Материалы по тегу: ix
|
09.06.2026 [18:19], Руслан Авдеев
NVIDIA поможет SK hynix, Naver, Doosan, SK Telecom и LG расширить ИИ-инфраструктуру Южной КореиNVIDIA анонсировала новые партнёрства с южнокорейскими технологическими гигантами. В их числе — поставщик чипов памяти SK hynix, интернет-гигант Naver, транснациональный конгломерат Doosan Group, а также SK Telecom и LG, сообщает Silicon Angle. Сделки последовали за поездкой в Южную Корею главы NVIDIA Дженсена Хуанга (Jensen Huang). Прибыв в конце прошлой недели, он провёл выходные за встречами с руководителями южнокорейских технологических компаний. SK hynix подписала с NVIDIA соглашение о многолетнем технологическом партнёрстве, основное внимание в рамках которого уделяется совершенствованию чипов памяти нового поколения для использования в передовых ИИ ЦОД. В рамках договора компания будет взаимодействовать с NVIDIA для обеспечения стабильных поставок памяти для ИИ-индустрии. Кроме того, она попытается расширить присутствие в смежных нишах «персонального ИИ» и «физического ИИ» — например, в сфере автономной робототехники и транспорта. По словам Хуанга, стабильные поставки памяти имеют ключевое значение для ускорения строительства и масштабирования ИИ-фабрик, которые возглавят новую промышленную революцию под предводительством ИИ. Также партнёры намерены сотрудничать в области «технологий симуляции» для разработки полупроводников. SK hynix будет применять библиотеку NVIDIA CUDA-X и фреймворк PhysicsNeMo для повышения скорости и эффективности симуляций, используемых при разработке и производстве передовых чипов. Это включает технологии автоматизированного проектирования (т. н. Technology Computer-Aided Design, TCAD) для анализа характеристик полупроводниковых техпроцессов и технологии вычислительной литографии для создания схем микрочипов. 
Источник изображения: NVIDIA Дополнительно родственная SK hynix компания SK Telecom рассчитывает построить в Южной Корее новое ИИ-облако гигаваттного масштаба на основе ИИ-ускорителей и инфраструктурных решений NVIDIA. Первый из нескольких ИИ ЦОД в составе этого облака должен быть введён в эксплуатацию в начале следующего года. С Naver и Doosan компания тоже договорилась о дополнительных проектах в сфере ИИ ЦОД. В случае с Naver взаимодействие стартует в Седжоне (Sejong), где расположен один из крупнейших в Азии ИИ ЦОД — Naver GAK Sejong. Компании намерены нарастить возможности объекта, а позже заняться строительством дополнительных ИИ-фабрик гигаваттного уровня, хотя будущее этих планов зависит от того, сможет ли Naver обеспечить необходимые закупки оборудования и доступ к электроэнергии. Doosan, разрабатывающая интеллектуальную робототехнику и выпускающая компоненты для GPU NVIDIA, поможет последней задействовать её энергетические решения в своих платформах для ЦОД. Doosan же рассчитывает применять технологии физического ИИ NVIDIA в своих роботах. Наконец, NVIDIA и LG Group строят ИИ-фабрику для ускорения развития нового поколения бизнесов LG, драйвером которых выступит ИИ, — от робототехники до автономного вождения, технологий ЦОД и облачных GPU-сервисов. ИИ-фабрика обеспечит LG инфраструктурой для обучения ИИ, симуляций, оценки и внедрения ИИ-приложений в ключевых сегментах бизнеса. Совместно компании объединят разработку ИИ-моделей, генерацию данных для физического ИИ, моделирование и обучение робототехники, развёртывание решений на периферии и создание цифровых двойников в масштабах целых предприятий в единый рабочий процесс для создания систем физического ИИ. Партнёрство с южнокорейскими компаниями должно помочь расширить присутствие NVIDIA в Южной Корее — одном из мировых технологических лидеров. Кстати, SK hynix и её конкурент Samsung Electronics являются двумя из трёх крупнейших производителей чипов памяти в мире, продукция которых имеет жизненно важное значение для ИИ ЦОД. В ноябре 2025 года сообщалось, что NVIDIA продаст Южной Корее 260 тыс. ускорителей для создания суверенной ИИ-инфраструктуры.
