Материалы по тегу: arm
|
27.09.2024 [21:50], Руслан Авдеев
Ampere создаст кастомные Arm-процессоры для UberКомпания Uber намерена использовать кастомные Arm-процессоры Ampere Computing в облаке Oracle Cloud Infrastructure (OCI). В частности, компании займутся оптимизацией чипов для ИИ-задач. До недавнего времени Uber использовала преимущественно собственные ЦОД, но в 2022 году приняла решение перенести большую часть задач в облака. С ростом количества ЦОД и зон доступности управлять IT-инфраструктурой Uber становилось всё сложнее. На ввод в эксплуатацию новой зоны порой требовались месяцы и сотни специалистов, поскольку управление серверами происходило чуть ли не «вручную», а инструменты автоматизации часто подводили. Рассмотрев различные варианты развития, Uber постепенно пришла к сотрудничеству с Ampere, Goolge и Oracle. А в феврале 2023 года компания подписала крупные семилетние облачные контракты с Google и Oracle. По данным Uber, водители и курьеры компании выполняют более 30 млн заказов ежедневно. Для этого требуется большая IT-инфраструктура, например, для оптимизации маршрутов, в том числе с применением ИИ-технологий — ежесекундно к ИИ-моделям приходит 15 млн запросов. По оценкам Uber и Ampere, перенос нагрузок в OCI не только снизил инфраструктурные затраты, но и уменьшил энергопотребление на 30 %. Сейчас компании совместно работают над новыми чипами, выявляя, какие изменения в микроархитектуру стоит внести, чтобы будущие процессоры оптимально подходили для задач Uber. 
Источник изображения: Denys Nevozhai/unsplash.com Собственные Arm-процессоры разрабатывают AWS, Google Cloud и Microsoft Azure — Graviton, Axion и Cobalt 100 соответственно. Однако кастомизацией под конкретного клиента, пусть даже крупного, они не занимаются. Тем не менее, эксперты IDC считают, что облачные клиенты безусловно выиграют от совместной подготовки с разработчиками чипов новых полупроводниковых решений. Клиенты могут обладать специфическими знаниями и интеллектуальной собственностью, но как правило не имеют возможности самостоятельно вывести на рынок готовый продукт. Сейчас Uber переносит тысячи микросервисов, многочисленные платформы хранения данных и десятки ИИ-моделей в OCI. Компания уже перевела значительную часть бессерверных рабочих нагрузок на платформы на базе Ampere. Впрочем, дело не ограничивается только Ampere — компания также активно использует инстансы на базе чипов AMD.
27.09.2024 [00:20], Владимир Мироненко
Oracle может получить полный контроль над производителем серверных Arm-процессоров Ampere ComputingКорпорация Oracle, уже владеющая 29 % акций стартапа Ampere Computing, специализирующегося на разработке серверных Arm-процессоров, может использовать будущие инвестиционные опции, чтобы получить над ним контроль, пишет Bloomberg. Об этом стало известно из нормативного документа, направленного Oracle регулятору на этой неделе. В нём сообщается, что в дополнение к долевому участию в стартапе Oracle инвестировала в течение финансового года, закончившегося 31 мая 2024 года, $600 млн в конвертируемые долговые ценные бумаги, выпущенные Ampere, после того как в 2023 финансовом году приобрела таких ценных бумаг на $400 млн. Срок погашения долга наступает в июне 2026 года. В случае реализации опций на приобретение дополнительной доли в капитале стартапа до января 2027 года Oracle «получит контроль над Ampere», указано в документе, подготовленном Oracle. 
Источник изображения: Ampere В документе также сообщается, что основатель и гендиректор Ampere Рене Джеймс (Renee James), а также Джеймс Вишал Сикка (Vishal Sikka), основатель и гендиректор Vianai Systems, покинут совет директоров Oracle и не будут баллотироваться на переизбрание на ежегодном собрании акционеров 14 ноября. В результате состав участников совета директоров сократится с 15 до 13 человек. Джеймс вошла в совет директоров Oracle в декабре 2015 года, а Сикка — в декабре 2019 года. По оценкам Ampere, в настоящее время 95 % сервисов Oracle используют её CPU, а недавно компания договорились о партнёрстве с Uber. Тем не менее, Oracle сообщила в документе, что сократила закупки микросхем Ampere. Компания разместила заказ по предоплате на процессоры Ampere в размере $104,1 млн в 2023 финансовом году. В итоге она получила чипы на $4,7 млн напрямую и на $43,2 млн через посредников. В 2024 финансовом году она приобрела чипы Ampere на $3 млн напрямую, но ничего не закупала через дистрибуторов. На данный момент предоплата Oracle за чипы составляет $101,1 млн. Что касается доли в Ampere, Oracle сообщила, что «общая балансовая стоимость её инвестиций в Ampere, после учёта убытков по методу долевого участия, составила $1,5 млрд по состоянию на 31 мая». Ранее стало известно, что Ampere больше не планирует в ближайшем будущем IPO и изучает возможность своей продажи крупному игроку рынка.
20.09.2024 [00:50], Владимир Мироненко
Ampere отказалась от IPO и может быть продана крупному игроку отраслиСтартап Ampere Computing LLC из Санта-Клары (Калифорния, США), специализирующийся на разработке серверных Arm-процессоров, в последние месяцы работал с финансовым консультантом с целью определения факторов, которые бы способствовали появлению интереса у крупных компаний к его поглощению, пишет Bloomberg. По словам источников ресурса, стартап открыт для переговоров с крупным игроком отрасли. Ampere продолжает обсуждать возможные варианты и может остаться независимой, говорят источники. Компания уже больше не планирует IPO в ближайшем будущем, хотя этого нельзя исключать в дальнейшем. В 2021 году капитализация Ampere исходя из инвестиционных предложений SoftBank Group была оценена в $8 млрд. Хотя стартап всё ещё может извлечь пользу из ажиотажа на рынке ИИ, конкуренция в полупроводниковой отрасли становится жёстче. Несколько крупных технологических компаний спешат разрабатывать те же типы чипов, которые производит Ampere, отметил Bloomberg. Планируемая сделка будет своего рода отступлением от своих позиций для основательницы компании и гендиректора Ampere Рене Джеймс (Renee James), которая рассматривала возможность вывода Ampere на биржу. Более того, в апреле 2022 года компания заявила, что подала конфиденциальную заявку на IPO в США. Как раз тогда начал расти спрос на чипы, а технологическое сообщество начало понемногу возвращаться в офисы после вызванного пандемией перехода на удалённый формат работы. 
