Материалы по тегу: инференс
|
19.07.2025 [13:46], Сергей Карасёв
Rockchip анонсировала ИИ-ускоритель RK182X с архитектурой RISC-VКомпания Rockchip, по сообщению ресурса CNX Software, представила в Китае ИИ-ускоритель RK182X, предназначенный для работы с большими языковыми моделями (LLM) и визуально-языковыми моделями (VLM) на периферии. Новинка ориентирована на совместное использование с другими SoC Rockchip. Изделие получило многоядерную архитектуру RISC-V (точное количество ядер пока не раскрывается). В зависимости от модификации задействованы 2,5 или 5 Гбайт памяти DRAM со «сверхвысокой пропускной способностью» (ПСП тоже не раскрывается). Реализована поддержка интерфейсов PCIe 2.0, USB 3.0 и Ethernet. По заявлениям Rockchip, ИИ-ускоритель RK182X способен обрабатывать LLM/VLM, насчитывающие до 7 млрд параметров. В частности, таким моделям требуется примерно 3,5 Гбайт памяти при использовании режимов INT4/FP4. Говорится о совместимости с фреймворками PyTorch, ONNX и TensorFlow, а также форматом HuggingFace GGUF (GPT-Generated Unified Format). 
Источник изображений: CNX Software ИИ-ускоритель спроектирован для применения в связке с такими процессорами Rockchip, как RK3576/RK3588 и другими, вероятно, включая решения RK3668 и RK3688, которые были также представлены вчера. Эти чипы содержат собственный интегрированный NPU-модуль с производительностью 6 TOPS или более для обработки ИИ-нагрузок. 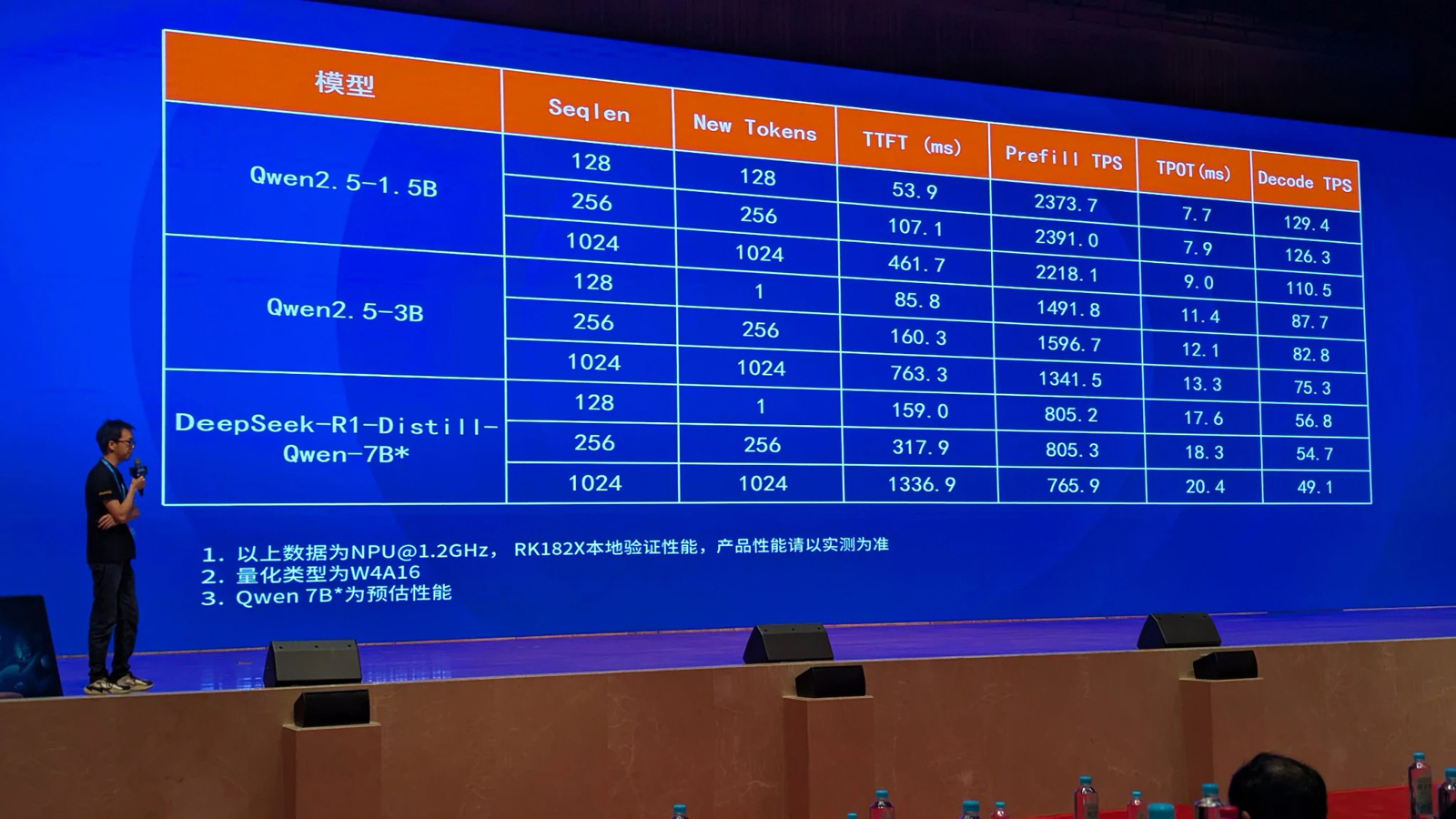 Однако благодаря применению отдельного ускорителя ИИ-быстродействие на определённых задачах может быть повышено в 8–10 раз. Rockchip, в частности, обнародовала скоростные показатели RK182X для таких популярных моделей, как DeepSeek-R1-Distill-Qwen-7B, Qwen2.5-1.5B и Qwen2.5-3B.
