Материалы по тегу: hardware
|
23.01.2026 [23:54], Владимир Мироненко
Слабый прогноз из-за дефицита компонентов уронил акции Intel, которая решила сосредоточиться на серверных продуктахКомпания Intel объявила результаты за IV квартал и 2025 финансовый год, завершившийся 27 декабря 2025 года. Хотя результаты за квартал превзошли ожидания Уолл-стрит, из-за слабого прогноза на текущий квартал, а также предупреждения о дефиците поставок, акции компании упали в пятницу на 15 %, сообщил ресурс CNBC. Впрочем, несмотря на падение акций после квартального отчёта, компания по-прежнему демонстрирует уверенный старт в 2026 году и с начала года её ценные бумаги выросли в цене на 47 %. Выручка Intel за IV квартал составила $13,7 млрд, что на 4 % меньше год к году, но выше консенсус-прогноза аналитиков, опрошенных LSEG, в размере $13,4 млрд. Скорректированная прибыль на акцию (non-GAAP) равняется 15¢ при прогнозе аналитиков от LSEG в 8¢. Компания сообщила о чистом убытке (GAAP) за отчётный квартал в размере $591 млн, или 12¢ на разводнённую акцию. Годом ранее у неё тоже был чистый убыток, но меньше — $126 млн, или 3¢ на акцию. 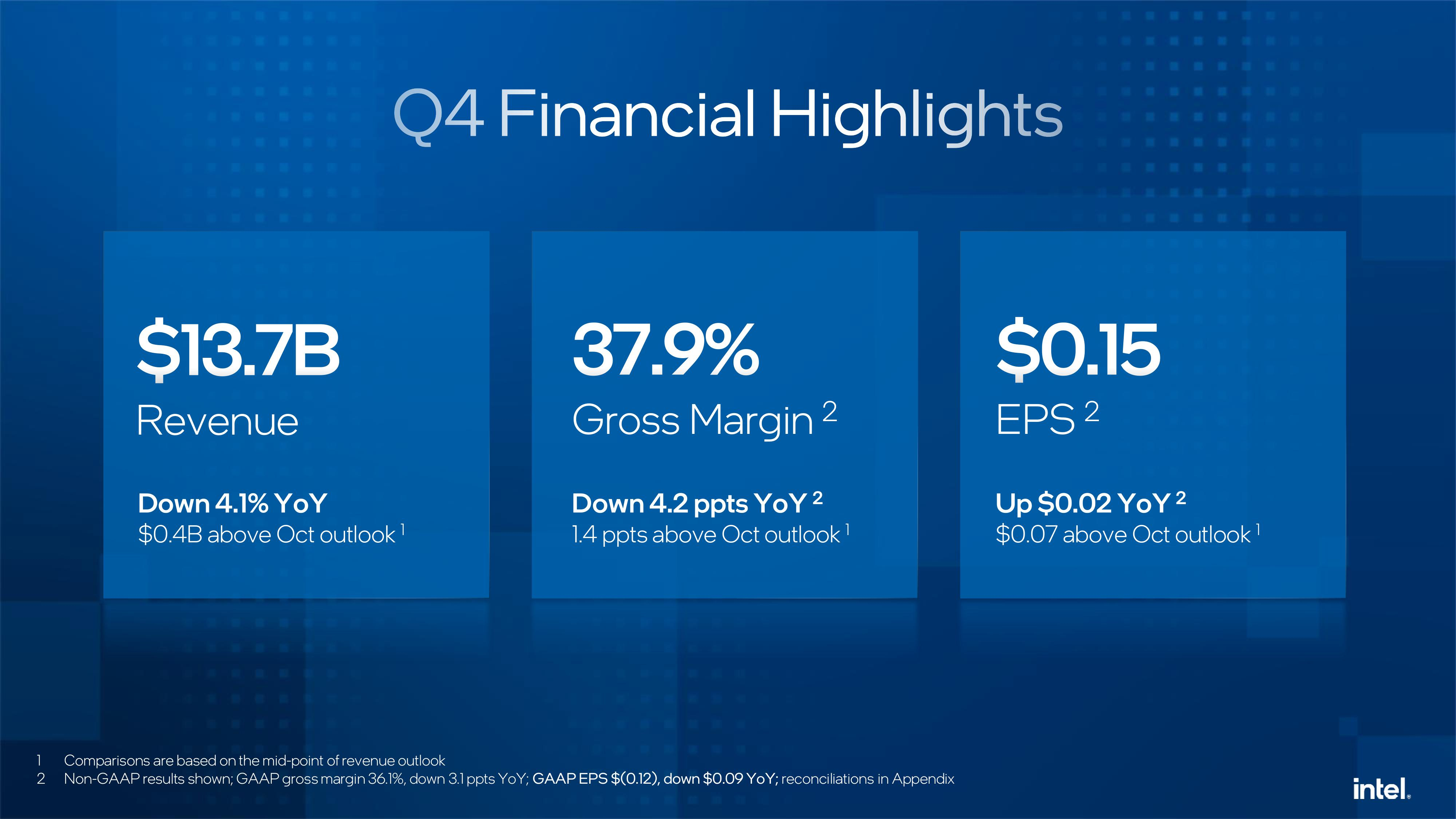
Источник изображений: Intel Intel объявила, что в текущем квартале рассчитывает на безубыточность по скорректированной прибыли на акцию и выручку в диапазоне от $11,7 до $12,7 млрд. Оба показателя оказались ниже прогноза аналитиков, опрошенных LSEG, ожидающих прибыль в размере 5¢ на акцию при выручке в $12,51 млрд. Как сообщает ресурс SiliconANGLE, финансовый директор Intel Дэвид Зинснер (David Zinsner) объяснил снижение прогноза проблемами с