Источник изображения: Ampere По словам Ampere, некоторые из крупнейших облачных провайдеров, включая Microsoft и Google, используют её чипы. Вместе с тем ей приходится конкурировать с их внутренними командами, поскольку гиперскейлеры стремятся быть менее зависимыми от внешних разработчиков технологий. В частности, Google занимается созданием собственного серверного Arm-процессора Axion, а Microsoft — Cobalt 100. Также следует добавить, что поскольку отрасль ЦОД переоснащается из-за роста интереса к ИИ-технологиям, Ampere, как и более крупные конкуренты вроде Intel и AMD, вынуждена реагировать на увеличение спроса на ускорители в ущерб CPU. Решение Ampere будет также зависеть от её крупнейшего инвестора в лице Oracle, которая, вероятно, является и крупнейшим заказчиком компании. Oracle уже портировала свою фирменную СУБД на чипы Ampere, а также перевела на них облачные сервисы OCI. Серверами с чипами Ampere в облаке Orale пользуется, например, Uber. По данным Bloomberg, объём сделок в полупроводниковой промышленности в этом году вырос более чем вдвое и составил около $60 млрд. Среди крупнейших сделок — соглашение Renesas о покупке компании Altium за AU$9,1 млрд ($6,2 млрд) и продажа Intel доли в предприятии, контролирующем завод по производству чипов в Ирландии, компании Apollo Global Management за $11 млрд.
10.09.2024 [14:55], Сергей Карасёв
TACC ввёл в эксплуатацию Arm-суперкомпьютер Vista на базе NVIDIA GH200 для ИИ-задачТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) объявил о том, что мощности нового НРС-комплекса Vista полностью доступны открытому научному сообществу. Суперкомпьютер предназначен для решения ресурсоёмких задач, связанных с ИИ. Формальный анонс машины Vista состоялся в ноябре 2023 года. Тогда говорилось, что Vista станет связующим звеном между существующим суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Vista состоит из двух ключевых частей. Одна из них — кластер из 600 узлов на гибридных суперчипах NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель H100/H200. Обеспечивается производительность на уровне 20,4 Пфлопс (FP64) и 40,8 Пфлопс на тензорных ядрах. Каждый узел содержит локальный накопитель вместимостью 512 Гбайт, 96 Гбайт памяти HBM3 и 120 Гбайт памяти LPDDR5. Интероконнект — Quantum 2 InfiniBand (400G). Второй раздел суперкомпьютера объединяет 256 узлов с процессорами NVIDIA Grace CPU Superchip, содержащими два кристалла Grace в одном модуле (144 ядра). Узлы укомплектованы 240 Гбайт памяти LPDDR5 и накопителем на 512 Гбайт. Интерконнект — Quantum 2 InfiniBand (200G). Узлы произведены Gigabyte, а за интеграцию всей системы отвечала Dell. 
Источник изображения: TACC Общее CPU-быстродействие Vista находится на отметке 4,1 Пфлопс. В состав комплекса входит NFS-хранилише VAST Data вместимостью 30 Пбайт. Суперкомпьютер будет использоваться для разработки и применения решений на основе генеративного ИИ в различных секторах, включая биологические науки и здравоохранение.
12.08.2024 [09:53], Владимир Мироненко
Mercury Research: Intel под натиском AMD теряет долю на рынке CPUIntel постепенно теряет лидирующие позиции на рынке серверных, настольных и мобильных процессоров, хотя по-прежнему удерживает его львиную долю, пишет The Register со ссылкой на исследование Mercury Research, сделанное по итогам II квартала 2024 года. Согласно данным Mercury Research, Intel потеряла год к году несколько п.п. доли рынка в каждой из трёх основных категорий CPU — серверных, настольных и мобильных — в то время как доля AMD выросла. Самых больших успехов AMD добилась в сегменте серверных процессоров, где увеличила долю рынка на 5,6 % до 24,1 % поставок, что также превышает показатель предыдущего квартала. В сегменте мобильных устройств доля поставок AMD выросла на 3,8 % до 20,3 % по сравнению с аналогичным периодом прошлого года, что также немного больше показателей I квартала. 
Источник изображения: Obie Fernandez / Unsplash Вместе с тем суммарные поставки процессоров во II квартале снизились по сравнению с I кварталом, что, как отметили аналитики, ниже обычных сезонных колебаний. Mercury Research объясняет сокращение рынка гораздо более низкими поставками в сегментах Интернета вещей (IoT) и систем на кристалле (SoC) — рынках встраиваемых решений — из-за более слабого спроса на эти чипы, особенно на SoC AMD для игровых консолей. Также сократились поставки мобильных процессоров начального уровня, в основном используемых в Chromebook. Если учитывать этот нюанс, то Intel фактически увеличила общую долю рынка — на 7 % по сравнению с прошлым годом, что в Mercury Research объясняют сокращением выпуска AMD SoC. Хотя AMD увеличила общую долю клиентских и серверных решений, этого оказалось недостаточно для компенсации резкого сокращения поставок SoC, заявил президент Mercury Research Дин Маккаррон (Dean McCarron). 
