Материалы по тегу: c
|
17.07.2024 [11:21], Руслан Авдеев
SK Telecom инвестирует $200 млн в Smart Global Holdings (Penguin Solutions) для совместной работы над ИИ- и HPC-инфраструктуройЮжнокорейская телекоммуникационая компания SK Telecom вложит $200 млн в бизнес Smart Global Holdings (SGH), связанный с системами искусственного интеллекта и инфраструктурными ИИ-проектами. По данным Datacenter Dynamics, в обмен на инвестиции SK получит часть акций SGH. В дальнейшем компании намерены совместно работать над использованием «взаимодополняющих возможностей» для расширения спектра предложений клиентам и создания дифференцированных комплексных решений и сервисов в области ИИ и дата-центров, предлагать передовые решения для рынка памяти и периферийных ИИ-серверов на базе NPU-чипов. Калифорнийская SGH уже продаёт ряд платформ и сервисов для HPC, ИИ, машинного обучения, отказоустойчивых вычислений и Интернета вещей, в том числе периферийные и облачные решения. Благодаря приобретению в 2018 году бизнеса Penguin Solutions компания предлагает интегрированные ИИ-решения для ЦОД, от разработки ИИ-кластеров до внедрения и поддержки эксплуатации таких продуктов. Совсем недавно компания объявила о ребрнединге — теперь SGH почти полностью уходит под «зонтик» Penguin Solutions, компания должна сменить имя до конца текущего года. Стоит отметить, что Penguin Solutions известна как поставщик HPC-решений для государственных и военных ведомств США. 
Источник изображения: Alexander Schimmeck/unsplash.com Глава SGH поприветствовал SK Telecom в качестве нового стратегического инвестора, заявив, что новость стала свидетельством возможностей Penguin Solutions по внедрению в больших масштабах «фабрик ИИ», ПО и прочих решений. Ожидается, что сотрудничество принесёт немало выгоды и акционерам. Ранее в текущем году SGH приняла участие в раунде финансирования серии C другой компании — Lambda Labs, привлёкшей $320 млн. SK Telecom получит 200 тыс. привилегированных акций в SGH, которые она сможет конвертировать в простые акции по цене $32,81 каждая. Компания расширяет своё ИИ-портофолио. В прошлом году она инвестировала $100 млн в Anthropic, стоящей за серией LLM Claude. По словам представителя SK Telecom, инвестиции и дальнейшее сотрудничество укрепит позиции южнокорейского гиганта в сфере ИИ.
09.07.2024 [17:02], Владимир Мироненко
IDC увеличила прогноз затрат на облачную инфраструктуру в 2024 годуКомпания International Data Corporation (IDC) опубликовала результаты исследования мирового рынка облачных инфраструктур за I квартал 2024 года. Согласно оценкам IDC, за квартал, завершившийся в марте, на вычислительные мощности и хранилища по всему миру было израсходовано $54,4 млрд, что на 46 % больше показателя годичной давности. Часть суммы была потрачена на выделенную (dedicated) инфраструктуру, которая размещается в собственных ЦОД или колокейшн-объектах, а часть на общедоступную (shared) облачную инфраструктуру. Следует отметить, что речь в данном случае идёт о продажах конечным потребителям или партнёрам по сбыту. Как полагает ресурс The Next Platform, порядка 40 % этой суммы было потрачено на ИИ-системы, большей частью на их аренду, причём в основном эти системы используют ускорители NVIDIA. По данным IDC, из общей суммы компании потратили в I квартале 2024 года $26,3 млрд на общедоступную облачную инфраструктуру, что на 43,9 % больше, чем в прошлом году. Как отметили аналитики, на неё по-прежнему приходится наибольшая доля расходов по сравнению с выделенной инфраструктурой и необлачными расходами. В I квартале 2024 года на долю общедоступного облака пришлось 56,1 % всех расходов на инфраструктуру. Расходы на выделенную облачную инфраструктуру выросли не столь сильно — на 15,3 % до $6,7 млрд, что ниже среднего показателя за последние 24 месяца в $7,4 млрд в квартал. В сумме расходы на всю облачную инфраструктуру, как общедоступную, так и выделенную, составили $33,0 млрд, что больше год к году на 36 %. На традиционную (необлачную) инфраструктуру было израсходовано $13,9 млрд (рост — 5,7 %). 