13.07.2025 [10:57], Сергей Карасёв
CoreWeave запустила первые общедоступные инстансы на базе NVIDIA RTX Pro 6000 Blackwell Server EditionОператор ИИ-облака CoreWeave объявил о запуске инстансов с ускорителями NVIDIA RTX Pro 6000 Blackwell Server Edition для генеративных приложений, рендеринга в реальном времени и работы с большими языковыми моделями (LLM). Утверждается, что это первые общедоступные облачные экземпляры, построенные на базе названных GPU. Изделия RTX Pro 6000 Blackwell Server Edition на архитектуре Blackwell насчитывают 24 064 ядра CUDA, 752 тензорных ядра пятого поколения и 188 ядер RT четвёртого поколения. В оснащение входят 96 Гбайт памяти GDDR7 с пропускной способностью до 1,6 Тбайт/с. CoreWeave заявляет, что по сравнению с инстансами на основе NVIDIA L40S новые экземпляры обеспечивают 5,6-кратное повышение производительности при LLM-инференсе, 3,5-кратное увеличение быстродействия на операциях преобразования текста в видео и более чем 2-кратное повышение скорости тонкой настройки ИИ-моделей. Заявленная ИИ-производительность в режиме FP4 достигает 3,8 Пфлопс. 
Источник изображения: CoreWeave / NVIDIA Инстансы CoreWeave с ускорителями NVIDIA RTX Pro 6000 Blackwell Server Edition доступны в конфигурациях, насчитывающих до восьми GPU. Задействованы два процессора Intel Xeon поколения Emerald Rapids, а также DPU NVIDIA BlueField-3. Экземпляры предоставляют свыше 7 Тбайт пространства для хранения данных на основе NVMe SSD. Говорится о поддержке служб CoreWeave Observability Services, которые отвечают за детальный мониторинг использования ресурсов, а также предоставляют данные о системных ошибках, температуре и пр. Это помогает быстро обнаруживать и устранять проблемы, минимизируя сбои в рабочих процессах. Новые инстансы доступны посредством CoreWeave Kubernetes Service (CKS) и Slurm on Kubernetes (SUNK) в американском регионе CoreWeave US-EAST-04.
09.07.2025 [16:30], Руслан Авдеев
SambaManaged превратит почти любой ЦОД в ИИ ЦОД всего за три месяцаРазработчик ИИ-ускорителей SambaNova анонсировал решение SambaManaged на базе SN40L. Это первый в отрасли продукт, оптимизированный для инференса, внедрить который можно всего за 90 дней — намного быстрее, чем обычно требуется для систем такого уровня (18–24 мес.), говорит компания. Модульная платформа разработана специально для быстрого развёртывания и позволяет существующим дата-центрам почти немедленно организовать ИИ-инференс с минимальными модификациями инфраструктуры. По мере того, как стремительно растёт спрос на ИИ-задачи, связанные именно с инференсом, традиционные дата-центры сталкиваются с новыми проблемами — на внедрение систем, оптимизированных для таких задач, требуется от полутора до двух лет, много энергии, а также дорогостоящие обновления оборудования. Решение SambaManaged позволяет устранить эти барьеры, быстро развернув прибыльные инференс-сервисы, используя уже имеющуюся силовую и сетевую инфраструктуру. 