Источник изображения: Intel Intel завершила II квартал 2024 года с убытками в размере $1,61 млрд, хотя годом ранее у неё была в аналогичном квартале чистая прибыль в размере $1,48 млрд. В связи с этим компания объявила план по сокращению расходов, включающий увольнение более 16 000 сотрудников — не менее 15 % персонала — и сокращение капитальных вложений более чем на 20 % до $25–27 млрд. Ранее Intel была вынуждена признать наличие проблем у некоторыми из своих процессоров Raptor Lake 13-го и 14-го поколений, и выпускает исправление микрокода для их устранения, которое включено в обновления BIOS. Руководитель Intel Пэт Гелсингер (Pat Gelsinger), объяснил слабые показатели II квартала ограничениями США на экспорт поставок чипов в Китай, но, как отметил The Register, на этом также отразился тот факт, что у компании нет популярных ИИ-ускорителей, тогда как на фоне бума ИИ в поставках для ЦОД преобладают именно такие чипы. В свете этого тренда Mercury Research отметила, что и AMD, и Intel показали скромное увеличение поставок серверных CPU во II квартале, что примечательно, поскольку «рынок обычных серверных процессоров значительно замедлился из-за переключения спроса ЦОД на ИИ-ускорители». 
Источник изображения: AMD Mercury Research сообщила, что рост у Intel наблюдался в основном в сегменте сетевых и периферийных процессоров, а не традиционных процессоров для ЦОД, где доходы Intel, по её данным, были стабильными. Что касается процессоров Arm, то по данным Mercury Research, доля рынка ПК с этой архитектурой снизилась до 10 % с 11 % в I квартале, несмотря на широко разрекламированный запуск серии Windows-компьютеров Copilot+ PC на базе чипов Qualcomm в мае этого года. По словам Mercury Research, падение было вызвано значительным снижением спроса на процессоры для Chromebook и снижением поставок Arm-компьютеров Apple Mac. Поставки систем класса Copilot+ PC были слишком малы, чтобы компенсировать это падение.
09.08.2024 [23:30], Сергей Карасёв
Представлена крошечная плата Raspberry Pi Pico 2 за $5 на чипе с ядрами RISC-V и ArmКомпания Raspberry Pi анонсировала микроплату Pico 2, в основу которого положен гибридный чип RP2350: это изделие объединяет ядра с архитектурой Arm и RISC-V. Для новинки заявлена обратная аппаратная и программная совместимость с более ранними представителями серии Pico. Оригинальная плата Raspberry Pi Pico дебютировала в январе 2021 года. Она получила микрочип собственной разработки RP2040, содержащий два ядра Cortex M0+ с базовой тактовой частотой 48 МГц и возможностью повышения до 133 МГц. Чип RP2350, в свою очередь, имеет более сложную конструкцию. 
