Материалы по тегу: компьютер
|
28.08.2025 [09:28], Владимир Мироненко
ASUS Cloud увеличит вычислительные мощности Тайваня на 50 %, построив 250-Пфлопс ИИ-суперкомпьютерASUS Cloud в партнёрстве с Taiwan AI Cloud (Taiwan Web Service Corp) и Национальным центром высокопроизводительных вычислений Тайваня (National Center for High-performance Computing, NCHC) в Тайнане (Тайвань) построит суперкомпьютер на ускорителях NVIDIA. Об этом сообщил гендиректор ASUS Cloud и Taiwan AI Cloud Питер Ву (Peter Wu, на фото ниже) в интервью газете South China Morning Post (SCMP). Питер Ву рассказал, что суперкомпьютер с начальной производительностью 80 Пфлопс (точность не уточняется) будет работать на 1700 ускорителях NVIDIA H200. Его запуск запланирован на декабрь, а со временем производительность новой системы вырастет до 250 Пфлопс. Ранее сообщалось, что NVIDIA также поставит два суперускорителя GB200 NVL72 и узлы HGX B300 для данной машины. По словам Ву, после запуска суперкомпьютера общая вычислительную мощность HPC-систем Тайваня вырастет минимум на 50 %. В феврале 2025 года Национальный совет по науке и технологиям Тайваня (NSTC) объявил о планах по увеличению общей вычислительной мощности систем страны примерно до 1200 Пфлопс к 2029 году с имеющихся 160 Пфлопс. 
Источник изображения: ASUS Как отметил DataCenter Dynamics, ASUS ранее сотрудничала с NVIDIA в развёртывании суперкомпьютеров на Тайване, включая 9-Плфопс машину Taiwania 2. В 2022 году ASUS и NVIDIA построили на Тайване суперкомпьютер для медицинских исследований. Taiwan AI Cloud уже реализовала аналогичные нынешнему проекты по созданию ИИ-инфраструктуры в других странах. Среди них — ЦОД в Сингапуре, а также объект во Вьетнаме с 200 ускорителями NVIDIA, который строят для государственного оператора Viettel. Этот проект стартовал в начале 2025 года после того, как правительство США одобрило поставку чипов NVIDIA. Ву отметил рост популярности агентного ИИ. Министерство цифровых технологий острова (MODA) «рекомендовало нам предоставить открытую архитектуру с фреймворком агентного ИИ», чтобы помочь местным компаниям использовать или модернизировать свои существующие приложения, сказал он. Говоря о материковом Китае, Питер Ву заявил, что компании будет «непросто» реализовывать там аналогичные проекты «из-за ситуации с поставками GPU». Китайский подход, заключающийся в «стекировании и кластеризации» малопроизводительных чипов для достижения производительности, аналогичной системам с передовыми ИИ-ускорителями, может быть осуществим с точки зрения инференса. Ву отметил, что запуск DeepSeek «рассуждающей» модели R1 в январе спровоцировал рост спроса на инференс, поскольку эта модель превосходно справляется с такими задачами. «Если рабочая нагрузка аналогична [инференсу], будет легче внедрить альтернативную технологическую схему с существующими [чипами]», — сказал Ву, добавив, что разработчики «могут столкнуться с проблемами в выборе GPU», если проект предполагает обучение или тонкую настройку ИИ-систем. Говоря о будущем, Ву сообщил, что ожидает дальнейшего развития трёх сегментов ИИ в будущем: вычислительной геномики, квантовых вычислений и так называемых цифровых двойников. «Приложение-убийца [для цифровых двойников] может появиться в сфере ухода за пожилыми людьми, помогая им получать лекарства, еду или принимать душ», — прогнозирует Ву.
26.08.2025 [22:13], Руслан Авдеев
IBM и AMD займутся разработкой новых вычислительных архитектур на стыке квантовых и классических подходовAMD и IBM анонсировали разработку нового поколения вычислительных архитектур, в основе которых лежат квантовые компьютеры и HPC-системы. Речь идёт о т.н. «квантово-центричных супервычислениях», сообщает пресс-служба AMD. Команды намерены продемонстрировать первые результаты до конца текущего года. Компании сотрудничают над разработкой масштабируемых, open source платформ, способствующих переосмыслению будущего вычислений с использованием лидерства IBM в сфере квантовых компьютеров и ПО для них, а также ведущей роли AMD в сфере HPC и ИИ-ускорителей. По словам главы IBM Арвинда Кришны (Arvind Krishna), квантовые вычисления со временем позволят «симулировать» реальный мир и представлять информацию принципиально новым способом. Комбинация технологий IBM и AMD позволят построить мощную гибридную модель, оставляющую позади традиционные вычисления. В новой архитектуре квантовые компьютеры будут работать в тандеме с HPC-кластерами и ИИ-инфраструктурой с использованием CPU, ИИ-ускорителей и прочих вычислительных модулей. При таком гибридном подходе различные части задачи решаются оптимальным для них типом оборудования. Например, в будущем квантовые компьютеры смогут моделировать поведение атомов и молекул, а классические ИИ-суперкомпьютеры — анализировать большие массивы данных. Вместе эти технологии смогут решать реальные задачи в беспрецедентном масштабе и с беспрецедентной скоростью, говорят компании. 