03.04.2026 [09:52], Сергей Карасёв
d-Matrix приобрела разработки GigaIO в области дата-центров, включая НРС-платформу SuperNODEСтартап d-Matrix, занимающийся разработкой ИИ-ускорителей и других специализированных изделий для НРС-систем, объявил о заключении соглашения по приобретению у компании GigaIO активов и разработок, связанных с дата-центрами. Стоимость сделки не раскрывается. В ассортименте d-Matrix присутствуют ускорители Corsair, базирующиеся на технологии вычислений в памяти DIMC (digital in-memory computing), а также IO-карты JetStream, предназначенные для распределения нагрузок ИИ-инференса между серверами в дата-центре. Кроме того, стартап создал стоечную систему SquadRack для пакетного инференса со сверхнизкой задержкой. В свою очередь, GigaIO предлагает так называемый суперкомпьютер в стойке SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Компания разработала архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. Ещё одним продуктом GigaIO является «суперкомпьютер в чемодане» Gryf, который, как утверждается, обеспечивает ИИ-производительность класса ЦОД на периферии. 
Источник изображения: GigaIO d-Matrix и GigaIO начали сотрудничество весной 2025 года. Тогда стороны объединили усилия для создания «самого масштабируемого в мире» решения для инференса. Речь идёт об интеграции ИИ-ускорителей Corsair в состав платформы SuperNODE. В рамках нового соглашения d-Matrix приобрела у GigaIO основные технологии для дата-центров, включая SuperNODE и архитектуру FabreX. По условиям сделки, в d-Matrix перейдут ведущие специалисты GigaIO по разработке стоечных систем: предполагается, что это позволит ускорить развёртывание комплексных решений для высокопроизводительного инференса в ЦОД. Вместе с тем GigaIO сосредоточится на внедрении вычислительных мощностей уровня ЦОД непосредственно на периферии. В частности, планируется дальнейшее развитие концепции Gryf. По заявления GigaIO, рынок периферийных вычислений обладает огромным потенциалом. Благодаря решениям на основе Gryf клиенты смогут обрабатывать критически важные данные ближе к их источнику без проблем с задержками. При этом монтировать Gryf можно практически в любой локации.
26.03.2026 [13:15], Руслан Авдеев
SanDisk стратегически вложила $1 млрд в тайваньского производителя памяти NanyaАкции тайваньского производителя памяти Nanya Technology подорожали на 10 % после того, как в среду компания в частном порядке продала свои акции на сумму $2,5 млрд компаниям SanDisk, Solidigm (SK hynix), Cisco и Kioxia для расширения производства передовых чипов, сообщает Reuters. Новый раунд финансирования был организован на фоне желания компании и её клиентов нарастить производственные мощности, поскольку покупателям очень нужен доступ к передовым чипам на фоне глобального дефицита, вызванного бумом ИИ. При этом пострадал не только рынок ИИ-решений, но и другие отрасли, требующие электронных компонентов, включая производство смартфонов, компьютеров и автомобилей. Быстрое развитие ИИ-инфраструктуры требует гигантских объёмов DRAM, NAND и HDD. В компании подчеркнули, что привлечённые средства будут потрачены на инвестиции в производственные мощности для выпуска передовой памяти. Ключевым инвестором является компания SanDisk, в среду заявившая о намерении купить приблизительно 139 млн акций. По данным The Wall Street Journal, это около 3,9 % с учётом всех «разводнений». Всего компания вложила в покупку около NT$31 млрд ($969,69 млн), остальные компании — по NT$16 млрд. 
Источник изображения: Nanya Помимо инвестиций в ценные бумаги, SanDisk заключила с Nanya и многолетнее стратегическое соглашение, в рамках которого тайваньский производитель будет поставлять американской компании DRAM-модули памяти. Также долгосрочное соглашение о поставке DRAM заключила и Kioxia, сославшись на рост бизнеса, связанного с ростом спроса ИИ-проектов на SSD и необходимость обеспечить себе стабильные поставки DRAM-модулей, играющих в твердотельных накопителях вспомогательное значение. Раунд финансирования состоялся вскоре после объявления SK Hynix, в среду заявившей о намерении выйти на IPO в США позже в 2026 году. Компания потенциально поможет привлечь $14 млрд. В марте Sandisk порекомендовала клиентам заключать долгосрочные контракты с предсказуемыми поставками памяти и, похоже, сама следует своим рекомендациям в делах с поставщиками.