Источник изображения: Raspberry Pi В состав RP2350 входят по два ядра Arm Cortex-M33 и RISC-V Hazard3 (RV32I с расширениями): в обоих случаях тактовая частота составляет 150 МГц. Однако использовать эти кластеры сообща нельзя — одна из двух конфигураций выбирается при инициализации устройства. Правда, при выборе RISC-V не будут работать часть функций безопасности и FP64-ускорение. Чип существует в модификациях RP2350A (QFN-60; 7 × 7 мм; 30 × GPIO) и RP2350B (QFN-80; 10 × 10 мм; 48 × GPIO). Есть 520 Кбайт памяти SRAM в обоих вариантах исполнения. Плата Raspberry Pi Pico 2 располагает 4 Мбайт флеш-памяти QSPI и портом Micro-USB 1.1. Говорится о поддержке 2 × UART, 2 × SPI, 2 × I2C, 16 × PWM, 4 × ADC. Размеры новинки равны 51 × 21 мм. Напряжение питания — от 1,8 до 5,5 В. Диапазон рабочих температур простирается от -20 до +85 °C. Плата Raspberry Pi Pico 2 предлагается как по отдельности, так и в партиях из 480 штук. Изделие будет производиться как минимум до января 2040 года, то есть жизненный цикл составляет не менее 16 лет. Приобрести новинку можно по цене $5.
08.08.2024 [17:50], Руслан Авдеев
Виртуальный суперкомпьютер Fugaku теперь можно запустить в облаке AWSЯпонская научная группа RIKEN Center for Computational Science представила виртуальную версию принадлежащего ей Arm-суперкомпьютера, которую можно развернуть в облаке AWS. По данным The Register, суперкомпьютер считался самым производительным в мире в 2020 году, пока его не потеснила первая экзафлопсная машина Frontier двумя годами позже. 
Источник изображения: RIKEN Центр намерен упростить желающим использование системы Fugaku, поэтому в RIKEN и решили создать виртуального двойника, способного работать в облаке или даже на суперкомпьютерах, принадлежащих другим компаниям. Представители центра сообщили, что построить машину из 160 тыс. узлов недостаточно, ведь необходимы ещё и программные решения. Другими словами, в облаке полностью воспроизвели программную HPC-экосистему Fugaku, которая включает массу оптимизированных для Arm пакетов и специализированного ПО. Первая версия Virtual Fugaku доступна в виде Singularity-образа. Она предназначена для запуска на Arm-процессорах Amazon Graviton3E, которые оптимизированы для задач HPC/ИИ. Как и процессоры Fujitsu A64FX, используемые в Fugaku, они предлагают инструкции Scalable Vector Extension (SVE). Основная ОС — RHEL 8.10. ПО собрано с использованием GCC 14.1 и библиотеки OpenMPI, которая поддерживает EFA. В Amazon крайне довольны выбором AWS в качестве базовой платформы для Virtual Fugaku. 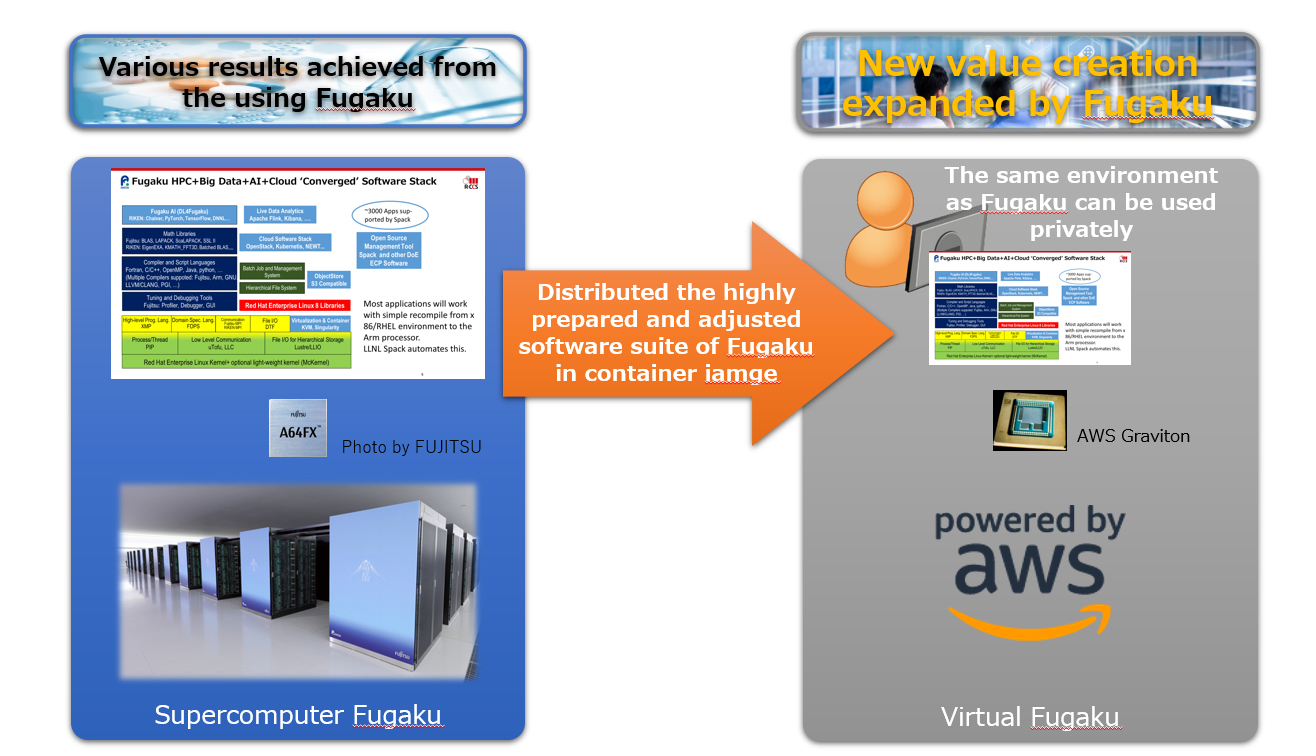
Источник изображения: RIKEN В будущем возможно портирование Virtual Fugaku и на другие архитектуры, но на какие бы платформы его ни перенесли, в RIKEN надеются, что инстансы «продолжат дело» своего родителя. Исследователи заявили, что результаты использования Fugaku, включая разработки, связанные с контролем заболеваний, созданием новых материалов и лекарств, хорошо известны. В ходе эксплуатации специалисты получили богатый опыт обращения с суперкомпьютером и намерены поделиться им с обществом. В RIKEN даже рассматривают