Лента новостей
|
30.08.2024 [14:30], Сергей Карасёв
«ИнфоТеКС» разработала межсетевой экран ViPNet xFirewall для каналов 200–400 Гбит/сКомпания «ИнфоТеКС» объявила о завершении испытаний высокопроизводительного межсетевого экрана следующего поколения (NGFW) ViPNet xFirewall, предназначенного для использования в дата-центрах. Решение предназначено для обработки больших объёмов трафика. Представленное устройство может обеспечивать защиту каналов связи с пропускной способностью до 200 Гбит/с. Кроме того, создан и протестирован кластер из двух программно-аппаратных комплексов ViPNet xFirewall и брокеров сетевых пакетов. Нагрузочные и функциональные тесты показали корректность и высокую стабильность работы решения при максимально допустимой нагрузке на каналах связи с пропускной способностью до 400 Гбит/с. Отмечается, что тестирование осуществлялось по методике, разработанной в соответствии с государственными нормами и учитывающей международные практики. «ИнфоТеКС» уже работает над продуктом, обеспечивающим производительность до 1 Тбит/с. 
Источник изображения: «ИнфоТеКС» В ассортименте компании представлены устройства серии ViPNet xFirewall 5 (на изображении) — NGFW, сочетающие функции обычного межсетевого экрана (анализ состояния сессии, проксирование, трансляция адресов) с расширенными возможностями обработки и фильтрации трафика (глубокая инспекция протоколов, выявление и предотвращение компьютерных атак, инспекция SSL/TLS-трафика, взаимодействие с антивирусными решениями, DLP и песочницами). Брандмауэры ViPNet xFirewall 5 устанавливаются на границе сети. Они обеспечивают комплексное решение задач информационной безопасности. Это, в частности, создание гранулированной политики безопасности на основе учётных записей пользователей и списка приложений, обнаружение и нейтрализация сетевых вторжений. Механизм DPI использует различные техники идентификации трафика приложений: на основе портов и протоколов, сигнатурный и эвристический методы. Это даёт возможность выявлять даже те приложения, трафик которых шифруется или маскируется. В семейство ViPNet xFirewall 5 входят модификации с разным уровнем производительности. Наиболее мощная на текущий момент версия, представленная на сайте — это 1U-модель xF5000 Q2, которая поддерживает до 9,9 млн одновременно обслуживаемых соединений и до 85 тыс. соединений в секунду. Пропускная способность NGFW достигает 1531 Мбит/с (EMIX, тип фильтрации не уточняется), инспекции SSL — 8400 Мбит/с. Есть четыре порта RJ45 1GbE и восемь портов SFP+10GbE.
30.08.2024 [13:39], Руслан Авдеев
Nokia опровергла слухи о продаже Samsung подразделения, занимающегося оборудованием для мобильной связиАктивы Nokia, связанные с оборудованием для мобильных сетей, вызывают интерес у многих компаний, одной из которых является Samsung Electronics. По данным Bloomberg, не исключается, что ей продадут соответствующее подразделение — в самой Nokia якобы разочарованы перспективами мобильного бизнеса, не приносящего желанных результатов. Samsung от комментариев отказалась, а Nokia официально опровергла все слухи. Как сообщают источники издания, компания якобы обсуждает варианты развития бизнеса, связанного с мобильными сетями, включая его полную или частичную продажу, выделение подразделения в отдельную бизнес-структуру или создание совместного предприятия с конкурентами. Целиком подразделение оценивается в $10 млрд и к покупке некоторых активов уже проявила интерес Samsung, которая не против расширить свои возможности по созданию оборудования для мобильных сетей, пишет Bloomberg. Рыночная капитализация компании достигла в последние дни €22,3 млрд ($24,7 млрд), с начала года она выросла на 30 %. Хотя с развёртыванием 5G-сетей по всему миру компания получила мощный импульс, в последнее время спрос со стороны телеком-операторов начал снижаться, поэтому компания ищет новые направления бизнеса, не так сильно зависящие от потребностей мобильных компаний, и избавляется от непрофильных активов вроде Alcatel Submarine Networks (ASN). Когда-то Nokia была одним из лидеров на рынке мобильных телефонов, но была вынуждена продать свой бизнес, уступив первенство Apple и Samsung. С тех пор компания занимается в первую очередь оборудованием для сетей связи.  