Источник изображений: SambaNova SambaManged формируется из стоек SambaRack SN40L-16, каждая из которых включает 16 ускорителей (RDU в терминологии SambaNova) SN40L с BF16-производительностью 10,2 Тфлопс. Платформа оснащена двумя 64-ядерными хост-процессорами, 2 Тбайт DDR4, четырьмя загрузочными 960-Гбайт SSD (RAID1 + два hot-spare) и шестью 7,6-Тбайт NVMe SSD в RAID10 для данных. Энергопотребление составляет всего 7–14,5 кВт (типовое 10 кВт). Стойка весит 485 кг. Рабочая температура — от +15 до +30 °C. Фактически это переименованная платформа DataScale SN40L, только теперь разработчик не говорит о возможности обучения моделей. Как подчёркивают в SambaNova, дата-центры сталкиваются с проблемами энергоснабжения и охлаждения, недостатком компетенций и др. на фоне роста спроса на ИИ. Система SambaManaged обеспечивает высокую ИИ-производительность при низком энергопотреблении и минимальных изменениях инфраструктуры. Преимуществами для ЦОД и облачных провайдеров называются рекордная производительность на каждый затраченный Вт, позволяющая снизить совокупную стоимость владения (TCO) и быстрее вернуть инвестиции. Систему можно внедрить всего за 90 дней. При этом обеспечивается невероятно быстрый инференс с ведущими open source моделями, что позволяет избежать привязки к конкретному вендору и гарантирует совместимость с будущими технологиями. Модульный дизайн позволяет быстро строить даже большие инференс-системы, включая т.н. Token Factory мощностью до 1 МВт (100 стоек). Систему можно масштабировать по мере изменения бизнес-потребностей. Можно выбрать полностью управляемое решение или взять на себя часть контроля за операциями.  SambaManaged уже внедряется крупной публичной компанией в США, потребляющей немало энергии. Платформа обеспечивает максимальную пропускную способность для моделей вроде DeepSeek и ей подобных, помогая клиентам увеличивать доход от инференса и оптимизировать энергоэффективность (PUE). В SambaNova заявляют, что SambaManaged меняет правила игры для организаций, желающих ускорить реализацию ИИ-проектов без ущерба скорости, масштабу или эффективности. Везде, где есть доступ к Сети и электроэнергии, можно обеспечить необходимую инфраструктуру в рекордные сроки. В конце июня 2025 года сообщалось, что SambaNova делает ставку на инференс и партнёрство с облачными провайдерами и госзаказчиками из США. Groq, ещё один поставщик решений для инференса, первым сменил бизнес-подход, отказавшись от продажи ускорителей в пользу формирования целых ИИ ЦОД. Cerebras совместно с партнёрами также создаёт крупные ИИ-суперкомпьютеры и кластеры.
08.07.2025 [14:55], Руслан Авдеев
Groq запустила свой первый европейский ЦОД в ХельсинкиКомпания Groq, предлагающая сервисы ИИ-инференса, объявила о расширении своей сети дата-центров, открыв свой первый в Европе ЦОД в Хельсинки (Финляндия). Это поможет удовлетворить растущие потребности европейских клиентов, сообщает пресс-служба компании. Как заявил глава Groq Джонатан Росс (Jonathan Ross), спрос на ИИ-инференс растёт всё быстрее, а европейский дата-центр позволит местным клиентам получить минимальную задержку и готовую инфраструктуру для инференса уже сегодня. Кроме того, данные хранятся на территории Европы. Новый объект создан в Хельсинки на площадке Equinix. Партнёрство Equinix и Groq позволяет клиентам Equinix Fabric организовать инференс на платформе GroqCloud. Новые и действующие пользователи в США и EMEA получат доступ к мощностям для инференса через инфраструктуру Equinix Fabric — публичную, частную или суверенную. В Equinix подчеркнули, что Скандинавия — отличное место для ИИ-инфраструктуры. Благодаря политике поддержки экоустойчивой энергетики, возможности использования фрикулинга для охлаждения и надёжности электросети Финляндия стала приоритетным выбором для размещения новых мощностей. 
Источник изображения: Groq Европейские государственные и негосударственные структуры рассчитывают получить полный контроль над развёртываемой инфраструктурой, в местах, которые выбирают они сами — они пытаются сохранить баланс между потребностью в обеспечении суверенитета данных и защиты их конфиденциальности и обеспечением мобильности этих данных. Благодаря новому проекту клиенты могут получать доступ к GroqCloud через частные подключения. Экспансия в Европе расширяет мощности Groq на площадках Equinix и DataBank в США, Bell Canada в Канаде и HUMAIN в Саудовской Аравии. Они уже генерируют более 20 млн токенов в секунду по всей сети Groq. В некоторой степени это отражает спрос на ИИ-ускорители Groq LPU (Language Processing Unit). Чуть более года назад Groq объявила, что больше не продаёт свои ИИ-ускорители, предлагая вместо этого совместно создавать ЦОД и облачные сервисы. Как заявляют в Groq, компания обеспечивает самую низкую стоимость за токен без ущерба качеству, что делает масштабное использование ИИ экономически выгодным как для ИИ-стартапов, так и для крупных корпораций по всему миру.
25.06.2025 [13:34], Руслан Авдеев
SambaNova делает ставку на инференс и партнёрство с облачными провайдерами и госзаказчикамиРазработчик ИИ-ускорителей SambaNova Systems объявил о стратегическом изменении профиля деятельности. Теперь основное внимание будет уделено инференсу, а не обучению ИИ-моделей, сообщает EE Times со ссылкой на главу компании Родриго Ляна (Rodrigo Liang). Тот считает, что в ближайшие годы инференс станет ключевым направлением в ИИ-секторе. Переосмысление стратегии привело к увольнению 77 сотрудников в апреле 2025 года. Компания всё ещё будет поддерживать обучение ИИ-моделей, но признаёт, что спрос на крупные кластеры для этих целей заметно снизился. Многие клиенты переходят на открытые модели, адаптируя и дообучая их — разработчики не желают создавать свои LLM с нуля. Поэтому теперь SambaNova будет предоставлять предприятиям и правительственным структурам инструменты для развёртывания открытых и доработанных моделей, в том числе «рассуждающих». Основными клиентами компании сегодня являются крупные предприятия и «суверенные» государственные заказчики, заинтересованные в сокращении затрат. У госзаказчиков особые требования, в частности — независимость от США и других стран. Кроме того, они используют модели, обученные на локальных данных и ориентированные на специфику национальных экономик. Поскольку стойки компании потребляют всего по 10 кВт, позволить их себе могут даже страны со слабой энергетической инфраструктурой. 
