Материалы по тегу: hpc
|
09.12.2024 [20:17], Руслан Авдеев
Канада потратит $2 млрд на ИИ ЦОД и суперкомпьютерыМинистр инноваций, науки и промышленности Канады Франсуа-Филипп Шампань (François-Philippe Champagne) официально заявил о старте реализации Канадской стратегии суверенных ИИ-вычислений (Canadian Sovereign AI Compute Strategy). Она предусматривает выделение до $2 млрд, сообщает HPC Wire. Предполагается, что стратегия будет способствовать достижению трёх ключевых целей:
Публичные консультации, посвящённые стратегии, проводились летом 2024 года. Были получены отзывы от более чем 1 тыс. заинтересованных сторон, в том числе от представителей науки, промышленности, общественности и др. Кроме того, власти страны приняли ряд мер по ответственному созданию и внедрению ИИ в экономику Канады, сформировав Канадский институт безопасности ИИ, подготовив Закон об искусственном интеллекте и данных (законопроект C-27) и предложив Добровольный кодекс ответственной разработки и управления передовыми системами генеративного ИИ. 
Источник изображения: Marc-Olivier Jodoin/unsplash.com Все $2 млрд выделят из государственного бюджета 2024 года в рамках стратегии, удовлетворяющей кратко-, средне- и долгосрочные потребностям исследователей и разработчиков в ИИ-вычислениях. До $700 млн получат представители промышленности, академических кругов и бизнеса, занимающиеся созданием канадских ИИ ЦОД. Среди заявок на финансирование приоритет будет отдаваться высокомаржинальным проектам. До $1 млрд выделят на создание суверенной суперкомпьютерной инфраструктуры, а также безопасного ЦОД. До $300 млн выделят в Фонд доступа к ИИ-вычислениям, более подробная информация котором появится после официального старта программы весной 2025 года. В 2022–2023 гг. количество специалистов в стране выросло на 29 %, достигнув 140 тыс., причём по скорости прироста Канада занимает первое место среди стран «Большой семёрки» (G7). В Канаде работают 10 % ведущих мировых исследователей систем искусственного интеллекта. С 2019 года она также занимет первое место среди стран G7 по количеству посвящённых ИИ научных статей на душу населения. А количество поданных канадскими изобретателями патентов в области ИИ в 2022–2023 гг. увеличилось на 57 %.
08.12.2024 [23:32], Сергей Карасёв
Юлихский суперкомпьютерный центр получил 100-кубитный квантовый компьютер PasqalКомпания Pasqal поставила в Юлихский суперкомпьютерный центр в Германии (JSC) 100-кубитный квантовый компьютер на нейтральных атомах. Установка системы выполнена в рамках проекта HPCQS, реализуемого Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU). Инициатива HPCQS (High Performance Computer and Quantum Simulator hybrid) нацелена на интеграцию квантовых систем с европейской инфраструктурой суперкомпьютеров. Это, как ожидается, позволит создать мощную вычислительную платформу для решения сложных задач в различных областях, таких как здравоохранение, энергетика, автомобилестроение, финансы, торговля и кибербезопасность. 
Источник изображения: Pasqal Проект HPCQS поддерживается предприятием EuroHPC JU и шестью европейскими странами — Австрией, Францией, Германией, Ирландией, Италией и Испанией. Новая система станет частью Унифицированной инфраструктуры квантовых вычислений Юлиха (Jülich UNified Infrastructure for Quantum Computing, JUNIQ). Система Pasqal использует нейтральные атомы для формирования кубитов. Такие атомы не имеют электрического заряда, благодаря чему слабо взаимодействуют с внешними электромагнитными полями — это позволяет улучшить стабильность. Атомы захватываются и манипулируются с помощью лазера, что даёт возможность проводить высокоточные квантовые операции. Кроме того, системы на базе нейтральных атомов относительно просто масштабируются. В JSC комплекс Pasqal будет сопряжён с суперкомпьютером JURECA DC. Квантовый компьютер планируется применять для выполнения сложного моделирования в физике и химии, а также для квантового машинного обучения. Нужно отметить, что весной нынешнего года JSC получил 5-кубитную систему Spark немецко-финского производителя IQM Quantum Computers. Кроме того, ранее консорциум EuroHPC объявило о планах по созданию двух дополнительных квантовых компьютеров.
