Материалы по тегу: hardware
|
02.03.2026 [13:00], Руслан Авдеев
Облако AWS пострадало от «удара объектов по ЦОД» в ОАЭ, приведшего к пожаруЗоны доступности mec1-az2 и mec1-az3 в регионе AWS ME-CENTRAL-1 в ОАЭ прекратили работу после того, как по дата-центру ударили «объекты». По данным AWS, объекты вызвали «искры и возгорание». Пожарные отключили сетевое электропитание и генераторы объекта для того, чтобы без помех погасить огонь. Сервисы EC2 и S3 отключены полностью, ещё 84 сервиса подвержены различным проблемам. 
Источник изображения: Matt C/unsplash.com Зона mec1-az1 не пострадала. Тем, кто не использовал резервирование в нескольких зонах, компания рекомендует развернуть нагрузки из последних бэкапов в незатронутых зонах или регионах. Сообщается, что компания всё ещё ждёт разрешения для того, чтобы вновь подать питание, и как только получит его, будет обеспечено безопасное восстановление работы и связи. 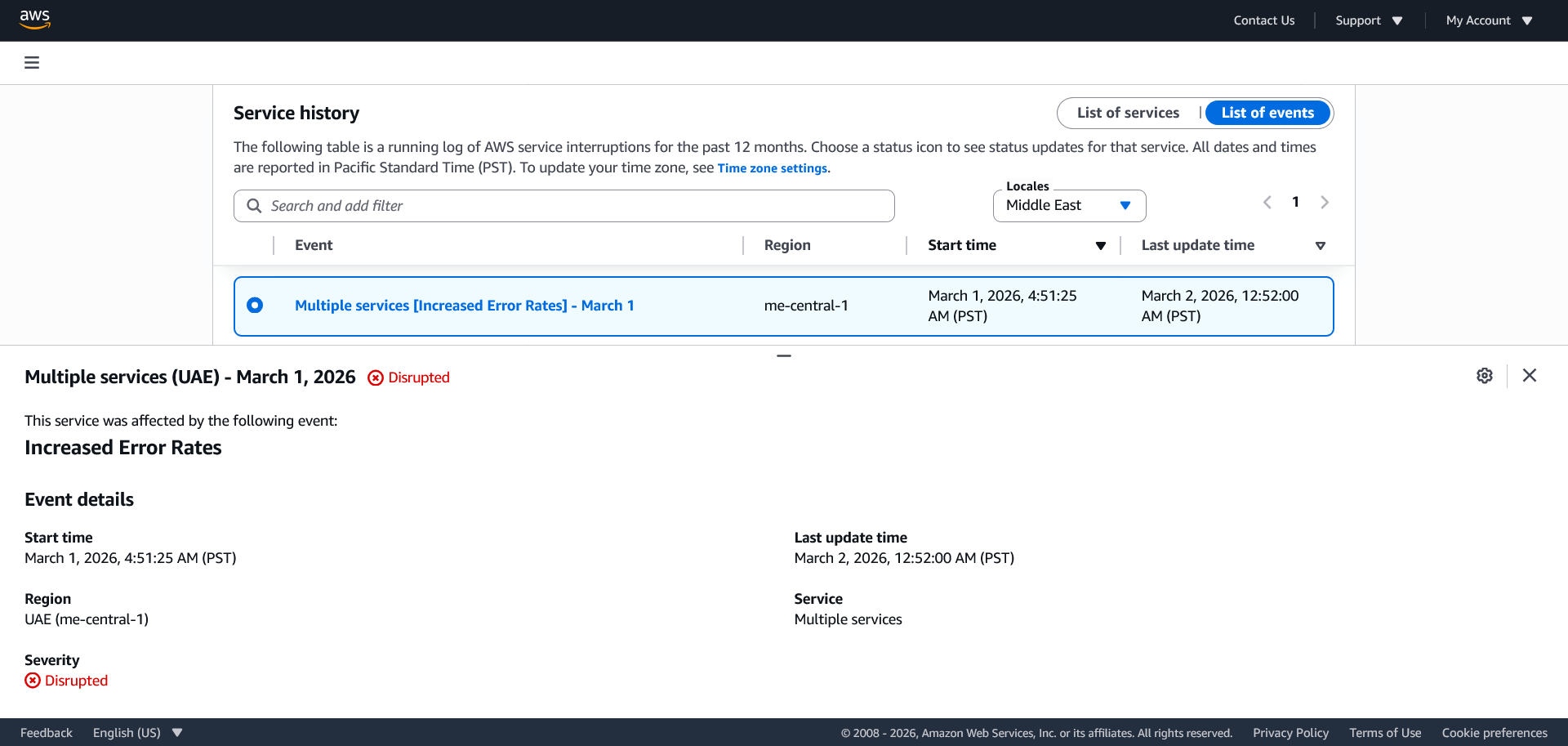
Источник изображения: AWS 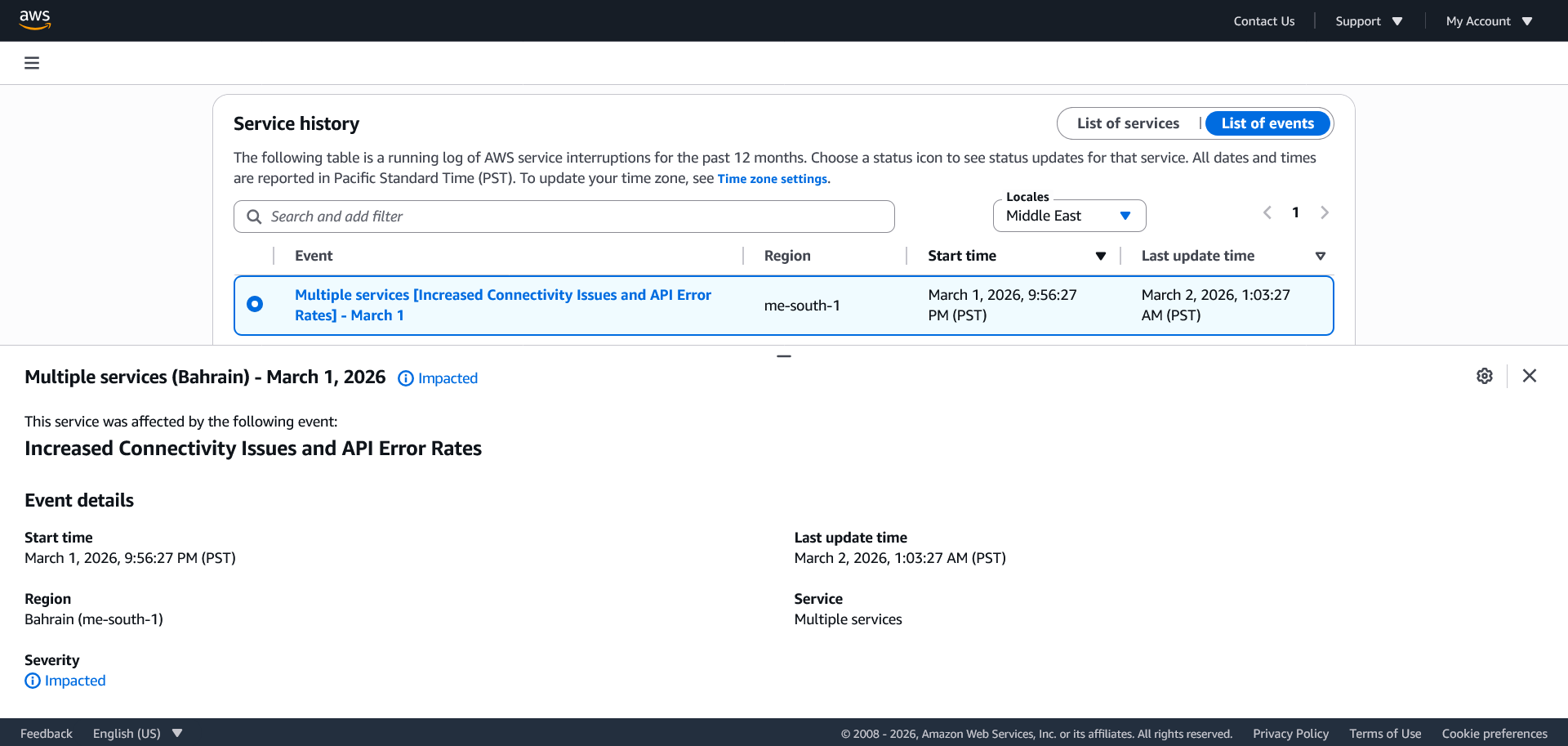
Источник изображения: AWS Одновременно пострадала и зона доступности mes1-az2 региона ME-SOUTH-1 в Бахрейне. Компания сообщает о проблемах с питанием и сетевым подключением, но не уточняет причины сбоя. Всего проблемы затронули 66 сервисов. Остальные зоны региона не пострадали.
