеет смысл, если спрос на что-либо относительно эластичен — снижающаяся из-за повышения эффективности цена создаёт ещё больший спрос на продукт. Одной из причин слабого внедрения ИИ-моделей в крупных организациях была их дороговизна. Это особенно касалось новых «рассуждающих» моделей, таких как o1 от OpenAI. Модели DeepSeek гораздо дешевле конкурентов в эксплуатации, так что теперь компании могут позволить себе развёртывать их для многих сценариев использования. В масштабах отрасли это может привести к резкому росту спроса на вычислительную мощность. В понедельник гендиректор Microsoft Сатья Наделла (Satya Nadella) и бывший гендиректор Intel Пэт Гелсингер (Pat Gelsinger) указали на это в сообщениях в социальных сетях. Наделла напрямую сослался на парадокс Джевонса, в то время как Гелсингер сказал, что «вычисления подчиняются» тому, что он назвал «законом газа». «Если сделать его значительно дешевле, рынок для него расширится… это сделает ИИ гораздо более широко распространенным, — написал он. — Рынки ошибаются». 
Источник изображения: Mark Daynes / Unsplash В Fortune задались вопросом: «Какая именно вычислительная мощность потребуется?». Топовые ускорители NVIDIA оптимизированы для обучения крупнейших больших языковых моделей (LLM), таких как GPT-4 от OpenAI или Claude 3-Opus от Anthropic. Для инференса чипы NVIDIA меньше подходят, чем изделия конкурентов, включая AMD и, например, Groq, чипы которых позволяют исполнять ИИ-нагрузки быстрее и намного эффективнее. Google и Amazon также создают свои собственные чипы ИИ, некоторые из которых оптимизированы для инференса. NVIDIA сейчас занимает более 80 % рынка ИИ-вычислений на базе ЦОД (если исключить кастомные ASIC облачных провайдеров, её доля может составить до 98 %) и вряд ли утратит доминирование быстро или полностью, отметили в Fortune. Ёе ускорители также могут использоваться для инференса, а программная платформа CUDA имеет большое и лояльное сообщество разработчиков, которое вряд ли откажется от него в одночасье. Если общий спрос на ИИ-чипы увеличится из-за парадокса Джевонса, общие доходы NVIDIA всё равно смогут вырасти даже при падении доли на рынке из-за увеличившегося рынка. Ещё одна причина, по которой спрос на передовые ИИ-чипы, вероятно, продолжит рост, связана с особенностями работы моделей рассуждений, таких как R1. В то время как способности предыдущих типов LLM росли по мере увеличения доступной вычислительной мощности во время обучения, то модели рассуждений зависят от вычислительных ресурсов во время инференса — чем их больше, тем лучше ответы. 
Источник изображения: Kayla Kozlowski / Unsplash Запустив R1 на ноутбуке, можно получить хороший ответ на сложный математический вопрос, скажем, через час, в то время как при использовании ускорителей в облаке на тот же ответ уйдут считанные секунды. Для многих бизнес-приложений задержка или время, необходимое модели для ответа, имеет большое значение. И чтобы сократить время выполнения задачи, по-прежнему будут нужны передовые ИИ-ускорители. Кроме того, многие эксперты сомневаются в правдивости заявления DeepSeek о том, что её модель V3 была обучена примерно на 2048 урезанных ускорителях NVIDIA H800 или что её модель R1 была обучена на столь малом количестве чипов. Александр Ван (Alexandr Wang), генеральный директор Scale AI, сообщил в интервью CNBC, что, по его данным, DeepSeek тайно получила доступ к кластеру из 50 тыс. ускорителей H100. Также известно, что хедж-фонд HighFlyer, которому принадлежит DeepSeek, успел закупить до введения санкций значительное количество менее производительных ускорителей NVIDIA. Так что вполне возможно, что NVIDIA находится в лучшем положении, чем предполагают паникующие инвесторы, и что проблема с экспортным контролем США заключается не в политике, а в её реализации, подытожили аналитики Fortune.