В самой Samsung отказываются комментировать тему, а в Nokia выступили с развёрнутым опровержением возможной сделки. В компании опубликовали обращение, свидетельствующее о том, что она стремится к успеху направления мобильных сетей, которое для компании остаётся стратегическим и показывает хорошие результаты. В компании добавляют, что «анонсировать нечего» и никаких внутренних проектов на тему продажи бизнеса просто не существует. Напротив, компания увеличила оборот с уже существующими клиентами и даже привлекла новых. Подразделение Nokia, разрабатывающее и выпускающее оборудование для мобильных сетей, поставляет клиентам со всего мира базовые станции, серверы и разнообразные решения для систем радиосвязи. На него приходится 44 % выручки компании за прошлый год — фактически это крупнейший сегмент Nokia. Тем не менее, как утверждает издание, в последнее время бизнес страдает, поскольку мобильные операторы, особенно в Европе, откладывают дорогостоящие апгрейды своих мобильных сетей. Власти западных стран чрезвычайно обеспокоены доминированием Huawei в сфере телекоммуникационного оборудования и отсутствием у китайского гиганта сильных соперников. Вашингтон бьёт тревогу, утверждая, что Пекин может использовать оборудование Huawei для шпионажа, поскольку компания успешно внедряет его по всему миру. Возможное сотрудничество Nokia и Huawei сорвалось из-за трений между США и Китаем. При этом Nokia сама является крупным поставщиком оборудования для мобильной связи в Китае. 
Источник изображения: Nokia Хотя в Nokia и отрицают вероятность сделки, возможное объединение мобильного бизнеса Nokia с соответствующим подразделением одного из конкурентов потенциально позволяет создать сильную структуру, способную лучше конкурировать в сфере новых технологий. Выбор у операторов связи невелик, поскольку предложений на рынке немного. Samsung также занимается выпуском телеком-оборудования для мобильной связи, но масштабы внедрения слишком малы в сравнении с Nokia, Huawei и Ericsson. Чувствительный удар Nokia нанесли в прошлом году, когда американский оператор AT&T выбрал Ericsson для контракта на $14 млрд. При этом в Nokia заявляют, что являются единственной компанией в мире за пределами Китая, способной поставлять все ключевые компоненты мобильной сетевой инфраструктуры, от ПО для ядра сети до всех аппаратных элементов, причём как для мобильной, так и для наземной связи. Компания отмечает рост в подразделении, занимающимся оборудованием для кабельных сетей. В июне компания согласилась приобрести американскую Infinera за $2,3 млрд, сделав ставку на бум ИИ-технологий. Бизнес Infinera чрезвычайно интересен Nokia, поскольку располагает технологиями для обеспечения связи в ЦОД. Ожидается, что этот сектор будет одним из самых быстрорастущих на телеком-рынке. Это крупнейшая сделка Nokia с момента покупки за €10,6 млрд компании Alcatel-Lucent в 2016 году.
30.08.2024 [13:11], Руслан Авдеев
ИИ-ускорители Intel Gaudi 3 дебютируют в облаке IBM CloudКомпании Intel и IBM намерены активно сотрудничать в сфере облачных ИИ-решений. По данным HPC Wire, доступ к ускорителям Intel Gaudi 3 будет предоставляться в облаке IBM Cloud с начала 2025 года. Сотрудничество обеспечит и поддержку Gaudi 3 ИИ-платформой IBM Watsonx. IBM Cloud станет первым поставщиком облачных услуг, принявшим на вооружение Gaudi 3 как для гибридных, так и для локальных сред. Взаимодействие компаний позволит внедрять и масштабировать современные ИИ-решения, а комбинированное использование Gaudi 3 с процессорами Xeon Emerald Rapids откроет перед пользователями дополнительные возможности в облаках IBM. Gaudi 3 будут применяться и в задачах инференса на платформе Watsonx — клиенты смогут оптимизировать исполнение таких нагрузок с учётом соотношения цены и производительности. Для помощи клиентам в различных отраслях, в том числе тех, деятельность которых жёстко регулируется, компании предложат возможности IBM Cloud для гибкого масштабирования нагрузок, а интеграция Gaudi 3 в среду IBM Cloud Virtual Servers for VPC позволит компаниям, использующим аппаратную базу x86, быстрее и безопаснее использовать свои решения, чем до интеграции. 