02.03.2026 [12:35], Сергей Карасёв
Team Group анонсировала новые индустриальные NVMe SSD и модули памятиTeam Group готовит новые SSD в различных форм-факторах, а также модули оперативной памяти для индустриальных и встраиваемых систем. В частности, готовятся накопители Team Group Industrial R252 стандарта U.2 (NVMe), предназначенные для серверов. Эти устройства оснащены интерфейсом PCIe 5.0 x4. Они обеспечивают скорость последовательного чтения информации до 14 000 Мбайт/с, скорость последовательной записи — до 10 000 Мбайт/с. Кроме того, выйдут SSD серии Team Group Industrial R253, ориентированные на решение разнообразных задач в современных дата-центрах и на периферии. Такие устройства, получившие формат EDSFF E3.S, позиционируются в качестве накопителей большой ёмкости с улучшенной защитой данных. Они подходят для обработки ИИ-нагрузок, аналитики в реальном времени и пр. Дебютируют также SSD семейства Team Group Industrial R251 стандарта EDSFF E1.S, оптимизированные для серверов форм-фактора 1U. Эти накопители имеют сертификацию по стандартам виброустойчивости MIL-STD, что означает надёжность при эксплуатации в системах с высокой плотностью размещения оборудования. 
Источник изображений: Team Group В сегменте оперативной памяти Team Group представит новые модули Industrial DDR4 U-DIMM и SO-DIMM, специально разработанные для промышленного применения и IoT-устройств. Помимо этого, готовятся изделия Industrial DDR5 CU-DIMM и CSO-DIMM с частотой до 7200 МГц, рассчитанные на ИИ-платформы. На системы со значительной интенсивностью вычислений ориентированы решения Team Group Industrial LPDDR5X CAMM2: они обеспечивают высокую пропускную способность и низкую задержку. 
02.03.2026 [08:59], Владимир Мироненко
Fujitsu похвасталась, что её 2-нм процессоры MONAKA получат продвинутую упаковку Broadcom 3.5D XDSiPBroadcom объявила о начале поставок первой в отрасли 2-нм специализированной SoC, построенной на платформе 3.5D eXtreme Dimension System in Package (XDSiP). Модульная многомерная платформа с многослойной компоновкой чиплетов, 3.5D XDSiP, которая используется в чипе Fujitsu MONAKA, сочетает в себе 2.5D-упаковку и 3D-интеграцию с использованием технологии гибридного соединения между чиплетами (Face-to-Face, F2F), значительно повышающего пропускную способность. Сообщается, что технология 3.5D XDSiP станет основой XPU следующего поколения. С её помощью компании в сфере ИИ могут создавать самые передовые XPU с «беспрецедентной плотностью сигнала, превосходной энергоэффективностью и низкой задержкой», позволяющие удовлетворить вычислительные потребности ИИ-кластеров гигаваттного масштаба. Платформа Broadcom XDSiP позволяет масштабировать вычислительные ресурсы, память и сетевые интерфейсы независимо друг от друга в компактном форм-факторе, обеспечивая энергоэффективные вычисления с высокой производительностью, говорит компания. 
Источник изображения: Fujitsu «Мы гордимся тем, что представили первый специализированный SoC на базе 3.5D-упаковки для Fujitsu», — сказал Фрэнк Остоич (Frank Ostojic), старший вице-президент и генеральный директор подразделения ASIC-продуктов Broadcom. Он отметил, что с момента внедрения технологии 3.5D XDSiP в 2024 году компания Broadcom расширила возможности своей 3.5D-платформы, чтобы поддерживать XPU для более широкой клиентской базы, поставки которых начнутся во II половине 2026 года. Как отметил ресурс The Register, Fujitsu стала одной из первых компаний-разработчиков чипов, публично признавших использование этой технологии Broadcom. Обычно клиенты Broadcom не стремятся предать огласке, какие IP-блоки они лицензируют, а какие создают сами. Например, всем известно, что Google тесно сотрудничает с Broadcom в разработке TPU, но не всегда ясно, где заканчивается вклад Google и начинается работа Broadcom. «Мы работаем над этой технологией почти пять лет, — рассказал The Register Хариш Бхарадвадж (Harish Bharadwaj), вице-президент подразделения ASIC-продуктов Broadcom. — Мы отгрузили образцы на этой неделе для Fujitsu, и в своё время многие другие наши клиенты внедрили эту технологию для своих [решений] следующих поколений». 
