Материалы по тегу: к
|
05.12.2025 [12:55], Руслан Авдеев
Key Point ввела в строй вторую очередь новосибирского ЦОДВ Новосибирске введена вторая очередь дата-центра ГК Key Point — 400 стоек по 7 кВт. Общая проектная мощность дата-центра составляет 11 МВт, объект рассчитан на 880 коммерческих стоек. Сообщается, что дата-центр соответствует всем международным требованиям к обеспечению стабильности работы ключевой IT-инфраструктуры, прошёл двухступенчатую сертификацию Uptime Institute и соответствует уровню надёжности Tier III. В компании утверждают, что дата-центр является крупнейшим коммерческим объектом такого рода в Сибири. Для постройки использовалась модульная технология с применением собственных префаб-решений. Надёжность работы обеспечена благодаря многоуровневому резервированию инженерной инфраструктуры: для энергоснабжения речь идёт о схеме 4/3N, для систем охлаждения — N+1. Есть возможность размещения стоек мощностью до 20 кВт. На объекте доступны сервисы девяти операторов связи. 
Источник изображения: ГК Key Point Первая очередь крупнейшего в Сибири коммерческого ЦОД была открыта Key Point в апреле 2024 года. В сентябре того же года сообщалось, что SoftLine и Key Point развернут модульные ЦОД в Сибири и на Дальнем Востоке, а ноябре появилась данные, что Key Point запустит дата-центр в Ростовской области в 2026 году. 
Источник изображения: ГК Key Point Наконец, в марте 2025 года появились данные о там, что ВТБ выделит 3,2 млрд руб. на строительство ЦОД в Свердловской области, а в ноябре — о намерении компании построить ЦОД в Санкт-Петербурге и Дагестане. Сегодня дата-центры компании охватывают большинство ключевых регионов России.
04.12.2025 [15:49], Сергей Карасёв
Лаборатория МФТИ получила российский JBOG-массив RSC ScaleStream-C для решения сложных ИИ-задачЛаборатория машинного обучения в науках о Земле Московского физико-технического института (МФТИ) взяла на вооружение внешний массив PCIe-коммутации RSC ScaleStream-C, разработанный российской группой компаний РСК. Это решение предназначено для выполнения ресурсоёмких задач, связанных с ИИ. RSC ScaleStream-C представляет собой JBOG-платформу в форм-факторе 3U, допускающую установку до десяти карт с интерфейсом PCIe 4.0 x16 (могут применяться карты разной ширины), которая может быть подключена к четырём серверам. Мощности ускорителей могут динамически перераспределяться между серверами. По заявлениям РСК, такой подход позволяет значительно увеличить утилизацию GPU (в некоторых случаях на десятки процентов) по сравнению со стандартными конфигурациями, когда карты устанавливаются непосредственно в серверы. Лаборатория получила массив RSC ScaleStream-C с четырьмя GPU (модель не уточняется). В перспективе могут быть добавлены дополнительные карты. Предполагается, что система поможет ускорить выполнение задач, связанных с базовыми высокоразрешающими ИИ-моделями атмосферы, океана и климата. Ожидается, что применение RSC ScaleStream-C позволит Лаборатории машинного обучения в науках о Земле существенно расширить возможности уже имеющегося оборудования при работе с ИИ-моделями. 
Источник изображения: РСК Основным направлением деятельности Лаборатории является создание ИИ-методов для моделирования атмосферы, океана и климата, а также для обработки данных в фундаментальных и прикладных задачах морской геологии, морской биологии, экологии моря, метеорологии, в области взаимодействия океана и атмосферы, городской микрометеорологии и пр. Специалисты лаборатории занимаются обработкой данных натурных наблюдений и измерений в метеорологии и океанологии, экологическим мониторингом, моделированием природных процессов и другими задачами, для которых требуются значительные вычислительные ресурсы.
24.11.2025 [10:17], Руслан Авдеев
Перекрыть потоки: NVIDIA усиливает контроль над цепочкой поставок СЖО для Vera Rubin
cooler master
delta electronics
foxconn
hardware
nvidia
odm
qct
vr200
wistron
водоблок
ии
производство
сжо
NVIDIA намерена серьёзно изменить управление цепочкой поставок для серверной платформы новейшего поколения Vera Rubin. Она ужесточает контроль над сборкой и поставкой ключевых компонентов систем охлаждения, что связано с ростом энергопотребления и обязательным применением СЖО, сообщает DigiTimes. Это ещё один шаг в процессе усиления контроля над выпуском ИИ-платформ. NVIDIA уже давно внимательно следит за цепочками поставок для ускорителей и плат, но теперь намерена перейти на новый уровень. Источники сообщают, что компания намерена отобрать четырёх поставщиков водоблоков, перейти к координации производства и централизованным закупкам. Предполагается, что это будут Cooler Master, Asia Vital Components (AVC), Auras Technology и Delta Electronics. Ранее СЖО для NVIDIA занимались, в основном, Cooler Master, AVC и некоторые другие поставщики. Ожидается, что для Vera Rubin вместо поставки лишь отдельных компонентов (L6), NVIDIA будет участвовать в процессе и на более позднем этапе (L10), взяв ответственность за интеграцию и сборку готовых серверных шкафов. В целом окончательную сборку поручат Foxconn, Wistron и Quanta. Из-за необходимости быстрого выпуска продукции на поставщиков легла дополнительная нагрузка. Некоторые из них в частном порядке жалуются, что NVIDIA настаивает на запуске массового производства ещё до утверждения окончательного дизайна платформ, а новое поколение платформ часто появляется до того, как предыдущее достигло стабильного уровня производства и качества. Централизованные закупки помогут NVIDIA оптимизировать поставки и контролировать качество, но рентабельность работы поставщиков может пострадать, поскольку NVIDIA сама будет управлять спросом и торговаться по поводу цен. При этом отказ от подобных условий практически невозможен, учитывая доминирующее положение компании на рынке ИИ-инфраструктуры. В результате снижается самостоятельность как ODM, так и облачных провайдеров. Из-за этого же, как считается, во многом замедлено и развитие погружных СЖО — NVIDIA попросту не готова сертифицировать такие системы. 
