Материалы по тегу: облако
|
30.04.2026 [12:24], Руслан Авдеев
ИИ-облако Verda развернёт процессоры Arm AGI в своих ЦОДФинская компания Verda намерена предложить клиентам новые решения в сфере ИИ и доступ к новейшему процессору AGI, разработанный компанией Arm. По словам Arm, Verda является самым быстрорастущим поставщиком неооблачных решений в Европе. В настоящее время компания работает над развёртыванием Arm AGI в комбинации с решениями NVIDIA GB300 и, в перспективе — с NVIDIA Vera Rubin. Предполагается, что взаимодействие с NVIDIA обеспечит совместную работу стоек разных типов и поколений в одном дата-центре. Сотрудничество с техногигантом позволяет добиться большей согласованности ПО и серверов и дать ИИ-агентам возможность автономно распределять рабочие нагрузки. Подробности о масштабах развёртывания и сроках доступности процессоров будут объявлены позже. 
Источник изображения: Verda Verda сообщает, что управляет ИИ-облаком, работающим на возобновляемой энергии и созданном для команд, занимающимся машинным обучением (ML). Сочетание Arm AGI с NVIDIA GB300 и готовящимися к выпуску VR200 обеспечит клиентам эффективноcть, необходимую для агентного ИИ. Фактически Arm AGI создан специально для современных систем агентного ИИ и будет выполнять роль «координатора», работая вместе с ускорителями и управляя потоками данных и взаимодействием компонентов в больших ИИ-системах. Чип создан в по 3-нм техпроцессу TSMC и включает 136 ядер. Verda, ранее известная как DataCrunch, основана в 2020 году и сегодня имеет дата-центры в Финляндии, работающие на 100 % возобновляемой энергии. Также она управляет ЦОД в Исландии и намерена построить ЦОД в Латвии.
25.04.2026 [21:46], Владимир Мироненко
Google инвестирует до $40 млрд в партнёра-конкурента Anthropic, выплатив авансом $10 млрдНа этой неделе стало известно о планах Google инвестировать до $40 млрд в ИИ-стартап Anthropic при его предварительной оценке в $350 млрд, что почти соответствует сумме, в которую компания была оценена в ходе раунда финансирования в феврале. $10 млрд стартап получит авансом, ещё $30 млрд будет выделено при достижении определённых целевых показателей, пишет Bloomberg. Несмотря на наличие собственных конкурирующих моделей Gemini AI, Google оказывает финансовую поддержку Anthropic, которая является одновременно и партнёром, и конкурентом. Как и OpenAI, Anthropic привлекает крупные инвестиции от компаний, у которых она покупает чипы и вычислительные мощности ЦОД, что вызывает обоснованные опасения у некоторых аналитиков относительно цикличности этих сделок. Компания извлекает выгоду из популярности своих ИИ-решений, включая модель Claude Code, ускоряющую разработку ПО. Anthropic становится доминирующим игроком на рынке ИИ-инструментов для разработки ПО, в которые сама Google также вложила значительные средства. По словам инсайдеров, внутри Google растёт обеспокоенность тем, что она теряет позиции на этом рынке. Вместе с тем Google продолжает активно инвестировать в разработку собственных моделей Gemini, которые обеспечивают работу функций ИИ в поисковой системе, Gmail и других приложениях. 