поставками компонентов, которых не хватает для удовлетворения сезонного спроса. По его словам, компания пытается решить эту проблему, повышая эффективность производства или выход годной продукции, чтобы увеличить поставки. «Наша производительность соответствует нашим внутренним планам», — сказал генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan), отметив, что она по-прежнему ниже того уровня, которого ему хотелось бы достичь. 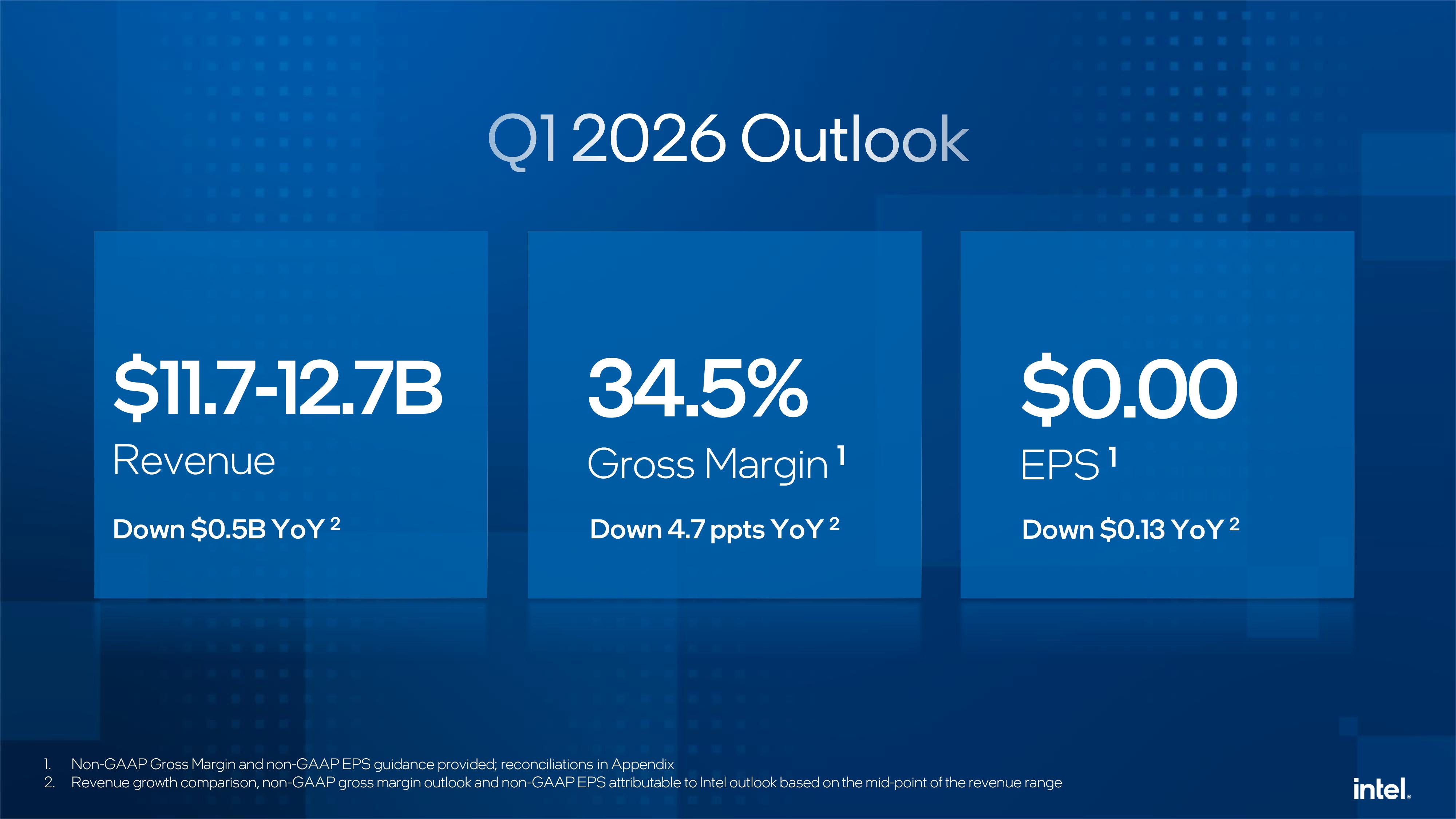 Выручка подразделения Datacenter and AI Group (DCAI), которое специализируется на продуктах для ЦОД и ИИ, выросла год к году на 9 % до $4,74 млрд. Операционная прибыль подразделения составила $1,25 млрд. Выручка потребительской группы Client Computing Group (CCG) упала на 7 % до $8,19 млрд. Подразделение Intel Foundry, которое занимается производством чипов, получило выручку в размере $4,51 млрд, что выше год к году на 4 %. При этом его операционный убыток составил $2,51 млрд. Годом ранее подразделение тоже сработало с убытком, составившим $2,25 млрд при выручке $4,34 млрд. Как отметил The Register, по сравнению с катастрофой, которой стал для Intel 2024 финансовый год, прошедший год был значительно лучше. В 2025 году компания понесла убытки всего в $267 млн при выручке в $52,9 млрд. Это значительно лучше рекордных убытков в $18,8 млрд годом ранее. В ходе общения с аналитиками Зинснер признал, что компания оказалась в затруднительном положении после того, как неправильно оценила спрос на свою продукцию для ЦОД, что привело к дефициту мощностей в течение квартала.  