Источник изображения: Satoshi Matsuoka (X/@ProfMatsuoka) Разрабатываемый Fujitsu чип MONAKA включает четыре 2-нм вычислительных чиплета, каждый — с 36 ядрами Armv9-A, расположенные поверх четырёх SRAM-чиплетов, изготовленных по 5-нм техпроцессу TSMC. Эти стеки объединяются с центральным I/O-чиплетом, который обслуживает 12 каналов DDR5 и линии PCIe 6.0/CXL 3.0, через кремниевую подложку-интерпозер. Кроме того, новинки получат поддержку NVIDIA NVLink. По словам Бхарадваджа, Fujitsu стала одной из первых компаний из числа внедривших технологию 3.5D XDSiP, но MONAKA является лишь одним из примерно полудюжины разрабатываемых проектов. Хотя MONAKA — это платформа для процессоров, примерно 80 % успешных проектов Broadcom с использованием XDSiP приходится на XPU с HBM, отметил он. В 2024 году сообщалось о поддержке платформой решений с 12 стеками HBM. В компании рассказали The Register, что сейчас разрабатываются проекты с более чем 12 стеками.
01.03.2026 [18:15], Руслан Авдеев
CPP Investments и Equinix купили за $4 млрд оператора экологичных ИИ ЦОД atNorthКанадский пенсионный фонд Canada Pension Plan Investment Board (CPP Investments) и Equinix анонсировали соглашение о покупке у Partners Group компании atNorth за $4 млрд, специализирующейся на предоставлении колокейшн-площадок для HPC/ИИ-нагрузок и провайдере ЦОД «под ключ», сообщает HPC Wire. Digital Realty, тоже пытавшаяся купить atNorth, осталась не у дел. CPP и Equinix предварительно согласовали финансирование в объёме $4,2 млрд (€3,6 млрд) как для закрытия самой сделки, так и для расширения бизнеса atNorth. CPP Investments намерена вложить около $1,6 млрд, получив долю в 60 % компании, а Equinix — около 40 %. Сообщается, что сразу после закрытия сделка, которая ещё ожидает одобрение регуляторов, окажет положительное действие на скорректированный денежный поток от операционной деятельности (AFFO) Equinix. Сделка укрепляет долговременное сотрудничество между Equinix и CPP Investments — в 2024 году было создано совместное предприятие с сингапурской GIC для расширения портфоли ЦОД xScale. У atNorth есть восемь действующих дата-центров, ещё несколько строятся в Дании, Финляндии, Исландии, Норвегии и Швеции — общий объём портфолио составляет 800 МВт. Кроме того, компания уже зарезервировала поставки 1 ГВт энергии. Некоторые объекты, разработанные для ИИ и HPC, поддерживают жидкостное охлаждение. Также компания активно внедряет возобновляемую энергетику, инициативы по использованию избыточного тепла от оборудования, в том числе для выращивания овощей, и модульный дизайн для минимизации ущерба окружающей среде и продвижению экономики замкнутого цикла. 
Источник изображения: atNorth atNorth заявляет, что компания по-прежнему будет придерживаться работы в северном регионе и продолжит независимую работу под собственным брендом, сохраняя приверженность культуре и ценностям, которые она продвигает. В CPP Investments подчеркнули, что сделка основана на уже имеющемся долгосрочном сотрудничестве с Equinix. Фонд намерен и далее наращивать бизнес в быстрорастущем секторе ЦОД. Equinix подчеркнула, что для клиентов, нуждающихся в надёжном масштабировании, компания предлагает готовую к будущим задачам инфраструктуру с сохранением юридического и информационного суверенитета. Северная Европа укрепляет статус критически важного хаба для следующего этапа цифрового роста. Он имеет сильную и надёжную экономику, активно внедряет инновации, делает ставку на исследования и техническую экспертизу, а также экоустойчивые проекты. Здесь есть много источников возобновляемой энергии и оптимальный для ЦОД климат. Equinix располагает восемью ЦОД на севере Европы: пять в Хельсинки и три в Стокгольме. Всего же в ведении компании есть более 100 объектов в 20 странах. В Европе компания на 100 % компенсирует энергопотребление своих дата-центров за счёт покупок возобновляемой энергии. Это вполне соответствует «зелёному» курсу atNorth и, как ожидается, Equinix добьётся нулевых выбросов к 2040 году.