Источник изображения: Intel Ранее сообщалось, что модель Gaudi 3 готова бросить вызов ускорителям NVIDIA. В своё время Intel выступила с заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при значительно меньшей стоимости. Позже Intel публично раскрыла стоимость новых ускорителей, нарушив негласные правила рынка.
30.08.2024 [12:43], Сергей Карасёв
Fujitsu займётся созданием ИИ-суперкомпьютера Fugaku Next зеттафлопсного уровняМинистерство образования, культуры, спорта, науки и технологий Японии (MEXT) объявило о планах по созданию преемника суперкомпьютера Fugaku, который в своё время возглавлял мировой рейтинг ТОР500. Ожидается, что новая система, рассчитанная на ИИ-задачи, будет демонстрировать FP8-производительность зеттафлопсного уровня (1000 Эфлопс). В нынешнем списке TOP500 Fugaku занимает четвёртое место с FP64-быстродействием приблизительно 442 Пфлопс. Реализацией проекта Fugaku Next займутся японский Институт физико-химических исследований (RIKEN) и корпорация Fujitsu. Создание системы начнётся в 2025 году, а завершить её разработку планируется к 2030-му. На строительство комплекса MEXT выделит ¥4,2 млрд ($29,06 млн) в первый год, тогда как общий объём государственного финансирования, как ожидается, превысит ¥110 млрд ($761 млн). MEXT не прописывает какой-либо конкретной архитектуры для суперкомпьютера Fugaku Next, но в документации ведомства говорится, что комплекс может использовать CPU со специализированными ускорителями или комбинацию CPU и GPU. Кроме того, требуется наличие передовой подсистемы хранения, способной обрабатывать как традиционные рабочие нагрузки ввода-вывода, так и ресурсоёмкие нагрузки ИИ. 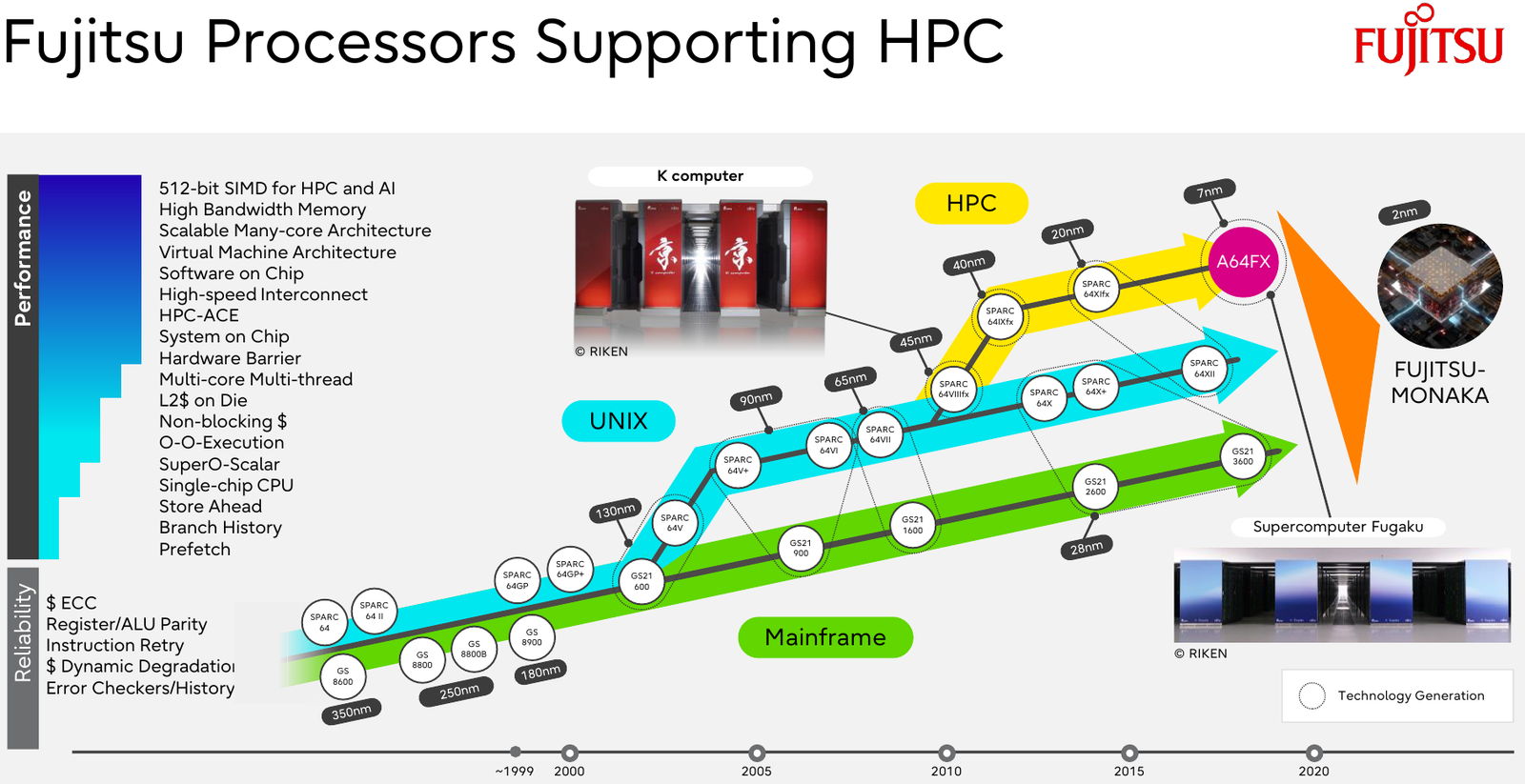
Источник изображения: Fujitsu Предполагается, что каждый узел Fugaku Next обеспечит пиковую производительность в «несколько сотен Тфлопс» для вычислений с двойной точностью (FP64), около 50 Пфлопс для вычислений FP16 и примерно 100 Пфлопс для вычислений FP8. Для сравнения, узлы системы Fugaku демонстрирует быстродействие FP64 на уровне 3,4 Тфлопс и показатель FP16 около 13,5 Тфлопс. Для Fugaku Next предусмотрено применение памяти HBM с пропускной способностью в несколько сотен Тбайт/с против 1,0 Тбайт/с у Fugaku. По всей видимости, в состав Fugaku Next войдут серверные процессоры Fujitsu следующего поколения, которые появятся после изделий MONAKA. Последние получат чиплетную компоновку с кристаллами SRAM и IO-блоками ввода-вывода, обеспечивающими поддержку DDR5, PCIe 6.0 и CXL 3.0. Говорится об использовании 2-нм техпроцесса.