Источник изображений: IDC Если оценивать динамику затрат по регионам, то в основном она была положительной, за исключением Латинской Америки, продемонстрировавшей снижение на 2,8 %. Почти во всех регионах рост затрат исчисляется двузначными цифрами, за исключением Западной Европы, а также Ближнего Востока и Африки, где он составил 4,0 % и 5,3 % соответственно. В число регионов, показавших уверенный двузначный рост расходов, вошли Азиатско-Тихоокеанский регион (исключая Японию и Китай), Япония, Центральная и Восточная Европа, США, Китай и Канада, где расходы на облачные технологии выросли год к году на 85,4 %, 53,1 %, 42,6 %, 37,0 %, 33,7 % и 16,1 % соответственно. Большая часть роста связана с крупными HPC- и ИИ-проектами, некоторые из которых в прошлом были отложены из-за проблем с поставками. IDC также значительно повысила прогноз по затратам на 2024 год. Согласно оценкам, в этом году затраты на облачную инфраструктуру вырастут год к году на 26,1 % до $138,3 млрд. Расходы на необлачную инфраструктуру вырастут на 8,4 % до $64,8 млрд. Общедоступная облачная инфраструктура, как ожидают в IDC, покажет рост 30,4 % год к году до $108,3 млрд (предыдущий прогноз — $95,3 млрд). Затраты на выделенную облачную инфраструктуру увеличатся на 12,8 % до $30,0 млрд (ранее ожидалось $34,6 млрд). Комментируя аналитические выкладки IDC, ресурс The Next Platform отметил, что облачная инфраструктура продолжит увеличивать долю в общих затратах на вычислительных ресурсы и СХД. Два года назад на неё приходилось 63,8 % все расходов, в прошлом году — 64,7 %, в этом году ожидается 68,1 %, а в 2028 году — 73,6 %.
08.07.2024 [11:29], Сергей Карасёв
Компактный компьютер ASUS ExpertCenter PN43 оснащён двумя портами 2.5GbEКомпания ASUS анонсировала компьютер небольшого форм-фактора ExpertCenter PN43, предназначенный для использования в бизнес-сфере. В основу устройства положена аппаратная платформа Intel Alder Lake-N, а в качестве ОС может применяться Windows 11 Pro. Доступны модификации с чипом Intel Processor N200 (4C/4T; до 3,7 ГГц; 6 Вт), Intel Processor N100 (4C/4T; до 3,4 ГГц; 6 Вт) и Intel Processor N97 (4C/4T; до 3,6 ГГц; 12 Вт). Есть один слот для модуля памяти DDR4 SO-DIMM ёмкостью до 32 Гбайт и коннектор M.2 2280 для SSD с интерфейсом PCIe 3.0 x4. 
Источник изображения: ASUS Устройство заключено в корпус с габаритами 166,2 × 119,7 × 33,9 мм, а масса составляет 0,7 кг. В оснащение входят адаптеры Intel Wi-Fi 6E (Gig+) 2 × 2 и Bluetooth 5.3, двухпортовый сетевой контроллер 2.5GbE. Питание подаётся от внешнего блока мощностью 65 Вт. Допускается монтаж при помощи крепления VESA.  На фронтальную панель выведены четыре порта USB 3.2 Gen1 Type-A, гнездо для микрофона и аудиовыход. Сзади располагаются три порта USB 2.0, интерфейсы DisplayPort 1.4 и HDMI 2.1 (до 4K; 60 Гц), два гнезда RJ-45 для сетевых кабелей, конфигурируемый разъём (USB Type-C, D-Sub или последовательный порт), гнездо для блока питания. Возможен одновременный вывод изображения на два дисплея формата 4K или на три монитора Full HD. ASUS ExpertCenter PN43 предлагается в модификациях с активным (вентилятор) и пассивным охлаждением. Верхняя и боковые панели имеют перфорацию для циркуляции воздуха.
05.07.2024 [16:42], Руслан Авдеев
TotalEnergies запустила гибридный суперкомпьютер Pangea 4 для ускорения «зелёного перехода»Французская нефтегазовая компания TotalEnergies ввела в эксплуатацию гибридный суперкомпьютер Pangea 4. Машина находится в Научно-техническом центре Жана Феже в По (Jean Féger Scientific and Technical Center at Pau) на юго-западе Франции и состоит из вычислительных мощностей, размещённых на самой площадке, и облачных ресурсов Pangea@Cloud. Pangea 4 компактнее и энергоэффективнее предшественницы Pangea II — она использует на 87 % меньше энергии. Компания не раскрывает производительность новой машины, хотя и указывает, что она вдвое производительнее одной из предыдущих машин. Машина Pangea III с теоретической пиковой FP64-производительностью 31,7 Пфлопс, ставшая в своё время самым мощным индустриальным суперкомпьютером, продолжит свою работу. Pangea 4 была создана HPE, которая также строит суперкомпьютер HPC6 для итальянской нефтегазовой компании Eni. 