Источник изображения: Yue WU/unsplash.com Компании изучают способы интеграции CPU, FPGA и ИИ-ускорителей AMD с квантовыми компьютерами IBM для совместного ускорения выполнения принципиально новых алгоритмов. Ключевым планом сотрудничества является разработка систем коррекции ошибок, что является важнейшим шагом на пути к созданию отказоустойчивых квантовых компьютеров, которые IBM планирует выпустить к 2030 году. Также компании планируют изучить, как именно open source решения вроде Qiskit могли бы выступить катализаторами развития и внедрения новых алгоритмов, использующих квантово-центричные супервычисления. IBM уже начала работать в направлении интеграции квантовых и традиционных систем. Недавно она заключила соглашение с японским НИИ RIKEN о подключении своего модульного квантового компьютера IBM Quantum System Two к одному из самых быстрых суперкомпьютеров мира Fugaku. Суперкомпьютеры Frontier в Ок-Риджской национальной лаборатории (ORNL) и El Capitan в Ливерморской национальной лаборатории (LLNL) полагаются на CPU и ускорители AMD. Другими словами, на чипах AMD работают два из быстрейших суперкомпьютеров из мирового рейтинга TOP500.
22.08.2025 [13:30], Алексей Разин
NVIDIA поможет японцам создать один из мощнейших суперкомпьютеров мира FugakuNEXTВ начале этого десятилетия созданный в Японии суперкомпьютер Fugaku пару лет удерживался на верхней строчке в рейтинге мощнейших систем мира TOP500, он и сейчас занимает в нём седьмое место. В попытке технологического реванша японский исследовательский институт RIKEN доверился компании NVIDIA, которая поможет Fujitsu создать суперкомпьютер Fugaku NEXT. Помимо