29.08.2024 [22:04], Владимир Мироненко
Анонсирована российская облачная платформа Astra Cloud для предприятий и госкомпаний«Группа Астра» представила облачную платформу Astra Cloud, предназначенную для корпоративного сегмента, в частности, для госкомпаний, которым важны масштабируемость, производительность и безопасность софта. Сервис основан на собственных продуктах «Группы Астра», которые теперь доступны в двух форматах: on-premise и собственного облака на базе ОС Astra Linux. Astra Cloud позволит завершить процесс импортозамещения, поскольку её продукты можно использовать вместо ПО ушедших зарубежных вендоров. На данном этапе клиенты получают СУБД и одноименную платформу баз данных Tantor, ОС Astra Linux в серверном исполнении, платформу для разработки ПО GitFlic, инструмент резервного копирования RuBackup, корпоративный почтовый сервер RuPost, службу каталогов ALD Pro и решение для создания инфраструктуры виртуальных рабочих мест Termidesk. В дальнейшем на платформе Astra Cloud появится весь портфель решений «Группы Астра». 
Источник изображения: «Группа Астра» Платформа Astra Cloud отличается гибкой архитектурой, поддержкой многоуровневой системы безопасности, возможностью интеграции с существующими решениями через службу каталогов, говорит разработчик. Решение выполнено с соблюдением актуальных норм и стандартов в области защиты данных, что крайне важно для госучреждений и крупных корпораций. Все размещённые на платформе продукты включены в реестр Минцифры. С помощью Astra Cloud можно провести цифровую трансформацию без дополнительных затрат на оборудование и обучение персонала, реализовывать ресурсоёмкие проекты, а также минимизировать риск потери данных, если пользоваться Astra Cloud как резервной площадкой по схеме «3-2-1»: две копии данных хранятся локально, одна — в облачной среде. 
Источник изображения: «Группа Астра» Облако Astra Cloud размещено в московских ЦОД DataPro и AtomData уровня TIER III/IV и обеспечено встроенной защитой от DDoS-атак (L7). Управление заказами на платформе осуществляется в личном кабинете, интегрируемом со службой каталогов клиента, что упрощает работу ИТ-специалистов. Сервисы Astra Cloud можно приобрести только у партнёров «Группы Астра». Также пользователям Astra Cloud предоставляются услуги сопровождения напрямую от экспертов разработчика с возможностью решать вопросы, связанные с ПО и облачной инфраструктурой.
