Материалы по тегу: s
|
22.04.2026 [01:35], Владимир Мироненко
MWS: в России продолжается олигополизация IT-рынка, а самым конкурентным рынком ПО остаётся рынок ИИСогласно исследованию MWS Cloud, на российском ИТ-рынке (ПО и оборудование) продолжается процесс олигополизации. В частности, на рынке ПО в 2026 году на Топ-5 компаний приходилось 58 %, тогда как годом ранее их доля составляла 56,8 %, а в 2022 — 52,8 %. Лидером по олигополизации оказался рынок платёжных систем, где доля Топ-5 игроков составила 93 %, а самым конкурентным — рынок ИИ, где их доля равна 36 %. В 2026 году на рынке облаков на Топ-5 игроков придётся 74 % рынка, тогда как в 2022 году на них приходилось 63 %. На рынке ERP и бухучёта на Топ-5 компаний придётся 67 % (в 2022 году — 66 %), HR и ИБ-сервисов — 62 % (в 2022 году — HR — 57 %, ИБ-сервисов — 55 %), ПО для взаимодействия с клиентами — 59 % (33 %), систем управления данными — 56 % (51 %), управления бизнесом — 54 % (53 %), производственного ПО — 51 % (50 %), систем продуктивности — 44 % (38 %), платформенного ПО — 42 % (38 %). 
Источник изображения: MWS Аналогичная ситуация наблюдается и на рынке оборудования в России. На Топ-5 компаний в среднем приходится 57,6 % рынка (в 2025 году — 54,8 %). Наибольшая доля Топ-5 компаний отмечена на рынке СХД — 75 % (62 % в 2022 году); далее следуют рынок серверов — 58 % (51 %), сетевого оборудования и ИБ — 57 % (в 2022 году 5 7% — на рынке сетевого оборудования, 56 % — на рынке ИБ-оборудования), оборудования для ЦОД — 41 % (59 %). Также укрепляются позиции Топ-5 компаний на рынке ИТ-услуг. Если в 2022 году в среднем их доля составляла 44 %, то в 2025 году она увеличилась до 51 %, а в 2026 году — до 53 %. Лидирует по олигополизации рынок колокации, где в 2026 году доля Топ-5 компаний составит 89 % (в 2022 году — 84 %). За ним следует рынок ИИ-сервисов — 71 % (53 %), далее — консалтинг — 64 % (51 %), заказная разработка ПО — 47 % (28 %), аутсорсинг — 43 % (38 %), системная интеграция — 35 % (31 %), услуги ИБ — 24 % (27 %).
21.04.2026 [11:19], Сергей Карасёв
Anthropic получит от AWS до 5 ГВт ИИ-мощностей и до $25 млрд инвестицийКомпании Anthropic и Amazon объявили о расширении сотрудничества в области облачной инфраструктуры и технологий ИИ. В рамках партнёрства Anthropic получит до 5 ГВт мощностей в инфраструктуре AWS для обучения и поддержания работы своих передовых ИИ-моделей семейства Claude. В ответ Amazon инвестирует в Anthropic дополнительные $5 млрд, а в будущем — ещё до $20 млрд в зависимости от достижения определённых коммерческих целей. Ранее Amazon уже вложила $8 млрд в Anthropic. Отмечается, что Anthropic и Amazon тесно работают с 2023 года. В настоящее время более 100 тыс. клиентов используют модели Claude на платформе Amazon Bedrock. Партнёры также запустили Project Rainier — крупнейший в истории AWS и один из самых масштабных вычислительных кластеров в мире. На сегодняшний день Anthropic использует более 1 млн ускорителей AWS Trainium2 для обучения и обслуживания Claude. В рамках расширенного соглашения Anthropic обязуется потратить более $100 млрд в течение следующих десяти лет на вычислительные мощности AWS. Речь идёт об использовании изделий Trainium текущих и будущих поколений, включая Trainium4. Кроме того, будут использоваться «десятки миллионов» ядер Graviton. В общей сложности это даст до 5 ГВт вычислительной мощности. Так, к концу 2026 года будет введено в эксплуатацию около 1 ГВт ресурсов на базе Trainium. 
Источник изображения: Amazon Договор предполагает использование дата-центров в Азии и Европе, что поможет повысить качество обслуживания растущей международной клиентской базы Claude. При этом пользователи смогут получить доступ к полнофункциональной консоли Claude (биллинг, безопасность, управление) непосредственно в облаке AWS — без необходимости управления дополнительными учётными данными или контрактами. Нужно отметить, что Anthropic сотрудничает и с другими поставщиками облачных услуг. В частности, недавно компания объявила о расширении использования инфраструктуры Google Cloud, а также ускорителей Google TPU. Кроме того, Anthropic взяла на себя обязательство приобрести вычислительные мощности Microsoft Azure стоимостью $30 млрд и заключить контракт на поставку дополнительных мощностей объёмом до 1 ГВт.