Источник изображения: Magnet.me/unsplash.com Хотя у SambaNova есть собственная облачная инфраструктура с поддержкой открытых моделей, компания не намерена строить крупные кластеры для инференса. Вместо этого она организует партнёрство с облачными провайдерами, предоставляя им технологии для создания ИИ-облаков. Некоторыми партнёрами стали региональные облачные провайдеры, намеренные развернуть собственные ИИ-экосистемы. Платформа SambaNova Cloud играет роль демонстрационной площадки и не претендует на конкуренцию с другими провайдерами, являясь шаблоном, по образцу которого можно развёртывать аналогичные схемы «под ключ». Технологии SambaNova позволяют запускать до 100 разных копий Llama-70B в одной стойке. Это отличный вариант для компаний, которым нужны разные варианты моделей для финансового, юридического и других отделов, для разных целей. По словам компании, у конкурентов для каждой версии модели требуется стойка на 140 кВт, в то время как SambaNova позволяет использовать стойки на 10 кВт для запуска множества моделей, причём переключение с одной на другую осуществляется «за миллисекунду». Это позволяет компаниям экономить значительные средства. Осенью 2024 года SambaNova объявила о запуске самой быстрой на тот момент облачной платформы для ИИ-инференса. В этом она соревнуется с Cerebras и Groq, которые пытаются составить конкуренцию NVIDIA. Стоит отметить, что Groq также сменила бизнес-подход, отказавшись от продажи отдельных ускорителей в пользу оснащения целых ИИ ЦОД для инференса. Cerebras совместно с партнёрами создаёт крупные ИИ-суперкомпьютеры и кластеры. От обучения моделей она не отказывается.
16.06.2025 [09:20], Владимир Мироненко
x86 не нужен: «недопроцессор» NeuReality NR1 кратно ускоряет инференс на любых GPUNeuReality объявила о выходе чипа NR1, специально созданного для оркестрации инференса, передаёт HPCwire. Он сочетается с любым GPU или ИИ-ускорителем, позволяя повысить эффективность использование GPU почти до 100 % по сравнению со средним показателем в 30–50 % при традиционном сочетании классического процессора и сетевого адаптера в современных серверах. Чип NR1 призван заменить традиционные CPU и NIC, которые являются узким местом для ИИ-нагрузок, предлагая вместе с тем шестикратное увеличение вычислительной мощности для обеспечения максимальной пропускной способности ускорителей и масштабного ИИ-инференса, утверждает разработчик. Как отметила компания, в течение многих лет разработчики развивали GPU, чтобы соответствовать требованиям ИИ, делая их быстрее и мощнее. Но традиционные CPU, разработанные для эпохи интернета, а не эпохи ИИ, в основном не менялись, становясь узким местом, поскольку ИИ-модели становятся всё более сложными, а запросы ИИ-нагрузок растут в объёме. 