29.08.2024 [18:12], Владимир Мироненко
Квартальные результаты NVIDIA и прогноз превысили ожидания Уолл-стрит, но акции упали на 7 %NVIDIA объявила финансовые результаты за II квартал 2025 финансового года, завершившийся 28 июля 2024 года. Рост выручки компании уже четвёртый квартал подряд превышает ожидания аналитиков. В ходе отчёта компания поделилась прогнозом на следующие три месяца, тоже превысившим ожидания Уолл-стрит. Тем не менее в ходе расширенных торгов акции компании упали на 7 %. Выручка NVIDIA составила $30,04 млрд, что выше показателя предыдущего квартала на 15 % и на 122 % год к году. Это также значительно выше консенсус-прогноза аналитиков на уровне $20,75 млрд. NVIDIA повысила ожидания по выручке за III квартал до $32,5 млрд (рост год к году на 80 %), что немного выше консенсусного прогноза в $31,77 млрд. Тем не менее, как сообщила ещё до публикации отчёта ресурсу CNBC Стейси Расгон (Stacy Rasgon), аналитик Bernstein, ожидания инвесторов были ближе к $33–$34 млрд. 
Источник изображения: NVIDIA Подразделение по выпуску продуктов для ЦОД принесло компании в отчётном квартале рекордную выручку в размере $26,3 млрд, превысившую результат предыдущего квартала на 16 % и на 154 % показатель годичной давности. При этом подразделение по выпуску вычислительных компонентов увеличило выручку год к году на 162 % до $22,6 млрд, а продажи сетевых решений повысились на 114 % до $3,7 млрд. Также объявлено, что выручка сегмента профессиональной визуализации увеличилась на 20 % до $454 млн, в автомобильном секторе выручка составила $346 млн (рост 37 %). Чистая прибыль (GAAP) NVIDIA выросла год к году на 168 % до $16,6 млрд или $0,67 на акцию. Чистая прибыль (Non-GAAP) увеличилась на 152 % до $16,9 млрд или $0,68 на акцию. Валовая прибыль составила во II квартале 2025 финансового года 75,1 %, что ниже показателя предыдущего квартала в размере 78,4 %. 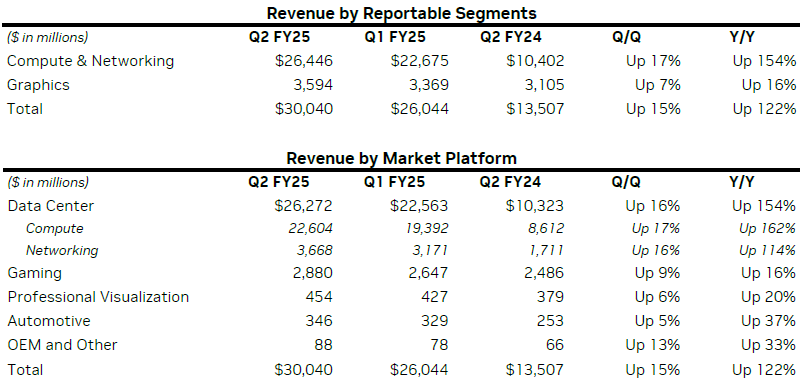
Источник: NVIDIA Как объяснила финансовый директор Колетт Кресс (Colette Kress), снижение связано с изменениями в конструкции ускорителей Blackwell GB200 следующего поколения. Недавно NVIDIA объявила о задержке выхода Blackwell, отметив, что рассчитывает нарастить поставки в IV квартале и получить дополнительно несколько миллиардов долларов дохода. Гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что платформа Blackwell будет способствовать росту так называемых «ИИ-фабрики ИИ» для поддержки чрезвычайно интенсивных рабочих нагрузок. Несмотря на впечатляющий рост бизнеса NVIDIA в сегменте ЦОД, старший аналитик Forrester Research Алвин Нгуен (Alvin Nguyen), выразил обеспокоенность по поводу того, что компания, возможно, «кладёт слишком много яиц в одну корзину». «Я всегда беспокоюсь, когда слишком много доходов сосредоточено на слишком малом количестве рынков, — сказал он, добавив: — Это не их вина. Рынок этого хочет». Бурный рост ЦОД сталкивается с недоступностью электроэнергии и воды, что влечёт за собой сопротивление местных властей. «В некоторых районах невозможно построить ЦОД, потому что он отбирает электроэнергию у 20 тыс. домов», — говорит Нгуен. 