Дело в том, что полгода назад почти все гипескейлеры говорили о планах заказать меньшее количество чипов с большим количеством ядер, но затем их позиция изменились, и спрос на продукты Intel Xeon значительно вырос в III и IV кварталах. Платформа Intel Xeon 6 широко используется в ИИ-системах, таких как NVIDIA DGX B200 и B300, а также во многих системах с AMD Instinct. Чтобы удовлетворить этот спрос, компания «перенаправляет как можно больше ресурсов в ЦОД», отметил Зинснер. При этом он заверил, что компания не откажется от своего клиентского бизнеса «полностью» в погоне за доходами от ИИ в ЦОД. «В клиентском сегменте мы фокусируемся на среднем и высоком сегментах, а на низком — не так сильно. В той мере, в какой у нас есть избыточные мощности, мы направляем их производство для ЦОД», — сказал финансовый директор. 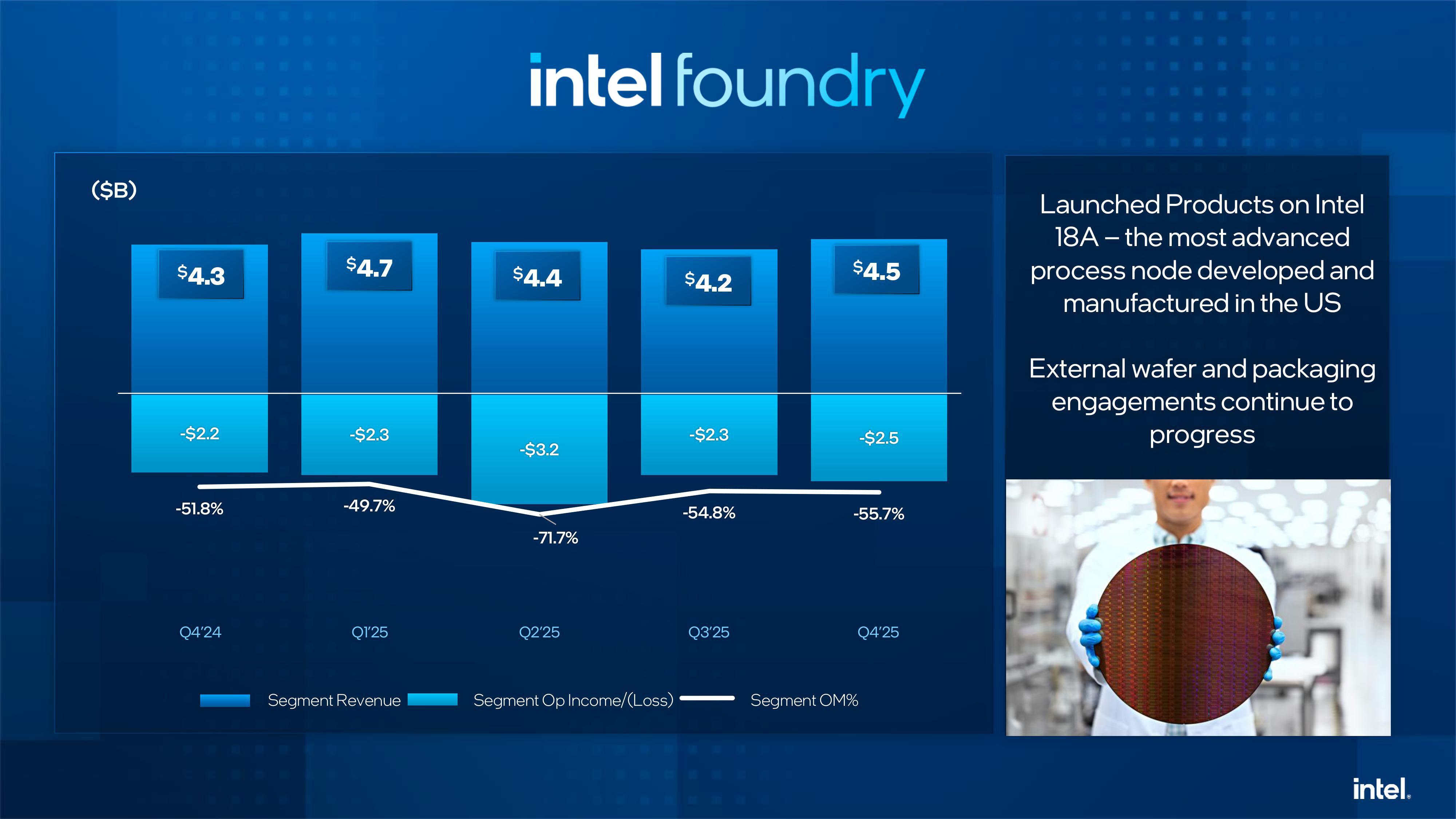 Ранее в этом месяце Тан заявил, что технология производства 18A, конкурирующая с 2-нм техпроцессом TSMC, «превзошла ожидания» в 2025 году. Он указал в годовом отчёте, что Intel «активно работает» над увеличением поставок продукции, изготовленной по техпроцессу 18A, для удовлетворения «высокого спроса со стороны клиентов». Зинснер сообщил ресурсу CNBC, что клиенты для следующего техпроцесса 14A от Intel появятся во II половине года. При этом компания не собирается публично об этом объявлять. «Как только мы их получим, нам нужно будет вкладывать значительные средства в развитие 14A, и тогда вы поймёте, что происходит», — сказал он. Вместе с тем аналитики RBC Capital Markets предупредили, что «значительный вклад в выручку» от клиентов продуктов согласно техпроцессу 14A может появиться не раньше конца 2028 года.