Источник изображения: Anthropic В этом месяце Anthropic представила свою новейшую модель Claude Mythos ограниченной группе партнёров. Anthropic заявила, что Mythos — её самая мощная модель на сегодняшний день, имеющая значительные возможности для применения в сфере кибербезопасности. В феврале 2026 года компания привлекла $30 млрд инвестиций при оценке в $380 млрд. Раунд возглавили сингапурский суверенный фонд GIC и Coatue, также в нём участвовали, помимо других инвесторов, Microsoft и NVIDIA. В октябре прошлого года Anthropic заключила сделку с Google, обеспечивающую ей доступ к ИИ-ресурсам мощностью более 1 ГВт с возможностью использования до 1 млн TPU. После этого компании расширили партнёрство при участии Broadcom, договорившись о предоставлении Anthropic 3,5 ГВт ИИ-мощностей на базе Google TPU. Согласно новому инвестиционному соглашению, Google Cloud предоставит Anthropic ещё 5 ГВт мощностей в течение следующих пяти лет с возможностью дальнейшего масштабирования. Пятилетнее соглашение может стоить около $200 млрд, подсчитали The Financial Times. Ранее на этой неделе Anthropic заключила сделку с Amazon, в рамках которой обязуется потратить более $100 млрд в течение следующих десяти лет на чипы Trainium и вычислительные мощности AWS, а Amazon обязалась инвестировать в стартап $5 млрд сразу, а затем ещё $20 млрд в течение определённого времени. Также в этом месяце стартапом было подписано многолетнее соглашение с неооблаком CoreWeave о предоставлении ИИ-мощностей для дальнейшего развития семейства моделей Claude.
25.04.2026 [11:15], Руслан Авдеев
Электрощит с ИИ-сервером: SPAN анонсировала «распределённый ЦОД» XFRAЗанимающаяся выпуском умных распределительных электрощитов компания SPAN представила решение XFRA, позиционирующееся, как «распределённый дата-центр». Предполагается использование свободных мощностей в жилых домах и коммерческой недвижимости для ИИ-вычислений, сообщает Datacenter Dynamics. Каждый из вычислительных узлов оснастят двумя серверами Dell Poweredge XE7745 с СЖО — всего четыре процессора AMD EPYC, 3 Тбайт RAM и 16 ускорителей NVIDIA RTX Pro 6000 Blackwell. Для управления разработана собственная платформа оркестрации XFRA Cloud. SPAN будет использовать функции управления питанием в своих распределительных щитах для отдачи вычислительным узлам свободных энергомощностей, не используемых в данный момент владельцами объектов. SPAN подчёркивает, что XFRA не станет заменой полноценным ЦОД, но дополнит их, ускоряя рост вычислительных мощностей на периферийных участках электросети. Внедрение XFRA силами американского девелопера PulteGroup стартует в 2026 году. По имеющимся данным, уже сформировано портфолио проектов, позволяющее выйти на гигаваттный масштаб в 2027 году. 
Источник изображения: SPAN PulteGroup заявила, что XFRA представляет собой решение, позволяющее снизить затраты на строительство. Строительство домов с щитами SPAN, системой XFRA и резервными аккумуляторами не просто снизит расходы на эксплуатацию жилья, но и позволит использовать энергетическую инфраструктуру объектов в интересах всей энергосистемы. SPAN входит в лоббистскую группу Utilize, созданную в марте 2025 года. Последняя выступает за «более умное, быстрое и доступное» использование имеющейся в США сетевой инфраструктуры. В число участников также входят Google, Tesla и производитель климатического оборудования — компания Carrier. 
Источник изображения: SPAN Бизнес уже активно использует серверы в домах и коммерческих помещениях, но, в первую очередь, в несколько иных целях. Так, British Gas заключила соглашение с Heata, в рамках которого в Великобритании будет тестироваться облачная платформа с серверами в жилых домах. Каждый сервер подключен к системе домашнего отопления, аккумулирующей тепло в ходе работы сервера. Британская коммунальная UK Power Networks (UKPN) в рамках программы SHIELD (Smart Heat and Intelligent Energy in Low-income Districts) начала устанавливать в домах микро-ЦОД на базе Raspberry Pi — для отопления домохозяйств малоимущих и оплаты их коммунальных услуг.