Источник изображения: NVIDIA Эксперты всё чаще говорят о росте напряжённости, которая со временем приведёт к открытому конфликту. Новый подход NVIDIA, вероятно, повлияет на цепочку поставок двумя путями. Во-первых, контракты на сборку консолидируются вокруг небольшого пула производителей, а выпуск водоблоков сконцентрируется в руках трёх-четырёх компаний. Облачным провайдерам, вероятно, тоже придётся идти на поводу NVIDIA при размещении крупных оптовых заказов, хотя они как раз предпочитают создавать собственные СЖО, что в целом тоже негативно влияет на некоторых игроков. Во-вторых, рост объёмов поставок не гарантирует роста рентабельности. Поставщики предполагают, что цена за единицу продукции в рамках попыток NVIDIA сконцентрировать производителей уменьшится, а более жёсткий контроль над проектированием снизит и стратегическую ценность индивидуальных разработок. Компании уже шутят, что статус крупнейшего поставщика NVIDIA может буквально навредить, поскольку по мере роста объёмов обычно растут и дисконты. Ожидается, что стойки поколения Vera Rubin обеспечат значительно более высокую плотность вычислений, чем уже доступные платформы GB200 и GB300, а для традиционного воздушного охлаждения места уже не останется. В отрасли ожидают, что Vera Rubin представят во II половине 2026 года. Платформа представляет собой важный шаг к созданию ИИ-инфраструктуры с полностью жидкостным охлаждением. Новейшая стратегия NVIDIA, касающаяся цепочек поставок, свидетельствует о решимости компании усилить прямой контроль качества, поставок и их стоимости по мере роста плотности мощности. В JPMorgan утверждают, что NVIDIA станет напрямую поставлять системы L10. Компания унифицирует конструкцию и заставит подрядчиков строго придерживаться предлагаемых чертежей и дизайна без использования проприетарных архитектур, созданных самими подрядчиками. Для NVIDIA это выгодно, поскольку позволяет значительно ускорить отгрузки и кратно сократить сроки развёртывания ИИ-инфраструктур (до 3 мес. вместо 9 мес.), опираясь на единые стандарты — от одного узла до целой ИИ-фабрики. При этом AWS, вероятно, придётся тяжелее всех, поскольку она пытается снизить зависимость от NVIDIA и в то же время не является активным сторонником OCP.
22.11.2025 [12:26], Сергей Карасёв
ASUS представила модульную ИИ-систему PE3000N на платформе NVIDIA Jetson Thor T5000Компания ASUS IoT, подразделение ASUS по выпуску умных устройств для интернета вещей, анонсировала компьютер PE3000N — модульную систему для периферийных ИИ-задач. Устройство выполнено в корпусе повышенной прочности в соответствии со стандартом MIL-STD-810H, а диапазон рабочих температур простирается от -20 до +60 °C. В основу новинки положен модуль NVIDIA Jetson Thor T5000. Изделие содержит CPU с 14 ядрами Arm Neoverse-V3AE (до 2,6 ГГц) и 2560-ядерный GPU на архитектуре Blackwell (до 1,57 ГГц). Имеется 128 Гбайт памяти LPDDR5X с пропускной способностью 273 Гбайт/с. ИИ-производительность достигает 2070 Тфлопс (FP4 Sparse). Встроенный VPU-блок способен осуществлять многопоточное декодирование видеоматериалов: 4 × 8Kp30 (H.265), 10 × 4Kp60 (H.265), 22 × 4Kp30 (H.265), 46 × 1080p60 (H.265), 92 × 1080p30 (H.265), 82 × 1080p30 (H.264) и 4 × 4Kp60 (H.264). Кодирование возможно в режимах 6 × 4Kp60 (H.265), 12 × 4Kp30 (H.265), 24 × 1080p60 (H.265), 50 × 1080p30 (H.265), 48 × 1080p30 (H.264) и 6 × 4Kp60 (H.264). 