06.12.2024 [17:05], Владимир Мироненко
xAI получил ещё $6 млрд инвестиций и приступил к расширению ИИ-кластера Colossus до 1 млн ускорителейСтартап xAI, курируемый Илоном Маском (Elon Musk), планирует на порядок расширить свой ИИ-кластер Colossus в Мемфисе (Теннесси, США), включающий в настоящее время 100 тыс. NVIDIA H100. Как пишет HPCwire, об этом заявил Брент Майо (Brent Mayo), старший менеджер xAI по строительству объектов и инфраструктуры. По словам Майо, стартап уже приступил к работам по расширению ИИ-кластера до не менее чем 1 млн ускорителей совместно с NVIDIA, Dell и Supermicro. Для содействия проекту xAI была создана оперативная группа под руководством главы Торговой палаты Мемфиса Теда Таунсенда (Ted Townsend), готовая оказать помощь в решении проблем в любое время суток. Проект знаменует собой крупнейшее капиталовложение в истории региона. Заявление о старте работ над расширением ИИ-кластера последовало после появления сообщений о том, что xAI удалось привлечь ещё $6 млрд инвестиций. Новые вливания могут увеличить оценку рыночной стоимости стартапа до $50 млрд. Точные цифры будут объявлены немного позже. 
Источник изображения: Supermicro Colossus используется для обучения моделей ИИ для чат-бота Grok, разработанного xAI, который уступает по возможностям и аудитории лидеру рынка OpenAI ChatGPT, а также Google Gemini. Стартап выпустил свою первую большую языковую модель Grok-1 в конце 2023 года, в апреле 2024 года вышла модель Grok-1.5, а Grok-2 — в августе. Colossus был построен в рекордные сроки — всего за три месяца. Гендиректор NVIDIA, Дженсен Хуанг (Jensen Huang), заявил, что «в мире есть только один человек, который мог бы это сделать». Хуанг назвал Colossus «несомненно самым быстрым суперкомпьютером на планете, если рассматривать его как один кластер», отметив, что ЦОД такого размера обычно строится три года. Активисты из числа жителей Мемфиса раскритиковали проект из-за повышенной нагрузки на местные энергосети и требований, которые ИИ-кластер предъявляет к региональной энергосистеме. «Мы не просто лидируем; мы ускоряем прогресс беспрецедентными темпами, обеспечивая при этом стабильность энергосети, используя Megapack», — заявил в ответ Брент Майо на мероприятии в Мемфисе, пишет Financial Times.
06.12.2024 [16:42], Сергей Карасёв
iGenius анонсировала Colosseum — один из мощнейших в мире ИИ-суперкомпьютеров на базе NVIDIA DGX GB200 SuperPodКомпания iGenius, специализирующаяся на ИИ-моделях для отраслей со строгим регулированием, анонсировала вычислительную платформу Colosseum. Это, как утверждается, один из самых мощных в мире ИИ-суперкомпьютеров на платформе NVIDIA DGX SuperPOD с тысячами ускорителей GB200 (Blackwell). Известно, что комплекс Colosseum располагается в Европе. Полностью характеристики суперкомпьютера не раскрываются. Отмечается, что он обеспечивает производительность до 115 Эфлопс на операциях ИИ (FP4 с разреженностью). Говорится о применении передовой системы жидкостного охлаждения. Для питания используется энергия из возобновляемых источников в Италии. По информации Reuters, в состав Colosseum войдут около 80 суперускорителей GB200 NVL72. Таким образом, общее количество ускорителей Blackwell достигает 5760. Общее энергопотребление системы должно составить почти 10 МВт. Стоимость проекта не называется. Но глава iGenius Ульян Шарка (Uljan Sharka) отмечает, что компания в течение 2024 года привлекла на развитие примерно €650 млн и намерена получить дополнительное финансирование для проекта Colosseum. При этом подчёркивается, что iGenius — один из немногих стартапов в области ИИ в Европе, капитализация которого превышает $1 млрд. 