28.02.2026 [23:59], Владимир Мироненко
Hyundai инвестирует более $6 млрд в ИИ ЦОД, роботов, водородную и солнечную энергетику
hardware
hyundai
nvidia
водород
ии
инвестиции
робототехника
солнечная энергия
финансы
цод
энергетика
южная корея
Hyundai Motor Group и правительство Южной Кореи подписали соглашение об инвестировании около ₩9 трлн ($6,26 млрд) с целью строительства объединённого инновационного центра в районе Сэмангым (Saemangeum) города Кунсан (Gunsan), который будет включать в себя ИИ ЦОД, завод по производству робототехники и производство водородной/солнечной энергии, сообщило агентство Reuters со ссылкой на министерство земельных ресурсов страны. По данным ведомства, около ₩5,8 трлн (около $4,04 млрд) Hyundai инвестирует в строительство ИИ ЦОД, в котором будет развёрнуто 50 тыс. NVIDIA Blackwell. ЦОД будет оснащён «массивным» хранилищем для хранения огромных массивов данных для обучения, разработки программно-определяемых транспортных средств (SDV) и внедрения «умных заводов», заявили в Hyundai. Ожидается, что интегрированная платформа позволит ускорить исследования и разработку продукции по всей цепочке создания стоимости. Ещё ₩400 млрд (около $278,8 млн) будет выделено на строительство завода по производству роботов, в том числе носимых (экзоскелетов). Также компания инвестирует ₩1 трлн (около $697,2 млн) в строительство электролизерной установки с протонообменной мембраной (Proton Exchange Membrane, PEM) мощностью 200 МВт для производства экологически чистого водорода с использованием возобновляемых источников энергии на месте. Hyundai планирует со временем достичь общей мощности электролизеров в 1 ГВт на внутреннем рынке. Hyundai утверждает, что её технология PEM достигла более чем 90 % локализации, что способствует технологической независимости Южной Кореи и расширению экспортных возможностей экологически чистого водорода, сообщил ресурс Data Center Knowledge. 
Источник изображения: Hyundai Motor Company Оставшуюся часть суммы в размере ₩1,3 трлн (около $906,6 млн) компания направит в солнечную энергетику — строительство солнечных электростанций гигаваттного масштаба к 2035 году на основе действующей с 2021 года 99-МВт электростанции. Hyundai рассматривает ЦОД как «мозг» своей ИИ-экосистемы, объединяющий данные производства, логистики и эксплуатации транспортных средств для развития ИИ внутри страны. В центре также будет создан «умный город» с водородными технологиями на основе ИИ, который интегрирует технологии в единую экосистему. Строительство ЦОД, солнечной инфраструктуры и объекта по производству водорода планируется начать в 2027 году и завершить в 2029 году. По прогнозам Hyundai, эти инвестиции принесут экономический эффект в размере около ₩16 трлн (примерно $11 млрд) и позволят создать около 71 тыс. рабочих мест.