Источник изображений: NeuReality NR1 включает все базовые функции CPU, необходимые для работы с ИИ-задачами, выделенные обработчики мультимедиа и данных, аппаратный гипервизор и комплексные сетевые IP-блоки, что обеспечивает значительно более высокую производительность, более низкое энергопотребление и окупаемость инвестиций. В тестах самой компании исполнение одной и той же модели на базе генеративного ИИ на одном и том же ИИ-ускорителе её чип NR1 позволяет получить в 6,5 раза больше токенов, чем x86-сервер при той же стоимости и энергопотреблении. 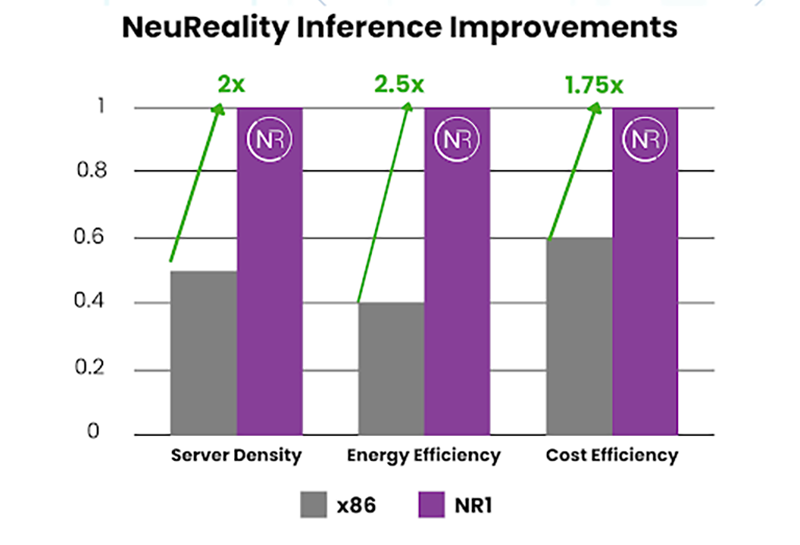 В соответствии с текущей тенденцией на разделение ресурсов хранения и вычислений, дезагрегация ИИ-ресурсов обеспечивает оптимизированную изоляцию ИИ-вычислений, отметила NeuReality. Такое разделение особенно важно в ЦОД и облаках. Традиционные программно-управляемые платформы, ориентированные на CPU, сталкиваются с такими проблемами, как высокая стоимость, энергопотребление и узкие места в системе при обработке задач ИИ-инференса. Сложность современной инфраструктуры и высокая стоимость часто ограничивают использование всех возможностей инференса, утверждает NeuReality. 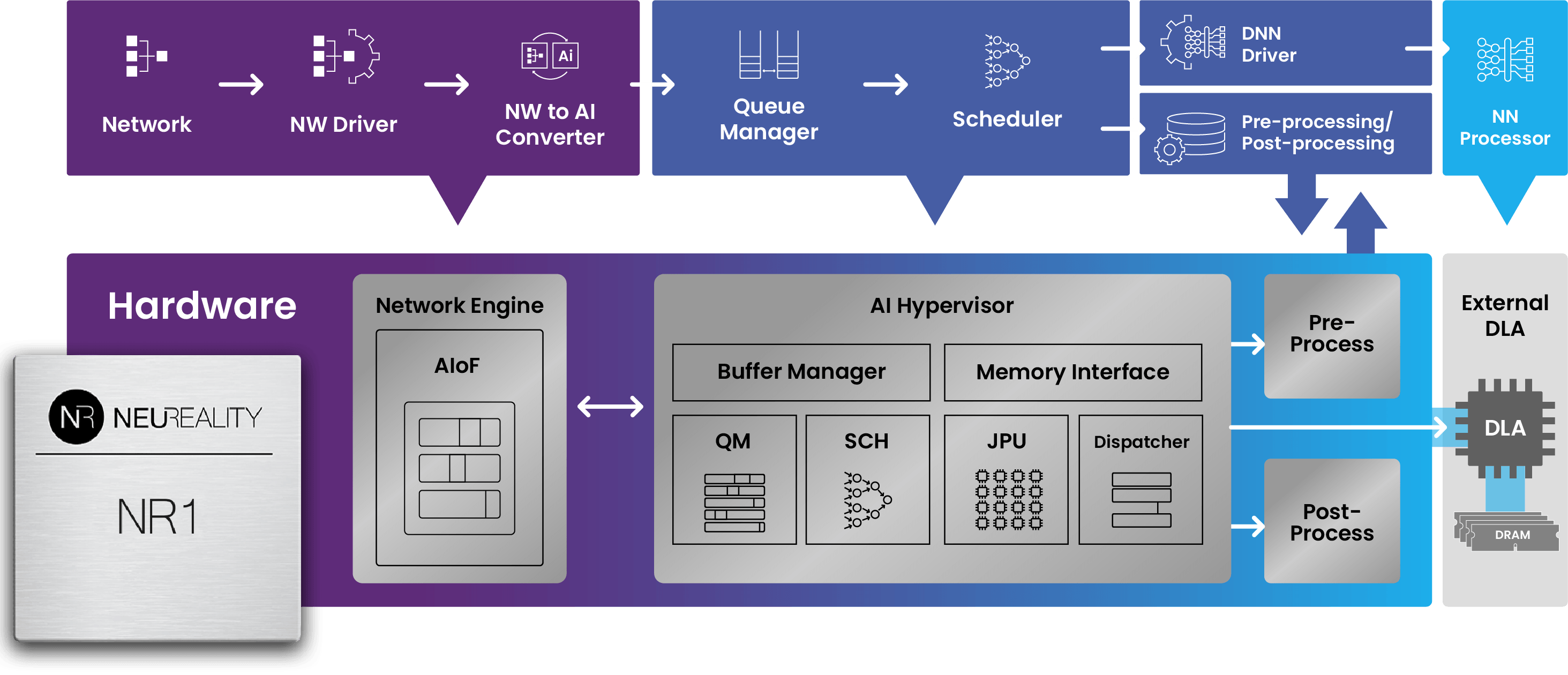 NR1 ориентирован на комплексную разгрузку ИИ-конвейера. Аппаратный ИИ-гипервизор отвечает за обработку путей данных и планирование заданий, охватывая механизмы пред- и постобработки данных, а также сетевой движок AI-over-Fabric. Благодаря этому достигнуто оптимальное соотношение цены и производительности и самые низкие эксплуатационные расходы, характеризующиеся низким энергопотреблением, минимальной задержкой и линейной масштабируемостью, говорит компания. Для DevOps и MLOps компания предоставляет полный SDK и сервисный слой на основе Kubernetes. Новый чип предлагается использовать для решения задач в сфере финансов и страхования, здравоохранении и фармацевтике, госуслугах и образовании, телекоммуникации, ретейле и электронной коммерции, для нагрузок генеративного и агентного ИИ, компьютерного зрения и т.д. NeuReality NR1 включает:
06.06.2025 [18:46], Руслан Авдеев
AMD продолжает шоппинг: компания купила стартап Brium для борьбы с доминированием NVIDIAВ последние дни компания AMD активно занимается покупками компаний, так или иначе задействованных в разработке ИИ-технологий. Одним из последних событий стала покупка стартапа Brium, специализирующегося на инструментах разработки и оптимизации ИИ ПО, сообщает CRN. AMD, по-видимому, всерьёз обеспокоилась развитием программной экосистемы после того, как выяснилось, что именно ПО не даёт раскрыть весь потенциал ускорителей Instinct. О покупке Brium, в состав которой входят «эксперты мирового класса в области компиляторов и программного обеспечения для ИИ», было объявлено в минувшую среду. Финансовые условия сделки пока не разглашаются. По словам представителя AMD, передовое ПО Brium укрепит возможности IT-гиганта «поставлять в высокой степени оптимизированные ИИ-решения», включающие ИИ-ускорители Instinct, которые играют для компании ключевую роль в соперничестве с NVIDIA. Дополнительная информация изложена в пресс-релизе AMD. В AMD уверены, что разработки Brium в области компиляторных технологий, фреймворков для выполнения моделей и оптимизации ИИ-инференса позволят улучшить эффективность и гибкость ИИ-платформы нового владельца. Главное преимущество, которое AMD видит в Brium — способность стартапа оптимизировать весь стек инференса до того, как модель начинает обрабатываться аппаратным обеспечением. Это позволяет снизить зависимость от конкретных конфигураций оборудования и обеспечивает ускоренную и эффективную работу ИИ «из коробки». В частности, команда Brium «немедленно» внесёт вклад в ключевые проекты вроде OpenAI Triton, WAVE DSL и SHARK/IREE, имеющие решающее значение для более быстрой и эффективной эксплуатации ИИ-моделей на ускорителях AMD Instinct. У технического директора Brium Квентина Коломбета (Quentin Colombet) десятилетний опыт разработки и оптимизации компиляторов для ускорителей в Google, Meta✴ и Apple. 