Arm-процессоров Fujitsu MONAKA-X, в основу нового японского суперкомпьютера лягут и ускорители NVIDIA, хотя изначально планировалось обойтись без них. NVIDIA будет принимать непосредственное участие в интеграции своих компонентов в суперкомпьютерную систему, создаваемую японскими партнёрами. По меньшей мере, скоростные интерфейсы, которыми располагает NVIDIA, пригодятся для обеспечения быстрого канала передачи информации между CPU и ускорителями. Сама NVIDIA обтекаемо говорит, что для этого можно задействовать шину NVLink Fusion. С ускорителями AMD, по-видимому, эти процессоры будут общаться более традиционно, т.е. по шине PCIe. 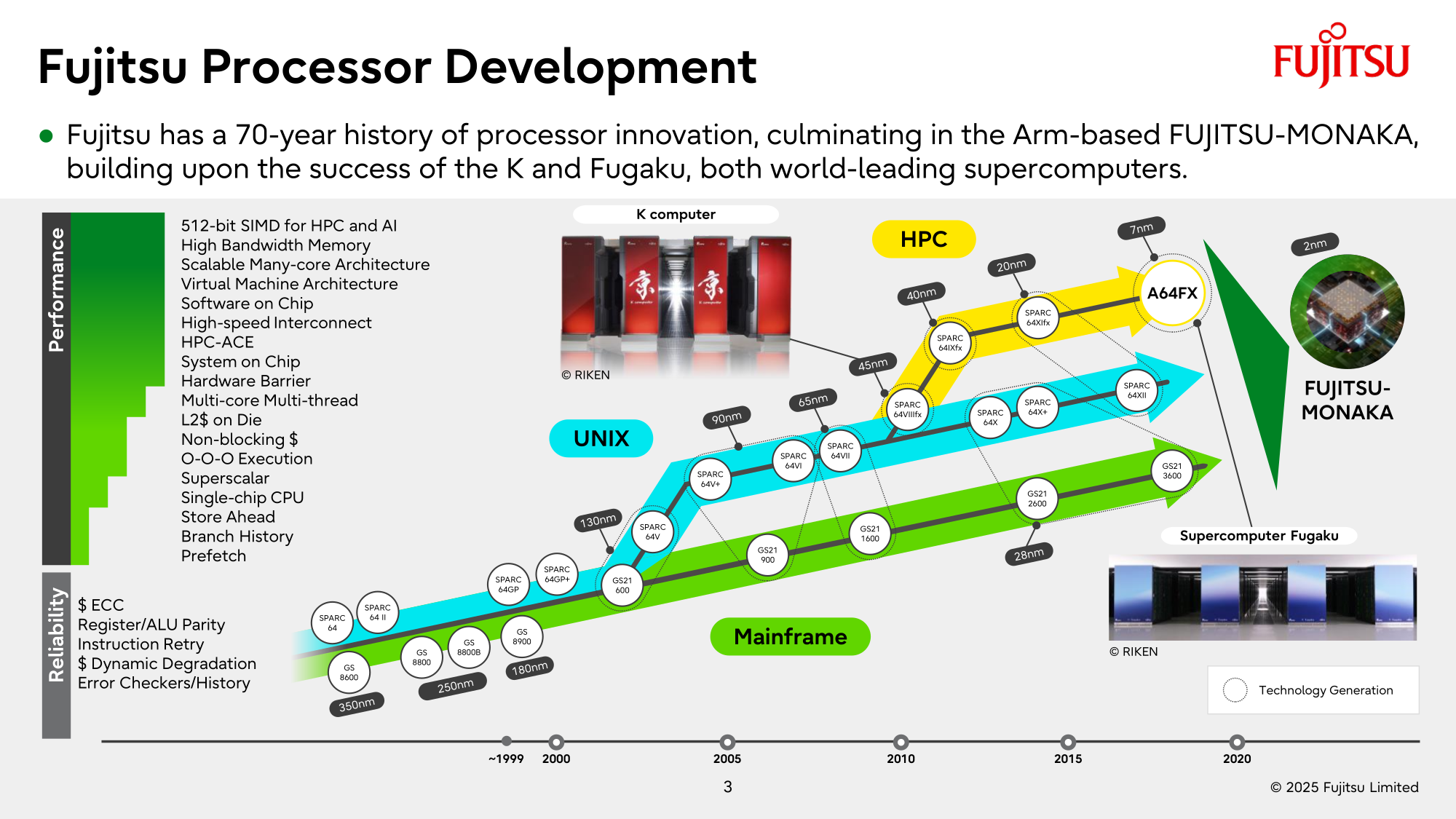
Источник изображений: Fujitsu Кроме того, NVIDIA собирается применить в составе данной системы передовые типы памяти. Применяемые при создании FugakuNEXT решения, по мнению представителей NVIDIA, смогут стать типовыми для всей отрасли в дальнейшем. Подчёркивается, что будущая платформа станет не просто техническим апгрейдом, а инвестицией в будущее страны. 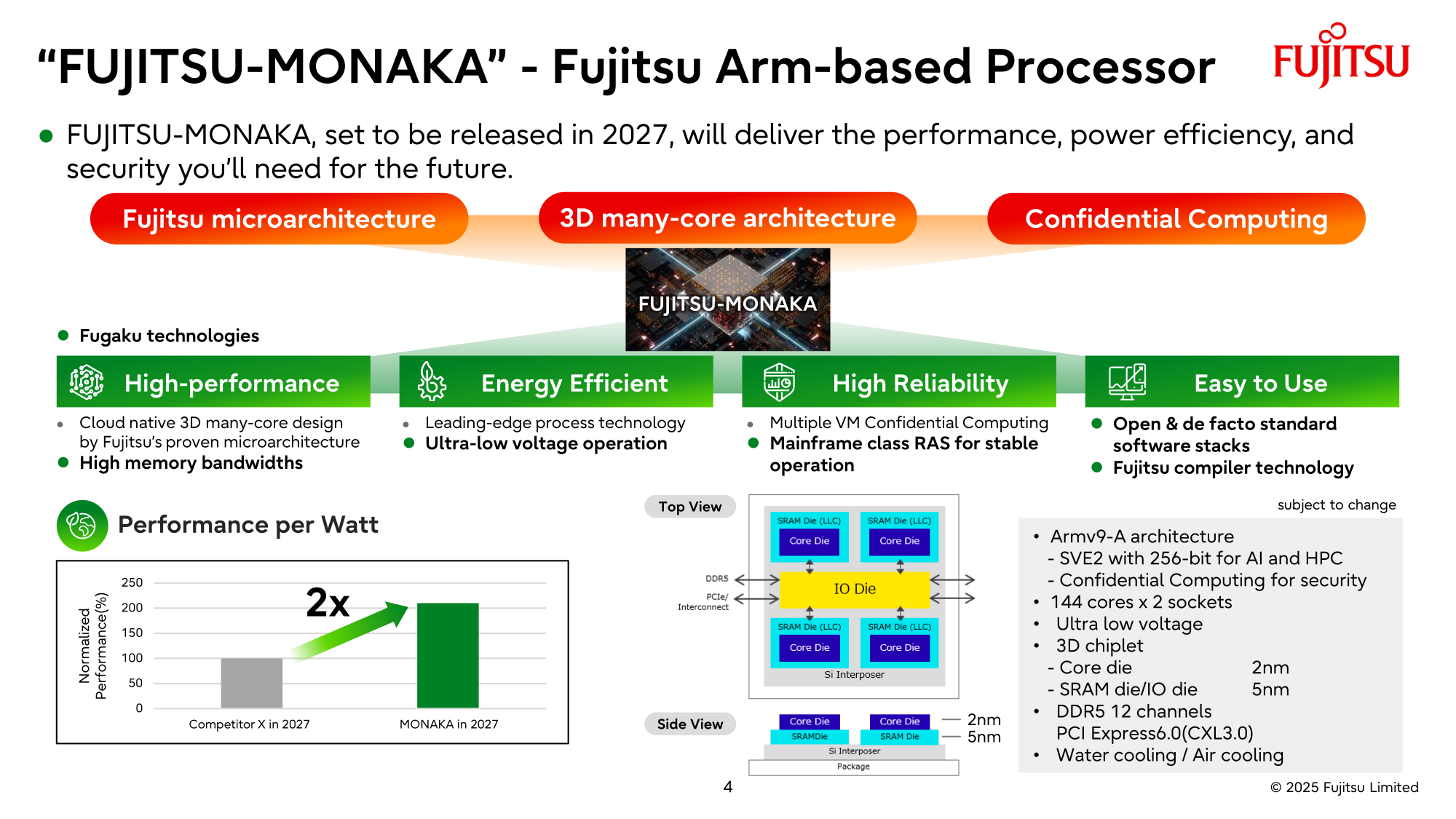 Сама архитектура системы не уточняется, поэтому сложно судить, насколько активно японские разработчики будут использовать ускорители NVIDIA, и к какому поколению они будут относиться. Создатели ставят перед собой амбициозные цели — FugakuNEXT должна стать первой системой «зетта-масштаба». Своего предшественника она должна превзойти более чем в пять раз, обеспечив быстродействие на уровне 600 Эфлопс (FP8). 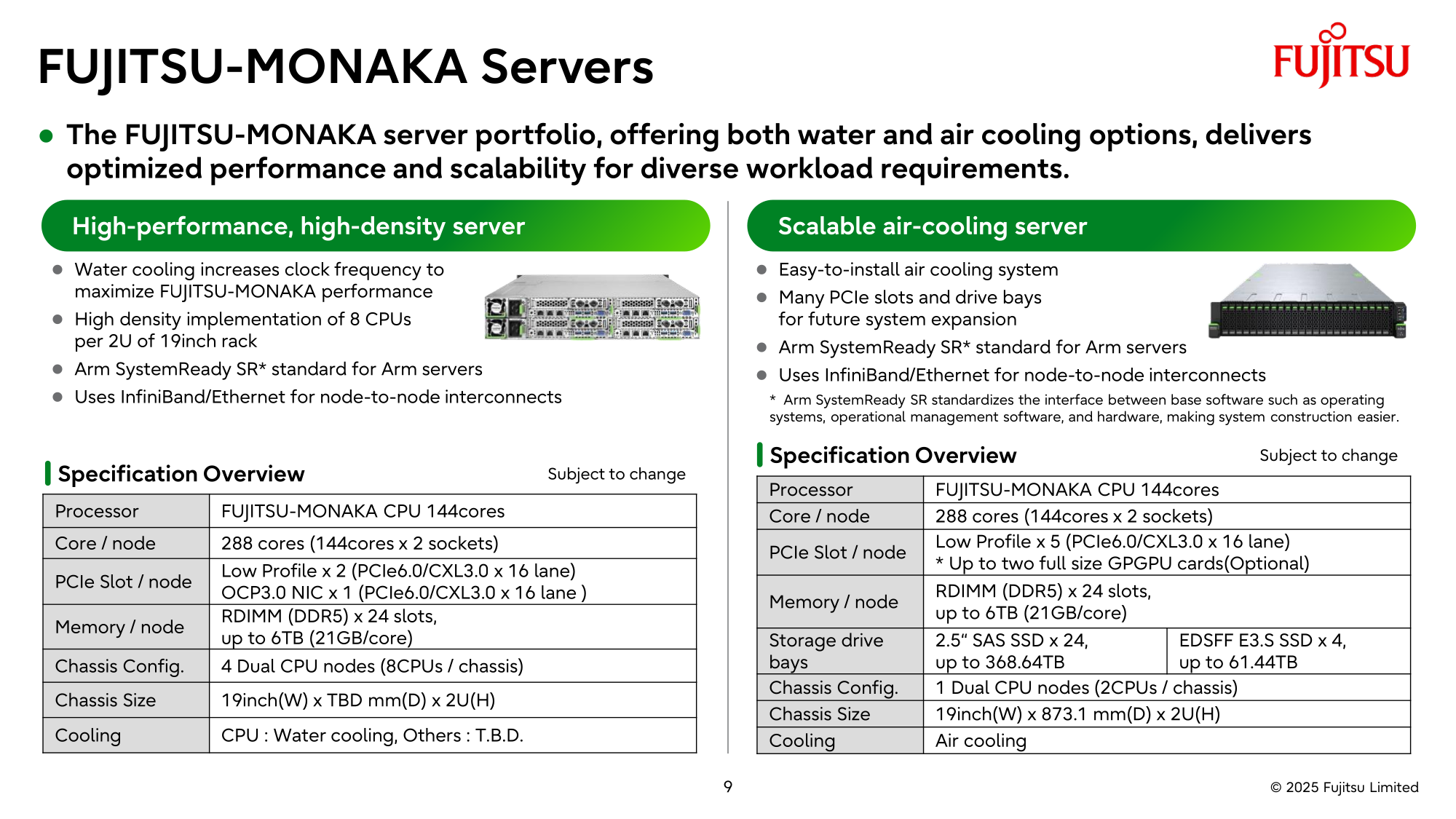 На уровне приложений прирос быстродействия может быть стократным, отмечают создатели. Новый суперкомпьютер сможет применяться для обучения больших языковых моделей. Впрочем, в строй он будет введён лишь к 2030 году, а Fujitsu ещё только предстоит выпустить свои процессоры MONAKA-X для этой системы.