16.03.2026 [10:45], Владимир Мироненко
ASIC + GPU: d-Matrix и Gimlet Labs в 10 раз ускорят инференс агентного ИИКомпании d-Matrix и Gimlet Labs сообщили о решении объединить усилия с целью повышения производительности и энергоэффективности инференса для задач агентного ИИ в режиме реального времени. В рамках партнёрства Gimlet интегрирует ускорители d-Matrix Corsair в облако Gimlet Cloud наряду с традиционными GPU. В гибридной архитектуре GPU будут отвечать за ресурсоёмкие этапы инференса, в то время как операции, чувствительные к работе с памятью и задержкам, будут обрабатывать Corsair. Компании сообщили, что совместное решение может обеспечить десятикратное улучшение задержки и пропускной способности на ватт по сравнению с использованием только GPU. Согласно пресс-релизу, решение «идеально подходит для рабочих нагрузок, чувствительных к задержке, включая спекулятивное декодирование, которое часто используется в крупномасштабных развёртываниях ИИ для снижения задержки». Corsair поставляется в виде стандартной карты PCIe с воздушным охлаждением, что позволяет быстро устанавливать решение в ЦОД внутри существующих серверов с GPU без специальных корпусов или нестандартных систем трубопроводов. Сетевые карты d-Matrix Jetstream передают данные между Corsair и GPU посредством стандартного Ethernet, упрощая интеграцию в масштабах инфраструктуры и повышая эффективность использования. 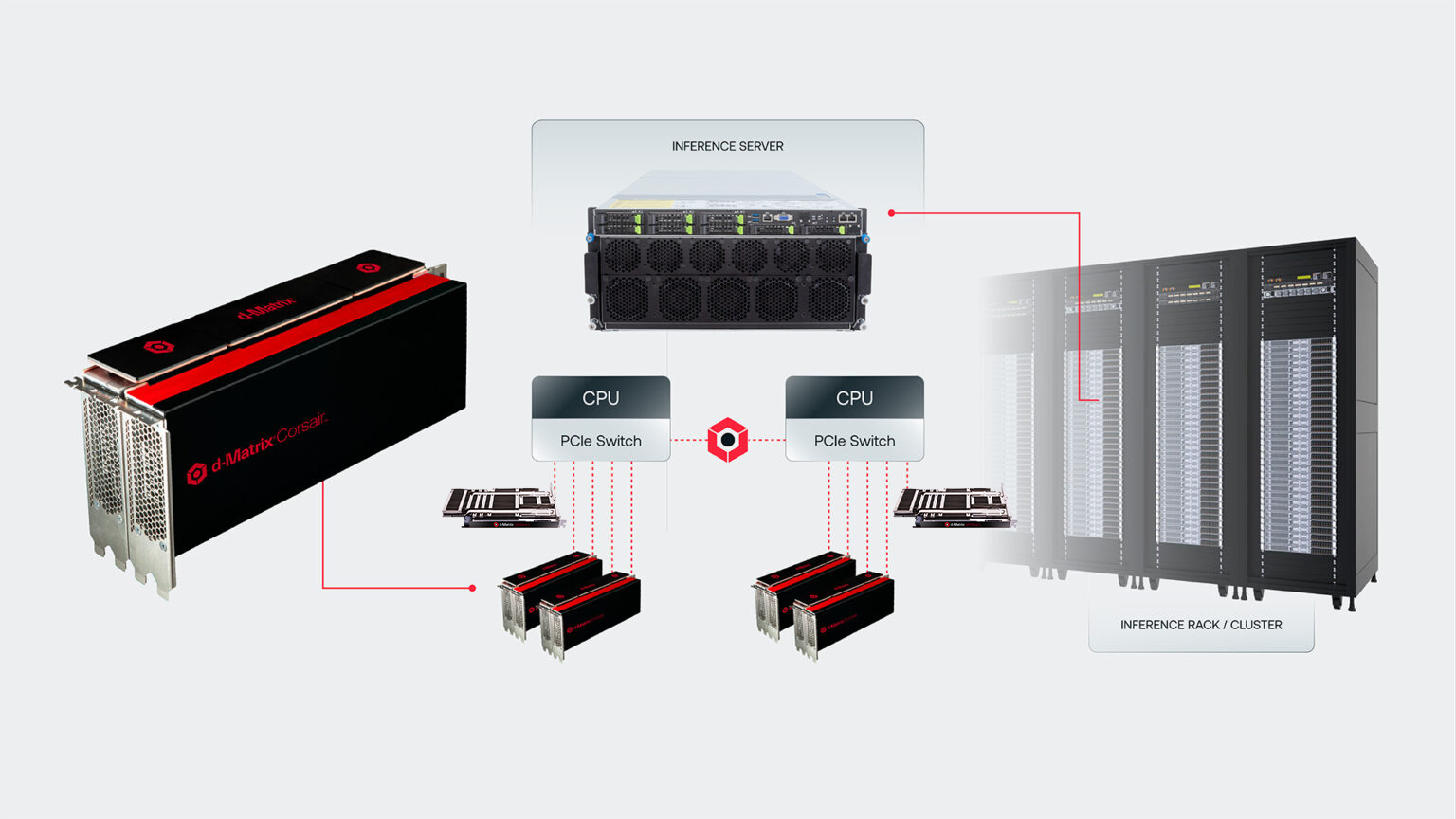
Источник изображения: d-Matrix Заин Асгар (Zain Asgar), сооснователь и генеральный директор Gimlet Labs, заявил, что «аппаратное обеспечение d-Matrix — идеальное решение для тех этапов инференса, на которых GPU тратят энергию впустую». «Используя Corsair для таких сценариев использования, как спекулятивное декодирование, мы можем обеспечить нашим клиентам значительно более высокую производительность при тех же габаритах», — добавил он. Программный стек Gimlet интеллектуально распределяет и сопоставляет рабочие нагрузки агентов между различными ускорителями разных производителей, поколений и архитектур, запуская каждый сегмент на наиболее оптимальном оборудовании. ЦОД Gimlet включают в себя различные типы оборудования и высокоскоростные интерконнекты для обслуживания передовых лабораторий и других компаний, занимающихся разработкой ИИ. Аналитик Мэтт Кимбалл (Matt Kimball) из Moor Insights & Strategy сообщил ресурсу Data Center Knowledge, что ключевым моментом является сочетание специализированного оборудования и программной оркестрации. «Архитектура d-Matrix разработана с учётом эффективности инференса, а не масштабируемости обучения, что соответствует рынку в ходе внедрения приложений ИИ в производство, — сказал Кимбалл. — Но одного оборудования недостаточно — такие платформы, как Gimlet, стремятся упростить развёртывание и легко интегрироваться в существующие рабочие