Virtual Fugaku как стандартную платформу для использования программных HPC-решений — если суперкомпьютерные центры по всему миру примут этот формат, пользователи оценят богатство библиотеки ПО. Впрочем, некоторые эксперты считают, что такая концепция не вполне жизнеспособна — HPC-задачи часто связаны с использованием оборудования, оптимизированного под конкретные цели, поэтому маловероятно, что одна программная платформа подойдёт всем заинтересованным сторонам.
01.08.2024 [23:55], Алексей Степин
Arm-процессоры AWS Graviton4 успешно конкурируют с актуальными Intel Xeon, а иногда обгоняют даже AMD EPYCВсего за пять лет Amazon успела разработать и внедрить четыре поколения серверных Arm-процессоров Graviton. 4-нм Graviton4 получили 96 ядер и 12 каналов памяти DDR5-5600, а также поддержку PCIe 5.0. Всё это дало AWS основание утверждать, что Graviton4 производительнее предшественника на 30 %, а пропускная способность памяти у него выше на 75 %. Насколько это соответствует истине, выяснил ресурс Phoronix, который заодно сравнил новинки с другими современными процессорами. В тестировании Phoronix приняли участие следующие модели Graviton:

Источник: AWS Платформа Graviton в последней итерации выглядит вполне достойно. Она использует современный набор инструкций Arm, а по количеству ядер и каналов памяти сопоставима с новейшими решениями Intel и AMD. Производительность по мере смены поколений у Graviton растёт практически линейно, за исключением перехода от первого поколения ко второму, что легко объясняется возросшим сразу вчетверо количеством ядер. Что касается Graviton4, то новые процессоры в среднем быстрее Graviton3 примерно в 1,55 раза, а первенца серии они превосходят в 10,4 раза. В некоторых случаях выигрыш выходит далеко за рамки теоретических 1,5x, поскольку у Graviton4 более совершенная архитектура, новее набор инструкций, вдвое больший объем кеша на ядро и существенно более производительная подсистема памяти. Такое поведение, к примеру, характерно для тестов srsRAN, задач криптографии и особенно работы с базами данных. 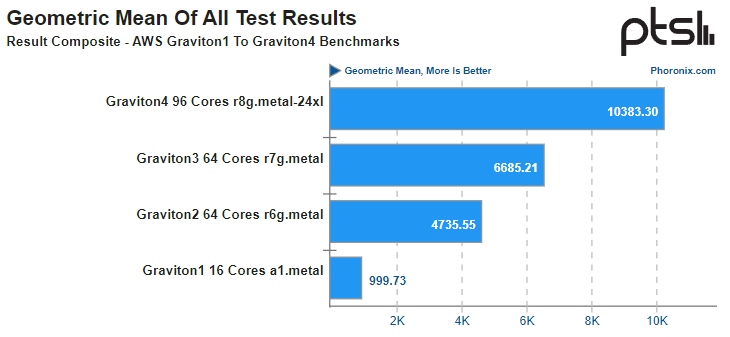
Источник здесь и далее: Phoronix В другом исследовании Phoronix процессорам Graviton4 довелось столкнуться с серьёзными соперниками из мира x86, включая 128-ядерный AMD EPYC 9754 (Bergamo) и 144-ядерные Intel Xeon 67xx (Sierra Forest), а также с ближайшим конкурентом по Arm-платформе, 128-ядерным процессором Ampere Altra Max. К сожалению, метрик энергопотребления в текущей версии инстанса r8g.metal-24xl получить не удалось, но и без этого результаты получены весьма интересные. С первых тестов очевидно, что Altra Max уже не соперник современным решениям, несмотря на сопоставимое количество ядер — сказывается не самая новая архитектура. А вот Graviton4 чувствует себя неплохо и в тестах на компиляцию может опережать даже AMD EPYC 9754. Хороша новинка и в базах данных, она лишь немного уступает процессорам Genoa и зачастую опережает 144-ядерное решение Intel c E-ядрами. И даже в HPC-нагрузках, для которых характерно активное использование FP-вычислений у Graviton4 всё хорошо! Неплохо себя детище AWS чувствует и в сценариях (де-)компрессии данных и кодировании видео. 