Источник изображения: iGenius iGenius планирует применять Colosseum для ресурсоёмких приложений ИИ, включая обучение больших языковых моделей (LLM) с триллионом параметров, а также работу с открытыми моделями генеративного ИИ. Подчёркивается, что создание Colosseum станет основой для следующего этапа сотрудничества между iGenius и NVIDIA в области ИИ для поддержки задач, требующих максимальной безопасности данных, надёжности и точности: это может быть финансовый консалтинг, обслуживание пациентов в системе здравоохранения, государственное планирование и пр. Модели iGenius AI, созданные с использованием платформы NVIDIA AI Enterprise, NVIDIA Nemotron и фреймворка NVIDIA NeMo, будут предлагаться в виде микросервисов NVIDIA NIM. По заявлениям iGenius, Colosseum поможет удовлетворить растущие потребности в ИИ-вычислениях. Colosseum также будет служить неким хабом, объединяющим предприятия, академические учреждения и государственные структуры. Нужно отметить, что около месяца назад компания DeepL, специализирующаяся на разработке средств автоматического перевода на основе ИИ, объявила о намерении развернуть платформу на базе NVIDIA DGX GB200 SuperPod в Швеции. DeepL будет применять этот комплекс для исследовательских задач, в частности, для разработки передовых ИИ-моделей.
05.12.2024 [16:14], Сергей Карасёв
Запущен британский Arm-суперкомпьютер Isambard 3 с суперчипами NVIDIA GraceВ Великобритании введён в эксплуатацию суперкомпьютер Isambard 3, предназначенный для ресурсоёмких приложений ИИ и задач НРС. Реализация проекта обошлась приблизительно в £10 млн, или примерно $12,7 млн. Машина пришла на смену комплексу Isambard 2, который отправился на покой в сентябре нынешнего года. Система Isambard 3 создана в рамках сотрудничества между исследовательским консорциумом GW4 Alliance, в который входят университеты Бата, Бристоля, Кардиффа и Эксетера, а также компаниями HPE, NVIDIA и Arm. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля, внесшего значимый вклад в Промышленную революцию. Полностью технические характеристики Isambard 3 не раскрываются. Известно, что в основу машины положены 384 суперпроцессорами NVIDIA Grace со 144 ядрами (2 × 72) Arm Neoverse V2 (Demeter), общее количество которых превышает 55 тыс. Задействована высокопроизводительная СХД HPE, которая обеспечивает расширенные IO-возможности с интеллектуальным распределением данных по нескольким уровням. Благодаря этому достигается эффективная обработка задач с интенсивным использованием информации, таких как обучение моделей ИИ. Известно также, что в составе комплекса применяется фирменный интерконнект HPE Slingshot, а в качестве внутреннего интерконнекта служит технология NVLink-C2C, которая в семь раз быстрее PCIe 5.0. Каждый узел суперкомпьютера содержит один суперчип Grace и сетевой адаптер Cassini с пропускной способностью до 200 Гбит/с. Объём системной памяти составляет 2 × 120 Гбайт (240 Гбайт). 
Источник изображения: GW4 Отмечается, что Isambard 3 демонстрирует в шесть раз более высокую производительность и в шесть раз лучшую энергоэффективность по сравнению с Isambard 2. Пиковое быстродействие FP64 у Isambard 3 достигает 2,7 Пфлопс при энергопотреблении менее 270 кВт. Применять новый суперкомпьютер планируется для таких задач, как проектирование оптимальной конфигурации ветряных электростанций на суше и воде, моделирование термоядерных реакторов, исследования в сфере здравоохранения и пр. Суперкомпьютер расположен в автономном дата-центре с системой самоохлаждения HPE Performance Optimized Data Center (POD) в Национальном центре композитов в Научном парке Бристоля и Бата. Там же ведётся монтаж ИИ-комплекса Isambard-AI стоимостью £225 млн ($286 млн), который должен стать самым быстрым и мощным суперкомпьютером в Великобритании. Проект Isambard-AI реализуется в несколько этапов. Первая фаза предполагает монтаж 42 узлов, каждый из которых несёт на борту четыре суперчипа NVIDIA GH200 Grace Hopper и 4 × 120 Гбайт памяти для CPU (доступно 460 Гбайт — по 115 Гбайт на CPU), а также 4 × 96 Гбайт памяти для GPU (H100). В ходе второй фазы будут добавлены 1320 узлов, насчитывающих в сумме 5280 суперчипов NVIDIA GH200 Grace Hopper. Кроме того, в состав Isambard 3 входит экспериментальный x86-модуль MACS (Multi-Architecture Comparison System), включающий сразу восемь разновидностей узлов на базе процессоров AMD EPYC и Intel Xeon нескольких поколений, часть из них также имеет ускорители AMD Instinct MI100 и NVIDIA H100/A100. Все они объединены 200G-интерконнектом HPE Slingshot.