20.04.2026 [12:54], Сергей Карасёв
«Однодолларовый» одноплатник BeagleConnect Zepto получил микроконтроллер Texas InstrumentsНекоммерческая организация BeagleBoard.org Foundation, по сообщению CNX Software, готовит к выпуску «однодолларовый компьютер» BeagleConnect Zepto — вычислительный модуль на основе открытого аппаратного обеспечения. Новинка ориентирована на устройства интернета вещей (IoT), системы автоматизации и т. п., т. ч. полноценным микрокомпьютером её не назвать. Изделие имеет размеры 33,7 × 25,4 мм. Его основой служит микроконтроллер Texas Instruments серии MSPM0, например, MSPM0L117 (стоит $0,51) с ядром Arm Cortex-M0+ (32 МГц), 16 Кбайт памяти SRAM и 128 Кбайт флеш-памяти. Возможны и другие варианты:

Источник изображения: BeagleBoard.org Foundation Реализована поддержка стандарта mikroBUS для подключения периферийных модулей. Говорится о совместимости с примерно 2 тыс. плат, включая некоторые решения Raspberry Pi HAT. В зависимости от модификации доступны до двух коннекторов Qwicc (I2C, UART, ADC, GPIO). Питание (5 В) может подаваться через опциональный порт USB Type-C или разъём Qwicc/JST. Предусмотрены кнопки Boot и Reset. Организация BeagleBoard.org Foundation указывает на поддержку BeagleConnect Greybus for Zephyr, что позволяет управлять модулями mikroBUS через Linux без необходимости разработки дополнительного софта для микроконтроллера. Упомянута прошивка Micropython поверх Zephyr.
19.04.2026 [14:20], Владимир Мироненко
TD Synnex арендовала у Nebius кластеры NVIDIA B300, чтобы дать ИИ-мощности партнёрами и клиентамTD Synnex, американский дистрибьютор и агрегатор IT-решений, объявил о расширении своего портфеля услуг ИИ-инфраструктуры (AI Infrastructure-as-a-Service) в Северной Америке за счёт резервирования более тысячи ускорителей в составе выделенных кластеров NVIDIA HGX B300, развёрнутых в ИИ-облаке Nebius. Мощности в Nebius AI Cloud предназначены для партнёров и клиентов TD Synnex, и это, по словам компании, первая сделка такого рода. Дистрибьютор отметил, что заблаговременное выделение GPU-мощностей помогает партнёрам преодолеть один из наиболее существенных барьеров на пути внедрения ИИ в корпоративной среде: непостоянный доступ к вычислениям. Партнёры смогут напрямую выделять зарезервированные мощности для рабочих нагрузок клиентов, ускоряя переход от экспериментов в области ИИ к продуктовым решениям. Облачная платформа TD Synnex x Nebius AI Cloud соответствует эталонной архитектуре NVIDIA Enterprise Reference Architecture (Enterprise RA) и поддерживает непрерывные рабочие нагрузки обучения и инференса. Встроенные функции безопасности, изоляции и операционной надёжности обеспечивают готовую основу для партнёров, предоставляющих корпоративные решения в области ИИ. Благодаря партнёрской экосистеме TD Synnex, инфраструктура может быть объединена с ПО NVIDIA AI Enterprise и продуктами независимых поставщиков ПО (ISV) для предоставления комплексных, готовых к использованию в корпоративной среде решений на основе ИИ. 
Источник изображения: TD Synnex «Спрос на ИИ в корпоративной среде реален, но реализация застопоривается, когда инфраструктура не гарантирована», — говорит вице-президент по глобальному партнёрству Nebius. Как сообщил ресурсу CRN старший вице-президент по облачным технологиям, безопасности и ИИ в TD Synnex, сделка с Nebius вызвала такой большой интерес у партнёров по каналу продаж, что, по его мнению, первая партия инстансов «вероятно, будет раскуплена довольно быстро», и компания уже думает о будущем расширении. В прошлом месяце было объявлено о стратегическом партнёрстве NVIDIA и Nebius, в рамках которого производитель чипов инвестирует в стартап $2 млрд для разработки и строительства ИИ ЦОД.