28.02.2026 [12:23], Владимир Мироненко
TrendForce: капзатраты восьми гиперскейлеров в 2026 году превысят ВВП ИрландииВ этом году, по оценкам TrendForce, восемь крупнейших мировых облачных провайдеров — Google, Amazon, Meta✴, Microsoft, Oracle, Tencent, Alibaba и Baidu — направят более $710 млрд на капитальные затраты, что примерно на 61 % больше, чем в прошлом году и превышает валовой внутренний продукт (ВВП) Ирландии за прошлый год. Около $650 млрд из этой суммы приходится на первых четверых гиперскейлеров из этого списка, пишет The Register. Эти средства будут потрачены на строительство и расширение ЦОД, а также оборудование для них, включая высокопроизводительные серверы, обычно оснащённые ускорителями AMD или NVIDIA. Также набирают популярность ASIC других брендов, которые в отличие от универсальных ускорителей разрабатываются для конкретных видов нагрузки. По данным TrendForce, Google остаётся единственной облачной компанией, которая добавляет больше серверов на базе ASIC, чем на базе GPU. По оценкам аналитиков консалтинговй компании, процессоры Tensor Processing Units (TPU) будут использоваться примерно в 78 % ИИ-серверов для дата-центров Google в этом году. Ожидается, что у Amazon 60 % серверов будут оснащены GPU, и компания начнёт наращивать системы на базе Trainium3 позже в этом году. Компания Meta✴ также будет в основном полагаться на ускорители NVIDIA и AMD, которыми будут оснащены более 80 % серверов, установленных в этом году. Microsoft продолжит закупать стоечные системы NVIDIA, а Oracle расширяет развёртывание стоечных серверов с GPU. Из китайских операторов Tencent также продолжит развёртывать серверы с ускорителями NVIDIA, пусть и опосредованно. 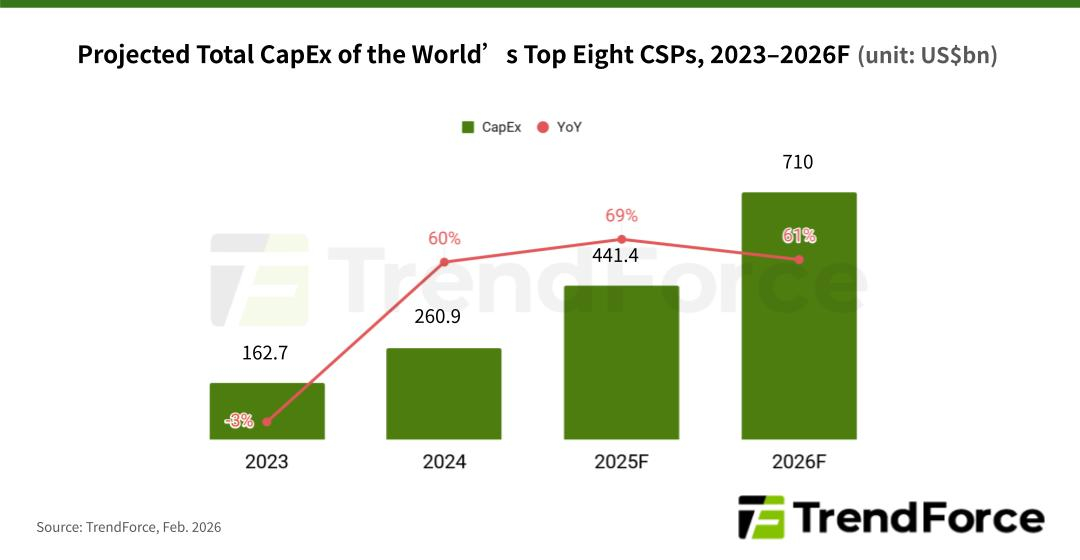
Источник изображения: TrendForce The Register отметил, что высокий спрос на ИИ-серверы привёл к росту цен на память и её дефициту, поскольку производители переводят производственные линии на выпуск высокорентабельных решений, таких как память HBM. Производители микросхем памяти SK Hynix и Sandisk объявили о работе над процессом стандартизации HBF-памяти для ИИ-инференса. SK hynix описывает HBF как новый уровень памяти между сверхбыстрой HBM и высокоёмкими SSD, утверждая, что она снизит совокупную стоимость владения (TCO), одновременно повышая масштабируемость ИИ-систем. Согласно прогнозу компании, спрос на такие решения, как HBF, возрастёт примерно к 2030 году.
28.02.2026 [11:43], Сергей Карасёв
Supermicro представила высокоплотную платформу MicroBlade на базе AMD EPYC 4005Компания Supermicro анонсировала новую серверную платформу MicroBlade для облачных и периферийных развёртываний. Система, как утверждается, на сегодняшний день обладает самой высокой плотностью компоновки из всех доступных решений, использующих процессоры AMD EPYC 4005 Grado. Основой MicroBlade служат узлы MBA-315R-1DE12, рассчитанные на чипы в исполнении AM5 (LGA-1718). Могут применяться процессоры с TDP до 110 Вт, насчитывающие до 16 вычислительных ядер (32 потока инструкций). В расчёте на процессор доступны два слота для модулей оперативной памяти DDR5-5600 суммарным объёмом до 128 Гбайт. Каждый узел оснащается контроллером Aspeed AST2600 BMC, двумя сетевыми портами 25GbE на базе Broadcom BCM57414, а также модулем TPM 2.0, отвечающим за безопасность. Возможна установка одного SSD формата M.2 (NVMe) и двух накопителей EDSFF E1.S. Диапазон рабочих температур — от +10 до +35 °C. Габариты составляют 589,28 × 125,48 × 30,48 мм, масса — около 1,5 кг. 