23.01.2026 [17:11], Руслан Авдеев
АЭС — это долго: в Казахстане построят «долину ЦОД» с питанием от угольных электростанцийПравительство Казахстана при содействии акимата Павлодарской области намерено построить в Экибастузе «долину ЦОД». Энергоснабжение дата-центров будет осуществляться за счёт местного угля, сообщает издание «Курсив» со ссылкой на президента страны Касым-Жомарта Токаева, который подчеркнул необходимость ввода в строй новых энергомощностей, не дожидаясь окончания строительства новых АЭС — возводить угольные электростанции просто необходимо. По словам президента, по энергопотреблению ЦОД сопоставимы с металлургическими предприятиями, поэтому энергетическая самодостаточность должна стать приоритетом государственной политики — в 2025 году генерация в стране составила 123 млрд кВт∙ч, этого слишком мало для того, чтобы успешно выполнить все поставленные задачи. Президент подчеркнул, что необходимо задействовать конкурентные преимущества страны — колоссальные запасы угля в объёме около 33 млрд т, которых с учётом современного уровня потребления должно хватить на 300 лет. 
Источник изображения: forzaalisherka/unsplash.com Как сообщило издание Bizmedia.kz, новый угольный проект предусматривает гибкие схемы участия:
Для участников проектов предполагаются налоговые преференции по принципам, характерным для специальных экономических зон (СЭЗ). Токаев поддержал позицию президента США Дональда Трампа (Donald Trump), не так давно давшего «зелёный свет» угольной энергетике. Добыча угля в Казахстане составляет более 110 млн т/год, поэтому Токаев подчеркнул, что «развитию угольной генерации нужно придать статус национального проекта». На повестке дня ускоренное строительство новых ТЭЦ в Кокшетау, Семее и Усть-Каменогорске. 
Источник изображения: Bart van Dijk/unsplash.com На сегодня Казахстан находится в десятке лидеров и по добыче, и по имеющимся запасам угля. Сообщается, что при продлении контрактов с угледобывающими компаниями власти будут включать обязательства последних по глубокой переработке угля. По оценкам Министерства промышленности и строительства (МПС) Казахстана, запуска и модернизация угольных электростанций увеличит потребление угля на 10 млн т/год. «Курсив» отмечает, что ранее обновлённый прогноз свидетельствовал, что в ближайшие годы Казахстан добьётся существенного профицита в добыче электроэнергии, избавившись от дефицита. У Казахстана большие амбиции на рынке ЦОД и сопутствующей инфраструктуры. Только в 2025 году подписано соглашение с Freedom Telecom Holding о строительстве оптоволоконной гипермагистрали Запад–Восток, а также ЦОД уровня не ниже Tier III для транзита и хранения международного трафика. Позже заявлялось, что в Казахстане заработает самый большой ЦОД в Центральной Азии, а в конце октября появилась новость, что Россия и Казахстан намерены проложить интернет-кабель по дну Каспийского моря. В 2025 году в Алматы и Астане введены в эксплуатацию два новых ЦОД мощностью 7,4 МВт, в 2026 году планируется запуск ещё трех ЦОД мощностью 12,9 МВт.
23.01.2026 [16:42], Владимир Мироненко
OpenAI готовит крупнейший в своей истории раунд финансирования на $50 млрд при участии инвесторов Ближнего ВостокаСогласно появившимся в прессе сообщениям, генеральный директор OpenAI Сэм Альтман (Sam Altman) проводит в ОАЭ переговоры о привлечении инвестиций для грядущего раунда финансирования объёмом до $50 млрд, передают источники Bloomberg. Условия ещё не утверждены, но ожидается, что раунд будет завершён в I квартале 2026 года. Всего три месяца назад OpenAI завершила продажу акций на сумму $6,6 млрд с оценкой рыночной стоимости в $500 млрд. До этого, в марте 2025 года компания провела раунд финансирования на $40 млрд, возглавляемый SoftBank при участии Microsoft и других крупных игроков, таких как Coatue, Altimeter и Thrive. Любопытно, что Anthropic тоже намерена привлечь инвестиции с Ближнего Востока, но не очень этому рада. Как пишет ресурс eWeek, суверенные фонды Ближнего Востока стали доминирующей силой в глобальных инвестициях в ИИ, вложив только в 2025 году $66 млрд в ИИ и цифровую инфраструктуру, что является самой большой долей инвестиций в ИИ в мире. Суверенный фонд благосостояния Саудовской Аравии (PIF) в прошлом году выделил $36,2 млрд на инициативы в области ИИ, в то время как Mubadala из ОАЭ инвестировала $12,9 млрд в ИИ и цифровые активы. Вместе семь крупнейших фондов Персидского залива представляли 43 % всего суверенного капитала, инвестированного в мире в 2025 году, вложив рекордную сумму $126 млрд. 