24.04.2026 [18:23], Руслан Авдеев
Microsoft вложит $18 млрд в ЦОД, ИИ и облака в АвстралииMicrosoft объявила о намерении инвестировать в расширение инфраструктуры и работы в сфере ИИ и облачных технологий в Австралии AU$25 млрд ($18 млрд) до конца 2029 года, сообщает Datacenter Dynamics. По словам главы компании Сатьи Наделы (Satya Nadela), выступавшего в Сиднее, это позволит расширить инфраструктуру Azure в стране более чем на 140 %. Новые инвестиции — продолжение политики Microsoft, в конце 2023 года пообещавшей вложить AU$5 млрд ($3,18 млрд). Тогда заявлялось, что это крупнейшая инвестиция компании за всю 40-летнюю историю её присутствия на континенте. С правительством страны подписан меморандум о взаимопонимании, в соответствии с которым Microsoft намерена соответствовать недавно названных официальным «ожиданиям» властей в отношении ЦОД и строителей ИИ-инфраструктуры, предполагающим приоритет национальных интересов Австралии, поддержку «зелёного перехода», ответственное использование воды, создание рабочих мест и др. В рамках «зелёного перехода» Microsoft увеличит мощности возобновляемой энергетики в стране с учётом собственных целей по достижению «углеродного нейтралитета» к 2030 году. Дополнительно компания намерена расширить сотрудничество с госструктурами в области КИИ и обучить к 2028 году 3 млн жителей Австралии навыкам работы с ИИ. Также в июле 2025 года Microsoft подписано пятилетнее соглашение с местным Министерством обороны на сумму AU$495 млн ($324,71 млн). Военные намерены использовать облачные мощности компании. 
Источник изображения: Srikant Sahoo/unsplash.com К концу 2025 года Microsoft владела и управляла тремя дата-центрами на континенте и строила ещё три объекта в окрестностях Сиднея и Мельбурна. У компании имеются облачные регионы в Канберре, Новом Южном Уэльсе и провинции Виктория — необходимые мощности арендуются у сторонних провайдеров. Ранее появилась информация, что Google рассматривает возможность инвестировать в Австралию AU$20 млрд ($14,2 млрд), но компанию беспокоят высокие налоги. AWS строит ЦОД для австралийского правительства — в июле 2024 года было объявлено, что он предназначен для обработки совершенно секретной информации. Правительство намерено инвестировать в новые системы в следующие десять лет AU$2 млрд ($1,3 млрд). Летом 2025 года сообщалось, что в ближайшие четыре года AWS потратит AU$20 млрд (US$13 млрд) на инфраструктуру дата-центров в Австралии. Тогда это была крупнейшая публичная инвестиция в технологическую сферу страны за всю её историю.
24.04.2026 [17:11], Сергей Карасёв
Meta✴ возьмёт на вооружение «десятки миллионов» Arm-ядер AWS Graviton5Компания Meta✴, по сообщению The Register, объявила о расширении сотрудничества с облаком AWS. Речь идёт об использовании Arm-процессоров Graviton5 для поддержания определённых ИИ-нагрузок, в частности, агентных систем. Сама AWS говорит о невероятном спросе на собственные процессоры. Крупным заказчиком является, например, Uber. AWS представила чипы Graviton5 в конце прошлого года. Эти изделия содержат 192 ядра Neoverse V3 (Poseidon), каждое из которых имеет 2 Мбайт кеша L2. Общий объём L3-кеша составляет 192 Мбайт. Присутствуют 12 каналов памяти DDR5-8800. Утверждается, что прирост производительности достигает 25 % по сравнению с процессорами Graviton предыдущего поколения. Meta✴ намерена использовать для своих задач «десятки миллионов» ядер Graviton5. Таким образом, компания станет одним из крупнейших клиентов, применяющих чипы собственной разработки AWS. Руководитель отдела инфраструктуры Meta✴, заявил, что сотрудничество с AWS направлено на диверсификацию вычислительных ресурсов. По его словам, это необходимо в свете реализации масштабных проектов в области ИИ. 
Источник изображения: AWS Ранее Meta✴ объявила о стратегическом партнёрстве с компанией Arm Holdings, которое направлено на «масштабирование эффективности ИИ на каждом уровне вычислений, охватывающем ПО и инфраструктуру ЦОД». В частности, Meta✴ намерена использовать чипы Arm AGI, специально оптимизированные для агентного ИИ. Однако, как уточняет The Register, эти изделия начнут поступать в дата-центры Meta✴ не ранее конца текущего года, поэтому компания пока будет разворачивать соответствующие нагрузки на базе Graviton5 в облаке AWS. Аналитики Counterpoint Research прогнозируют, что к 2029 году на Arm-решения будет приходиться до 90 % рынка серверных ASIC-изделий, ориентированных на ИИ. Между тем сама Meta✴ проектирует фирменные ИИ-ускорители MTIA, которые в зависимости от модификации могут применяться для обучения моделей, инференса и пр.