Источник изображения: Supermicro Новая платформа поддерживает до 40 узлов в одном корпусе форм-фактора 6U. Таким образом, в серверной стойке 48U могут разместиться до 320 узлов. Supermicro подчёркивает, что это обеспечивает «беспрецедентную вычислительную плотность, энергоэффективность и экономичность для масштабируемых и многопользовательских сред». Решение MicroBlade подходит для широкого спектра нагрузок, среди которых названы виртуальные частные серверы, периферийные системы, микросервисы, службы обработки данных, приложения в области кибербезопасности, площадки электронной коммерции и пр.
28.02.2026 [11:37], Сергей Карасёв
ASUS готовит «беспамятные» облачные мини-ПК NUC 16 для Windows 365Компания ASUS сообщила о скором выходе компьютеров небольшого форм-фактора NUC 16, оптимизированных для использования облачного ПО Windows 365. Устройства, заключенные в корпус объёмом всего 0,7 л, построены на аппаратной платформе Intel. Полностью технические характеристики NUC 16 for Windows 365 не раскрываются. При этом ASUS говорит о применении «новейшего процессора Intel», работающего в тандеме с памятью DDR5. Сетевые источники считают, что с учётом специфики компьютеров могут быть задействованы чипы поколения Twin Lake или Wildcat Lake. В оснащение устройств входят адаптеры Wi-Fi 6E и Bluetooth 5.3, сетевой контроллер 2.5GbE, интерфейс HDMI, порты USB Type-C (20 Гбит/с) и USB Type-A (10 Гбит/с), стандартное аудиогнездо на 3,5 мм. Внешне изделия напоминают мини-компьютер ASUS NUC 16 Pro, который использует платформу Intel Panther Lake. В максимальной конфигурации устанавливается процессор Core Ultra X9 388H с 16 ядрами (4Р+8Е+4LPE), а объём ОЗУ достигает 128 Гбайт. Возможна установка SSD типоразмера М.2 с интерфейсом PCIe 5.0 x4 (NVMe) вместимостью до 8 Тбайт. Этот компьютер рассчитан на работу с Windows 11 Pro или Home. Габариты составляют 144 × 117 × 42 мм, масса — 685 г. Допускается монтаж посредством крепления VESA. Однако в случае нового NUC 16 локальное хранение данных и приложений не предполагается — всё находится в Microsoft Azure, что как минимум позволит сэкономить на дефицитных SSD и RAM. 
Источник изображения: ASUS Кроме того, сообщается, что компактные компьютеры для работы с Windows 365 готовит Dell. Речь идёт об устройствах Pro Desktop, которые получат процессор Intel N-Series с пассивным охлаждением. Это означает, что может быть использован чип Twin Lake или Alder Lake-N. Упомянуты порты USB Type-C и USB Type-A, а также 3,5-мм аудиогнездо.
28.02.2026 [09:48], Сергей Карасёв
Dell представила подвесной уличный сервер PowerEdge XR9700 с замкнутой СЖОDell анонсировала сервер PowerEdge XR9700, предназначенный для инфраструктур Cloud RAN и ИИ-приложений на периферии. Устройство рассчитано на эксплуатацию в неблагоприятных условиях, в том числе на открытом воздухе: оно может монтироваться на опорах линий электропередач, крышах и фасадах зданий. Новинка заключена в корпус объёмом около 15 л. Говорится о сертификации IP66 и GR-3108 Class 4: серверу не страшны пыль, влага и воздействие прямого солнечного излучения. Диапазон рабочих температур простирается от -40 до +46 °C. В основу PowerEdge XR9700 положена аппаратная платформа Intel Xeon 6 SoC — Granite Rapids-D (до 72 P-ядер, TDP до 325 Вт). Также возможна установка ИИ-ускорителей и различных сетевых карт, в том числе для обработки L1-трафика. Задействована система жидкостного охлаждения с замкнутым контуром, а ребристая внешняя поверхность работает в качестве радиатора. Без СЖО с таким уровнем тепловыделения CPU/GPU и в таком компактном корпусе уже вряд ли можно обойтись. 