08.08.2025 [11:50], Руслан Авдеев
Tesla отказалась от развития ИИ-суперкомпьютеров DojoTesla распускает команду, стоявшую за суперкомпьютером Dojo, сообщает TechCrunch со ссылкой на Bloomberg. Как сообщают анонимные источники, глава проекта Питер Бэннон (Peter Bannon) покидает компанию, а оставшихся участников команды переведут на работу с другими вычислительными проектами Tesla. О закрытии Dojo стало известно после ухода из Tesla порядка 20 сотрудников, основавших собственный ИИ-стартап DensityAI, который займётся разработкой чипов, аппаратного и программного обеспечения для ИИ ЦОД, связанных с робототехникой, ИИ-агентами и автомобильными приложениями. DensityAI основана бывшим руководителем Dojo Ганешем Венкатарамананом (Ganesh Venkataramanan), причём в не самый удачный для Tesla момент, поскольку глава компании Илон Маск (Elon Musk) ранее настоял на том, чтобы акционеры рассматривали компанию как бизнес, занимающийся ИИ и робототехникой. Решение о закрытии Dojo стало значительным изменением стратегии. Ранее Маск утверждал, что суперкомпьютер станет краеугольным камнем для удовлетворения амбиций компании в сфере ИИ и основная цель — добиться полной автономии машин благодаря способности Dojo обрабатывать огромные массивы видеоданных. В 2023 году Morgan Stanley посчитал, что Dojo может поднять капитализацию Tesla на $500 млрд за счёт новых источников дохода — проектов роботакси и программных сервисов. 