Источник изображения: TotalEnergies Pangea 4 будет использоваться не только для традиционных геофизических расчётов, но и для проектов по улавливанию и захоронению CO2, моделированию биотоплива и полимеров, расчётов механик снижения метановых выбросов, моделирования воздушных потоков для проектирования ветроэнергетических установок и т.д. А комбинация on-premise вычислений с облачными отвечает растущим запросам бизнеса, особенно с сфере новой энергетики — для того, чтобы помочь реализовать стратегию «зелёного перехода». Впрочем, приверженность компании «зелёным» ценностям находится под вопросом. TotalEnergies входит в одну из семи крупнейших нефтяных компаний. В прошлом году исследователи Oil Change International сообщили, что TotalEnergies занимала третье место по одобрению новых проектов расширения нефте- и газодобычи и использовала рекордную выручку для удвоения инвестиций в ископаемое топливо.
04.07.2024 [23:59], Владимир Мироненко
Systême Electric представила первые продукты для мониторинга и автоматизации инфраструктуры ЦОДРоссийская производственная компания «Систэм Электрик» (Systême Electric, ранее Schneider Electric в России) объявила о выходе семейства продуктов для мониторинга и автоматизации инфраструктуры ЦОД, которое включает устройство мониторинга параметров окружающей среды SystemeBotz, решение для контроля доступа в ИТ-стойку SystemeBotzAC, а также ПО для централизованного мониторинга DCGuard. Решения являются полноценной заменой аналогичной продукции APC. Новинки будут доступны для проведения опытно-промышленной эксплуатации на объектах клиентов до 31 октября 2024. SystemeBotz представляет собой масштабируемую систему активного мониторинга, призванную обеспечить защиту помещений, технологического и ИТ-оборудования от различных факторов риска. Это типовое решение сетевого мониторинга серверных комнат, узлов связи и ЦОД, которое устанавливается в стойку и позволяет подключить без надобности в предварительной настройке различные типы датчиков Systême Electric: температуры и влажности, точечных и ленточных протечек, положения двери, дыма и пожара, наличия напряжения, датчики типа «сухой контакт». 
Источник изображения: «Систэм Электрик» SystemeBotzAC — система контроля и управления доступом, разработанная для защиты стоек, позволяющая в режиме реального времени выполнять мониторинг факторов риска физического воздействия и несанкционированного доступа к ИТ-инфраструктуре. Система включает датчики положения дверей, ручки стоек со встроенными считывателями карт, коммуникационные блоков для передачи параметров, блоки питания и IP-камеры. Все компоненты системы совместимы с серверными шкафами Systême Electric, а также некоторыми стойками других производителей. Программная платформа верхнего уровня DCGuard в режиме реального времени собирает, хранит и визуализирует параметры работы инженерной инфраструктуры объекта, оповещая пользователя об инцидентах и аварийных событиях. DCGuard обеспечивает сбор данных по промышленным протоколам для однофазных и трёхфазных ИБП, рядных и периметральных кондиционеров, PDU) устройств мониторинга параметров окружающей среды, систем холодоснабжения (чиллеров, драйкуллеров, частотно-регулируемых приводов и др.), систем мониторинга батарей, дизель-генераторных установок, а также распределительных щитов.
02.07.2024 [23:55], Алексей Степин
15 тыс. ускорителей на один ЦОД: Alibaba Cloud рассказала о сетевой фабрике, используемой для обучения ИИAlibaba Cloud раскрыла ряд сведений технического характера, касающихся сетевой инфраструктуры и устройства своих дата-центров, занятых обработкой ИИ-нагрузок, в частности, обслуживанием LLM. Один из ведущих инженеров компании, Эньнань Чжай (Ennan Zhai), опубликовал доклад «Alibaba HPN: A Data Center Network for Large Language Model Training», который будет представлен на конференции SIGCOMM в августе этого года. В качестве основы для сетевой фабрики Alibaba Cloud выбрала Ethernet, а не, например, InfiniBand. Новая платформа используется при обучении масштабных LLM уже в течение восьми месяцев. Выбор обусловлен открытостью и универсальностью стека технологий Ethernet, что позволяет не привязываться к конкретному вендору. Кроме того, меньше шансы пострадать от очередных санкций США. Отмечается, что традиционный облачный трафик состоит из множества относительно небыстрых потоков (к примеру, менее 10 Гбит/с), тогда как трафик при обучении LLM включает относительно немного потоков, имеющих периодический характер со всплесками скорости до очень высоких значений (400 Гбит/с). При такой картине требуются новые подходы к управлению трафиком, поскольку традиционные алгоритмы балансировки склонны к перегрузке отдельных участков сети. 