17.04.2026 [23:32], Владимир Мироненко
Храним здесь, запускаем там: OCI и AWS подружили свои облачные сетиOracle и Amazon решили объединить усилия для создания частного высокоскоростного соединения между OCI и AWS. Благодаря установлению связи между Oracle Interconnect и AWS Interconnect–multicloud клиенты обеих компаний получат доступ к быстрому, частному, управляемому соединению для бесперебойного запуска приложений и перемещения данных между OCI и AWS. Как отмечено в пресс-релизе, благодаря созданию ранее облачного сервиса Oracle AI Database@AWS компании впервые предложили клиентам более простой способ запуска Oracle AI Database в ЦОД AWS с теми же функциями, архитектурой и производительностью, что и в локальной среде. «Теперь мы развиваем это направление, устанавливая соединение между нашим популярным межоблачным соединением и AWS Interconnect–multicloud. Это поможет нашим общим клиентам модернизировать свои приложения, объединить данные и открыть новые возможности генеративного ИИ», — сообщила Oracle. Этот шаг отражает переход предприятий к мультиоблачным инфраструктурам, использующим десятки отдельных облачных платформ и сервисов, пишет ресурс SiliconANGLE. Современные ИИ-приложения обычно работают на архитектуре с разделённым стеком — например, компания может использовать высокопроизводительную базу данных в OCI вместе с AWS SageMaker. Изменить что-либо после запуска системы непросто, и без высокопроизводительного моста между двумя облаками клиенты будут сталкиваться с экстремальными задержками, что будет отражаться на возможностях ИИ-приложений. 
Источник изображения: Oracle SiliconANGLE назвал нынешний анонс довольно неожиданным, учитывая, что отношения компаний долгое время были напряжёнными. Однако, похоже, обе компании только выиграют от партнёрства, обеспечив передачу данных между своими облаками как между единой интегрированной платформой. С этой целью Oracle интегрирует свой собственный сервис межсетевого взаимодействия со спецификацией AWS Interconnect-multicloud для создания безопасного и приватного соединения, полностью обходящего публичный интернет. Это позволит компаниям поддерживать развёртывание с разделением стека, так что организации смогут запускать приложение в OCI и хранить его данные в AWS, или наоборот. Примечательно, что Oracle охарактеризовала новое решение как «управляемое» и «нативное», то есть, клиентам не нужно настраивать вручную маршрутизацию или разрабатывать сложные стратегии репликации данных. Соблюдая спецификации AWS, Oracle, по сути, стандартизирует способ взаимодействия своего облака с платформой конкурента. 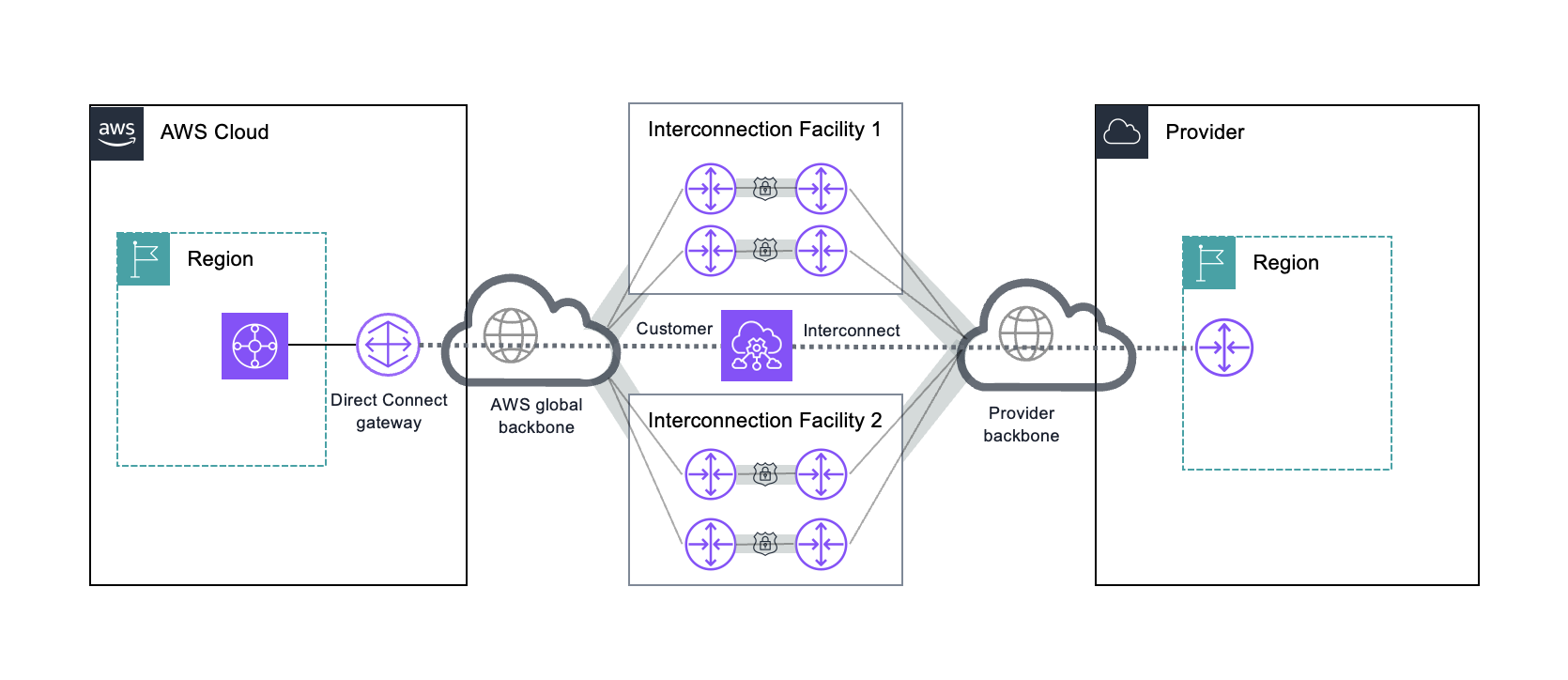
Источник изображения: AWS Роб Стречай (Rob Strechay), ведущий аналитик theCUBE Research и Smuget Consulting, сообщил ресурсу SiliconANGLE, что сегодняшний шаг подчеркивает убеждение в том, что мультиоблачные решения — это уже не просто стратегия, а реальность для каждого предприятия. «Устраняя сложность сетевого взаимодействия между двумя крупнейшими доменами, Oracle и AWS делают межоблачную отказоустойчивость и ИИ-архитектуры гораздо более достижимыми для предприятий», — сказал он. «Будущее ИИ — это когда ваши данные хранятся в одном месте, ваши модели работают в другом, и сеть не мешает, — отметил Стречай. — Это также позволяет организациям легко осуществлять аварийное восстановление в разных облаках. Хотя на бумаге это всегда имело смысл для баз данных, Oracle делает это достижимым на практике без создания масштабного проекта в области сетевых технологий». Следует отметить, что Google Cloud ещё в мае 2023 года запустил мультиоблачное соединение Cross-Cloud Interconnect, а затем, в декабре прошлого года, — выделенное частное соединение с AWS. Со своей стороны, Oracle уже установила межсетевые соединения с Google Cloud и Azure от Microsoft. Oracle отметила, что сотрудничество между OCI и AWS Interconnect–multicloud станет последним дополнением к её комплексным мультиоблачным возможностям, планируя запуск высокопроизводительного канала позже в этом году в регионе AWS us-east-1.