Источник изображений: ASUS Компьютер располагает коннектором M.2 M-key 2242/2260/2280 для SSD, разъёмом M.2 E-key 2230 для адаптера Wi-Fi/Bluetooth, коннектором M.2 B-key 3042/3052 для сотового модема 4G/5G (плюс слот для карты nano-SIM), а также разъёмом PCIe x4/x8. Есть сетевые порты 1GbE RJ45 и 10GbE RJ45, интерфейс HDMI 2.0, четыре порта USB 3.1 Type-A, по одному порту USB 3.1 Type-C и USB 3.1 Type-C OTG (OS Flash), два порт USB 2.0, аудиогнёзда на 3,5 мм. Могут быть также задействованы два последовательных порта RS-232/422/485 и четыре порта 25GbE. Реализован интерфейс MIPI CSI (16 линий; через коннектор AGX CSI) с возможностью подключения до 16 камер GMSL.  Дополнительные интерфейсные модули закрепляются в нижней части компьютера. Один из таких блоков содержит шесть портов 1GbE с поддержкой PoE, другой — четыре разъёма 10GbE M12 и два коннектора Fakra для GSML-камер. Габариты системы составляют 165 × 165 × 68 мм (165 × 165 × 97 мм с модулем расширения). Возможна подача питания в диапазоне 12–60 В. В качестве программной платформы применяется Ubuntu.
19.11.2025 [23:59], Владимир Мироненко
Скандал в NetApp: бывший техдиректор продал разработки конкуренту и скрылся в ИсландииNetApp подала в суд на своего бывшего старшего вице-президента и технического директора Йона Торгримура Стефанссона (Jón Thorgrímur Stefánsson), обвинив его в том, что он, работая в компании и продолжая получать зарплату, тайно развивал конкурирующий бизнес, который продал прямому конкуренту за неназванную сумму всего через несколько недель после того, как покинул NetAPP. Об этом сообщил The Register. В иске, поданном NetApp 6 ноября в Окружной суд США по Среднему округу Флориды, утверждается, что Стефанссон в последние месяцы работы в компании занимался кражей интеллектуальной собственности, пытался вербовать своих коллег, а в конечном итоге обманул NetApp, присвоив её разработки, чтобы продать VAST Data свой стартап в сентябре 2025 года. Благодаря своей позиции он имел «широкий доступ» к конфиденциальным материалам компании, от фирменных инноваций до стратегических деловых отношений. Стефанссон проработал в NetApp восемь лет. Согласно иску, он «принимал непосредственное участие в разработке и интеграции облачных продуктов хранения NetApp с основными гиперскейлерами», такими как AWS, Google Cloud и Microsoft Azure, и отвечал за весь облачный портфель продуктов компании. Как и все сотрудники, имеющие доступ к конфиденциальной информации, Стефанссон подписал с NetApp «Соглашение о конфиденциальной информации, изобретениях и неразглашении» (PIIA), которое запрещает раскрытие или ненадлежащее использование конфиденциальной и служебной информации NetApp во время и после окончания трудовых отношений. 
Источник изображения: Tara Vester / Unsplash В рамках соглашения Стефанссон обязался не участвовать в конфликтующих коммерческих проектах, не переманивать сотрудников или партнёров NetApp в течение как минимум года после увольнения, не рекламировать свои изобретения сотрудникам и деловым партнерам NetApp, а также передать NetApp все изобретения, разработанные им во время работы на компанию. Соглашение также обязывает подписавшего уведомлять о любых изобретениях, созданных в течение шести месяцев после окончания трудовых отношений. В иске утверждается, что каждое из этих обязательств было нарушено. Стефанссон покинул NetApp 27 июня и в течение недели создал новую компанию Red Stapler, которая была официально зарегистрирована 3 июля 2025 года. Компания работала в скрытом режиме. Стефанссон занял пост гендиректора, к нему присоединились пять бывших сотрудников и один действующий сотрудник NetApp — Эйрикур Свейнн Храфнссон (Eiríkur Sveinn Hrafnsson), который покинул NetApp лишь 31 августа 2025 года и стал вторым по величине акционером Red Stapler. А уже 9 сентября, VAST Data, один из прямых конкурентов NetApp, приобрела стартап и назначила Стефанссона генеральным директором по облачным решениям. По словам VAST Data, решения Red Stapler позволят её продуктам «легко интегрироваться в публичные облачные среды». NetApp «не верит, что Red Stapler разработала собственную облачную платформу управления и доставки данных менее чем за десять недель» с момента основания, и утверждает, что приобретённые VAST продукты фактически были её собственными технологиями. Компания сообщила, что потратила годы и десятки миллионов долларов на разработку своего Service Delivery Engine — слоя оркестрации, связывающего облака гиперскейлеров и хранилища NetApp. SDE позволяет конечным пользователям управлять всеми элементами своего хранилища данных из отдельного интерфейса, интегрируясь с любой публичной облачной платформой, пишет Forbes. 
Источник изображения: Tara Vester / Unsplash Ровно это, по мнению NetApp, и предоставляет решение Red Stapler. Даже если предположить, что Стефанссон и его команда каким-то образом самостоятельно разработали технологию Red Stapler в кратчайшие сроки, соглашение PIIA всё равно требовало от него уведомить NetApp об изобретении, но он этого не сделал. В судебных документах NetApp приведены доказательства её обвинений. Во-первых, приводится текстовое сообщение бывшего сотрудника NetApp, ныне входящего в совет директоров VAST, указывающее на то, что Стефанссон согласился присоединиться к VAST в январе 2025 года, за несколько месяцев до своего ухода. Во-вторых, компания обнаружила переписку в Slack, где Стефанссон обсуждал переманивание сотрудников NetApp перед своим уходом. В частности, Стефанссон якобы спрашивал Храфнссона, есть ли у него «данные о зарплатах всех», кого они хотели бы нанять в Red Stapler. В-третьих, компания указывает на учётную запись redstapler-is на GitHub, которая, была создана не позднее 16 июня 2025 года, т.е. за 11 дней до официального ухода Стефанссона из NetApp. Это, как утверждает NetApp, свидетельствует о том, что проектирование и разработка велись, когда Стефанссон всё ещё работал в NetApp. По словам NetApp, в совокупности эти документы показывают, что Стефанссон «разрабатывал технологии и/или исходный код, а также занимался инновациями от имени другой организации», работая в компании. 