Источник здесь и далее: Alibaba Cloud Разработанная Alibaba Cloud альтернатива носит название High Performance Network (HPN). Она учитывает многие аспекты работы именно с LLM. Например, при обучении важна синхронизация работы многих ускорителей, что делает сетевую инфраструктуру уязвимой даже к единичным точкам отказа, особенно на уровне внутристоечных коммутаторов. Alibaba Cloud использует для решения этой проблемы парные коммутаторы, но не в стековой конфигурации, рекомендуемой производителями. 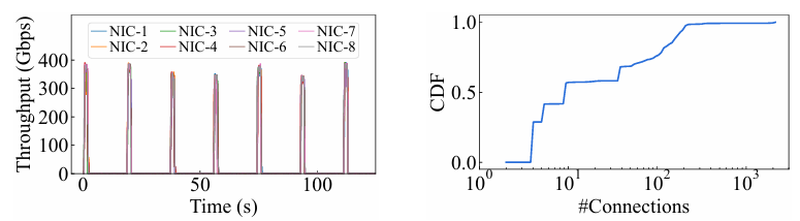
Характер трафика при обучении LLM Каждый хост содержит восемь ИИ-ускорителей и девять сетевых адаптеров. Каждый из NIC имеет по паре портов 200GbE. Девятый адаптер нужен для служебной сети. Между собой внутри хоста ускорители общаются посредством NVLink на скорости 400–900 Гбайт/с, а для общения с внешним миром каждому из них полагается свой 400GbE-канал с поддержкой RDMA. При этом порты сетевых адаптеров подключены к разным коммутаторам из «стоечной пары», что серьёзно уменьшает вероятность отказа. 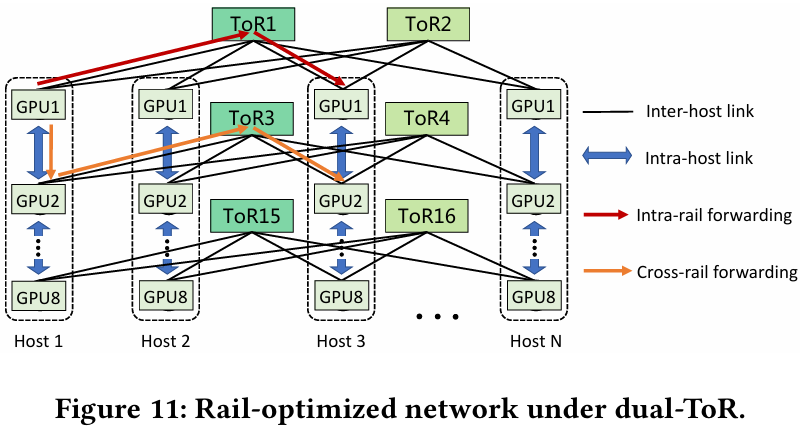 В докладе говорится, что Alibaba Cloud использует современные одночиповые коммутаторы с пропускной способностью 51,2 Тбит/с. Этим условиям отвечают либо устройства на базе Broadcom Tomahawk 5 (март 2023 года), либо Cisco Silicon One G200 (июнь того же года). Судя по использованию выражения «начало 2023 года», речь идёт именно об ASIC Broadcom. 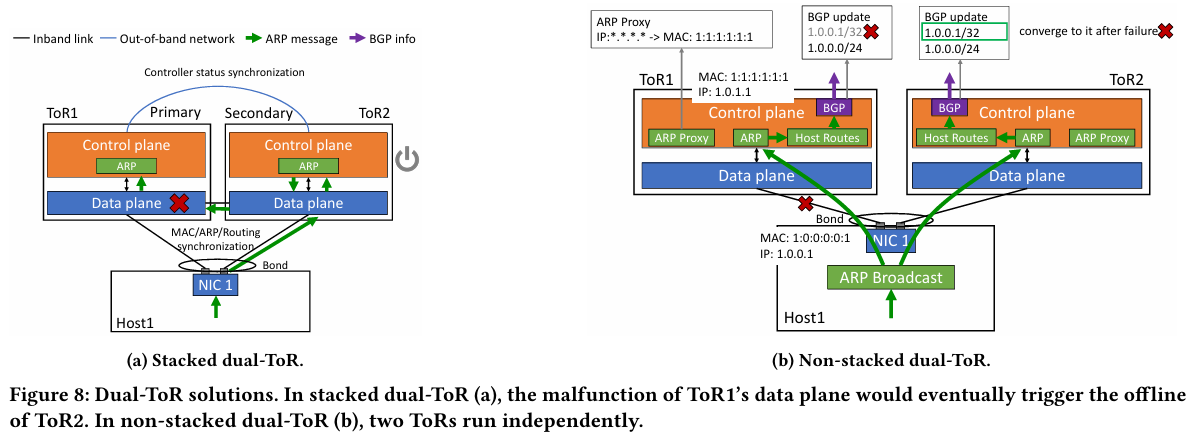 Своё предпочтение именно одночиповых коммутаторов компания объясняет просто: хотя многочиповые решения с большей пропускной способностью существуют, в долгосрочной перспективе они менее надёжны и стабильны в работе. Статистика показывает, что аппаратные проблемы у подобных коммутаторов возникают в 3,77 раза чаще, нежели у одночиповых. 