17.04.2026 [22:53], Владимир Мироненко
ИИ-стартап Cerebras поставит OpenAI ускорители ещё на $20 млрдКомпания OpenAI заключила соглашение с ИИ-стартапом Cerebras, согласно которому она выплатит более $20 млрд в течение следующих трёх лет за поставку ИИ-ускорителей, сообщило издание The Information. В рамках сделки OpenAI получит варранты на миноритарную долю в Cerebras, при этом её доля может увеличиться по мере роста расходов, утверждают источники The Information. По их данным, OpenAI также согласилась предоставить Cerebras около $1 млрд для финансирования развёртывания ЦОД на базе её ИИ-ускорителей. До этого, в январе Cerebras договорилась с OpenAI о поставке в течение трёх лет своих ускорителей общей мощностью 750 МВт. Стоимость этой сделки оценивается в $10 млрд. Новое соглашение подчеркивает растущий интерес отрасли к вычислительным мощностям для инференса, отметило агентство Reuters. По его данным, Cerebras может раскрыть некоторые подробности своего соглашения с OpenAI, когда предоставит регулятору документы для проведения первичного публичного размещения (IPO). 
Источник изображения: Cerebras Исходя из общей суммы контрактов The Information допускает, что OpenAI может получить варранты, представляющие до 10 % доли в Cerebras. Сотрудничество с OpenAI является ключевым элементом в планах Cerebras по выходу на биржу, планирующего провести листинг во II квартале этого года. Cerebras, чья рыночная стоимость, по последним оценкам, составляет $23,1 млрд, планирует привлечь $3 млрд в ходе первичного публичного размещения акций в следующем месяце при оценке примерно в $35 млрд, сообщил The Information. Выход на биржу неоднократно откладывался. Сначала компанию подозревали в опосредованных связях с Китаем и зависимости от ближневосточных нефтедолларов, а потом компания дважды получила крупные инвестиции и нарастила капитализацию. Сделки с AWS и OpenAI укрепили её позиции и успокоили инвесторов. В пятницу Cerebras объявила о подаче заявки на первичное публичное размещение акций (IPO) в США. Компания планирует разместить свои акции на Nasdaq под тикером CBRS. Ведущими андеррайтерами размещения являются Morgan Stanley, Citigroup, Barclays и UBS. Ранее на этой неделе Morgan Stanley открыл Cerebras возобновляемую кредитную линию с доступом до $250 млн, с возможностью увеличения лимита до $850 млн после IPO, сообщил CNBC. Согласно документам, поданным в пятницу, среди инвесторов Cerebras — Alpha Wave, Benchmark, Eclipse, Fidelity и Foundation Capital. На сайте Cerebras также указан генеральный директор OpenAI Сэм Альтман (Sam Altman) в качестве инвестора. Cerebras указала в заявке, что не владеет ЦОД, которые использует для предоставления облачных услуг, но может построить собственные в будущем. В документе также сообщается, что чистая прибыль Cerebras за 2025 год составила $87,9 млн при выручке в $510 млн (рост год к году на 76 %). Компания получила прибыль в размере $1,38 на акцию, по сравнению с убытком в $9,90 на акцию годом ранее. По состоянию на 31 декабря 2025 года у Cerebras оставалось $24,6 млрд невыполненных обязательств, и ожидается, что 15 % этой суммы будет учтено в 2026 и 2027 годах.