03.12.2024 [10:00], Сергей Карасёв
Астрофизики Японии получили суперкомпьютер Aterui III на базе Intel Xeon MaxЦентр вычислительной астрофизики Национальной астрономической обсерватории Японии (NAOJ) объявил о вводе в эксплуатацию суперкомпьютера NS-06 Aterui III на платформе HPE Cray XD2000. Новый НРС-комплекс планируется применять в качестве «лаборатории теоретической астрономии» для исследования широкого спектра астрофизических явлений. Архитектура Aterui III предполагает применение модулей двух типов — System M с высокой пропускной способностью памяти (3,2 Тбайт/с на узел, что в 12,5 раза больше, чем у Aterui II) и System P с большим объёмом памяти (512 Гбайт в расчёте на узел, в 1,3 раза больше по сравнению с Aterui II). Все узлы оснащены двумя процессорами Intel Xeon Sapphire Rapids. В частности, задействованы 208 узлов System M с чипами Xeon CPU Max 9480 (56C/112T; 1,9–3,5 ГГц; 350 Вт). Таким образом, суммарное количество ядер достигает 23 296. Каждый узел несёт на борту 128 Гбайт памяти, а её совокупный объём составляет 26,6 Тбайт. Общая пропускная способность — 665 Тбайт/с. 
Источник изображения: NAOJ Кроме того, в состав Aterui III включены 80 узлов System P с парой процессоров Xeon Platinum 8480+ (56C/112T; 2,0–3,8 ГГц; 350 Вт). В общей сложности применяются 8960 ядер и 40,96 Тбайт памяти с суммарной пропускной способностью 98,24 Тбайт/с (614 Гбайт/с на узел). В целом, суперкомпьютер использует 288 узлов с 32 256 ядрами CPU. Кластер на базе System M обеспечивает производительность на уровне 1,4 Пфлопс, сегмент на основе System P — около 0,57 Пфлопс. Общее быстродействие НРС-комплекса достигает почти 2 Пфлопс.
02.12.2024 [11:39], Сергей Карасёв
Один из модулей будущего европейского экзафлопсного суперкомпьютера JUPITER вошёл в двадцатку самых мощных систем мираЮлихский исследовательский центр (FZJ) в Германии объявил о достижении важного рубежа в рамках проекта JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) по созданию европейского экзафлопсного суперкомпьютера. Введён в эксплуатацию JETI — второй модуль этого НРС-комплекса. Напомним, контракт на создание JUPITER заключён между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (подразделение Atos) и ParTec. Суперкомпьютер JUPITER создаётся на базе модульного дата-центра, за строительство которого отвечает Eviden. Система JUPITER получит, в частности, энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1 с HBM. Кроме того, в состав машины входят узлы с NVIDIA Quad GH200, а общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Узлы объединены интерконнектом NVIDIA Mellanox InfiniBand. Запущенный модуль JETI (JUPITER Exascale Transition Instrument) обладает FP64-производительностью 83,14 Пфлопс, тогда как пиковый теоретический показатель достигает 95 Пфлопс. С такими результатами эта машина попала на 18-ю строку нынешнего рейтинга мощнейших суперкомпьютеров мира TOP500. В составе JETI задействованы в общей сложности 391 680 ядер. Энергопотребление модуля равно 1,31 МВт. Отмечается, что JETI обеспечивает примерно одну двенадцатую от общей расчётной производительности машины JUPITER. Попутно JETI занял шестое место в рейтинге энергоэффективных систем Green500. 
Источник изображения: Eviden Ожидается, что после завершения строительства суммарное быстродействие JUPITER на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность превысит 1 Эфлопс. Затраты на создание комплекса оцениваются в €273 млн, включая доставку, установку и обслуживание НРС-системы.