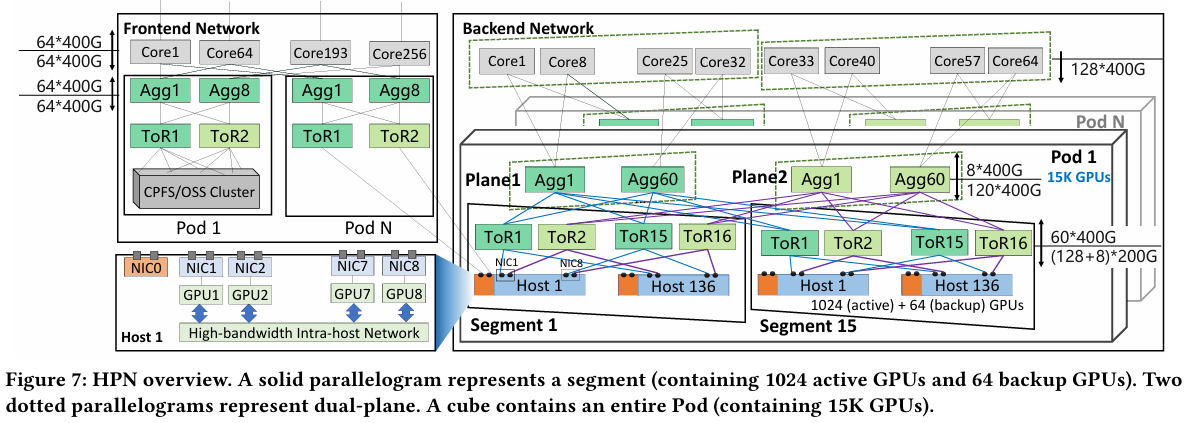 Одночиповые решения класса 51,2 Тбит/с выделяют много тепла, но ни один поставщик оборудования не смог предложить Alibaba Cloud готовые решения, способные удерживать температуру ASIC в пределах 105 °C. Выше этого порога срабатывает автоматическая защита. Поэтому для охлаждения коммутаторов Alibaba Cloud создала собственное решение на базе испарительных камер. 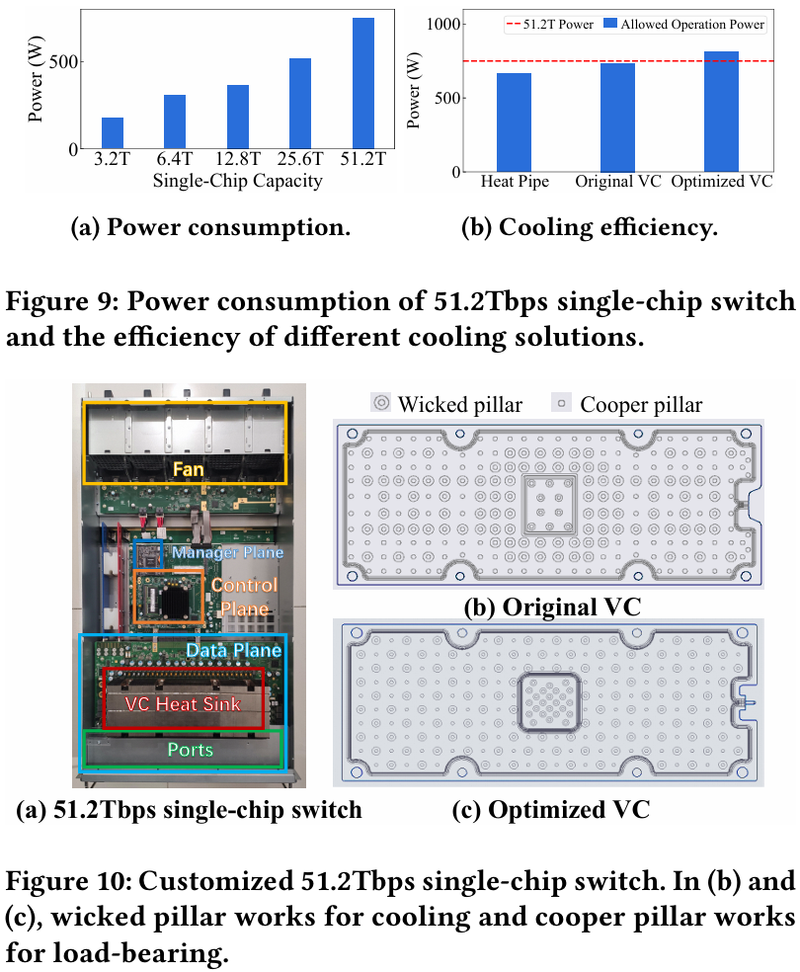 Сетевая фабрика позволяет создавать кластеры, каждый из которых содержит 15360 ускорителей и располагается в отдельном здании ЦОД. Такое высокоплотное размещение позволяет использовать оптические кабели длиной менее 100 м и более дешёвые многомодовые трансиверы, которые дешевле одномодовых примерно на 70 %. Ёмкость такого дата-центра составляет около 18 МВт. 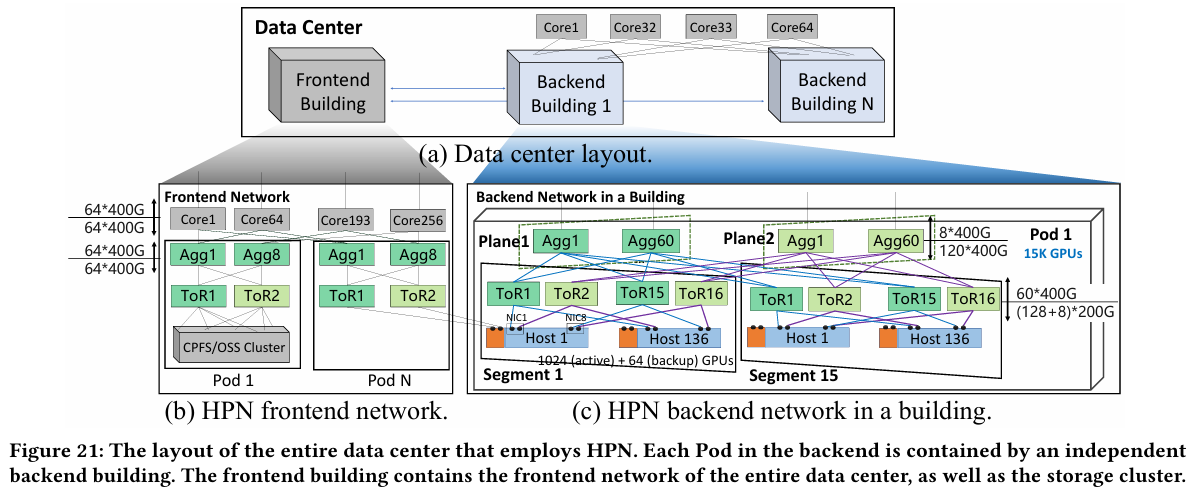 Но есть у HPN и недостаток: использование топологии с двумя внутристоечными коммутаторами и другие особенности архитектуры усложняют кабельную подсистему, поэтому инженеры поначалу столкнулись с ростом ошибок при подключении сетевых интерфейсов. В настоящее время активно используются тесты, позволяющие проверить каждое подключение на соответствие идентификаторов портов и коммутаторов рабочим схемам. Отмечается, что параметры Ethernet-коммутаторов удваиваются каждые два года, поэтому компания уже разрабатывает сетевую архитектуру следующего поколения, рассчитанную на применение будущих ASIC 102,4 Тбит/с. По словам Alibaba Cloud, обучение LLM с сотнями миллиардов параметров потребует огромного распределённого кластера, количество ускорителей в котором исчисляется миллионами. И ему требуется соответствующая сетевая инфраструктура.