17.04.2026 [17:20], Андрей Крупин
«Группа Астра» выпустила инструмент для бесшовной миграции с Windows на Astra Linux«Группа Астра» объявила о коммерческом релизе Astra Migration — инструмента для автоматизированного и управляемого переноса рабочих станций с операционной системы Windows на российскую платформу Astra Linux. Astra Migration представляет собой комплексное клиент-серверное решение для массового перевода рабочих мест на ОС отечественной разработки. Клиентский модуль продукта — Astra Migration App — централизованно устанавливается на исходную Windows, инвентаризирует рабочую станцию и информирует пользователя о ходе миграции на всех этапах перехода при минимальном участии с его стороны. Серверная часть — Astra Migration Server — предоставляет IT-администратору единую панель управления: настройку сценариев миграции, формирование волн перехода, мониторинг статусов устройств в режиме реального времени и контроль блокеров.  Astra Migration обеспечивает перенос пользовательских данных и настроек, проверку совместимости программного обеспечения и оборудования, а также возможность отката к исходной ОС в случае необходимости. В текущей версии поддерживается режим параллельной установки Dualboot — Windows и Astra Linux сосуществуют на одном устройстве, с переносом пользовательских данных и настроек в рамках поддерживаемого сценария. Режим полной замены ОС с переносом данных появится в следующих обновлениях продукта. Все этапы миграции — от инвентаризации исходной системы до финального перехода на Astra Linux — полностью управляемы и прозрачны для IT-администратора. По заверениям «Группы Астра», продукт кратно — в десятки раз — ускоряет процесс миграции по сравнению с ручным переводом на Astra Linux, обеспечивая при этом параллельную обработку более 100 рабочих станций одновременно.
14.04.2026 [16:12], Руслан Авдеев
Как по волшебству: AWS запускает инициативу Project Houdini для ускорения строительства ЦОДAmazon Web Services (AWS) исследует возможность поставить на поток строительство модульных дата-центров для ускорения развёртывания новых мощностей, сообщает Business Insider. Как следует из полученных журналистами внутренних документов компании, инициатива Project Houdini предполагает переход к готовым, собранным ещё на заводе модулям, из которых формируются машинные залы. Предполагается, что такая схема позволит сократить сроки возведения ЦОД «на месяцы». По словам представителя AWS, инновации в сфере строительства дата-центров позволяют создавать ИИ-инфраструктуру «дешевле и быстрее», поэтому клиенты обращаются именно к AWS для выполнения ресурсоёмких рабочих нагрузок. Ожидается, что только в этом году капитальные затраты Amazon составят $200 млрд, большая часть которых пойдёт на ЦОД. На днях руководство AWS сообщало сотрудникам, что компания испытывает недостаток производственных мощностей, из-за чего не может в полной мере удовлетворить спрос на мощности. Отмечается, что сейчас на обустройство машинных залов может уйти до 15 недель, около 60–80 тыс. человеко-часов от момента старта до установки серверов. Рабочие вручную прокладывают коммуникационные сети и электропроводку, готовят стойки т.д. Project Houdini предусматривает создание на производстве крупных секций, объединяющих стойки, системы электропитания, кабельную разводку, освещением, системами пожаротушения и безопасности. 45″ модули массой около 9 т доставляются в ЦОД грузовиками. 