29.11.2024 [10:15], Сергей Карасёв
Система Cerebras с ускорителями WSE установила рекорд в молекулярной динамике, превзойдя суперкомпьютер FrontierАмериканский стартап Cerebras Systems, специализирующийся на создании чипов для систем машинного обучения и других ресурсоёмких задач, объявил об установлении нового мирового рекорда производительности в области молекулярной динамики. В эксперименте приняли участие Сандийские национальные лаборатории (SNL), Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе Министерства энергетики США (DOE). Вычисления выполнялись на системе, оснащённой фирменными ускорителями Cerebras Wafer Scale Engine (WSE). Говорится, что впервые в истории молекулярной динамики исследователи достигли результата более 1 млн шагов моделирования в секунду (timesteps per second, TPS). В частности, показано значение на уровне 1,1 млн TPS на платформе Cerebras CS-2, оборудованной чипами WSE-2, которые насчитывают 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Для сравнения: в случае суперкомпьютера экзафлопсного класса Frontier, который в нынешнем рейтинге TOP500 занимает второе место, результат составляет 1470 TPS. Таким образом, система Cerebras обеспечивает 748-кратный выигрыш в быстродействии на задачах молекулярной динамики. При этом энергопотребление комплекса Cerebras составляет 27 кВт против 21 МВт у Frontier. 
Источник изображения: Cerebras Кроме того, комплекс Cerebras превзошел Anton 3 — самый мощный в мире специализированный суперкомпьютер для молекулярной динамики. Anton 3 использует 512 кастомных ASIC, а его энергопотребление находится на уровне 400 кВт. Показатель быстродействия Anton 3 достигает 980 тыс. TPS. То есть, система Cerebras показывает выигрыш примерно в 20 %. Предполагается, что ускорители Cerebras предоставят качественно новые возможности для исследований в различных областях, включая разработку материалов следующего поколения, перспективных лекарственных препаратов и решений в сфере возобновляемой энергетики. Нужно отметить, что ранее Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на чипах Cerebras WSE-3. А сама компания Cerebras развернула «самую мощную в мире» ИИ-платформу для инференса.
27.11.2024 [17:31], Владимир Мироненко
Китайцы создали Ethernet для ИИ- и HPC-кластеровНа прошлой неделе китайские технологические гиганты объявили о выпуске чипа для поддержки технологии Global Scheduling Ethernet, предназначенной для сетевого протокола, который должен обеспечить запуск приложений ИИ и других требовательных рабочих нагрузок, сообщил ресурс The Register. Как полагает ресурс, China Mobile является движущей силой этой технологии, поскольку ещё в 2023 году она опубликовала описание технической структуры GSE Ethernet. Цель китайского проекта совпадает с задачей, поставленной консорциумом Ultra Ethernet Consortium (UEC) — оптимизировать Ethernet для приложений ИИ и HPC. В UEC входят Intel, AMD, HPE, Arista, Broadcom, Cisco, Meta✴ и Microsoft. Протокол Ethernet создавался без учёта сегодняшних рабочих нагрузок и при его использовании сложно организовать пути для трафика, перемещающегося по очень большим и загруженным сетям, что приводит к высоким задержкам. 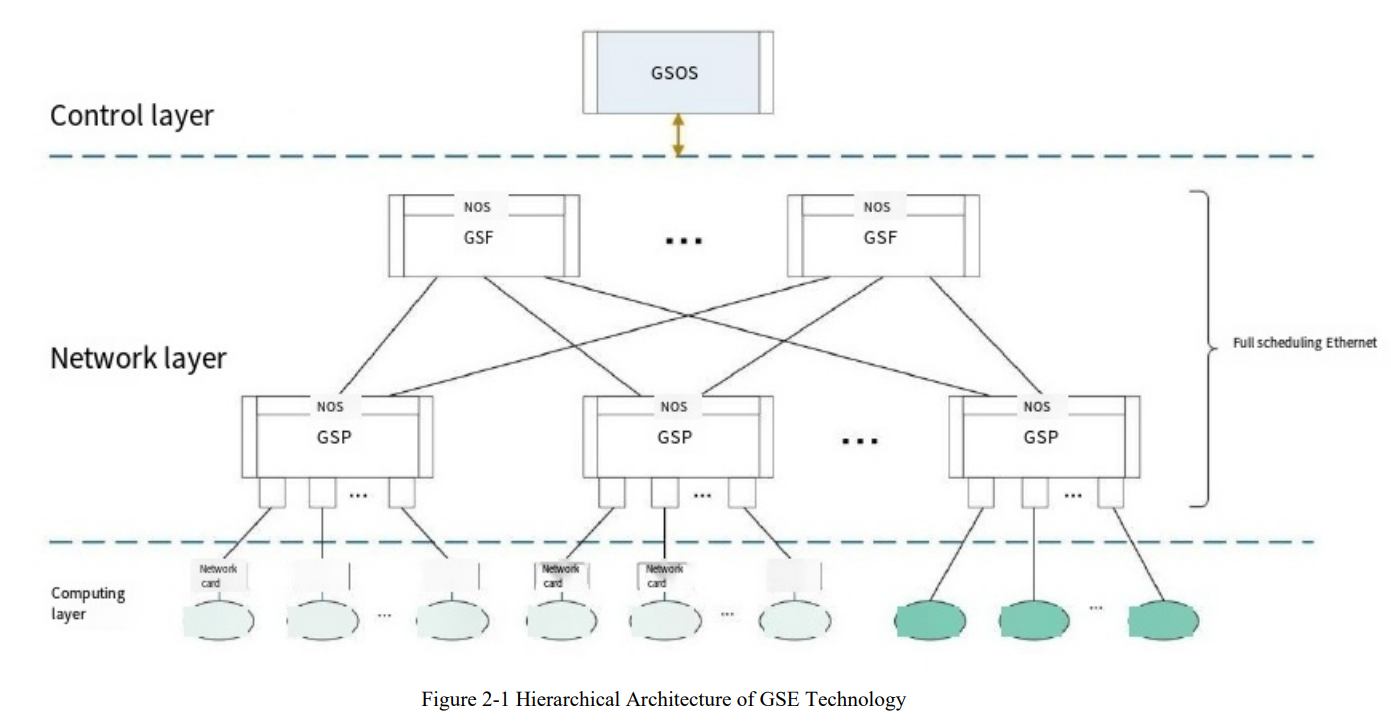