23.04.2026 [15:19], Руслан Авдеев
Британские антимонопольщики дали ход коллективному «облачному» иску к Microsoft на £2 млрдВ Великобритании продолжается судебное разбирательство по иску от имени 59 тыс. компаний и организаций, использующих ОС Windows Server в публичных облаках, не связанных с Microsoft. Апелляционный трибунал по вопросам конкуренции решил признать иск на сумму £2 млрд обоснованным, сообщает Computer Weekly. Иск связан с практикой Microsoft, обвиняемой в завышении цен для британских предприятий и организаций, использующих Windows Server на альтернативных облачных серверах в обход облака Azure или связанных с Microsoft площадок. CAT отклонил доводы Microsoft, пытавшейся добиться отклонения дела на раннем этапе, поэтому спор, вероятно, перейдёт к полноценному судебному разбирательству. В марте 2025 года Управление по вопросам конкуренции и рынков Великобритании (CMA) объявила о старте расследования в отношении Microsoft, касающегося лицензирования ПО на рынке облачных вычислений. В конце 2025 года представитель истцов заявил, что Microsoft доминирует в некоторых сферах IT-инфраструктуры и злоупотребляет этим для навязывания пользователям бизнес-процессов, которые в ином случае сочли бы неприемлемыми. Компания просто делает это, поскольку может делать, ограничивая выбор людей. Утверждается, что действия Microsoft годами оказывали негативный финансовый эффект как на государственные, так и на частные организации и теперь представители истца ожидают возможности вернуть деньги. 
Источник изображения: Benjamin Brunner/unsplash.com Коллективный иск касается двух аспектов лицензирования компанией. Во-первых, её обвиняют в злоупотреблении ценообразованием в рамках лицензионного соглашения Microsoft Service Provider License Agreement (SPLA). Утверждается, что оптовые цены, которые запрашивает Microsoft, выше, чем цены на такие же лицензии для пользователей облака Azure. Кроме того, если клиент использует Windows Server на собственных мощностях и решает перенести лицензию в облако с помощью программы Azure Hybrid Benefit, дополнительная плата не взимается, но если речь идёт о выборе альтернативного облачного провайдера, платить придётся, что предоставляет Azure неконкурентные преимущества. По словам представителей юридической компании Scott+Scott, ведущей дело против Microsoft, подтверждение судом дальнейшего расследования является «ключевым шагом на пути к получению компенсаций для тысяч предприятий и организаций», в качестве потребителей нуждающихся и заслуживающих доступа к правосудию. В своём решении суд отклонил доводы Microsoft и разрешил передать дело на рассмотрение по существу. Также суд подчеркнул, что иск с очевидным запасом преодолевает порог «наличия реальных перспектив на успех». К концу 2025 года с Microsoft в Великобритании стали требовать уже почти $3 млрд за завышение расценок для клиентов облачных конкурентов. Попутно давление оказывают прямые конкуренты компании в лице AWS и Google Cloud. Аналогичную тактику они избрали и в Евросоюзе. Кроме того, Microsoft Azure грозит получение статуса стратегического рыночного игрока, что позволит CMA применять к компании адресные меры.