Источник изображения: Josh Olalde/unspalsh.com По оценкам AWS, время развёртывания сократится с 15 до 2–3 недель. Предполагается, что технология будет отработана к августу 2026 года, в конечном итоге её можно будет использовать для строительства более 100 ЦОД ежегодно. В рамках инициативы AWS взаимодействует с Cupertino Electric, производство первых модулей планируется начать в Топике (Topeka, Канзас), Хьюстоне (Houston, Техас) и Солт-Лейк-Сити (Salt lake City, Юта). Хотя модульные ЦОД предлагаются уже давно, обычно они используются в небольших проектах, в качестве одиночного периферийного дата-центра или как объекты всего из нескольких модулей. Такие решения предлагают, например, Schneider Electric и Vertiv. Впрочем, есть и иные подходы. Так, Meta✴ вовсе отказалась от капитального строительства, разместив ИИ-оборудование внутри быстровозводимых тентов.
13.04.2026 [22:25], Владимир Мироненко
Amazon призвала акционеров не углубляться в климатические показатели компанииСовет директоров Amazon преддверии ежегодного общего собрания призвал акционеров отклонить предложение обязать компанию раскрывать больше информации о влиянии расширения её парка ЦОД на её же климатические обязательства, сообщил The Register. Это предложение было подано некоммерческой организацией As You Sow, выступающей за корпоративную ответственность, и Mercy Investment Services, инвестиционным подразделением Sisters of Mercy of the Americas. В нём отмечается, что Amazon стремится к масштабному расширению своей облачной инфраструктуры в течение следующих нескольких лет, что ставит под сомнение реалистичность климатических обязательств, сделанных раннее центральным элементом её корпоративной стратегии. Ранее Amazon обязалась «достичь нулевых выбросов углерода к 2040 году» и полностью перейти на возобновляемые источники энергии к 2030 году. Хотя она утверждает, что выполнила последнее обязательство в 2023 году, в предложении выражается сомнение в том, сможет ли компания поддерживать этот уровень в ближайшие годы, учитывая масштабное расширение ЦОД, запланированное AWS. Компания наряду с Meta✴ действительно является одним из крупнейших мире покупателей «чистой» энергии. Однако ранее глава компании Энди Джасси (Andy Jassy) сообщил, что Amazon добавила 3,9 ГВт вычислительных мощностей в течение 2025 года и намерена удвоить этот показатель к концу 2027 года, потратив $200 млрд на расширение инфраструктуры в 2026 году. 
Источник изображения: MohammadO Shokoofe / Unsplash Для этой инфраструктуры потребуется дополнительная электроэнергия. В предложении отмечено, что коммунальные предприятия в таких штатах, где развиты ЦОД, теперь вынуждены строить новые газовые электростанции для удовлетворения растущего спроса и даже поддерживать работу угольных электростанций. Всё это приводит к выбросам миллионов тонн дополнительных парниковых газов в атмосферу. В связи с этим в предложении задан вопрос, как Amazon планирует решать эту проблему и будет ли увеличен объём закупаемых сертификатов возобновляемой энергии (REC). Инвесторы Amazon выиграют от анализа, объясняющего, как компания будет решать эти проблемы, говорится в документе. В свою очередь, Amazon свой призыв к акционеров отклонить предложение объяснила тем, что считает отчёт, запрошенный в предложении, ненужным. «Мы уже регулярно предоставляем публичные обновления о нашем прогрессе, инициативах и работе по достижению наших климатических целей, включая регулярные отчёты о нашей углеродоёмкости и о наших усилиях по сокращению углеродного следа рабочих нагрузок ИИ и повышению устойчивости и эффективности наших ЦОД, — говорится в обращении Amazon, — В результате, наша текущая публичная отчётность уже решает конкретные проблемы, обозначенные в этом предложении, и делает отчёт, запрошенный в предложении, ненужным».
13.04.2026 [13:05], Сергей Карасёв
Aria Networks представила «думающую» сетевую платформу Deep Networking для высокоэффективных ИИ-инфраструктурКомпания Aria Networks анонсировала сетевую платформу Deep Networking, призванную повысить эффективность работы ИИ-систем. Предложенное решение объединяет специализированное коммутационное оборудование, сетевую ОС SONiC, высокоточную телеметрию на коммутаторах, трансиверах и сетевых картах, а также ИИ-алгоритмы на разных уровнях вычислительной инфраструктуры. Стартап Aria Networks основан в январе 2025 года Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019-м приобрёл американский производитель сетевого оборудования Juniper Networks. Aria Networks занимается разработкой высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным ПО для управления большим количеством модульных коммутаторов как единой системой. На сегодняшний день стартап привлёк в общей сложности $125 млн инвестиций от Sutter Hill Ventures, Atreides Management, Valor Equity Partners и Eclipse Ventures. Идея Deep Networking заключается в том, чтобы рассматривать сеть в качестве активного участника кластера ИИ, а не в роли пассивного слоя. Это достигается путём сбора детальной телеметрии с коммутационных ASIC, внедрения интеллектуальных агентов на каждом уровне и постоянного распространения обновлений ПО через облако. 