30.06.2024 [14:28], Сергей Карасёв
В Австралии запущен ИИ-суперкомпьютер Virga [Обновлено]Государственное объединение научных и прикладных исследований Австралии (CSIRO) сообщило о вводе в эксплуатацию высокопроизводительного вычислительного комплекса Virga. Система, предназначенная для ИИ-задач, ускорит научные открытия, а также поможет развитию промышленности и экономики страны. Суперкомпьютер располагается в дата-центре Hume компании CDC в Канберре. Его созданием занималась компания Dell: в основу положены серверы PowerEdge XE9640, оснащённые двумя процессорами Intel Xeon Sapphire Rapids 8452Y (36C/72T, 2,0/3,2 ГГц, 300 Вт), до 512 Гбайт RAM и четырьмя 61,44-Тбайт NVMe SSD. Задействованы ИИ-ускорители NVIDIA H100 с 96 Гбайт памяти HBM3 — всего 448 шт. Система занимает 14 стоек, а в качестве интерконнекта используется Infiniband NDR. Dell заключила контракт на создание Virga в 2023 году: сумма изначально составляла $9,65 млн, однако фактическое строительство комплекса обошлось в $10,85 млн. Новый суперкомпьютер придёт на смену НРС-системе CSIRO предыдущего поколения под названием Bracewell, но унаследует от неё BeeGFS-хранилище, также построенное на оборудовании Dell. В нынешнем рейтинге TOP500 машина занимает 72 место с пиковой и практической FP64-производительностью 18,46 Пфлопс и 14,94 Пфлопс соответственно. Комплекс Virga получил своё имя в честь метеорологического эффекта «вирга» — это дождь, который испаряется, не достигая земли: видеть его можно в виде полос, выходящих из-под облаков. Систему Virga планируется использовать для таких задач, как прогнозирование пожаров, разработка вакцин нового поколения, проектирование гибких солнечных панелей, анализ медицинских изображений и пр. 