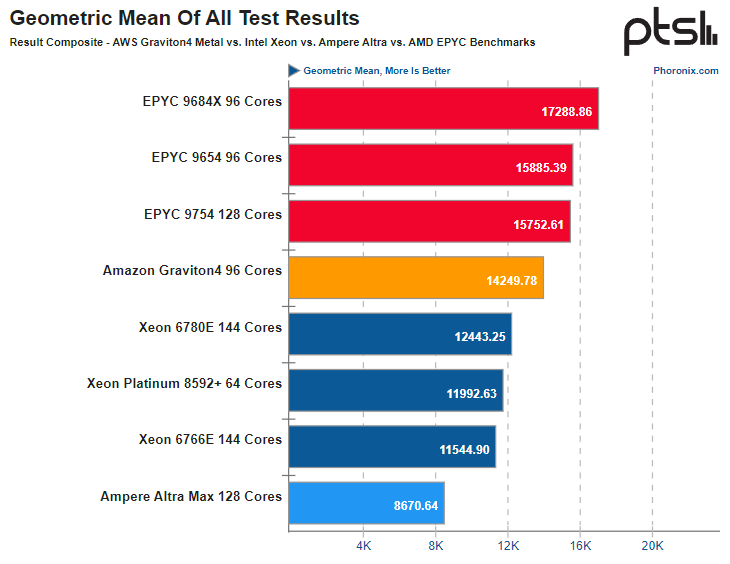 В итоговом зачёте AWS Graviton4 уверенно занимает место в середине таблицы, опережая оба Xeon — и 64-ядерный Platinum 8592+ (Emerald Rapids), и 144-ядерный Xeon 6780E, но до уровня AMD EPYC 9754 всё же несколько недотягивая. Это вполне даёт основание считать, что платформа AWS Graviton достигла зрелости. Она вполне конкурентоспособна даже на фоне x86-монстров. Более того, на сегодня Graviton4 можно считать самым продвинутым серверным процессором с архитектурой AArch64. Впрочем, вскоре предстоят сражения с Granite Rapids, Turin и AmpereOne (а на подходе ещё и Aurora с HBM).
01.08.2024 [00:53], Игорь Осколков
Ampere анонсировала 512-ядерные Arm-процессоры AmpereOne Aurora с HBM-памятью и встроенным ИИ-ускорителемAmpere Computing анонсировала процессоры AmpereOne Aurora, которые получат до 512 однопоточных Arm-ядер собственной разработки, набортную HBM-память и фирменные IP-блоки для обучения и инференса ИИ-моделей. Речь, судя по всему, идёт о чиплетной компоновке, поскольку компания говорит не только о фирменном меш-интерконнекте для вычислительных блоков, но и об объединении разных кристаллов в рамках SoC. Предполагается, что Aurora появятся где-то на рубеже 2025–2026 гг. 
Источник изображений: Ampere Computing Что интересно, для Aurora обещана возможность использования воздушного охлаждения. Для гиперскейлеров, на которых Ampere по-прежнему ориентируется, это важный пункт. Впрочем, больше никаких подробностей о новинках компания не сообщила, отметив лишь, что встроенный ускоритель сгодится для RAG и векторных баз данных. Ну и сообщив, что по количеству ядер и производительности её ещё не выпущенный чип обгоняет все остальные чипы: 144-ядерные Intel Xeon 6 (Sierra Forest), которые вскоре станут 288-ядерными (при этом все варианты без Hyper-Threading), и 128-ядерные AMD EPYC Bergamo (256 потоков), которым на смену придут 192-ядерные EPYC Turin Dense (384 потока). 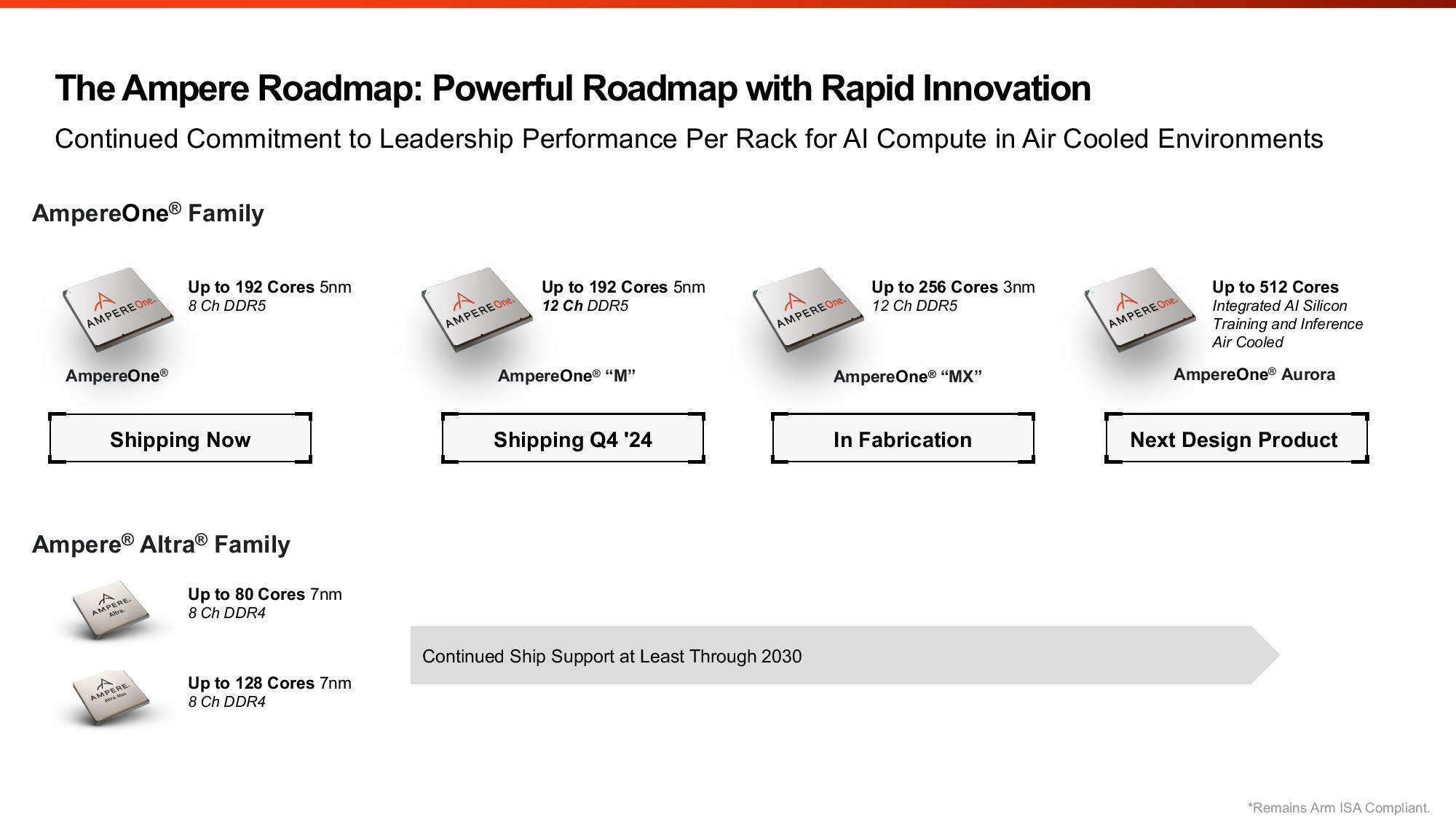 До Aurora компания выпустит ещё две серии процессоров AmpereOne: M в конце 2024 года и MX в 2025 году. 5-нм AmpereOne M получат до 192 ядер и 12-канальный контроллер памяти DDR5. 3-нм AmpereOne MX получат такой же контроллер и до 256 ядер. Заодно компания опубликовала прайс-лист актуальных CPU. В нём нет изначально заявлявшихся 136- и 172-ядерных моделей. Кроме того, остальные процессоры несколько подорожали в сравнении с прошлым поколением Altra Max, но по цене всё ещё привлекательнее решений AMD и Intel — $5555 за 192 ядра. Следует учесть, что в таблице приведён не привычный показатель TDP, а усреднённое энергопотребление чипа, из-за чего сравнивать процессоры Ampere с другими чипами затруднительно. 