Источник изображений: Aria Networks В качестве ключевых показателей быстродействия Aria Networks рассматривает MFU (уровень утилизации оборудования при обучении) и Token Efficiency (эффективность токенов). Первый параметр отражает, какой процент от теоретической максимальной производительности ИИ-ускорителя (пиковых FLOPS) реально тратится на полезные вычисления для обучения или инференса. В свою очередь, эффективность токенов показывает, уровень MFU или время на обработку одного токена. Основное техническое преимущество Deep Networking заключается в получении детализированной телеметрии. Традиционные инструменты мониторинга сети собирают данные постфактум — с относительно невысокой точностью. Решение Aria Networks обрабатывает телеметрию в реальном времени непосредственно с ASIC. Благодаря этому обеспечивается адаптивная настройка параметров DLB (динамическая балансировка нагрузки) и DCQCN (механизм управления перегрузками). 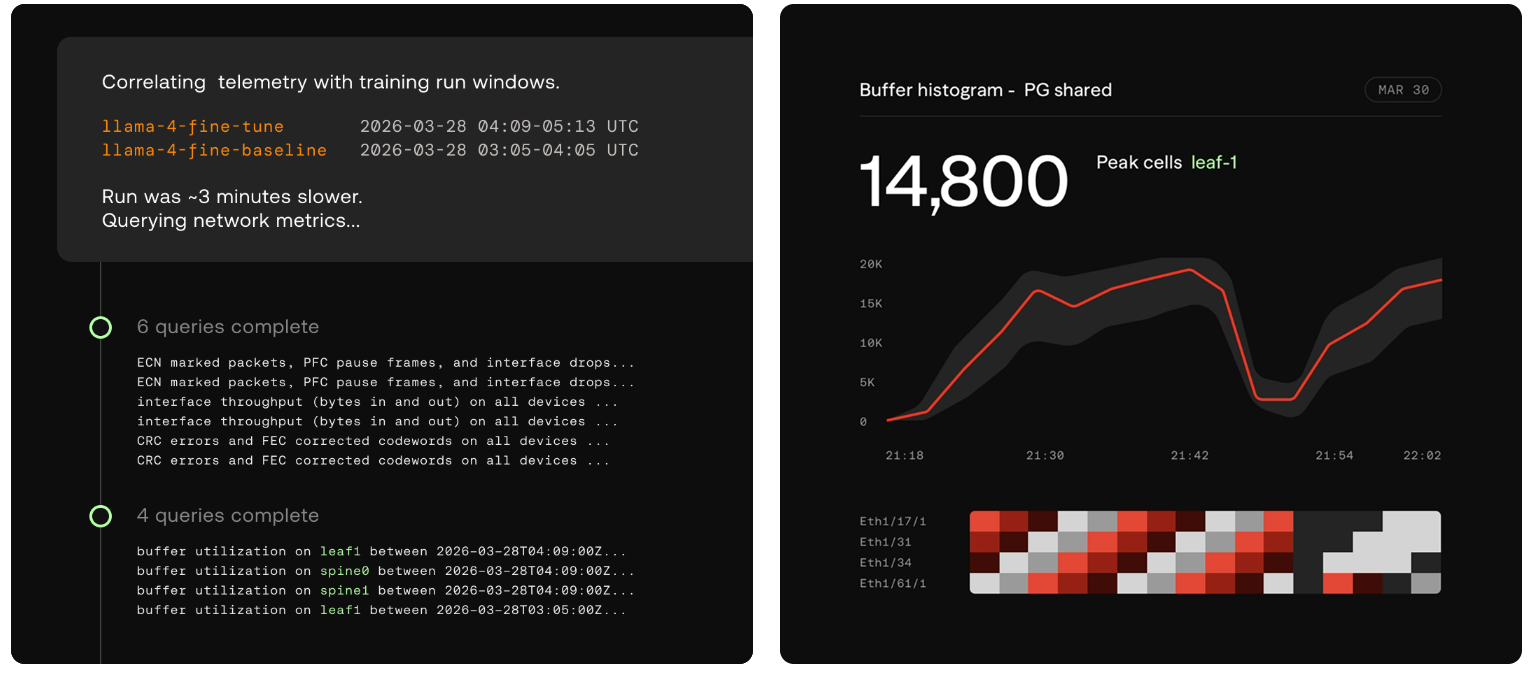 Сама платформа Deep Networking имеет многоуровневую архитектуру. На самых нижних уровнях ИИ-агенты в течение микросекунд реагируют на такие события, как сбои в работе трансиверов, перенаправляя трафик между коммутаторами. На более высоких уровнях принимаются стратегические решения о перераспределении потоков в кластере. Кроме того, внешние системы, например, планировщики заданий