процессы. Именно это делает данное решение привлекательным». Аналитик добавил, что реальная ценность решения заключается в уровне абстракции, который предоставляет Gimlet, позволяя запускать рабочие нагрузки на гетерогенных чипах без переписывания кода. «Рабочие нагрузки в области ИИ становятся всё более гетерогенными, но большая часть инфраструктуры по-прежнему оптимизирована под один тип ускорителя», — отметил он. По его словам, если Gimlet сможет упростить разработчикам развёртывание на нескольких чипах, это обеспечит реальное повышение эффективности системы. «Успешные платформы — это те, которые разработчики могут использовать, не задумываясь об оборудовании», — считает Кимбалл. Компании планируют предоставить своё объединённое решение отдельным клиентам в рамках Gimlet Cloud во II половине 2026 года. Data Center Knowledge отметил, что это также подчёркивает более широкую тенденцию в инфраструктуре ИИ: гетерогенные системы, вероятно, будут доминировать на следующем этапе развёртывания ИИ, и успех будет зависеть как от оркестрации ПО, так и от производительности оборудования. NVIDIA тоже добавил к своим GPU Rubin новые ASIC Groq.
01.03.2026 [18:15], Руслан Авдеев
CPP Investments и Equinix купили за $4 млрд оператора экологичных ИИ ЦОД atNorthКанадский пенсионный фонд Canada Pension Plan Investment Board (CPP Investments) и Equinix анонсировали соглашение о покупке у Partners Group компании atNorth за $4 млрд, специализирующейся на предоставлении колокейшн-площадок для HPC/ИИ-нагрузок и провайдере ЦОД «под ключ», сообщает HPC Wire. Digital Realty, тоже пытавшаяся купить atNorth, осталась не у дел. CPP и Equinix предварительно согласовали финансирование в объёме $4,2 млрд (€3,6 млрд) как для закрытия самой сделки, так и для расширения бизнеса atNorth. CPP Investments намерена вложить около $1,6 млрд, получив долю в 60 % компании, а Equinix — около 40 %. Сообщается, что сразу после закрытия сделка, которая ещё ожидает одобрение регуляторов, окажет положительное действие на скорректированный денежный поток от операционной деятельности (AFFO) Equinix. Сделка укрепляет долговременное сотрудничество между Equinix и CPP Investments — в 2024 году было создано совместное предприятие с сингапурской GIC для расширения портфоли ЦОД xScale. У atNorth есть восемь действующих дата-центров, ещё несколько строятся в Дании, Финляндии, Исландии, Норвегии и Швеции — общий объём портфолио составляет 800 МВт. Кроме того, компания уже зарезервировала поставки 1 ГВт энергии. Некоторые объекты, разработанные для ИИ и HPC, поддерживают жидкостное охлаждение. Также компания активно внедряет возобновляемую энергетику, инициативы по использованию избыточного тепла от оборудования, в том числе для выращивания овощей, и модульный дизайн для минимизации ущерба окружающей среде и продвижению экономики замкнутого цикла. 