Источник изображения: CSIRO Пока подробные технические характеристики Virga и показатели быстродействия не раскрываются. Отмечается лишь, что в составе комплекса применена гибридная система прямого жидкостного охлаждения. Говорится также, что CDC оперирует двумя кампусами дата-центров Hume. Площадка Hume Campus One объединяет три ЦОД и имеет мощность 21 МВт, тогда как в состав Hume Campus Two входят два объекта суммарной мощностью 51 МВт.
27.06.2024 [12:58], Сергей Карасёв
В Японии запущен суперкомпьютер TSUBAME4.0 с ускорителями NVIDIA H100 для ИИ-задачГлобальный научно-информационный вычислительный центр (GSIC) Токийского технологического института (Tokyo Tech) в Японии объявил о вводе в эксплуатацию вычислительного комплекса TSUBAME4.0, созданного компанией HPE. Новый суперкомпьютер будет применяться в том числе для задач ИИ. В основу машины легли 240 узлов HPE Cray XD665. Каждый из них несёт на борту два процессора AMD EPYC Genoa и четыре ускорителя NVIDIA H100 SXM5 (94 Гбайт HBM2e). Объём оперативной памяти DDR5-4800 составляет 768 Гбайт. Задействован интерконнект Infiniband NDR200. Вместимость локального накопителя NVMe SSD — 1,92 Тбайт. В состав НРС-комплекса входит подсистема хранения данных HPE Cray ClusterStor E1000. Сегмент на основе HDD имеет ёмкость 44,2 Пбайт — это в 2,8 раза больше по сравнению с суперкомпьютером предыдущего поколения TSUBAME 3.0. Кроме того, имеется SSD-раздел ёмкостью 327 Тбайт. Пиковая производительность TSUBAME4.0 достигает 66,8 Пфлопс (FP64), что в 5,5 больше по отношению к системе третьего поколения. Быстродействие на операциях половинной точности (FP16) поднялось в 20 раз по сравнению с TSUBAME3.0 — до 952 Пфлопс. 
Источник изображения: Tokyo Tech На сегодняшний день TSUBAME4.0 является вторым по производительности суперкомпьютером в Японии после Fugaku. Эта система в нынешнем рейтинге TOP500 занимает четвёртое место с показателем 442 Пфлопс. Лидером в мировом масштабе является американский комплекс Frontier — 1,21 Эфлопс.
26.06.2024 [01:00], Игорь Осколков
Etched Sohu — самый быстрый в мире ИИ-ускоритель, но только для трансформеровСтартап Etched, основанный в 2022 году выпускниками Гарварда, анонсировал самый быстрый, по его словам, ИИ-ускоритель Sohu. Секрет высокой производительности очень прост — Sohu представляет собой узкоспециализированный 4-нм ASIC, который умеет работать только с моделями-трансформерами. При этом в длинном анонсе новинки обещана чуть ли не революция в мире ИИ. Etched прямо говорит, что делает ставку на трансформеры, и надеется, что не прогадает. Данная архитектура ИИ-моделей была создана в недрах Google в 2017 году, но сама Google распознать её потенциал, по-видимому, вовремя не смогла. Сейчас же, по словам Etched, практически все массовые ИИ-модели являются именно трансформерами, а стремительно набирать популярность этот подход начал всего полтора года назад с выходом ChatGPT, хотя в Etched «предугадали» важность трансформеров ещё до выхода детища OpenAI. 