Источник изображения: Tesla В 2024 году Маск сообщил, что команда Tesla, занятая искусственным интеллектом, «удвоит ставку» на Dojo перед презентацией роботакси. Тем не менее разговоры о Dojo уже в августе того же года постепенно сошли на нет, когда Маск начал продвигать ИИ-кластер Cortex (на базе ускорителей NVIDIA) при штаб-квартире Tesla в Остине (Техас). Проект Dojo включал в себя как суперкомпьютер, так и предполагал собственное производство ИИ-ускорителей. Ещё в 2021 году Tesla во время официального анонса Dojo представила чип D1, который должен был бы использоваться совместно с ускорителями NVIDIA для обеспечения работы Dojo. Также сообщалось, что ведутся работы над чипом D2, в котором будут устранены недостатки предшественника. По данным источников Bloomberg, теперь Tesla намерена сделать ставку преимущественно на NVIDIA, а также других сторонних партнёров вроде AMD, а Samsung будет выпускать чипы на заказ. В прошлом месяце с Samsung подписан контракт на выпуск инференс-чипов AI6, которые будут работать как с автопилотами Tesla, так и использоваться в роботах Optimus и дата-центрах. Ранее Маск намекнул, что в случае с Dojo 3 (D3) и инференс-чипом AI6, речь, возможно, будет идти о едином чипе. Недавно совет директоров Tesla предложил Маску пакет акций на $29 млрд, чтобы тот оставался в Tesla и продвигал ИИ-разработки компании, вместо того чтобы отвлекаться на другие бизнесы.
29.07.2025 [14:30], Владимир Мироненко
Стартап SpiNNcloud поставит Лейпцигскому университету «нейроморфный» суперкомпьютер для создания новых лекарств in silicoСтартап SpiNNcloud Systems из Дрездена (Германия) сообщил о заключении сделки на поставку Лейпцигскому университету нейроморфного суперкомпьютера, основанного на принципах функционирования человеческого мозга и предназначенного для разработки новых лекарственных препаратов. Суперкомпьютер будет использоваться учёными для моделирования сворачивания белков в рамках исследований в области персонализированной медицины, объединяющей достижения геномики, ИИ, робототехники и новейших диагностических технологий. Стоимость сделки не разглашается. В суперкомпьютере применена высокопараллельная архитектура с 48 чипами SpiNNaker2 на серверной плате, каждый из которых содержит 152 Arm-ядра со специализированными ускорителями и потребляет 0,8–2,5 Вт. Вся система, оснащённая 4320 чипами с 656 640 ядрами, помещается в одну стойку, но университет решил развернуть её в двух стойках, сообщил Гектор Гонсалес (Hector Gonzalez), соучредитель и генеральный директор SpiNNcloud, отметив, что общий энергетический бюджет системы составляет 25 кВт. 
Источник изображений: SpiNNcloud Новый подход к разработке лекарств использует исключительную параллельность и масштабируемость суперкомпьютера для развёртывания миллионов небольших моделей, которым поручено находить соответствия между молекулами и профилями пациентов. Эта конструкция обеспечивает эффективные, событийно-ориентированные вычисления, позволяя выполнять сложное моделирование и разрабатывать новые персонализированные препараты с более высокой скоростью сходимости и при более низком энергопотреблении по сравнению с традиционными системами на базе GPU. «Точное и детализированное управление процессорами позволяет использовать очень разреженный маршрут, не задействуя все ядра, — поясняет Гонсалес. — Это один из фундаментальных аспектов, который очень сложно реализовать на GPU, поскольку GPU устроен как каскад вычислительных блоков, которые необходимо задействовать максимально полно, чтобы добиться синхронной эффективности». «Архитектура SpiNNcloud делает возможным скрининг миллиардов молекул in silico (виртуальное клиническое исследование)», — сообщил Кристиан Майр (Christian Mayr), соучредитель SpiNNcloud. По его словам, изначально разработанная для моделирования биологических нейронных сетей серверная система SpiNNcloud адаптирована для массивно-параллельного выполнения небольших гетерогенных задач. Прототип нейронной сети позволяет провести скрининг 20 млрд молекул менее чем за час — это на два порядка быстрее, чем на 1000 CPU-ядер.  Гонсалес сообщил ресурсу EE Times, что индивидуальный подход к разработке лекарств, используемый в персонализированной медицине, хорошо вписывается в архитектуру SpiNNcloud. «Это множество небольших моделей, которые взаимодействуют друг с другом через чрезвычайно быструю сеть», — пояснил он. «Наша вычислительная архитектура <…> уникально подходит для развёртывания эффективных алгоритмов, требующих динамической разреженности и экстремального параллелизма», — добавил глава SpiNNcloud. «Экстремальный параллелизм SpiNNcloud делает их идеально подходящими для задач, связанных со сворачиванием белков, например, для поиска низкомолекулярных лекарственных препаратов, — отметил Йенс Майлер (Jens Meiler), профессор Института Александра фон Гумбольдта по Интернету и обществу и директор Института поиска лекарственных препаратов Лейпцигского университета. — «Фолдинг белков можно рассматривать как задачу оптимизации, в которой белок стремится найти своё наименьшее энергетическое состояние. Суперкомпьютеры SpiNNcloud хорошо справляются с такими задачами».  Самая крупная система, развёрнутая SpiNNcloud на данный момент, включает 30 тыс. чипов (более 5 млрд вычислительных элементов) в Дрезденском университете. «Максимально возможная система, которую мы можем спроектировать, – это 16 стоек, — говорит Гонсалес. — При более чем 16 стойках будет сложно поддерживать достаточную связанность между моделями». По его словам, можно было бы развернуть в Лейпциге и более крупный суперкомпьютер с большим числом ядер, но компании пришлось учитывать финансовые ограничения университета. Как сообщает EE Times, SpiNNcloud также тестирует своё оборудование в новых исследовательских направлениях, основанных на классических методах глубокого обучения, в частности, в работе с MoE-моделями. По словам Гонсалеса, архитектура SpiNNcloud хорошо подходит для таких задач. Разработчик выразил надежду, что архитектуры, вдохновлённые принципами работы мозга, такие как SpiNNcloud, позволят создавать новые типы моделей, невозможные для реализации на массовом оборудовании.