Источник изображения: NVIDIA Тем не менее, гиперскейлеры ищут способы обойти эти барьеры, и именно они могут принести более 45 % доходов ЦОД NVIDIA в течение следующих нескольких лет, говорит Лукас Ке (Lucas Keh), аналитик глобальной исследовательской компании Third Bridge Group Ltd. «Темпы прироста доходов от GPU, как ожидается, сохранятся в течение следующих 12–18 месяцев, — сказал он. — Наши эксперты полагают, что к концу 2025 года 60–70 % обучения (моделей) гипескейлеров будет проводиться на Blackwell». Впрочем, NVIDIA работает над диверсификацией источников доходов. В этом году она запустила десятки NIM-микросервисов, предназначенных для ускорения развёртывания базовых моделей на облачных платформах. NVIDIA также расширила экосистему библиотек CUDA, которые являются строительными блоками для ИИ-приложений. В компании по-прежнему порядка трёх четвертей инженеров занимается именно разработкой ПО. Кроме того, растут доходы компании от сетевых технологий.
29.08.2024 [17:11], Руслан Авдеев
Акции Supermicro обрушились после обвинений Hindenburg ResearchАкции Super Micro Computer Inc. (Supermicro) упали в цене более чем на 20 % после того, как известная на биржевом рынке инвестиционная компания Hindenburg Research опубликовала разгромный доклад об операциях производителя IT-комплектующих и серверов. Silicon Angle сообщает, что в отчётах имеются крайне тревожные для акционеров сведения. Hindenburg Research выявила соглашения между связанными сторонами — обычно таковые заключаются между компанией и её дочерними структурами на нерыночных условиях. Кроме того, Hindenburg Research обвинила компанию в нарушении санкционного режима в отношении России и других «прегрешениях» разной степени тяжести: снова нанятые сотрудники, ранее уволенные за недобросовестное ведение дел, отгрузка товаров низкого качества, выдача чужих инновации за свои, плохие сопровождение и постпродажное обслуживание и т.д. После выдвинутых претензий Supermicro объявила о намерении отложить подачу финансовой отчётности по форме K-10, сообщив, что менеджменту потребуется дополнительное время для оценки показателей. Правда, в компании не сказали, какие данные она намерена перепроверить. Сообщается, что Supermicro не пересмотрит отчётность за IV квартал и 2024 финансовый год в целом, опубликованные ранее в этом месяце. 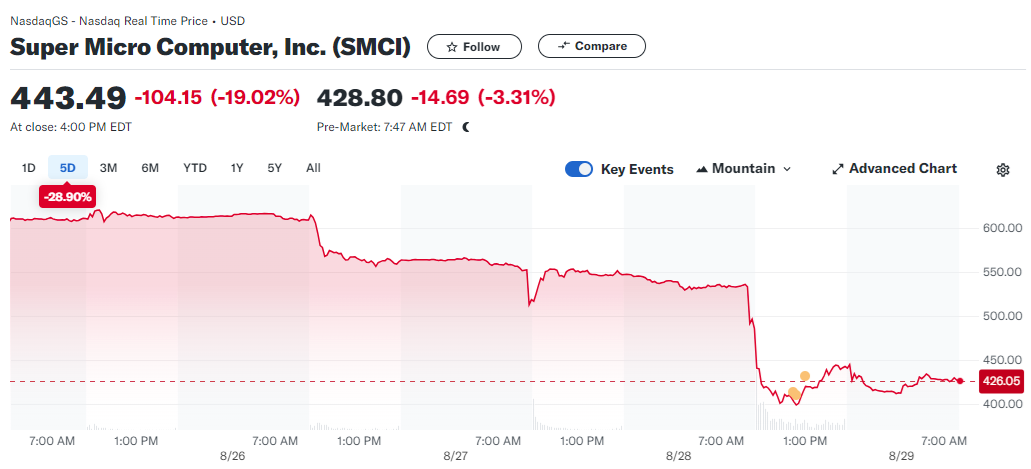
Источник изображения: Yahoo Finance В последнем финансовом квартале фискального 2024 года, закончившегося 30 июня, выручка год к году более чем удвоилась, достигнув $5,31 млрд. Драйвером роста стал спрос на ИИ-оборудование компании, что также помогло буквально утроить цену акций Supermicro в I половине года. На момент написания материала акции оценивались почти в $430 каждая — более чем вдвое ниже исторического рекорда, поставленного в минувшем марте. Впрочем, они всё ещё несопоставимо дороже, чем в начале года, когда их цена опускалась до $285. Публикация доклада на этой неделе — не первый раз, когда финансовые показатели Supermicro ставились под вопрос. В 2020 году компания была вынуждена заплатить $17,5 млн для того, чтобы прекратить расследование, проводившееся Комиссией по ценным бумагам и биржам США (U.S. Securities and Exchange Commission, SEC) в связи с очередными проблемами с бухгалтерской отчётностью. А в 2018 году компанию и вовсе снимали с торгов Nasdaq. Большой спрос на ИИ-оборудование обеспечил компании высокую выручку и, похоже, тенденция сохранится в обозримом будущем. Компания прогнозирует, что выручка в текущем квартале составят $6–$7 млрд, т.е. более чем втрое выше, чем годом ранее. При этом компания перестала быть эксклюзивным поставщиком ИИ-систем CoreWeave и xAI и лишилась Digital Ocean как клиента — все они обратились к Dell. Более того, Supermicro упустила возможность поставки ИИ-кластеров для AWS.
29.08.2024 [16:41], Руслан Авдеев
Илон Маск показал ИИ-суперкластер Tesla Cortex из 50 тыс. ускорителей NVIDIAИлон Маск (Elon Musk) продолжает наращивать вычислительные мощности своих компаний. Как сообщает Tom’s Hardware, он поделился сведениями об ИИ-суперкластере Cortex. По данным Tom's Hardware, недавнее дополнение завода Giga Texas компании Tesla будет состоять из 70 тыс. ИИ-серверов, а также потребует 130 МВт энергии на обеспечение вычислений и охлаждения на момент запуска, к 2026 году мощность вырастет до 500 МВт. На опубликованном в социальной сети X видео Илона Маска показан машинный зал: по 16 IT-стоек в ряд, по два ряда на коридор. Каждая стойка вмещает восемь ИИ-серверов, а в середине каждого ряда видны стойки без таковых. В видео можно разглядеть порядка 16–20 рядов, поэтому довольно грубый подсчёт позволяет предположить наличие около 2 тыс. серверов с ускорителями, т.е. менее 3 % от запланированной ёмкости. В ходе июльского финансового отчёта Tesla Илон Маск рассказал, что Cortex будет крупнейшим обучающим кластером Tesla на сегодняшний день и будет состоять из 50 тыс. ускорителей NVIDIA H100 и 20 тыс. ускорителей Tesla D1 собственной разработки. Это меньше, чем Маск прогнозировал раньше, в июне он сообщал, что Cortex будет включать 50 тыс. D1. Правда, сообщалось, что на момент запуска будут применяться только решения NVIDIA, а разработки Tesla появятся позже. 
Источник изображения: Alexander Shatov/unsplash.com Кластер Cortex предназначен в первую очередь для обучения автопилота Full Self Driving (FSD), сервиса Cybertaxi и роботов Optimus, ограниченное производство которых должно начаться в 2025 году для использования на заводах компании. Также Маск анонсировал планы потратить $500 млн на суперкомпьютер Dojo в Буффало (штат Нью-Йорк), также принадлежащий Tesla. Первым же в «коллекции» Маска заработал Memphis Supercluster, принадлежащий xAI и оснащённый 100 тыс. NVIDIA H100. Со временем эта система получит 300 тыс. ускорителей NVIDIA B200, но задержки с их производством заставили отложить реализацию проекта на несколько месяцев.