Источник изображения: Growtika/unsplash.com Как сообщила ранее Deloitte, суверенные фонды Персидского залива рассматривают ИИ как «стратегический актив», а не как спекулятивную игру. Согласно прогнозам, опубликованным в начале этого месяца, к 2030 году доля ИИ в ВВП ОАЭ составит 14 %, а в ВВП Саудовской Аравии — 12,4 %. Новый раунд нацелен на выполнение масштабных инфраструктурных проектов, уже находящихся в стадии реализации. OpenAI заключила партнёрское соглашение с G42, поддерживаемой инвестиционной компанией Mubadala, для разработки кластера ЦОД мощностью 5 ГВт в Абу-Даби — части более масштабного проекта Stargate. Как отметил eWeek, фонды из Абу-Даби за последний год инвестировали $31 млрд во французские ЦОД и $40 млрд в американские объекты, а консорциум во главе с MGX из Абу-Даби в октябре 2025 года заключил сделку на $40 млрд по приобретению Aligned Data Centers. Согласно анализу EY, за первые девять месяцев 2025 года суверенные фонды благосостояния участвовали в венчурных сделках в сфере ИИ на общую сумму $46 млрд, что составляет почти половину всех венчурных инвестиций в ИИ за год. Геополитические последствия этого подхода не менее значительны. В США приветствуют инвестиции стран Персидского залива в ЦОД и полупроводники как способ противодействия влиянию Китая на цепочки поставок в сфере ИИ. К 2035 году на регион Персидского залива может приходиться 5-10 % новых глобальных развёртываний ИИ-ускорителей, что позиционирует страны Ближнего Востока как критически важных партнёров по инфраструктуре для американских ИИ-компаний.
23.01.2026 [13:07], Руслан Авдеев
Застопорившаяся сделка с Intel заставила SambaNova искать $500 млн дополнительных инвестицийПоставщик ИИ-ускорителей SmabaNova рассчитывает привлечь до $500 млн в ходе раунда финансирования после того, как приостановились переговоры с Intel. Последняя рассматривала возможность покупки SambaNova, пишет Bloomberg. Ранее появилась информация, что компании вели расширенные дискуссии о возможном поглощении SambaNova, включая долг, компанией Intel за $1,6 млрд, но окончательное решение так и не было принято. Переговоры пока не принесли результатов, и поставщик ИИ-решений теперь ищет инвестиции из других источников — технологических компаний и производителей полупроводников. При этом глава Intel Лип-Бу Тан (Lip-Bu Tan) одновременно является председателем SambaNova. Первые слухи о том, что SambaNova рассматривает возможность продажи, появились в октябре 2025 года. По данным источников The Information, компания наняла инвестиционную структуру для того, чтобы та курировала потенциальную покупку. 
Источник изображения: SambaNova В 2021 году SambaNova оценивалась в $5 млрд, а всего с момента основания привлекла более $1,1 млрд от инвесторов, включая GV, Intel Capital, BlackRock и SoftBank Vision Fund. Однако BlackRock, владеющая акциями SambaNova, ранее снизила оценку до $2,4 млрд. Теперь же, по-видимому, даже оценка в $1,6 млрд не является корректной. Основанная в 2017 году SambaNova изначально ориентировалась на обучение ИИ-моделей, но затем переключилась на услуги облачного и локального инференса с использованием собственных ИИ-чипов SN40L, представленных в сентябре 2023 года.
23.01.2026 [12:23], Сергей Карасёв
TrendForce: мировые поставки ИИ-серверов в 2026 году поднимутся на 28 %По данным компании TrendForce, глобальные поставки серверов в 2025 году поднялись на 7,8 % по сравнению с предыдущим годом, тогда как в сегменте ИИ-систем зафиксирован рост на 24,2 % (абсолютные цифры не приводятся). Аналитики полагают, что в 2026-м общий объём рынка увеличится на 12,8 %, а отгрузки серверов для ИИ-задач подскочат на 28,3 %. В 2025 году, согласно оценкам TrendForce, в сегменте ИИ-серверов доминировали системы, оснащённые ускорителями на базе GPU: их доля составила 75,9 %. Ещё 20,9 % пришлось на машины с ASIC и ускорителями других типов, 3,2 % — на устройства с FPGA. 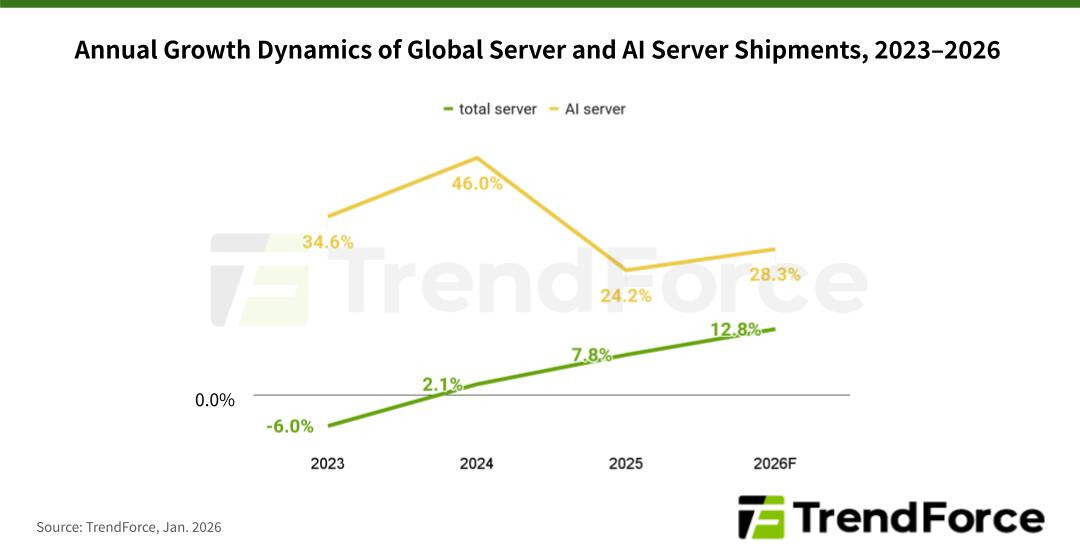