Источник изображения: Michel Catalisano / Unsplash Когда NetApp узнала о сделке VAST в конце октября, она направила Стефанссону письменное предупреждение о нарушении прав интеллектуальной собственности (cease-and-desist letter), в котором подчёркивалось прямое дублирование его работы в NetApp и позиции гендиректора по облачным решениям VAST. В письме также подчёркивалась невозможность разработки платформы Red Stapler без использования конфиденциальной информации NetApp в столь короткие сроки. Стефанссон не ответил на письмо, после чего NetApp отправила ему второе послание, которое тоже осталось без ответа. Более того, через несколько дней после первого письма Стефанссон выставил свой дом в Орландо (Orlando) на продажу и затем покинул США, переехав, по всей видимости, в Исландию. После этого NetApp обратилась в суд, который вынес временный судебный запрет Стефанссону использовать материалы, являющиеся собственностью NetApp, участвовать в любой работе, связанной с продуктами или ПО, разработанными им в период работы в Исландии, привлекать деловых партнёров NetApp, а также уничтожать или распоряжаться документами, имеющими отношение к делу. Срок действия временного запрета истекает 26 ноября. NetApp заявила, что намерена добиваться бессрочного судебного запрета, остающегося в силе до конца судебного разбирательства. Следует также отметить, что VAST не упоминается в иске и не обвиняется NetApp в каких-либо правонарушениях. Пока речь идёт лишь о предполагаемых действиях покинувшего компанию ключевого руководителя, который случайно оказался в VAST Data, чтобы помочь в разработке конкурирующего продукта.
19.11.2025 [16:50], Руслан Авдеев
Кризис в Красном море повлиял на проекты интернет-кабелей Google и Meta✴Военно-политический кризис в регионе Красного моря негативно сказался на проектах кабельной инфраструктуры. По данным eWeek, пострадали проект самого протяжённого в мире кабеля Meta✴ 2Africa, системы Google Blue-Raman, India-Europe-Xpress (IAX), Sea-Me-We 6 и другие, оказавшиеся в зоне продолжающихся боевых действий. Хотя Meta✴ уже объявила о завершении строительства базовой инфраструктуры 2Africa, eWeek утверждает, что участок на юге Красного моря всё ещё чересчур опасен для строительства. Отмечаются эксплуатационные проблемы, препятствия со стороны регуляторов и геополитические риски, которые и не думают идти на спад. Утверждается, что контролирующие часть региона хуситы в последние два года постоянно наносили ракетные удары, вынуждавшие суда обходить опасные зоны и лишая кабелеукладчики возможности работать. Через Красное море проходит порядка 17 % мирового интернет-трафика, а также более 90 % цифровых коммуникаций между Европой и Азией. При этом ситуация не улучшается. В 2024 году в Красном море были повреждены четыре подводных кабеля (нарушено 25 % телеком-трафика между Европой, Азией и Африкой). Пару месяцев назад несколько кабелей были снова повреждены, из-за чего упало качество связи на Ближнем Востоке и в Азии. Весной был ещё один обрыв. 
Источник изображения: Sandro Gautier/unsplash.com Столкнувшись с ростом рисков, техногиганты изучают прокладку дорогостоящих сухопутных альтернативных кабелей, позволяющих полностью обойти акваторию Красного моря, и покупку мощностей на других маршрутах. Задержки с реализацией проектов ограничивают развитие широкополосного интернета в регионе, и без того страдающего от недостаточно качественной связи. Утверждается, что в прокладку подводных кабелей в регионе Красного моря в 2000–2024 гг. инвестировали свыше $10 млрд более 30 телеком-компаний, поэтому каждый месяц задержки весьма чувствителен для них. Важную роль играет и необходимость постоянного устранения обрывов. По словам экспертов, среднее время ремонта повреждённого кабеля составляет сегодня порядка 40 дней, но возможностей всё ещё недостаточно с учётом быстрого развития подводных ВОЛС. Согласно расчётам экспертов, в 2025–2027 гг. инвестиции только в новые подводные проекты достигнут около $13 млрд, тогда как парк судов растёт значительно медленнее, чем требуется. По мере роста напряжённости всё активнее диверсифицируется создание устойчивых сетей, способных выдержать удары стихии или конфликты с сохранением функциональности. В eWeek утверждают, что вопрос не в том, «подвергнутся ли уязвимые места новому испытанию?», а в том, когда это случится и будет ли готова к этому глобальная Сеть. Об угрозе кабелям в Красном море TeleGeography сообщала почти два года назад — уже тогда под вопросом оказалась не только возможность прокладки новых цифровых маршрутов, но и обслуживания уже имеющихся в регионе кабелей.