23.07.2025 [15:46], Руслан Авдеев
Илон Маск объявил, что ИИ-суперкомпьютер xAI Colossus 2 запустят в ближайшие неделиОснователь ИИ-стартапа xAI Илон Маск (Elon Musk) поделился в социальной сети X информацией о будущем второго кампуса ЦОД в Мемфисе (Теннесси). В числе прочего он объявил намерении запустить в эксплуатацию суперкомпьютер Colossus 2 в ближайшие недели, сообщает Commercial Appeal. По его словам, Colossus 2 получит 550 тыс. ИИ-ускорителей. Компания располагает в городе двумя кампусами — Colossus 1 и Colossus 2. Первый расположен на территории бывшего завода Electrolux и включает 230 тыс. укорителей, в том числе 30 тыс. NVIDIA GB200. Система используется только для обучения, инференс осуществляется в облаках партнёров xAI. Второй кампус, Colossus 2 на площадке Тулейн-роуд (Tulane Road), на первом этапе получит 110 тыс. GB200 и GB300, что потребует 170 МВт энергии. Он должен начать работу в течение нескольких недель. Сроки развёртывания оставшихся 440 тыс. ускорителей не определены, поскольку поставки NVIDIA GB300 задерживаются. В феврале дочерняя структура xAI, компания CTC Property, купила более 75 га вдоль Тулейн-роуд за $70,9 млн. С тех пор, как xAI объявил о планах довести количество ускорителей Colossus до 1 млн, всё чаще возникает вопрос, как именно компания намерена снабжать свой проект энергией. В мае Маск объявил, что Colossus 2 станет первым гигаваттным ИИ-кластером. 15 июля в xAI подтвердили, что компания работает с Memphis Light, Gas and Water (MLGW) и Tennessee Valley Authority (TVA) над обеспечением объекта питанием. MLGW подтвердила, что у неё есть договор на поставку 500 кВт объекту xAI на Тулейн-роуд. 
Источник изображения: X/@elonmusk А 16 июля MXZ Tech LLC, дочерняя компания xAI, приобрела территорию бывшей электростанции Duke Energy (46 га) неподалёку от кампуса Colossus 2. Этот объект сохранил подключение к энергосети TVA. Кроме того, кампус Colossus 2 уже получил 168 модулей Tesla Megapacks. По-видимому, этот кампус тоже не обойдётся без газовых турбин, и использование которых для питания Colossus 1 вызвало недовольство местных экоактививстов NAACP и SELC. Впрочем, пока непонятно, состоится ли серьёзное разбирательство. 
Источник изображения: X/@elonmusk Совсем недавно Илон Маск сообщил о намерении ввести в эксплуатацию эквивалент 50 млн NVIDIA H100 в течение пяти лет — это ответ на недавнее заявление OpenAI о намерении освоить более 1 млн ускорителей к концу текущего года, а в будущем получить в своё распоряжение 100 млн ускорителей. Сейчас xAI намерена найти ещё $12 млрд на закупку ускорителей.
21.07.2025 [16:42], Сергей Карасёв
Запущен самый мощный в Великобритании ИИ-суперкомпьютер — комплекс Isambard-AIВ Великобритании официально введён в эксплуатацию суперкомпьютер Isambard-AI: это самый мощный в стране вычислительный комплекс, ориентированный на задачи ИИ. В июньском рейтинге TOP500 машина занимает 11-е место, а в списке наиболее энергоэффективных систем Green500 — четвёртую позицию. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля (Isambard Kingdom Brunel), внёсшего значимый вклад в Промышленную революцию. Проект реализован при участии компаний NVIDIA и HPE, Бристольского университета (University of Bristol) и других организаций. Создание Isambard-AI обошлось примерно в £225 млн ($302 млн). В основу комплекса положена платформа HPE Cray EX с интерконнектом Slingshot 11. Задействованы 5448 суперчипов NVIDIA GH200 Grace Hopper, которые объединяют 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. Применена СХД Cray ClusterStor E1000 вместимостью 25 Пбайт. Питание полностью обеспечивается от источников энергии с нулевыми выбросами углерода. Избыточное тепло может использоваться для обогрева близлежащих зданий. Развёрнута система прямого жидкостного охлаждения HPE. 