Источник изображений: TrendForce В 2026 году, как полагают эксперты, расстановка сил изменится. Связано это с тем, что в 2024–2025 гг. нагрузки ИИ были сфокусированы преимущественно на обучении больших языковых моделей (LLM) с огромным количеством параметров. Однако к концу 2025 года наметился сдвиг в сторону инференса и использования ИИ-агентов. Прогнозируется, что по итогам 2026-го доля ИИ-серверов на основе GPU сократится до 69,7 %. Вместе с тем до 27,8 % поднимется доля систем, в состав которых входят ASIC. На машины с FPGA при этом придётся 2,5 %. Прогнозируется также, что темпы роста поставок ИИ-серверов на базе ASIC будут выше, чем темпы роста отгрузок GPU-систем. Отмечается, что такие компании, как Google и Meta✴, ускоряют разработку собственных ASIC. 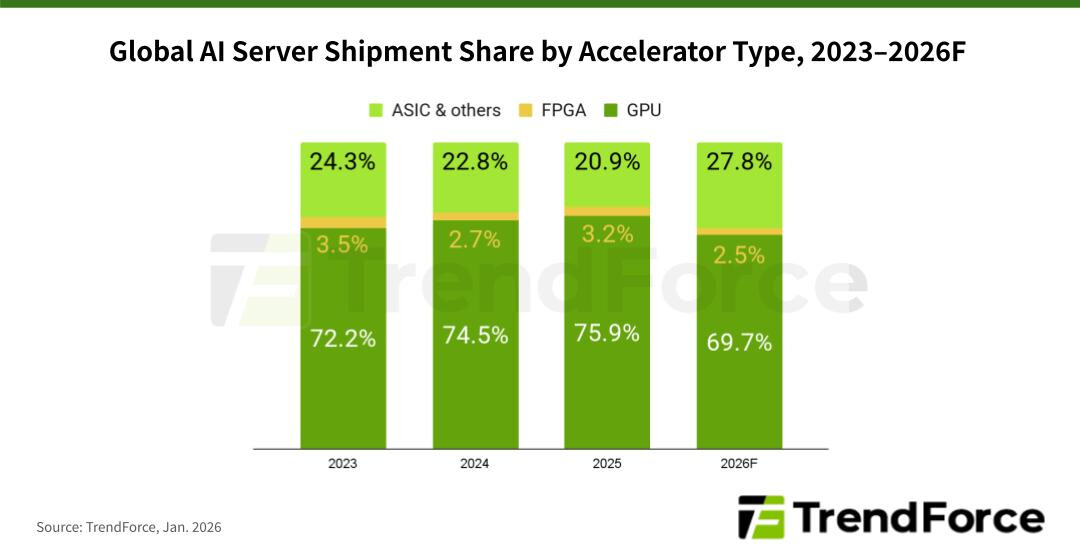 TrendForce полагает, что совокупные капитальные затраты пяти крупнейших североамериканских провайдеров облачных услуг — Google, AWS, Meta✴, Microsoft и Oracle — увеличатся в 2026 году на 40 % по отношению к предыдущему году. Помимо масштабного развития инфраструктуры дата-центров, часть средств пойдёт на обновление серверов общего назначения, приобретённых во время бума облачного рынка в 2019–2021 гг.
23.01.2026 [12:18], Сергей Карасёв
Чип Qualcomm и модуль 5G: одноплатный компьютер Advantech MIO-5355 ориентирован на ИИ-задачи на периферииКомпания Advantech анонсировала индустриальный одноплатный компьютер MIO-5355, выполненный в 3,5″ форм-факторе на аппаратной платформе Qualcomm. Устройство предназначено для решения различных ИИ-задач на периферии, в том числе в суровых условиях эксплуатации — при температурах от -20 до +70 °C. Новинка доступна в двух модификациях. Старшая версия несет на борту процессор Qualcomm DragonWing QCS6490 с восемью ядрами Kryo 670 в конфигурации 1 × Gold Plus (Cortex-A78) с частотой 2,7 ГГц, 3 × Gold (Cortex-A78) с частотой 2,4 ГГц и 4 × Silver (Cortex-A55) с частотой до 1,9 ГГц. В состав чипа входит графический ускоритель Adreno 643 (812 МГц) с поддержкой Open GL ES 3.2, Open CL 2.0, Vulkan 1.x, DX FL 12. Встроенный VPU-блок Adreno 633 обеспечивает возможность декодирования материалов 4K60 H.264/H.265/VP9 и кодирования 4K30 H.264/H.265. Кроме того, имеется ИИ-движок Qualcomm AI Engine шестого поколения с производительностью до 12,3 TOPS. 
Источник изображения: Advantech Менее мощная версия получила процессор Qualcomm DragonWing QCS5430 с шестью ядрами Kryo 670 в виде связки 2 × Gold Plus (Cortex-A78) с частотой до 2,1 ГГц и 4 × Silver (Cortex-A55) с частотой до 1,8 ГГц. Графический ускоритель Adreno 642L (812 МГц) обладает поддержкой OpenGL ES 3.2, DirectX FL 12, OpenCL 2.0 и Vulkan. Модуль VPU Adreno 642L способен декодировать материалы 4K60 H.264/H.265/VP9 и кодировать 4K30 H.264/H.265. Быстродействие на операциях ИИ составляет до 3,5 TOPS. Объём оперативной памяти LPDDR5 в обоих вариантах равен 8 Гбайт. Возможна установка флеш-модуля UFS или eMMC вместимостью до 128 Гбайт, NVMe SSD формата M.2 2280 и карты microSD. Есть двухпортовый сетевой контроллер 1GbE на основе Realtek RTL8211FS. Опционально могут быть добавлены комбинированный адаптер Wi-Fi/Bluetooth (модуль M.2 E-Key) и модем 5G/4G (M.2 B-Key плюс слот Nano-SIM). Допускается вывод изображения одновременно на два монитора через интерфейсы HDMI 2.0 (до 4К; 60 Гц) и LVDS (1920 × 1080 пикселей) или eDP 1.4. Предусмотрены по два порта USB 3.0 Type-A и USB 2.0 Type-A, два гнезда RJ45 для сетевых кабелей, аудиогнездо на 3,5 мм (кодек Realtek ALC5682I), два интерфейса камер MIPI-CSI (по 4 линии). Через разъёмы на плате можно задействовать по два последовательных порта RS-232/422/485 и RS-232, а также по два порта USB 3.0 и USB 2.0. Габариты составляют 146 × 102 мм, масса — 128 г (без радиатора охлаждения). Питание подаётся через ATX-коннектор. Заявлена совместимость с Windows 11 IoT Enterprise, Ubuntu 24.04 LTS и Yocto Linux.