Источник изображения: AMD Компания сосредоточится на внедрении новых форматов данных вроде MX FP4 и FP6, которые уменьшают объём вычислений и снижают энергопотребление, сохраняя приемлемую точность моделей. В результате разработчики могут добиться более высокой производительности ИИ-моделей, снижая затраты на оборудование и повышая энергоэффективность. Покупка Brium также поможет ускорить создание open source инструментов. Это даст возможность AMD лучше адаптировать свои решения под специфические потребности клиентов из разных отраслей. Так, Brium успешно адаптировала Deep Graph Library (DGL) — фреймворк для работы с графовыми нейронными сетями (GNN) — под платформу AMD Instinct, что дало возможность эффективно запускать передовые ИИ-приложения в области здравоохранения. Такого рода компетенции повышают способность AMD предоставлять оптимальные решения для отраслей с высокой добавленной стоимостью и расширять охват рынка. Brium — лишь одно из приобретений AMD за последние дни для усиления позиций в соперничестве с NVIDIA, доминирование которой на рынке ИИ позволило получить в прошлом году выручку, более чем вдвое превышавшую показатели AMD и Intel вместе взятых. В числе последних покупок — стартап Enosemi, работающий над решениями в сфере кремниевой фотоники, поставщик инфраструктуры ЦОД ZT Systems, а также софтверные стартапы Silo AI, Nod.ai и Mipsology. Кроме того, совсем недавно компания купила команду Untether AI, не став приобретать сам стартап.
06.06.2025 [17:58], Руслан Авдеев
AMD купила команду разработчика ИИ-чипов Untether AI, но не саму компанию, которая тут же закрыласьКомпания AMD объявила об очередной за несколько дней корпоративной покупке. Она наняла неназванное количество сотрудников Untether AI, разрабатывающей ИИ-чипы для энергоэффективного инференса в ЦОД и на периферии, сообщает Silicon Angle. Первым информацией о сделке поделился представитель рекрутинговой компании SBT Industries, специализирующейся на полупроводниковой сфере. Позже в AMD подтвердили, что компания приобрела «талантливую команду инженеров по аппаратному и программному ИИ-обеспечению» у Untether AI. Новые сотрудники помогут оптимизировать разработку компиляторов и ядер ИИ-систем, а также улучшить проектирование чипсетов, их проверку и интеграцию. Вероятно, сделку завершили в прошлом месяце, причём в команду не вошёл глава Untether Крис Уокер (Chris Walker), перешедший в стартап из Intel и возглавивший его в начале 2024 года. Судя по информации из соцсетей, Уокер покинул компанию в мае. Сделка довольно необычна, поскольку никаких активов компании не покупалось, но Untether AI уже объявила о закрытии бизнеса и поставок или поддержки чипов speedAI и ПО imAIgine Software Development Kit (SDK). 