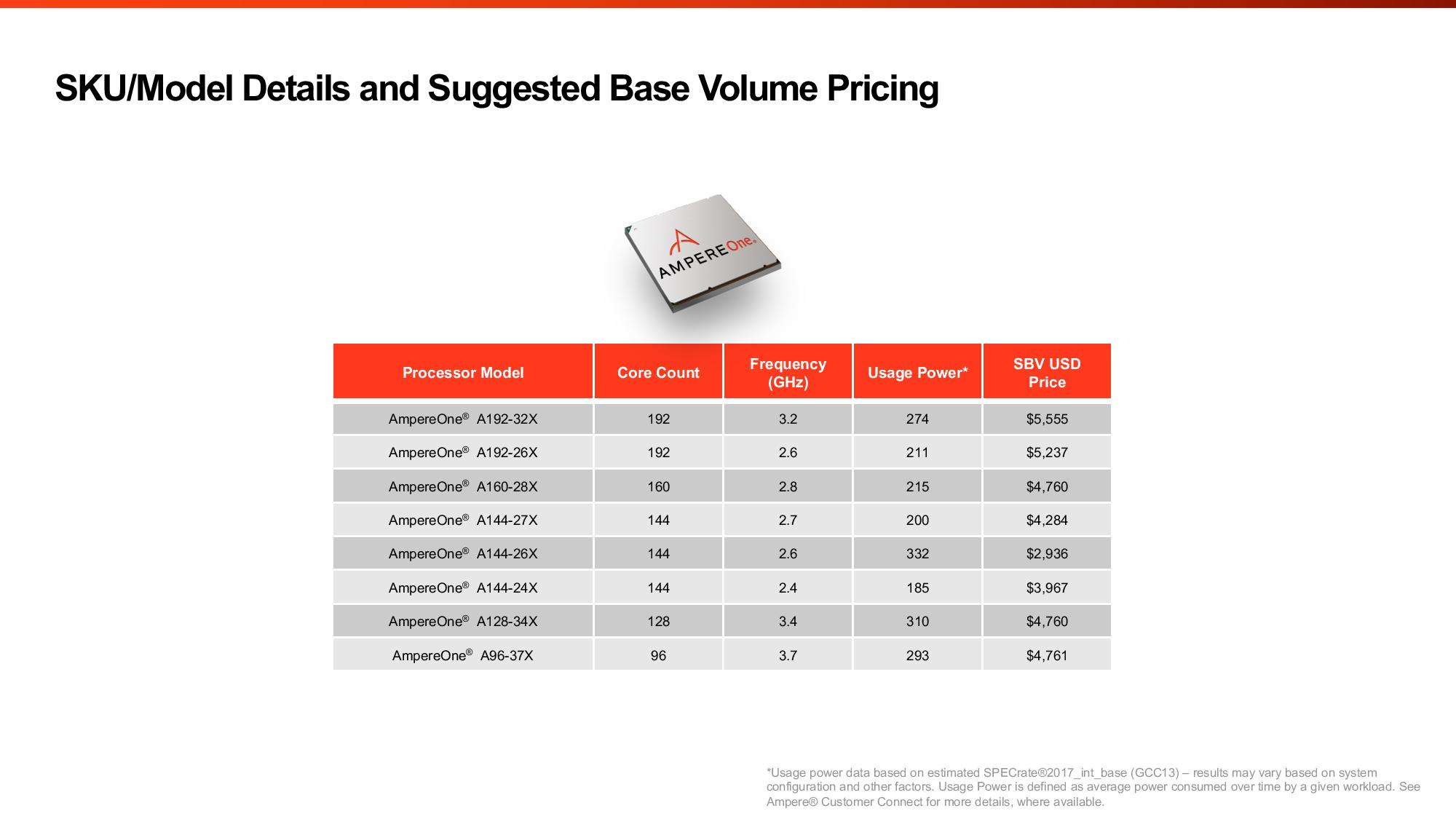 Насколько Aurora станет популярным у гиперскейлеров и других заказчиков, покажет время. У Ampere есть якорный заказчик в лице Oracle, но другие IT-гиганты уже сами разрабатывают собственные Arm-процессоры. AWS в Graviton4 довела количество ядер до 96, Microsoft анонсировала 128-ядерный Cobalt 100, Alibaba массово внедряет 128-ядерные Yitian 710, а Google готовит Axion. Fujitsu к 2027 году подготовит 144-ядерные MONAKA, которые тоже получат поддержку ИИ-нагрузок, но упор в них сделан не на HBM, а на SRAM. Собственно говоря, HBM есть только у HPC-процессоров: Fujitsu A64FX, SiPearl Rhea1 и C-DAC AUM. Даже NVIDIA Grace, которые в основном ассистируют ускорителям, обходятся LPDDR5x.
25.07.2024 [10:12], Владимир Мироненко
AMD показала превосходство чипов EPYC над Arm-процессорами NVIDIA Grace в серии бенчмарков, но не всё так простоAMD провела серию тестов, чтобы доказать преимущество своих нынешних процессоров AMD EPYC над Arm-процессорами NVIDIA Grace Superchip. Как отметила AMD, в связи с растущей востребованностью ЦОД некоторые компании начали предлагать альтернативные варианты процессоров, «часто обещающие преимущества по сравнению с обычными решениями x86». «Обычно их представляют с большой помпой и заявлениями о значительных преимуществах в производительности и энергоэффективности по сравнению с x86. Слишком часто эти утверждения довольно сложно воплотить в реальные сценарии конкурентной рабочей нагрузки — с использованием устаревших, недостаточно оптимизированных альтернатив или плохо документированных предположений», — отметила AMD. С помощью серии стандартных отраслевых тестов AMD, по её словам, продемонстрировала преимущество EPYC над решениями на базе Arm. «Благодаря проверенной архитектуре x86-64, впервые разработанной AMD, вы можете получить всё это без дорогостоящего портирования или изменений в архитектуре», — подчеркнула компания. Иными словами, тесты AMD могут быть просто попыткой развеять опасения, что архитектура x86 «выдыхается» и что Arm берёт верх. 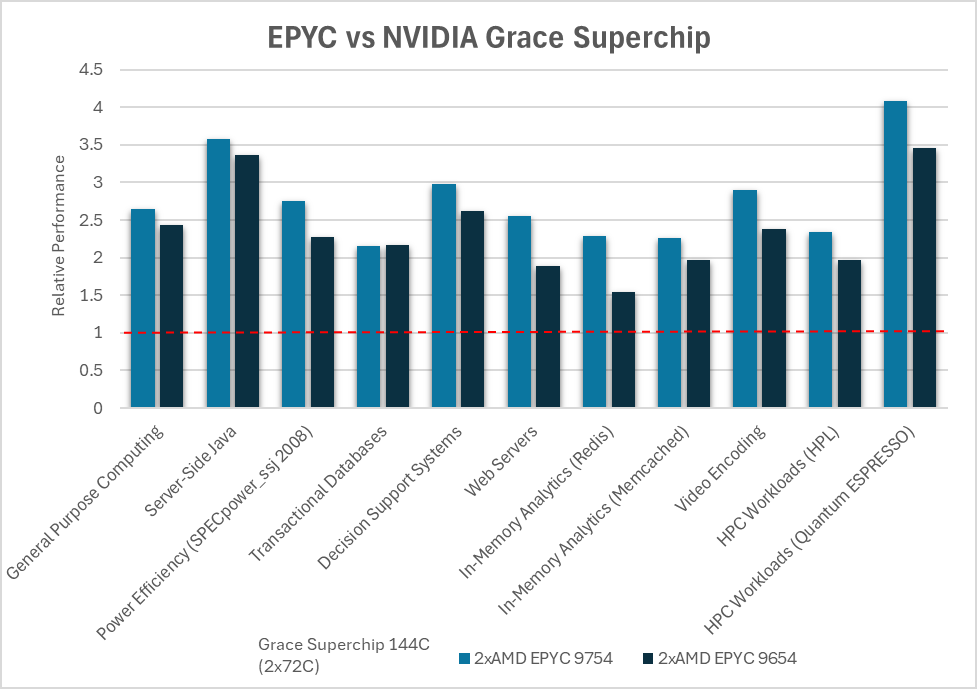
Источник изображений: AMD AMD сравнила производительность AMD EPYC и NVIDIA Grace CPU в десяти ключевых рабочих нагрузках, охватывающих вычисления общего назначения, Java, транзакционные базы данных, системы поддержки принятия решений, веб-серверы, аналитику, кодирование видео и нагрузки HPC. Согласно представленному выше графику, 128-ядерный процессор EPYC 9754 (Bergamo) и 96-ядерный EPYC 9654 (Genoa) более чем вдвое превзошли NVIDIA Grace CPU Superchip по производительности при обработке вышеуказанных нагрузок. Напомним, что Grace CPU Superchip содержит два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2, соединённых шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работает как единый 144-ядерный процессор. В свою очередь, ресурс The Register отметил, что речь идёт о версии с 480 Гбайт памяти LPDDR5x, а не с 960 Гбайт. 