23.01.2026 [09:22], Руслан Авдеев
FuelCell Energy и SDCL поставят дата-центрам топливные ячейки на 450 МВтАмериканская компания FuelCell Energy и британская инвестиционная компания Sustainable Development Capital (SDCL) объявили о поставках дата-центрам топливных ячеек общей мощностью до 450 МВт, сообщает Datacenter Knowledge. FuelCell Energy делает акцент на переходе к новой архитектуре с централизованным электропитанием 800 В DC, оптимальным для масштабирования ИИ-инфраструктуры ЦОД. Подчёркивается, что системы FuelCell Energy могут обеспечить прямое DC-питание «мегаваттного уровня» в обход электросетей. При этом клиенты пока могут приобретать AC-варианты систем с последующим переходом на постоянный ток без замены силовых модулей. FuelCell Energy выпускает карбонатные топливные ячейки Molten Carbonate Fuel Cells (MCFC) мощностью 2,5 МВт и 1,25 МВт, способные работать на биогазе, природном газе и смесях того и другого с добавлением до 50 % водорода. Также компания заявляет, что её системы могут генерировать горячую и холодную воду, а также пар высокого давления. 
Источник изображения: FuelCell Energy Более крупный конкурент Bloom Energy выпускает твердооксидные топливные элементы (SOFC), уже присутствующие на рынке дата-центров. Места для роста на рынке топливных элементов пока достаточно. По оценкам, к 2030 году совокупная выручка в этой нише достигнет $18,6 млрд, в 2025 году она составила $5,6 млрд. В исследованиях Canaccord Genuity указывается, что FuelCell Energy всё ещё необходимо показать пример конкурентоспособного внедрения в сегменте ЦОД. FuelCell — не новичок на рынке. В марте 2025 года сообщалось, что она, в числе других компаний, намерена использовать газ из угольных шахт для энергоснабжения ЦОД, а в июле появилась информация, что Inuverse планирует оснастить дата-центр AI Daegu Data Center в Южной Корее её топливными элементами.
22.01.2026 [17:43], Сергей Карасёв
Алюминиевый корпус и интерфейс USB 3.0: официальная флешка Raspberry Pi Flash Drive стоит от $30Компания Raspberry Pi анонсировала фирменный флеш-брелок под названием Raspberry Pi Flash Drive. Устройство доступно для заказа в модификациях вместимостью 128 и 256 Гбайт по ориентировочной цене $30 и $55 соответственно. Производитель популярных одноплатных компьютеров отмечает, что у многих пользователей, которым нужна флешка для резервного копирования данных или их передачи между разными системами, часто возникает соблазн купить самый дешевый вариант на маркетплейсе или в ближайшем магазине. Но в этом случае покупатели рискуют получить некачественное устройство с низкими скоростями чтения и записи, хрупким корпусом или гораздо меньшей вместимостью, нежели заявлено. Изделие Raspberry Pi Flash Drive лишено всех этих недостатков. 
Источник изображения: Raspberry Pi Для обмена данными служит интерфейс USB 3.0 (Type-A). Заявленная скорость записи достигает 75 Мбайт/с у варианта на 128 Гбайт и 150 Мбайт/с у версии ёмкостью 256 Гбайт. Говорится, что накопителю не страшны внезапные отсоединения от порта и сбои питания. Устройство наделено кешем pSLC для кратковременного повышения производительности при записи. Реализована поддержка средств мониторинга S.M.A.R.T., а также команд TRIM. При простое флешка автоматически переходит в режим пониженного энергопотребления. Новинка заключена в прочный полностью алюминиевый корпус, заявляет компания. Имеется отверстие для крепления, что позволяет носить брелок, например, на связке ключей. На поверхности выгравирован логотип Raspberry Pi.
22.01.2026 [17:40], Руслан Авдеев
OpenAI представила программу Stargate Community для налаживания добрососедских отношений с местными жителямиКомпания OpenAI, объявившая о намерении создать «общий искусственный интеллект» (AGI) на благо всего человечества, намерена организовать работу таким образом, чтобы в ходе достижения этой цели её кампусы приносили пользу местным жителям. С этой целью компания представила программу Stargate Community, способствующую развитию экономики и созданию рабочих мест в регионах присутствия. В рамках инициативы Stargate компания задалась целью нарастить инфраструктуру ИИ в США до 10 ГВт к 2029 году. Первый объект в Абилине (Abilene, Техас) уже работает, новые объекты строятся по всей стране. С момента запуска в январе 2025 года, партнёры по Stargate анонсировали несколько проектов большой мощности по всему миру. В сентябре были анонсированы планы построить пять кампусов ЦОД в Техасе, Нью-Мексико, Висконсине и Мичигане общей мощностью 5,5 ГВт. ИИ уже приносит ощутимую пользу, помогая сотням людей в вопросах здоровья и обеспечения общего благополучия, говорит OpenAI. В будущем каждая площадка Stargate будет иметь собственный план Stargate Community, подготовленный с учётом местных проблем. По словам компании, добиться результатов можно, только будучи «хорошими соседями». 