19.11.2025 [13:30], Руслан Авдеев
Самый протяжённый в мире подводный интернет-кабель Meta✴ 2Africa охватил треть населения ЗемлиMeta✴ объявила о завершении строительства базовой инфраструктуры 2Africa — самой протяжённой в мире кабельной системы открытого доступа. Проект стал результатом многолетнего сотрудничества и инноваций, говорит компания. Интернет-кабель соединит Восточную и Западную Африку в единую сеть, а также обеспечит связь континента с Ближним Востоком, Южной Азией и Европой. Сегодня проект охватывает 33 страны и их число продолжает увеличиваться. Компания обеспечивает связью 3 млрд человек в Африке, Европе и Азии, т.е. речь идёт о более 30 % населения мира. Консорциум во главе с Meta✴, включающий Bayobab (MTN Group), center3 (stc), CMI, Orange, Telecom Egypt, Vodafone Group и WIOCC, объединился для разработки и инвестиций в проект, призванный обеспечить прокладку самой протяжённой в мире подводной кабельной системы открытого доступа. С учётом расширения в 2026 году проекта Pearls общая протяжённость кабелей 2Africa в 45 тыс. км превысит длину окружности Земли. 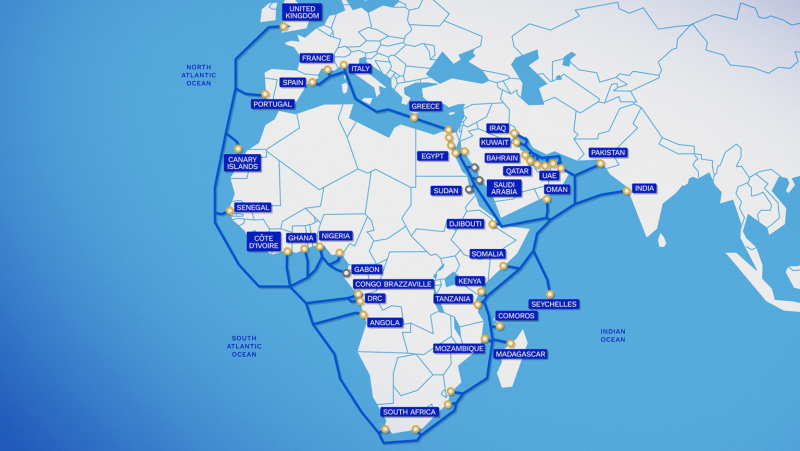
Источник изображения: Meta✴ Для реализации проекта потребовалось сотрудничество государственного и частного секторов. Компании управляли проектом и обеспечивали взаимодействие с партнёрами на местах, развёртывание охватило 50 юрисдикций и заняло почти шесть лет. Модель открытого доступа гарантирует, что инфраструктуру могут использовать сразу несколько поставщиков телеком-услуг, что ускорит цифровую трансформацию региона и внедрение на соответствующей территории ИИ-технологий. Новые партнёры, в том числе Bharti Airtel и MainOne (Equinix), сотрудничали с консорциумом в отдельных сегментах, что дополнительно расширило охват кабельной сети. Глубина прокладки 2Africa выросла на 50 % в сравнении с предыдущими системами для защиты от всевозможных угроз на морском дне — это повысило устойчивость и доступность сети. Система получила по два независимых магистральных канала электропитания, в Западном, Восточном и Средиземноморском сегментах. Кроме того, отдельное внимание было уделено прокладке кабеля в местах пересечений с более чем 60 подводными нефте- и газопроводами. Также были учтены природные опасности вроде гигантских подводных оползней у берегов Западной Африки. Для прокладки задействовали 35 морских судов (в общей сложности 32 года эксплуатации) и десятки прибрежных судов. В некоторых районах устанавливалось специальное оборудование вроде водолазных декомпрессионных камер. 
Источник изображения: Meta✴ Кабель использует 16 пар волокон и пространственное мультиплексирование (SDM) — это первый подводный кабель такого класса, обеспечивший связью практически весь континент. Партнёры внедрили подводную оптоволоконную коммутацию, позволяющую динамически управлять полосами пропускания и удовлетворять растущие потребности ИИ и облачных решений. 2Africa обеспечивает континенту значительно большую пропускную способность, чем предыдущие системы. Так, в западном сегменте от Англии (Великобритания) до Южной Африки (охватывает Сенегал, Гану, Кот-д'Ивуар, Нигерию, Габон, Республику Конго, Демократическую Республику Конго и Анголу), пропускная способность составляет 21 Тбит/с на пару волокон, а транка из нескольких волокон — около 180 Тбит/с. Такая пропускная способность обеспечивает почти неограниченный доступ к международному интернету, позволяя интернет-провайдерам и мобильным операторам получать доступ к связи по низким оптовым ценам. Это создаёт рыночную конкуренцию, поддерживает облачные сервисы, дата-центры и развёртывание сетей 5G. Ожидается, что 2Africa только за первые два-три года эксплуатации внесёт вклад в ВВП Африки в объёме до $36 млрд. Прокладка кабеля помогает созданию рабочих мест, развитию предпринимательства и инновационных центров в подключенных регионах. 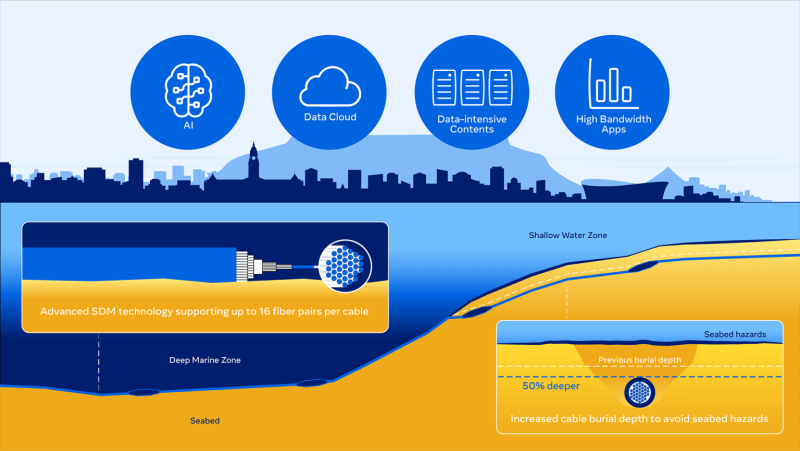