Источник изображения: Untether AI Untether AI была основана 2018 году в Торонто (Канада). В июле 2021 года стартап привлёк $125 млн в раунде финансирования, возглавленном венчурным подразделением Intel Capital. Компания разрабатывала энергоэффективные чипы для инференса для периферийных решений, потребляющих мало энергии. В одной упаковке объединялись модули для вычислений и память. В октябре 2024 года начала продажи чипа speedAI240 Slim (развитие speedAI240). speedAI240 Slim, по данным компании, втрое энергоэффективнее аналогов в сегменте ЦОД. Помимо Intel, Untether AI имела партнёрские отношения с Ampere Computing, Arm Holdings и NeuReality. Буквально в минувшем апреле Уокер сообщил журналистам, что компания отметила большой спрос на свои чипы для инференса со стороны покупателей, ищущих альтернативы продуктам NVIDIA с более высокой энергоёмкостью. Более того, в прошлом году компания договорилась с индийской Ola-Krutrim о совместной разработке ИИ-ускорителей не только для инференса, но и для тюнинга ИИ-моделей. Покупка состоялась всего через два дня после объявления о приобретении малоизвестного стартапа Brium, специализировавшегося на инструментах разработки и оптимизации ИИ ПО. Вероятно, AMD заинтересована в использовании его опыта для оптимизации инференса на отличном от NVIDIA оборудовании. Сделка с Brium состоялась всего через шесть дней после того, как AMD объявила о покупке разработчика систем кремниевой фотоники Enosemi. Это поможет AMD нарастить компетенции в соответствующей сфере, поскольку всё больше клиентов пытаются объединять тысячи ускорителей для поддержки интенсивных ИИ-нагрузок.
02.06.2025 [09:02], Сергей Карасёв
EnCharge AI представила аналоговые ИИ-ускорители EN100Компания EnCharge AI анонсировала изделия семейства EN100 — аналоговые ИИ-ускорители для in-memory вычислений. Дебютировали устройства в форм-факторе M.2 для ноутбуков и карты расширения PCIe для настольных рабочих станций. Стартап EnCharge AI, основанный в 2022 году, разрабатывает чипы, которые дают возможность перенести ИИ-нагрузки из облака на локальные платформы. Для этого применяется концепция вычислений в оперативной памяти, позволяющая увеличить эффективность и устранить узкие места, связанные с перемещением данных. NPU-ядра EnCharge AI, как утверждает сам разработчик, обеспечивают производительность на уровне 40 Топс/Вт (8-бит точность). Ускоритель EN100 для ноутбуков имеет типоразмер M.2 2280. В оснащение входят 32 Гбайт памяти с пропускной способностью до 68 Гбайт/с. Быстродействие превышает 200 Топс при общем энергопотреблении не более 8,25 Вт. Для оркестрации задействована многопоточная архитектура RISC-V. 
Источник изображений: EnCharge AI На рабочие станции ориентированы ускорители EN100 в виде карт расширения PCIe HHHL. Они несут на борту 128 Гбайт памяти с суммарной пропускной способностью 272 Гбайт/с. Производительность составляет около 1 Попс. Изделия обоих типов изготавливаются с применением 16-нм CMOS-технологии. 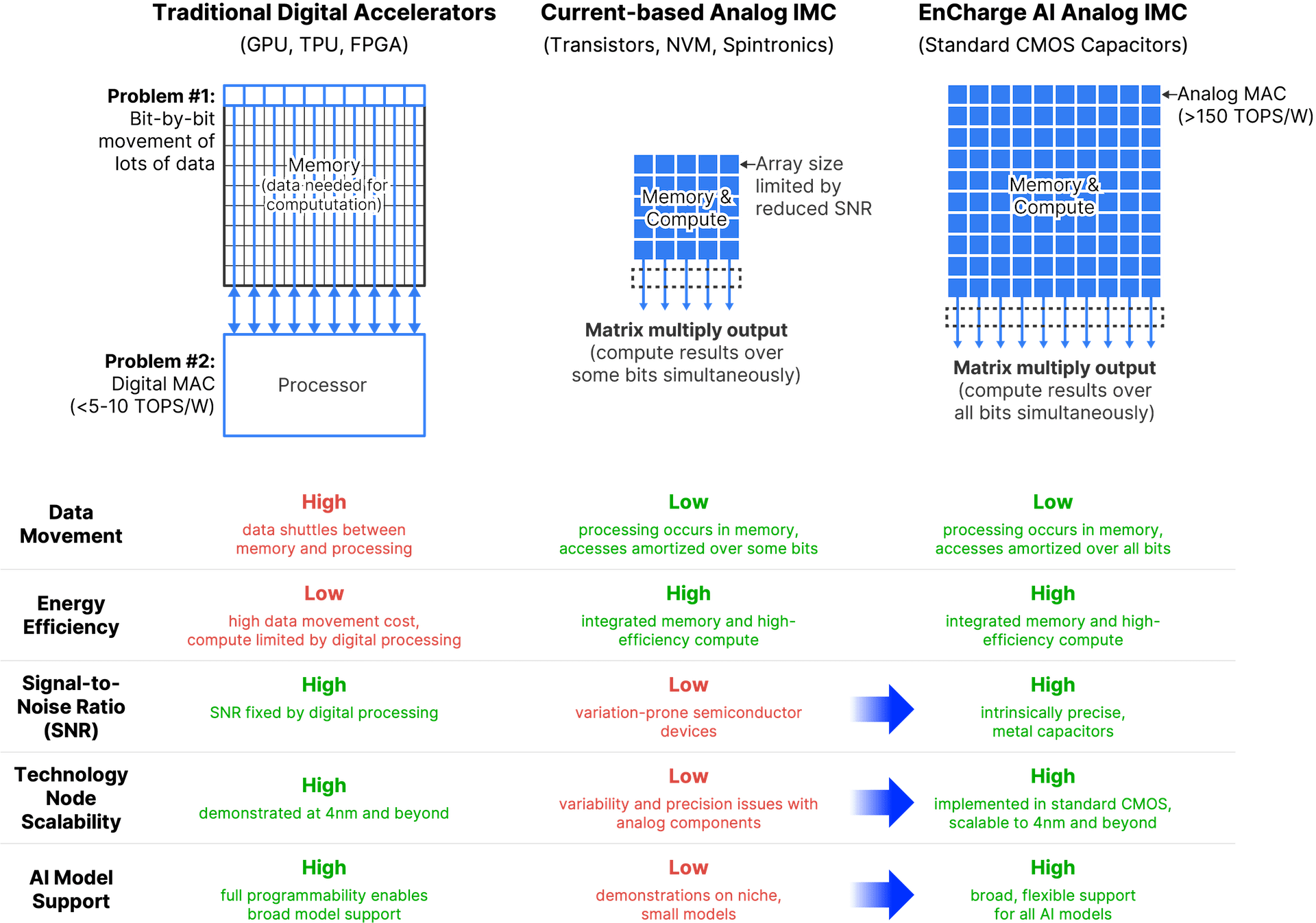 Навин Верма (Naveen Verma), генеральный директор EnCharge AI, заявляет, что решения компании позволят выполнять ресурсоёмкие задачи ИИ локально, не полагаясь на облачную инфраструктуру. Утверждается, что такие устройства по сравнению с современными ИИ-ускорителями обеспечат в 20 раз более высокую энергоэффективность (Топс/Вт) и в 9 раз более высокую плотность вычислений (Топс/мм2) при 10-кратном снижении совокупной стоимости владения (TCO).