Источник изображения: atNorth atNorth заявляет, что компания по-прежнему будет придерживаться работы в северном регионе и продолжит независимую работу под собственным брендом, сохраняя приверженность культуре и ценностям, которые она продвигает. В CPP Investments подчеркнули, что сделка основана на уже имеющемся долгосрочном сотрудничестве с Equinix. Фонд намерен и далее наращивать бизнес в быстрорастущем секторе ЦОД. Equinix подчеркнула, что для клиентов, нуждающихся в надёжном масштабировании, компания предлагает готовую к будущим задачам инфраструктуру с сохранением юридического и информационного суверенитета. Северная Европа укрепляет статус критически важного хаба для следующего этапа цифрового роста. Он имеет сильную и надёжную экономику, активно внедряет инновации, делает ставку на исследования и техническую экспертизу, а также экоустойчивые проекты. Здесь есть много источников возобновляемой энергии и оптимальный для ЦОД климат. Equinix располагает восемью ЦОД на севере Европы: пять в Хельсинки и три в Стокгольме. Всего же в ведении компании есть более 100 объектов в 20 странах. В Европе компания на 100 % компенсирует энергопотребление своих дата-центров за счёт покупок возобновляемой энергии. Это вполне соответствует «зелёному» курсу atNorth и, как ожидается, Equinix добьётся нулевых выбросов к 2040 году.
26.02.2026 [23:11], Владимир Мироненко
AMD инвестирует в Nutanix $250 млн и создаст совместную платформу для агентного ИИAMD и Nutanix объявили о заключении соглашения о многолетнем стратегическом партнёрстве с целью разработки открытой инфраструктурной платформы для корпоративных приложений в области агентного ИИ, первая версия которой должна появиться к концу этого года. В рамках соглашения AMD инвестирует $150 млн в обыкновенные акции Nutanix по цене $36,26/шт. и предоставит до $100 млн дополнительного финансирования для совместных инженерных и маркетинговых инициатив, а также сотрудничества в области выхода на рынок с целью ускорения внедрения совместной платформы агентного ИИ. Ожидается, что сделка по инвестиции в акционерный капитал будет завершена во II квартале 2026 года после получения необходимых разрешений регулирующих органов. Совместно разработанная платформа агентного ИИ предназначена для обеспечения ускорения инференса на базе ускорителей Instinct и процессоров EPYC, HPC и оркестрации с использованием EPYC, а также унифицированного управления жизненным циклом с помощью Nutanix Enterprise AI, что позволит развёртывать открытые и коммерческие ИИ-модели без зависимости от вертикально интегрированных стеков ИИ. В рамках сделки Nutanix также интегрирует ПО AMD ROCm и Enterprise AI в свою облачную платформу Nutanix Cloud и платформу Nutanix Kubernetes, отметил ресурс SiliconANGLE. 
Источник изображения: AMD В настоящее время Nutanix поддерживает только ускорители NVIDIA. Благодаря этой сделке Nutanix будет поддерживать и ускорители AMD, что, как ожидается, позволит AMD расширить круг клиентов. «Наша цель — предоставить клиентам выбор, — заявил глава Nutanix Раджив Рамасвами (Rajiv Ramaswami) изданию The Register. — NVIDIA — лидер рынка, а AMD — ещё одна крупная компания, владеющая платформой». О сделке было объявлено после того, как Nutanix сообщила о финансовых результатах за II квартал 2026 финансового года. Выручка компании выросла год к году на 10 % до $723 млн. Скорректированная прибыль на акцию составила 56¢. Оба показателя превысили прогнозы аналитиков, ожидавших $710,35 млн выручки и 44¢ на акцию скорректированной прибыли. Высокие показатели были достигнуты благодаря росту клиентской базы: годовой доход от регулярных платежей по состоянию на конец января составил $2,36 млрд, что на 16 % больше, чем годом ранее. Рамасвами сообщил, что за прошедший квартал компания заключила 1000 новых контрактов с клиентами, и большинство из них намерены перейти с VMware на Nutanix. Вместе с тем дефицит в цепочках поставок процессоров и комплектующих, включая память и накопители, привёл к тому, что компания снизила свой прогноз на весь год с $2,82–$2,86 млрд до $2,80–$2,84 млрд. После объявления о сделке AMD и Nutanix акции Nutanix выросли в цене на 15 %.