24.01.2025 [14:33], Сергей Карасёв
Бывший гендиректор Intel Пэт Гелсингер инвестировал средства в ИИ-стартап FractileЭкс-гендиректор Intel Пэт Гелсингер, по сообщению TrendForce, стал инвестором британского стартапа Fractile.ai, который специализируется на разработках в области ИИ. Сумма, которую предоставил бывший глава Intel на развитие этой компании, не раскрывается. Fractile.ai основана в 2022 году Уолтером Гудвином (Walter Goodwin) — специалистом, получившим докторскую степень в области искусственного интеллекта и робототехники в Оксфордском университете. Стартап разрабатывает специализированные ИИ-чипы, использующие метод вычислений в оперативной памяти. Такой подход может существенно повысить скорость инференса и выполнения других задач, связанных с интенсивными вычислениями. Утверждается, что по сравнению с традиционными ИИ-ускорителями на базе GPU решения Fractile.ai обеспечат ряд значительных преимуществ. В частности, говорится, что новые чипы позволят поднять производительность больших языковых моделей (LLM) в 100 раз при одновременном 10-кратном снижении затрат по сравнению с решениями NVIDIA. При этом чипы Fractile.ai обеспечат в 20 раз более высокую производительность в расчёте на 1 Вт затрачиваемой энергии по сравнению с любым другим оборудованием ИИ, представленным в настоящее время на рынке. 
Источник изображения: Intel Однако пока Fractile.ai не изготовила тестовые образцы изделий, а оценка их характеристик и возможностей проводится путём компьютерного моделирования. Тем не менее, Гелсингер говорит, что ни один подход в отношении ИИ-вычислений не воодушевляет его больше, чем тот, который предлагает Fractile.ai. По его словам, для дальнейшего масштабирования ИИ большое значение имеет снижение как энергопотребления, так и стоимости вычислений. Отмечается также, что стартап Fractile.ai ранее привлек в общей сложности $17,5 млн финансирования. В число инвесторов входят Kindred Capital, NATO Innovation Fund, Oxford Science Enterprises и несколько бизнес-ангелов.
23.01.2025 [13:29], Руслан Авдеев
В Nebius AI Studio появились открытые ИИ-модели для преобразования текста в изображениеИИ-компания Nebius B.V. (бывшая Yandex N.V.) анонсировала обновление платформы «инференс как услуга» для разработчиков. В частности, добавлены новые open source модели, предназначенные для преобразования текста в изображение, сообщает Silicon Angle. В скором времени в сервисе появятся модели для преобразования текста в видео. Nebius AI Studio представляет собой гибкую, удобную для пользователей среду для разработчиков, решивших заняться созданием ИИ-приложений, говорит компания. Помимо обеспечения доступа к обширному набору больших языковых моделей (LLM), решение является одним из самых доступных с точки зрения стоимости. Поскольку компания управляет своей собственной облачной инфраструктурой, она может обеспечить одну из самых низких цен за токен на рынке, подчёркивает Nebius. Кроме того, предлагается гибкая ценовая модель — чем больше ресурсов потребляется, тем они дешевле. 
Источник изображения: Nebius Ранее компания называлась Yandex N.V. — это была родительская структура российского «Яндекса». Позже она продала поисковый и некоторые другие бизнесы, но сохранила ЦОД за пределами России (и даже намерена строить новые) и, наконец, превратилась в облачный инфраструктурный ИИ-сервис. На этой инфраструктуре и работает Nebius AI Studio. Обновление добавило модели Flux Schnell и Flux Dev, разработанные ИИ-стартапом Black Forest Labs Inc. — позиционирующим себя как одного из конкурентов OpenAI. Разработчики, создающие ИИ-приложения в Nebius AI Studio, смогут напрямую интегрировать в них новые модели. В компании утверждают, что она обеспечивает одну из самых высоких скоростей рендеринга — изображения создаются за секунды. Приложения, создаваемые с использованием Nebius AI Studio, могут поддерживать обработку до 100 млн токенов в минуту, сообщает пресс-служба компании. |
|