29.08.2024 [14:55], Руслан Авдеев
CoreWeave развернёт в Швеции крупнейший в Европе ИИ-кластер NVIDIA BlackwellОблачный провайдер CoreWeave намерен арендовать ЦОД у шведского оператора EcoDataCenter. По данным Datacenter Dynamics, партнёры анонсировали сотрудничество для размещения «одного из крупнейших» в Европе кластеров NVIDIA Blackwell. CoreWeave заявила, что разместит тысячи новых ускорителей NVIDIA, чтобы удовлетворить спрос на крупномасштабную ИИ-инфраструктуру ведущих ИИ-лабораторий и компаний. Эти кластеры должны заработать уже в 2025 году. Дополнительные подробности о том, какие объекты будут использоваться и каков реальный масштаб проекта, неизвестны. По словам представителя CoreWeave, сотрудничество с EcoDataCenter стало поворотной точкой для экспансии в Европе. EcoDataCenter была сформирована в 2015 году шведской энергетической компанией Falu Energi & Vatten и оператором ЦОД EcoDC AB. В 2018 году застройщик Areim приобрёл контрольный пакет акций компании, обошедшийся приблизительно в $22 млн, а в 2019 году объединил её со шведским оператором Fortlax. Сейчас шведская компания управляет пятью дата-центрами на трёх площадках. Ранее в этом году она объявила о планах постройки нового 150-МВт кампуса EcoDataCenter 2. Кампус будут строить поэтапно, первый блок на 20 МВт построят уже в 2026 году. 
Источник изображения: EcoDataCenter Основанная в 2017 году компания CoreWeave изначально специализировалась на крипто- и блокчейн-технологиях и активно инвестировала в облачные проекты, обеспечивая доступ клиентам к ускорителям. За последние два года компания привлекла $12 млрд в виде инвестиций и прямых займов и планирует потратить $3,5 млрд на расширение бизнеса в Европе, в том числе в Норвегии и Великобритании. К концу 2024 года компания рассчитывает управлять 28 объектами по всему миру, в прошлом году речь шла всего о 14 ЦОД.
29.08.2024 [13:43], Сергей Карасёв
«К2 НейроТех» представила российские ПАК для HPC-нагрузок, ИИ и машинного обученияКомпания К2Тех объявила о формировании нового бизнес-подразделения — «К2 НейроТех», специализацией которого являются проектирование, поддержка и масштабирование суперкомпьютерных кластеров. Созданное предприятие предлагает комплексные услуги по развёртыванию суперкомпьютеров «под ключ». Кроме того, «К2 НейроТех» представила два программно-аппаратных комплекса — ПАК-HPC и ПАК-ML. Отмечается, что в штат «К2 НейроТех» вошли высококвалифицированные инженеры, разработчики и системные архитекторы. Специалисты имеют опыт проектирования и построения суперкомпьютерных систем для добывающей промышленности и машиностроительной отрасли, а также для научных и образовательных организаций. В частности, команда участвовала в создании суперкомпьютера «Оракул» на базе Новосибирского государственного университета (НГУ), который победил в конкурсе «Проект года». ПАК-HPC и ПАК-ML построены на основе российских аппаратных и программных решений из реестров Минцифры и Минпромторга. Благодаря этому, как утверждается, снижаются риски, связанные с зависимостью от зарубежных поставок, и появляются возможности для стабильной техподдержки решений и дальнейшего их масштабирования по запросу. ПАК-HPC предназначен для ускорения научных исследований и разработки в таких отраслях, как фармацевтика, добывающая промышленность и машиностроение. В свою очередь, ПАК-ML ориентирован на работу с ресурсоёмкими приложениями ИИ и машинного обучения. 
Источник изображения: К2Тех Конфигурация обоих комплексов включает 18 серверов на стойку. Задействовано высокоскоростное соединение NVLink/Infinity Fabric. Объём оперативной памяти варьируется от 128 до 512 Гбайт на сервер. Для хранения данных применяются SSD вместимостью 1 Тбайт и более. Версия ПАК-HPC обеспечивает пиковую производительность до 7,6 Тфлопс (FP64) на один сервер. Вариант ПАК-ML, который, судя по всему, несёт восемь ускорителей NVIDIA H100, обладает пиковым быстродействием 536 Тфлопс (FP64 Tensor Core) на сервер. Преимуществами ПАК названы: высокая производительность, гибкая конфигурация, масштабируемость, единый графический интерфейс, безопасность, надёжность и импортонезависимость. «Создание бренда "К2 НейроТех" — это логичный ответ на запросы рынка по расширению вычислительных мощностей, необходимых для внедрения ИИ и ускорения проводимых исследований в условиях импортозамещения. Мало у кого сейчас есть практический опыт по созданию систем на базе отечественного оборудования с учётом оптимизации производительности. Именно поэтому мы решили вложить наши компетенции и опыт в создание комплексного предложения по построению суперкомпьютерных кластеров и разработку двух ПАК для задач HPC и ML под единым брендом», — отмечает директор по продвижению решений «К2 НейроТех». |
|