Источник изображения: Meta✴ Опыт предыдущих прокладок показывает, что качественный доступ в Сеть способствует повышению уровня занятости, производительности труда, а также помогает осваивать более квалифицированные профессии. 2Africa в Meta✴ называют частью миссии компании по построению будущего межчеловеческих связей, новая ВОЛС открывает большие возможности для африканских сообществ — они смогут играть важную роль на новом этапе активности глобальной цифровой экономики. В начале ноября сообщалось, что Seacom рассматривает прокладку подводного кабеля по суше, через самое сердце Африки. Перенаправлять трафик в случае инцидентов не всегда просто и довольно дорого. Сквозное соединение через континент помогло бы избежать многих проблем, но его пока нет. Сама Meta✴ когда-то предложила прокладывать ВОЛС вглубь континента по ЛЭП с помощью роботов, а также использовать беспроводные сети Terragraph. Сейчас компания готовит проект кабельной системы Waterworth длиной 50 тыс. км, опоясывающей всю Землю.
16.11.2025 [12:35], Сергей Карасёв
Qualcomm представила чипы Dragonwing IQ-X для индустриальных Windows-компьютеровКомпания Qualcomm анонсировала новые SoC семейства Dragonwing IQ-X — изделия IQ-X5181 и IQ-X7181, ориентированные на индустриальный сектор. Чипы предназначены для построения промышленных Windows-компьютеров, систем автоматизации, робототехнических платформ, медицинского оборудования и пр. Решение IQ-X5181 объединяет восемь кастомизированных ядер Qualcomm Oryon (Armv8) с тактовой частотой до 3,4 ГГц, модификация IQ-X7181 — двенадцать. В состав SoC входит графический ускоритель Qualcomm Adreno с частотой соответственно 1,1 и 1,25 ГГц. Младшая версия способна справляться с декодированием видеоматериалов 4Kp60 VP9/AV1 и кодированием 4Kp30 AV1, старшая — 4K120 VP9/AV1 и 4Kp60 AV1. Чипы обеспечивают ИИ-производительность до 45 TOPS с учётом блоков CPU, GPU и Hexagon NPU. 
Источник изображения: Qualcomm Возможно использование до 64 Гбайт оперативной памяти LPDDR5X-4200, флеш-накопителей UFS 4.0 и карт SD/MMC (SD 3.0). Реализованы интерфейсы eDP (eDP1.4b) с поддержкой разрешения до 4096 × 2160 пикселей при 60 Гц и DisplayPort v1.4a (через USB) с поддержкой разрешения до 5120 × 2880 точек при 60 Гц. Изделие IQ-X5121 располагает двумя интерфейсами камер CSI на четыре линии каждый, IQ-X7181 — четырьмя. Для обеих новинок заявлена поддержка 2 × USB 3.1, 3 × USB 4.0 Type-C (DisplayPort v1.4a Alt Mode), 6 × eUSB 2.0 и 221 × GPIO (UART, SPI, I3C, I2C via QUP). В случае IQ-X5181 реализованы интерфейсы 2 × PCIe 4.0 х4 и 2 × PCIe 3.0 х2, в случае IQ-X7181 — PCIe 4.0 х8, PCIe 4.0 х4 и 2 × PCIe 3.0 х2. Кроме того, говорится о поддержке Ethernet (чип-компаньон QPS615), Wi-Fi и Bluetooth (посредством модуля M.2 PCIe), Wi-Fi 7 / Wi-Fi 6E (через WCN785/WCN6856), а также 5G (модем Snapdragon X65). Изделия выполнены в корпусе 1747-ball BGM с размерами 58 × 58 мм с максимальной толщиной 3 мм. Диапазон рабочих температур простирается от -40 до +105 °C. Говорится о совместимости с Windows 10/11 IoT Enterprise LTSC, Qt, CODESYS, EtherCAT и пр. Гарантирована доступность чипов в течение более чем 10 лет.
14.11.2025 [01:55], Владимир Мироненко
NVIDIA вновь впереди всех в новом раунде MLPerf Training v5.1Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training v5.1. На этот раз был установлен новый рекорд по разнообразию представленных систем. Участники этого раунда тестирования представили 65 уникальных систем, оснащённых 12 различными аппаратными ускорителями и различными программными платформами. Почти половина заявок была для многоузловых систем, что на 86 % больше, чем в раунде MLPerf Training 4.1 год назад, причём они так же отличались разнообразием сетевых архитектур. Раунд MLPerf Training v5.1 включает в себя результаты 20 компаний, подавших заявки: AMD, ASUS, Cisco, Dell, Giga Computing, HPE, Krai, Lambda, Lenovo, MangoBoost, MiTAC, Nebius, NVIDIA, Oracle, Quanta Cloud Technology (QCT), Supermicro, Supermicro + MangoBoost, Университет Флориды, Verda (DataCrunch), Wiwynn. 