17.02.2026 [11:08], Сергей Карасёв
SK hynix предлагает гибридную память HBM/HBF для ускорения ИИ-инференсаКомпания SK hynix, по сообщению ресурса Blocks & Files, разработала концепцию гибридной памяти, объединяющей на одном интерпозере HBM (High Bandwidth Memory) и флеш-чипы с высокой пропускной способностью HBF (High Bandwidth Flash). Предполагается, что такое решение будет подключаться к GPU для повышения скорости ИИ-инференса. Современные ИИ-ускорители на основе GPU оснащаются высокопроизводительной памятью HBM. Однако существуют ограничения по её ёмкости, из-за чего операции инференса замедляются, поскольку доступ к данным приходится осуществлять с использованием более медленных SSD. Решить проблему SK hynix предлагает путём применения гибридной конструкции HBM/HBF под названием H3. Архитектура HBF предусматривает монтаж кристаллов NAND друг над другом поверх логического кристалла. Вся эта связка располагается на интерпозере рядом с контроллером памяти, а также GPU, CPU, TPU или SoC — в зависимости от предназначения конечного изделия. В случае H3 на интерпозере будет дополнительно размещён стек HBM. Отмечается, что время доступа к HBF больше, чем к HBM, но вместе с тем значительно меньше, нежели к традиционным SSD. Таким образом, HBF может служить в качестве быстрого кеша большого объёма. 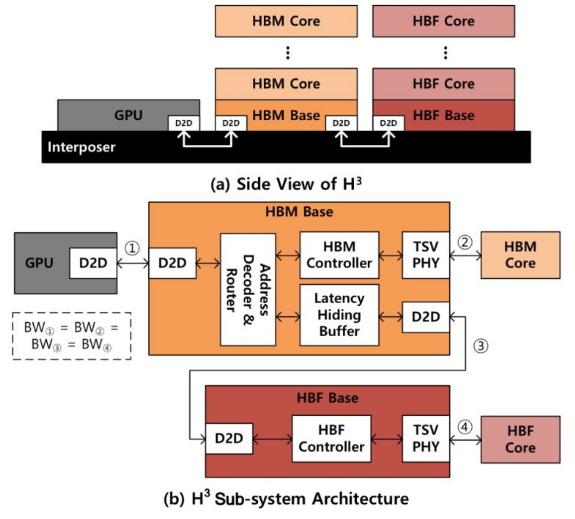
Источник изображения: SK hynix По заявлениям SK hynix, стеки HBF могут иметь до 16 раз более высокую ёмкость по сравнению с HBM, обеспечивая при этом сопоставимую пропускную способность. С другой стороны, HBF обладает меньшей износостойкостью при записи, до 4 раз более высоким энергопотреблением и большим временем доступа. HBF выдерживает около 100 тыс. циклов записи, а поэтому лучше всего подходит для рабочих нагрузок с интенсивным чтением. В результате, как утверждается, гибридная конструкция сможет эффективно решать задачи инференса при использовании больших языковых моделей (LLM) с огромным количеством параметров. В ходе моделирования работы H3, проведенного специалистами SK hynix, рассматривался ускоритель NVIDIA Blackwell B200 с восемью стеками HBM3E и таким же количеством стеков HBF. В пересчете на токены в секунду производительность системы с памятью H3 оказалась в 1,25 раза выше при использовании 1 млн токенов и в 6,14 раза больше при использовании 10 млн токенов по сравнению с решениями, оборудованными только чипами HBM. Более того отмечено 2,69-кратное повышение производительности в расчёте на 1 Вт затрачиваемой энергии по сравнению с конфигурациями без HBF. К тому же связка HBM и HBF может обрабатывать в 18,8 раз больше одновременных запросов, чем только HBM.
10.02.2026 [16:42], Руслан Авдеев
В погоне за цифровым суверенитетом десятки стран обратились к открытому протоколу MatrixНа фоне растущего запроса на достижение цифрового суверенитета, открытый коммуникационный протокол Matrix получил второе дыхание и сегодня всё более востребован, сообщает The Register. Проект Matrix (и его коммерческое подразделение Element) существует многие годы. В 2014 году подразделение Matrix отделилось от телеком-провайдера Amdocs. В рамках Matrix действует некоммерческий фонд Matrix.org, стоящий за протоколом Matrix, а также отвечающая за клиентское приложение Element (ранее Vector и, позже, Riot). Коммерческое предприятие Element.io представляет не только клиентское ПО, но и серверное ПО, совместимое с протоколом Matrix. Помимо бесплатных версий с открытым кодом предлагаются коммерческие варианты Element Pro и Element Server Suite Pro. Matrix — открытый протокол, поэтому его используют многие сторонние приложения, поэтому нет необходимости использовать исключительно приложения Element для общения. По данным The Register, на фоне роста спроса ЕС на цифровой суверенитет, дела у Matrix идут весьма хорошо и, по словам одного из учредителей, «интерес растёт». Сегодня Matrix ведёт переговоры приблизительно с 35 странами о создании инфраструктуры связи на базе open source решений, причём инициативу, по словам разработчиков, поддерживает и ООН. Сообщается, что организация использовала Matrix в качестве основы для собственного решения для связи, независимого от любых стран и хостинг-провайдеров. 