Источник изображения: China Mobile Communications Research Institute В «Белой книге» China Mobile указаны похожие задачи, которые возможно решить с помощью таких методов, как контейнеры пакетов фиксированного размера и «динамическая глобальная очередь планирования», которая не привязана к физическим портам, но учитывает состояние порта целевого устройства перед организацией оптимального соединения с использованием таких способов, как многопутевая доставка (multi-path spraying). Кстати, UEC тоже считает перспективным этот способ. На прошлой неделе китайские СМИ сообщили, что в разработке чипа, который делает GSE Ethernet реальностью, участвовало более 50 провайдеров облачных услуг, производителей оборудования, производителей микросхем и университетов внутри и за пределами Китая. Согласно сообщениям, можно предположить, что GSE Ethernet уже развёрнут в кластере из тысячи серверов в ЦОД China Mobile, где он, по-видимому, обеспечил существенное улучшение производительности сети во время обучения большой языковой модели. Если Китай решил создать и использовать собственную версию Ethernet для некоторых приложений — и его крупные технологические компании готовы её применять — это означает, что членам UEC будет сложнее ориентироваться на китайский рынок (и страны, где доминируют китайские поставщики), пишет The Register. А несколько лет назад Huawei предложила отказаться от TCP/IP в пользу разработанного ей стека New IP.
27.11.2024 [11:48], Сергей Карасёв
El Dorado, младший брат самого мощного в мире суперкомпьютера El Capitan, вошёл в двадцатку TOP500Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) объявили о том, что новый НРС-комплекс El Dorado занял 20-е место в свежем рейтинге самых мощных суперкомпьютеров мира TOP500, обнародованном на конференции SC24. На вершине ноябрьского списка TOP500 находится машина El Capitan, построенная специалистами HPE Cray. Эта система демонстрирует FP64-быстродействие на уровне 1,742 Эфлопс в тесте Linpack (HPL), а пиковый теоретический показатель достигает 2,746 Эфлопс. Основой El Capitan служит платформа HPE Cray Shasta на базе AMD Instinct MI300A. Отмечается, что комплекс El Dorado, по сути, приходится младшим братом El Capitan. Машина El Dorado меньше по масштабу, но архитектурно идентична лидеру рейтинга TOP500. Система построена компанией HPE на платформе Cray EX4000: в общей сложности задействованы 384 узла на основе Instinct MI300A. Суммарное количество ядер составляет 383 040. Используется интерконнект HPE Slingshot-11. Вычислительные узлы используют прямое жидкостное охлаждение. 
Источник изображения: SNL Производительность El Dorado достигает 68,02 Пфлопс, а теоретическое пиковое быстродействие находится на отметке 95,29 Пфлопс. Суперкомпьютер фактически представляет собой мощную тестовую площадку для создания, тестирования и подготовки программного кода перед запуском на машине экзафлопсного класса El Capitan. Кроме того, El Dorado позволит осуществлять определённые научно-исследовательские и опытно-конструкторские работы. |
|