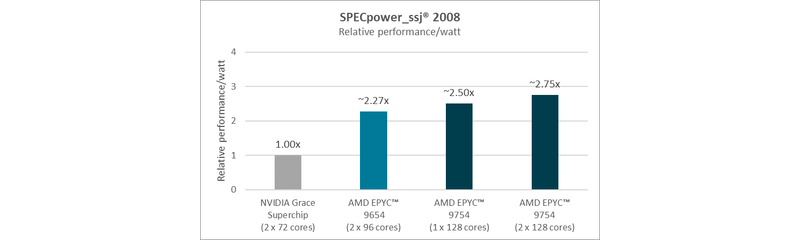 В тесте SPECpower-ssj2008, по данным AMD, одно- и двухсокетные системы на базе AMD EPYC 9754 превосходят систему NVIDIA Grace CPU Superchip по производительности на Вт примерно в 2,50 раза и 2,75 раза соответственно, а двухсокетная система AMD EPYC 9654 — примерно в 2,27 раза. Помимо производительности и эффективности, ещё одним важным фактором для операторов ЦОД является совместимость, сообщила AMD. По оценкам, во всем мире существуют триллионы строк программного кода, большая часть которого написана для архитектуры x86. EPYC основаны на архитектуре x86-64, впервые разработанной AMD, и эта архитектура является наиболее широко используемой и поддерживаемой в индустрии ЦОД, заявила компания, добавив, что изменения в архитектуре сложны, дороги и чреваты риском. AMD также отметила, что экосистема AMD EPYC включает более 250 различных конструкций серверов и поддерживает около 900 уникальных облачных инстансов. Также процессоры AMD EPYC установили более 300 мировых рекордов производительности и эффективности в широком спектре тестов. В то же время лишь немногие Arm-решения доказали свою эффективность. В свою очередь, ресурс The Register отметил, что ситуация не так проста, как AMD пытается всех убедить. В феврале сайт The Next Platform сообщил, что исследователи из университетов Стоуни-Брук и Буффало сравнили данные о производительности суперчипа NVIDIA Grace CPU Superchip и нескольких процессоров x86, предоставленные несколькими НИИ и разработчиком облачных решений. 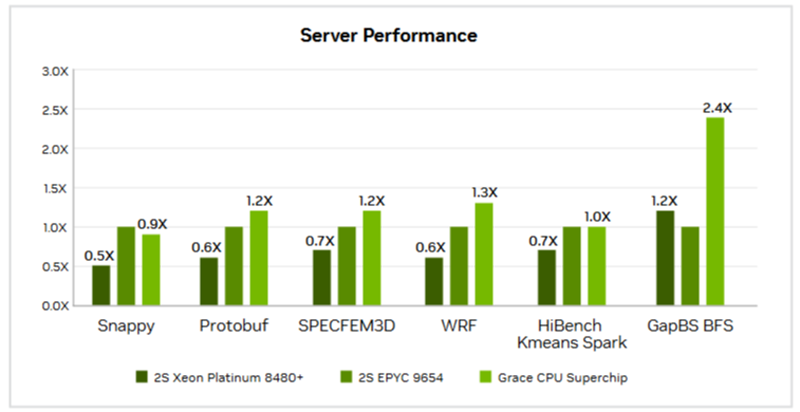
Источник изображений: NVIDIA Большинство этих тестов были ориентированы на HPC, включая Linpack, HPCG, OpenFOAM и Gromacs. И хотя производительность системы Grace сильно различалась в разных тестах, в худшем случае она находилась где-то между Intel Skylake-SP и Ice Lake-SP, превосходя AMD Milan и находясь в пределах досягаемости от показателей Xeon Max. Данные результаты отражают тот факт, что самые мощные процессоры AMD EPYC Genoa и Bergamo могут превзойти первый процессор NVIDIA для ЦОД — при правильно выбранном тесте. 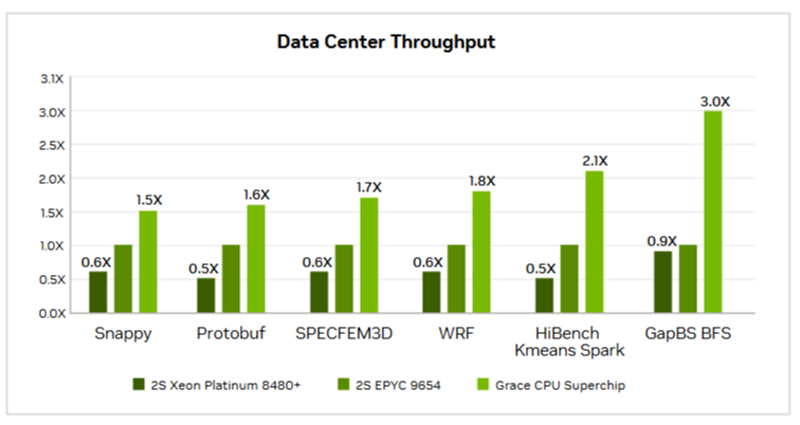 В техническом описании Grace CPU Superchip компания NVIDIA сообщает, что этот чип обеспечивает от 0,9- до 2,4-кратного увеличения производительности по сравнению с двумя 96-ядерными EPYC 9654 и предлагает до трёх раз большую пропускную способность в различных облачных и HPC-сервисах. NVIDIA отмечает, что Superchip предназначен для «обработки массивов для получения интеллектуальных данных с максимальной энергоэффективностью», говоря об ИИ, анализе данных, нагрузках облачных гиперскейлеров и приложениях HPC. |
|