Источник изображений: Dell Отмечается, что с технической точки зрения устройство идентично модели PowerEdge XR8720t, которая дебютировала в октябре прошлого года. В зависимости от конфигурации это решения располагает четырьмя или восемью слотами для модулей DDR5. Возможна установка до трёх SSD формата M.2 (NVMe). В оснащение могут входить два порта 100GbE QSFP и восемь портов 10/25GbE SFP. Реализованы интерфейсы USB 3.0 Type-A, UCB Type-C, Mini-DisplayPort и пр.  Заявлена поддержка Wind River SUSE Linux Enterprise Server/RT, Ubuntu Server LTS и Red Hat Enterprise Linux/RT. Интегрированный контроллер удалённого доступа Dell (iDRAC) обеспечивает мониторинг и управление. Говорится о совместимости с существующим набором решений для периферийных вычислений в области телекоммуникаций. В продажу PowerEdge XR9700 поступит во II половине текущего года.
27.02.2026 [22:55], Владимир Мироненко
Amazon вложит в OpenAI $50 млрд, OpenAI в ответ потратит $100 млрд на 2 ГВт мощностей TrainiumOpenAI и Amazon объявили о заключении соглашения о стратегическом партнёрстве с целью ускорения инноваций в области ИИ для предприятий, стартапов и конечных потребителей по всему миру. В рамках многолетнего соглашения Amazon инвестирует в OpenAI $50 млрд — $15 млрд первым траншем, а затем еще $35 млрд в ближайшие месяцы при выполнении определённых условий. AWS и OpenAI совместно создадут среду выполнения с сохранением состояния (Stateful Runtime Environment) на базе моделей OpenAI, которая будет доступна в Amazon Bedrock для создания приложений и агентов генеративного ИИ. Подобное окружение позволяет разработчикам сохранять контекст, запоминать предыдущую работу, работать с различными программными инструментами и источниками данных, а также получать доступ к вычислительным ресурсам. Новинка будет интегрирована с Amazon Bedrock AgentCore и инфраструктурными сервисами, чтобы приложения и ИИ-агенты клиентов работали согласованно с остальными приложениями инфраструктуры, работающими в AWS. AWS также станет эксклюзивным сторонним поставщиком облачных услуг для платформы OpenAI Frontier, позволяющей компаниям создавать, развёртывать и управлять командами ИИ-агентов, работающих в реальных бизнес-системах с общим контекстом. По мере перехода компаний от экспериментов к внедрению ИИ в производство, Frontier упрощает быструю, безопасную и глобальную интеграцию ИИ-технологий в существующие рабочие процессы. Кроме того, OpenAI и Amazon будут сотрудничать в разработке пользовательских моделей для работы с приложениями Amazon, ориентированными на клиентов. 
Источник изображения: Amazon AWS и OpenAI также сообщили о расширении ещё на $100 млрд более раннего соглашения о многолетнем стратегическом партнёрстве стоимостью $38 млрд, в рамках которого AWS обязалась предоставлять OpenAI в течение семи лет доступ к ускорителям NVIDIA. Расширенное соглашение со сроком действия 8 лет включает в себя обязательство OpenAI использовать около 2 ГВт мощностей на базе ускорителей Trainium, чтобы поддерживать спрос на Stateful Runtime, Frontier и другие рабочие нагрузки. Это обязательство распространяется как на чипы Trainium3, так и на чипы следующего поколения Trainium4, которые появятся в 2027 году и получат технологию NVIDIA NVLink. Сегодняшний день оказался богатым на события для OpenAI. Компания объявила о привлечении $110 млрд инвестиций в рамках раунда финансирования с предварительной оценкой её рыночной стоимости в $730 млрд, что значительно больше оценки в $500 млрд в октябре 2025 года. Лидером раунда стала Amazon с инвестициями в $50 млрд, за ней следуют NVIDIA и SoftBank, инвестировавшие по $30 млрд. Компания заявила, что ожидает, что к раунду присоединятся и другие инвесторы. Ранее Anthropic, ключевой конкурент OpenAI, закрыл раунд финансирования на $30 млрд, подняв капитализацию до $380 млрд. У компании долгие и тесные отношения с AWS, которая развернула для стартапа один из крупнейших в мире ИИ-кластеров Project Rainier. Впрочем, Anthropic тоже старается диверсифицировать поставки вычислительных мощностей — она заключила контракты с Microsoft (на чипы NVIDIA), а также с Google (на TPU). |
|