Источник изображений: NVIDIA Также сообщается, что структура заявок свидетельствует о растущем внимании к тестам, ориентированным на задачи генеративного ИИ: количество заявок на тест Llama 2 70B LoRa увеличилось на 24 %, а на новый тест Llama 3.1 8B — на 15 % по сравнению с тестом, который он заменил (BERT). NVIDIA объявила, что её чипы на архитектуре NVIDIA Blackwell заняли первые позиции во всех семи тестах MLPerf Training v5.1, обеспечив максимально быстрое обучение в работе с большими языковыми моделями (LLM), генерацией изображений, рекомендательными системами, компьютерным зрением и графическими нейронными сетями. 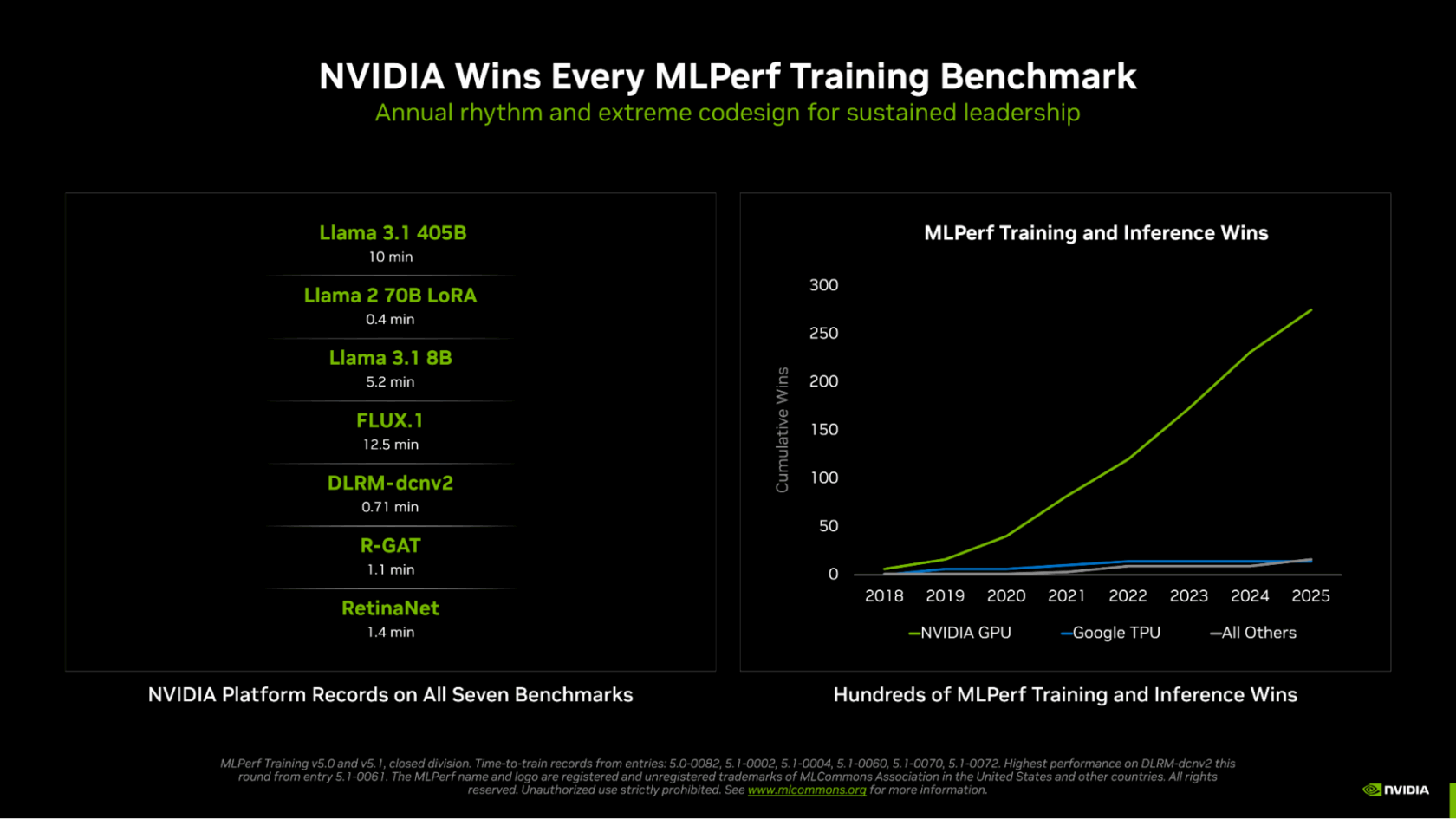 NVIDIA подчеркнула, что была единственной платформой, которая предоставила результаты по всем тестам — это, по словам компании, «подчёркивает широкие возможности программирования ускорителей NVIDIA, а также зрелость и универсальность программного стека CUDA». Компания сообщила, что в этом раунде MLPerf Training дебютировала стоечная система GB300 NVL72, работающая на базе ускорителя NVIDIA Blackwell Ultra, показав рекордные результаты и доказав, что является наилучшим выбором для интенсивных рабочих ИИ-нагрузок. При предварительном обучении Llama 3.1 40B ускорители GB300 обеспечивают более чем вчетверо большую производительность по сравнению с H100 и почти вдвое — по сравнению с GB200. Аналогичным образом, при точной настройке Llama 2 70B восемь ускорителей GB300 обеспечили в пять раз большую производительность по сравнению с H100.  NVIDIA отметила, что этого удалось достичь благодаря архитектурным усовершенствованиям Blackwell Ultra, включая новые тензорные ядра, которые обеспечивают ИИ-производительность в формате NVFP4 в размере 15 Пфлопс, вдвое большую производительность в работе механизма внимания (attention-layer compute) и 279 Гбайт HBM3e, а также новые методы обучения, которые позволили повысить вычислительную производительность архитектуры NVFP4. В MLPerf также дебютировала 800G-платформа Quantum-X800 InfiniBand, объединяющая несколько систем GB300 NVL72, которая удвоила пропускную способность сети по сравнению с предыдущим поколением. Но по словам компании, «ключом к выдающимся результатам в этом раунде было выполнение вычислений с использованием NVFP4 — впервые в истории MLPerf Training». NVIDIA обеспечила поддержку FP4 для обучения LLM на каждом уровне, что позволило удвоить скорость вычислений по сравнению с FP8. Ускоритель NVIDIA Blackwell может выполнять вычисления в формате FP4 (в т.ч. NVFP4 и др.) с удвоенной скоростью по сравнению с FP8, а Blackwell Ultra — с утроенной.  