Источник изображения: Nathan Fertig / Unsplash Компания намерена компенсировать свои энергопотребности таким образом, что это не будет приводить к росту тарифов на электричество для местных жителей, строя энергохранилища, оплачивая создание генерирующих мощностей и модернизацию электросетей, разрабатывая режимы гибкого эгнергопотребления и др. Так, в Висконсине Oracle и Vantage совместно с WEC Energy Group развивают генерирующие мощности и полностью берут на себя расходы на энергетическую инфраструктуру нового объекта, чтобы все затраты на энергосети для ИИ ЦОД не перекладывались на обычных потребителей. В Мичигане Oracle и Related Digital взаимодействуют с DTE Energy в вопросе использования существующих энергоресурсов, дополненных новым аккумуляторным хранилищем, оплаченным проектом. Наконец, в Техасе принадлежащая SoftBank компания SB Energy рассчитывает построить новые генерирующие мощности и системы хранения энергии, чтобы обеспечить большую часть потребностей местного кампуса Stargate на 1,2 ГВт. OpenAI также приветствует инициативу Microsoft Community-First AI Infrastructure Plan, распространяющуюся на строящиеся для OpenAI кампусы, в рамках которой компания тоже пообещала сохранить стабильные тарифы на электроэнергию для обычных граждан, стать водноположительной, обучать и создавать рабочие места для местных жителей, а также направлять средства на социальные нужды и поддерживать местные НКО. 
Источник изображения: OpenAI В OpenAI тоже придерживаются подхода, при котором используются замкнутые или использующие мало питьевой воды системы охлаждения. Власти Абилина утверждают, что местный кампус будет потреблять в год вдвое меньше, чем город использует за день. Такие же решения внедряются в кампусах Stargate в других локациях, а в Висконсине не менее $175 млн направят на местную инфраструктуру и проекты восстановления водных ресурсов. В Абилине же откроется первая OpenAI Academу для подготовки специалистов в области ИИ ЦОД, от строителей до управляющих. Несмотря на все попытки OpenAI и партнёров, а также указы правительства, у экспертов и общественности сохраняются опасения, что крупные ИИ ЦОД приведут к росту цен на электричество. Вызывает обеспокоенность и вероятное использование природного газа для энергоснабжения объектов Stargate. В марте 2025 года сообщалось, что Crusoe, ответственная за строительство ЦОД в Абилине, заказала газовые турбины общей мощностью 4,5 ГВт для питания сети ЦОД.
22.01.2026 [14:12], Руслан Авдеев
Alibaba создала совместное предприятие с Китайской национальной ядерной корпорациейКитайский техногигант Alibaba Group запустил совместное предприятие с принадлежащей государству компанией China National Nuclear Company (CNNC), занимающейся реализацией атомных проектов. Проект оценивается в ¥250 млн ($35,9 млн), сообщает Bloomberg. Оговорены потенциальные сферы сотрудничества, включая генерацию энергии, но реальные масштабы взаимодействия пока не разглашаются, а сама Alibaba информацию не комментирует. Новое соглашение потенциально имеет важное влияние на достижение целей Китая в сфере искусственного интеллекта. Alibaba является одним из крупнейших облачных провайдеров в стране, распоряжаясь дюжиной облачных регионов и почти 60 зонами доступности в Китае и Гонконге. В следующие несколько лет компания намерена выделить на развитие инфраструктуры $53 млрд, значительная часть их этих средств пойдёт на строительство ИИ ЦОД. CNNC основана в 1955 году и управляет одним из крупнейших парков атомных электростанций в мире. По данным за 2025 год, около 25 объектов генерируют более 23 ГВт. В портфолио у компании имеется и ещё 15–17 строящихся или одобренных для строительства объектов совокупной мощностью более 20 ГВт. Всего в КНР сегодня строятся 38–44 реактора, каждый год страна намерена достраивать по 6–10 из них. 
Источник изображения: Amina Atar/unsplash.com По данным Datacenter Dynamics, Китай активно развивает атомную энергетику, планируя добиться 200 ГВт генерации к 2035 году, и 400–500 ГВт — к 2050 году. В отличие от США, где рост атомных проектов во многом связан с малыми модульными реакторами (SMR), Китай будет полагаться преимущественно на классические АЭС. Речь идёт о крупных реакторах, которые Китай способен строить дешевле и быстрее, чем США, благодаря государственному финансированию, использованию стандартизированных проектов и отработанному процессу лицензирования, без столь жёстких требований к проектам, как в Соединённых Штатах. Сделка — первая в своём роде между технологической компанией и застройщиком АЭС в Китае. За последние пару лет в США уже были подобные соглашения, например, недавно Meta✴ подписала три договора, два из которых — с разработчиками малых модульных реакторов TerraPower и Oklo, а один — с энергетическим гигантом Vistra. В общей сложности сделки обеспечат IT-гиганту доступ к 6,6 ГВт. Похожие сделки заключили Amazon (АЭС Susquehanna, SMR X-Energy), Google (АЭС DAEC, SMR Kairos) и Microsoft (АЭС Three Miles Island). |
|