Источник изображения: Element Протокол используется и Международным уголовным судом (МУС), активно пытающимся отказаться от инструментов американского происхождения после того, как США ввели санкции против его членов, нарушившие работу электронной почты и др. МУС переходит на пакет OpenDesk вместо Microsoft Office, а в самом пакете есть Element. За внедрение отвечает немецкая ZenDiS (Zentrum für Digitale Souveränität der Öffentlichen Verwaltung — Центр цифрового суверенитета государственного управления). Протокол продвигается и в других странах, в многочисленных организациях Евросоюза. На мероприятии Ubuntu Summit в 2024 году анонсирована версия протокола Matrix 2.0, а официально её представили в конце того же года. Среди новых функций — ускоренная синхронизация и запуск клиента, многопользовательский видео- или VoIP-чат через Element Call. Хотя официальную спецификацию ещё не публиковали, новая версия протокола уже используется. Например, по умолчанию современным мобильным клиентом для Matrix 2.0 является Element X. Отличительная особенность протокола в том, что очень многие используют его, даже не слышав о нём, поскольку протокол интегрирован в инструменты и приложения с другими именами. Хотя технология, возможно, так и останется нишевой в сравнении с решениями крупных компаний с большими рекламными бюджетами, но это не означает, что она не имеет значения.
08.02.2026 [17:00], Владимир Мироненко
Из-за ИИ и так дефицитная SLC NAND подорожает на 400–500 %В связи с продолжающимся усовершенствованием ИИ-серверов и коммутаторов объём NOR-памяти на одну единицу такой продукции, как ожидают аналитики DigiTimes, вырастет в несколько раз на фоне прогнозируемого дефицита высокопроизводительных компонентов. Согласно прогнозу DigiTimes, во II квартале 2026 года цены на NOR Flash вырастут последовательно на 40–50 %, причем по некоторым позициям клиенты будут готовы платить надбавки, чтобы гарантировать поставки в рамках контрактов. Что касается памяти SLC NAND и MLC NAND, то здесь ожидается ещё более значительный рост цен — на 400–500 % во II квартале в годовом исчислении, что побудит тайваньского производителя Winbond Electronics ускорить расширение мощностей по производству SLC NAND. Winbond выпускает NOR-память для ИИ-серверов и сетевых приложений с использованием 58-нм техпроцесса, в то время как память для носимых устройств, таких как Bluetooth-гарнитуры, производится по 45-нм техпроцессу. DigiTimes отметил, что более сложный дизайн NVIDIA GB300 по сравнению с GB200 с большим объёмом памяти и более высокими требованиями к её спецификациям обусловил рост спроса на модули NOR ёмкостью 512 Мбайт и 1 Гбайт. Но запасы модули NOR-памяти большой ёмкости остаются относительно ограниченными. По данным источников, цены на NOR-флеш выросли в I квартале 2026 года примерно на 30 %, а на некоторые позиции — на 50 %. Хотя масштабы повышения цен менее значительны, чем в категории DDR4, предложение NOR остаётся ограниченным, и ожидается, что контрактные цены неё во II квартале вырастут ещё на 40–50 %, а сроки поставки специальных вариантов увеличатся до 12–14 недель. 
Источник изображения: Winbond Тайваньский производитель Macronix тоже утверждает, что продолжающийся рост выпуска серверов для ИИ-нагрузок создаёт структурную напряжённость на рынке NOR, которую будет сложно преодолеть в краткосрочной перспективе. Уход крупных производителей NAND-памяти с рынков SLC NAND и MLC NAND ещё больше подстегнул дефицит и позволил Winbond и Macronix выступать на рынке в качестве основных поставщиков. Цены Macronix на MLC eMMC недавно выросли вдвое по сравнению с декабрём 2025 года. Несмотря на авансовые платежи, внесённые ранее в этом году, клиентам не обеспечили поставки до китайского Нового года, что сделало эту продукцию крайне дефицитной на нишевых рынках, пишет DigiTimes. Доля в выручке Macronix от памяти NAND (включая eMMC) выросла до 21 %, более чем вдвое превысив уровень прошлого года. Контрактные цены Winbond на память SLC NAND во II квартале 2026 года, как ожидается, резко вырастут по сравнению с аналогичным периодом 2025 года — до 400–500 %. Цены Winbond на SLC NAND в I квартале выросли больше всего в её портфолио, превысив рост цен на DDR4. Компания планирует расширение своих мощностей по производству памяти. В частности, будут запущены производственные линии по выпуску DRAM на заводе в Гаосюне (Gāoxióng). Сообщается, что мощность завода компании в Тайчжуне (Táizhōng) составляет примерно 58 тыс. пластин в месяц, включая приблизительно 25 тыс. пластин для NOR, 15 тыс. пластин для NAND и 10 тыс. пластин для DRAM. Ожидается значительное увеличение общего объёма производства до примерно 50 тыс. пластин памяти NOR и SLC NAND с более высокой рентабельностью. 