Источник изображений: NVIDIA В тесте Linpack комплекс Isambard-AI демонстрирует FP64-быстродействие на уровне 216,5 Пфлопс, тогда как теоретический пиковый показатель составляет 278,58 Пфлопс. Производительность при решении ИИ-задач достигает 21 Эфлопс (FP8). Как отмечается, Isambard-AI более чем в 10 раз превосходит по скорости второй по быстродействию суперкомпьютер в Великобритании и предоставляет больше вычислительной мощности, чем все остальные НРС-машины страны вместе взятые.  Новый комплекс будет применяться для решения наиболее сложных и ресурсоёмких задач, таких как разработка передовых лекарственных препаратов, моделирование климата, материаловедение, большие языковые модели (LLM) и др. Доступ к ресурсам Isambard-AI регулируется Министерством науки, инноваций и технологий и Департаментом исследований и инноваций Великобритании.
21.07.2025 [09:27], Сергей Карасёв
10 долгих лет: состоялся официальный запуск экзафлопсного суперкомпьютера AuroraВ Аргоннской национальной лаборатории (ANL) Министерства энергетики США (DOE) в Иллинойсе состоялась церемония торжественного разрезания ленты в честь официального запуска суперкомпьютера Aurora экзафлопсного класса. В мероприятии приняли участие руководители и исследователи Intel, HPE и DOE. Церемония была скорее формальностью, поскольку Aurora стала доступна исследователям со всего мира в начале текущего года. Aurora является одним из трёх суперкомпьютеров DOE с производительностью более 1 Эфлопс. Наряду с El Capitan в Ливерморской национальной лаборатории имени Лоуренса (LLNL) и Frontier в Национальной лаборатории Оук-Ридж (ORNL) эти НРС-комплексы занимают первые три места как в списке TOP500 самых быстрых суперкомпьютеров мира, так и в бенчмарке HPL-MxP для оценки производительности ИИ. У суперкомпьютера непростая судьба. Анонс машины состоялся в 2015 году — система с FP64-производительностью на уровне 180 Пфлопс по плану должна была заработать в 2018 году. Однако планы неоднократно корректировались, а проект в конце концов был кардинально пересмотрен. Первые тестовые кластеры системы заработали более двух лет назад, а частично запущенная система попала в TOP500 в конце 2023 года. Целиком она заработала в 2024 году. 
Источник изображения: ANL / Intel В проекте по созданию Aurora принимали участие Intel и HPE. Машина построена на платформе HPE Cray EX — Intel Exascale Compute Blade: задействованы процессоры Intel Xeon CPU Max и ускорители Intel Data Center GPU Max, объединённые интерконнектом HPE Slingshot. В общей сложности применяются 63 744 ускорителей, что делает Aurora одним из крупнейших в мире суперкомпьютеров на базе GPU. 
Источник изображения: ANL / Intel Установлена ОС SUSE Linux Enterprise Server 15 SP4. Производительность в тесте Linpack составляет 1,012 Эфлопс, а теоретический пиковый показатель достигает 1,980 Эфлопс. НРС-комплекс занимает площадь около 930 м2. Развёрнута современная инфраструктура жидкостного охлаждения. Общая протяжённость соединений превышает 480 км, а количество конечных точек сети достигает 85 тыс.  Aurora останется по-своему уникальным суперкомпьютером: CPU с HBM на борту больше не планируются, от Ponte Vecchio компания отказалась в пользу Habana Gaudi и Falcon Shores. Но и последние на рынок не попадут, а будут использоваться для внутренних тестов и обкатки технологий. На смену им должны прийти Jaguar Shores, но точных дат Intel не называет.  Вычислительные мощности Aurora, как отмечается, помогают в решении сложнейших задач в самых разных областях. В биологии и медицине исследователи используют ИИ-возможности суперкомпьютера для прогнозирования эволюции вирусов, улучшения методов лечения рака и картирования нейронных связей в мозге. В аэрокосмической сфере Aurora используется для создания двигательных установок нового поколения и моделирования аэродинамических процессов. Комплекс играет важную роль в развитии технологий термоядерной энергетики, квантовых вычислений и пр.
17.07.2025 [17:50], Владимир Мироненко
Бразилия потратит $4,2 млрд на развитие ИИ и хочет построить один из мощнейших в мире суперкомпьютеровПравительство Бразилии планирует провести модернизацию суперкомпьютера Santos Dumont (SDumont), установленного в Национальной лаборатории научных вычислений (LNCC) в Петрополисе (Petrópolis), в рамках программы Brazilian Artificial Intelligence Plan (BPIA, Бразильский план развития ИИ), пишет ресурс The Next Platform. Страна намерена получить ИИ-суперкомпьютер, который войдёт в пятёрку самых производительных в мире. С его помощью предполагается обучать собственные ИИ-модели. Как сообщает ресурс The Dannemann Siemsen Institute (IDS), проект BPIA, получивший название «ИИ на благо всех», направлен на то, чтобы вывести Бразилию в мировые лидеры в области ИИ-технологий. Он был разработан в сотрудничестве с частным сектором и другими учреждениями для определения целей и руководящих принципов развития и применения ИИ в различных областях, включая здравоохранение, образование, общественную безопасность и энергетику. Инвестиции BPIA будет получать от частного сектора, Национального фонда научно-технологического развития (FNDCT), организации Finep (Financiadora de Estudos e Projetos) Министерства науки, технологий и инноваций (MCTI), и Национального банка экономического и социального развития (BNDES). Всего на реализацию BPIA в 2025–2028 гг. будет направлено R$23 млрд ($4,2 млрд). 