На сегодняшний день NVIDIA является единственной платформой, которая представила результаты MLPerf Training с вычислениями, выполненными с использованием FP4 при соблюдении строгих требований к точности в тесте. Эти результаты были получены с использованием 5120 ускорителей Blackwell GB200, которым потребовалось всего 10 мин. на бенчмарк Llama 3.1 405B, что является новым рекордом. Это в 2,7 раза быстрее, чем лучший результат с использованием архитектуры Blackwell, показанный в предыдущем раунде бенчмарка. NVIDIA также установила рекорды производительности в двух новых тестах: Llama 3.1 8B и FLUX.1. Llama 3.1 8B — компактная, но обладающая высокой производительностью LLM — заменила модель BERT-large, добавив в линейку базовых моделей современную LLM малого размера. NVIDIA представила результаты с использованием до 512 ускорителей Blackwell Ultra, потратив 5,2 мин. на прохождение теста. FLUX.1 — современная модель генерации изображений — заменила Stable Diffusion v2, и только платформа NVIDIA представила результаты этого теста. NVIDIA представила результаты с использованием 1152 ускорителей Blackwell, установив рекорд — 12,5 мин. обучения.
12.11.2025 [14:09], Сергей Карасёв
Компактная рабочая станция Minisforum MS-R1 получила 12-ядерный Arm-процессор с NPU и два порта 10GbEКомпания Minisforum анонсировала рабочую станцию небольшого форм-фактора MS-R1, подходящую для решения различных ИИ-задач. В новинке, которая уже доступна для заказа, соседствуют процессор с архитектурой Arm и ОС на ядре Linux. Устройство заключено в корпус объемом примерно 1,78 л с габаритами 196 × 189 × 48 мм. Применён чип Cix CP8180 (P1) с 12 вычислительными ядрами в конфигурации DynamIQ: 4 × Cortex-A720 с частотой до 2,6 ГГц, 4 × Cortex-A720 с частотой 2,3–2,4 ГГц и 4 × Cortex-A520 с частотой 1,8 ГГц. В состав изделия входит графический ускоритель Arm Immortalis G720 MC10 с поддержкой Vulkan 1.3, OpenGL ES 3.2, OpenCL 3.0. Встроенный VPU-блок обеспечивает возможность декодирования материалов 8Kp60 AV1, H.265, H.264, VP9, VP8, H.263, MPEG-4, MPEG-2, а также кодирования видео 8Kp30 H.265, H.264, VP9, VP8. Процессор наделён нейромодулем (NPU) с поддержкой операций INT4/INT8/INT16/FP16/BF16 и производительностью до 28,8 TOPS. Общее ИИ-быстродействие с учётом CPU и GPU достигает 45 TOPS. 
Источник изображения: Minisforum Компьютер может нести на борту до 64 Гбайт LPDDR5-5500. Есть коннектор M.2 2280/22110 для NVMe SSD с интерфейсом PCIe 4.0 x4. Кроме того, присутствует x16-слот (PCIe 4.0 x8) для карты расширения. В оснащение входят адаптеры Wi-Fi 6E и Bluetooth 5.3 (модуль M.2 2230 E-Key) и двухпортовый сетевой контроллер 10GbE (Realtek RTL8127). Устройство располагает тремя портами USB 3.1 Type-A и четырьмя разъёмами USB 2.0 Type-A, двумя интерфейсами USB 3.1 Type-C (DisplayPort 1.4 Alt Mode), двумя гнёздами RJ45 для сетевых кабелей, интерфейсом HDMI 2.0, аудиогнездом на 3,5 мм и 40-контактной колодкой GPIO. Питание (19 В, 180 Вт) подаётся через DC-разъём. Система охлаждения включает три медные тепловые трубки и вентилятор. Новинка поставляется с Debian 12. Цена варьируется примерно от $500 за версию с 32 Гбайт ОЗУ без накопителя до $700 за модификацию с 64 Гбайт памяти и SSD вместимостью 1 Тбайт. |
|