23.04.2026 [15:04], Андрей Крупин
Selectel выпустила обновлённую ИИ-платформу с расширенными возможностями масштабирования моделей и внедрения в бизнес-процессыКомпания Selectel, являющаяся специализированным поставщиком IT-решений на базе собственной сети дата-центров, сообщила об обновлении собственной ИИ-платформы, упрощающей внедрение искусственного интеллекта в корпоративные процессы и позволяющей организациям быстро разворачивать и масштабировать ИИ-модели в облаке без необходимости самостоятельно настраивать IT-инфраструктуру для работы с ними. Ключевым изменением ИИ-платформы Selectel стала обновлённая версия Foundation Models Catalog — сервиса для тестирования, запуска и интеграции больших языковых моделей (LLM) в приложения и бизнес-процессы, дополненного средствами управления ИИ-моделями через REST API и пользовательский интерфейс, а также инструментами мониторинга и автоматизации, помогающими отслеживать работу моделей и улучшать их производительность. 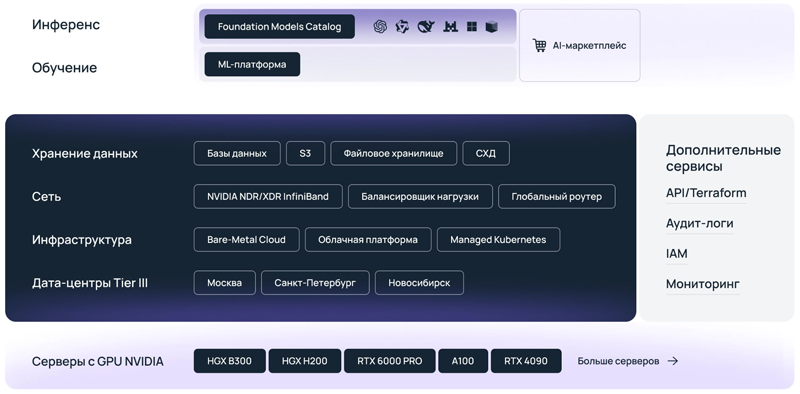
Как устроена ИИ-инфраструктура Selectel (источник изображения: selectel.ru/solutions/ai-infrastructure) Среди прочих обновлений в продукте разработчик отмечает следующие:
Оплата за пользование ИИ-платформой Selectel осуществляется за фактически используемые вычислительные ресурсы. В ближайшее время заказчикам станет доступна новая модель тарификации по количеству токенов.
22.04.2026 [10:30], Сергей Карасёв
РТК-ЦОД внедрил обновлённые решения Basis Dynamix и Basis Virtual Security в «Облаке КИИ»ИТ-сервис-провайдер полного цикла РТК-ЦОД сообщил о масштабном обновлении ПО «Базиса» в своих дата-центрах. В частности, установлены сертифицированные апдейты для платформы управления динамической инфраструктурой Basis Dynamix и средства защиты виртуальных сред Basis Virtual Security. Названные продукты являются основой «Облака КИИ». Это, как утверждается, первое в России мультитенантное защищённое облако, построенное на отечественных программных и аппаратных решениях. Безопасность «Облака КИИ» подтверждена аттестатом соответствия требованиям приказа ФСТЭК №239, что позволяет размещать в нём объекты критической информационной инфраструктуры до 2 категории значимости включительно и обеспечивать защищённое подключение пользователей. «Облако КИИ» аттестовано в соответствии с требованиями по обработке персональных данных 1 уровня защищённости, а также требованиями по защите данных государственных информационных систем 1 класса. 
Источник изображений: «Ростелеком» Благодаря обновлению софта «Базиса» пользователям «Облака КИИ» стали доступны дополнительные возможности. Среди них упомянуты гибкое управление размером хранилища, перемещение виртуальных машин между узлами средствами платформы для балансировки нагрузки, новые функции межсетевого экрана, в том числе управление его политиками, и пр. Облако подходит как субъектам КИИ, так и крупным коммерческим компаниям, которые уделяют особое внимание защите своих информационных систем. «Мы были первыми, кто в конце 2024 года предложил государственным организациям и крупному бизнесу защищённую облачную инфраструктуру, построенную полностью на российских решениях. Но на этом рынке мало быть первым, нужно быть лидером — а это значит постоянно расширять спектр предлагаемых заказчикам возможностей и поддерживать качество оказываемых услуг. Первую задачу нам помогает решать платформа Basis Dynamix, лидер на рынке серверной виртуализации, а вторую — слаженная работа инженерных команд "РТК-ЦОД" и "Базиса"», — говорит Алексей Суравикин, директор продуктового офиса «РТК-ЦОД».