Источник изображения: LNCC Программа BPIA направлена на модернизацию государственных услуг, предоставляемых населению, с помощью ИИ. План включает два основных этапа: так называемые «Меры немедленного воздействия» и «Меры структурирования». Основная доля инвестиций будет направлена на реализацию «Мер немедленного воздействия», включающих 31 инициативу, которые уже реализуются или будут запущены в ближайшее время для решения конкретных проблем в таких приоритетных областях, как здравоохранение, сельское хозяйство, окружающая среда, промышленность, торговля и сфера услуг, образование, социальное развитие и управление государственными услугами. На модернизацию Santos Dumont Бразилии будет выделено порядка R$1,8 млрд ($322 млн), что позволит вчетверо увеличить вычислительные мощности. Основным поставщиком останется Eviden (Atos), которая и развернула Santos Dumont в 2015 году. Его производительность на тот момент составляла 1,1 Пфлопс. В 2019 году эта система была модернизирована, благодаря чему её производительность выросла до 1,5 Пфлопс. Последний апгрейд были завершён в июле этого года, производительность суперкомпьютера выросла до 18,85 Пфлопс (FP64). В настоящее время Santos Dumont состоит из пяти модулей. Первый включает 62 блейд-сервера BullSequana XH3145-H: два 48-ядерных Intel Xeon 9468 (Sapphire Rapids Max) + четыре NVIDIA H100. Второй отсек содержит 20 «лезвий» BullSequana XH3420 с тремя узлами, каждый из которых оснащён парой 96-ядерных процессоров AMD EPYC 9684X (Genoa-X). Третий модуль состоит из 36 узлов BullSequana XH3515-H на базе NVIDIA Quad GH200. Четвёртый включает шесть «лезвий» по три узла с парой AMD Instinct MI300A APU. Наконец, пятый модуль состоит из четырёх узлов с NVIDIA Grace Superchip.
08.07.2025 [17:09], Владимир Мироненко
Российский суперкомпьютер «Говорун» получил два узла «РСК Экзастрим ИИ» с NVIDIA H100 и фирменной СЖО
emerald rapids
h100
h200
hpc
intel
nvidia
sapphire rapids
xeon
россия
рск
сделано в россии
сервер
суперкомпьютер
ГК РСК продемонстрировала 2U-узел (912 × 508 × 88 мм) собственной разработки «РСК Экзастрим ИИ» на базе восьми ускорителей NVIDIA H100 с прямым жидкостным охлаждением. Два таких узла были установлены в суперкомпьютере «Говорун» в Дубне. «РСК Экзастрим ИИ» включает:
«РСК Экзастрим ИИ» имеет локальную подсистему хранения «тёплых данных», сетевую подсистему с доступом на основе технологии GPUDirect. Также есть возможность расширения ресурсов путём подключения дополнительных пар ускорителей или системы внешнего хранения данных на базе пула JBOF, подключаемой напрямую. Производительность «РСК Экзастрим ИИ» составляет до 208 Тфлопс (FP64). При установке 21 сервера в шкаф «РСК Экзастрим» пиковая производительность достигает 4,26 Пфлопс (FP64). Сервер отличается высокой энергоэффективностью, сверхвысокой плотностью монтажа и надёжной работой. Он может использоваться для решения ресурсоёмких задач в области машинного обучения и ИИ, создания мощных вычислительных ресурсов облачных провайдеров и в частных облаках и т.д. 
Источник изображений: РСК Два узла «РСК Экзастрим ИИ» были установлены в суперкомпьютере «Говорун» в Лаборатории информационных технологий им М.Г. Мещерякова Объединенного института ядерных исследований (ЛИТ ОИЯИ) в Дубне в рамках нового этапа модернизации, проведенной силами специалистов ГК РСК и лаборатории.  Как сообщается, новые серверы «РСК Экзастрим ИИ» уникальны и были сконструированы и изготовлены для СК «Говорун» с учётом его архитектурных особенностей. При этом пиковая FP64-производительность GPU-компоненты суперкомпьютера «Говорун» выросла на 36 % и достигла 1,4 Пфлопс, пиковая суммарная FP64-производительность суперкомпьютера теперь составляет 2,2 Пфлопс. Характеристики серверов «РСК Экзастрим ИИ», установленных в ОИЯИ:
 В конце 2024 года было проведено расширение СХД суперкомпьютера «Говорун», после чего её ёмкость увеличилась до 10 Пбайт. В СХД вычислительного комплекса ОИЯИ были добавлены два узла хранения данных RSC Tornado AFS ёмкостью 1 Пбайт каждый. Обновленная модификация СХД RSC Tornado AFS включает серверную плату на базе процессоров Intel Xeon Sapphire Rapids, а также коммутатор с интерфейсом PCIe 4.0, что позволило установить по два адаптера интерконнекта с пропускной способностью 200 Гбит/с каждый.  СХД RSC Tornado AFS поддерживает технологию GPUDirect Storage (GDS), которая обеспечивает прямую передачу данных между локальным или удалённым хранилищем и памятью ускорителя. Две СХД, установленные ранее специалистами РСК в суперкомпьютере «Говорун» входят в мировой рейтинг IO500 самых высокопроизводительных системам хранения данных. В суперкомпьютере «Говорун» используются интегрированный программный комплекс «РСК БазИС 4» и модуль «РСК БазИС СХД» (включены в Реестр российского ПО). Микроагентная архитектура «РСК БазИС 4» обеспечивает функционирование объектов системы, позволяя также взаимодействовать с ними. «РСК БазИС» в сочетании с аппаратными платформами РСК позволяет создавать гиперконвергентные решения для HPC и эффективной обработки больших объёмов данных. |
|