Источник изображения: Macronix Согласно данным Winbond, на SLC NAND, производимую по 46-нм и 32-нм техпроцессам, приходится около 15–25 % выручки. Её доля в выручке компании будет расти по мере роста цен, что приведет к сокращению мощностей, выделенных на производство DRAM по устаревшим техпроцессам. Цены на флеш-память, изготовленную по традиционным технологиям, стремительно растут, а спрос на NOR-память большой ёмкости увеличился в несколько раз. По данным источников DigiTimes, Winbond, увеличившая объёмы поставок, недавно завершила согласование цен по контрактам на I квартал 2026 года. Ожидается, что рост цен на DRAM, начавшийся в IV квартале 2025 года, продолжится и во II квартале 2026 года, что ознаменует собой третий подряд квартал роста и фактически удвоение контрактных цен в годовом исчислении. Также сообщается, что новые производственные мощности Winbond, запланированные к вводу в эксплуатацию в 2027 году, уже полностью забронированы. Глава Winbond сообщил о резко увеличившемся количестве запросов от клиентов, что создало дефицит предложения и затрудняет удовлетворение всех их потребностей. Помимо прямых клиентов первого уровня, владельцы брендов второго уровня и операторы третьего уровня всё чаще обходят посредников и ведут переговоры напрямую с Winbond, что отражает высокий рыночный спрос, отметил DigiTimes.
28.01.2026 [23:51], Владимир Мироненко
SK hynix создала на базе Solidigm американскую «дочку» для инвестиций в ИИ-решенияЮжнокорейская компания SK hynix объявила о создании в США новой компании, специализирующейся на решениях в сфере ИИ с предварительным названием AI Company (AI Co.). Новая компания будет сформирована путём реструктуризации Solidigm (SK hynix NAND Product Solutions Corp.), калифорнийской «дочки» SK hynix по производству SSD корпоративного класса, образованной в 2021 году в результате покупки NAND-бизнеса Intel за $9 млрд. При этом её бизнес-операции будут переданы новой дочерней компании, которая будет называться Solidigm Inc., «для обеспечения преемственности бренда». Новая структура призвана укрепить конкурентоспособность SK hynix в области технологий памяти для ИИ-платформ, включая высокоскоростную память (HBM). Компания заявила, что эта инициатива знаменует собой переход от традиционной роли производителя памяти к роли ключевого партнёра в решениях для ИИ ЦОД. Полученные в этой роли возможности будут объединены для создания синергии с дочерними компаниями и филиалами SK Group. SK hynix отметила, что благодаря своему бизнесу по производству SSD корпоративного класса, Solidigm уже является ключевым игроком в экосистеме ИИ ЦОД. Включение Solidigm в состав AI Company направлено на поиск возможностей для сотрудничества и развития бизнеса, которые могут создать синергию с различными направлениями бизнеса в ИИ-индустрии. 
Источник изображений: SK hynix Официальное название AI Company будет объявлено в феврале. Сначала будет сформирована временная управленческая команда и совет директоров, после чего запланирован переход к постоянной управленческой группе, состоящей из местных экспертов с глубокими знаниями рынка США. Для обеспечения первоначального финансирования SK hynix инвестирует в AI Company $10 млрд. Причём эта сумма будет структурирована как резерв на привлечение капитала, в рамках которого средства будут использоваться по запросу AI Co. для финансирования инвестиций. SK hynix планирует осуществлять через AI Co. стратегические инвестиции в ИИ-компании и расширять сотрудничество с американскими новаторами в сфере ИИ. SK hynix стремится укрепить своё лидерство в области производства памяти, одновременно развивая возможности решений по всей цепочке создания стоимости в ИИ ЦОД, поскольку растёт спрос на оптимизацию на системном уровне для решения проблем с узкими местами в передаче данных, отметил ресурс Korea IT Times. Первоначально SK hynix планирует сосредоточиться на ПО для оптимизации ИИ-систем, а затем постепенно расширять инвестиции в экосистему ИИ ЦОД.  Недавно сообщалось о том, что SK hynix на три месяца ускорила график запуск завода по производству микросхем в южнокорейском Йонъине (Yongin), поскольку компания вкладывает большие деньги в освоение ИИ-волны. На поставках для ЦОД можно заработать ещё больше, поскольку, по крайней мере в краткосрочной перспективе, это создало дефицит памяти в потребительском секторе, отметил ресурс Hothardware. Также в этом месяце стало известно, что SK hynix инвестирует ₩19 трлн ($12,9 млрд) в строительство нового завода по упаковке и тестированию чипов для ИИ-технологий в Чхонджу (Cheongju). Планы по созданию нового предприятия в США также соответствуют политике США, стимулирующей размещение производства в стране с помощью регулирования пошлин на поставки извне. SK hynix уже строит в Индиане научно-исследовательский центр по производству современных микросхем и их упаковке стоимостью $3,87 млрд, о котором было объявлено ещё в 2024 году. Завод будет производить HBM для ИИ-ускорителей, начало его работы запланировано на 2028 год, пишет ресурс CNBC. |
|