и маршрутизаторы, могут напрямую запрашивать сведения о состояние сети и интегрировать их в процесс принятия собственных решений. С аппаратной точки зрения инфраструктура Deep Networking базируется на коммутаторах Aria Switch 800G, Aria Switch 1.6T High Radix и Aria Switch 1.6T, оснащённых чипами Broadcom. Платформа непрерывно настраивает каждый аспект сетевой инфраструктуры для конкретного обслуживаемого ИИ-кластера без ручного вмешательства, что сводит к минимуму задержки и устраняет ошибки, обусловленные человеческим фактором. Администраторам достаточно указать свои потребности, после чего платформа соответствующим образом оптимизирует сеть. При этом система постоянно оценивает состояние сети и в режиме реального времени принимает меры для обеспечения наилучшей производительности и бесперебойной работы. 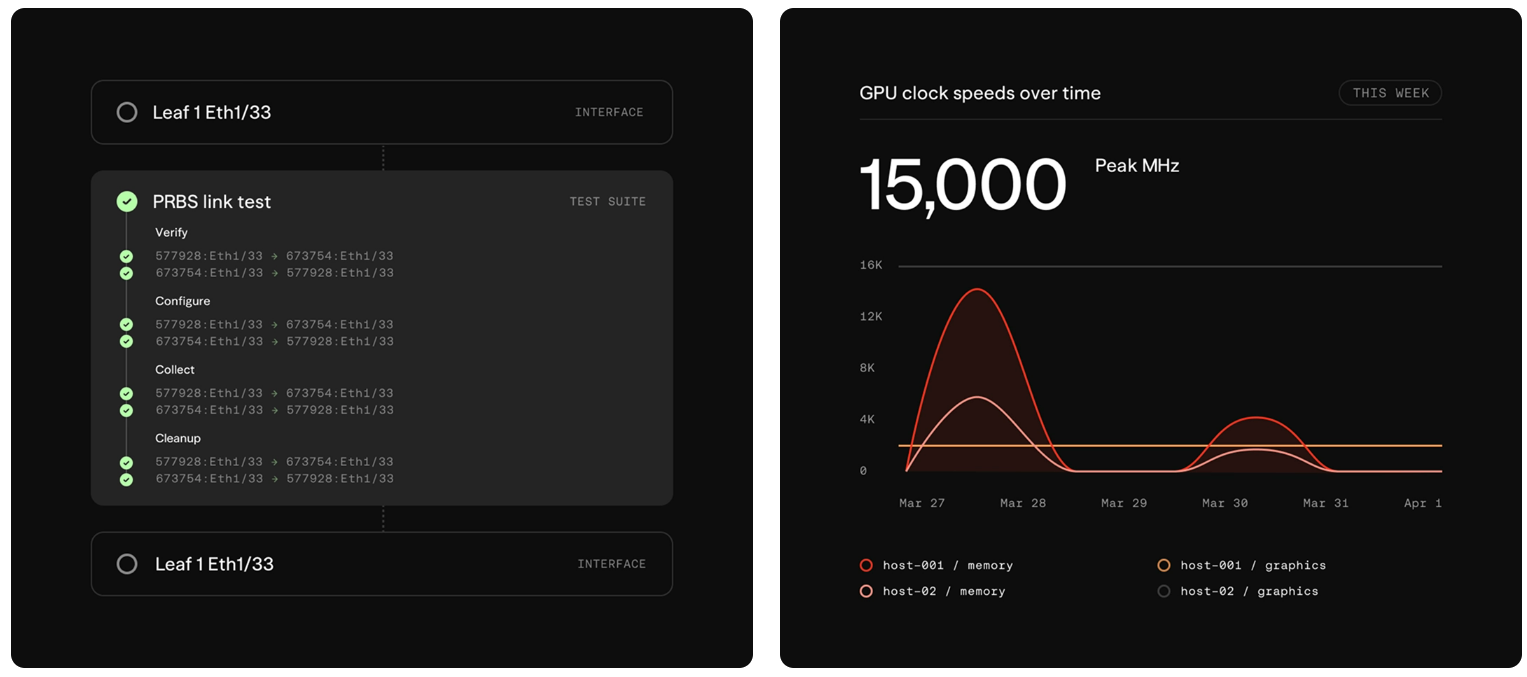 Aria Networks утверждает, что один неисправный сетевой адаптер в кластере из 10 тыс. XPU может снизить показатель MFU на 1,7 %. А сбой трансивера способен спровоцировать некорректную переадресацию трафика, что приведёт к существенным финансовым потерям. Архитектура Deep Networking позволяет эффективно решать подобные проблемы, одновременно улучшая производительность. Так, повышение MFU на 3 % в кластере из 10 тыс. XPU, по оценкам стартапа, приводит к увеличению годовой выручки на $49,8 млн. |
|