23.05.2025 [13:46], Руслан Авдеев
ИИ-парковка: Tonomia интегрировала серверы в парковочные навесы с солнечными батареями и аккумуляторамиКомпания Tonomia предлагает размещение ИИ-ускорителей на… автопарковках — оборудование будет снабжаться энергией благодаря навесным солнечным элементам. Основанный в 2023 году бельгийский стартап сотрудничает с британским поставщиком оборудования Panchaea над созданием и продвижением комплекса eCloud, сообщает Datacenter Dynamics. Солнечные панели, используемые в качестве своеобразных «навесов» на парковках, нередко используются для подпитки АКБ электромобилей. Tonomia предложила использовать получаемую таким образом энергию и для питания ИИ-ускорителей своей облачной платформы. В компании полагают, что повсеместная установка таких «солнечных навесов» навесов в Европе и США позволит увеличить выработку энергии и снизить нагрузки на электросети, а интеграция вычислительного оборудования позволит получить дополнительный доход. Компания предложила объединить ИИ-серверы и действующие солнечные модули системы eParking с литий-ионными или натрий-ионными аккумуляторами. В Tonomia утверждают, что навесы способны генерировать до 600 Вт в Европе или 750 Вт в США (из-за большей площади парковок). Как утверждают в Panchaea, только в Европе есть более 350 млн наземных парковочных мест, причём большинство из них пустуют 80 % времени. Tonomia готова превратит автопарковки в «активы двойного назначения». 
Источник изображения: Tonomia Tonomia готова предложить ИИ-серверы Supermicro, MITAC или Panchaea. Конфигурации кластеров подбираются под особенности индивидуальных бизнес-моделей. Предполагается, что каждое парковочное место потенциально позволяет генерировать до 20 кВт∙ч ежедневно, т.е. около £8 ($10,74) в денежном эквиваленте, если исходить из стоимости инференса £0,40 ($0,53) за кВт·ч. Дополнительный доход может принести и зарядка электромобилей, передача энергии в электросеть и отдача избыточного тепла на обогрев близлежащих зданий. 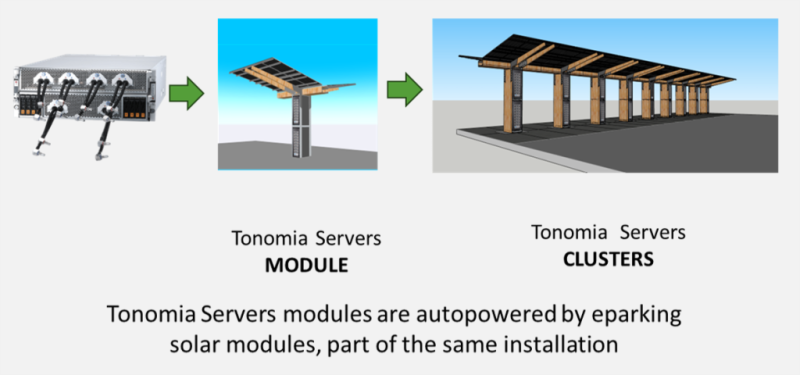
Источник изображения: Tonomia Tonomia разработала eCloud на основе оригинального продукта eParking после того, как к ней обратились игроки ИИ-сектора, заинтересованные в локальной генерации энергии. По словам компании, городам необходима подобная многофункциональная инфраструктура, а предприятиям нужны мощности для периферийных вычислений в непосредственной близости от потребителей. Кроме того, такая экоустойчивая система должна понравиться и регуляторам. Солнечная энергия активно используется в разных странах. Впрочем, как показывает европейский опыт, слишком много «зелёной» энергии — не всегда хорошо: Нидерланды уже столкнулись с определёнными проблемами. |
|