21.04.2026 [21:56], Андрей Крупин
«Турбо облако» представило платформу для быстрого запуска ИИ-моделей с поминутной тарификацией и автоматическим масштабированиемОблачный провайдер «Турбо облако» (входит в коммерческий IT-кластер «Ростелекома»), запустил Inference Platform — платформу для развёртывания и эксплуатации моделей искусственного интеллекта, в основу которой положены ускорители NVIDIA H200 SXM с интерконнектом InfiniBand. Inference Platform поддерживает различные типы ИИ-моделей, включая open source-решения. Пользователи могут загружать собственные модели или использовать контейнерные образы, разворачивая их в облачной среде без дополнительных инфраструктурных настроек. Сервис обеспечивает автоматическое масштабирование ресурсов (автоскейлинг) в зависимости от нагрузки. Такой подход позволяет оптимизировать использование GPU и снизить затраты при нерегулярной нагрузке, говорит компания. Платформа поддерживает распределённый инференс, позволяя запускать модели объёмом до 1 тплн параметров с размещением на нескольких вычислительных узлах. Также доступно гибкое использование GPU-ресурсов, включая их дробление под задачи меньшего объёма. Дополнительным преимуществом является поминутная тарификация ресурсов, гарантирующая более точный контроль расходов по сравнению с почасовой оплатой. 
Источник изображения: Omar Lopez-Rincon / unsplash.com В настоящее время новый продукт доступен для тестирования: компании могут оценить его возможности на собственных моделях.
21.04.2026 [11:19], Сергей Карасёв
Anthropic получит от AWS до 5 ГВт ИИ-мощностей и до $25 млрд инвестицийКомпании Anthropic и Amazon объявили о расширении сотрудничества в области облачной инфраструктуры и технологий ИИ. В рамках партнёрства Anthropic получит до 5 ГВт мощностей в инфраструктуре AWS для обучения и поддержания работы своих передовых ИИ-моделей семейства Claude. В ответ Amazon инвестирует в Anthropic дополнительные $5 млрд, а в будущем — ещё до $20 млрд в зависимости от достижения определённых коммерческих целей. Ранее Amazon уже вложила $8 млрд в Anthropic. Отмечается, что Anthropic и Amazon тесно работают с 2023 года. В настоящее время более 100 тыс. клиентов используют модели Claude на платформе Amazon Bedrock. Партнёры также запустили Project Rainier — крупнейший в истории AWS и один из самых масштабных вычислительных кластеров в мире. На сегодняшний день Anthropic использует более 1 млн ускорителей AWS Trainium2 для обучения и обслуживания Claude. В рамках расширенного соглашения Anthropic обязуется потратить более $100 млрд в течение следующих десяти лет на вычислительные мощности AWS. Речь идёт об использовании изделий Trainium текущих и будущих поколений, включая Trainium4. Кроме того, будут использоваться «десятки миллионов» ядер Graviton. В общей сложности это даст до 5 ГВт вычислительной мощности. Так, к концу 2026 года будет введено в эксплуатацию около 1 ГВт ресурсов на базе Trainium. 
Источник изображения: Amazon Договор предполагает использование дата-центров в Азии и Европе, что поможет повысить качество обслуживания растущей международной клиентской базы Claude. При этом пользователи смогут получить доступ к полнофункциональной консоли Claude (биллинг, безопасность, управление) непосредственно в облаке AWS — без необходимости управления дополнительными учётными данными или контрактами. Нужно отметить, что Anthropic сотрудничает и с другими поставщиками облачных услуг. В частности, недавно компания объявила о расширении использования инфраструктуры Google Cloud, а также ускорителей Google TPU. Кроме того, Anthropic взяла на себя обязательство приобрести вычислительные мощности Microsoft Azure стоимостью $30 млрд и заключить контракт на поставку дополнительных мощностей объёмом до 1 ГВт. |
|