Источник изображений: Etched Etched в целом справедливо отмечает, что подавляющее большинство ИИ-ускорителей умышленно создаётся так, чтобы быть достаточно универсальными и уметь работать с различными типами и архитектурами ИИ-моделей. Это ведёт к взрывному росту транзисторного бюджета и уменьшению общей эффективности. Так, по словам Etched, загрузка ускорителя на базе GPU работой на практике составляет около 30 %, а у Sohu она будет на уровне 90 %.  Тут есть некоторое лукавство, потому что Etched в основном говорит о «больших» ускорителях, ориентированных и на обучение тоже, тогда как Sohu предназначен исключительно для инференса. На практике же бывают и гибридные подходы. Например, у AWS есть не только Trainium, но Inferentia. Meta✴ использует чипы NVIDIA для обучения, но для инференса разрабатывает собственные ускорители MTIA. Cerebras практически отказалась от инференса, а Groq — от обучения моделей. Корректнее было бы сравнить именно инференс-ускорители, пусть даже никто из упомянутых Etched конкурентов не ориентирован исключительно на трансформеры.  Также стартап критикует громоздкую программную экосистему для современного генеративного ИИ, к тому же не всегда открытую. Важность оптимизации ПО хороша видна на примере NVIDIA TensorRT-LLM. Но крупным компаниям этого мало, они готовы вкладывать немало средств в глубокую оптимизацию, чтобы ещё чуть-чуть повысить производительность. Дело доходит до выяснения того, у какого регистра задержка меньше при работе с каким тензорным ядром, говорит Etched. Стартап обещает, что его заказчикам не придётся заниматься такими изысканиями — весь программный стек будет open source. Впрочем, на примере AMD ROCm видно, что открытость ещё не означает мгновенный успех у пользователей. 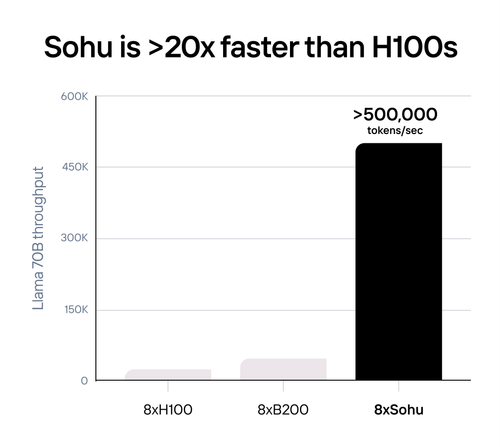 Технические характеристики Sohu не раскрываются. Явно говорится лишь о наличии 144 Гбайт HBM3e. Обещанная производительность сервера с восемью ускорителями Sohu составляет 500 тыс. токенов в секунду для Llama 70B: FP8 без разреженности, параллелизм на уровне модели, 2048 токенов на входе и 128 токенов на выходе. Иными словами, один такой сервер Sohu заменяет сразу 160 ускорителей NVIDA H100, говорит Etched. А вот про масштабируемость своих платформ компания пока ничего не говорит. Зато хвастается, что первые заказчики уже зарезервировали Sohu на десятки миллионов долларов.
25.06.2024 [17:01], Сергей Карасёв
Второй в Европе экзафлопсный суперкомпьютер Alice Recoque разместится во Франции, а его создание обойдётся в €544 млнЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о подписании соглашения с французским национальным агентством высокопроизводительных вычислений (GENCI) о размещении второго в Европе суперкомпьютера экзафлопсного класса. Напомним, первым европейским HPC-комплексом с производительностью более 1 Эфлопс станет Jupiter, который расположится в Юлихском исследовательском центре (FZJ) в Германии. В создании системы участвуют NVIDIA, ParTec, Eviden и SiPearl. В состав суперкомпьютера войдут модули NVIDIA Quad GH200, а также энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea. Машина будет развёрнута на базе модульного ЦОД. Ввод в эксплуатацию запланирован в 2024 году. Второй в Европе экзафлопсный суперкомпьютер получил имя Alice Recoque) — в честь французского учёного, компьютерного инженера и специалиста по компьютерной архитектуре. Она работала над созданием мини-компьютеров в 1970-х годах и руководила исследованиями, связанными с ИИ. 
Мини-компьютер Mitra-15, разработанный под руководством Алисы Рекок (Фото: Damien.b / Wikipedia) Стоимость создания машины оценивается в €544 млн. Управление суперкомпьютером возьмёт на себя Французская комиссия по альтернативным источникам энергии и атомной энергии (CEA). Комплекс будет смонтирован на территории Брюйер-ле-Шатель, к юго-западу от Парижа. Для размещения и эксплуатации машины выбран французско-нидерландский консорциум Жюля Верна. Известно, что в основу суперкомпьютера ляжет модульная энергоэффективная архитектура. По мере необходимости в состав системы могут добавляться дополнительные узлы на базе GPU или квантовых процессоров. Комплекс, в частности, будет построен на Arm-чипах SiPearl Rhea2, которые в настоящее время находятся в разработке. Не исключается также применения высокопроизводительных RISC-V процессоров EPI EPAC. Запуск Alice Recoque предварительно намечен на 2026 год, но может затянуться до 2027–2028 гг. Система будет доступна академическим организациям, государственным структурам и промышленным предприятиям. Использовать её планируется для выполнения ресурсоёмких задач в области ИИ и НРС. |
|

